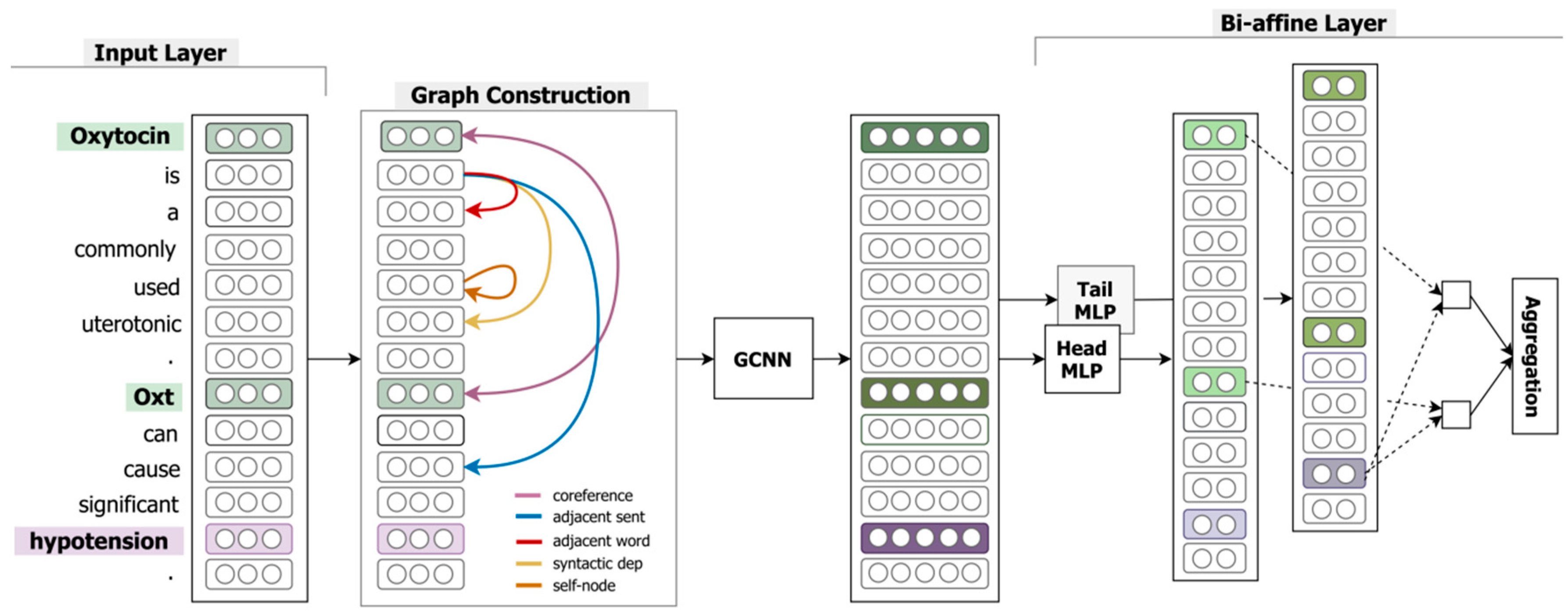
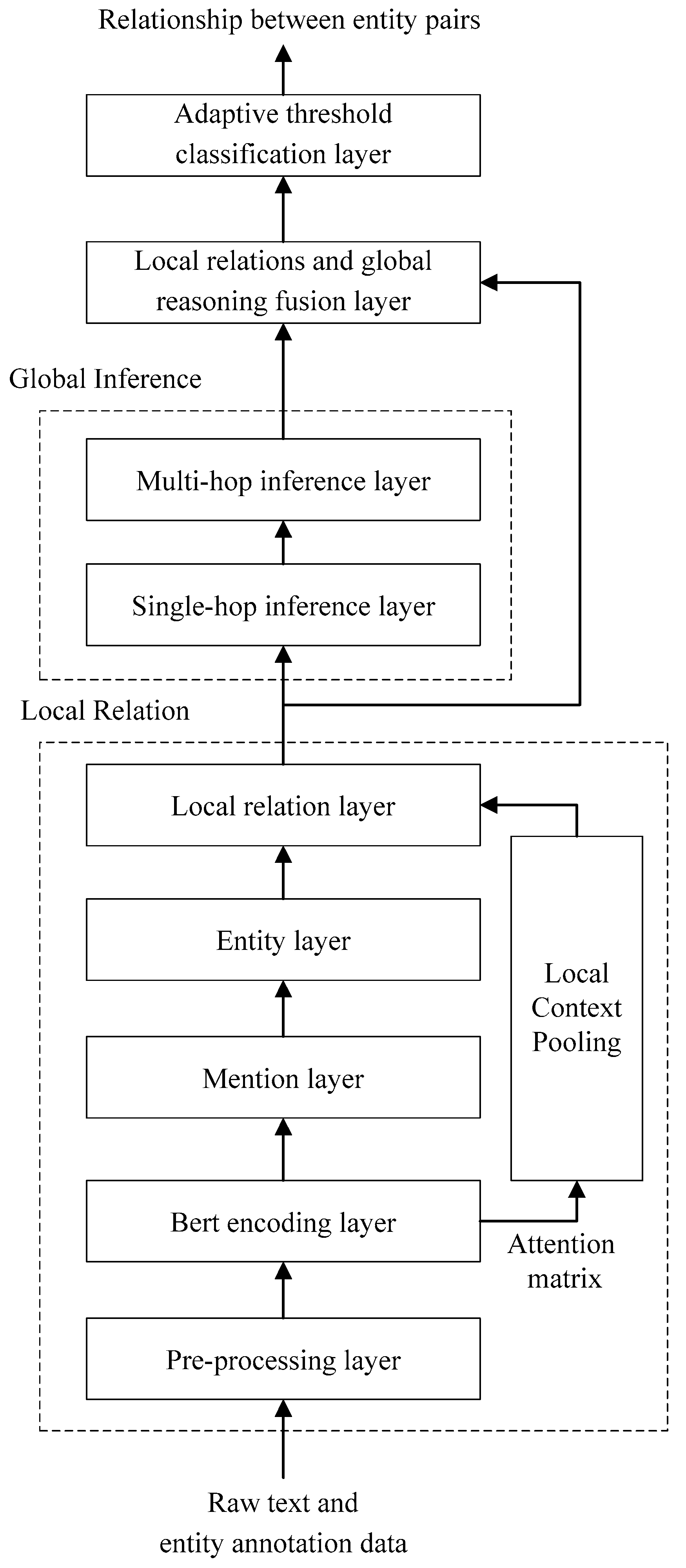
Local relations between entity pairs are obtained using local context pooling, which relies on the attention mechanism in the BERT pre-training model. However, the attention mechanism is affected by the sentence length, and the longer the sentence length is, the more the accuracy of its relation extraction gradually decreases, which is especially obvious in document-level relation extraction.
To address this issue, the ATLOP model is extended in this paper to implement global relational inference.
On the basis of local context pooling of text contents to obtain local relations between entity pairs, Floyd’s algorithm is improved to perform global inference, i.e., to derive global relations between entity pairs from local relations.
In the process of global inference, the computation of relationships between entity pairs will no longer depend on the entity positions in the document but on the local relationships.
Floyd’s algorithm is improved by this model, and an explicit relation inference mechanism (explicit relation inference layer based on the improved Floyd’s algorithm) is proposed to solve the global relation for any pair of entities ( and ) with as the head entity and as the tail entity.
3.3.2. Explicit Relational Inference Based on Improved Floyd’s Algorithm
The explicit relational inference mechanism proposed in this paper is a modification of the state transfer equation of the classical Floyd algorithm.
(1) Single-hop relational inference mechanism
The distance
in the state transfer equation in the classical Floyd algorithm is modified to a local relation vector
. Since the inference relation
containing information about the intermediate entity
with
as the head entity and
as the tail entity cannot be obtained by direct summation of the local relations, the computational model of the distance between node
and node
passing through intermediate node
under the constraint of a single intermediate node is modified from
to a neural network constructed with a bilinear function whose inputs are two local relations
and
, as Equation (12) shows:
where
,
are the training parameters in the global inference layer neural network.
In order to fuse the information of all paths, the set of entities (
…
) except
and
is represented by
. After traversing all intermediate nodes, the minimum value calculation method in the classical Floyd algorithm is modified to calculate the average value for all inference relation vectors containing information of a single intermediate node to obtain the global inference relation
for the entity pair. The modified state transfer equation is shown in Equation (13):
where
is the number of entities in the set
.
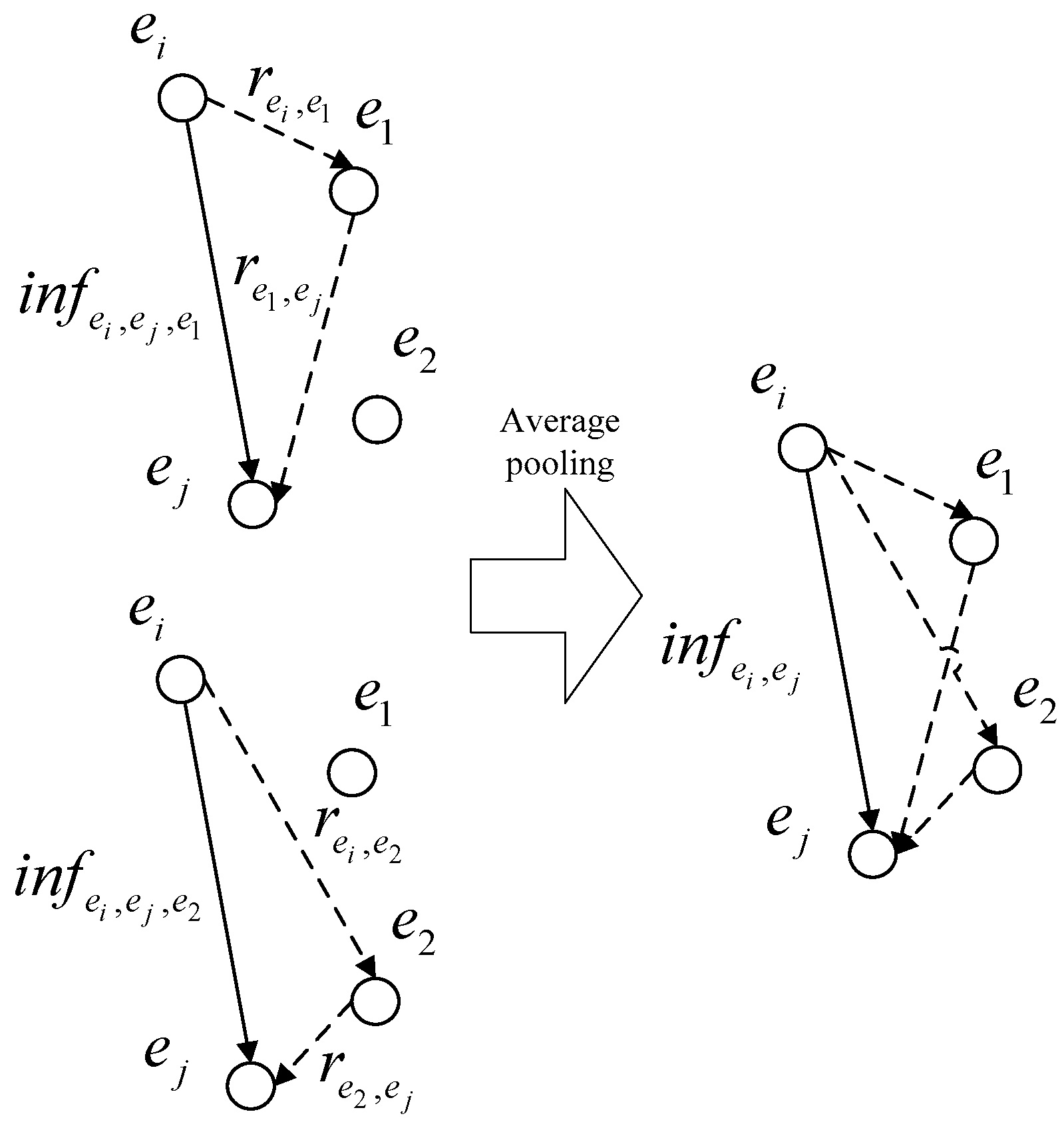
When
, the single-hop relational inference process based on the improved Floyd algorithm is shown in
Figure 6.
The nodes in
Figure 6 represent entities, the edges represent local relations, and the weights of the edges are the local relation vectors, which are calculated by the method in
Section 3.2. The direction of the edge is the direction of the relationship.
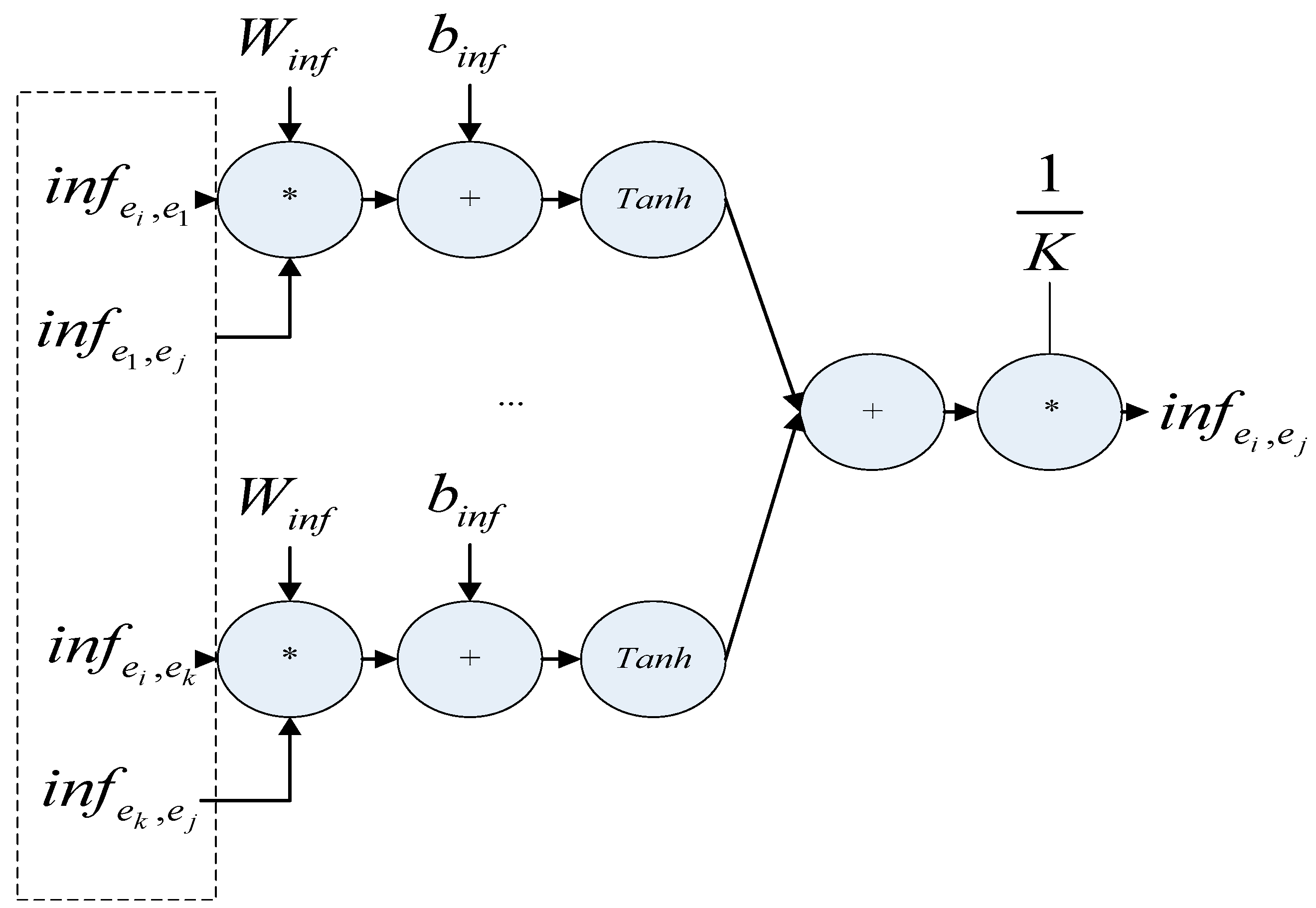
Single-hop relational inference takes the entities in the document other than the head entity and the tail entity as the intermediate entities of the global inference relation, and for each intermediate entity , a neural network model constructed with a bilinear function is used to obtain the inference relation between pairs of entities containing the intermediate entity .
After traversing the intermediate entities, the global inference relation between pairs of entities containing a single intermediate entity is obtained by pooling the mean value between the pairs of entities containing a single intermediate entity .
In order to make full use of the rich relationship information implied between multiple entities in documents, the single-hop relationship inference algorithm is extended to propose a multi-hop relationship extraction calculation.
(2) Multi-hop relational inference mechanism
The entities in the document other than the head entity and the tail entity are used as intermediate entities for multiple relationship inference.
For each intermediate entity , two global single-hop inference relations with as the head entity and as the tail entity and with as the head entity and as the tail entity, respectively, are obtained by inference about the single-hop relations, as shown in Equation (13).
Each global single-hop inference relation is obtained by traversing the intermediate entities other than the head and tail entities of the global single-hop inference relation in the document to complete the inference calculation.
We fed and into a neural network constructed as a bilinear function to obtain the multi-hop inference relation containing information about these two global single-hop inference relations. is the inference of all multi-hop relations computed by traversing the intermediate entity. After all multi-hop inference relations are pooled by the average value, the global multi-hop inference relation containing the information of multiple intermediate entities is obtained.
The global inference relation
from entity
to entity
contains information about entities in the set
, as shown in Equation (14):
where
is the inference relation computed using
and
iterations from entity
to entity
when the last traversed intermediate entity is
.
is the global inference relation from the head entity
to the tail entity
. The same is true for
and
.
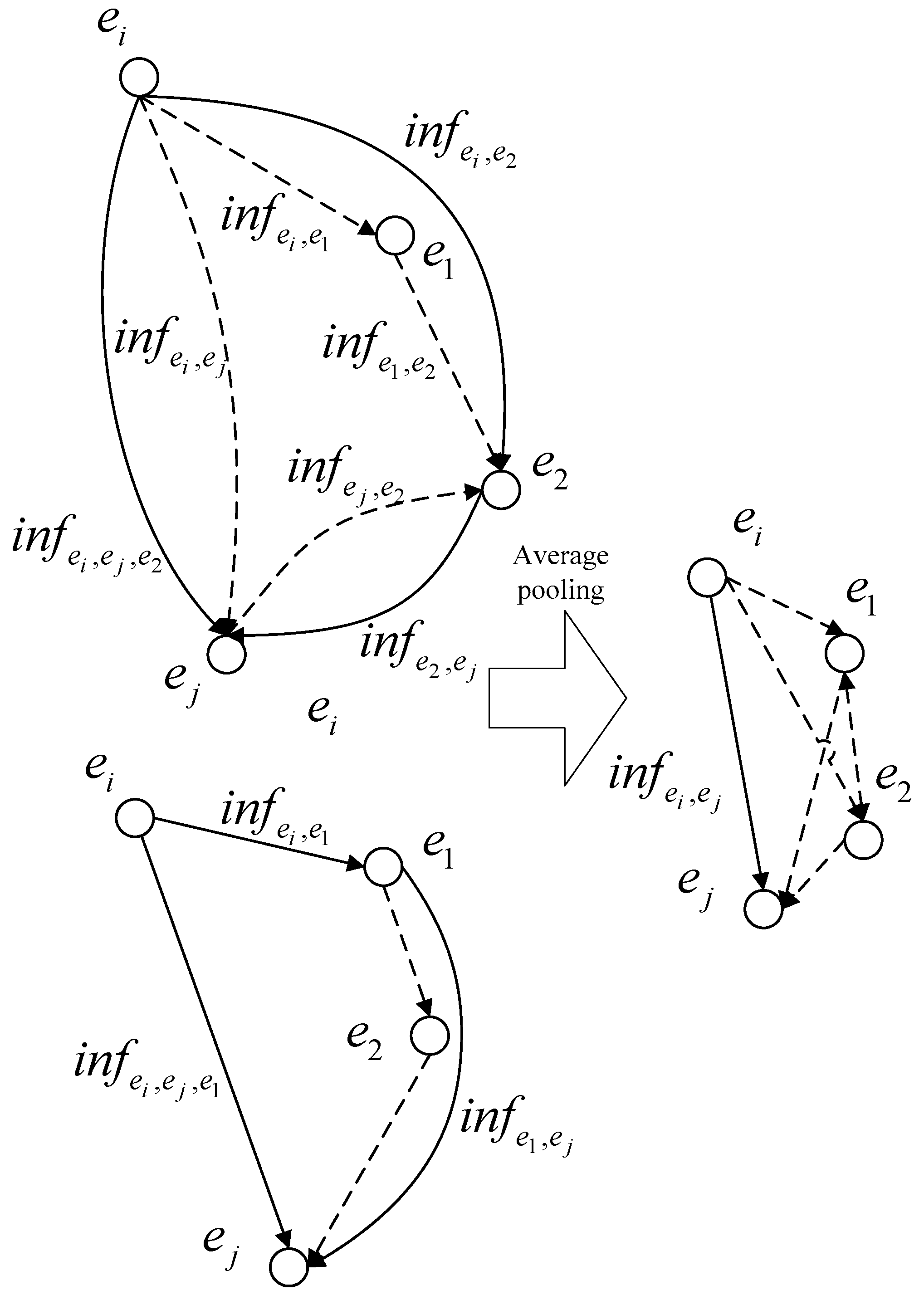
When
, the multi-hop relational inference mechanism based on the improved Floyd algorithm is shown in
Figure 7.
In
Figure 7, the single-hop inference relations
,
,
, and
are obtained according to Equation (10), and then the global inference relation
is obtained after the first iteration of the multi-hop inference layer, as shown in Equation (15).
The global inference relation is obtained in the same way.
The global relations
and
are fed into a neural network constructed with a bilinear function to obtain the inference relation
with
as the intermediate entity, as shown in Equation (16):
Similarly, the inference relation is obtained.
The global relation
is obtained by averaging pooling for the inference relations
and
, as shown in Equation (17):
The second iteration process is represented by Equations (16) and (17).
Multi-path multi-hop inference can be implemented by the above procedure to obtain the global relation for the head entity pointing to the tail entity .
When , i.e., the number of intermediate entities is greater than two, the inference process is still as shown in Equation (14).
Since the intermediate entities between entity pairs can be repeatedly traversed during the iteration, the number of intermediate entities traversed by the global inference relation calculation between any entity pair is 2N−1 after N iterations of multi-path multi-hop inference.
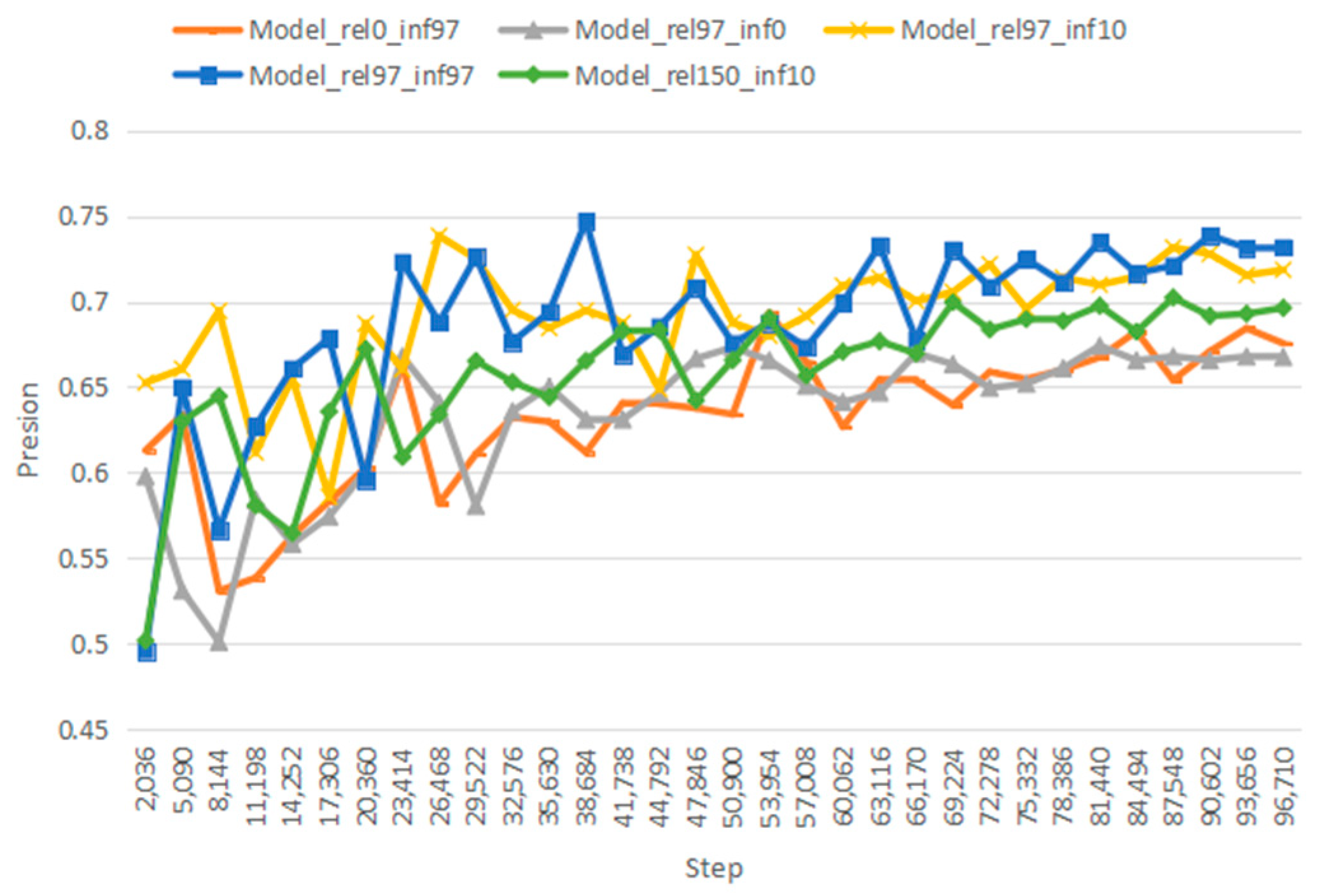
The flowchart of the algorithm for the global inference mechanism in this model is shown in
Figure 8.
In
Figure 8,
,
are any head and tail entities in the document, and their output global multi-hop inference relations
, which can be continuously updated by iteration and used as input for global multi-hop inference, are calculated to obtain global multi-hop inference relations for other head and tail entities.




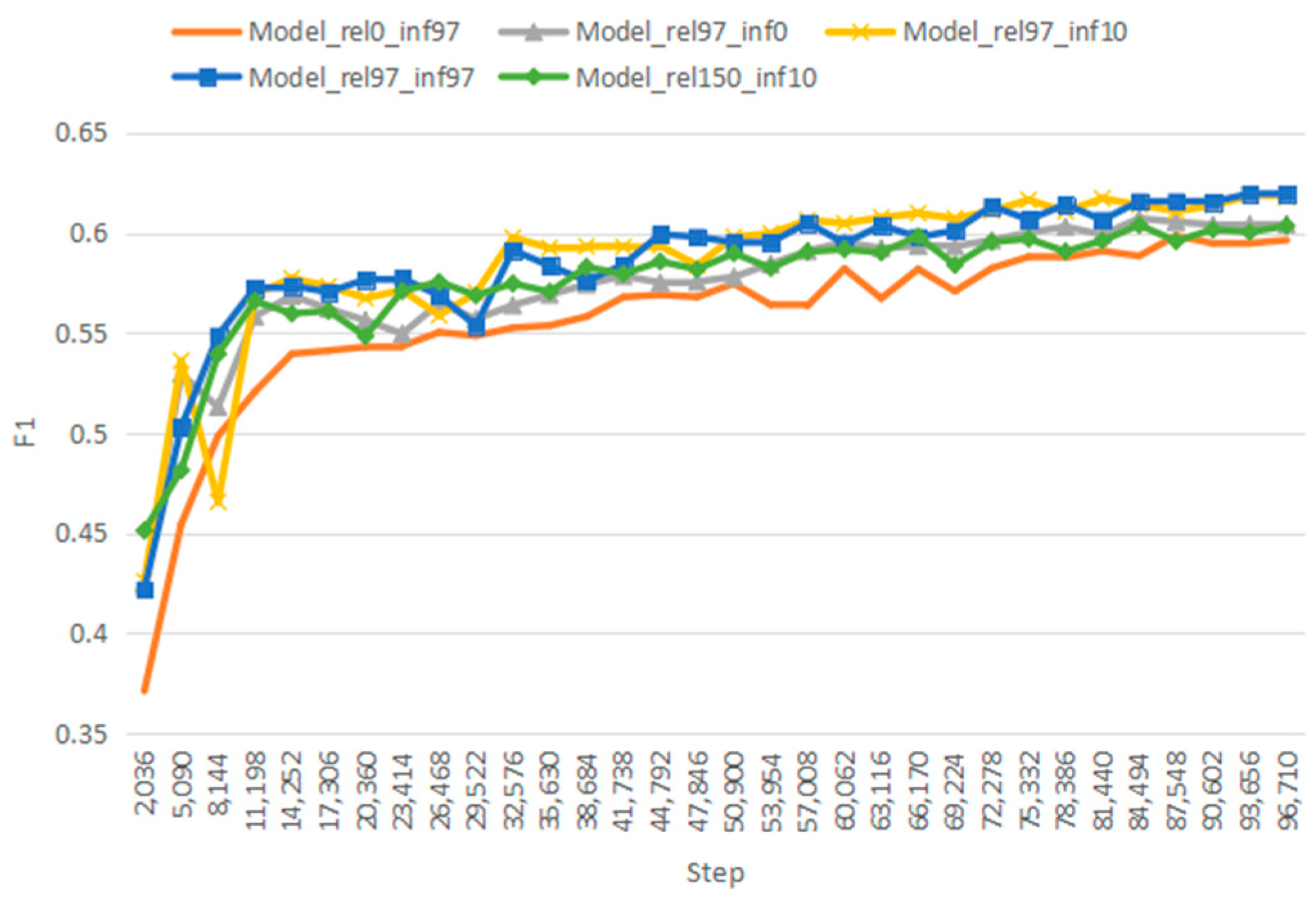
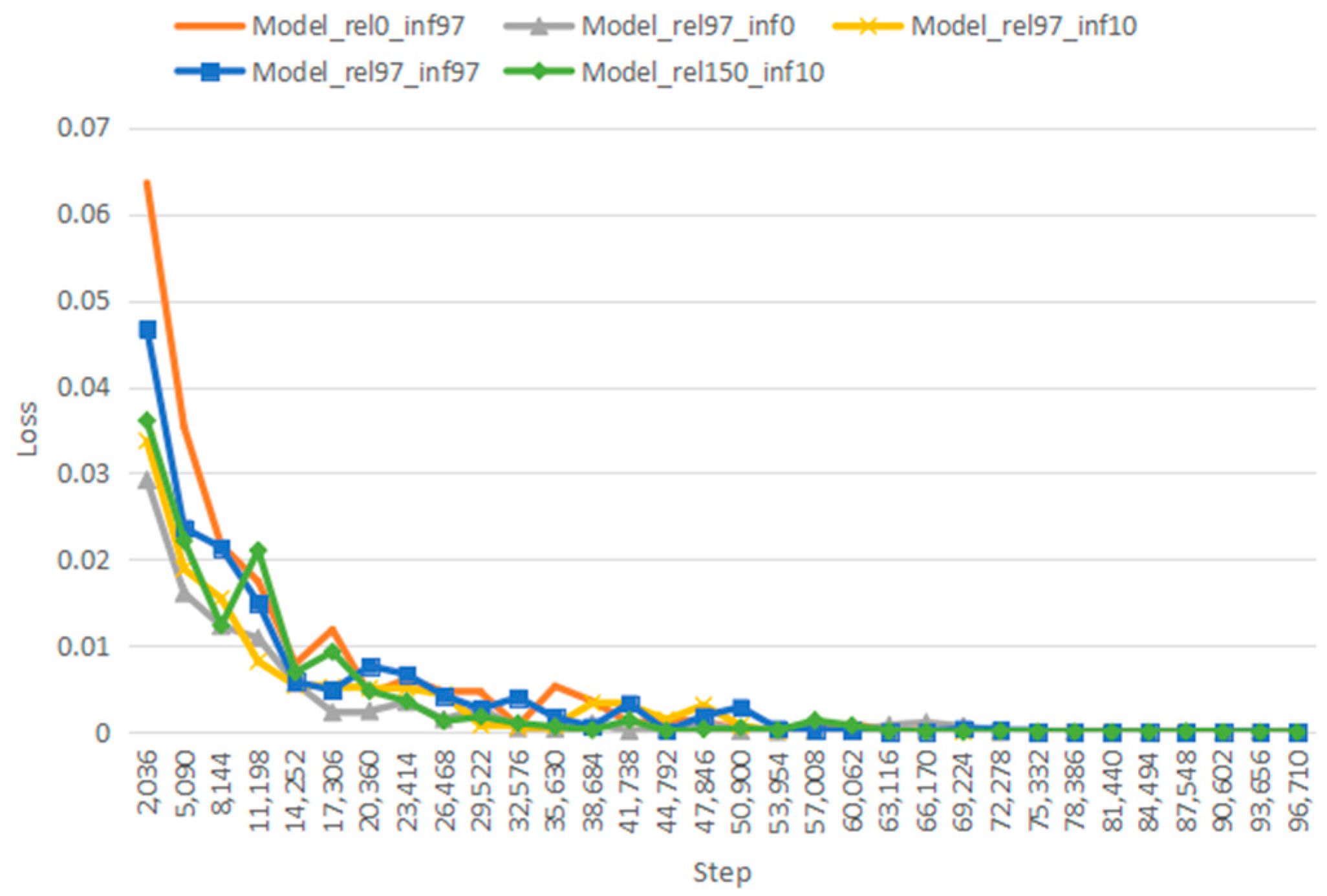

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}