

Cyber Security on the Edge: Efficient Enabling of Machine Learning on IoT Devices


Abstract
1. Introduction
1.1. Background
1.2. Research Contribution
- Use of AI-enabled architecture in the cluster;
- Use of machine learning models for the detection of DDos and other attacks;
- Use of container orchestration tool like Microk8s;
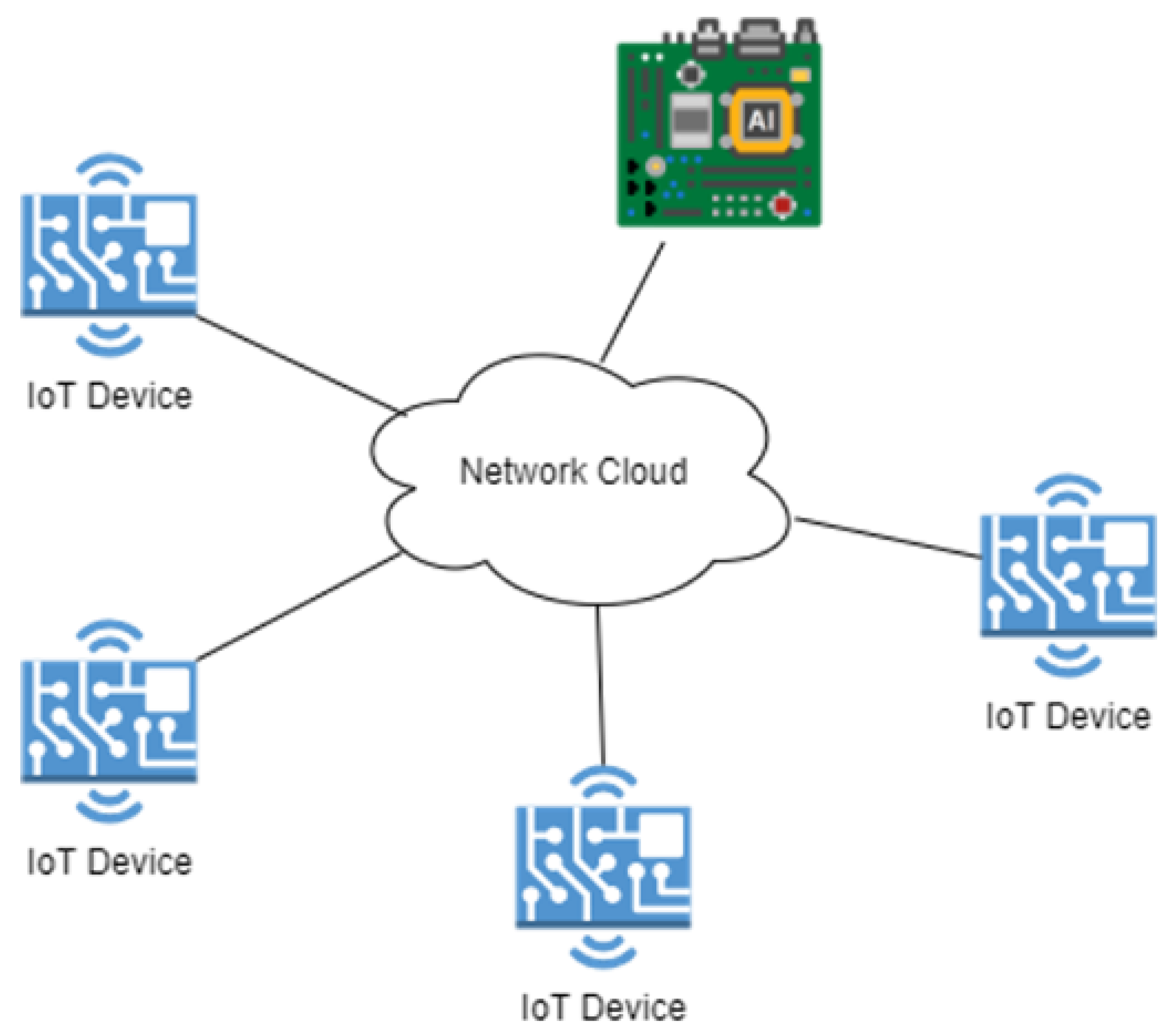
- Use of different forms of architecture with AI-enabled IoT devices or simple IoT devices like Raspberry Pi;
- Use of Docker images for microservices;
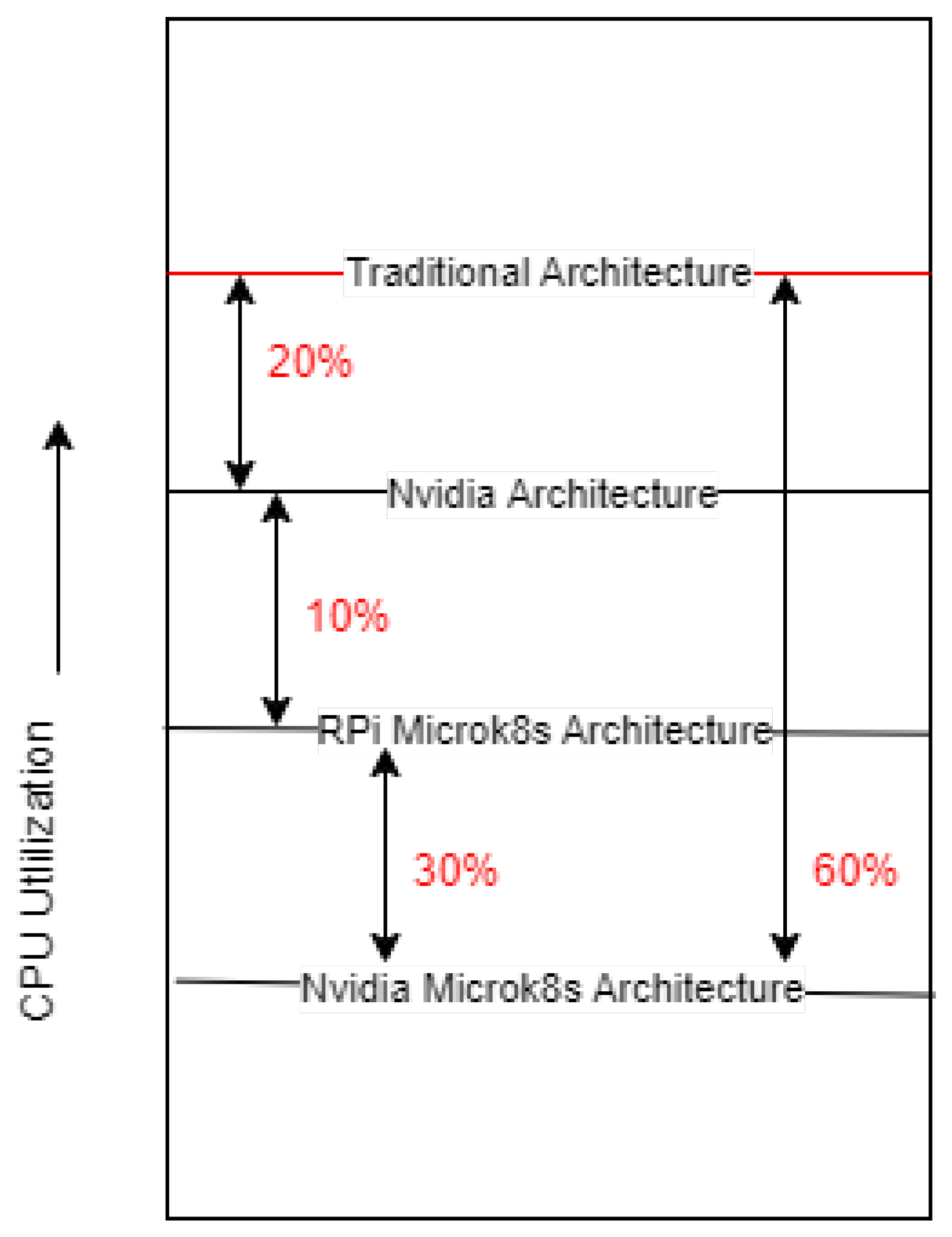
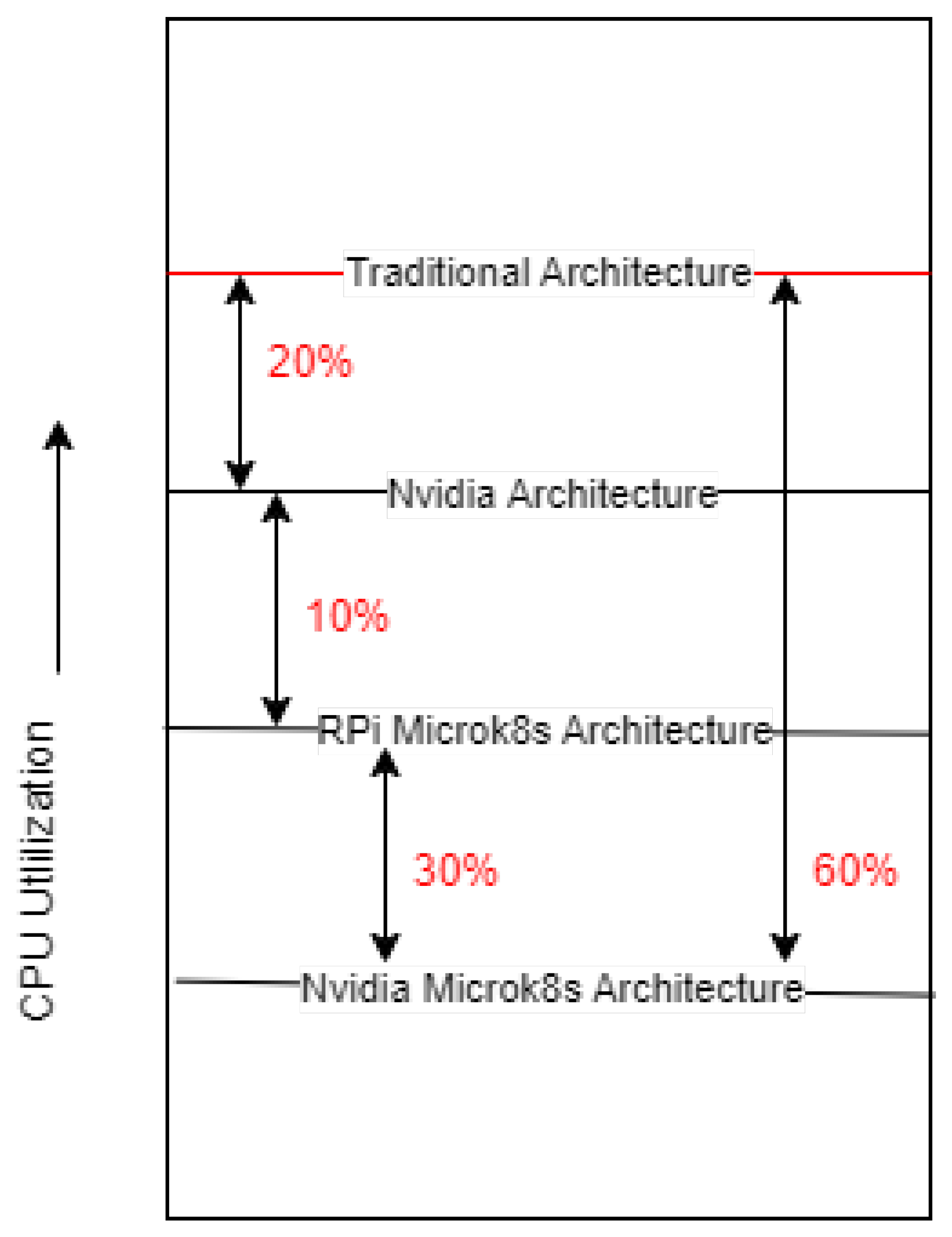
- An overall decrease of 60% in CPU utilisation from the traditional architecture of Raspberry Pi to Microk8s architecture with Nvidia is achieved;
- Container orchestration-as-a-solution: it provides a way to efficiently manage the autoscaling of the resources if required and did a great job with job scheduling.
2. Related Work
2.1. Cyber Security as a Challenge to IoT Devices
2.2. Solutions Implemented to Solve Security Vulnerabilities
2.3. Container Orchestration Applied to IoT Devices
2.4. Mitigation to DDoS Attacks on IoT Devices
2.5. Research Gap
3. Methodology
3.1. DDoS Detection Model
- Dummy Classifier: A dummy classifier is a simple and baseline machine learning model used for comparison and benchmarking purposes. It is typically employed when dealing with imbalanced datasets or as a reference to assess the performance of more sophisticated models. The dummy classifier makes predictions based on predefined rules and does not learn from the data. The dummy classifier with the strategy of predicting the most frequent class is utilised for the baseline. The most frequent class classifier always predicts the class that appears most frequently in the training data. This is useful when dealing with imbalanced datasets where one class is significantly more prevalent than others [20].
- Logistic Regression: Logistic regression is a popular and widely used classification algorithm in machine learning. Despite its name, it is used for binary classification tasks, where the output variable has two classes (e.g., “Yes” or “No”, “True” or “False”). The logistic regression model calculates the probability that an input data point belongs to a particular class. It does this by transforming its output through the logistic function (also known as the sigmoid function). The logistic function maps any real-valued number to a value between 0 and 1, which can be interpreted as a probability [21].
- Deep Learning Model: The deep learning model has three layers to it. The first layer is the input layer. It has got the input shape of 80 neurons which outputs a shape of (None, 128). A dropout regularisation enables this layer to handle overfitting of the data. This is followed by another dense layer which also has a dropout regularisation. In the end, the model has an output layer with one neuron giving a probability as an output due to the sigmoid function being used in the last layer.
Performance Metrics
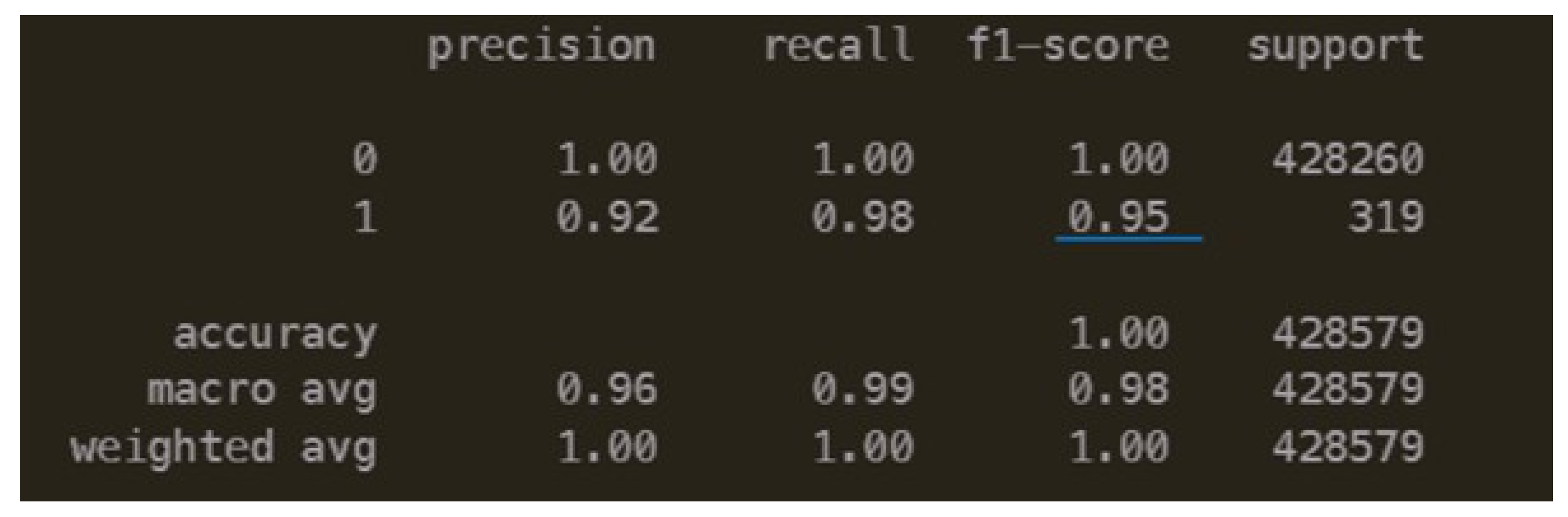
- F1 score: It combines the precision and recall scores of a model. It is usually more useful than accuracy, especially if you have an uneven class distribution. The equation is provided in Equation (1).
3.2. Technology Used
3.2.1. Python
- Flask: This is a framework defined under the Python language for hosting REST APIs. The programmer can define the business logic which interacts with the front end. It provides an interface between the end user and databases.
3.2.2. Microk8s
3.3. Components
3.3.1. Nvidia Jetson Nano
3.3.2. Raspberry Pi
3.3.3. Netgear Switch
3.4. Networking Architectures
3.4.1. Traditional Architecture and Nvidia Architecture
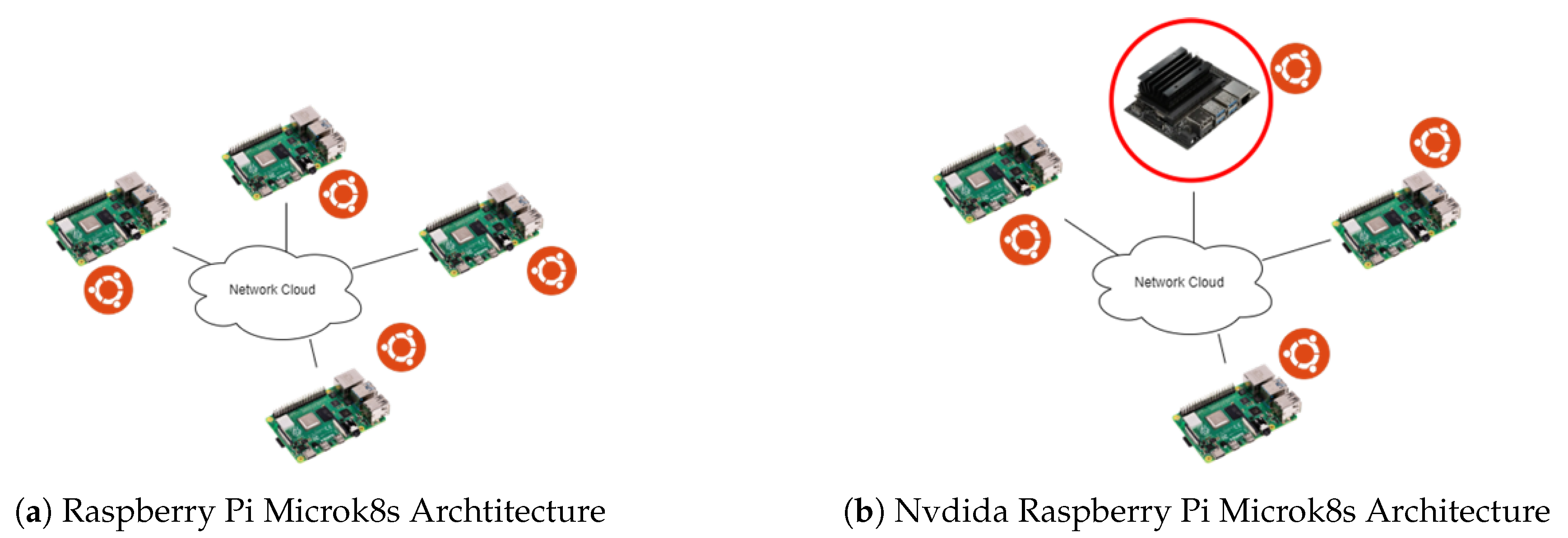
3.4.2. Raspberry Pi Microk8s Archtitecture and Nvdida Raspberry Pi Microk8s Architecture
3.5. Validation of Hypothesis
3.5.1. Machine Learning Validation
3.5.2. Architecture Improvement Validation
4. Design and Implementation
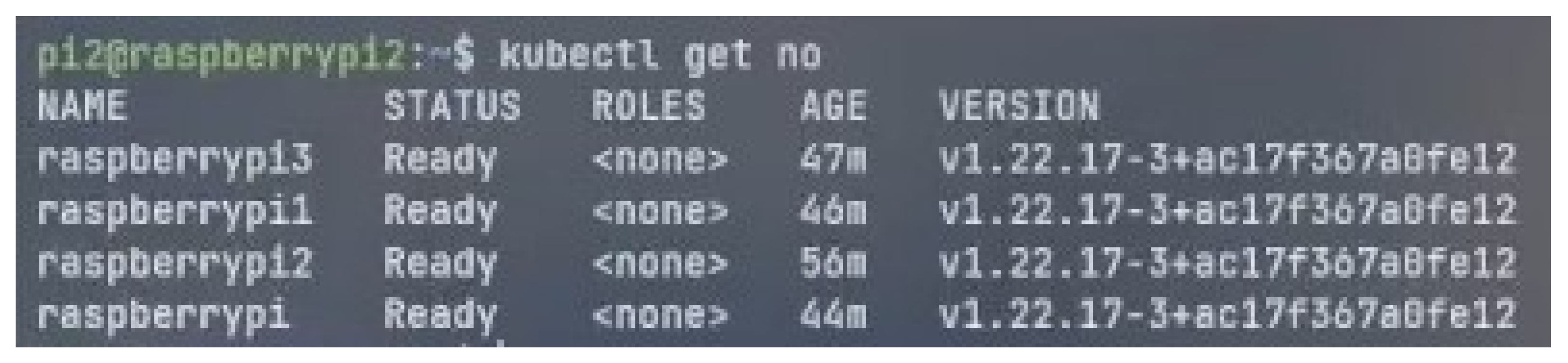
4.1. Cluster Setup
Raspberry Pi Cluster and Nvidia-Raspberry Pi Cluster
4.2. Docker
4.3. Kubernetes Terminologies
4.3.1. Pods
4.3.2. Deployment
4.3.3. Namespaces
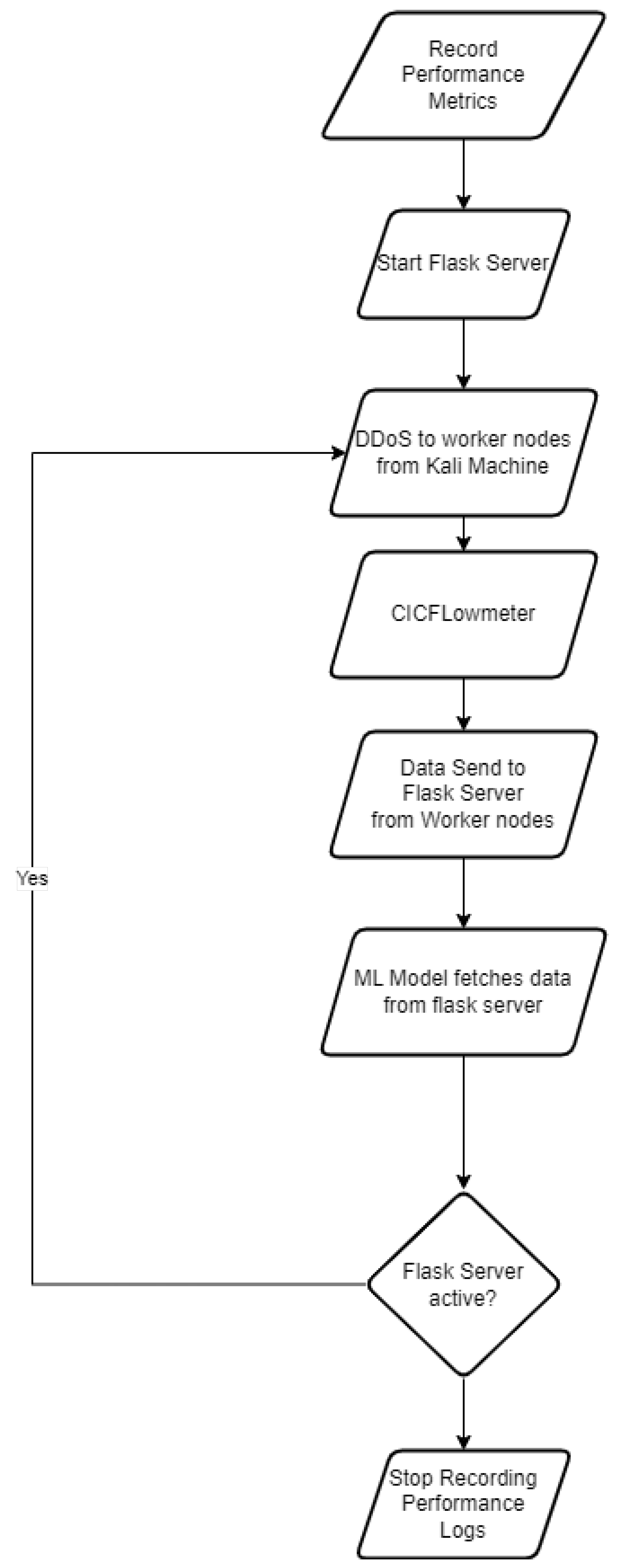
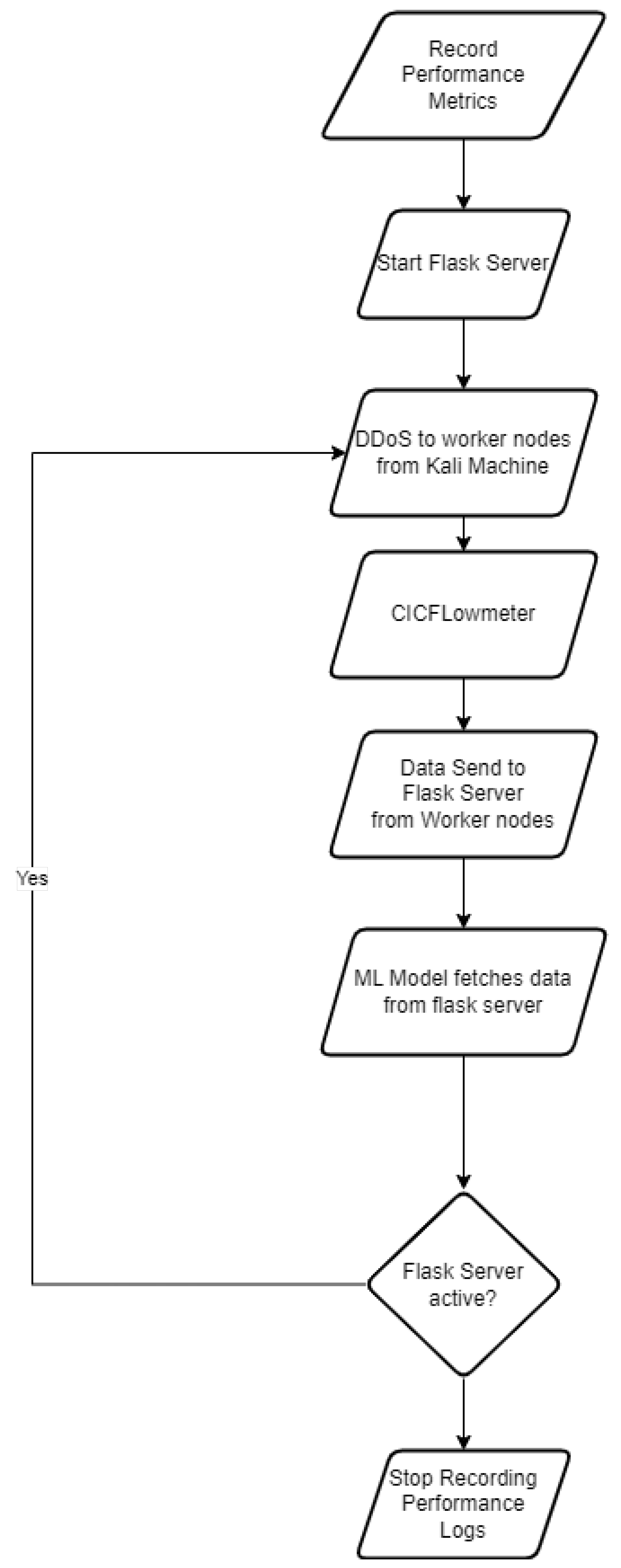
4.4. Design Flow
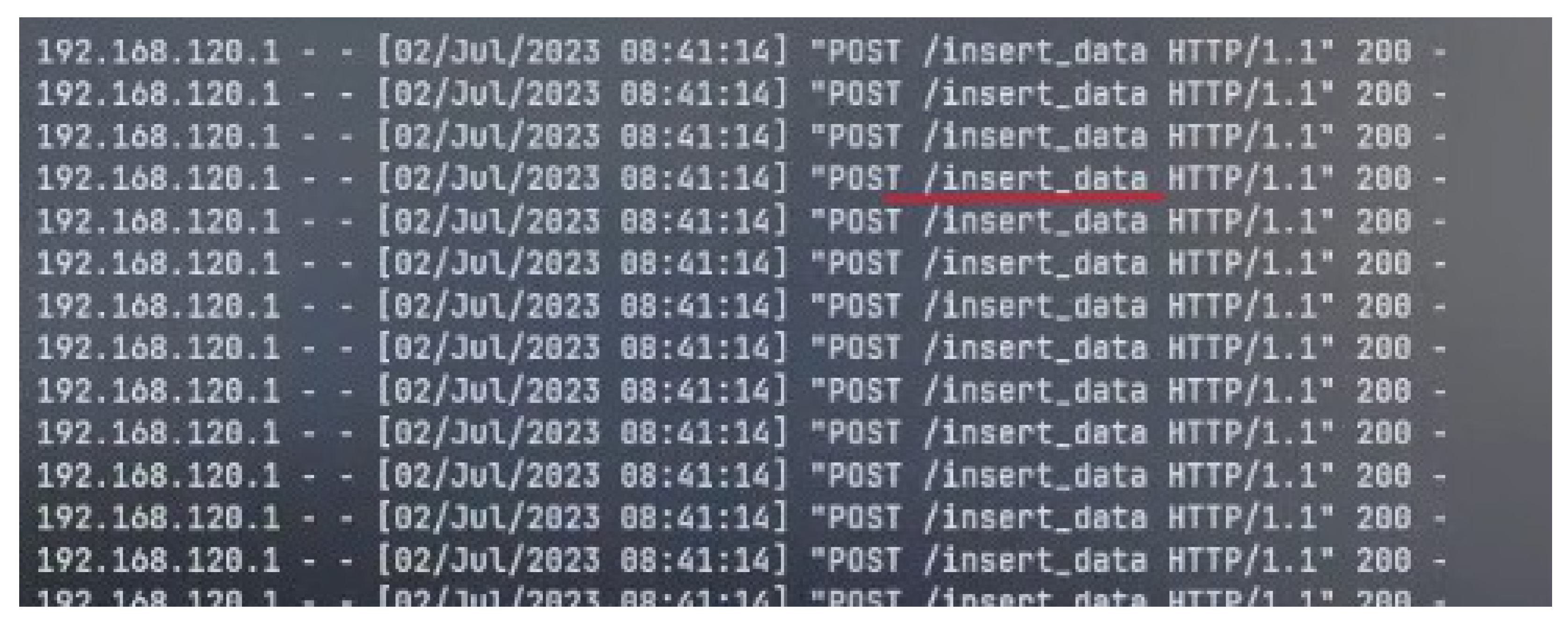
Message Queue Implementation
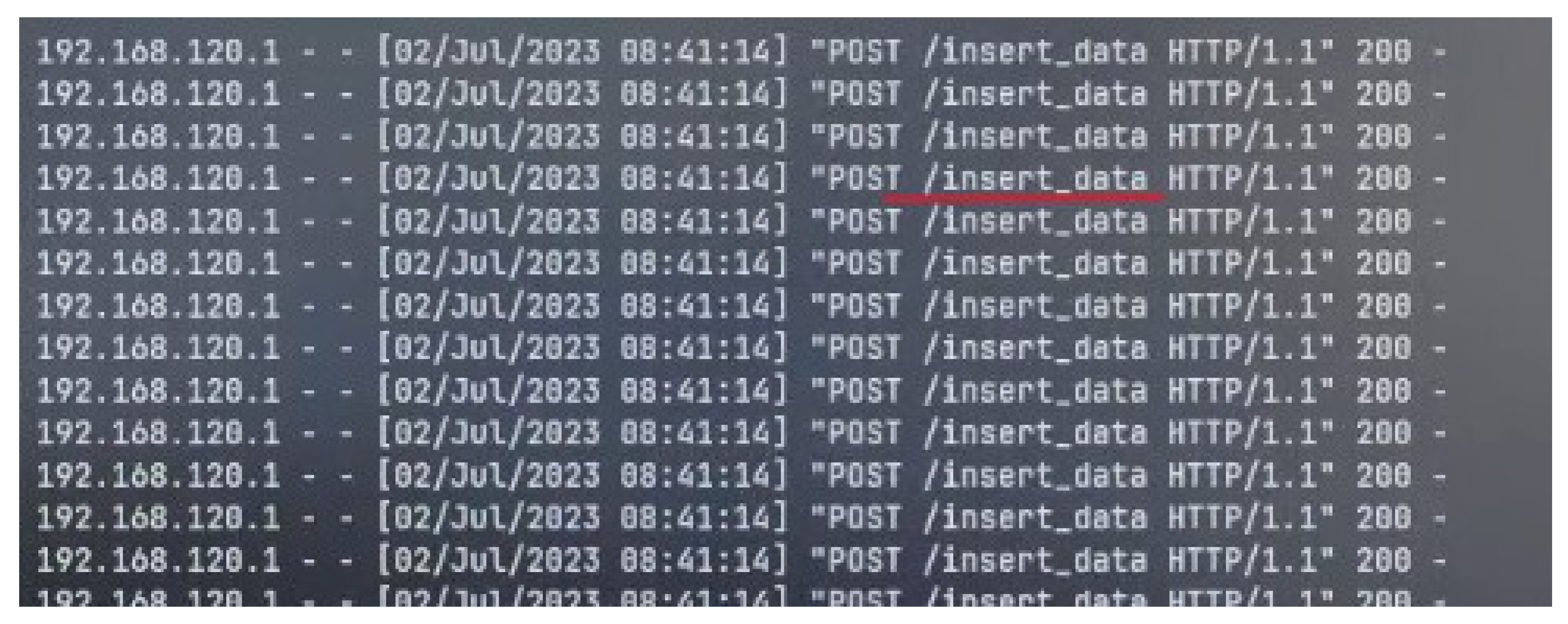
- DNS (Domain Name Service): This is required for the pods to resolve the flask-app service internally when the machine learning/data-sending script is executed.
- Metallb (Metal Load Balancer): This load balancer is required to load balance if there are multiple pods for flask service running.
- Ingress.
- GPU: This only applies to Nvidia-based hardware and given that the device should have an Nvidia GPU. The Microk8s detect the GPU and execute the tasks which require GPU if the deployment is launched.
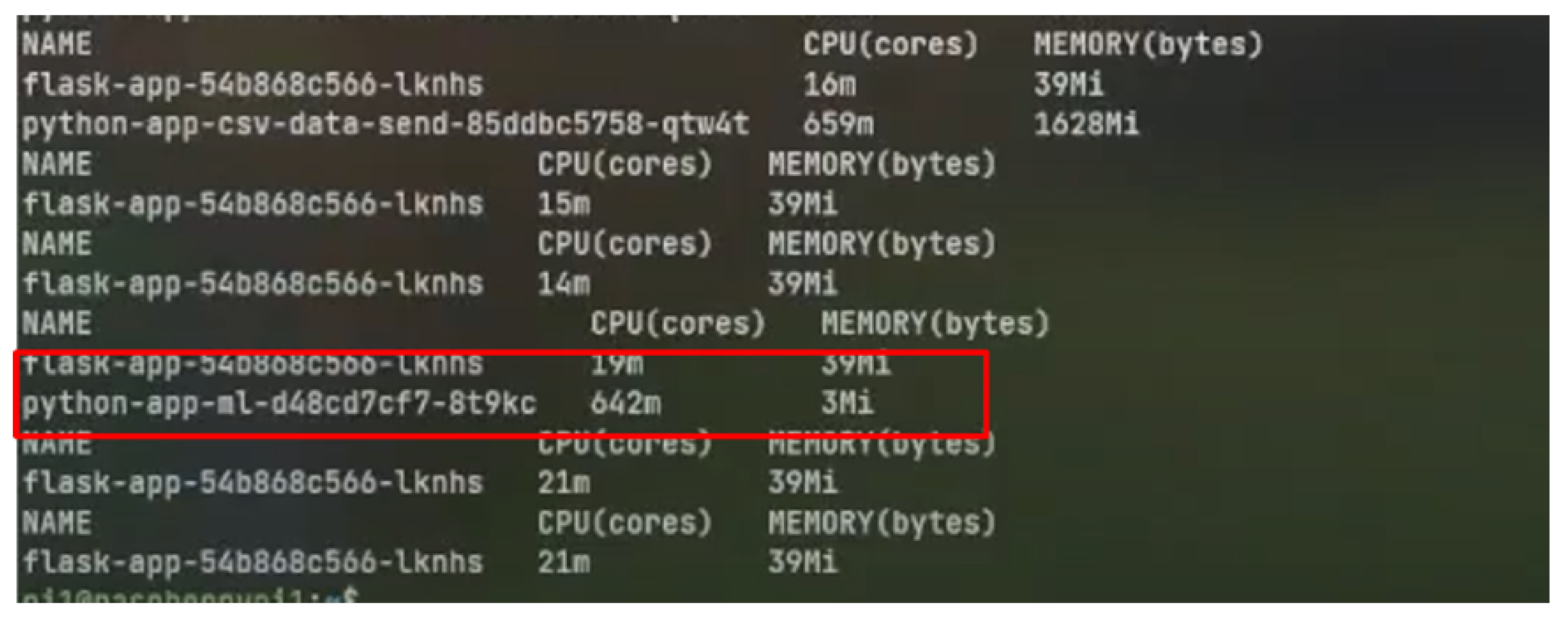
- Metrics-server: This is required for recording the performance metrics of the Kubernetes cluster. This service enquires about the utilisation of CPU and memory for every pod running in a particular namespace.
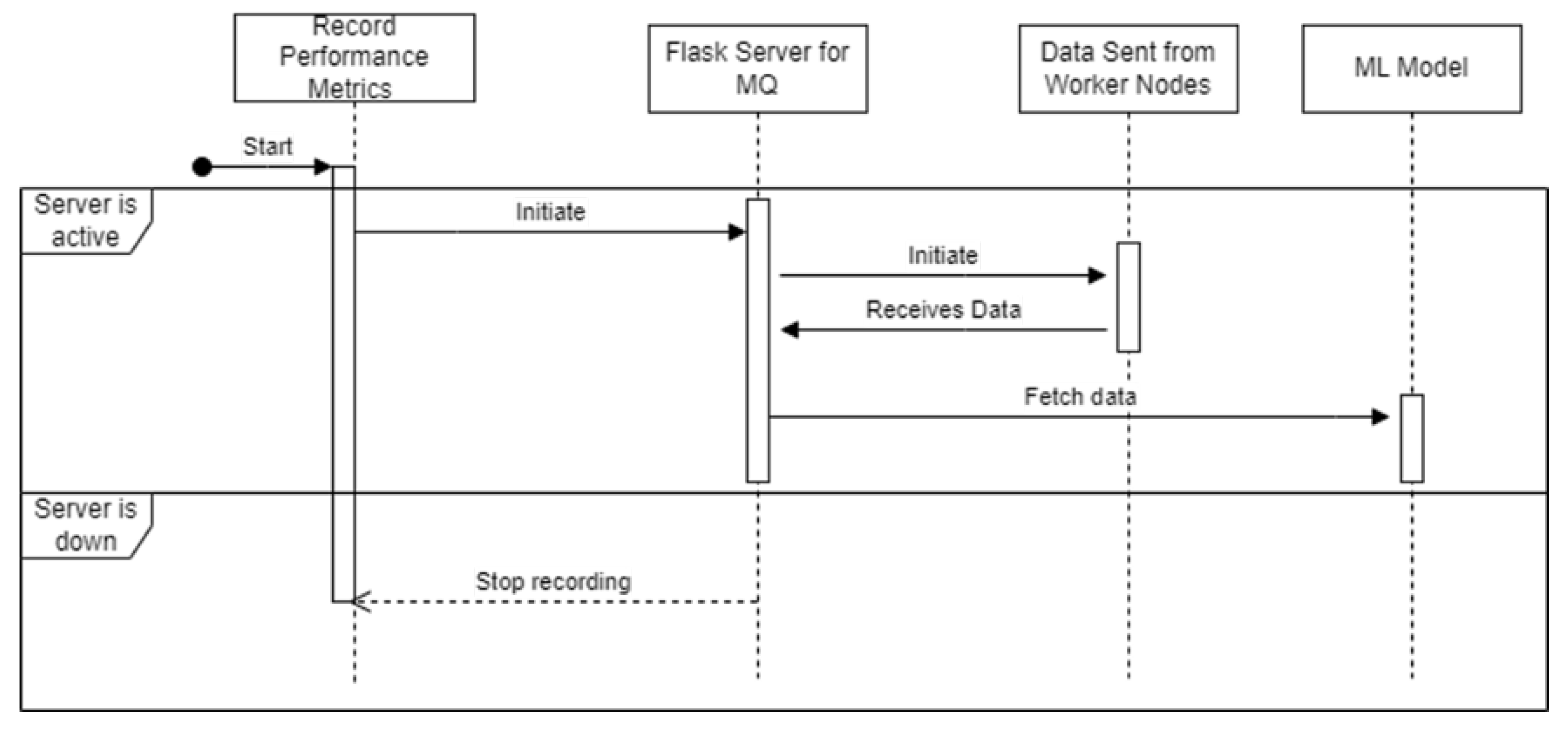
4.5. Implementation of Non-Microk8s Architecture
4.5.1. Performance Metrics
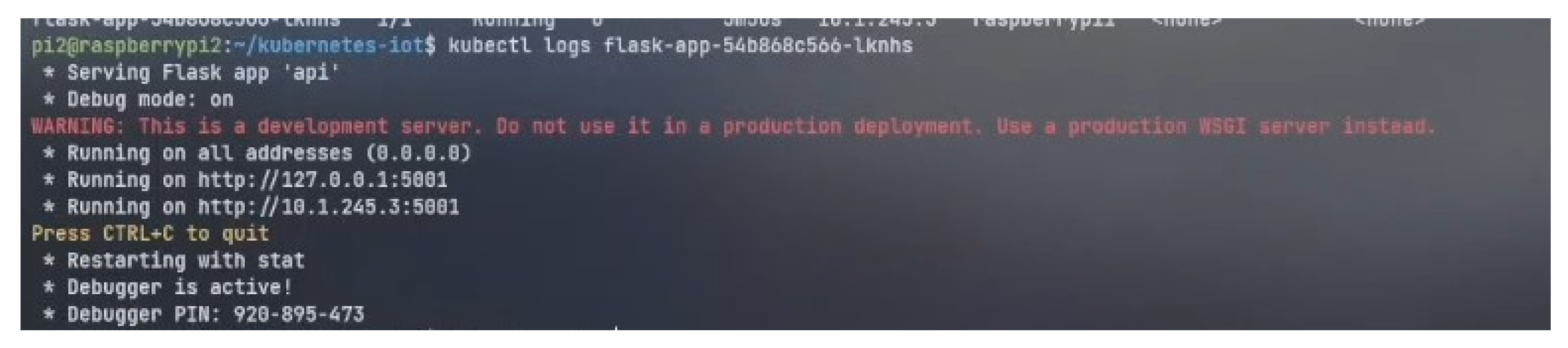
4.5.2. Machine Learning Execution
4.5.3. Reading Performance File
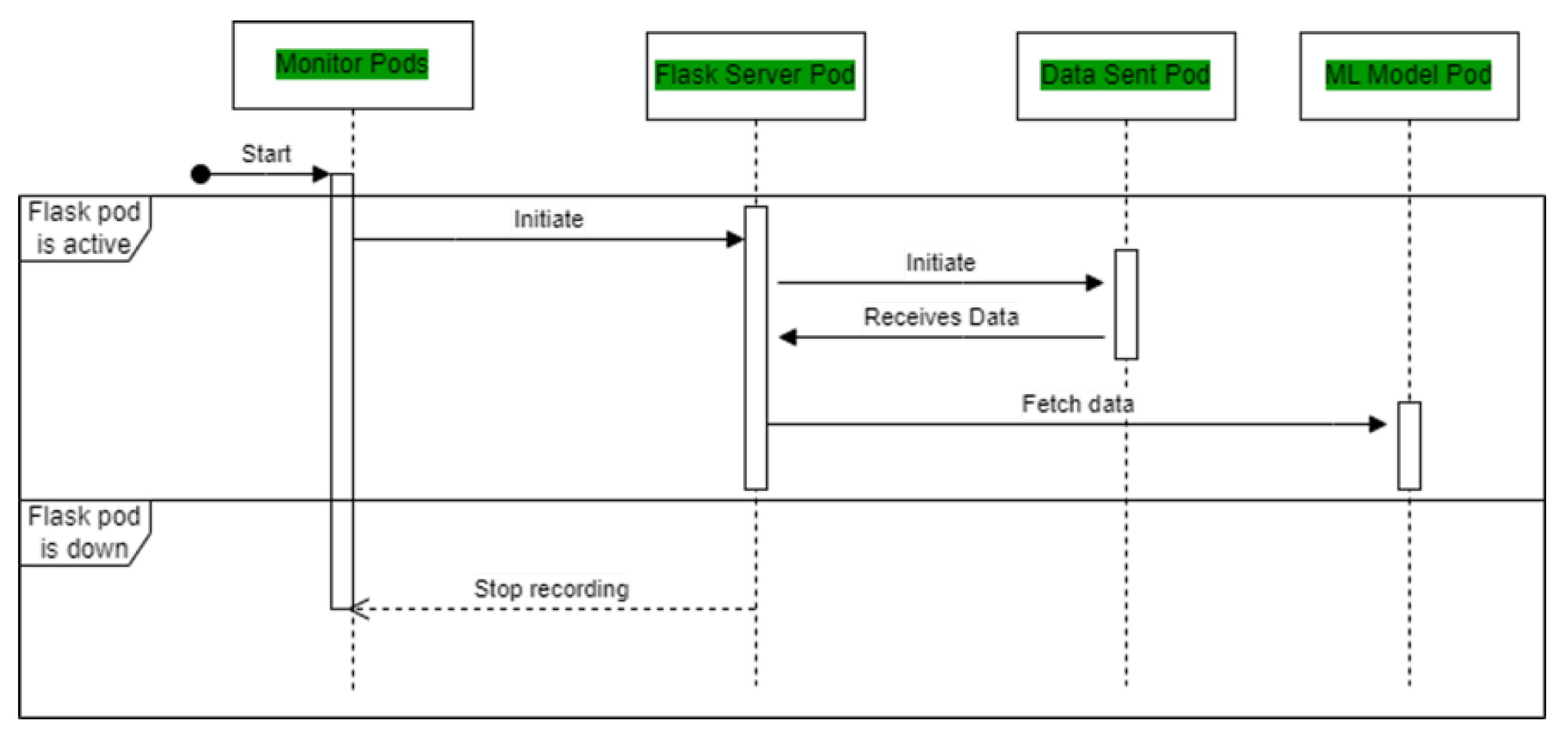
4.6. Implementation of Microk8s Architecture
Performance Metrics
4.7. Challenges
- Microk8sSnap package manager has many Microk8s variants. This requires choosing the proper version for the use case. Initial use of the current version caused issues with the Kubelet API server and connecting devices through Microk8s. These flaws were also in the lower version. The author consulted the Microk8s community to locate a version that supported Prometheus, Grafana, and GPU add-ons. Despite version difficulties, all versions allowed the addition of devices and capabilities of Kubernetes provided through the Microk8s. The version suggested by them was 1.22.
- Nvidia Jetson Nano Setup Finding the appropriate operating system was initially difficult due to the variety of versions and their features, some of which were outdated and unsupported by hardware. Operating system images were available for prior Nvidia chipsets. Nvidia forums and community helped choose the correct image. Nvidia crashed when a 16 GB Micro SD card was used because the image size was 14 GB after installation. Nvidia could no longer use the SD card for utility software. This was carried out later with a 64 GB card.
- TFLite Model on Nvidia Jetson The TFLite model dependencies could not run on Nvidia Jetson due to the Tensorflow version being very different from other IoT device versions. This is because of the hardware architecture of Nvidia. Therefore, the H5 model is used because it is able to run on both platforms and allows a fair comparison between the traditional Raspberry Pi and Nvidia-enabled architecture.
- Prometheus and Grafana These services are offered as add-ons to the Microk8s (version 1.22+). They are responsible for capturing resource utilisation of every pod in each namespace or node in the cluster. Prometheus and Grafana were initially tested on the cluster. Still, the resource utilisation by the Prometheus namespace was high which was crashing the Microk8s service on the nodes when the other deployments were being initiated. Therefore, it is suggested to have at least 8 GB of RAM on the node’s hardware.
5. Evaluation
5.1. Machine Learning
5.1.1. Dummy Classifier Performance
5.1.2. Logistic Regression Performance
5.1.3. Neural Network Performance
5.2. Architecture
5.2.1. Energy Consumption
5.2.2. Scalability and Latency
5.2.3. Efficiency, Security and Cost Effectiveness
5.3. Real-World Applications
6. Conclusions
- Comparison Of Raspberry Pi to Microk8s Raspberry Pi: Reduction of almost 30% (CPU) and 99% (Memory).
- Comparison Of Nvidia—Raspberry Pi to Microk8s Nvidia—Raspberry Pi: Reduction of almost 42% (CPU) and 98% (Memory).
- Comparison of Raspberry Pi and Nvidia-Raspberry Pi: Reduction of almost 21% (CPU) and Increase of 62.5% (Memory).
- Comparison of Microk8s Architecture—Raspberry Pi vs. Nvidia-Raspberry Pi: Reduction of almost 32.5% (CPU) & Increase of 95% (Memory).
- An overall decrease of 60% in CPU utilisation from the traditional architecture of Rasp berry Pi to Microk8s architecture with Nvidia.
- Container Orchestration-as-a-solution: It managed resources efficiently, auto-scaled when needed, and scheduled jobs well. Since the solutions are not directly distributed to the host, malware implantation can be stopped by restarting another pod for that deployment, making it security-reliable.
Future Work
- Use of Google Coral Device: The Google gadget has a Tensor Processing Unit. Eventually, this gadget and Raspberry Pi can be compared to Nvidia Jetson Nano for performance analysis. This can be clustered or standalone.
- Realtime updating of Machine Learning Model: When data become available on the platform, cloud updating of the machine learning model affects the model’s real-time performance reliability. If this could be conducted on the edge with CPU optimization in mind, imagine what IoT devices could achieve with merely data coming in and the model being updated in real time without sending it to the cloud.
- Adversarial AI for Malware Detection: Attackers must escape IoT devices after planting botnets to avoid leaving cyber fingerprints. Adversarial AI that predicts evasion and avoids malware plants. This would preserve the attackers’ fingerprints and make tracking malware to its source easier. Generative Adversarial Network implementation in malware detection is also receiving interest.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Merenda, M.; Porcaro, C.; Iero, D. Edge machine learning for ai-enabled iot devices: A review. Sensors 2020, 20, 2533. [Google Scholar] [CrossRef] [PubMed]
- Ghosh, A.; Chakraborty, D.; Law, A. Artificial intelligence in Internet of things. CAAI Trans. Intell. Technol. 2018, 3, 208–218. [Google Scholar] [CrossRef]
- Covi, E.; Donati, E.; Liang, X.; Kappel, D.; Heidari, H.; Payvand, M.; Wang, W. Adaptive extreme edge computing for wearable devices. Front. Neurosci. 2021, 15, 611300. [Google Scholar] [CrossRef] [PubMed]
- Fayos-Jordan, R.; Felici-Castell, S.; Segura-Garcia, J.; Lopez-Ballester, J.; Cobos, M. Performance comparison of container orchestration platforms with low cost devices in the fog, assisting Internet of Things applications. J. Netw. Comput. Appl. 2020, 169, 102788. [Google Scholar] [CrossRef]
- Taylor, R.; Baron, D.; Schmidt, D. The world in 2025-predictions for the next ten years. In Proceedings of the 2015 10th International Microsystems, Packaging, Assembly and Circuits Technology Conference (IMPACT), Taipei, Taiwan, 21–23 October 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 192–195. [Google Scholar]
- Wu, H.; Han, H.; Wang, X.; Sun, S. Research on artificial intelligence enhancing internet of things security: A survey. IEEE Access 2020, 8, 153826–153848. [Google Scholar] [CrossRef]
- Shakdher, A.; Agrawal, S.; Yang, B. Security vulnerabilities in consumer iot applications. In Proceedings of the 2019 IEEE 5th Intl Conference on Big Data Security on Cloud (BigDataSecurity), IEEE Intl Conference on High Performance and Smart Computing, (HPSC) and IEEE Intl Conference on Intelligent Data and Security (IDS), Washington, DC, USA, 27–29 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Dinculeană, D.; Cheng, X. Vulnerabilities and limitations of MQTT protocol used between IoT devices. Appl. Sci. 2019, 9, 848. [Google Scholar] [CrossRef]
- Pokhrel, S.; Abbas, R.; Aryal, B. IoT security: Botnet detection in IoT using machine learning. arXiv 2021, arXiv:2104.02231. [Google Scholar]
- Alrowaily, M.; Lu, Z. Secure edge computing in IoT systems: Review and case studies. In Proceedings of the 2018 IEEE/ACM Symposium on Edge Computing (SEC), Seattle, WA, USA, 25–27 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 440–444. [Google Scholar]
- SmartDefense: A distributed deep defense against DDoS attacks with edge computing. Comput. Netw. 2022, 209, 108874. [CrossRef]
- Bhardwaj, K.; Miranda, J.C.; Gavrilovska, A. Towards {IoT-DDoS} Prevention Using Edge Computing. In Proceedings of the USENIX Workshop on Hot Topics in Edge Computing (HotEdge 18), Boston, MA, USA, 11–13 July 2018. [Google Scholar]
- Mirzai, A.; Coban, A.Z.; Almgren, M.; Aoudi, W.; Bertilsson, T. Scheduling to the Rescue; Improving ML-Based Intrusion Detection for IoT. In Proceedings of the 16th European Workshop on System Security, Rome, Italy, 8 May 2023; pp. 44–50. [Google Scholar]
- Beltrão, A.C.; de França, B.B.N.; Travassos, G.H. Performance Evaluation of Kubernetes as Deployment Platform for IoT Devices. In Proceedings of the Ibero-American Conference on Software Engineering, Curitiba, Brazil, 4–8 May 2020. [Google Scholar]
- Koziolek, H.; Eskandani, N. Lightweight Kubernetes Distributions: A Performance Comparison of MicroK8s, k3s, k0s, and Microshift. In Proceedings of the 2023 ACM/SPEC International Conference on Performance Engineering, Coimbra, Portugal, 15–19 April 2023; pp. 17–29. [Google Scholar]
- Hayat, R.F.; Aurangzeb, S.; Aleem, M.; Srivastava, G.; Lin, J.C.W. ML-DDoS: A blockchain-based multilevel DDoS mitigation mechanism for IoT environments. IEEE Trans. Eng. Manag. 2022, 1–14. [Google Scholar] [CrossRef]
- Todorov, M.H. Deploying Different Lightweight Kubernetes on Raspberry Pi Cluster. In Proceedings of the 2022 30th National Conference with International Participation (TELECOM), Sofia, Bulgaria, 27–28 October 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–4. [Google Scholar]
- Ferdowsi, A.; Saad, W. Generative adversarial networks for distributed intrusion detection in the internet of things. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Elsayed, M.S.; Le-Khac, N.A.; Dev, S.; Jurcut, A.D. Ddosnet: A deep-learning model for detecting network attacks. In Proceedings of the 2020 IEEE 21st International Symposium on “A World of Wireless, Mobile and Multimedia Networks” (WoWMoM), Cork, Ireland, 31 August–3 September 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 391–396. [Google Scholar]
- Kannavara, R.; Gressel, G.; Fagbemi, D.; Chow, R. A Machine Learning Approach to SDL. In Proceedings of the 2017 IEEE Cybersecurity Development (SecDev), Cambridge, MA, USA, 24–26 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 10–15. [Google Scholar]
- Bapat, R.; Mandya, A.; Liu, X.; Abraham, B.; Brown, D.E.; Kang, H.; Veeraraghavan, M. Identifying malicious botnet traffic using logistic regression. In Proceedings of the 2018 Systems and Information Engineering Design Symposium (SIEDS), Charlottesville, VA, USA, 27 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 266–271. [Google Scholar]
- Ma, L.; Chai, Y.; Cui, L.; Ma, D.; Fu, Y.; Xiao, A. A deep learning-based DDoS detection framework for Internet of Things. In Proceedings of the ICC 2020—2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Debauche, O.; Mahmoudi, S.; Guttadauria, A. A new edge computing architecture for IoT and multimedia data management. Information 2022, 13, 89. [Google Scholar] [CrossRef]
- Süzen, A.A.; Duman, B.; Şen, B. Benchmark analysis of jetson tx2, jetson nano and raspberry pi using deep-cnn. In Proceedings of the 2020 International Congress on Human-Computer Interaction, Optimization and Robotic Applications (HORA), Ankara, Turkey, 26–28 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–5. [Google Scholar]
- Gizinski, T.; Cao, X. Design, Implementation and Performance of an Edge Computing Prototype Using Raspberry Pis. In Proceedings of the 2022 IEEE 12th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 26–29 January 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 0592–0601. [Google Scholar]
- Docker Docs. Docker Overview. 2023. Available online: https://docs.docker.com/get-started/overview/ (accessed on 25 July 2023).
- Redhat. “What is kuberentes?”. 2023. Available online: https://www.redhat.com/en/topics/containers/what-is-kubernetes (accessed on 25 July 2023).
- Kubernetes. “Pods”. 2023. Available online: https://kubernetes.io/docs/concepts/workloads/pods/ (accessed on 25 July 2023).
- Kubernetes. “Deployment”. 2023. Available online: https://kubernetes.io/docs/concepts/workloads/controllers/deployment/ (accessed on 25 July 2023).
- Kubernetes. “Namespaces”. 2023. Available online: https://kubernetes.io/docs/concepts/overview/working-with-objects/namespaces/ (accessed on 25 July 2023).
- Lahmadi, A.; Duque, A.; Heraief, N.; Francq, J. MitM attack detection in BLE networks using reconstruction and classification machine learning techniques. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Bilbao, Spain, 14–18 September 2020; Springer: Cham, Switzerland, 2020; pp. 149–164. [Google Scholar]
- Alrashdi, I.; Alqazzaz, A.; Aloufi, E.; Alharthi, R.; Zohdy, M.; Ming, H. Ad-iot: Anomaly detection of iot cyberattacks in smart city using machine learning. In Proceedings of the 2019 IEEE 9th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 7–9 January 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 0305–0310. [Google Scholar]
- Atutxa, A.; Franco, D.; Sasiain, J.; Astorga, J.; Jacob, E. Achieving low latency communications in smart industrial networks with programmable data planes. Sensors 2021, 21, 5199. [Google Scholar] [CrossRef] [PubMed]
- Ferrari, P.; Sisinni, E.; Brandão, D.; Rocha, M. Evaluation of communication latency in industrial IoT applications. In Proceedings of the 2017 IEEE International Workshop on Measurement and Networking (M&N), Naples, Italy, 27–29 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Cui, L.; Xu, C.; Yang, S.; Huang, J.Z.; Li, J.; Wang, X.; Ming, Z.; Lu, N. Joint optimization of energy consumption and latency in mobile edge computing for Internet of Things. IEEE Internet Things J. 2018, 6, 4791–4803. [Google Scholar] [CrossRef]
- Azari, A.; Stefanović, Č.; Popovski, P.; Cavdar, C. On the latency-energy performance of NB-IoT systems in providing wide-area IoT connectivity. IEEE Trans. Green Commun. Netw. 2019, 4, 57–68. [Google Scholar] [CrossRef]
- Javed, A.; Malhi, A.; Kinnunen, T.; Främling, K. Scalable IoT platform for heterogeneous devices in smart environments. IEEE Access 2020, 8, 211973–211985. [Google Scholar] [CrossRef]
- Badiger, S.; Baheti, S.; Simmhan, Y. Violet: A large-scale virtual environment for internet of things. In Proceedings of the Euro-Par 2018: Parallel Processing: 24th International Conference on Parallel and Distributed Computing, Turin, Italy, 27–31 August 2018; Proceedings 24. Springer: Cham, Switzerland, 2018; pp. 309–324. [Google Scholar]
- Meghana, V.; Anisha, B.; Kumar, P.R. IOT based Smart Traffic Signal Violation Monitoring System using Edge Computing. In Proceedings of the 2021 2nd Global Conference for Advancement in Technology (GCAT), Bangalore, India, 1–3 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–5. [Google Scholar]
- Surantha, N.; Atmaja, P.; Wicaksono, M. A review of wearable internet-of-things device for healthcare. Procedia Comput. Sci. 2021, 179, 936–943. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Work Carried Out | Challenges |
|---|---|---|
| [6] | Attribution analysis of IoT Security Threats Security Threats in different layers of OSI modelDiscussion of Feasibility Analysis of AI in IoT SecurityAI solution for IoT security threats | Linear Growth of Cloud Computing does not match the exponential growth of IoT Devices.Computational Complexity for IoT DevicesData Manipulation done by attackers |
| [11] | A two-stage DDoS detection solution that utilizes deep learning algorithms and operates on the provider edge (PE) and consumer edge (CE). | Solution is not based on IoT devices but rather on routers. |
| [17] | ShadowNet deployed at the network’s edge to speed up defence against IoT-DDoS attacks. | Solution deployed on gateways |
| [14] | Exploring different Kubernetes distributions on rasp- berry pi clusters. Exploring pros and cons | Did not perform a load test on the cluster |
| [18] | Distributed platform over IoT devices so as to make them support GAN as a solution to Intrusion. Reduced dependency on Central cloud systems | The research did not present the CPU utilisation and Memory utilisation on the devices. |
| [15] | Analysis of different lightweight k8s distributions | Implemented it on Azure VMs. |
| [16] | Ethereum based blockchain Signature-based authenticity test of devices | Eliminates the affected botnet devices |
| [12] | Kubernetes deployed on Raspberry Pi. Test conducted using synchronous and asynchronous scenarios to handle IoT components | The test could have also involved testing on machine learning paradigm as well. |
| S.No. | Flow Duration | TotalFwd Packet | .. | Similar HTTP | Inbound | Label |
|---|---|---|---|---|---|---|
| 1 | 9141643 | 85894 | .. | 0 | 1 | DrDoS_LDAP |
| 2 | 1 | 2 | .. | 0 | 1 | DrDoS_LDAP |
| 3 | 2 | 2 | .. | 0 | 1 | DrDoS_LDAP |
| 4 | 1 | 2 | .. | 0 | 1 | DrDoS_LDAP |
| 5 | 2 | 2 | .. | 0 | 1 | DrDoS_LDAP |
| 6 | 2 | 2 | .. | 0 | 1 | DrDoS_LDAP |
| 7 | 2 | 2 | .. | 0 | 1 | DrDoS_LDAP |
| .. | .. | .. | .. | .. | .. | .. |
| 2181536 | 1 | 2 | .. | 0 | 1 | DrDoS_LDAP |
| 2181537 | 50 | 2 | .. | 0 | 1 | DrDoS_LDAP |
| 2181538 | 1 | 2 | .. | 0 | 1 | DrDoS_LDAP |
| 2181539 | 1 | 2 | .. | 0 | 1 | DrDoS_LDAP |
| 2181540 | 1 | 2 | .. | 0 | 1 | DrDoS_LDAP |
| 2181541 | 1 | 2 | .. | 0 | 1 | DrDoS_LDAP |
| 2181542 | 2 | 2 | .. | 0 | 1 | DrDoS_LDAP |
| Non-Microk8s (H5 Model) | Microk8s (TFLite Model) | |||
|---|---|---|---|---|
| Rpi (Traditional) | Nvidia-Rpi | Rpi | Nvidia-Rpi | |
| CPU (%) | 93.5 | 73.4 | 64.2 | 31.5 |
| Memory (%) | 10.5 (420 MB) | 28.6 (1120 MB) | 0.0007 (3 MB) | 0.01 (73 MB) |
| Ref | [33] | [34] | [35] | [36] | [37] | [38] | Proposed |
|---|---|---|---|---|---|---|---|
| Latency | 18 ms | 400 ms | 2 s | 2 s | 2 s–5 s | 25–50 ms | 10–15 ms |
| Ref. | Efficiency | Security | Cost Effective |
|---|---|---|---|
| [17] | The study in this research evolved around raspberry Pis and how different light versions of Kubernetes perform on the cluster of raspberry Pis. There was no load test to understand the efficiency of the architecture. | Kubernetes is being used in the architecture of this paper but it is not leveraging any security benefits from the Kubernetes. | It’s just using Raspberry Pis with Kubernetes running on them but 20 of them for the research makes the experiment expensive. |
| [15] | This research aimed to test the lightweight Kubernetes solutions for IoT devices. The idea was to perform a formal comparison between them. Efficiency was looked at the best distribution which can be used. | The study utilized Azure VMs to test their architecture. The security associated with the cloud resources is better than doing so on the IoT devices. | Although cloud resources are better than IoT devices, they come along with costs. They prove to be way more costly if not configured properly. |
| Our | When it comes to efficiency, the Kubernetes deployment mechanism and distribution of workloads is state-of-the-art. It distributes the workloads efficiently with the distribution of processing between different pods. While considering use of AI IoT devices, the performance of hardware given its GPU provides enhanced efficiency. | In terms of security, all of the data processing is performed on the AI-IoT device, which is not exposed to the external world. They function in their own private subnet of the edge network. Kubernetes ensures the segregation of the network packets are maintained between the devices from the external world. | The AI-IoT device such as the Nvidia Jetson Nano are a bit expensive as compared to the costs of the Raspberry pi but the abilities they provide as seen in this particular research showcases their effectiveness for the price. Google’s Coral device can also be an alternative which can be used along with raspberry Pis. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kumari, S.; Tulshyan, V.; Tewari, H. Cyber Security on the Edge: Efficient Enabling of Machine Learning on IoT Devices. Information 2024, 15, 126. https://doi.org/10.3390/info15030126
Kumari S, Tulshyan V, Tewari H. Cyber Security on the Edge: Efficient Enabling of Machine Learning on IoT Devices. Information. 2024; 15(3):126. https://doi.org/10.3390/info15030126
Chicago/Turabian StyleKumari, Swati, Vatsal Tulshyan, and Hitesh Tewari. 2024. "Cyber Security on the Edge: Efficient Enabling of Machine Learning on IoT Devices" Information 15, no. 3: 126. https://doi.org/10.3390/info15030126
APA StyleKumari, S., Tulshyan, V., & Tewari, H. (2024). Cyber Security on the Edge: Efficient Enabling of Machine Learning on IoT Devices. Information, 15(3), 126. https://doi.org/10.3390/info15030126