
A Literature Survey on Word Sense Disambiguation for the Hindi Language


 and
and 
Abstract
:1. Introduction
2. Various Approaches for WSD
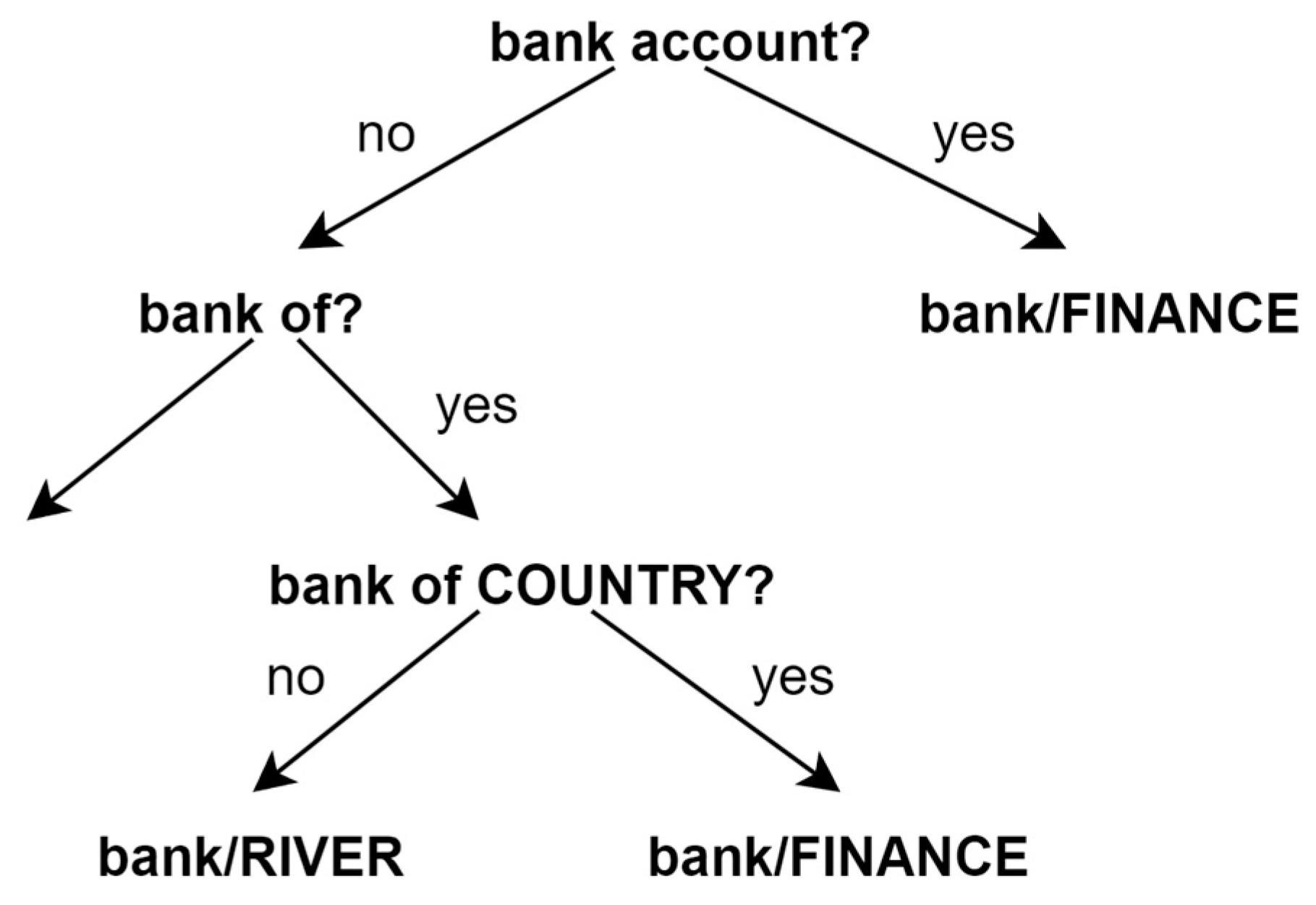
2.1. Knowledge-Based Approaches
- LESK Algorithm
- Semantic Similarity
- Selectional preferences
- Heuristic Approach
- (a)
- The most frequent sense heuristic operates on the principle of identifying all possible meanings that a word can have, with the understanding that one particular sense occurs more frequently than others.
- (b)
- The one sense per discourse heuristic posits that a term or word maintains the same meaning throughout all instances within a specified text.
- (c)
- The one sense per collocation heuristic has a similar meaning to the one sense per discourse heuristic, but it assumes that nearby words offer a robust and consistent indication of the contextual sense of a word.
- Walker’s Algorithm
2.2. ML-Based Approaches
2.2.1. Supervised Techniques
- Decision list
- Decision Tree
- Naïve Bayes
- Neural network
- Support Vector Machine (SVM)
- Exemplar or instance-based learning
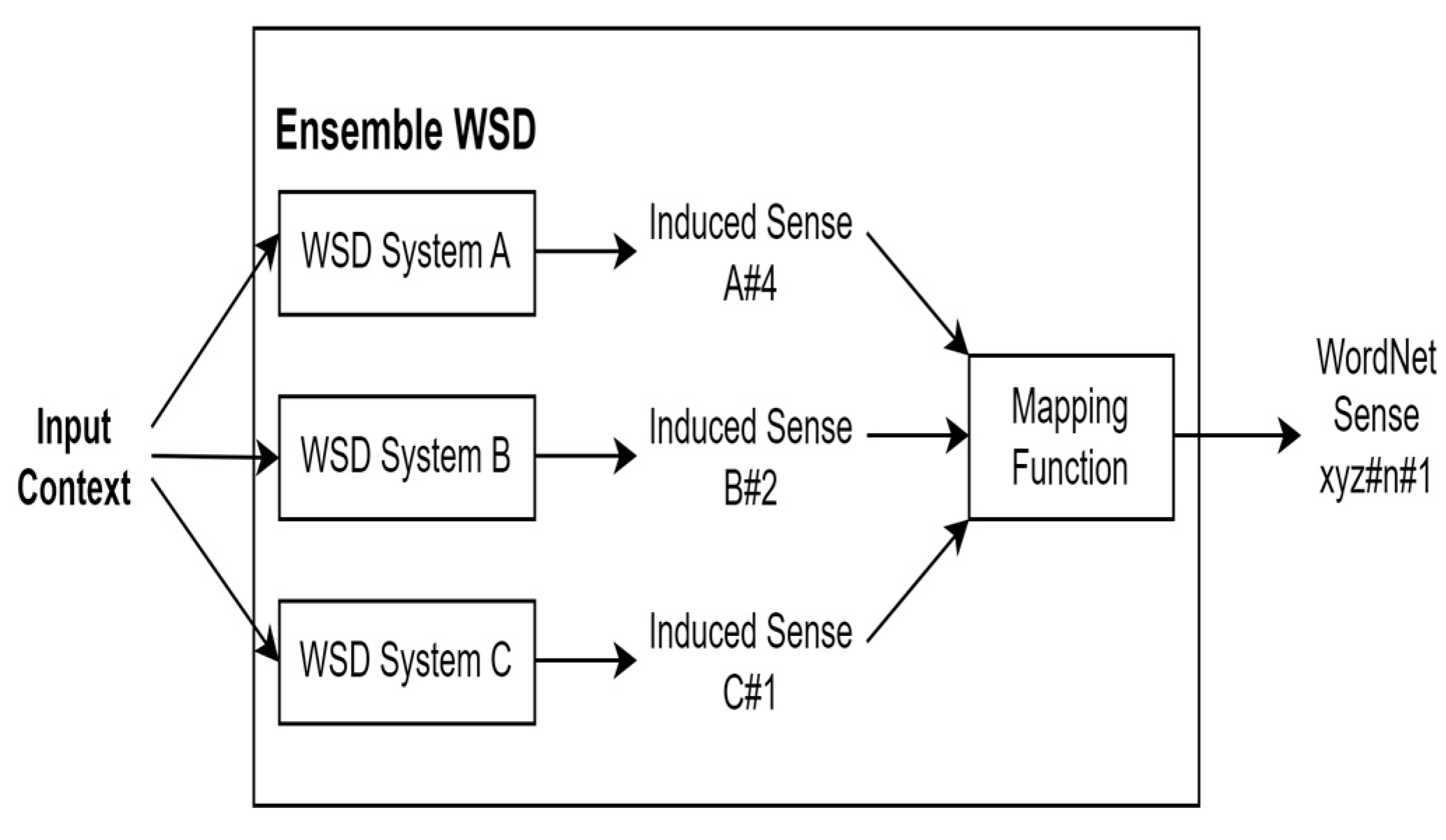
- Ensemble methods
2.2.2. Unsupervised Techniques
2.2.3. Semi-Supervised Techniques
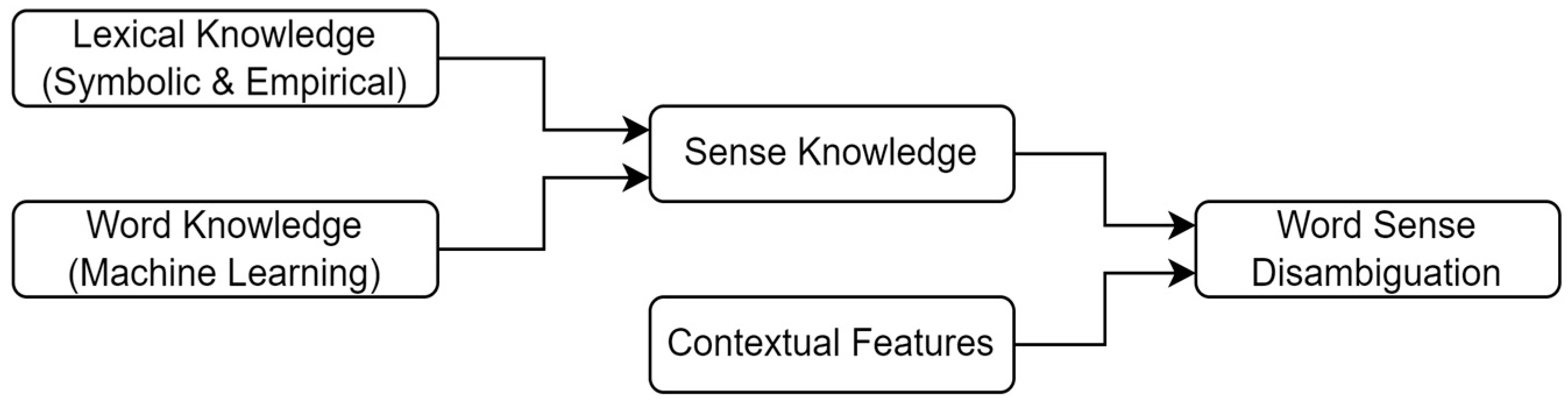
3. WSD Execution Process
- Synset: This is a group of words, or synonyms, with similar meanings. For example, “पेन, कलम, लेखनी” (pen, kalam, lekhanee) refers to a tool or device used for writing with ink. According to the frequency of usage, the words are organized in the synset.
- Gloss: It explains the ideas. It is divided into two sections: a text definition that explains the concepts indicated by the synset (for example, “स्याही के सहयोग से कागज आदि पर लिखने का उपकरण (syaahee ke sahayog se kaagaj aadi par likhane ka upakaran)” elaborates on the idea of a writing or drawing instrument that utilizes ink), along with an illustrative sentence showcasing the importance of each word within a sentence. In general, a synset’s words may be simply changed in a phrase (for instance, “यह पेन किसी ने मुझे उपहार में प्रदान की है | (yah pen kisee ne mujhe upahaar mein pradaan kee hai) (Someone gifted me this pen.)” illustrates the usefulness of the synset’s words describing an ink writing or drawing equipment).
4. Results and Discussions
4.1. Knowledge-Based Techniques
4.2. Supervised Techniques
4.3. Unsupervised Techniques
4.4. Research Gaps and Future Scope
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zipf, G.K. Human Behavior and the Principle of Least Effort; Addison-Wesley Press: Oxford, UK, 1949. [Google Scholar]
- Wilks, Y.; Fass, D. The preference semantics family. Comput. Math. Appl. 1992, 23, 205–221. [Google Scholar] [CrossRef]
- Navigli, R. Word sense disambiguation: A survey. ACM Comput. Surv. 2009, 41, 1459355. [Google Scholar] [CrossRef]
- Vickrey, D.; Biewald, L.; Teyssier, M.; Koller, D. Word-sense disambiguation for machine translation. In Proceedings of the Conference on Human Language Technology and Empirical Methods in Natural Language Processing (HLT/EMNLP 2005), Vancouver, BC, Canada, 6 October 2005; pp. 771–778. [Google Scholar] [CrossRef]
- Carpuat, M.; Wu, D. Improving statistical machine translation using word sense disambiguation. In Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL), Prague, Czech Republic, 28–30 June 2007; pp. 61–72. [Google Scholar]
- Pu, X.; Pappas, N.; Henderson, J.; Popescu-Belis, A. Integrating Weakly Supervised Word Sense Disambiguation into Neural Machine Translation. Trans. Assoc. Comput. Linguist. 2018, 6, 635–649. [Google Scholar] [CrossRef]
- Plaza, L.; Jimeno-Yepes, A.J.; Díaz, A.; Aronson, A.R. Studying the correlation between different word sense disambiguation methods and summarization effectiveness in biomedical texts. BMC Bioinform. 2011, 12, 355. [Google Scholar] [CrossRef] [PubMed]
- Madhuri, J.N.; Ganesh Kumar, R. Extractive Text Summarization Using Sentence Ranking. In Proceedings of the 2019 International Conference on Data Science and Communication (IconDSC), Bangalore, India, 1–2 March 2019; pp. 19–21. [Google Scholar] [CrossRef]
- Carpineto, C.; Romano, G. A survey of automatic query expansion in information retrieval. ACM Comput. Surv. 2012, 44, 2071390. [Google Scholar] [CrossRef]
- Sharma, N.; Niranjan, P.S. Applications of Word Sense Disambiguation: A Historical Perspective. IJERT 2015, 3, 1–4. [Google Scholar]
- Sumanth, C.; Inkpen, D. How much does word sense disambiguation help in sentiment analysis of micropost data? In Proceedings of the 6th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, Lisboa, Portugal, 14 July 2015; pp. 115–121. [Google Scholar] [CrossRef]
- Xu, G.; Yu, Z.; Yao, H.; Li, F.; Meng, Y.; Wu, X. Chinese Text Sentiment Analysis Based on Extended Sentiment Dictionary. IEEE Access 2019, 7, 43749–43762. [Google Scholar] [CrossRef]
- Chifu, A.G.; Ionescu, R.T. Word sense disambiguation to improve precision for ambiguous queries. Open Comput. Sci. 2012, 2, 398–411. [Google Scholar] [CrossRef]
- Asim, M.N.; Wasim, M.; Khan, M.U.G.; Mahmood, N.; Mahmood, W. The Use of Ontology in Retrieval: A Study on Textual, Multilingual, and Multimedia Retrieval. IEEE Access 2019, 7, 21662–21686. [Google Scholar] [CrossRef]
- Advaith, V.; Shivkumar, A.; Sowmya Lakshmi, B.S. Parts of Speech Tagging for Kannada and Hindi Languages using ML and DL models. In Proceedings of the 2022 IEEE International Conference on Electronics, Computing and Communication Technologies (CONECCT), Bangalore, India, 8–10 July 2022. [Google Scholar] [CrossRef]
- Gadde, S.P.K.; Yeleti, M.V. Improving statistical POS tagging using Linguistic feature for Hindi and Telugu Improving statistical POS tagging using linguistic features for Hindi and Telugu. In Proceedings of the ICON-2008: International Conference on Natural Language Processing, Pune, India, 20–22 December 2008. [Google Scholar]
- Banerjee, S.; Pedersen, T. An Adapted Lesk Algorithm for Word Sense Disambiguation Using WordNet. In Proceedings of the Computational Linguistics and Intelligent Text Processing, Mexico City, Mexico, 17–23 February 2002; Gelbukh, A., Ed.; Springer: Berlin/Heidelberg, Germany, 2002; pp. 136–145. [Google Scholar]
- Lesk, M. Automatic sense disambiguation using machine readable dictionaries: How to tell a pine cone from an ice cream cone. In Proceedings of the 5th Annual International Conference on Systems Documentation, Toronto, ON, Canada, 1 June 1986; pp. 24–26. [Google Scholar] [CrossRef]
- Mittal, K.; Jain, A. Word Sense Disambiguation Method Using Semantic Similarity Measures and Owa Operator. ICTACT J. Soft Comput. 2015, 5, 896–904. [Google Scholar] [CrossRef]
- Mccarthy, D.; Carroll, J. Adjectives Using Automatically Acquired Selectional Preferences. Comput. Linguist. 2003, 29, 639–654. [Google Scholar] [CrossRef]
- Ye, P.; Baldwin, T. Verb Sense Disambiguation Using Selectional Preferences Extracted with a State-of-the-art Semantic Role Labeler. In Proceedings of the Australasian Language Technology Workshop 2006, Sydney, Australia, 4–6 December 2006; pp. 139–148. [Google Scholar]
- Sarika; Sharma, D.K. A comparative analysis of Hindi word sense disambiguation and its approaches. In Proceedings of the International Conference on Computing, Communication & Automation, Pune, India, 26–27 February 2015; pp. 314–321. [Google Scholar]
- Walker, J.Q., II. A node-positioning algorithm for general trees. Softw. Pract. Exp. 1990, 20, 685–705. [Google Scholar] [CrossRef]
- Parameswarappa, S.; Narayana, V.N. Decision List Preliminaries of the Kannada Language and the Basic. 2013, Volume 2. Available online: https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=7620a95796c2eae4a94498fa779b00e2b25c957a (accessed on 21 May 2023).
- Yarowsky, D. Hierarchical decision lists for word sense disambiguation. Lang. Resour. Eval. 2000, 34, 179–186. [Google Scholar]
- Singh, R.L.; Ghosh, K.; Nongmeikapam, K.; Bandyopadhyay, S. A Decision Tree Based Word Sense Disambiguation System in Manipuri Language. Adv. Comput. Int. J. 2014, 5, 17–22. [Google Scholar] [CrossRef]
- Rawat, S.; Kalambe, K.; Kawade, G.; Korde, N. Supervised word sense disambiguation using decision tree. Int. J. Recent Technol. Eng. 2019, 8, 4043–4047. [Google Scholar] [CrossRef]
- Thwet, N.; Soe, K.M.; Thein, N.L. System Using Naïve Bayesian Algorithm for Myanmar Language. Int. J. Sci. Eng. Res. 2011, 2, 1–7. [Google Scholar]
- Le, C.A.; Shimazu, A. High WSD accuracy using Naive Bayesian classifier with rich features. In Proceedings of the 18th Pacific Asia Conference on Language, Information and Computation PACLIC 2004, Tokyo, Japan, 8–10 December 2004; pp. 105–113. [Google Scholar]
- Popov, A. Neural network models for word sense disambiguation: An overview. Cybern. Inf. Technol. 2018, 18, 139–151. [Google Scholar] [CrossRef]
- Kumar, S.; Kumar, R. Word Sense Disambiguation in the Hindi Language: Neural Network Approach. Int. J. Tech. Res. Sci. 2021, 1, 72–76. [Google Scholar] [CrossRef]
- Kumar, M.; Sankaravelayuthan, R.; Kp, S. Tamil word sense disambiguation using support vector machines with rich features. Int. J. Appl. Eng. Res. 2014, 9, 7609–7620. [Google Scholar]
- Decadt, B.; Hoste, V.; Daelemans, W.; van den Bosch, A. GAMBL, genetic algorithm optimization of memory-based WSD. In Proceedings of the Third International Workshop on the Evaluation of Systems for the Semantic Analysis of Text, Barcelona, Spain, 25–26 July 2004; pp. 108–112. [Google Scholar]
- Fix, E.; Hodges, J.L. Discriminatory Analysis. Nonparametric Discrimination: Consistency Properties. Int. Stat. Rev. Rev. Int. Stat. 1989, 57, 238. [Google Scholar] [CrossRef]
- Hamming, R.W. Error detecting and error correcting codes. Bell Syst. Tech. J. 1950, 29, 147–160. [Google Scholar] [CrossRef]
- Revesz, P.Z. A Generalization of the Chomsky-Halle Phonetic Representation using Real Numbers for Robust Speech Recognition in Noisy Environments. In Proceedings of the 27th International Database Engineered Applications Symposium, Heraklion, Greece, 5–7 May 2023; pp. 156–160. [Google Scholar] [CrossRef]
- Brody, S.; Navigli, R.; Lapata, M. Ensemble methods for unsupervised WSD. In Proceedings of the 21st International Conference on Computational Linguistics and the 44th Annual Meeting of the Association for Computational Linguistics, Stroudsburg, PA, USA, 17–18 July 2006; Volume 1, pp. 97–104. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A Short Introduction to Boosting. 1999. Available online: https://api.semanticscholar.org/CorpusID:9621074 (accessed on 20 December 2022).
- Martín-Wanton, T.; Berlanga-Llavori, R. A clustering-based approach for unsupervised word sense disambiguation. Proces. Leng. Nat. 2012, 49, 49–56. [Google Scholar]
- Lin, D. Automatic retrieval and clustering of similar words. Proc. Annu. Meet. Assoc. Comput. Linguist. 1998, 2, 768–774. [Google Scholar] [CrossRef]
- Pantel, P.A. Clustering by Committee. 2003, pp. 1–137. Available online: https://www.patrickpantel.com/download/papers/2003/cbc.pdf (accessed on 25 January 2023).
- Silberer, C.; Ponzetto, S.P. UHD: Cross-lingual word sense disambiguation using multilingual Co-occurrence graphs. In Proceedings of the 5th International Workshop on Semantic Evaluation, Uppsala, Sweden, 12 July 2010; pp. 134–137. [Google Scholar]
- Miller, G.A. WordNet: A Lexical Database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Bhattacharyya, P. IndoWordnet. In The WordNet in Indian Languages; Springer: Berlin/Heidelberg, Germany, 2010; pp. 3785–3792. [Google Scholar] [CrossRef]
- Sinha, M.; Reddy, M.K.; Bhattacharyya, P.; Pandey, P.; Kashyap, L. Hindi Word Sense Disambiguation. 2004. Available online: https://api.semanticscholar.org/CorpusID:9438332 (accessed on 25 January 2023).
- Singh, S.; Siddiqui, T.J. Evaluating effect of context window size, stemming and stop word removal on Hindi word sense disambiguation. In Proceedings of the 2012 International Conference on Information Retrieval & Knowledge Management, Kuala Lumpur, Malaysia, 13–15 March 2012; pp. 1–5. [Google Scholar] [CrossRef]
- Kumar Vishwakarma, S.; Vishwakarma, C.K. A Graph Based Approach to Word Sense Disambiguation for Hindi Language. Int. J. Sci. Res. Eng. Technol. 2012, 1, 313–318. Available online: www.ijsret.org (accessed on 25 January 2023).
- Singh, S.; Singh, V.K.; Siddiqui, T.J. Hindi Word Sense Disambiguation Using Semantic Relatedness Measure BT-Multi-Disciplinary Trends in Artificial Intelligence; Ramanna, S., Lingras, P., Sombattheera, C., Krishna, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 247–256. [Google Scholar]
- Singh, S.; Siddiqui, T.J. Role of semantic relations in Hindi Word Sense Disambiguation. Procedia Comput. Sci. 2015, 46, 240–248. [Google Scholar] [CrossRef]
- Sawhney, R.; Kaur, A. A modified technique for Word Sense Disambiguation using Lesk algorithm in Hindi language. In Proceedings of the 2014 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Delhi, India, 24–27 September 2014; pp. 2745–2749. [Google Scholar] [CrossRef]
- Gautam, C.B.S.; Sharma, D.K. Hindi word sense disambiguation using lesk approach on bigram and trigram words. In Proceedings of the International Conference on Advances in Information Communication Technology & Computing, Bikaner, India, 12–13 August 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Jain, G.; Lobiyal, D.K. Word sense disambiguation of Hindi text using fuzzified semantic relations and fuzzy Hindi WordNet. In Proceedings of the 2019 9th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, 10–11 January 2019; pp. 494–497. [Google Scholar] [CrossRef]
- Sharma, P.; Joshi, N. Knowledge-Based Method for Word Sense Disambiguation by Using Hindi WordNet. Eng. Technol. Appl. Sci. Res. 2019, 9, 3985–3989. [Google Scholar] [CrossRef]
- Sau, A.; Amin, T.A.; Barman, N.; Pal, A.R. Word sense disambiguation in bengali using sense induction. In Proceedings of the 2019 International Conference on Applied Machine Learning (ICAML), Bhubaneswar, India, 25–26 May 2019; pp. 170–174. [Google Scholar] [CrossRef]
- Tripathi, P.; Mukherjee, P.; Hendre, M.; Godse, M.; Chakraborty, B. Word Sense Disambiguation in Hindi Language Using Score Based Modified Lesk Algorithm. Int. J. Comput. Digit. Syst. 2021, 10, 939–954. [Google Scholar] [CrossRef]
- Yusuf, M.; Surana, P.; Sharma, C. HindiWSD: A Package for Word Sense Disambiguation in Hinglish & Hindi. In Proceedings of the 6th Workshop on Indian Language Data: Resources and Evaluation (WILDRE-6), Marseille, France, 20–25 June 2022; pp. 18–23. [Google Scholar]
- Purohit, A.; Yogi, K.K. A Comparative Study of Existing Knowledge Based Techniques for Word Sense Disambiguation. In Proceedings of the International Joint Conference on Advances in Computational Intelligence, Online, 23–24 October 2021; Uddin, M.S., Jamwal, P.K., Bansal, J.C., Eds.; Springer Nature: Singapore, 2022; pp. 167–182. [Google Scholar]
- Singh, S.; Slddiqui, T.J.; Sharma, S.K. Naïve bayes classifier for hindi word sense disambiguation. In Proceedings of the 7th ACM India Computing Conference, Nagpur, India, 9 October 2014. [Google Scholar] [CrossRef]
- Sarika; Sharma, D.K. Hindi word sense disambiguation using cosine similarity. In Proceedings of the Advances in Intelligent Systems and Computing, Athens, Greece, 29–31 August 2016. [Google Scholar]
- Walia, H.; Rana, A.; Kansal, V. A Supervised Approach on Gurmukhi Word Sense Disambiguation Using K-NN Method. In Proceedings of the 2018 8th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, 11–12 January 2018; pp. 743–746. [Google Scholar] [CrossRef]
- pal Singh, V.; Kumar, P. Naive Bayes classifier for word sense disambiguation of Punjabi Language. Malaysian J. Comput. Sci. 2018, 31, 188–199. [Google Scholar] [CrossRef]
- Mishra, B.K.; Jain, S. Word Sense Disambiguation for Hindi Language Using Neural Network BT-Advancements in Smart Computing and Information Security; Rajagopal, S., Faruki, P., Popat, K., Eds.; Springer Nature: Cham, Switzerland, 2022; pp. 14–25. [Google Scholar]
- Mishra, N.; Yadav, S.; Siddiqui, T.J. An Unsupervised Approach to Hindi Word Sense Disambiguation. In Proceedings of the First International Conference on Intelligent Human Computer Interaction, Rome, Italy, 20–23 January 2009. [Google Scholar]
- Jain, A.; Lobiyal, D.K. Unsupervised Hindi word sense disambiguation based on network agglomeration. In Proceedings of the 2015 International Conference on Computing for Sustainable Global Development, INDIACom 2015, New Delhi, India, 11–13 March 2015. [Google Scholar]
- Nandanwar, L. Graph connectivity for unsupervised Word Sense Disambiguation for Hindi language. In Proceedings of the ICIIECS 2015—2015 IEEE International Conference on Innovations in Information, Embedded and Communication Systems, Coimbatore, India, 19–20 March 2015. [Google Scholar]
- Jain, A.; Lobiyal, D.K. Fuzzy Hindi wordnet and word sense disambiguation using fuzzy graph connectivity measures. ACM Trans. Asian Low-Resource Lang. Inf. Process. 2015, 15, 2790079. [Google Scholar] [CrossRef]
- Jain, G.; Lobiyal, D.K. Word Sense Disambiguation Using Cooperative Game Theory and Fuzzy Hindi WordNet Based on ConceptNet. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2022, 21, 3502739. [Google Scholar] [CrossRef]
- Vaishnav, Z.B. Gujarati Word Sense Disambiguation Using Genetic Algorithm. 2017. Available online: https://api.semanticscholar.org/CorpusID:212514785 (accessed on 25 January 2023).
- Kumari, A.; Lobiyal, D.K. Word2vec’s Distributed Word Representation for Hindi Word Sense Disambiguation. In Proceedings of the 16th International Conference, ICDCIT 2020, Bhubaneswar, India, 9–12 January 2020. [Google Scholar] [CrossRef]
- Sruthi, S.; Kannan, B.; Paul, B. Improved Word Sense Determination in Malayalam using Latent Dirichlet Allocation and Semantic Features. ACM Trans. Asian Low-Resource Lang. Inf. Process. 2022, 21, 3476978. [Google Scholar] [CrossRef]
- Kumari, A.; Lobiyal, D.K. Efficient estimation of Hindi WSD with distributed word representation in vector space. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 6092–6103. [Google Scholar] [CrossRef]
- Bhatia, S.; Kumar, A.; Khan, M. Role of Genetic Algorithm in Optimization of Hindi Word Sense Disambiguation. IEEE Access 2022, 10, 3190406. [Google Scholar] [CrossRef]
- Jha, P.; Agarwal, S.; Abbas, A.; Siddiqui, T. Comparative Analysis of Path-based Similarity Measures for Word Sense Disambiguation. In Proceedings of the 2023 3rd International Conference on Artificial Intelligence and Signal Processing (AISP), Vijayawada, India, 18–20 March 2023; pp. 1–5. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Technique | Working | Advantages | Disadvantages | Justification for Usage |
|---|---|---|---|---|
| Knowledge-based | Utilizes pre-defined rules and human expertise to make decisions or classify data. | 1. Interpretable outcomes | 1. Limited scalability | Useful when domain-specific knowledge is available and interpretability is essential |
| 2. Robust to noisy data | 2. Relies on expert knowledge | |||
| Supervised | Trained on labeled data with input–output pairs and predicts outputs for unseen data based on the learned model. | 1. High accuracy | 1. Requires labeled data | Preferred when labeled data are available and the goal is precise predictions |
| 2. Well-established algorithms | 2. Sensitive to outliers and noise | |||
| 3. Suitable for various problem types (classification, regression, etc.) | 3. Lack of generalization to unseen classes or categories | |||
| Unsupervised | Clusters data or discovers hidden patterns without labels. | 1. Useful for exploratory data analysis | 1. Limited guidance in model evaluation | Ideal for identifying structures in data when labeled data are scarce or unavailable. |
| 2. Can handle large datasets | 2. Lack of direct feedback on model performance | |||
| 3. Detects anomalies or outliers | 3. Difficulty in interpreting the results | |||
| Semi-supervised | Utilizes a combination of labeled and unlabeled data. | 1. Utilizes the advantages of both supervised and unsupervised learning | 1. Difficulty in obtaining and managing labeled data | Valuable when labeled data are expensive to acquire but unlabeled data are abundant |
| 2. Cost-effective for certain applications | 2. Semi-supervised methods may not outperform fully supervised or unsupervised techniques | |||
| 3. Improves performance with limited labeled data | 3. May suffer from error propagation due to incorrect labels |
| Year (Ref.) | Language | Technique | Method | Specification | Dataset Used | Accuracy | Comments |
|---|---|---|---|---|---|---|---|
| 1986 [18] | English | Knowledge-Based | Lesk | Overlapping of context and word definition is performed. | Used Machine Readable Dictionaries | - | Only definitions are used for deriving the meaning. |
| 2002 [17] | English | Knowledge-Based | Adapted Lesk | The proposed approach expands the comparisons by incorporating the glosses of words that are linked to the words under disambiguation in the given text. These connections are established using the WordNet lexical database. | WordNet is used | 32% | - |
| 2004 [45] | Hindi | Knowledge-Based | Lesk Method | Comparison of the ambiguous word’s context and the context derived from Hindi WordNet is performed. | The manually created test set. | 40–70% | Works with only nouns and does not deal with morphology. |
| 2009 [63] | Hindi | Unsupervised | Decision List | After pre-processing, a decision list of untagged examples is created that is utilized to depict the meaning of the polysemous word. | A dataset for 20 ambiguous words with 1856 training instances and 1641 test instances was used. | The accuracy ranges from approximately 82% to around 92% when employing techniques such as stop-word elimination, automatic generation of decision lists, and stemming. | - |
| 2012 [46] | Hindi | Knowledge-Based | Lesk Algorithm | Effects of context window size, stop word elimination, and stemming has been analyzed with Lesk | Evaluation is carried out on a test set of 10 polysemous with 1248 test instances. | Improvement of 9.24% over baseline. | Works only for nouns. |
| 2012 [47] | Hindi | Knowledge-based | Graph-Based | A graph is constructed using the DFS algorithm and then centrality measures are applied to deduce the sense of the word. | Text files that contain 913 nouns are used as datasets. | 65.17% | For graph centrality, only the in-degree algorithm is used. |
| 2013 [48] | Hindi | Knowledge-Based | A Leacock-Chodorow measure of semantic relatedness | The Leacock–Chodorow algorithm is used to find the length of the route among two noun concepts. | dataset of 20 polysemous Hindi nouns | 60.65% | Works only for nouns |
| 2014 [49] | Hindi | Knowledge-Based | Semantic Relations | The significance of different relationships such as hypernym, hyponym, holonym, and meronym is examined here. | dataset of 60 nouns is used. | Improvement of 9.86% over baseline. | Only for nouns. |
| 2014 [58] | Hindi | Supervised | Naive Bayes | Naive Bayes classifier with eleven different features has been applied for Hindi WSD. | A dataset of 60 polysemous Hindi nouns is used. | 86.11% | Works only for nouns |
| 2014 [50] | Hindi | Knowledge-Based | Modified Lesk | A modified Lesk approach with a dynamic context window is used in this paper. | A dataset of 10 ambiguous words is used. | - | Accuracy depends on the size of the dynamic context window. |
| 2015 [64] | Hindi | Unsupervised | Network Agglomeration | An interpretation graph is created for each interpretation derived from the graph of the sentence, and subsequently, network agglomeration is performed to determine the correct interpretation. | Health and Tourism datasets are used. | Health-43% (All words) and 50% (Nouns) Tourism-44% (All Words) and 53% (Nouns) | Works for nouns as well as other parts of speech, too. |
| 2015 [65] | Hindi | Unsupervised | Graph Connectivity | A graph is generated to represent all the senses of a polysemous word, then it is analyzed to determine the accurate sense of the word. | Hindi Wordnet is used as a reference library. | - | No standard dataset. |
| 2015 [66] | Hindi | Unsupervised | Fuzzy Graph Connectivity Measures | Different global and local fuzzy graph connectivity measures are computed to find the meaning of a polysemous word. | Used Health corpus. | Performance increases by 8% when we use Fuzzy Hindi WordNet. | - |
| 2016 [51] | Hindi | Knowledge-Based | Tri-Gram and Bi-Gram | Lesk’s approach is applied to tri-gram and bi-gram verb words. | 15 words of verbs are used as a dataset with 103 test instances. | 52.98% with bi-gram and 33.17% with tri-gram. | Only work for verb words. |
| 2016 [59] | Hindi | Supervised | Cosine Similarity | The cosine similarity of vectors, created from input query and senses from Wordnet, is calculated to determine the meaning of the word. | dataset of 90 Hindi ambiguous word | 78.99% | It does not perform part-of-speech disambiguation for word categories other than nouns, such as adjectives, adverbs, etc. |
| 2017 [68] | Gujarati | Unsupervised | Genetic Algorithm | A genetic algorithm is used. | - | - | - |
| 2018 [60] | Gurumukhi | Supervised | K-NN | KNN classifier is used to find the similarity between vectors of input words and their meaning in Wordnet. | Punjabi Corpora of 100 sense tagged words is used. | The accuracy varies for each word, with the highest being 76.4% and the lowest being 53.6%. | The size of the dataset is too small. |
| 2018 [61] | Punjabi | Supervised | Naive Bayes | Naive Bayes classifier, with Bow and collocation model as feature extraction technique, is used. | corpus of 150 ambiguous words having 6 or more senses taken from Punjabi word net | 89% with BoW and 81% with the collocation model. | One word disambiguation per context. |
| 2019 [69] | Hindi | Unsupervised | Word Embedding | Two-word embedding techniques, i.e., Skip-gram and CBow are used with cosine similarity to deduce the correct sense of the world. | - | 52% | Semantic relations such as hypernyms, hyponyms, etc., are not used for the creation of sense vectors. |
| 2019 [52] | Hindi | Knowledge-Based | Fuzzified Semantic Relations | Fuzzified semantic relations along with FHWN are used for WSD. | - | 58–63% | There is uncertainty associated with fuzzy values. Values assigned to fuzzy memberships are based on the intuition of annotators. |
| 2019 [53] | Hindi | Knowledge-Based | Lesk | Lesk algorithm is used to disambiguate the words. | A corpus of 3000 ambiguous sentences is used. | 71.43% | POS tagger is not used |
| 2019 [54] | Bengali | Knowledge-Based | Sense Induction | The semantic similarity measure is calculated for various sense clusters of ambiguous words. | A test set of 10 Bengali words is used. | 63.71% | Classification of senses is not performed. |
| 2021 [55] | Hindi | Knowledge-Based | Score-Based Modified Lesk | A scoring technique is utilized for advancing the performance of the Lesk algorithm. | - | - | Due to the segregation of only a part of the data from WordNet, the database needs to be queried repeatedly. |
| 2021 [70] | Malyalam | Unsupervised | Semantic Features and Latent Dirichlet Allocation | An unsupervised LDA-based approach using semantic features has been applied for the target word sense disambiguation of the Malayalam language. | A dataset of 1147 contexts of polysemous words is used. | 80% | LDA does not take into account the positional parameters within the context. |
| 2021 [71] | Hindi | Unsupervised | Word Embeddings | Various word embedding technique has been used for WSD and experiments shows that Word2Vec performs better than all. | Hindi word embeddings were generated using articles sourced from Wikipedia. | 54% | Further enhancements can be achieved by incorporating additional similarity metrics and incorporating sentence or phrase-level word embeddings into the approach. |
| 2022 [67] | Hindi | Unsupervised | Co-operative Game Theory | Co-operative game theory along with Concept Net is used. It mitigated the influence of variations in membership values of fuzzy relations.. | Health and tourism dataset and a manually created dataset from Hindi newspaper articles. | 66% | - |
| 2022 [56] | Hindi | Knowledge-Based | A complete framework named “HindiWSD” is developed in this that uses the knowledge-based modified Lesk algorithm. | A dataset of 20 ambiguous word along with Hindi WordNet is used. | 71% | Dataset size is small. | |
| 2022 [72] | Hindi | Unsupervised | Genetic Algoritm | After pre-processing and creating the context bag and sense bag, GA is employed. In GA, selection, crossover and mutation are applied for the disambiguation of the word. | A manually created dataset is used. | 80% | Only worked with nouns. |
| Data Source/Benchmark | Description |
|---|---|
| Hindi WordNet | Lexical database providing synsets and semantic relations for word senses in Hindi. |
| SemEval Hindi WSD Task | Part of the SemEval workshops, offering annotated datasets, evaluation metrics, and tasks for WSD in multiple languages. |
| Sense-Annotated Corpora | Manually annotated text segments where words are tagged with their corresponding senses from Hindi WordNet. |
| Cross-Lingual Resources | Leveraging resources from related languages with more data for WSD and transferring knowledge across languages. |
| Parallel Corpora | Using texts available in multiple languages to align senses and perform cross-lingual WSD. |
| Indigenous Corpora | Domain-specific or genre-specific corpora in Hindi, focusing on specific areas such as medicine, technology, or literature. |
| Supervised Approaches | Using a small annotated dataset for training models, often involving manually sense-tagged instances. |
| Unsupervised Approaches | Employing techniques such as clustering or distributional similarity without relying heavily on labeled data. |
| Contextual Embeddings | Utilizing pretrained models such as BERT to capture rich semantic information from large text corpora. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gujjar, V.; Mago, N.; Kumari, R.; Patel, S.; Chintalapudi, N.; Battineni, G. A Literature Survey on Word Sense Disambiguation for the Hindi Language. Information 2023, 14, 495. https://doi.org/10.3390/info14090495
Gujjar V, Mago N, Kumari R, Patel S, Chintalapudi N, Battineni G. A Literature Survey on Word Sense Disambiguation for the Hindi Language. Information. 2023; 14(9):495. https://doi.org/10.3390/info14090495
Chicago/Turabian StyleGujjar, Vinto, Neeru Mago, Raj Kumari, Shrikant Patel, Nalini Chintalapudi, and Gopi Battineni. 2023. "A Literature Survey on Word Sense Disambiguation for the Hindi Language" Information 14, no. 9: 495. https://doi.org/10.3390/info14090495
APA StyleGujjar, V., Mago, N., Kumari, R., Patel, S., Chintalapudi, N., & Battineni, G. (2023). A Literature Survey on Word Sense Disambiguation for the Hindi Language. Information, 14(9), 495. https://doi.org/10.3390/info14090495