
Unsupervised Decision Trees for Axis Unimodal Clustering


Abstract
1. Introduction
1.1. Decision Trees for Interpretable Clustering
- Definition of splitting criterion. Metrics like information gain or Gini index, which are commonly used to guide the splitting process in supervised learning, cannot be applied in unsupervised learning, since no data labels are available.
- Specification of hyperparameters (e.g., number of clusters), since cross-validation cannot be applied.
1.2. Unimodality-Based Clustering
1.3. Contribution
2. Notations—Definitions
2.1. Unimodality of Univariate Data
2.2. The Dip-Test for Unimodality
2.3. Axis Unimodal Dataset
2.4. Node Splitting
3. Axis Unimodal Clustering with a Decision Tree Model
3.1. Splitting Multimodal Features
- If both subsets and are multimodal, then the -value and -value are low resulting in a low value.
- If both subsets and are unimodal, then the -value and -value are high resulting in a high value.
- In case one subset (let ) is unimodal and the other (let ) is multimodal, we need to consider the size of each subset: if and since (unimodal , multimodal ) then the resulting value is high. In the opposite case, the set becomes the dominant set and thus demonstrates a lower value.
| Algorithm 1 best_split_point |
|
3.2. Decision Tree Construction
| Algorithm 2 = best_split() |
|
| Algorithm 3 DTAUC() |
|
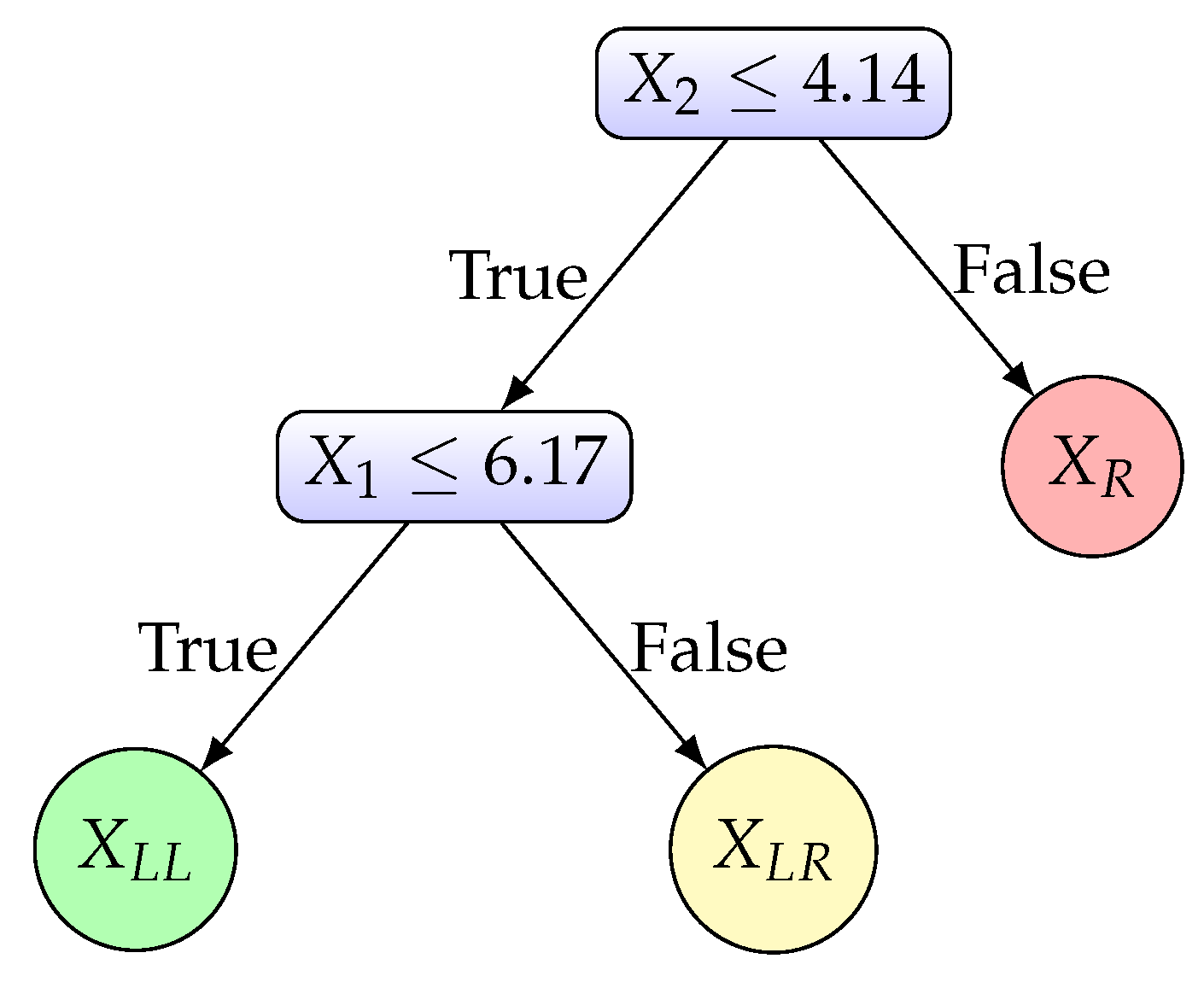
3.3. An Illustrative Example
4. Experimental Results
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CART | Classification and regression trees |
| CDF | Cumulative distribution function |
| CHAID | Chi-squared automatic interaction detector |
| CUBT | Clustering using unsupervised binary trees |
| DTAUC | Decision trees for axis unimodal clustering |
| ECDF | Empirical cumulative distribution function |
| ICOT | Interpretable clustering via optimal trees |
| ID3 | Iterative dichotomiser 3 |
| NMI | Normalized mutual information |
| OCT | Optimal classification trees |
| Probability density function | |
| SEP | Separation |
| SP | Split threshold |
References
- Breiman, L.; Friedman, J.; Stone, C.J.; Olshen, R. Classification and Regression Trees; CRC Press: Boca Raton, FL, USA, 1984. [Google Scholar]
- Quinlan, J.R. Discovering rules by induction from large collections of examples. In Expert Systems in the Micro Electronics Age; Edinburgh University Press: Edinburgh, UK, 1979. [Google Scholar]
- Quinlan, J.R. C4. 5: Programs for Machine Learning; Morgan Kaufmann Pub: Cambridge, MA, USA, 1993. [Google Scholar]
- Kass, G.V. An exploratory technique for investigating large quantities of categorical data. J. R. Stat. Soc. Ser. Appl. Stat. 1980, 29, 119–127. [Google Scholar] [CrossRef]
- Laber, E.; Murtinho, L.; Oliveira, F. Shallow decision trees for explainable k-means clustering. Pattern Recognit. 2023, 137, 109239. [Google Scholar] [CrossRef]
- Tavallali, P.; Tavallali, P.; Singhal, M. K-means tree: An optimal clustering tree for unsupervised learning. J. Supercomput. 2021, 77, 5239–5266. [Google Scholar] [CrossRef]
- Blockeel, H.; De Raedt, L.; Ramon, J. Top-down induction of clustering trees. arXiv 2000, arXiv:cs/0011032. [Google Scholar]
- Basak, J.; Krishnapuram, R. Interpretable hierarchical clustering by constructing an unsupervised decision tree. IEEE Trans. Knowl. Data Eng. 2005, 17, 121–132. [Google Scholar] [CrossRef]
- Fraiman, R.; Ghattas, B.; Svarc, M. Interpretable clustering using unsupervised binary trees. Adv. Data Anal. Classif. 2013, 7, 125–145. [Google Scholar] [CrossRef]
- Liu, B.; Xia, Y.; Yu, P.S. Clustering through decision tree construction. In Proceedings of the Ninth International Conference on Information and Knowledge Management, McLean, VA, USA, 6–11 November 2000; pp. 20–29. [Google Scholar]
- Gabidolla, M.; Carreira-Perpiñán, M.Á. Optimal interpretable clustering using oblique decision trees. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 14–18 August 2022; pp. 400–410. [Google Scholar]
- Heath, D.; Kasif, S.; Salzberg, S. Induction of oblique decision trees. IJCAI 1993, 1993, 1002–1007. [Google Scholar]
- Bertsimas, D.; Orfanoudaki, A.; Wiberg, H. Interpretable clustering: An optimization approach. Mach. Learn. 2021, 110, 89–138. [Google Scholar] [CrossRef]
- Bertsimas, D.; Dunn, J. Optimal classification trees. Mach. Learn. 2017, 106, 1039–1082. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- Dunn, J.C. Well-separated clusters and optimal fuzzy partitions. J. Cybern. 1974, 4, 95–104. [Google Scholar] [CrossRef]
- Adolfsson, A.; Ackerman, M.; Brownstein, N.C. To cluster, or not to cluster: An analysis of clusterability methods. Pattern Recognit. 2019, 88, 13–26. [Google Scholar] [CrossRef]
- Hartigan, J.A.; Hartigan, P.M. The dip test of unimodality. Ann. Stat. 1985, 13, 70–84. [Google Scholar] [CrossRef]
- Chasani, P.; Likas, A. The UU-test for statistical modeling of unimodal data. Pattern Recognit. 2022, 122, 108272. [Google Scholar] [CrossRef]
- Kalogeratos, A.; Likas, A. Dip-means: An incremental clustering method for estimating the number of clusters. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 2393–2401. [Google Scholar]
- Maurus, S.; Plant, C. Skinny-dip: Clustering in a sea of noise. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1055–1064. [Google Scholar]
- Vardakas, G.; Kalogeratos, A.; Likas, A. UniForCE: The Unimodality Forest Method for Clustering and Estimation of the Number of Clusters. arXiv 2023, arXiv:2312.11323. [Google Scholar]
- Ultsch, A. Fundamental Clustering Problems Suite (Fcps); Technical Report; University of Marburg: Marburg, Germany, 2005. [Google Scholar]
- Dua, D.; Graff, C. UCI Machine Learning Repository. 2017. Available online: https://archive.ics.uci.edu (accessed on 20 May 2024).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sets | Features | q | Split or Save | Result | |
|---|---|---|---|---|---|
| X | 1 (M) | Split X | Sets | ||
| 2 (M) | |||||
| 1 (M) | Split | Sets | |||
| 2 (U) | ∅ | ∅ | |||
| 1 (U) | ∅ | ∅ | Save | ||
| 2 (U) | ∅ | ∅ | |||
| 1 (U) | ∅ | ∅ | Save | ||
| 2 (U) | ∅ | ∅ | |||
| 1 (U) | ∅ | ∅ | Save | ||
| 2 (U) | ∅ | ∅ |
| Dataset | n | d | |
|---|---|---|---|
| Synthetic | |||
| Synthetic I | 750 | 3 | 4 |
| Hepta | 212 | 3 | 7 |
| Lsun | 400 | 2 | 3 |
| Tetra | 400 | 3 | 4 |
| TwoDiamonds | 800 | 2 | 2 |
| WingNut | 1016 | 2 | 2 |
| Real | |||
| Boot Motor | 94 | 3 | 3 |
| Dermatology | 366 | 33 | 6 |
| Ecoli | 327 | 7 | 5 |
| Hist OldMaps | 429 | 3 | 10 |
| Image Seg. | 210 | 19 | 7 |
| Iris | 150 | 4 | 3 |
| Ruspini | 75 | 2 | 4 |
| Seeds | 210 | 7 | 3 |
| Dataset | /NMI | DTAUC | ICOT | ExShallow |
|---|---|---|---|---|
| Synthetic I | ||||
| NMI | 0.99 | 0.77 | 0.60 | |
| Hepta | ||||
| NMI | 0.95 | 0.74 | 1.00 | |
| Lsun | ||||
| NMI | 0.97 | 0.73 | 0.53 | |
| Tetra | ||||
| NMI | 0.94 | 1.00 | 1.00 | |
| Two Diamonds | ||||
| NMI | 1.00 | 1.00 | 1.00 | |
| WingNut | ||||
| NMI | 1.00 | 1.00 | 0.17 |
| Dataset | /NMI | DTAUC | ICOT | ExShallow |
|---|---|---|---|---|
| Boot Motor | ||||
| NMI | 1.00 | 1.00 | 0.99 | |
| Dermatology | ||||
| NMI | 0.55 | 0.44 | 0.83 | |
| Ecoli | ||||
| NMI | 0.61 | 0.01 | 0.54 | |
| Hist OldMaps | ||||
| NMI | 0.74 | 0.03 | 0.75 | |
| Image Seg. | ||||
| NMI | 0.69 | 0.01 | 0.60 | |
| Iris | ||||
| NMI | 0.73 | 0.73 | 0.81 | |
| Ruspini | ||||
| NMI | 0.89 | 1.00 | 1.00 | |
| Seeds | ||||
| NMI | 0.63 | 0.53 | 0.66 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chasani, P.; Likas, A. Unsupervised Decision Trees for Axis Unimodal Clustering. Information 2024, 15, 704. https://doi.org/10.3390/info15110704
Chasani P, Likas A. Unsupervised Decision Trees for Axis Unimodal Clustering. Information. 2024; 15(11):704. https://doi.org/10.3390/info15110704
Chicago/Turabian StyleChasani, Paraskevi, and Aristidis Likas. 2024. "Unsupervised Decision Trees for Axis Unimodal Clustering" Information 15, no. 11: 704. https://doi.org/10.3390/info15110704
APA StyleChasani, P., & Likas, A. (2024). Unsupervised Decision Trees for Axis Unimodal Clustering. Information, 15(11), 704. https://doi.org/10.3390/info15110704