1. Introduction
The last decade has witnessed a profound transformation in communication, largely due to the emergence of social networks. Digital platforms have greatly changed human interactions globally and on a systemic level, impacting various aspects of life such as personal, work, social, educational, and political domains. Previously controlled by traditional media and agencies, the flow of information and knowledge is now accessible to the entire population, allowing anyone to publish content or express opinions.
In this context, tools for analyzing social media are incredibly useful. In fact, they provide valuable insights and actionable data that businesses can leverage to improve their efficiency and drive business growth in today’s digital landscape. Social media analysis involves the use of various techniques to extract insights, trends, and patterns from social media data [
1,
2,
3,
4]. Text mining and Natural Language Processing (NLP) techniques are used to analyze textual data from social media posts, comments, and messages. This includes tasks such as sentiment analysis, topic modeling, named entity recognition, and keyword extraction. Sentiment analysis involves determining the sentiment or emotional tone expressed in social media content. This technique classifies text as positive, negative, or neutral, enabling businesses to understand customer sentiment toward their brand, products, or services [
5]. Topic modeling techniques, such as Latent Dirichlet Allocation (LDA) [
6,
7] or Non-Negative Matrix Factorization (NMF) [
8,
9], are used to identify latent topics or themes in social media discussions. This helps businesses understand the main topics of conversation and emerging trends within their industry or target audience.
The use of an ontology enhances the efficiency of analyzing and retrieving unstructured content in social media data [
10,
11] and in the medical realm [
12,
13]. An ontology can enrich the semantics of unstructured text by providing specific conceptual representations of entities, thus improving the accuracy of concept identification [
14,
15]. Interpreting relations in social media data based on a dataset-specific ontology leads to the effective discovery of inherent relationships between entities [
16]. Potential applications include improving the relevance of data retrieved from user profiles on social network websites or developing semantic search engines. However, the effective use of an ontology requires a considerable initial investment due to the development of an accurate domain-specific ontology. This has, in the past, limited the use of ontologies in social media analysis.
In this paper, we present an original approach to implementing automatic topic extraction from social media posts, based on the use of a consolidated and well-known financial domain ontology. This will result in the ability to automatically group social media posts based on the topics they actually cover. Specifically, in this work, we present an approach to identify interest groups within the Reddit community (Reddit APIs allowed us to perform automatic data extraction). Our approach consists of analyzing posts created by various Reddit users within the same subreddit tag, which are linked to financial subjects. Starting from these posts, interest groups are identified through a correlation process, deriving affinity relations with concepts defined in a well-known and widely adopted domain-specific financial ontology.
The automatic linking of posts with ontology classes could be of assistance to financial advisors in various ways: (i) selecting posts by accessing one (or more) ontology concepts; (ii) finding posts that are related to each other by an ontology concept; (iii) representing many posts using a smaller number of ontology concepts; (iv) summarizing and highlighting important aspects of posts connected to an ontology concept; and (v) quickly identifying the most important concepts that users are interested in by looking at the number of posts for each concept. Then, accordingly, financial advisors could read a selection of related posts and possibly propose financial services that may be of interest to users.
This paper is structured as follows.
Section 2 offers an overview of the works carried out in the literature.
Section 3 presents the key concepts, i.e., the ontologies and external sources used.
Section 4 explains our approach.
Section 5 presents the results of our analysis. Finally,
Section 6 presents the conclusions.
4. Proposed Approach
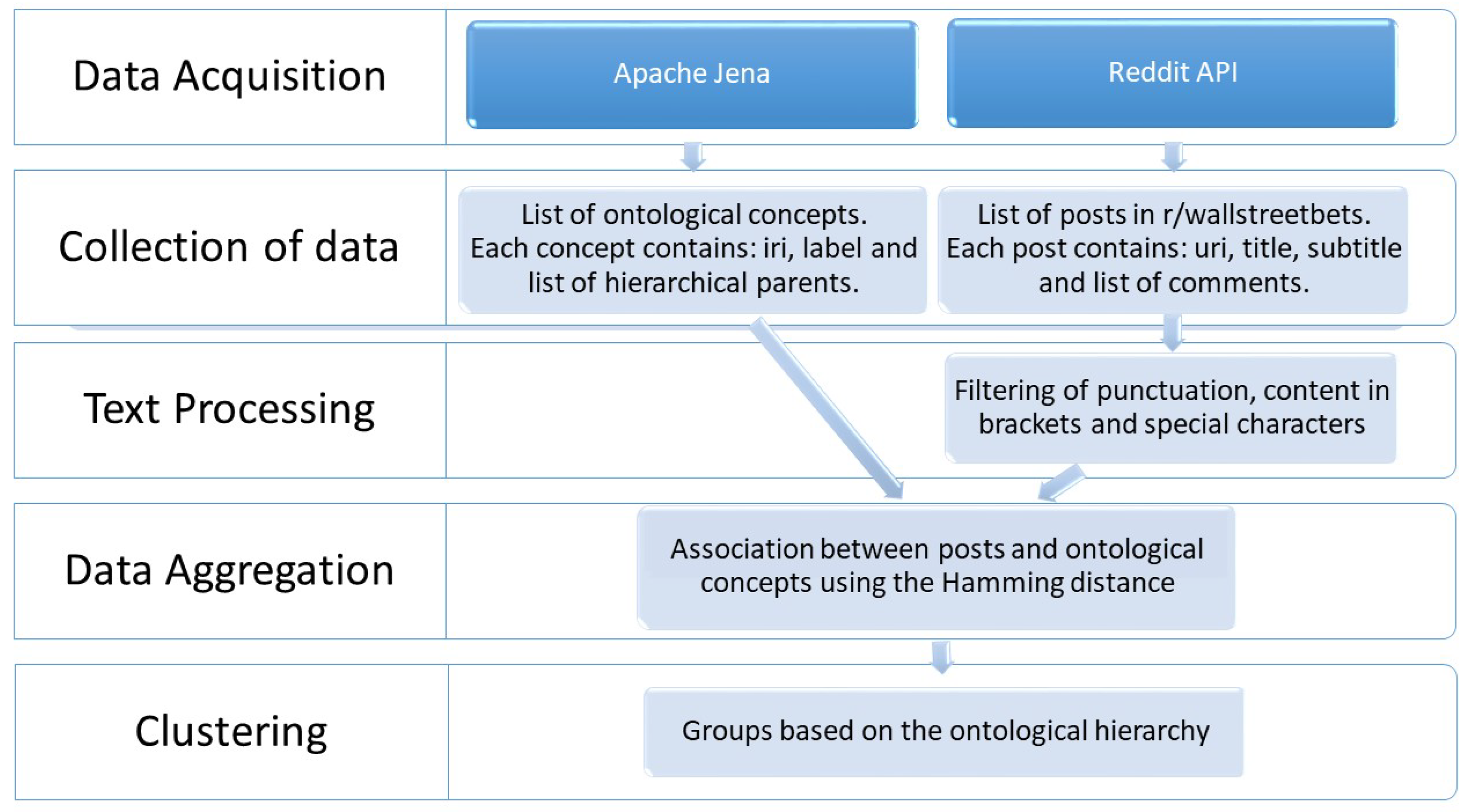
In our proposed approach, the text written in the posts is analyzed to determine their possible associations with the concepts expressed in FIBO, a set of ontologies dedicated to the financial field. The aim is to automatically identify and summarize the recurrent financial concepts that are of interest to the users.
Figure 1 gives an overview of the approach. The following processing steps are performed to organize text from posts. The association between posts and concepts is the result of step 3, whereas the summarization of recurrent concepts used in posts is the result of step 4.
The steps performed were as follows:
Using the APIs provided by the Reddit platform, the text in the posts of the selected subreddits was gathered.
The ontologies in FIBO were parsed to extract the names of the financial concepts represented in them as classes.
The text from the Reddit posts was cleaned (essentially to remove punctuation), and then the degree of connection between each post and a financial concept present in the FIBO ontologies was computed.
Posts that were connected to some FIBO classes were further analyzed to identify potential clusters, which could be determined by concepts represented in the FIBO ontologies appearing together frequently across the posts.
These steps are described in the following section.
5. Results and Discussion
In this section, we present the results of our analysis of posts extracted from the Reddit platform and connected to FIBO ontologies.
Table 1 shows a small sample of posts with titles, subtitles, and the associated labels from the ontologies. Among all the posts gathered from Reddit (over 4500) and the r/wallstreetbets community, 2700 distinct posts were retained since they contained text in the titles and subtitles (posts with only a title and a picture were not considered). The FIBO ontologies used were those found in the FND, BP, and DER macro-areas.
First, we formed a collection of posts, each containing a title and a subtitle. The connections of these posts to the labels from the ontologies were searched, and then clusters for classes with connections were created. This first experiment was called Test 1. Second, we formed a collection of posts, each containing a title, a subtitle, and some comments. Then, the connections of these posts to the labels from the ontologies were determined, and clusters were created (similar to before). This second experiment was called Test 2.
Using the collection formed in Test 1, labels from ontologies were associated with approximately 1200 posts. In this case, the cluster consisting of the highest number of labels contained 20 labels, whereas the cluster connecting the highest number of posts contained 432 posts. From the collection formed in Test 2, labels were associated with approximately 1700 posts. In this case, the cluster consisting of the highest number of labels contained 25 labels, whereas the cluster connected to the highest number of posts contained 1508 posts.
Table 2 shows a small sample of clusters, indicating the representative label for each cluster, a description of the label, the number of labels within the cluster, and the number of connected posts.
Some words were used in the posts with a different meaning than the ontological labels. For example, good, future, and holding have very different meanings in the two sources (posts and ontological labels). Therefore, we listed common words that have several meanings, and we filtered out these words when looking for a connection between posts and ontological labels to avoid false positives.
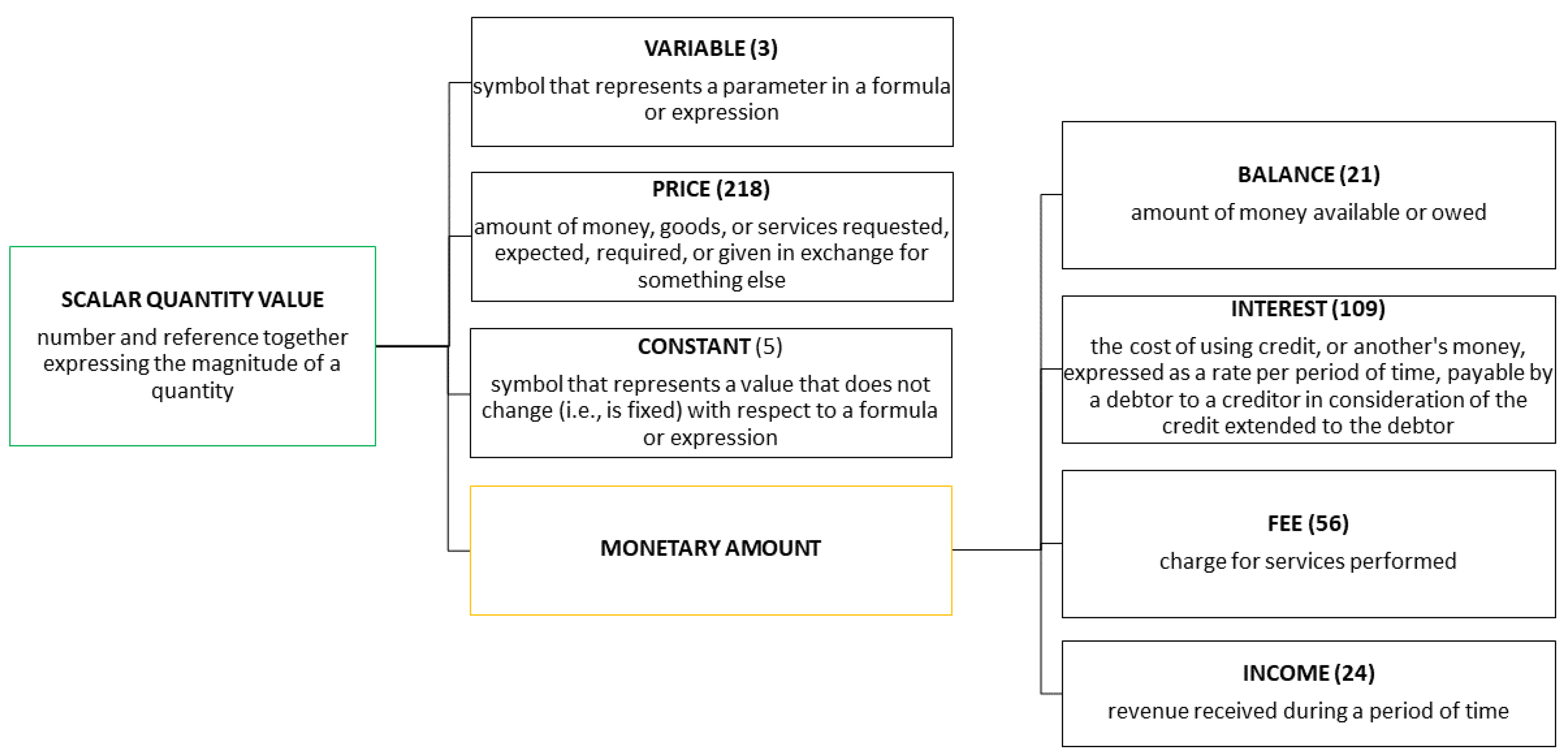
Figure 2 shows an example of a cluster identified in the ontology FND/TransactionsExt/MarketTransactions.rdf. The cluster is illustrated using a tree structure. The root node of the tree (the box on the left) shows the URI label of a class (in capital letters within the box) along with its definition (words in the box below the label). This root node is inherited by other URIs (in the center). The yellow node is a node that is inherited by other nodes (on the right). Each node shown is connected to posts obtained from Reddit. For each node, the number of posts connected to each ontology class is shown within round brackets beside the label.
Table 3 shows some results obtained from both tests. The two results highlighted in bold in
Table 3 refer to the Monetary Amount label, which is both a label and an identified cluster. Although the cluster identified in the two tests was the same, as defined by its constituting classes, the number of connected posts differed. There were 222 posts connected in the first test, and 897 posts connected in the second test. This was due to the fact that Test 2 included a higher number of posts, including those with comments.
By analyzing the definitions and concepts that define a cluster, it is possible to better understand and study the fields of interest of users. Each cluster provides the labels that facilitate connections with posts. Over the long term, by observing the change in the number of posts connected to a cluster, it is possible to determine whether the interests of groups of people remain consistent or have shifted elsewhere. Moreover, by analyzing the resulting clusters, it is possible to discover related interests (common to a cluster) and create recommendation systems.
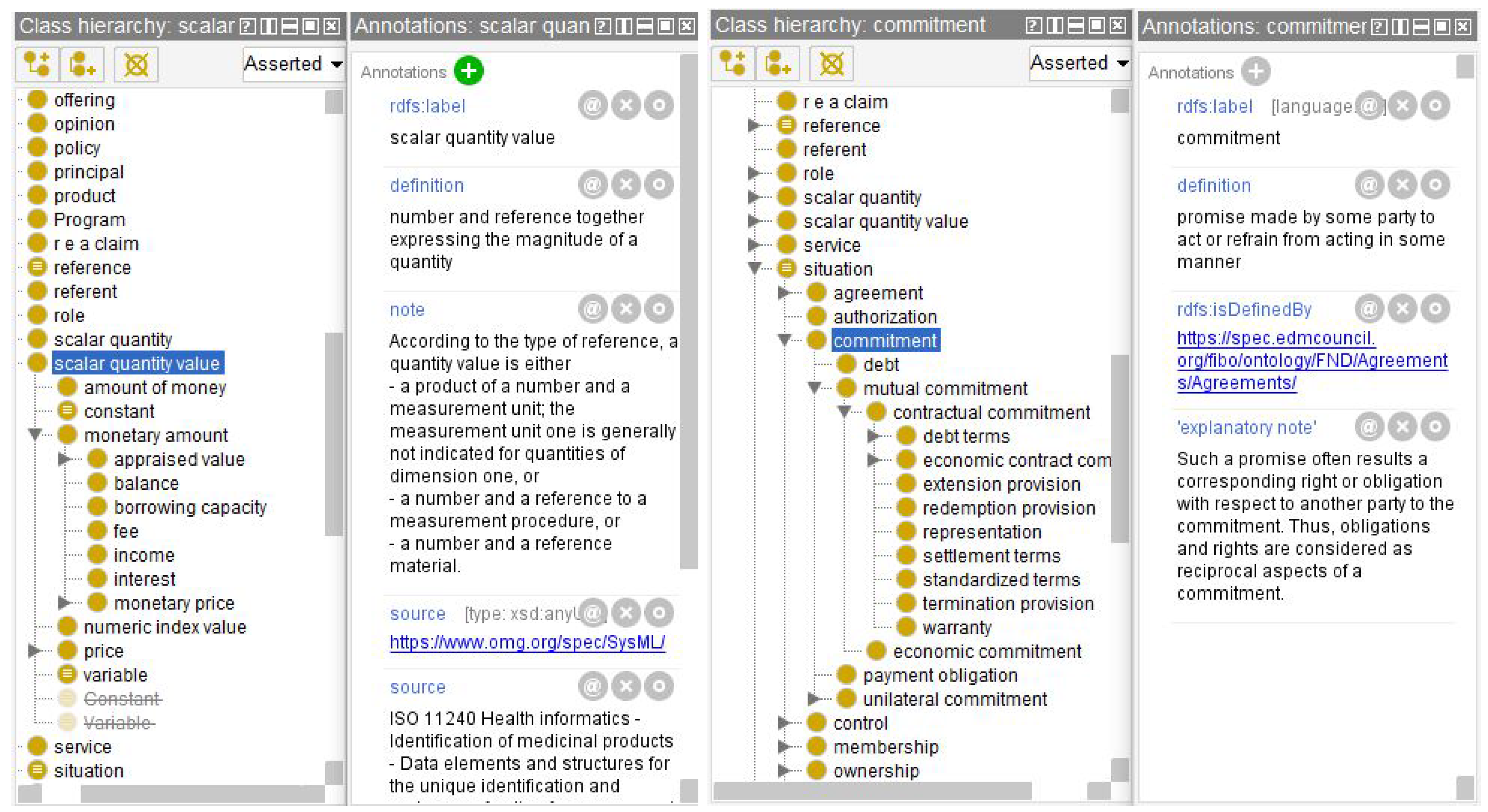
Figure 3 shows two examples of clusters presented as trees of classes. On the left, the root URI has the label scalar quantity value, and the cluster was identified within the ontology FND/TransactionsExt/MarketTransactions.rdf. The hierarchy shown is the same as that of the cluster shown in
Figure 2 (last accessed 30 March 2024). On the right, the root URI has the label commitment, and the cluster contains debt, warranty, and representation from the same ontology.
Some clusters were detected based on information present in multiple ontologies. For example, there was a cluster with the parent URI documents and the following terms identified in the posts: notice, record, report, catalog, publication, license, certificate, passport, and appraisal. This cluster resulted from the combination of labels present in the three ontologies.
Overall Analysis of the Processed Posts
In this section, we analyze the additional processed data to highlight how the size and composition of the semantic groups and the number of connected posts are related and can provide insights into interesting aspects of the active discussions about the considered domain: What are the most active topics? Which group of discussion topics exhibits the most accurate, technically verbose, and in-depth lexicon for dealing with the related subject?
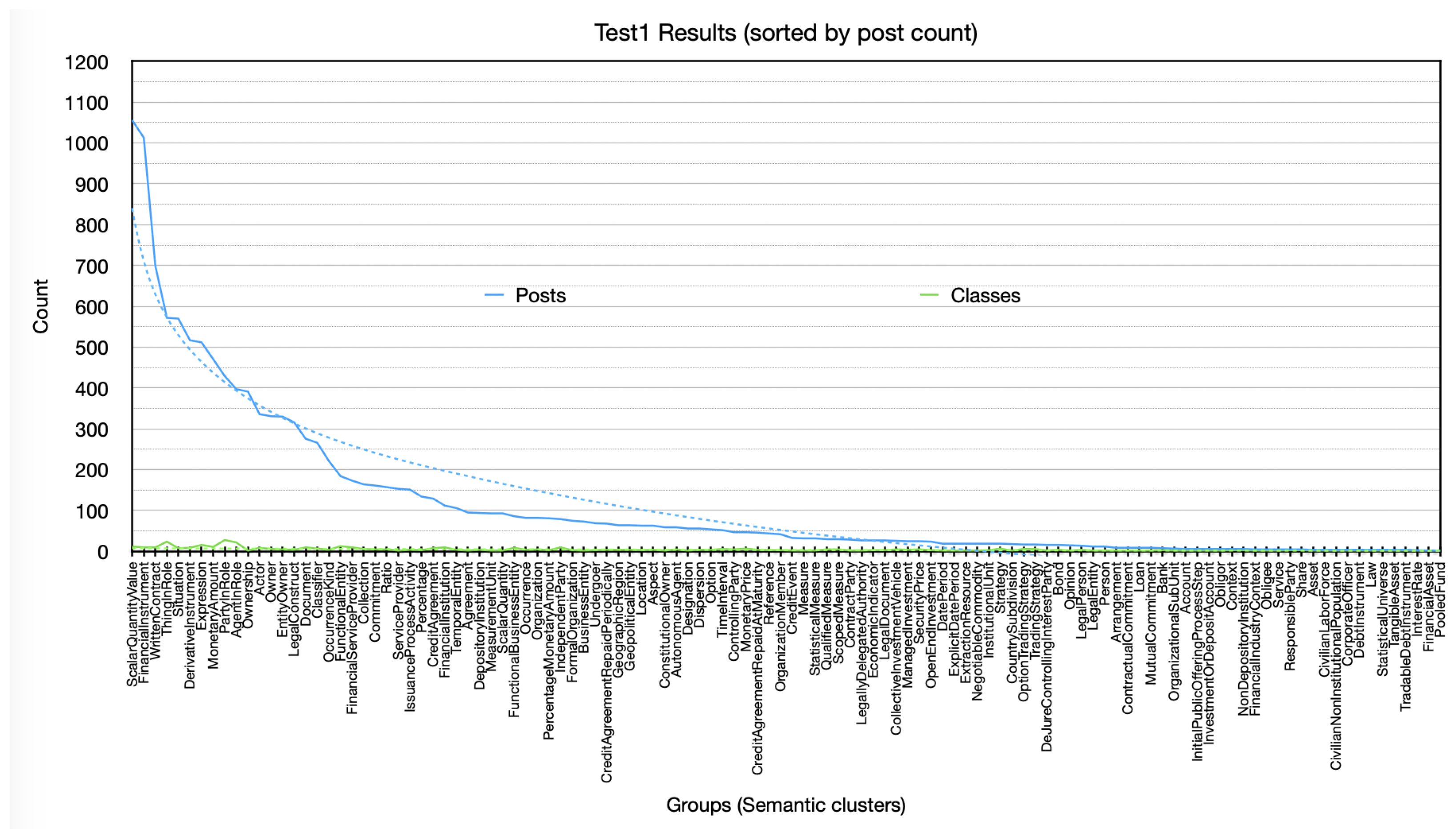
We provide a series of graphic charts representing the distribution of data resulting from Test 1 performed on Reddit post contents. We start by showing in
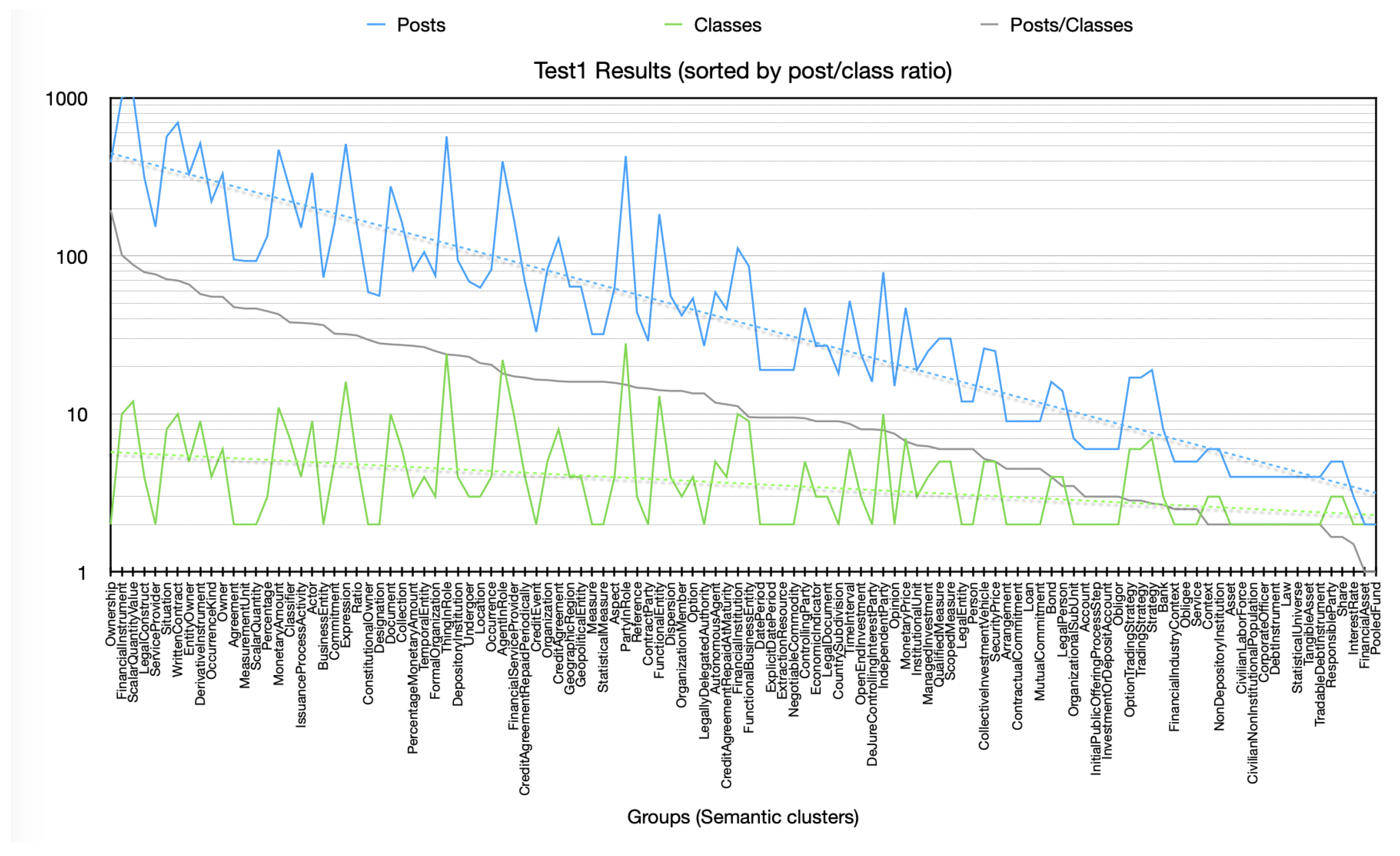
Figure 4 an overall graphic chart representing the size of each identified semantic cluster (groups) in terms of closely connected ontology classes (labels) and their respective number of connected posts, sorted by descending post count.
It should be noted that the size of the post count follows a logarithmic distribution with respect to the ontology groups, which means that there is a very small set of concept groups consistently receiving significantly more attention than the others. Also, we can see that a large majority of the groups receive very little attention from the community.
We assume that semantic groups with a poor vocabulary and very few posts are symptomatic of trivial, superficial, or inherently irrelevant discussion topics. It also might erroneously be concluded that this post distribution is not related to the size of their clusters, but this is a consequence of these figures being very small compared to the post counts.
In fact, it is evident that this is not the case from looking at
Figure 5, which redraws the same quantities on a logarithmic scale while also reordering the data series with respect to another metric: the normalized cluster size. This metric represents the ratio of connected posts vs. the size (in terms of the number of classes) of the respective cluster, providing a measure of the popularity of the post irrespective of the size (or verbosity) of their associated group. The sizes of the groups in this re-scaled view clearly exhibit a logarithmic decreasing trend, similar to that of their related post counts. Despite the variability in their absolute data values, this logarithmically scaled chart clearly shows a direct proportionality relationship between the average sizes of the ontology groups and their respective number of posts. This is not surprising at all; the proportionality relationship between the two data series is actually already defined by the normalized cluster size by construction, and this parameter exhibits a smooth linear trend. This could make it a good candidate as a parameter to set thresholds for the selection of the best groups of posts to process for further specific applications.
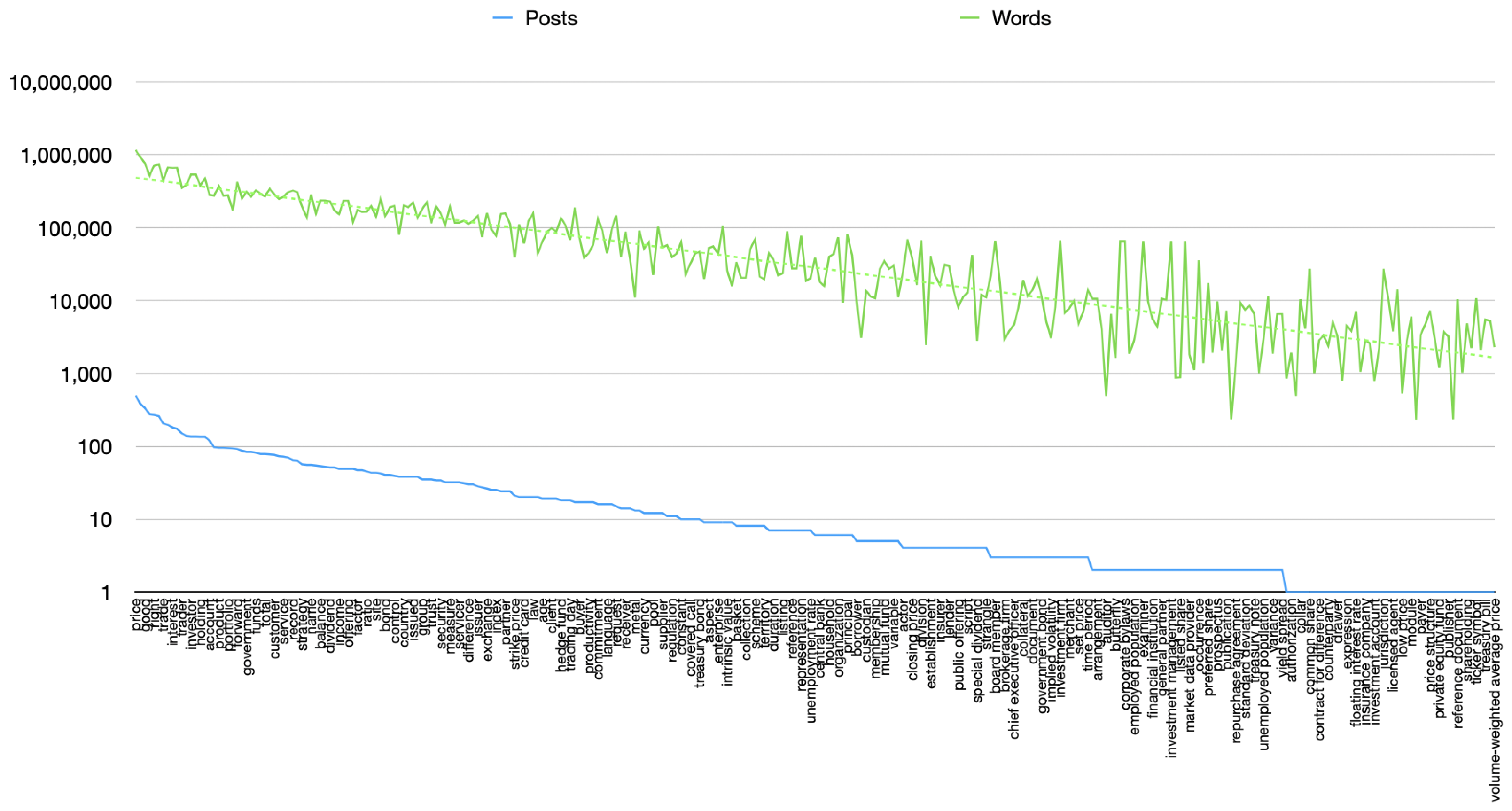
In
Figure 6, we present the whole set of ontology labels actually used, along with the number of connected posts found and the corresponding body of text for all those posts. This shows how a small fraction of semantic labels receive hundreds of times more attention in posts than all the others, resulting in a proportional but much larger amount of social media text content, in terms of words to be read. This is a clear indication of the significance and interest to users. As a consequence, it is of great convenience to be able to identify the ontological concepts related to that large body of text and to gain a quick understanding of the type of content it represents by simply examining a short list of connected terms instead of having to go through hundreds of thousands of words to catch the details.
6. Conclusions
This study explored the automatic aggregation of discussion topics on social media platforms, particularly focusing on those related to financial matters. While there exist several works on ontology-based analysis of unstructured text, none of them directly address the automatic classification of social media posts in the financial domain.
We presented an original approach to achieving this goal and also implemented and tested it on actual data extracted from a large volume of Reddit social media posts.
Reading and organizing thousands of user posts would be infeasible within a reasonable amount of time. The proposed tool automatically organizes the posts by connecting them to ontology classes, with each class providing the number of connected posts and the actual posts themselves.
We showed that the devised approach is able to automatically process large sets of unstructured social media text, effectively identifying key discussion topics and clustering relevant and semantically related concepts. In fact, by using financial concepts from a specialized ontology, we could highlight meaningful keywords and financial concepts that may have predictive power or practical implications. The ontological connections assisted in identifying interested user groups while covering a significant portion of the posts.
The proposed implemented approach provided valuable insights for understanding collective thinking within the financial sector, including aspects well beyond the discovery of user special interests or the support of recommendation systems. Indeed, there are limitations to analyzing and organizing social media data. As pointed out by Gore et al. [
33], social media messages are posted by an unrepresentative portion of the population and thus contain demographic and geographic biases that can contribute to distorted views. While it is reasonable to assume these biases also exist in financial posts, we must consider that our analysis is not aimed at extrapolating general statements representative of the whole population. Our analysis aims to profile specific post contents, allowing for a more convenient indexing of their actual contents.
Financial advisors could gain insights from the way the posts are organized and the summaries provided by each class (and group of classes). This organization provides a way to skim posts. Moreover, the number of posts for each class could be used as a priority indicator for advisors when selecting concepts and posts to read. The organized posts could indicate the importance of certain concepts to users, allowing financial advisors to determine the main user interests.
It is important to note that the represented data series is a snapshot of the social media data collected for one run of our tool, whereas these data continuously change over time due to the natural evolution of the local and global financial markets. However, while the groups and actual data figures will change dynamically, the type of data distribution will always highlight a very small subset as more active/interesting than others at each point in time, which our approach will be able to identify.
Additionally, by integrating knowledge from a domain ontology, the topic clustering automatically reflects and defines a network of semantic relations among the contents of the actual post, free from biases imposed by any pre-compiled list of flat options. This is of paramount importance when dealing with datasets whose specific content profile is subject to continuous and dynamic changes over time. As a direction for future development, it is, in fact, of primary interest to focus on the dynamics of how financial topics gain or lose social media traction in the long term, that is, to track the popularity of individual ontology clusters and classes over time.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}