

An Easily Customizable Approach for Automated Species-Specific Detection of Anuran Calls Using the European Green Toad as an Example
 , , , , and
, , , , and {kind=link}
Abstract
1. Introduction
2. Materials and Methods
2.1. Example Species and Call Characteristics
2.2. Data Sources
2.3. Data Preparation
2.4. Call Detection Algorithm Training and Testing
2.5. Example Protocol for Customized Call Recognition
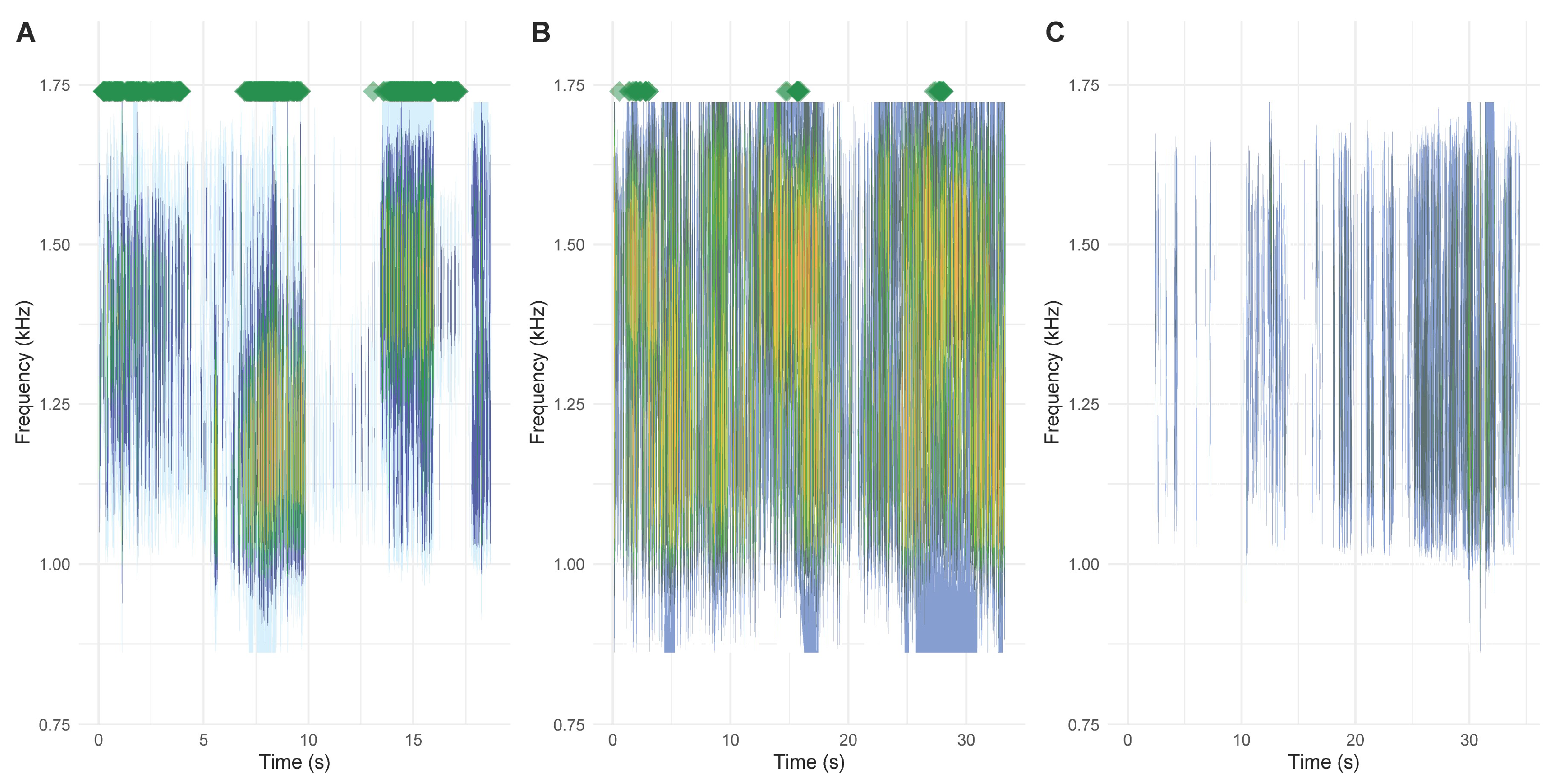
3. Results
3.1. Call Recognition Performance
3.2. Example Protocol for Customized Call Recognition Algorithm
4. Discussion
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Asht, S.; Dass, R. Pattern Recognition Techniques: A Review. Int. J. Comput. Sci. Telecommun. 2012, 3, 25–29. [Google Scholar]
- Sukthankar, R.; Ke, Y.; Hoiem, D. Semantic Learning for Audio Applications: A Computer Vision Approach. In Proceedings of the 2006 Conference on Computer Vision and Pattern Recognition Workshop (CVPRW’06), New York, NY, USA, 17–22 June 2006; p. 112. [Google Scholar]
- Jiang, H.; Diao, Z.; Shi, T.; Zhou, Y.; Wang, F.; Hu, W.; Zhu, X.; Luo, S.; Tong, G.; Yao, Y.-D. A Review of Deep Learning-Based Multiple-Lesion Recognition from Medical Images: Classification, Detection and Segmentation. Comput. Biol. Med. 2023, 157, 106726. [Google Scholar] [CrossRef]
- Jiwani, N.; Gupta, K.; Pau, G.; Alibakhshikenari, M. Pattern Recognition of Acute Lymphoblastic Leukemia (ALL) Using Computational Deep Learning. IEEE Access 2023, 11, 29541–29553. [Google Scholar] [CrossRef]
- Myat Noe, S.; Zin, T.T.; Tin, P.; Kobayashi, I. Comparing State-of-the-Art Deep Learning Algorithms for the Automated Detection and Tracking of Black Cattle. Sensors 2023, 23, 532. [Google Scholar] [CrossRef]
- Marsot, M.; Mei, J.; Shan, X.; Ye, L.; Feng, P.; Yan, X.; Li, C.; Zhao, Y. An Adaptive Pig Face Recognition Approach Using Convolutional Neural Networks. Comput. Electron. Agric. 2020, 173, 105386. [Google Scholar] [CrossRef]
- Nassif, A.B.; Shahin, I.; Attili, I.; Azzeh, M.; Shaalan, K. Speech Recognition Using Deep Neural Networks: A Systematic Review. IEEE Access 2019, 7, 19143–19165. [Google Scholar] [CrossRef]
- Adjabi, I.; Ouahabi, A.; Benzaoui, A.; Taleb-Ahmed, A. Past, Present, and Future of Face Recognition: A Review. Electronics 2020, 9, 1188. [Google Scholar] [CrossRef]
- Campbell, C.J.; Barve, V.; Belitz, M.W.; Doby, J.R.; White, E.; Seltzer, C.; Di Cecco, G.; Hurlbert, A.H.; Guralnick, R. Identifying the Identifiers: How iNaturalist Facilitates Collaborative, Research-Relevant Data Generation and Why It Matters for Biodiversity Science. BioScience 2023, 73, 533–541. [Google Scholar] [CrossRef]
- Lapp, S.; Wu, T.; Richards-Zawacki, C.; Voyles, J.; Rodriguez, K.M.; Shamon, H.; Kitzes, J. Automated Detection of Frog Calls and Choruses by Pulse Repetition Rate. Conserv. Biol. 2021, 35, 1659–1668. [Google Scholar] [CrossRef]
- Xie, J.; Towsey, M.; Zhang, J.; Roe, P. Frog Call Classification: A Survey. Artif. Intell. Rev. 2018, 49, 375–391. [Google Scholar] [CrossRef]
- Alonso, J.B.; Cabrera, J.; Shyamnani, R.; Travieso, C.M.; Bolaños, F.; García, A.; Villegas, A.; Wainwright, M. Automatic Anuran Identification Using Noise Removal and Audio Activity Detection. Expert Syst. Appl. 2017, 72, 83–92. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2022. [Google Scholar]
- Luque, A.; Romero-Lemos, J.; Carrasco, A.; Barbancho, J. Non-Sequential Automatic Classification of Anuran Sounds for the Estimation of Climate-Change Indicators. Expert Syst. Appl. 2018, 95, 248–260. [Google Scholar] [CrossRef]
- Bentéjac, C.; Csörgő, A.; Martínez-Muñoz, G. A Comparative Analysis of Gradient Boosting Algorithms. Artif. Intell. Rev. 2021, 54, 1937–1967. [Google Scholar] [CrossRef]
- Nalluri, M.; Pentela, M.; Eluri, N.R. A Scalable Tree Boosting System: XG Boost. Int. J. Res. Stud. Sci. Eng. Technol. 2020, 12, 36–51. [Google Scholar]
- Chen, T.; He, T.; Benesty, M.; Khotilovich, V.; Tang, Y.; Cho, H.; Chen, K.; Mitchell, R.; Cano, I.; Zhou, T.; et al. Xgboost: Extreme Gradient Boosting; R Foundation for Statistical Computing: Vienna, Austria, 2023. [Google Scholar]
- Budka, M.; Jobda, M.; Szałański, P.; Piórkowski, H. Acoustic Approach as an Alternative to Human-Based Survey in Bird Biodiversity Monitoring in Agricultural Meadows. PLoS ONE 2022, 17, e0266557. [Google Scholar] [CrossRef]
- Melo, I.; Llusia, D.; Bastos, R.P.; Signorelli, L. Active or Passive Acoustic Monitoring? Assessing Methods to Track Anuran Communities in Tropical Savanna Wetlands. Ecol. Indic. 2021, 132, 108305. [Google Scholar] [CrossRef]
- Rowley, J.J.L.; Callaghan, C.T. Tracking the Spread of the Eastern Dwarf Tree Frog (Litoria fallax) in Australia Using Citizen Science. Aust. J. Zool. 2023, 70, 204–210. [Google Scholar] [CrossRef]
- Farr, C.M.; Ngo, F.; Olsen, B. Evaluating Data Quality and Changes in Species Identification in a Citizen Science Bird Monitoring Project. Citiz. Sci. Theory Pract. 2023, 8, 24. [Google Scholar] [CrossRef]
- Rowley, J.J.L.; Callaghan, C.T. The FrogID Dataset: Expert-Validated Occurrence Records of Australia’s Frogs Collected by Citizen Scientists. ZooKeys 2020, 912, 139–151. [Google Scholar] [CrossRef] [PubMed]
- Westgate, M.J.; Scheele, B.C.; Ikin, K.; Hoefer, A.M.; Beaty, R.M.; Evans, M.; Osborne, W.; Hunter, D.; Rayner, L.; Driscoll, D.A. Citizen Science Program Shows Urban Areas Have Lower Occurrence of Frog Species, but Not Accelerated Declines. PLoS ONE 2015, 10, e0140973. [Google Scholar] [CrossRef]
- Paracuellos, M.; Rodríguez-Caballero, E.; Villanueva, E.; Santa, M.; Alcalde, F.; Dionisio, M.Á.; Fernández Cardenete, J.R.; García, M.P.; Hernández, J.; Tapia, M.; et al. Citizen Science Reveals Broad-Scale Variation of Calling Activity of the Mediterranean Tree Frog (Hyla meridionalis) in Its Westernmost Range. Amphib.-Reptil. 2022, 43, 251–261. [Google Scholar] [CrossRef]
- Nieto-Mora, D.A.; Rodríguez-Buritica, S.; Rodríguez-Marín, P.; Martínez-Vargaz, J.D.; Isaza-Narváez, C. Systematic Review of Machine Learning Methods Applied to Ecoacoustics and Soundscape Monitoring. Heliyon 2023, 9, e20275. [Google Scholar] [CrossRef] [PubMed]
- Platenberg, R.J.; Raymore, M.; Primack, A.; Troutman, K. Monitoring Vocalizing Species by Engaging Community Volunteers Using Cell Phones. Wildl. Soc. Bull. 2020, 44, 782–789. [Google Scholar] [CrossRef]
- Čeirāns, A.; Pupina, A.; Pupins, M. A New Method for the Estimation of Minimum Adult Frog Density from a Large-Scale Audial Survey. Sci. Rep. 2020, 10, 8627. [Google Scholar] [CrossRef] [PubMed]
- Walters, C.L.; Collen, A.; Lucas, T.; Mroz, K.; Sayer, C.A.; Jones, K.E. Challenges of Using Bioacoustics to Globally Monitor Bats. In Bat Evolution, Ecology, and Conservation; Adams, R.A., Pedersen, S.C., Eds.; Springer: New York, NY, USA, 2013; pp. 479–499. ISBN 978-1-4614-7397-8. [Google Scholar]
- Dufresnes, C.; Mazepa, G.; Jablonski, D.; Oliveira, R.C.; Wenseleers, T.; Shabanov, D.A.; Auer, M.; Ernst, R.; Koch, C.; Ramírez-Chaves, H.E.; et al. Fifteen Shades of Green: The Evolution of Bufotes Toads Revisited. Mol. Phylogenet. Evol. 2019, 141, 106615. [Google Scholar] [CrossRef] [PubMed]
- Vences, M. Development of New Microsatellite Markers for the Green Toad, Bufotes viridis, to Assess Population Structure at Its Northwestern Range Boundary in Germany. Salamandra 2019, 55, 191–198. [Google Scholar] [CrossRef]
- Giacoma, C.; Zugolaro, C.; Beani, L. The Advertisement Calls of the Green Toad (Bufo viridis): Variability and Role in Mate Choice. Herpetologica 1997, 53, 454–464. [Google Scholar]
- Lörcher, K.; Schneider, H. Vergleichende Bio-Akustische Untersuchungen an der Kreuzkröte, Bufo calamita (Laur.), und der Wechselkröte, Bufo v. Viridis (Laur.). Z. Tierpsychol. 1973, 32, 506–521. [Google Scholar] [CrossRef] [PubMed]
- Vargová, V.; Čerepová, V.; Balogová, M.; Uhrin, M. Calling Activity of Urban and Rural Populations of Green Toads Bufotes viridis Is Affected by Environmental Factors. N.-West. J. Zool. 2023, 19, 46–50. [Google Scholar]
- Ooms, J. Working with Audio and Video in R; R Foundation for Statistical Computing: Vienna, Austria, 2023. [Google Scholar]
- Ligges, U.; Krey, S.; Mersmann, O.; Schnackenberg, S. tuneR: Analysis of Music and Speech; R Foundation for Statistical Computing: Vienna, Austria, 2023. [Google Scholar]
- Sueur, J.; Aubin, T.; Simonis, C. Seewave: A Free Modular Tool for Sound Analysis and Synthesis. Bioacoustics 2008, 18, 213–226. [Google Scholar] [CrossRef]
- Kuhn, M. Building Predictive Models in R Using the Caret Package. J. Stat. Softw. 2008, 28, 1–26. [Google Scholar] [CrossRef]
- Mehdizadeh, R.; Eghbali, H.; Sharifi, M. Vocalization Development in Geoffroy’s Bat, Myotis emarginatus (Chiroptera: Vespertilionidae). Zool. Stud. 2021, 60, 20. [Google Scholar] [CrossRef]
- Castellano, S.; Rosso, A.; Doglio, S.; Giacoma, C. Body Size and Calling Variation in the Green Toad (Bufo viridis). J. Zool. 1999, 248, 83–90. [Google Scholar] [CrossRef]
- Chou, W.-H.; Lin, J.-Y. Geographical Variations of Rana seuterl (Anura: Ranidae) in Taiwan. Zool. Stud. 1997, 36, 201–221. [Google Scholar]
- Rowley, J.J.; Callaghan, C.T.; Cutajar, T.; Portway, C.; Potter, K.; Mahony, S.; Trembath, D.F.; Flemons, P.; Woods, A. FrogID: Citizen Scientists Provide Validated Biodiversity Data on Frogs of Australia. Herpetol. Conserv. Biol. 2019, 14, 155–170. [Google Scholar]
- Zilli, D. Smartphone-Powered Citizen Science for Bioacoustic Monitoring. Ph.D. Thesis, University of Southampton, Southampton, UK, 2015. [Google Scholar]
- Pérez-Granados, C.; Feldman, M.J.; Mazerolle, M.J. Combining Two User-Friendly Machine Learning Tools Increases Species Detection from Acoustic Recordings. Can. J. Zool. 2024, 102, 403–409. [Google Scholar] [CrossRef]
- Shonfield, J.; Heemskerk, S.; Bayne, E.M. Utility of Automated Species Recognition for Acoustic Monitoring of Owls. J. Raptor Res. 2018, 52, 42. [Google Scholar] [CrossRef]
- Dorcas, M.E.; Price, S.J.; Walls, S.C.; Barichivich, W.J. Auditory Monitoring of Anuran Populations. In Amphibian Ecology and Conservation; Dodd, C.K., Ed.; Oxford University Press: Oxford, UK, 2009; pp. 281–298. ISBN 978-0-19-954118-8. [Google Scholar]
- Rubbens, P.; Brodie, S.; Cordier, T.; Destro Barcellos, D.; Devos, P.; Fernandes-Salvador, J.A.; Fincham, J.I.; Gomes, A.; Handegard, N.O.; Howell, K.; et al. Machine Learning in Marine Ecology: An Overview of Techniques and Applications. ICES J. Mar. Sci. 2023, 80, 1829–1853. [Google Scholar] [CrossRef]
- Arch, V.S.; Narins, P.M. Sexual Hearing: The Influence of Sex Hormones on Acoustic Communication in Frogs. Hear. Res. 2009, 252, 15–20. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Landler, L.; Kornilev, Y.V.; Burgstaller, S.; Siebert, J.; Krall, M.; Spießberger, M.; Dörler, D.; Heigl, F. An Easily Customizable Approach for Automated Species-Specific Detection of Anuran Calls Using the European Green Toad as an Example. Information 2024, 15, 610. https://doi.org/10.3390/info15100610
Landler L, Kornilev YV, Burgstaller S, Siebert J, Krall M, Spießberger M, Dörler D, Heigl F. An Easily Customizable Approach for Automated Species-Specific Detection of Anuran Calls Using the European Green Toad as an Example. Information. 2024; 15(10):610. https://doi.org/10.3390/info15100610
Chicago/Turabian StyleLandler, Lukas, Yurii V. Kornilev, Stephan Burgstaller, Janette Siebert, Maria Krall, Magdalena Spießberger, Daniel Dörler, and Florian Heigl. 2024. "An Easily Customizable Approach for Automated Species-Specific Detection of Anuran Calls Using the European Green Toad as an Example" Information 15, no. 10: 610. https://doi.org/10.3390/info15100610
APA StyleLandler, L., Kornilev, Y. V., Burgstaller, S., Siebert, J., Krall, M., Spießberger, M., Dörler, D., & Heigl, F. (2024). An Easily Customizable Approach for Automated Species-Specific Detection of Anuran Calls Using the European Green Toad as an Example. Information, 15(10), 610. https://doi.org/10.3390/info15100610