


A Comparison of Neural-Network-Based Intrusion Detection against Signature-Based Detection in IoT Networks


Abstract
1. Introduction
- Attacks that target an IoT device;
- Attacks that originate from an IoT device.
- How does a state-of-the-art DLIDS perform in comparison to a signature-based IDS?
- How well is the DLIDS able to generalize and to perfom in a replicated environment using slightly modified attacks?
- Evaluation of a DLIDS in a replicated environment using the same attacks with and without slight modifications in the attack pattern. Furthermore, we evaluate the DLIDS against an unseen attack, demystifying the claim of zero-day attack detection.
- Demonstration of the shortcomings of existing training sets and proposing new validation datasets (MQTT-IoT-IDS2020-UP and variations).
- A discussion of the weaknesses of current applied performance metrics in the context of IDS, (addressing P7—Inappropriate Performance Measures from [19]).
- We give an overview of IoT datasets to support IDS researchers in selecting a suitable dataset for their research.
2. Related Work
2.1. Discussion of Machine Learning Pitfalls
- P1
- Sampling bias, when the datasets used for training and testing do not represent the network traffic (see Section 3).
- P6
- Inappropriate baseline, when new approaches are only compared against very similar approaches, but not against the state of the art (see Section 5.5).
- P7
- Inappropriate performance measures: In the context of NIDS, just one performance metric, like accuracy, is insufficient. Precision is important since a high false positive rate would render the system useless. Further, in the context of NIDS, binary and multiclass classification are both applied. The detailed definition of the performance metrics for the multiclass classification problem is often missing (see Section 5.7).
- P8
- Base rate fallacy: This is similar to P7, but accounts for misleading interpretation of results.
2.2. DLIDS
3. Discussion of IDS Benchmarks
3.1. Popular IDS Benchmarks
3.2. Benchmarks Specific to the IoT
- DoS: A DoS attack against the MQTT broker by saturating it with a large number of messages per second and new connections.
- Man in the middle (MitM): The attack uses the Kali Linux distribution and the Ettercap tool to intercept the communication between a sensor and the broker to modify sensor data.
- Intrusion (MQTT topic enumeration): Here, the attacker contacts the broker on its well-known port (1883) and checks whether the broker returns all registered MQTT topics.
3.3. Class Imbalance
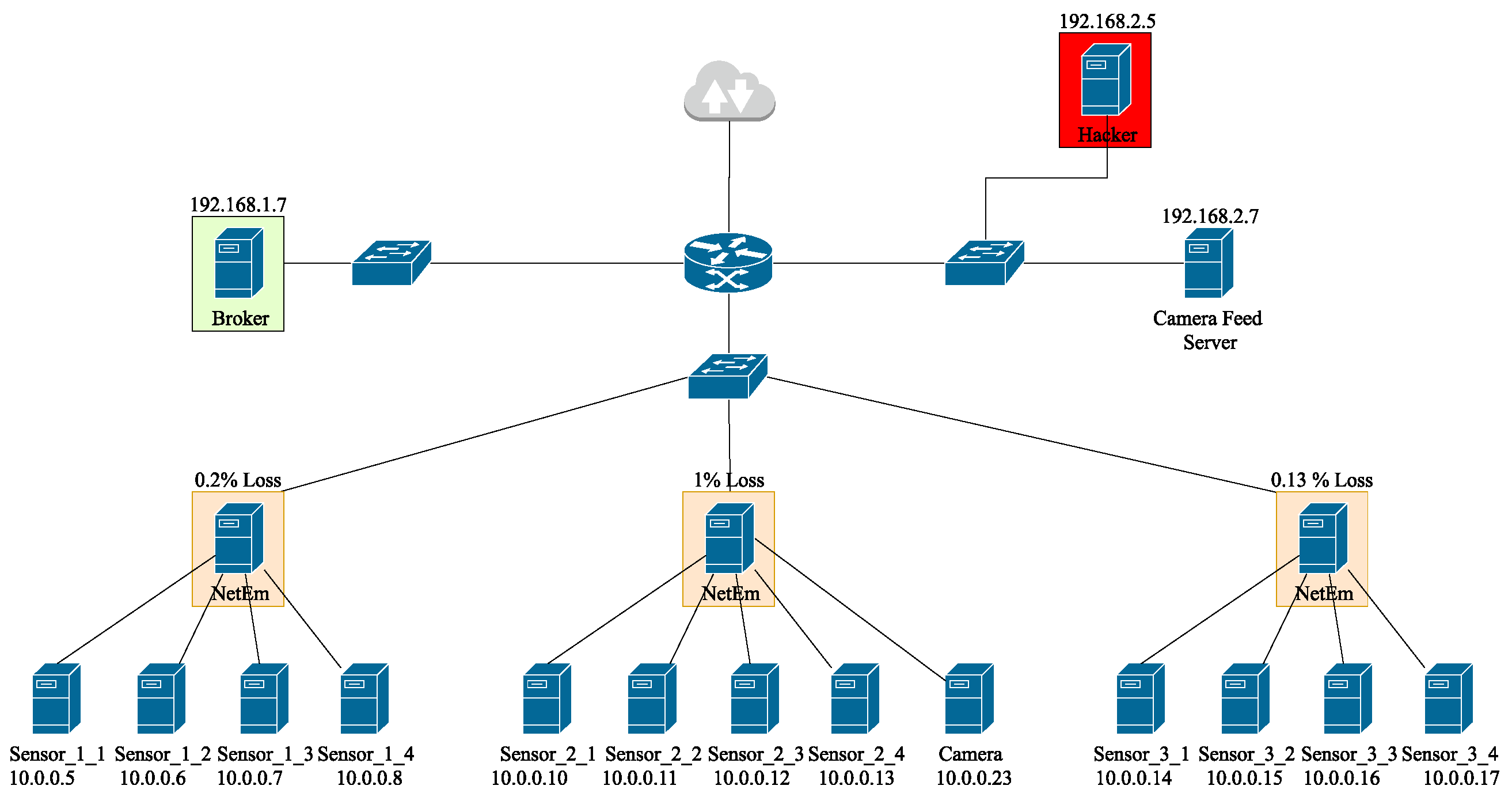
4. Reproducibility Study
4.1. Selection of Representative DNN-IDS
- Only deep learning models are considered.
- The model is trained for IoT environments, i.e., the training set includes MQTT-specific attacks.
- We want to compare the selected model against a proper baseline, which is a signature-based intrusion detection system. These perform multiclass classification. For example, a Snort rule is configured with so-called rule messages that describe the detected attack. Hence, for a fair comparison, we consider only models that are also capable of multiclass classification.
- We restrict ourselves to recent publications that offer the best performance as far as we are aware.
4.2. Detection Metrics
4.3. Replication Problems
4.4. Replication Results
5. Evaluation
5.1. First Experiment: Replication of Dataset
5.2. Second Experiment: New Scan Variants
5.3. Third Experiment: Sensor Updates
5.4. Fourth Experiment: Zero-Day Attacks
5.5. Comparison against Snort as Baseline
5.5.1. Snort Configuration
| Listing 1. Snort rule to detect too many SSH authentication attempts. |
| alert tcp any any -> $HOME_NET 22 |
| ( |
| flow: established,to_server; |
| content: "SSH", nocase, offset 0, depth 4; |
| detection_filter: track by_src, count 30, seconds 60; |
| msg: "ssh bruteforce"; sid:1000002 |
| ) |
| Listing 2. Snort rule to detect too many MQTT authentication attempts. |
| alert tcp any 1883 -> any any |
| ( |
| flow: established,to_client; |
| content: "|20|", offset 0, depth 1; |
| content: "|05|", offset 3, depth 1; |
| detection_filter: track by_src, count 30, seconds 60; |
| msg: "MQTT Bruteforce"; sid:1000001; |
| ) |
5.5.2. Results for MQTT-IoT-IDS2020-UP
5.5.3. Results for Traffic Variations
5.6. Discussion
5.7. Discussion of Performance Metrics
5.8. Usability
5.9. Analysis with Flow Data
5.10. Limitations and Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
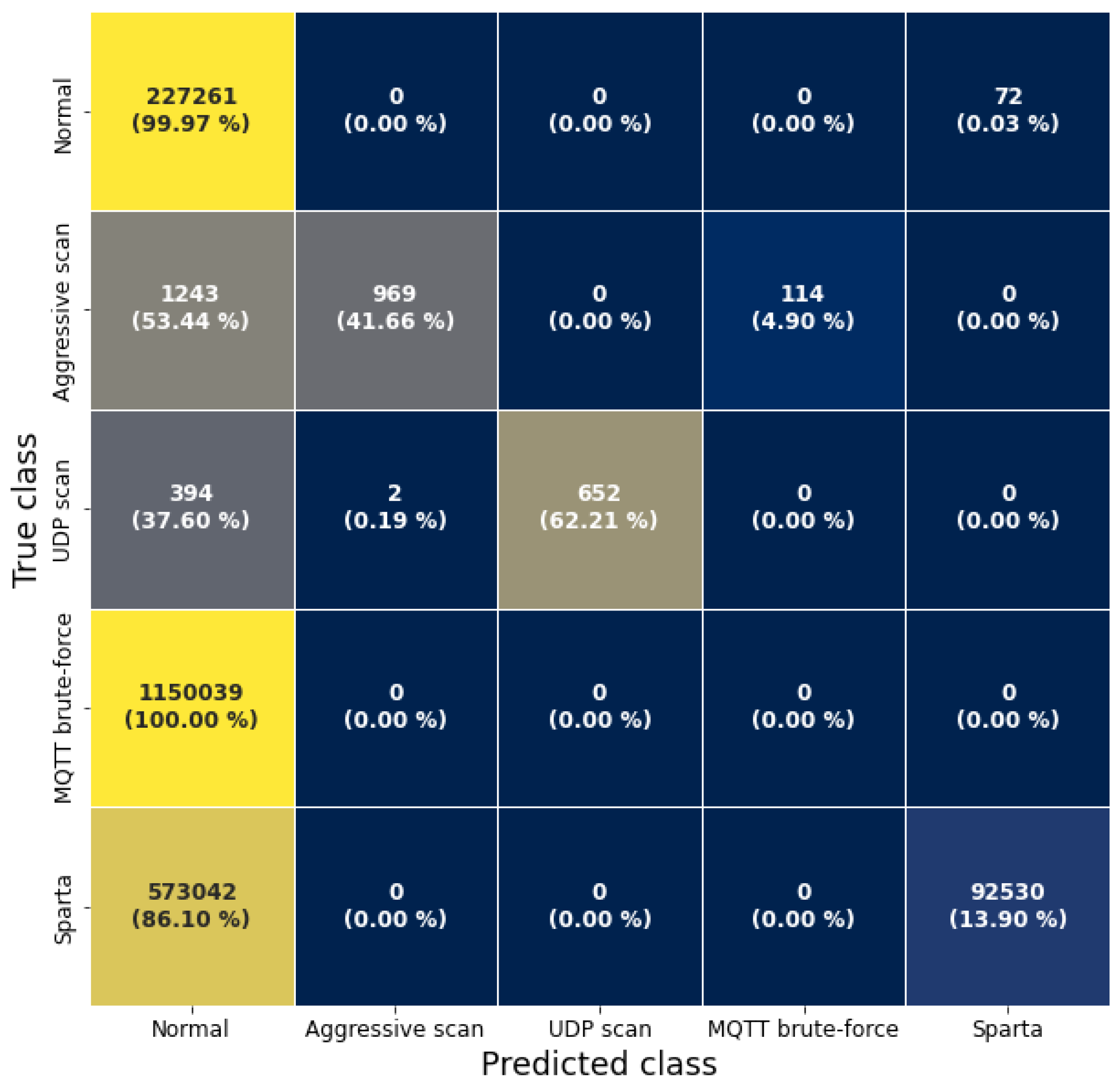
Appendix A. Confusion Matrices




Appendix B. Binary Classification

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | MQTT-IoT-IDS2020 | Replicated Training Set | MQTT-IoT-IDS2020-UP |
|---|---|---|---|
| Normal | 7.21% | 82.04% | 11.11% |
| Scan_A | 0.13% | 1.44% | 0.11% |
| Scan_SU | 0.07% | 0.79% | 0.05% |
| MQTT Brute-force | 31.17% | 7.83% | 56.20% |
| Sparta | 61.42% | 7.90% | 32.53% |
| Model | Dataset | Accuracy | Precision | Recall | Score |
|---|---|---|---|---|---|
| Adopted scaling | MQTT-IoT-IDS2020 | 99.99 | 100.00 | 99.99 | 99.99 |
| MQTT-IoT-IDS2020-UP | 98.89 | 98.77 | 99.99 | 99.38 | |
| Without IP and | MQTT-IoT-IDS2020 | 93.73 | 100.00 | 65.07 | 78.84 |
| timestamps | MQTT-IoT-IDS2020-UP | 54.59 | 99.30 | 49.26 | 65.85 |
| Model | Dataset | Accuracy | Precision | Recall | Score |
|---|---|---|---|---|---|
| Adopted scaling | Original scan | 100.00 | 100.00 | 100.00 | 100.00 |
| UP scan | 99.63 | 99.74 | 99.10 | 99.42 | |
| Full Port Scan | 99.99 | 99.99 | 100.00 | 99.99 | |
| Sensor | 99.90 | 99.66 | 99.95 | 99.80 | |
| Without IP and timestamps | Original scan | 100.00 | 100.00 | 100.00 | 100.00 |
| UP scan | 99.86 | 99.57 | 100.00 | 99.79 | |
| Full Port Scan | 99.99 | 99.99 | 99.99 | 99.99 | |
| Sensor | 99.75 | 99.08 | 100.00 | 99.54 |
References
- Alaiz-Moreton, H.; Aveleira-Mata, J.; Ondicol-Garcia, J.; Muñoz-Castañeda, A.L.; García, I.; Benavides, C. Multiclass Classification Procedure for Detecting Attacks on MQTT-IoT Protocol. Complexity 2019, 2019, 6516253. [Google Scholar] [CrossRef]
- Ciklabakkal, E.; Donmez, A.; Erdemir, M.; Suren, E.; Yilmaz, M.K.; Angin, P. ARTEMIS: An Intrusion Detection System for MQTT Attacks in Internet of Things. In Proceedings of the 2019 38th Symposium on Reliable Distributed Systems (SRDS), Lyon, France, 1–4 October 2019; pp. 369–371. [Google Scholar]
- Hindy, H.; Bayne, E.; Bures, M.; Atkinson, R.; Tachtatzis, C.; Bellekens, X. Machine Learning Based IoT Intrusion Detection System: An MQTT Case Study (MQTT-IoT-IDS2020 Dataset). In INC 2020: Selected Papers from the 12th International Networking Conference; Lecture Notes in Networks and Systems; Ghita, B., Shiaeles, S., Eds.; Springer: Cham, Switzerland, 2021; Volume 180, pp. 73–84. [Google Scholar]
- Ge, M.; Fu, X.; Syed, N.; Baig, Z.; Teo, G.; Robles-Kelly, A. Deep Learning-Based Intrusion Detection for IoT Networks. In Proceedings of the 2019 IEEE 24th Pacific Rim International Symposium on Dependable Computing (PRDC), Kyoto, Japan, 1–3 December 2019; pp. 256–265. [Google Scholar]
- Khan, M.A.; Khan, M.A.; Jan, S.U.; Ahmad, J.; Jamal, S.S.; Shah, A.A.; Pitropakis, N.; Buchanan, W.J. A Deep Learning-Based Intrusion Detection System for MQTT Enabled IoT. Sensors 2021, 21, 7016. [Google Scholar] [CrossRef] [PubMed]
- Mosaiyebzadeh, F.; Araujo Rodriguez, L.G.; Macêdo Batista, D.; Hirata, R. A Network Intrusion Detection System using Deep Learning against MQTT Attacks in IoT. In Proceedings of the 2021 IEEE Latin-American Conference on Communications (LATINCOM), Santo Domingo, Dominican Republic, 17–19 November 2021; pp. 1–6. [Google Scholar]
- Ullah, I.; Ullah, A.; Sajjad, M. Towards a Hybrid Deep Learning Model for Anomalous Activities Detection in Internet of Things Networks. IoT 2021, 2, 428–448. [Google Scholar] [CrossRef]
- Gray, N.; Dietz, K.; Seufert, M.; Hossfeld, T. High Performance Network Metadata Extraction Using P4 for ML-based Intrusion Detection Systems. In Proceedings of the 2021 IEEE 22nd International Conference on High Performance Switching and Routing (HPSR), Paris, France, 7–10 June 2021; pp. 1–7. [Google Scholar] [CrossRef]
- Engelen, G.; Rimmer, V.; Joosen, W. Troubleshooting an Intrusion Detection Dataset: The CICIDS2017 Case Study. In Proceedings of the 2021 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 27 May 2021; pp. 7–12. [Google Scholar] [CrossRef]
- Kamaldeep; Malik, M.; Dutta, M. Feature Engineering and Machine Learning Framework for DDoS Attack Detection in the Standardized Internet of Things. IEEE Internet Things J. 2023, 10, 8658–8669. [Google Scholar] [CrossRef]
- Cholakoska, A.; Gjoreski, H.; Rakovic, V.; Denkovski, D.; Kalendar, M.; Pfitzner, B.; Arnrich, B. Federated Learning for Network Intrusion Detection in Ambient Assisted Living Environments. IEEE Internet Comput. 2023, 27, 15–22. [Google Scholar] [CrossRef]
- Sinha, S. State of IoT 2023: Number of Connected IoT Devices Growing 16% to 16.7 Billion Globally. Available online: https://iot-analytics.com/number-connected-iot-devices/ (accessed on 27 September 2023).
- Kolias, C.; Kambourakis, G.; Stavrou, A.; Voas, J. DDoS in the IoT: Mirai and Other Botnets. Computer 2017, 50, 80–84. [Google Scholar] [CrossRef]
- Kumari, P.; Jain, A.K. A comprehensive study of DDoS attacks over IoT network and their countermeasures. Comput. Secur. 2023, 127, 103096. [Google Scholar] [CrossRef]
- BSI. Grundlagen: 1. IDS-Grundlagen und Aktueller Stand. Available online: https://www.bsi.bund.de/DE/Service-Navi/Publikationen/Studien/IDS02/gr1_htm.html?nn=132646 (accessed on 19 August 2023).
- Dini, P.; Elhanashi, A.; Begni, A.; Saponara, S.; Zheng, Q.; Gasmi, K. Overview on Intrusion Detection Systems Design Exploiting Machine Learning for Networking Cybersecurity. Appl. Sci. 2023, 13, 7507. [Google Scholar] [CrossRef]
- Mliki, H.; Kaceam, A.H.; Chaari, L. A Comprehensive Survey on Intrusion Detection based Machine Learning for IoT Networks. EAI Endorsed Trans. Secur. Saf. 2021, 8, e3. [Google Scholar] [CrossRef]
- IBM. What Are Neural Networks? Available online: https://www.ibm.com/topics/neural-networks (accessed on 20 November 2023).
- Arp, D.; Quiring, E.; Pendlebury, F.; Warnecke, A.; Pierazzi, F.; Wressnegger, C.; Cavallaro, L.; Rieck, K. Dos and Don’ts of Machine Learning in Computer Security. In Proceedings of the USENIX Security Symposium, Boston, MA, USA, 12–14 August 2020. [Google Scholar]
- Snort. Snort 3 Rule Writing Guide. Available online: https://docs.snort.org/ (accessed on 19 November 2023).
- The Open Information Security Foundation. Suricata. Available online: https://suricata.io/ (accessed on 19 November 2023).
- Project, T.Z. The Zeek Network Security Monitor. Available online: https://zeek.org/ (accessed on 19 November 2023).
- Threats, E. Emerging Threats Ruleset. Available online: https://community.emergingthreats.net/ (accessed on 20 November 2023).
- Cahyo, A.N.; Kartika Sari, A.; Riasetiawan, M. Comparison of Hybrid Intrusion Detection System. In Proceedings of the 2020 12th International Conference on Information Technology and Electrical Engineering (ICITEE), Yogyakarta, Indonesia, 6–8 October 2020; pp. 92–97. [Google Scholar] [CrossRef]
- Leevy, J.; Khoshgoftaar, T. A survey and analysis of intrusion detection models based on CSE-CIC-IDS2018 Big Data. J. Big Data 2020, 7, 104. [Google Scholar] [CrossRef]
- Ceschin, F.; Botacin, M.; Bifet, A.; Pfahringer, B.; Oliveira, L.S.; Gomes, H.M.; Grégio, A. Machine Learning (In) Security: A Stream of Problems. Digit. Threat. 2023. [Google Scholar] [CrossRef]
- Dambra, S.; Han, Y.; Aonzo, S.; Kotzias, P.; Vitale, A.; Caballero, J.; Balzarotti, D.; Bilge, L. Decoding the Secrets of Machine Learning in Windows Malware Classification: A Deep Dive into Datasets, Feature Extraction, and Model Performance. arXiv 2023, arXiv:2307.14657. [Google Scholar]
- Venturi, A.; Zanasi, C.; Marchetti, M.; Colajanni, M. Robustness Evaluation of Network Intrusion Detection Systems based on Sequential Machine Learning. In Proceedings of the 2022 IEEE 21st International Symposium on Network Computing and Applications (NCA), Boston, MA, USA, 14–16 December 2022; Volume 21, pp. 235–242. [Google Scholar] [CrossRef]
- Aldhaheri, S.; Alhuzali, A. SGAN-IDS: Self-Attention-Based Generative Adversarial Network against Intrusion Detection Systems. Sensors 2023, 23, 7796. [Google Scholar] [CrossRef]
- Zola, F.; Bruse, J.L.; Galar, M. Temporal Analysis of Distribution Shifts in Malware Classification for Digital Forensics. In Proceedings of the 2023 IEEE European Symposium on Security and Privacy Workshops (EuroS&PW), Delft, The Netherlands, 3–7 July 2023; pp. 439–450. [Google Scholar] [CrossRef]
- Apruzzese, G.; Andreolini, M.; Marchetti, M.; Venturi, A.; Colajanni, M. Deep Reinforcement Adversarial Learning Against Botnet Evasion Attacks. IEEE Trans. Netw. Serv. Manag. 2020, 17, 1975–1987. [Google Scholar] [CrossRef]
- Sharafaldin, I.; Lashkari, A.H.; Ghorbani, A.A. Toward Generating a New Intrusion Detection Dataset and Intrusion Traffic Characterization. In Proceedings of the 4th International Conference on Information Systems Security and Privacy, ICISSP 2018, Funchal, Portugal, 22–24 January 2018; Mori, P., Furnell, S., Camp, O., Eds.; SciTePress: Setubal, Portugal, 2018; pp. 108–116. [Google Scholar] [CrossRef]
- Tidjon, L.N.; Khomh, F. Threat Assessment in Machine Learning based Systems. arXiv 2022, arXiv:2207.00091. [Google Scholar]
- OWASP. OWASP Machine Learning Security Top Ten. Available online: https://owasp.org/www-project-machine-learning-security-top-10/ (accessed on 21 November 2023).
- OWASP. OWASP AI Security and Privacy Guide. Available online: https://owasp.org/www-project-ai-security-and-privacy-guide/ (accessed on 21 November 2023).
- Vaccari, I.; Chiola, G.; Aiello, M.; Mongelli, M.; Cambiaso, E. MQTTset, a New Dataset for Machine Learning Techniques on MQTT. Sensors 2020, 20, 6578. [Google Scholar] [CrossRef] [PubMed]
- Aveleira, J. MQTT_UAD: MQTT Under Attack Dataset. A Public Dataset for the Detection of Attacks in IoT Networks Using MQTT. Available online: https://joseaveleira.es/dataset/ (accessed on 20 November 2023).
- Hindy, H.; Tachtatzis, C.; Atkinson, R.; Bayne, E.; Bellekens, X. MQTT-IoT-IDS2020: MQTT Internet of Things Intrusion Detection Dataset. IEEE Dataport 2020. [Google Scholar] [CrossRef]
- Koroniotis, N.; Moustafa, N.; Sitnikova, E.; Turnbull, B. Towards the development of realistic botnet dataset in the Internet of Things for network forensic analytics: Bot-IoT dataset. Future Gener. Comput. Syst. 2019, 100, 779–796. [Google Scholar] [CrossRef]
- Koroniotis, N.; Moustafa, N.; Sitnikova, E.; Turnbull, B. The Bot-IoT Dataset. Available online: https://research.unsw.edu.au/projects/bot-iot-dataset (accessed on 5 October 2023).
- Ullah, I.; Mahmoud, Q.H. A Technique for Generating a Botnet Dataset for Anomalous Activity Detection in IoT Networks. In Proceedings of the 2020 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Toronto, ON, Canada, 11–14 October 2020; pp. 134–140. [Google Scholar] [CrossRef]
- Ullah, I.; Mahmoud, Q.H. IoT Network Intrusion Datasets. Available online: https://sites.google.com/view/iotdataset1 (accessed on 18 December 2023).
- Garcia, S.; Parmisano, A.; Erquiaga, M.J. IoT-23: A Labeled Dataset with Malicious and Benign IoT Network Traffic (Version 1.0.0). 2020. Available online: https://www.stratosphereips.org/datasets-iot23 (accessed on 18 December 2023).
- Vaccari, I.; Chiola, G.; Aiello, M.; Mongelli, M.; Cambiaso, E. MQTTset. Available online: https://www.kaggle.com/datasets/cnrieiit/mqttset (accessed on 5 January 2024).
- McHugh, J. Testing Intrusion Detection Systems: A Critique of the 1998 and 1999 DARPA Intrusion Detection System Evaluations as Performed by Lincoln Laboratory. ACM Trans. Inf. Syst. Secur. 2000, 3, 262–294. [Google Scholar] [CrossRef]
- Nehinbe, J.O. A critical evaluation of datasets for investigating IDSs and IPSs researches. In Proceedings of the 2011 IEEE 10th International Conference on Cybernetic Intelligent Systems (CIS), London, UK, 1–2 September 2011; pp. 92–97. [Google Scholar] [CrossRef]
- Hindy, H.; Brosset, D.; Bayne, E.; Seeam, A.K.; Tachtatzis, C.; Atkinson, R.; Bellekens, X. A Taxonomy of Network Threats and the Effect of Current Datasets on Intrusion Detection Systems. IEEE Access 2020, 8, 104650–104675. [Google Scholar] [CrossRef]
- Thakkar, A.; Lohiya, R. A Review of the Advancement in Intrusion Detection Datasets. Procedia Comput. Sci. 2020, 167, 636–645. [Google Scholar] [CrossRef]
- Rosay, A.; Carlier, F.; Leroux, P. MLP4NIDS: An Efficient MLP-Based Network Intrusion Detection for CICIDS2017 Dataset. In MLN 2019: Machine Learning for Networking; Boumerdassi, S., Renault, É., Mühlethaler, P., Eds.; Springer: Cham, Switzerland, 2020; pp. 240–254. [Google Scholar]
- Kurniabudi; Stiawan, D.; Darmawijoyo; Bin Idris, M.Y.; Bamhdi, A.M.; Budiarto, R. CICIDS-2017 Dataset Feature Analysis With Information Gain for Anomaly Detection. IEEE Access 2020, 8, 132911–132921. [Google Scholar] [CrossRef]
- Holland, J.; Schmitt, P.; Feamster, N.; Mittal, P. New Directions in Automated Traffic Analysis. In Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security—CCS’21, New York, NY, USA, 9–13 November 2021; pp. 3366–3383. [Google Scholar] [CrossRef]
- Panigrahi, R.; Borah, S. A detailed analysis of CICIDS2017 dataset for designing Intrusion Detection Systems. Int. J. Eng. Technol. 2018, 7, 479–482. [Google Scholar]
- OASIS Open. MQTT Version 5.0; OASIS Standard; OASIS Open: Woburn, MA, USA, 2019. [Google Scholar]
- Neto, E.C.P.; Dadkhah, S.; Ferreira, R.; Zohourian, A.; Lu, R.; Ghorbani, A.A. CICIoT2023: A Real-Time Dataset and Benchmark for Large-Scale Attacks in IoT Environment. Sensors 2023, 23, 5941. [Google Scholar] [CrossRef]
- Palsson, K. Malaria Toolkit. 2019. Available online: https://github.com/etactica/mqtt-malaria (accessed on 28 January 2024).
- Open JS Foundation & Contributors. Node-RED. Available online: https://nodered.org (accessed on 5 January 2024).
- Jacobs, A.S.; Beltiukov, R.; Willinger, W.; Ferreira, R.A.; Gupta, A.; Granville, L.Z. AI/ML for Network Security: The Emperor Has No Clothes. In Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security—CCS’22, New York, NY, USA, 7–11 November 2022; pp. 1537–1551. [Google Scholar] [CrossRef]
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for scientific data management and stewardship. J. Sci. Data 2016, 3, 160018. [Google Scholar] [CrossRef]
- Schrötter, M. Replication DLIDS Khan. Available online: https://gitup.uni-potsdam.de/maxschro/replication-dlids-khan (accessed on 5 January 2024).
- Raj Kumar, P.A.; Selvakumar, S. Distributed denial of service attack detection using an ensemble of neural classifier. Comput. Commun. 2011, 34, 1328–1341. [Google Scholar] [CrossRef]
- Ahrenholz, J.; Danilov, C.; Henderson, T.R.; Kim, J.H. CORE: A real-time network emulator. In Proceedings of the MILCOM 2008—2008 IEEE Military Communications Conference, San Diego, CA, USA, 16–19 November 2008; pp. 1–7. [Google Scholar] [CrossRef]
- Sahlmann, K.; Clemens, V.; Nowak, M.; Schnor, B. MUP: Simplifying Secure Over-The-Air Update with MQTT for Constrained IoT Devices. J. Sens. 2020, 21, 10. [Google Scholar] [CrossRef]
- Ahmad, R.; Alsmadi, I.; Alhamdani, W.; Tawalbeh, L. Zero-day attack detection: A systematic literature review. Artif. Intell. Rev. 2023, 56, 10733–10811. [Google Scholar] [CrossRef]
- Gharib, M.; Mohammadi, B.; Dastgerdi, S.H.; Sabokrou, M. AutoIDS: Auto-encoder Based Method for Intrusion Detection System. arXiv 2019, arXiv:1911.03306. [Google Scholar]
- Hindy, H.; Atkinson, R.; Tachtatzis, C.; Colin, J.N.; Bayne, E.; Bellekens, X. Utilising Deep Learning Techniques for Effective Zero-Day Attack Detection. Electronics 2020, 9, 1684. [Google Scholar] [CrossRef]
- Soltani, M.; Ousat, B.; Jafari Siavoshani, M.; Jahangir, A.H. An adaptable deep learning-based intrusion detection system to zero-day attacks. J. Inf. Secur. Appl. 2023, 76, 103516. [Google Scholar] [CrossRef]
- Ouiazzane, S.; Addou, M.; Barramou, F. A Suricata and Machine Learning Based Hybrid Network Intrusion Detection System. In Advances in Information, Communication and Cybersecurity; Maleh, Y., Alazab, M., Gherabi, N., Tawalbeh, L., Abd El-Latif, A.A., Eds.; Springer: Cham, Switzerland, 2022; pp. 474–485. [Google Scholar]
- Khraisat, A.; Gondal, I.; Vamplew, P.; Kamruzzaman, J. Survey of intrusion detection systems: Techniques, datasets and challenges. Cybersecurity 2019, 2, 20. [Google Scholar] [CrossRef]
- Heuse, M. THC IPv6 Attack Tool Kit. 2005. Available online: https://github.com/vanhauser-thc/thc-ipv6 (accessed on 5 January 2024).
- Schroetter, M.; Scheffler, T.; Schnor, B. Inspector for the Neighbour Discovery Protocol. Available online: https://redmine.cs.uni-potsdam.de/projects/snort3-ipv6-plugin/files (accessed on 26 January 2024).
- Schroetter, M.; Scheffler, T.; Schnor, B. Evaluation of Intrusion Detection Systems in IPv6 Networks. In Proceedings of the International Conference on Security and Cryptography (SECRYPT 2019), Prague, Czech Republic, 26–28 July 2019. [Google Scholar]
- Shamir, A.; Melamed, O.; BenShmuel, O. The Dimpled Manifold Model of Adversarial Examples in Machine Learning. arXiv 2021, arXiv:2106.10151. [Google Scholar]
| Datasets | |||||||
|---|---|---|---|---|---|---|---|
| Category | MQTT-Specific [1] | MQTT-Specific [2] | Bot-Iot [39] | MQTTset [36] | IoT-23 [43] | MQTT-IoT-IDS2020 [3] | CICIoT2023 [54] |
| Year | 2019 | 2019 | 2019 | 2020 | 2020 | 2021 | 2023 |
| Benign | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Broker DoS | ✓ | ✓ | - | ✓ | - | - | - |
| MitM | ✓ | - | - | - | - | - | ✓ |
| Topic-Enumeration | ✓ | - | - | - | - | - | - |
| MQTT BF | - | - | - | ✓ | - | ✓ | - |
| Port Scan | - | - | ✓ | - | ✓ | ✓ | ✓ |
| OS f. p. | - | - | ✓ | - | - | - | ✓ |
| Botnet DoS | - | - | ✓ | - | ✓ | - | ✓ |
| Data Theft | - | - | ✓ | - | - | - | - |
| SSH BF | - | - | - | - | - | ✓ | ✓ |
| C&C | - | - | - | - | ✓ | - | - |
| Datasets | Detection | ML-Based | Evaluation | FAIR Criteria: | ||
|---|---|---|---|---|---|---|
| Anomaly | Multi-Class | Detection Method | Baseline | Reproducibility | ||
| Khan et al., | MQTT-IoT- | ✓ | ✓ | DNN, NB, RF, kNN, | [1] | ✓ |
| 2021 [5] | IDS2020 [3] | DT, LSTM, GRU | ||||
| Alaiz-Moreton et al., | MQTT-specific | - | ✓ | DNN, XGBoost, | - | – |
| 2019 [1] | [1] | GRU, LSTM | ||||
| Ciklabakkal et al., | MQTT-specific | ✓ | - | OCSVM, RF, IF, | - | – |
| 2019 [2] | [2] | K-Means, SO_GAAL, | ||||
| Autoencoder | ||||||
| Hindy et al., | MQTT-IoT- | - | ✓ | LR, NB, kNN, | - | ✓ |
| 2021 [3] | IDS2020 [3] | SVM, DT, RF | ||||
| Ge et al., | Bot-IoT | ✓ | ✓ | DNN | SVM [60] | – |
| 2019 [4] | [39] | |||||
| Mosaiyebzadeh et al., | MQTT-IoT- | - | ✓ | DNN, LSTM, | DT [3] | ✓ |
| 2021 [6] | IDS2020 [3] | CNN-RNN-LSTM | ||||
| Ullah et al., | MQTT-IoT- | ✓ | ✓ | CNN, GRU | [3] | – |
| 2021 [7] | IDS2020 [3], | and more | ||||
| BoT-IoT and IoT | ||||||
| Network Intrusion [42], | ||||||
| IoT-23 [43] | ||||||
| Class | MQTT-IoT-IDS2020 [38] | Khan et al. [5] | Replicated Result |
|---|---|---|---|
| Normal | 7.21% | 72.62% | 82.04% |
| Scan_A | 0.13% | 2.42% | 1.44% |
| Scan_SU | 0.07% | 1.34% | 0.79% |
| MQTT Brute-force | 31.17% | 7.83% | 7.83% |
| Sparta | 61.42% | 7.90% | 7.90% |
| Model | Accuracy | Precision | Recall | Score |
|---|---|---|---|---|
| Khan et al. [5] | 90.798 | 89.4118 | 81.640 | 85.346 |
| Replicated model | 82.04 | 16.41 | 20.00 | 18.03 |
| With adopted scaling | 99.69 | 98.67 | 99.72 | 99.14 |
| Without IP and timestamps | 93.04 | 97.54 | 92.10 | 83.91 |
| Model | Accuracy | Precision | Recall | Score |
|---|---|---|---|---|
| Khan et al. [5] | 2.498 | 1.115 | 0.403 | 0.620 |
| Replicated model | 0.00 | 0.00 | 0.00 | 0.00 |
| With adopted scaling | 0.58 | 2.32 | 0.39 | 1.31 |
| Without IP and timestamps | 0.61 | 0.77 | 1.22 | 1.44 |
| Model | Dataset | Accuracy | Precision | Recall | Score |
|---|---|---|---|---|---|
| Adopted scaling | MQTT-IoT-IDS2020 | 99.99 | 99.99 | 99.99 | 99.99 |
| MQTT-IoT-IDS2020-UP | 98.44 | 96.38 | 70.65 | 74.34 | |
| Without IP and | MQTT-IoT-IDS2020 | 93.72 | 98.54 | 83.72 | 85.78 |
| timestamps | MQTT-IoT-IDS2020-UP | 54.52 | 74.28 | 67.90 | 60.17 |
| IP Address | Accuracy | Precision | Recall | Score |
|---|---|---|---|---|
| 192.168.2.5 | 98.44 | 96.38 | 70.65 | 74.34 |
| 192.168.2.42 | 98.44 | 96.38 | 70.65 | 74.34 |
| 37.142.89.42 | 15.71 | 62.27 | 43.55 | 36.15 |
| Model | Dataset | Accuracy | Precision | Recall | Score |
|---|---|---|---|---|---|
| Adopted scaling | Original scan | 100.00 | 100.00 | 100.00 | 100.00 |
| UP scan | 68.66 | 88.46 | 1.98 | 3.87 | |
| Full Port Scan | 3.44 | 0.00 | 0.00 | 0.00 | |
| Sensor | 99.79 | 99.66 | 99.56 | 99.61 | |
| Without IP and timestamps | Original scan | 100.00 | 100.00 | 100.00 | 100.00 |
| UP scan | 83.66 | 99.13 | 49.18 | 65.75 | |
| Full Port Scan | 86.41 | 99.99 | 85.93 | 92.43 | |
| Sensor | 88.46 | 98.40 | 57.39 | 72.50 |
| Model | Dataset | Accuracy | Precision | Recall | Score |
|---|---|---|---|---|---|
| Adopted scaling | Original benign | 100.00 | 100.00 | 100.00 | 100.00 |
| UP benign | 90.05 | 100.00 | 90.05 | 94.76 | |
| MUP | 99.89 | 100.00 | 99.89 | 99.94 | |
| Without IP and timestamps | Original benign | 100.00 | 100.00 | 100.00 | 100.00 |
| UP benign | 97.21 | 100.00 | 97.21 | 98.59 | |
| MUP | 99.71 | 100.00 | 99.71 | 99.86 |
| Model | Attack | Accuracy | Precision | Recall | Score |
|---|---|---|---|---|---|
| Adopted scaling | DoS New IPv6 | 81.45 | 0.00 | 0.00 | 0.00 |
| Without IP and timestamps | DoS New IPv6 | 89.02 | 0.00 | 0.00 | 0.00 |
| Model | Data | Accuracy | Precision | Recall | Score |
|---|---|---|---|---|---|
| Snort | Normal | 99.81 | 99.81 | 100.00 | 99.90 |
| Aggressive Scan | 96.81 | 100.00 | 96.81 | 98.38 | |
| UDP Scan | 83.77 | 100.00 | 83.77 | 91.17 | |
| MQTT Brute-force | 99.99 | 100.00 | 99.99 | 99.99 | |
| Sparta | 99.91 | 100.00 | 99.91 | 99.96 | |
| Without IP and timestamps | Normal | 19.21 | 19.32 | 97.21 | 32.23 |
| Aggressive Scan | 37.71 | 61.77 | 49.18 | 54.76 | |
| UDP Scan | 68.60 | 91.33 | 73.38 | 81.38 | |
| MQTT Brute-force | 19.75 | 100.00 | 19.75 | 32.98 | |
| Sparta | 98.96 | 98.96 | 100.00 | 99.48 |
| Model | Data | Accuracy | Precision | Recall | Score |
|---|---|---|---|---|---|
| Snort | Sensor | 99.62 | 100.00 | 98.53 | 99.26 |
| Full Port Scan | 99.98 | 100.00 | 99.98 | 99.99 | |
| Sparta Slow | 96.67 | 100.00 | 95.33 | 97.61 | |
| Sparta Fast | 96.26 | 100.00 | 94.88 | 97.37 | |
| DoS New IPv6 | 100.00 | 100.00 | 100.00 | 100.00 | |
| MUP | 100.00 | 100.00 | 100.00 | 100.00 | |
| Without IP and timestamps | Sensor | 88.46 | 98.40 | 57.39 | 72.50 |
| Full Port Scan | 86.41 | 99.99 | 85.93 | 92.43 | |
| Sparta Slow | 99.77 | 98.50 | 100.00 | 99.24 | |
| Sparta Fast | 99.98 | 99.98 | 100.00 | 99.99 | |
| Dos New IPv6 | 89.02 | 0.00 | 0.00 | 0.00 | |
| MUP | 99.71 | 100.00 | 99.71 | 99.86 |
| Model/Dataset | Characteristic | Accuracy | Precision | Recall | Score |
|---|---|---|---|---|---|
| Khan et al. [5] | uni-flow | 97.08 | 94.76 | 86.44 | 90.61 |
| Bi-flow | 98.13 | 95.11 | 86.72 | 90.72 | |
| MQTT-IoT-IDS2020 | uni-flow | 99.82 | 99.94 | 99.35 | 99.63 |
| Bi-flow | 99.76 | 99.92 | 99.25 | 99.56 | |
| MQTT-IoT-IDS2020-UP | uni-flow | 7.77 | 58.99 | 58.00 | 39.72 |
| Bi-flow | 45.32 | 56.05 | 66.82 | 50.91 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Schrötter, M.; Niemann, A.; Schnor, B. A Comparison of Neural-Network-Based Intrusion Detection against Signature-Based Detection in IoT Networks. Information 2024, 15, 164. https://doi.org/10.3390/info15030164
Schrötter M, Niemann A, Schnor B. A Comparison of Neural-Network-Based Intrusion Detection against Signature-Based Detection in IoT Networks. Information. 2024; 15(3):164. https://doi.org/10.3390/info15030164
Chicago/Turabian StyleSchrötter, Max, Andreas Niemann, and Bettina Schnor. 2024. "A Comparison of Neural-Network-Based Intrusion Detection against Signature-Based Detection in IoT Networks" Information 15, no. 3: 164. https://doi.org/10.3390/info15030164
APA StyleSchrötter, M., Niemann, A., & Schnor, B. (2024). A Comparison of Neural-Network-Based Intrusion Detection against Signature-Based Detection in IoT Networks. Information, 15(3), 164. https://doi.org/10.3390/info15030164