Abstract
Text matching, as a core technology of natural language processing, plays a key role in tasks such as question-and-answer systems and information retrieval. In recent years, the development of neural networks, attention mechanisms, and large-scale language models has significantly contributed to the advancement of text-matching technology. However, the rapid development of the field also poses challenges in fully understanding the overall impact of these technological improvements. This paper aims to provide a concise, yet in-depth, overview of the field of text matching, sorting out the main ideas, problems, and solutions for text-matching methods based on statistical methods and neural networks, as well as delving into matching methods based on large-scale language models, and discussing the related configurations, API applications, datasets, and evaluation methods. In addition, this paper outlines the applications and classifications of text matching in specific domains and discusses the current open problems that are being faced and future research directions, to provide useful references for further developments in the field.
1. Introduction
Text matching aims at determining whether two sentences are semantically identical or not, and it plays a key role in domains such as question and answer, information retrieval, and summarization. Early text-matching techniques relied heavily on statistical methods such as the longest common substring (LCS) [1], edit distance [2], Jaro similarity [3], dice coefficient [4], and Jaccard method [5]. These methods have the advantage of quantifiable similarity and have been widely used in several scenarios such as text comparison, spell-checking, gene sequence analysis, and recommender systems. They have a solid theoretical foundation that ensures the accuracy and reliability of similarity computation. However, there are some limitations to these methods, such as the high computational complexity of some of them, their sensitivity to input data, and limited semantic understanding. These methods include the bag-of-words model [6], distributed representation [7], matrix decomposition [8], etc., and their common advantage is that they can transform textual data into numerical representations, which is easy for computer processing. At the same time, they are flexible and scalable and can adapt to different needs and data characteristics. However, these methods still have limitations in deep semantic understanding and may not be able to accurately capture complex meanings and contextual information. In addition, the computational complexity is high when dealing with large-scale corpora, and the parameters need to be adjusted and optimized to obtain the best results. In recent years, with the rise of neural network technology, recursive neural network-based matching methods such as LSTM (Long Short-Term Memory) [9], BiLSTM(Bidirectional Long Short-Term Memory) [10], and BiGRU (Bidirectional Gated Recurrent Unit) [11] have gradually emerged. These methods share common features in terms of sequence modeling, gating mechanism, state transfer, bi-directional processing, and optimization and training. They can fully utilize the information in sequences, capture long-term dependencies, and show excellent performance in handling complex tasks.
However, these methods often ignore the interaction information between the statements to be matched during the matching process, thus limiting the further improvement of the matching effect. To solve this problem, researchers have proposed sentence semantic interaction matching methods, such as DSSTM [12], DRCN [13], DRr-Net [14], and BiMPM [15]. The core of these methods lies in capturing the semantic interaction features between sentences using deep learning models and optimizing the matching task through an end-to-end training approach. These methods usually have a high matching performance and are flexible enough to be applied to different types of matching tasks. However, these methods are usually sensitive to noise and ambiguity and are data-dependent, with limited generalization capability. With the continuous development of technology, knowledge graph and graph neural network matching methods are gradually emerging. These methods show unique advantages in dealing with graph-structured data, can effectively extract features and perform representation learning, and are suitable for dealing with complex relationships. At the same time, they also show a strong flexibility and representation capability and can be adapted to different types of matching tasks. However, these methods also face some challenges, such as high computational complexity and sensitivity to data quality and structure. In recent years, advances in deep learning methods, the availability of large amounts of computational resources, and the accumulation of large amounts of training data have driven the development of techniques such as neural networks, attention mechanisms, and Transformer [16] language models. These research results have further advanced the development of big language models. Big language models utilize neural networks containing billions of parameters, trained on massive amounts of unlabeled text data through self-supervised learning methods. Often pre-trained on large corpora from the web, these models can learn complex patterns, linguistic subtleties, and connections. This technique has also significantly advanced the development of sentence matching, with models such as BERT [17], Span-BERT [18], Roberta [19], XLNet [20], the GPT family [21,22,23,24], and PANGU-Σ [25] demonstrating superior performance in sentence-matching tasks.
The large language model described above lays the cornerstone for sentence semantic matching and focuses on exploring generic strategies for encoding text sequences. In text matching, previous approaches typically add a simple categorization target through fine-tuning and perform direct text comparisons by processing each word. However, this approach neglects the utilization of the semantic information of tags, as well as the differences in the granularity of multilevel matching in the sentence content. To address this problem, researchers have proposed a matching method based on a large language model that combines different features, which is capable of digging deeper into the semantic-matching information at different levels of granularity in tags [26] and sentences [27,28,29]. These studies have made important contributions to the development of the text-matching field. Therefore, a comprehensive and reliable evaluation of text-matching methods is particularly important. Although a few studies [30,31,32] have demonstrated the potential and advantages of some of the matching methods, there is still a relative paucity of studies that comprehensively review the recent advances, possibilities, and limitations of these methods.
In addition, researchers have extensively explored multiple aspects of text matching in several studies [30,31,32], but these studies often lack in-depth analyses of the core ideas, specific implementations, problems, and their solutions for matching methods. Also, there are a few exhaustive discussions on hardware configurations, training details, performance evaluation metrics, datasets, and evaluation methods, as well as applications in specific domains of matching methods. Therefore, there is an urgent need to delve into these key aspects to understand and advance the development of text-matching techniques more comprehensively. Given this, this paper aims to take a comprehensive look at the existing review studies, reveal their shortcomings, and explore, understand, and evaluate text-matching methods in depth. Our research will cover core concepts, implementation strategies, challenges encountered, and solutions for matching methods, while focusing on their required hardware configurations and training processes. In addition, we will compare the performance of different metrics for different tasks, analyze the choice of datasets and evaluation methods, and explore the practical applications of matching methods in specific domains. Finally, this paper will also examine the current open problems and challenges faced by text-matching methods, to provide directions and suggestions for future research and promote further breakthroughs in text-matching technology.
The main contributions of this paper are as follows: (1) The core ideas, implementation methods, problems, and solutions for text-matching methods are thoroughly outlined and analyzed. (2) The hardware configuration requirements and training process of the matching method are analyzed in depth. (3) A detailed comparison of the performance of text-matching models with different metrics for different tasks is presented. (4) The datasets used for training and evaluating the matching model are comprehensively sorted out and analyzed. (5) The interface of the text-matching model in practical applications is summarized. (6) Application cases of matching models in specific domains are analyzed in detail. (7) Various current unsolved problems, challenges, and future research directions faced by matching methods are surveyed, aiming to provide useful references and insights to promote the development of the field.
The chapter structure of this study includes an overview of some leading research comparisons in Section 2. Then, the literature collection and review strategy is presented in Section 3. Then, in Section 4 we check, review, and analyze 121 top conference and journal papers published from 1912 to 2024. In Section 5, we focus on the core of the matching approach, exploring in detail its main ideas, implementation methods required hardware configurations, and training process, and comparing the performance of text-matching models with different metrics for different tasks. Through this section, readers can gain a deeper understanding of the operation mechanism and the advantages and disadvantages of the matching method. Section 6 then focuses on analyzing and summarizing the datasets used for training and evaluating the matching models and their evaluation methods, providing guidance and a reference for researchers in practice. Section 7 further explores the application of matching models in specific domains, demonstrating their practical application value and effectiveness through case studies. Section 8 reveals the various outstanding issues and challenges that the matching method is currently facing, and it stimulates the reader to think about future research directions. In Section 9, we delve into the future research directions of matching methods, providing useful insights and suggestions for researchers. Finally, in Section 10, we summarize the research in this paper.
2. Literature Review
Text matching, as an important branch in the field of artificial intelligence, has made a remarkable development in recent years. To deeply explore and evaluate its capabilities, numerous researchers have carried out extensive research work. Researchers from different disciplinary backgrounds have contributed many innovative ideas to text-matching methods, demonstrating their remarkable progress and diverse application prospects. Overall, these studies have collectively contributed to the continuous advancement in text-matching techniques. As shown in Table 1, Asha S et al. [30] provided a comprehensive review of string-matching methods based on artificial intelligence techniques, focusing on the application of key techniques such as neural networks, graph models, attention mechanisms, reinforcement learning, and generative models. The study not only demonstrates the advantages and potential of these techniques in practical applications but also deeply analyzes the challenges faced and indicates future research directions. In addition, Hu W et al. [31] provided an exhaustive review of neural network-based short text matching algorithms in recent years. They introduced models based on representation and word interaction in detail and analyzed the applicable scenarios of each algorithm in depth, providing a quick-start guide to short text matching for beginners. Meanwhile, Wang J et al. [32] systematically sorted out the current research status of text similarity measurement, deeply analyzed the advantages and disadvantages of existing methods, and constructed a more comprehensive classification and description system. The study provides an in-depth discussion of the two dimensions of text distance and text representation, summarizes the development trend of text similarity measurement, and provides valuable references for related research and applications.

Table 1.
Comparison between leading studies.
Table 1 compares in detail the research content and focus of different review papers in the field of text matching. Among them, the application of large language models in text matching, the core ideas of matching methods and their implementation, problems and solutions, and logical relationships have been explored to different degrees. However, the studies by Asha S [30] and Hu W et al. [31] are deficient in some key areas, such as the lack of a detailed overview and analysis of the matching methodology, an in-depth comparison of hardware configurations and training details, a comprehensive evaluation of the performance of the text-matching model under different tasks, and a comprehensive overview of the dataset, evaluation metrics, and interfaces of the model application. Similarly, the study by Wang J et al. [32] fails to cover many of these aspects. In contrast, our paper remedies these shortcomings by comprehensively exploring the core idea of the text-matching approach and its methodology, problems and solutions, hardware configurations, and training details, and comparing the performance of text-matching models for different tasks using different metrics. In addition, this study provides an overview of the datasets, evaluation metrics, and application programming interfaces for text-matching models, and analyzes in detail the application of the models in specific domains. Through these comprehensive studies and analyses, this thesis provides richer and deeper insights into the research and applications in the field of text matching.
As can be seen from the above analysis, most of the past studies have focused on limited areas of semantic matching, such as technology overviews, matching distance calculations, and evaluation tools. However, this study is committed to overcoming these limitations by providing an in-depth and comprehensive analysis of the above aspects, thus better revealing the strengths and weaknesses of the matching methods based on large language models. The core of this study is to deeply analyze the core idea of the matching method, compare the impact of different hardware configurations and training details on performance, evaluate the effectiveness of the text-matching model in various tasks with different metrics, outline the application program interface of the text-matching model, and explore its application in specific domains. By providing exhaustive information, this study aims to be an important reference resource for sentence-matching researchers. In addition, this study addresses open issues in sentence-matching methods, such as bottlenecks in the application of large models to sentence-matching tasks, model-training efficiency issues, interference between claim comprehension and non-matching information, the handling of key detail facts, and the challenges of dataset diversity and balance. The study highlights these key challenges and indicates directions and valuable resources for future research for sentence-matching researchers, to provide new ideas for solving these open problems.
3. Data Collection
The literature review strategy consisted of three steps. First, the scope of the study was identified as text matching in NLP. The second step was to select widely recognized and high-quality literature search databases, such as Web of Science, Engineering Village, IEEE, SpringerLink, etc., and use Google Scholar for the literature search. Keywords include text matching, large language modeling, question and answer and retrieval, named entity recognition, named entity disambiguation, author names disambiguation, and historical documentation. In the third step, 121 articles related to text matching were collected for a full-text review and used for text-matching research and summarization. (See Figure 1).
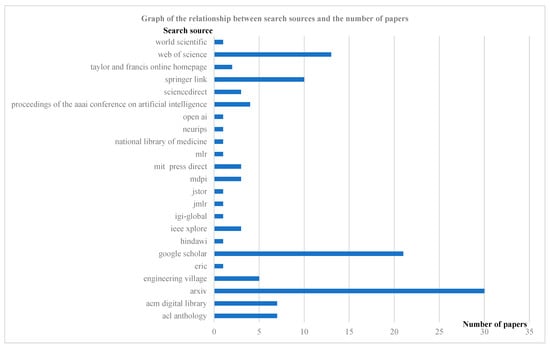
Figure 1.
Graph of search sources versus number of papers.
4. Summary of Results
Figure 2, Figure 3 and Figure 4 illustrate the distribution of articles related to text-matching survey research by year, region, and journal. As can be seen in Figure 2, this type of research has shown a significant growth trend since around 2015. Previous studies have also shown that the field of machine vision is facing a similar situation, which is closely related to the increased demand for AI technology in various industries, the improved performance of computer hardware, and the rapid development and dissemination of AI. From Figure 3, it can be observed that the US has the highest number of papers published in text-matching-related research, accounting for 49.59% of the total. This is followed by China, the UK, India, Germany, and Canada. Other countries such as the United Arab Emirates, South Korea, Israel, and South Africa have published corresponding articles. Finally, Figure 4 shows the 65 top conferences and journals that were sources of the literature, mainly focusing on the field of natural language processing, where 18 papers from 2017 to 2024 were selected in the Arxiv preprint. Eight papers from 2014 to 2022 were selected for ACL. 6 papers from 2016 to 2022 were selected for AAAI.
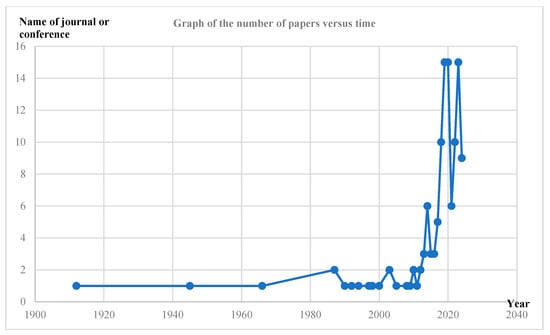
Figure 2.
Graph of number of papers vs. time.
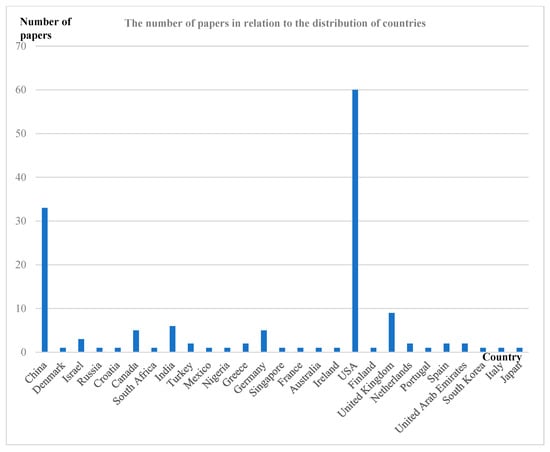
Figure 3.
Graph of the number of papers in relation to the distribution of countries.
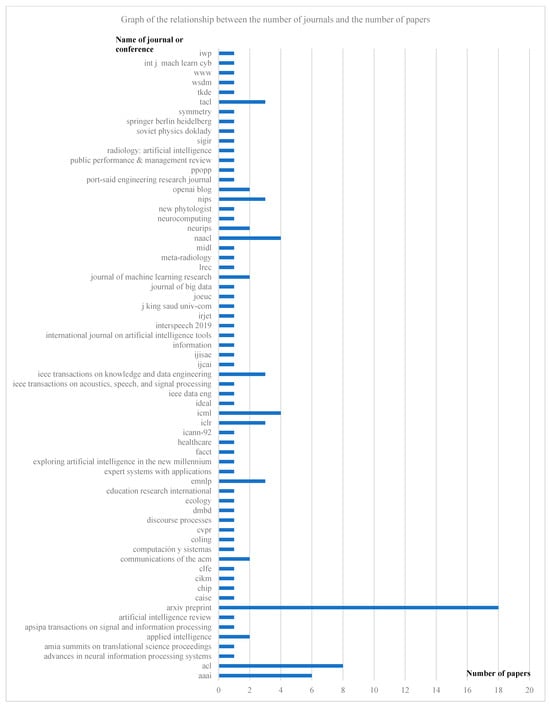
Figure 4.
Graph of journals versus number of conferences and papers.
5. Text-Matching Methods
Text-matching methods cover several different techniques and strategies, each with its unique application scenarios and advantages. These methods can be broadly classified into the following categories: string-based methods, corpus-based methods, recursive neural network matching methods, sentence semantic interaction matching, matching methods based on graph structures, matching methods based on pre-trained language models, and matching methods based on large language models utilizing different features, as shown in Figure 5. String-based methods usually match by comparing the similarity of characters or strings in text and are suitable for simple and straightforward text comparison tasks. Corpus-based methods, on the other hand, rely on large-scale corpora to extract similarities and relationships between texts and achieve matching through statistical and probabilistic models. Recursive neural network matching methods utilize neural networks to deeply understand and represent the text, capturing the hierarchical information of the text through recursive structures to achieve a complex semantic matching. Sentence semantic interaction matching, on the other hand, emphasizes the semantic interaction and understanding between sentences, and improves the matching effect by modeling the interaction between sentences. Graph structure-based matching methods utilize graph theory knowledge to represent and compare texts, and match by capturing structural information in the text. In contrast, sentence vector-matching methods based on large language models improve the matching performance by capturing the deep semantic features of the text with the help of pre-trained language models from large-scale corpora. Among the large language model-based matching methods utilizing different features, the matching methods utilizing tagged semantic information consider the effect of tags or metadata on text matching and enhance the accuracy of matching by introducing additional semantic information. The fine-grained matching method pays more attention to the detailed information in the text and realizes fine-grained matching by accurately capturing the subtle differences between texts.
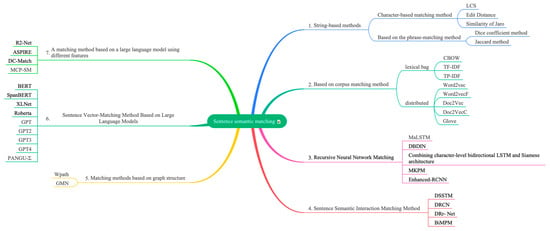
Figure 5.
Matching method overview diagram.
5.1. Text-Matching Methods
String similarity metrics are an important text analysis tool that can be used to measure the degree of similarity between two text strings, which in turn supports string matching and comparison. Among these metrics, the cosine similarity measure is popular for its simplicity and effectiveness. The cosine similarity metric calculates the similarity between two texts based on the cosine of the angle of the vectors [33], which consists of calculating the dot product of the two vectors, calculating the modulus (i.e., length) of the respective vectors, and dividing the dot product by the product of the moduli; the result is the cosine of the angle, i.e., the similarity score. However, the cosine similarity is not sensitive to the magnitude of the value, does not apply to non-positive spaces, and is affected by the feature scale. To improve its performance, methods such as adjusting the cosine similarity (e.g., centering the values), using other similarity measures (e.g., Pearson’s correlation coefficient), or feature normalization can be adopted to improve the accuracy and applicability of the similarity calculation.
Several variants or improved forms of cosine similarity have also been proposed by researchers to address specific needs in different scenarios. These variants include weighted cosine similarity [34] and soft cosine similarity [35], among others. Weighted cosine similarity allows different weights to be assigned to each feature dimension to reflect the importance of different features; soft cosine similarity reduces the weight of high-frequency words in text similarity computation by introducing a nonlinear transformation. In addition, depending on the basic unit of division, string-matching-based methods can be divided into two main categories: character-based matching and phrase-based matching. These methods are illustrated in Figure 6, and their key ideas, methods, key issues, and corresponding solutions are summarized in detail in Table 2. These string-matching-based methods provide a rich set of tools and options for text analysis and processing to meet the needs of different application scenarios.
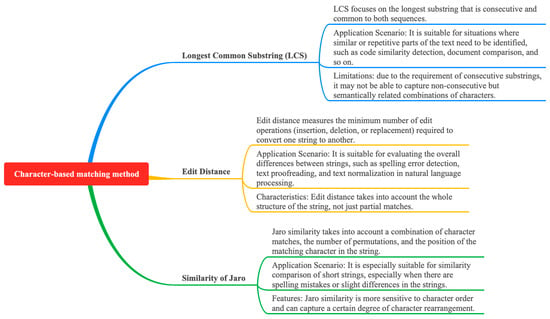
Figure 6.
Overview of logical relationships based on character-matching methods.
Table 2.
Overview of key ideas, methods, key issues, and solutions for string-matching-based approaches.
Longest common substring (LCS) [1], edit distance [2], and Jaro similarity [3] are three methods based on character matching, which have their own focuses and logically complement each other. LCS focuses on consecutive character matching, edit distance measures the overall conversion cost, and Jaro similarity considers character matching, permutation, and positional information. These methods constitute a diversified toolbox for character-matching analysis, which can be flexibly selected and combined according to the application scenarios. With the development of natural language processing technology, more new methods may emerge in the future to meet more complex text-processing needs.
The longest common substring matching algorithm iteratively determines the length of the longest common substring by calculating a threshold array to find the optimal solution, and it reduces the running time by optimizing the set operation [1]. For large-scale data and complex scenarios, parallelization and distributed processing schemes are proposed to improve the scalability and processing speed of the algorithm. Edit distance constructs binary codes by analogy to correct optimal code problems such as wounding, insertion, and inversion [2]. However, it faces problems such as a limited error correction capability, difficulty in recognizing insertion errors, and high computational complexity in inversion error detection and computation. The solutions include adopting more powerful error correction codes, designing synchronization markers, utilizing checksum methods, and optimizing the algorithm implementation. Jaro similarity is measured by a string comparator and optimized by the record-joining method of the FellegiSunter model, which uses the Jaro method to handle string discrepancies and adjust the matching weights [3]. However, the database quality and string comparator parameter settings affect the matching accuracy. We propose strategies such as data cleaning, increasing the sample diversity, and an adaptive string comparator to optimize the performance and accuracy of the matching algorithm.
Phrase-based matching methods include the dice coefficient method [4] and the Jaccard method [5], as shown in Figure 7. The difference between phrase-based matching methods and character-based matching methods is that the basic unit of processing is the phrase. The dice coefficient method in the phrase-based matching method is mainly used to measure the similarity of two samples. However, this method has limitations in dealing with synonyms, contextual information, and large-scale text. For this reason, context-based word embedding models, deep learning methods, and the optimization of data structures, in combination with approximation algorithms, are used to improve the accuracy and efficiency of the similarity assessment. In the field of natural language processing, it is often used to calculate the similarity of two text phrases. The principle of the dice coefficient is based on the similarity measure of sets [4], which is calculated as follows:
where |X ∩ Y| denotes the size of the intersection of X and Y, and |X| and |Y| denotes the size (i.e., number of elements) of X and Y, respectively. The value domain of the dice coefficient is [0, 1]. When two samples are identical, the dice coefficient is 1; when two samples have no intersection, the dice coefficient is 0. Therefore, the larger the dice coefficient, the more similar the two samples are.
dice coefficient = (2 × |X ∩ Y|)/(|X| + |Y|)
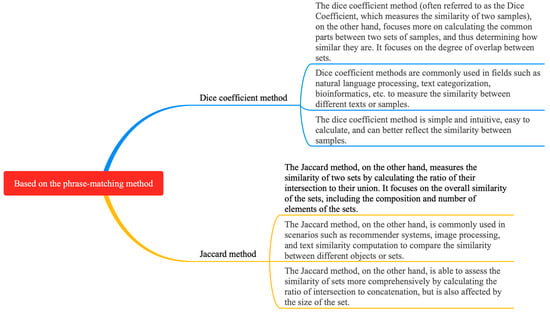
Figure 7.
Overview of logical relationships based on phrase-matching methods.
The Jaccard method in the phrase-based matching method is an algorithm used to calculate the similarity of two sets [5]. Its principle is based on the Jaccard coefficient in set theory, which measures the similarity of two sets by calculating the ratio of their intersection and concatenation. Specifically, given two sets A and B, the Jaccard coefficient is defined as the number of elements in the intersection of A and B divided by the number of elements in the concatenation of A and B. However, the method suffers from the problems of being insensitive to sparse text and ignoring word weights and word order. To improve these problems, it is possible to convert word items into word embedding vectors, add word item weights, and for these to be used in combination with other similarity measures to evaluate text semantic similarity more accurately. Its calculation formula is as follows:
where |A ∩ B| denotes the number of intersection elements of sets A and B, and |A ∪ B| denotes the number of concatenation elements of sets A and B. The Jaccard coefficient has a value range of [0, 1], with larger values indicating that the two sets are more similar.
Jaccard(A, B) = |A ∩ B|/|A ∪ B|
5.2. Based on the Corpus-Matching Method
Typical methods for corpus-based matching include bag-of-words modeling such as BOW (bag of words), TF-IDF (term frequency-inverse document frequency), distributed representation, and matrix decomposition methods such as LSA (Latent Semantic Analysis), as shown in Figure 8. The key ideas, methods, key problems, and solutions for typical methods of corpus-based matching are summarized in Table 3.
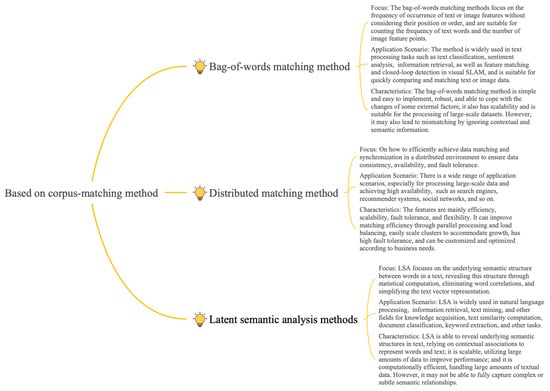
Figure 8.
Corpus-based matching method.
Table 3.
Overview of key ideas, methods, key problems, and solutions of corpus-based matching methods.
Typical approaches to bag-of-words models are BOW [6], TF-IDF [40], and its variant TP-IDF [42]. The bag-of-words model reduces the text to a collection of lexical frequencies, ignores the order and semantics, and is not precise enough for complex text processing. To improve this model, the n-gram model can be used to consider word combination and order, or word embedding technology can be used to capture semantic relationships, so as to enhance the accuracy and performance of text processing.TF-IDF is an important method in the bag-of-words model, which evaluates the importance of words by combining the word frequency and the inverse document frequency, and extracts key information effectively. However, IDF simplified processing may lead to information loss and the underestimation of similar text keywords. For improvement, text representation techniques such as TF-IWF, or ones combined with word embedding models, can be used to represent text content more comprehensively.TP-IDF is an improvement to the traditional TF-IDF method, which combines the positional information of the word items in the document to assess the word importance more accurately, and it is especially suitable for short text analysis. However, it also faces the challenges of defining location factors, stability, noise interference, and computational complexity in its application. By optimizing the position factor definition, combining other text features, deactivating word processing, and algorithm optimization, TP-IDF can improve the efficiency and accuracy of text data processing.
Distributed approaches cover a range of techniques based on dense vector representations [51], such as Word2vec [7], Word2VecF [45], Doc2Vec [46], Doc2VecC [47], and glove [39]. These techniques represent vectors using fixed-size arrays where each element contains a specific value, thus embedding words, documents, or other entities into a high-dimensional space to capture their rich semantic information. Dense vector representations have been widely used in natural language processing tasks such as text categorization, sentiment analysis, recommender systems, etc., because of their simplicity, intuitiveness, and ease of processing. Word2Vec, as a representative of this, achieves a quantitative representation of semantics by mapping words into continuous vectors through neural networks. However, CBOW and Skip-gram, as their main training methods, have problems such as ignoring word order, multiple meanings of one word, and OOV words. To overcome these limitations, researchers have introduced dynamic word vectors and character embeddings or pre-trained language models, in conjunction with models such as RNN, Transformer, etc., to significantly improve the performance and applicability of Word2Vec. Word2VecF is a customized version of Word2Vec that allows users to customize word embeddings by supplying word–context tuples, to be able to exploit global context information. However, it also faces challenges such as data quality, parameter tuning, and computational resources. To overcome these challenges, researchers have adopted technical approaches such as data cleaning, parameter optimization, distributed computing, and model integration to improve the accuracy and efficiency of word embeddings.
The glove model, on the other hand, captures global statistics by constructing co-occurrence matrices to represent the word vectors, but it suffers from the challenges of dealing with rare words, missing local contexts, and high computational complexity. To improve the performance and utility of the glove, researchers introduced an external knowledge base, incorporated a local context approach, and used optimized algorithms and model structures, as well as a distributed computing framework for training. These improvements make the glove model more efficient and accurate in natural language processing tasks.
The core idea of LSA (Latent Semantic Analysis) is to reveal the implicit semantics in the text by mapping the high-dimensional document space to the low-dimensional latent semantic space [8]. It uses methods such as singular value decomposition to realize this process. However, LSA suffers from semantic representation limitations, sensitivity to noise, and computational complexity. To improve the performance, it can be combined with other semantic representation methods, data preprocessing, and cleaning, as well as the optimization of the algorithm and computational efficiency. Through these measures, LSA can be utilized more effectively for text processing and semantic analysis.
5.3. Recursive Neural Network-Based Matching Method
Neural network architectures are at the heart of deep learning models and determine how the model processes input data and generate output. These architectures consist of multiple layers and neurons that learn patterns and features in the data by adjusting the weights of connections between neurons. Common neural network architectures include feed-forward neural networks, recurrent neural networks, and convolutional neural networks, each of which is suitable for different data-processing needs. When dealing with sentence-matching tasks, specific architectures such as twin networks and interactive networks can efficiently compute the similarity between sentences. In addition, the attention mechanism [52] improves the efficiency and accuracy of processing complex data by simulating the allocation of human visual attention, enabling the model to selectively focus on specific parts of the input data. Recursive neural network matching methods, such as those based on LSTM, BiLSTM, and BiGRU, are shown in Figure 9. They further combine neural network architectures and attention mechanisms to provide powerful tools for processing sequential data. By properly designing and adapting these architectures, deep learning models can be constructed to adapt to various tasks. The key ideas, methods, key issues, and solutions for the recursive neural network matching approach are summarized in Table 4.
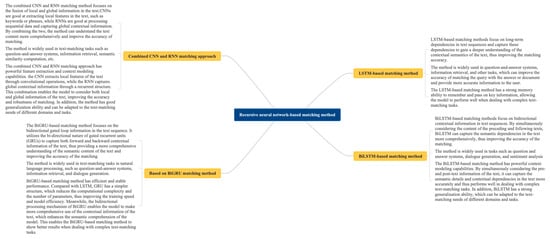
Figure 9.
Overview of logical relationships of recursive neural network-based matching methods.
Table 4.
Overview of key ideas, methods, key problems, and solutions for recursive neural matching-based approaches.
The MaLSTM model predicts semantic similarity by capturing the core meaning of sentences through LSTM and fixed-size vectors [9]. However, there are problems with low-frequency vocabulary processing, capturing complex semantic relations, and computational efficiency. This study proposes strategies such as data preprocessing, introducing an attention mechanism, optimizing the model structure, and utilizing pre-trained models to improve the model’s effectiveness on the sentence similarity learning task. The DBDIN model [55] achieves precise semantic matching between sentences through two-way interaction and an attention mechanism but faces the problems of a high consumption of computational resources, difficulty in capturing complex semantics, and limited generalization ability. Optimizing the model structure, introducing contextual information and pre-training models, and combining multiple loss functions and regularization techniques can improve the performance and stability of DBDIN on the sentence similarity learning task. The deep learning model proposed by Neculoiu P et al. combines a character-level bi-directional LSTM and Siamese architecture [10] to learn character sequence similarity efficiently but suffers from high complexity, and it may ignore overall semantic information and show a lack of robustness. Optimizing the performance can be accomplished by simplifying the model structure, introducing high-level semantic information, cleaning the data, and incorporating regularization techniques.
Lu X et al. [11] proposed a sentence-matching method based on multiple keyword pair matching, which uses the sentence pair attention mechanism to filter keyword pairs and model their semantic information, to accurately express semantics and avoid redundancy and noise. However, the method still has limitations in keyword pair selection and complex semantic processing. The accuracy and application scope of sentence matching can be improved by introducing advanced keyword extraction techniques, extending the processing power of the model, and optimizing the algorithm. Peng S et al. proposed the Enhanced-RCNN model [57], which fuses a multilayer CNN and attention-based RNN to improve the accuracy and efficiency of sentence similarity learning. However, the model still has challenges in handling complex semantics, generalization ability, and computational resources. The model performance can be improved by introducing new techniques, optimizing models and algorithms, and expanding the dataset.
5.4. Semantic Interaction Matching Methods
Typical models of semantic interactive matching methods include DSSTM [12], DRCN [13], DRr- Net [14], and BiMPM [15], as shown in Figure 10. As shown in Table 5, this study outlines the key ideas, methods, key issues, and solutions for interaction matching methods.
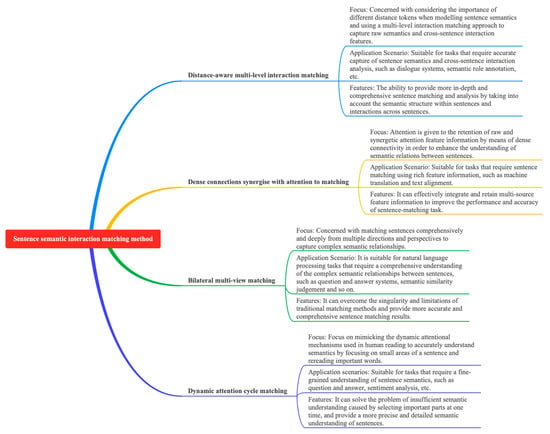
Figure 10.
Overview of logical relations of sentence semantic interaction matching methods.
Table 5.
Overview of key ideas, methods, key problems, and solutions for interaction matching methods.
Deng Y et al. proposed constructing a DSSTM model [12], which utilizes distance-aware self-attention and multilevel matching to enhance sentence semantic matching accuracy but suffers from computational inefficiency and insufficient deep semantic capture, and it is suggested to optimize the model structure and introduce complex semantic representations to improve the performance. Kim S et al. [13] proposed a novel recurrent neural network architecture, which enhances inter-sentence semantic comprehension through dense connectivity and collaborative attention but suffers from rising feature dimensions’ computational complexity and information loss. It is suggested to optimize the feature selection and compression techniques to improve the model performance. Zhang K et al. [14] proposed a sentence semantic matching method that simulates the dynamic attention mechanism of human reading, which improves comprehension comprehensiveness and accuracy but is limited by the quality of training data and preprocessing. It is suggested to optimize the training strategy, increase the diversity of data, improve the preprocessing techniques, and combine linguistic knowledge to enhance the model performance. The BiMPM model proposed by Wang Z et al. [15] improves the performance of NLP tasks through multi-view matching but suffers from complexity and cross-domain or cross-language adaptability problems. Optimizing the model structure and introducing the attention mechanism are schemes that help to improve the model’s accuracy and adaptability.
5.5. Matching Methods Based on Graph Structure
Typical approaches for matching based on graph structures include knowledge graphs and graph neural networks, as shown in Figure 11. This study also outlines the key ideas, methods, key problems, and solutions for graph-based matching methods, as shown in Table 6.
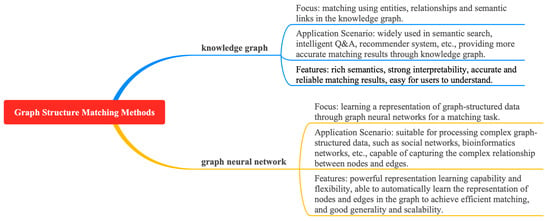
Figure 11.
Overview of logical relationships of graph structure matching methods.
Table 6.
Overview of key ideas, methods, key problems, and solutions based on graph matching methods.
Zhu G et al. proposed the wpath method [59] to measure semantic similarity by combining path length and information content in a knowledge graph. However, there are problems of graph sparsity, computational complexity, and information content limitations. It is suggested to introduce multi-source paths, optimize the graph structure and algorithm, integrate other semantic features, and adjust the weights to improve the applicability and performance of the wpath method. Chen L et al. proposed a GMN framework to improve the accuracy of Chinese short text matching through multi-granularity input and attention graph matching [60], but there are problems such as high complexity and poor interpretability. It is suggested to optimize the graph matching mechanism, enhance interpretability, reduce model dependency, and use data enhancement and automation tools to improve performance.
5.6. Sentence Vector Matching Method Based on Large Language Models
The embedding technique is an important means to transform textual data, such as words, phrases, or sentences, into fixed dimensional vector representations. These vectors not only contain the basic features of the text but are also rich in semantic information, enabling similar words or sentences to have similar positions in the vector space. In the sentence-matching task, the embedding technique is particularly important because it can transform sentences into computable vector representations, thus facilitating our subsequent similarity calculations and comparisons. Among the many embedding methods, models such as Word2Vec, Glove, and BERT have shown excellent performance. They can capture the contextual information of words and generate semantically rich vector representations, providing strong support for NLP (Natural Language Processing) tasks such as sentence matching. In recent years, significant progress has been made in sentence vector matching methods based on large language models. Models such as BERT [17], Span BERT [18], XLNet [19], Roberta [20], GPT family, and PANGU-Σ [25] are among the leaders. As shown in Figure 12, these models have their features and advantages in sentence vector representation. This study delves into the key ideas and methods of these models, as well as the key problems and solutions encountered in practical applications. As shown in Table 7, we provide an overview of the performance of these models, aiming to help readers better understand their principles and applicable scenarios. Through this study, we can see that sentence vector matching methods based on large language models have become one of the important research directions in the field of NLP. These models not only improve the accuracy and efficiency of sentence matching but also provide rich feature representations for subsequent NLP tasks. With the continuous development of technology, we have reason to believe that these models will play an even more important role in future NLP research.
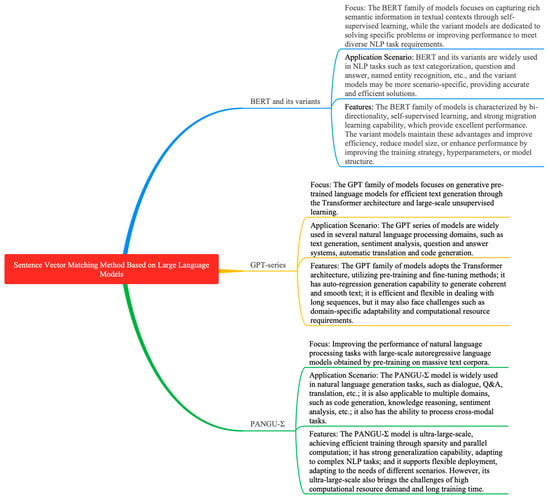
Figure 12.
Overview of logical relations of sentence vector matching method based on large language model.
Table 7.
Overview of key ideas, methods, key issues, and solutions based on large language model.
BERT [17], proposed by Devlin J et al., uses a bi-directional encoder and self-attention mechanism to capture deep semantic and contextual information of a text, which are pre-trained and fine-tuned to achieve efficient applications. However, there are problems such as a high consumption of computational resources and insufficient learning. Optimizing the algorithm and model structure, increasing the amount of data, and exploring new text-processing techniques can improve the performance and generalization of BERT. SpanBERT [18], proposed by Joshi M et al., improves the text representation by masking successive text segments and predicting the content, but it suffers from the problems of context-dependence and the stochasticity of the masking strategy. It is suggested to introduce an adaptive masking mechanism and balance multiple strategies, combining stable training and unsupervised pre-training tasks to improve the model’s stability and generalization ability. XLNet [19], proposed by Yang Z et al., improves text quality and accuracy by introducing causal and bi-directional contextual modeling and aligned language modeling, and although there are problems such as computational complexity, these can be solved by techniques such as an approximate attention mechanism to improve the model efficiency and performance. Liu Y et al. presented the study of Roberta [20] and pointed out that the hyperparameters and the amount of training data in BERT’s pre-training are crucial to the performance, and by replicating and adjusting the pre-training process, it was found that the performance of BERT could rival that of the subsequent models. However, there are problems such as an incomplete hyperparameter search and computational resource limitation. It is suggested to expand the search scope, use distributed computing, and combine advanced models and techniques to optimize its performance.
The GPT [21] model overcomes BERT’s limitations through an autoregressive structure and expanded vocabulary to generate coherent text sequences, which are applicable to a variety of NLP tasks. It faces the problems of data bias, dialog consistency, and long text processing, but these can be solved by diversifying the data, introducing a dialog history, and segmentation. GPT [21] possesses the advantages of text generation and still faces the challenges of long text processing and training complexity.
The GPT [21] model proposed by Radford A et al. is widely used and provides high-quality and adaptable text generation, but the results are inaccurate and inconsistent. It performs poorly on rare data. GPT2 [22] improves the text quality and diversity by increasing the model size and training data but still faces challenges. It can be improved by a bi-directional encoder, model compression, etc., and addressing concerns about security and ethical issues. GPT2 [22], proposed by Radford A et al., enhances the quality and diversity of text generation but suffers from a lack of accuracy and consistency. GPT3 [23], proposed by Brown T et al., further enhances its generation capability by increasing the size and training data, and it supports multi-tasking. However, it faces challenges such as a high cost and a lack of common sense and reasoning ability. An optimization of the model and attention to ethical norms are needed. GPT4 [24], proposed by Achiam J et al., demonstrates high intelligence, handles complex problems, and accepts multimodal inputs, but suffers from problems such as hallucinations and inference errors. It can be improved by adding more data, human intervention, and model updating. Meanwhile, optimizing its algorithms and quality control inputs can improve its accuracy and reliability; checking the data quality, increasing the dataset and number of training sessions, and using integrated learning techniques can also reduce the error rate and bias. The PANGU-Σ [25] model proposed by Ren X et al. adopts a scalable architecture and a distributed training system, and utilizes massive corpus in pre-training to improve the performance of NLP, but it faces challenges such as sparse architecture design, accurate feedback acquisition, and other challenges. These can be solved by optimizing its algorithms, improving data annotation and self-supervised learning, designing multimodal fusion networks, model compression, and optimization.
5.7. A Matching Method Based on a Large Language Model Utilizing Different Features
Typical models of matching methods based on large language models utilizing different features include the R2-Net [26], ASPIRE [27], DC-Match [28], and MCP-SM [29] models, as shown in Figure 13. This study outlines the key ideas, methods, key issues, and solutions for their fine-grained matching approaches, as shown in Table 8.
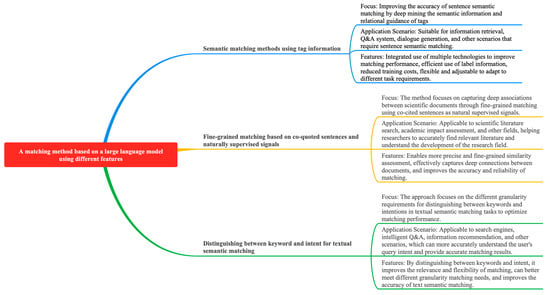
Figure 13.
Overview of the logical relationships of fine-grained matching methods.
Table 8.
Summary of key ideas, methods, key problems, and solutions for fine-grained matching methods.
Zhang K et al. [26] proposed to improve sentence semantic matching accuracy by deep mining label semantic information and relational guidance, combining global and local coding and self-supervised relational classification tasks to achieve significant results, but there are problems of model complexity, label quality, and hyperparameter tuning. Model compression, distributed computing, semi-supervised learning or migration learning, and automatic hyperparameter-tuning tools are suggested to solve these problems and improve the model’s performance and utility. Mysore S et al. [27] studied to achieve a fine-grained similarity assessment among scientific documents by utilizing paper co-citation sentences as a naturally supervised signal. The ASPIRE [27] method constructs multi-vector models to capture fine-grained matching at the sentence level but faces data sparsity, noise, and computational complexity issues. Data enhancement and filtering techniques can be used to improve its generalization ability, optimize the model structure, and reduce the complexity by using parallel computation to deal with a large-scale scientific corpus efficiently. Zou Y et al. study proposed a DC-Match [28] training strategy for different granularity requirements of query statements in text semantic matching tasks, which optimizes the matching performance by distinguishing between keywords and intent. However, DC-Match may face remote supervision information accuracy, computational complexity, and flexibility issues. It is suggested to optimize the resource selection and quality, adopt advanced remote supervision techniques, optimize the algorithm and model structure, utilize distributed computing techniques, and introduce domain-adaptive techniques to improve performance and adaptability. Yao D et al. propose a semantic matching method based on multi-concept parsing to reduce the dependence on traditional named entity recognition and improve the flexibility and accuracy of multilingual semantic matching. The method constructs a multi-concept parsing semantic matching framework (MCP-SM [29]), but faces concept extraction uncertainty, language and domain differences, and computational resource limitations. It is suggested to optimize the concept extraction algorithm, introduce multi-language and domain adaptation mechanisms, and optimize the model structure and computational process to improve the performance and applicability.
This study also compares the number of parameters, hardware equipment, training time, and context learning of recursive neural network matching methods, sentence vector matching methods based on large language models, and large language model-based matching methods utilizing different features, as shown in Table 9.
Table 9.
Comparison of hardware configurations and training details for matching models.
In terms of the number of model parameters, there is an overall increasing trend from recursive neural network-based matching methods to interactive matching methods, to sentence vector matching methods based on large language models. Specifically, the MKPM model based on the recurrent neural network has the least number of parameters, which is 1.8 M, while the number of parameters of GPT4 is the largest, reaching an amazing 1.8 T. In terms of hardware requirements, as the performance of the matching model gradually increases, the requirements for the performance of the graphics card show a corresponding trend of enhancement. This suggests that to effectively train these high-performance matching models, we need to equip more advanced graphics card devices. Meanwhile, in terms of training time, the training time required for sentence vector matching methods based on large language models is also increasing. Notably, these matching models are designed based on contextual learning, which helps them to better understand and process complex semantic information.
This paper delves into the performance comparison of different matching models on different datasets, aiming to provide researchers with a comprehensive and detailed analysis perspective. Through comparative experiments and data analysis, different matching models do have significant differences in performance, as shown in Table 10.
Table 10.
Performance comparison of matching models in different tasks.
The Pearson correlation (r), Spearman’s ρ, and MSE of MaLSTM on SICK were 0.8822, 0.8345, and 0.2286. The Acc of MaLSTM features + SVM was 84.2%. The GMN model based on the graph neural network had an accuracy of 84.2% and 84.6% on LCQMC and BQ, with F1 values of 84.1% and 86%. In the QQP dataset, we witness a gradual improvement in the accuracy of multiple matching methods. Initially, the recursive neural network-based matching method increases the accuracy to 89.03%, and then the interactive matching method further pushes this figure to 91.3%. Then, using the labeling information of the sentence pairs to be matched, the accuracy of the matching method climbed again to 91.6%. However, the fine-grained matching method, with its unique advantages, boosted the accuracy to a maximum of 91.8%, highlighting its sophistication in its current state. At the same time, the large language model shows performance growth on multiple datasets. Whether in MNLI, QQP, QNLI, COLA, or MRPC and RTE tasks, the big language model has grown in terms of GLUE scores, which fully proves the continuous improvement in the big language model’s performance. Of note is the performance of the GPT family of models on the dataset RTE. With the evolution from GPT to GPT3, the accuracy of the models also grows steadily, which fully demonstrates the continuous enhancement of the performance of the GPT series of models. In addition, the PANGU-sigma model shows a strong performance in several tasks. In CMNLI, OCNLI, AFQMC, and CSL tasks, it achieved accuracy rates of 51.14%, 45.97%, 68.49%, and 56.93%, respectively, which further validates its ability to handle complex tasks. In the fine-grained matching approach, our accuracy rate in the MRPC dataset is also further improved by introducing different large language models as skeletons. Specifically, the accuracies increased from 88.1% and 88.9% to 88.9% and 89.7%, and this enhancement again proves the effectiveness of the fine-grained matching approach.
This paper also outlines the APIs for the matching model, and different APIs have their advantages and disadvantages in terms of performance, ease of use, and scalability, and the selection of a suitable API (Application Programming Interface) depends on the specific application scenario and requirements, as shown in Table 11. These NLP APIs have their characteristics in several aspects, and by comparing them, we can draw the following similarities and differences. The similarity is that these APIs are launched by tech giants or specialized NLP technology providers with strong technical and R&D support capabilities. For example, Google Cloud Natural Language API, IBM Watson Natural Language Understanding API, Microsoft Azure Text Analytics API, and Amazon Comprehend API are the respective company’s flagship products in the NLP field, all of which reflect their deep technical accumulation and R&D capabilities. In addition, most of the APIs support multi-language processing, covering major languages such as English and Chinese to meet the needs of different users. Whether it is a sentiment analysis of English text or an entity recognition of Chinese text, these APIs can provide effective support. In terms of interface design, these APIs are usually designed with RESTful interfaces, enabling developers to integrate and invoke them easily. This standardized interface design reduces the learning cost of developers and improves development efficiency. In terms of application scenarios, these APIs are suitable for NLP tasks such as text analysis, sentiment analysis, entity recognition, etc., and can be applied to multiple industries and scenarios. Whether it is the analysis of product reviews on e-commerce platforms or the monitoring of public opinion in news media, these APIs can provide strong support.
Table 11.
Comparison of matching model APIs.
However, there are some differences in these APIs. First, API-providing companies may differ in their focus and expertise in NLP. For example, the Google Cloud Natural Language API excels in syntactic analysis and semantic understanding, while IBM Watson is known for its powerful natural language generation and dialog system. Second, while both support multilingual processing, the specific types of languages supported, and the level of coverage may vary. Some APIs may be optimized for specific languages or regions, to better suit the local culture and language habits. In terms of interface types, while most APIs utilize RESTful interfaces, some APIs may also provide other types of interfaces, such as SDKs or command-line tools. For example, Hugging Face Transformers provides a rich SDK and model library, enabling developers to train and deploy models more flexibly. Each API may also have a focus in terms of application scenarios. For example, some APIs may specialize in sentiment analysis, which can accurately identify emotional tendencies in a text, while others may focus more on entity recognition or text classification tasks, which can accurately extract key information in a text. In the marketplace, certain APIs are more advantageous due to their brand recognition, technological prowess, or marketing strategies. However, this advantage may change as technology evolves and the market changes. Therefore, developers need to consider several factors when choosing an NLP API, including technical requirements, budget constraints, data privacy, and security. In addition, each API may have some drawbacks or limitations. For example, some APIs may face performance bottlenecks and be unable to handle large-scale text data; or the accuracy of some APIs may be affected by specific domain or language characteristics. Therefore, developers need to fully understand the advantages and disadvantages of NLP APIs when choosing them, and combine them with their actual needs.
6. Comparison of Different Matching Models across Datasets and Evaluation Methods
This section focuses on outlining the performance of different matching models on different datasets as shown in Table 12. From the perspective of datasets, English datasets are widely used in matching models, while Chinese datasets are relatively few, mainly including OCNLI, LCQMC, BQ, Medical-SM, and Ant Financial. From the perspective of modeling, recursive neural network-based matching methods are mainly applied to natural language inference and implication (NLI) datasets such as SNLI and SciTail, and Q&A and matching datasets such as QQP, LCQM, and BQ. Interactive matching methods are mainly focused on NLI datasets such as SNLI and Q&A and matching datasets such as Trec-QA and WikiQA. Graph neural network matching methods are mainly applied to Q&A and matching datasets such as LCQMC and BQ, while fine-grained matching methods are widely applied to NLI datasets such as XNLI, Q&A, and matching datasets such as QQP, MQ2Q, etc., as well as other specific datasets such as MRPC and Medcial-SM. Semantic matching methods utilizing label information are mainly applied to NLI datasets such as SNLI and SciTech, SNLI and SciTail, and Q&A and matching datasets such as QQP. As for the matching methods based on large language models, their application scope is even wider, covering NLI datasets such as MNLI and QNLI, Q&A and matching datasets such as QQP, the sentiment analysis dataset SST-2, and other specific datasets such as MRPC and COLA. To summarize, different matching models are applied to all kinds of datasets, but the English dataset is more commonly used. The models perform well on specific datasets and provide strong support for the development of the natural language processing field.
Table 12.
Comparison of different matching model training datasets and evaluation methods.
From the perspective of evaluation metrics, when discussing the evaluation metrics for the sentence-matching task in Table 12, this study needs to first clarify the definition of each metric, as well as their applicability and effectiveness in different scenarios. First, accuracy (Acc) is a basic categorization evaluation metric, which is defined as the proportion of samples correctly predicted by the model to the total number of samples. In the sentence-matching task, when the distribution of positive and negative samples is more balanced, the accuracy rate can intuitively reflect the performance of the model. However, when faced with category imbalance, the accuracy rate may not accurately assess the effectiveness of the model.
For the regression prediction task of sentence similarity scores, the Pearson correlation (r) and Spearman’s ρ are two important evaluation metrics. The Pearson correlation (r) measures the strength and direction of a linear relationship between two continuous variables, while Spearman’s ρ measures the strength and direction of a monotonic relationship between two variables, which is less demanding on the distributional pattern of the data. These two metrics are useful in assessing the relationship between predicted and true scores. The Mean Square Error (MSE) is another commonly used metric for regression assessment, which calculates the mean of the squares of the differences between the predicted and true values. In the regression task of sentence similarity scoring, the MSE can directly reflect the accuracy of the model’s predicted scores. For the binary classification task of sentence matching, especially when the distribution of positive and negative samples is not balanced, the F1 score is a more accurate evaluation metric. It combines precision and recall and comprehensively evaluates the model’s performance by calculating the reconciled average of the two.
When the sentence-matching task involves ranking multiple queries or sentence pairs, the Mean Average Precision (MAP) and Mean Reverse Ranking (MRR) are two important evaluation metrics. MAP is used to evaluate the average precision of multiple queries, while MRR computes the average of the reverse of the first relevant result ranking across all queries. These two metrics are effective in evaluating the performance of the model in ranking results. The Macro-F1 is an evaluation metric for multi-category sentence-matching tassk. When calculating the F1 score, it calculates the F1 score for each category separately and then averages the scores, regardless of the sample size of the categories. This allows Macro-F1 to treat each category equally and is suitable for sentence-matching tasks where the performances of multiple categories need to be considered together. GLUE (General Language Understanding Evaluation) is a benchmark evaluation suite that includes a range of natural language understanding tasks. If a sentence-matching task is included in the GLUE suite, we can use the evaluation metrics provided (e.g., accuracy, F1 score, etc.) to evaluate the performance of the model. Finally, metrics such as MC/F1/PC may be acronyms or specific metrics under a particular task or dataset. In the absence of a specific context, they may stand for accuracy (MC may be an abbreviation for Multi-Class), F1 score, or some kind of precision. Depending on the specific task and dataset, these metrics may be used to evaluate different aspects of the performance of the sentence-matching model. By using a combination of these evaluation metrics, we can gain a more comprehensive understanding of the performance of sentence-matching models and optimize the model design accordingly.
7. Field-Specific Applications
This section provides insights into the wide range of applications of matching methods in different domains, especially in education, healthcare, economics, industry, agriculture, and natural language processing. Through the detailed enumeration in Table 12, we can clearly see the main contributions of matching models within each domain, as well as reveal the limitations they may encounter in practical applications and potential future research directions. In the exploration of text-matching techniques, we recognize their central role in several practical scenarios, especially in the key tasks of natural language processing, such as named entity recognition and named entity disambiguation. To gain a more comprehensive understanding of the current status and trends of these techniques, we have expanded the scope of our literature review to cover research results in these areas. Named entity recognition (NER) [104] is a crucial task in natural language processing, whose goal is to accurately identify entities with specific meanings, such as names of people, places, organizations, etc., from the text. In recent years, with the continuous development of deep learning technology, the field of NER has made significant progress. Meanwhile, named entity disambiguation [105] (NED) is also an important research direction in the field of natural language processing. It aims to solve the problem that the same named entity may refer to different objects in different contexts, to improve the accuracy and efficiency of natural language processing. In summary, matching methods and text-matching techniques have a wide range of application prospects and an important research value in several fields. (See Table 13).
Table 13.
Field-specific application of text matching.
In education, matching technologies have significantly improved planning efficiency by automatically aligning learning objectives within and outside of subjects. In addition, the design of data science pipelines has enabled the analysis of learning objective similarities and the identification of subject clustering and dependencies. Meanwhile, text-matching software has demonstrated its versatility by being used not only as a tool for educating students but also for detecting inappropriate behavior. In the medical field, matching technology provides powerful support for doctors. It is used in the retrieval and generation of radiology reports, in the linking of medical text entities, and in Q&A systems to help doctors carry out their diagnosis and treatment more efficiently. In the economic domain, matching technology provides powerful support for the accurate provision of job information, the formulation of industry-specific recommendations, and the promotion of policy tourism and economic cooperation. Especially in the e-commerce field, matching technology has made a big difference, not only improving the accuracy of matching product titles in online shops and e-commerce platforms so that users can find the products they need more quickly but also significantly improving the efficiency and accuracy of product retrieval in the e-commerce industry. In addition, matching technology also solves the problem of duplicate product detection in online shops, which improves the operational efficiency and market competitiveness of the platform.
In the industrial field, text-matching technology is applied to robots, which enhances the model’s ability to understand the real scene and promotes the development of industrial automation. In the field of agriculture, the application of text-matching methods improves the retrieval efficiency of digital agricultural text information and provides an effective method for the scientific retrieval of agricultural information. In named entity recognition, named entity disambiguation, author name disambiguation, and historical documents in natural language processing, matching techniques play a crucial role. In named entity recognition, the matching technique, which dynamically adjusts visual information, can more effectively fuse the semantic information of text and images to improve the accuracy of recognition. In this process, the cross-modal alignment (CA) module plays a key role, narrowing the semantic gap between the two modalities of text and image, making the recognition results more accurate. In named entity disambiguation, the matching technique is also crucial. By exploiting the semantic similarity in the knowledge graph, the same entity in different contexts can be judged more accurately for disambiguation. In addition, the embedding model of joint learning also provides strong support for entity disambiguation, improving the performance of entity disambiguation by capturing the intrinsic relationship between entities. In summary, matching techniques play a crucial role in the field of named entity recognition and named entity disambiguation, which not only improves the accuracy of recognition but also provides strong support for other tasks in natural language processing.
In author name disambiguation, LightGBM creates a paper similarity matrix and hierarchical clustering method (HAC) for clustering, which enables paper clustering to be implemented more accurately and efficiently, thus avoiding the problem of over-merging papers. The automatic segmentation of words in damaged and deformed historical documents is achieved based on cross-document word matching in historical documents. An image analysis method based on online and sub-pattern detection is successfully applied to pattern matching and duplicate pattern detection in Islamic calligraphy (Kufic script) images. Through the above analyses, matching techniques have shown a wide range of application prospects and significant results in different fields, but at the same time, there are some limitations and challenges that require further research and exploration. To enable the text-matching technique to be applied in the specific application areas mentioned above, this study provides practical insights or guidelines for implementing the sentence-matching technique in real-world applications, including some hints on hardware requirements, software tools, and optimization strategies.
When implementing sentence-matching technology in the specific application areas mentioned above, it is first necessary to define the specific application requirements, including application scenarios, the desired accuracy, and response time. These requirements will directly guide the subsequent technology selection and model design. Subsequently, a high-quality, clearly labeled dataset is the basis for training an efficient sentence-matching model, so the data preparation stage is crucial. In terms of hardware, to meet the training and inference needs of deep learning models, it is recommended to choose servers equipped with high-performance GPUs or utilize cloud computing services. Meanwhile, a sufficient memory is essential to support data loading and computation during model training and inference. For storage needs, it is recommended to use high-speed SSD hard disks or distributed storage systems to accommodate huge datasets and model files.
In terms of software tool selection, deep learning frameworks such as TensorFlow and PyTorch are indispensable tools that provide a rich set of APIs and tools that greatly simplify the model development and deployment process. Text-processing libraries such as NLTK and spaCy, on the other hand, can help us efficiently perform text preprocessing and feature extraction. In addition, the combination of pre-trained models and specialized semantic matching tools, such as BERT [17] and Roberta [20], can further improve the accuracy of sentence matching.
To further improve the performance of the model, we can employ a series of optimization strategies. Data enhancement techniques [63] can increase the diversity of training data and improve the generalization ability of the model. Model compression techniques [75] can reduce the size and computations of the model, thus speeding up the inference. Multi-stage training strategies, especially pre-training and fine-tuning, can make full use of large-scale unlabeled data and small amounts of labeled data. Integrated learning [58] can further improve sentence-matching accuracy by combining predictions from multiple models. Finally, hardware optimization techniques such as GPU acceleration and distributed computing can be utilized to significantly improve the efficiency of model training and inference.
8. Open Problems and Challenges
8.1. Limitations of State-of-the-Art Macro Models in Sentence-Matching Tasks
Despite the dominance of the BERT [17] family and its improved versions in sentence-matching tasks, some state-of-the-art macro models, such as GPT4 [24] and GPT-5, are currently difficult to apply in sentence-matching tasks due to their not-yet-open-source nature. This limits to some extent the possibility that sentence-matching tasks can be advanced and developed using new technologies.
The application of state-of-the-art macro models to sentence-matching tasks is limited by multiple challenges. Among them, the issue of model openness driven by commercial interests is particularly critical. These models are usually owned by large technology companies or research organizations as a core competency and thus are not readily made public. Even partial disclosure may be accompanied by usage restrictions and high licensing fees, making it unaffordable for researchers and small developers. This openness issue not only limits the wide application of the model in sentence-matching tasks but also may hinder research progress in the field. The lack of support from advanced models makes it difficult for researchers to make breakthroughs in sentence-matching tasks and to fully utilize the potential capabilities of these models. Therefore, addressing the issue of model openness driven by commercial interests is crucial to advancing research and development in sentence-matching tasks.
8.2. Model-Training Efficiency of Sentence-Matching Methods
Most of the sentence-matching methods are based on large language models, which leads to high requirements on device memory during the training process, and the training time is up to several hours or even dozens of hours. This inefficient training process not only increases the consumption of computational resources but also limits the rapid deployment and iteration of the model in real applications. Therefore, we need to investigate how to optimize the model-training process, improve the training efficiency, and reduce the dependence on device memory, as well as reducing the training time.
It is difficult to solve the problem of the model-training efficiency of sentence-matching methods, mainly because of the following reasons: the high complexity of large language models leads to a large demand for memory, which poses a challenge to users with limited hardware; the training time is long, and the processing of a large amount of data requires multiple rounds of iterations, which consumes computational resources and affects the efficiency; how to reduce the dependence on memory and the training time, while guaranteeing performance, involves many technical challenges in terms of the model structure, the algorithm design, and data processing.
8.3. Assertion Comprehension and Non-Matching Information Interference in Sentence Matching
A key challenge in the sentence-matching task is the lack of in-depth understanding of the sentence claim, while being susceptible to interference from non-matching information. Sentence claims are the embodiment of the core meaning of a sentence, while noisy information or non-matching content may mislead the matching process. To address this problem, research is needed to design more effective model architectures or introduce new semantic understanding mechanisms to enhance the capture and recognition of sentence claims, while reducing the interference of non-matching information.
The main challenges of claim comprehension and non-matching information interference in sentence matching are the complexity and subtlety of sentence claim comprehension, which require the model to deeply analyze the semantics and context of the sentence; at the same time, non-matching information interference is difficult to overcome, as it requires the model to have a strong semantic differentiation ability to filter the interfering content. Therefore, solving these problems requires the model to realize significant breakthroughs in semantic understanding and information filtering.
8.4. Confusion or Omission in Handling Key Detail Facts
Key Detail Facts in Sentence-Matching Processing Detail information is crucial for accurate matching in sentence-matching tasks [121]. However, existing methods for sentence matching often suffer from the problem of confusion or omission when dealing with key detail facts. Losing certain detailed information may lead to inaccurate matching results. Therefore, there is a need to investigate how to optimize sentence-matching algorithms to capture and process key detail facts more accurately. This may involve the optimization of extraction, representation, and matching strategies for detailed information.
The main difficulties in processing key detail facts in sentence-matching tasks are the accurate extraction of detail information, effective representation, and the optimization of matching strategies. Due to the diversity and complexity of languages, it is extremely challenging to extract key details in sentences; meanwhile, existing methods may not be able to fully capture the full meaning of the detail information, leading to confusion or omission during the matching process; in addition, it is also a major challenge to design a matching strategy that can fully take into account the importance of the detail information, which may lead to inaccurate matching results.
8.5. Diversity and Balance Challenges of Sentence-Matching Datasets
Currently, most sentence-matching datasets focus on the English domain, while there are relatively few Chinese datasets. In addition, there is a relative lack of application-specific datasets to meet the application requirements in different scenarios. This imbalance and lack of datasets limit the generalization ability and application scope of sentence-matching models. Therefore, there is a need to work on constructing and expanding diverse and balanced sentence-matching datasets, especially increasing Chinese datasets and datasets of specific application domains, to promote the development and application of sentence-matching technology.
The diversity and balance challenges of sentence-matching datasets are significant, and are mainly reflected in the uneven distribution of languages, the lack of application-specific datasets, and the difficulty of guaranteeing the balance of datasets, etc. English datasets are relatively rich, while Chinese and other language datasets are scarce, which limits the generalization ability of the model in different languages. Meanwhile, the lack of domain-specific datasets results in limited model performance in specific scenarios. In addition, constructing a balanced dataset faces difficulties in data collection and labeling, and an unbalanced dataset may affect the training effect and matching accuracy of the model.
9. Future Research Directions
9.1. Future Research Direction I: The Problem of Sentence-Matching Model Publicity Driven by Commercial Interests and Solutions
Future research directions should focus on solving the problem of model openness driven by commercial interests, promoting open-source models and community construction, innovating model authorization and sharing mechanisms, strengthening privacy protection and model security, optimizing model performance and adaptive capability, and strengthening interdisciplinary cooperation and innovative applications to promote the research and development of sentence-matching tasks.
9.2. Future Research Directions II: Optimization Strategies That Focus on Model-Training Efficiency for Sentence-Matching Methods
Many users face the problem of a low training efficiency due to the high complexity of large language models, the high memory requirements, and long training time. To address this challenge, future research will explore the lightweight design of the model structure, the efficient tuning of algorithms, and the improvement of data-processing techniques. By optimizing the model structure, adopting efficient algorithms, and fine-tuning the data processing, we aim to reduce memory dependency and training time, thus promoting the development and application of sentence-matching techniques. These optimization strategies will help address current and future training efficiency issues and promote continued progress in the field of sentence matching.
9.3. Future Research Directions III: Optimization Strategies Focusing on the Efficiency of Model Training for Sentence-Matching Methods
These two challenges place high demands on the model’s semantic comprehension and information-filtering abilities. Propositional understanding is the core problem, which requires the model to deeply parse the semantic and contextual information of sentences to capture and understand deeper meanings and subtle differences. However, existing models have limitations in semantic understanding. Meanwhile, the interference of non-matching information is also a major challenge, and the model needs to filter out irrelevant information and focus only on matching key content. However, the existing models are still insufficient in dealing with interference. Therefore, future research should be devoted to improving the model’s semantic understanding and information-filtering capabilities, to better address these two challenges and promote new progress in the research and application of sentence-matching tasks.
9.4. Future Research Direction IV: Difficulties and Breakthroughs in Processing Key Detail Facts in Sentence-Matching Tasks
Sentence-matching tasks face multiple challenges in processing key detail facts, including the extraction of detailed information, representation, and the optimization of matching strategies. First, accurately extracting key detail information in sentences is a basic but challenging task. Due to the complexity and diversity of language, it is often difficult for existing methods to capture these details comprehensively, leading to confusion or omission in the matching process. Therefore, future research should explore more efficient information extraction techniques, such as utilizing recent advances in deep learning or natural language processing to enhance the ability to capture detailed information. Second, effective representation of this critical detail information is crucial for matching. Existing representation methods may not be able to convey the meaning of detailed information completely, leading to matching bias. Therefore, research should focus on more advanced representation-learning techniques, such as distributed representation or representation models that incorporate contextual information, to reflect the connotations of detailed information more accurately. Finally, the optimization of matching strategies is equally critical. Existing strategies often ignore the importance of detailed information, leading to inaccurate matching results. Future research should explore smarter matching strategies, such as using the attention mechanism to emphasize the role of key details in matching or combining machine learning techniques to automatically learn the optimal matching strategy.
9.5. Future Research Direction V: Addressing the Challenges of Diversity and Balance in Sentence-Matching Datasets
Although sentence-matching tasks are widely used, the diversity and balance of datasets are still the key challenges for performance improvement and generalization ability. Currently, English datasets are relatively rich, while Chinese and other languages are relatively scarce, which limits the model’s matching ability in different languages. At the same time, datasets for specific domains such as finance, healthcare, law, etc., are also insufficient, which limits the application of the model in these domains. In addition, the problem of dataset balance is an important factor that affects the model-training effect and matching accuracy. Therefore, future research should focus on constructing multilingual and domain-specific datasets, such as generating data using GPT4 [24] and GPT5, and exploring effective data-balancing methods, such as over-sampling, under-sampling, and adopting appropriate loss functions, to improve the model’s matching performance and generalization ability. These efforts will help promote the application of sentence-matching techniques in more languages and domains and facilitate the continuous development of the natural language processing field.
10. Conclusions
Text-matching technology has experienced a stepwise development from character-based matching methods, recursive neural network-based matching methods, and sentence vector matching methods based on large models, to large model-based matching methods utilizing different fine-grained features, and it has made significant progress. While string-based methods are simple and intuitive, they lack an in-depth understanding of semantics, while corpus-based methods make up for this by utilizing large-scale data to capture semantic relationships. With the development of deep learning, recurrent neural networks and sentence semantic interaction matching methods can further capture the hierarchical structure of text and contextual information, improving the accuracy of matching. However, these methods have high computational complexity. Graph structure-based matching methods are suitable for specific tasks such as relationship extraction but are challenging for unstructured text processing. In recent years, with improvements in arithmetic power and the enhancement of data resources, sentence vector matching methods based on large language models capture rich sentence semantic information through large-scale corpus pre-training and then utilize it to directly complete the calculation of the matching probability. In addition, large model-based matching methods utilizing different fine-grained features can accurately capture differences, but the computational complexity is also higher. These methods are developing in a complementary way, and jointly promote the progress of text-matching technology. In the future, with the promotion of downstream applications, matching technology will make breakthroughs in multimodal matching, model optimization, multi-granularity semantic understanding, and the domain adaptability of images, videos, and texts, which will further promote the development of matching technology and bring broader application prospects for its downstream applications.
Author Contributions
Conceptualization, P.J. and X.C.; methodology, P.J. investigation, P.J.; resources, X.C.; data curation, P.J.; writing—original draft preparation, P.J.; writing—review and editing, P.J.; visualization, X.C.; supervision, X.C.; project administration, X.C.; funding acquisition, X.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research is supported by the intelligent integrated media platform r&d and application demonstration project (PM21014X).
Data Availability Statement
Not applicable.
Conflicts of Interest
The author(s) declare no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
References
- Hunt, J.W.; Szymanski, T.G. A Fast Algorithm for Computing Longest Common Subsequences. Commun. ACM 1977, 20, 350–353. [Google Scholar] [CrossRef]
- Levenshtein, V.I. Binary Codes Capable of Correcting Deletions, Insertions, and Reversals. Sov. Phys. Dokl. 1966, 10, 707–710. [Google Scholar]
- Winkler, W.E. String Comparator Metrics and Enhanced Decision Rules in the Fellegi-Sunter Model of Record Linkage. 1990. Available online: https://files.eric.ed.gov/fulltext/ED325505.pdf (accessed on 21 May 2024).
- Dice, L.R. Measures of the Amount of Ecologic Association between Species. Ecology 1945, 26, 297–302. [Google Scholar] [CrossRef]
- Jaccard, P. The Distribution of the Flora in the Alpine Zone. 1. New Phytol. 1912, 11, 37–50. [Google Scholar] [CrossRef]
- Salton, G.; Buckley, C. Term Weighting Approaches in Automatic Text Retrieval. Inf. Process. Manag. 1988, 24, 513–523. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Landauer, T.K.; Foltz, P.W.; Laham, D. An Introduction to Latent Semantic Analysis. Discourse Process. 1998, 25, 259–284. [Google Scholar] [CrossRef]
- Mueller, J.; Thyagarajan, A. Siamese Recurrent Architectures for Learning Sentence Similarity. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 2786–2792. [Google Scholar]
- Neculoiu, P.; Versteegh, M.; Rotaru, M. Learning Text Similarity with Siamese Recurrent Networks. In Proceedings of the 1st Workshop on Representation Learning for NLP, Berlin, Germany, 11 August 2016; pp. 148–157. [Google Scholar]
- Lu, X.; Deng, Y.; Sun, T.; Gao, Y.; Feng, J.; Sun, X.; Sutcliffe, R. MKPM: Multi Keyword-Pair Matching for Natural Language Sentences. Appl. Intell. 2022, 52, 1878–1892. [Google Scholar] [CrossRef]
- Deng, Y.; Li, X.; Zhang, M.; Lu, X.; Sun, X. Enhanced Distance-Aware Self-Attention and Multi-Level Match for Sentence Semantic Matching. Neurocomputing 2022, 501, 174–187. [Google Scholar] [CrossRef]
- Kim, S.; Kang, I.; Kwak, N. Semantic Sentence Matching with Densely-Connected Recurrent and Co-Attentive Information. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence, Hilton Hawaiian Village, Honolulu, HI, USA, 27 January–1 February 2019; pp. 6586–6593. [Google Scholar]
- Zhang, K.; Lv, G.; Wang, L.; Wu, L.; Chen, E.; Wu, F.; Xie, X. Drr-Net: Dynamic Re-Read Network for Sentence Semantic Matching. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence, Hilton Hawaiian Village, Honolulu, HI, USA, 27 January–1 February 2019; pp. 7442–7449. [Google Scholar]
- Wang, Z.; Hamza, W.; Florian, R. Bilateral Multi-Perspective Matching for Natural Language Sentences. arXiv 2017, arXiv:1702.03814. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Joshi, M.; Chen, D.; Liu, Y.; Weld, D.S.; Zettlemoyer, L.; Levy, O. Spanbert: Improving Pre-Training by Representing and Predicting Spans. Trans. Assoc. Comput. Linguist. 2020, 8, 64–77. [Google Scholar] [CrossRef]
- Yang, Z.L.; Dai, Z.H.; Yang, Y.M.; Carbonell, J.; Salakhutdinov, R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. arXiv 2019, arXiv:1906.08237. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A Robustly Optimized Bert Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://www.mikecaptain.com/resources/pdf/GPT-1.pdf (accessed on 21 May 2024).
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models Are Unsupervised Multitask Learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A. Language Models Are Few-Shot Learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Achiam, J.; Adler, J.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S. GPT-4 Technical Report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Ren, X.; Zhou, P.; Meng, X.; Huang, X.; Wang, Y.; Wang, W.; Li, P.; Zhang, X.; Podolskiy, A.; Arshinov, G. PanGu-{\Sigma}: Towards Trillion Parameter Language Model with Sparse Heterogeneous Computing. arXiv 2023, arXiv:2303.10845. [Google Scholar]
- Zhang, K.; Wu, L.; Lv, G.Y.; Wang, M.; Chen, E.H.; Ruan, S.L.; Assoc Advancement Artificial, I. Making the Relation Matters: Relation of Relation Learning Network for Sentence Semantic Matching. In Proceedings of the Thirty-Fifth AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021; pp. 14411–14419. [Google Scholar]
- Mysore, S.; Cohan, A.; Hope, T. Multi-Vector Models with Textual Guidance for Fine-Grained Scientific Document Similarity. arXiv 2021, arXiv:2111.08366. [Google Scholar]
- Zou, Y.; Liu, H.; Gui, T.; Wang, J.; Zhang, Q.; Tang, M.; Li, H.; Wang, D.; Assoc Computa, L. Divide and Conquer: Text Semantic Matching with Disentangled Keywords and Intents. In Proceedings of the 60th Annual Meeting of the Association-for-Computational-Linguistics, Dublin, Ireland, 22–27 May 2022; pp. 3622–3632. [Google Scholar]
- Yao, D.; Alghamdi, A.; Xia, Q.; Qu, X.; Duan, X.; Wang, Z.; Zheng, Y.; Huai, B.; Cheng, P.; Zhao, Z. A General and Flexible Multi-Concept Parsing Framework for Multilingual Semantic Matching. arXiv 2024, arXiv:2403.02975. [Google Scholar]
- Asha, S.; Krishna, S.T. Semantics-Based String Matching: A Review of Machine Learning Models. Int. J. Intell. Syst. 2024, 12, 347–356. [Google Scholar]
- Hu, W.; Dang, A.; Tan, Y. A Survey of State-of-the-Art Short Text Matching Algorithms. In Proceedings of the Data Mining and Big Data: 4th International Conference, Chiang Mai, Thailand, 26–30 July 2019; pp. 211–219. [Google Scholar]
- Wang, J.; Dong, Y. Measurement of Text Similarity: A Survey. Information 2020, 11, 421. [Google Scholar] [CrossRef]
- Deza, E.; Deza, M.M.; Deza, M.M.; Deza, E. Encyclopedia of Distances. In Encyclopedia of Distances; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1–583. [Google Scholar]
- Li, B.; Han, L. Distance Weighted Cosine Similarity Measure for Text Classification. In Proceedings of the Intelligent Data Engineering and Automated Learning—IDEAL 2013: 14th International Conference, Hefei, China, 20–23 October 2013; pp. 611–618. [Google Scholar]
- Sidorov, G.; Gelbukh, A.; Gómez-Adorno, H.; Pinto, D. Soft Similarity and Soft Cosine Measure: Similarity of Features in Vector Space Model. Comput. Sist. 2014, 18, 491–504. [Google Scholar] [CrossRef]
- Dean, J.; Ghemawat, S. Mapreduce: Simplified Data Processing on Large Clusters. Commun. ACM 2008, 51, 107–113. [Google Scholar] [CrossRef]
- Bejan, I.; Sokolov, A.; Filippova, K. Make Every Example Count: On Stability and Utility of Self-Influence for Learning from Noisy NLP Datasets. arXiv 2023, arXiv:2302.13959. [Google Scholar]
- Yedidia, J.S.; Freeman, W.T.; Weiss, Y. Understanding Belief Propagation and Its Generalizations. Explor. Artif. Intell. New Millenn. 2003, 8, 0018–9448. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Robertson, S.E.; Walker, S. Some Simple Effective Approximations to the 2-Poisson Model for Probabilistic Weighted Retrieval. In Proceedings of the International ACM Sigir Conference on Research and Development in Information Retrieval SIGIR ‘94, Dublin, Ireland, 3–6 July 1994; pp. 232–241. [Google Scholar]
- Katz, S. Estimation of Probabilities from Sparse Data for the Language Model Component of a Speech Recognizer. IEEE Trans. Acoust. Speech Signal Process. 1987, 35, 400–401. [Google Scholar] [CrossRef]
- Akritidis, L.; Alamaniotis, M.; Fevgas, A.; Tsompanopoulou, P.; Bozanis, P. Improving Hierarchical Short Text Clustering through Dominant Feature Learning. Int. J. Artif. Intell. Tools 2022, 31, 2250034. [Google Scholar] [CrossRef]
- Bulsari, A.B.; Saxen, H. A recurrent neural network model. In Proceedings of the 1992 International Conference (ICANN-92), Brighton, UK, 4–7 September 1992; pp. 1091–1094. [Google Scholar]
- Peters, M.; Neumann, M.; Iyyer, M.; Gardner, M.; Zettlemoyer, L. Deep Contextualized Word Representations. arXiv 2018, arXiv:1802.05365. [Google Scholar]
- Levy, O.; Goldberg, Y. Dependency-Based Word Embeddings. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: Tutorials, Baltimore, MD, USA, 22 June 2014; pp. 302–308. [Google Scholar]
- Le, Q.; Mikolov, T. Distributed Representations of Sentences and Documents. In Proceedings of the International Conference on Machine Learning, Beijing, China, 22–24 June 2014; pp. 1188–1196. [Google Scholar]
- Chen, M. Efficient Vector Representation for Documents through Corruption. arXiv 2017, arXiv:1707.02377. [Google Scholar]
- Petroni, F.; Rocktäschel, T.; Lewis, P.; Bakhtin, A.; Wu, Y.; Miller, A.H.; Riedel, S. Language Models as Knowledge Bases? arXiv 2019, arXiv:1909.01066. [Google Scholar]
- Guyon, I.; Elisseeff, A. An Introduction to Variable and Feature Selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Tabassum, A.; Patil, R.R. A Survey on Text Pre-Processing & Feature Extraction Techniques in Natural Language Processing. Int. Res. J. Eng. Technol. 2020, 7, 4864–4867. [Google Scholar]
- Elsafty, A. Document Similarity Using Dense Vector Representation. 2017. Available online: https://www.inf.uni-hamburg.de/en/inst/ab/lt/teaching/theses/completed-theses/2017-ma-elsafty.pdf (accessed on 22 May 2024).
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M.; Furht, B. Text Data Augmentation for Deep Learning. J. Big Data 2021, 8, 34. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q.A. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Liu, M.; Zhang, Y.; Xu, J.; Chen, Y. Deep Bi-Directional Interaction Network for Sentence Matching. Appl. Intell. 2021, 51, 4305–4329. [Google Scholar] [CrossRef]
- Park, D.S.; Chan, W.; Zhang, Y.; Chiu, C.C.; Zoph, B.; Cubuk, E.D.; Le, Q.V.; Int Speech Commun, A. SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition. arXiv 2019, arXiv:1904.08779. [Google Scholar]
- Peng, S.; Cui, H.; Xie, N.; Li, S.; Zhang, J.; Li, X. Enhanced-RCNN: An Efficient Method for Learning Sentence Similarity. In Proceedings of the Web Conference 2020: Proceedings of the World Wide Web Conference WWW 2020, Taipei, Taiwan, 20–24 April 2020; pp. 2500–2506. [Google Scholar]
- Mahajan, P.; Uddin, S.; Hajati, F.; Moni, M.A. Ensemble Learning for Disease Prediction: A Review. Healthcare 2023, 11, 1808. [Google Scholar] [CrossRef]
- Zhu, G.; Iglesias, C.A. Computing Semantic Similarity of Concepts in Knowledge Graphs. IEEE Trans. Knowl. Data Eng. 2016, 29, 72–85. [Google Scholar] [CrossRef]
- Chen, L.; Zhao, Y.; Lyu, B.; Jin, L.; Chen, Z.; Zhu, S.; Yu, K. Neural Graph Matching Networks for Chinese Short Text Matching. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 6–8 July 2020; pp. 6152–6158. [Google Scholar]
- Dean, J.; Corrado, G.; Monga, R.; Chen, K.; Devin, M.; Mao, M.; Ranzato, M.; Senior, A.; Tucker, P.; Yang, K. Large Scale Distributed Deep Networks. In Proceedings of the Advances in Neural Information Processing Systems 25: 26th Annual Conference on Neural Information Processing Systems 2012, Lake Tahoe, NV, USA, 3–6 December 2012; Volume 25. [Google Scholar]
- Goldar, P.; Rai, Y.; Kushwaha, S. A Review on Parallelization of Big Data Analysis and Processing. IJETCSE 2016, 23, 60–65. [Google Scholar]
- Pluščec, D.; Šnajder, J. Data Augmentation for Neural NLP. arXiv 2023, arXiv:2302.11412. [Google Scholar]
- Jacob, B.; Kligys, S.; Chen, B.; Zhu, M.; Tang, M.; Howard, A.; Adam, H.; Kalenichenko, D. Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2704–2713. [Google Scholar]
- Han, S.; Pool, J.; Tran, J.; Dally, W.J. Learning Both Weights and Connections for Efficient Neural Networks. In Proceedings of the 29th Annual Conference on Neural Information Processing Systems (NIPS), Palais des Congrès de Montréal Convention and Exhibition Center, Montreal, QC, Canada, 8–10 December 2015; Volume 28. [Google Scholar]
- Chen, Z.; Qu, Z.; Quan, Y.; Liu, L.; Ding, Y.; Xie, Y. Dynamic n: M Fine-Grained Structured Sparse Attention Mechanism. In Proceedings of the 28th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming, Montreal, QC, Canada, 25 February–1 March 2023; pp. 369–379. [Google Scholar]
- Tenney, I.; Das, D.; Pavlick, E. BERT Rediscovers the Classical NLP Pipeline. arXiv 2019, arXiv:1905.05950. [Google Scholar]
- Howard, J.; Ruder, S. Universal Language Model Fine-Tuning for Text Classification. arXiv 2018, arXiv:1801.06146. [Google Scholar]
- Fedus, W.; Goodfellow, I.; Dai, A.M. Maskgan: Better Text Generation via Filling in the _. arXiv 2018, arXiv:1801.07736. [Google Scholar]
- Dai, Z.H.; Yang, Z.L.; Yang, Y.M.; Carbonell, J.; Le, Q.V.; Salakhutdinov, R. Acl Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context. In Proceedings of the 57th Annual Meeting of the Association-for-Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 2978–2988. [Google Scholar]
- He, M.; Liu, Y.; Wu, B.; Yuan, J.; Wang, Y.; Huang, T.; Zhao, B. Efficient Multimodal Learning from Data-Centric Perspective. arXiv 2024, arXiv:2402.11530. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.Q.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res. 2020, 21, 67. [Google Scholar]
- Vinyals, O.; Le, Q. A Neural Conversational Model. arXiv 2015, arXiv:1506.05869. [Google Scholar]
- Sahin, U.; Kucukkaya, I.E.; Toraman, C. ARC-NLP at PAN 2023: Hierarchical Long Text Classification for Trigger Detection. arXiv 2023, arXiv:2307.14912. [Google Scholar]
- Neill, J.O. An Overview of Neural Network Compression. arXiv 2020, arXiv:2006.03669. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a Distilled Version of BERT: Smaller, Faster, Cheaper and Lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Bordia, S.; Bowman, S.R.; Assoc Computat, L. Identifying and Reducing Gender Bias in Word-Level Language Models. arXiv 2019, arXiv:1904.03035. [Google Scholar]
- Holtzman, A.; Buys, J.; Du, L.; Forbes, M.; Choi, Y. The Curious Case of Neural Text Degeneration. arXiv 2019, arXiv:1904.09751. [Google Scholar]
- Bender, E.M.; Gebru, T.; McMillan-Major, A.; Shmitchell, S. On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? In Proceedings of the 2021 ACM conference on fairness, accountability, and transparency, Virtual Event, Toronto, ON, Canada, 3–10 March 2021; pp. 610–623. [Google Scholar]
- Treviso, M.; Lee, J.-U.; Ji, T.; van Aken, B.; Cao, Q.; Ciosici, M.R.; Hassid, M.; Heafield, K.; Hooker, S.; Raffel, C. Efficient Methods for Natural Language Processing: A Survey. Trans. Assoc. Comput. Linguist. 2023, 11, 826–860. [Google Scholar] [CrossRef]
- He, W.; Dai, Y.; Yang, M.; Sun, J.; Huang, F.; Si, L.; Li, Y. Space-3: Unified Dialog Model Pre-Training for Task-Oriented Dialog Understanding and Generation. arXiv 2022, arXiv:2209.06664. [Google Scholar]
- He, W.; Dai, Y.; Zheng, Y.; Wu, Y.; Cao, Z.; Liu, D.; Jiang, P.; Yang, M.; Huang, F.; Si, L. Galaxy: A Generative Pre-Trained Model for Task-Oriented Dialog with Semi-Supervised Learning and Explicit Policy Injection. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; Volume 36, pp. 10749–10757. [Google Scholar]
- He, W.; Dai, Y.; Hui, B.; Yang, M.; Cao, Z.; Dong, J.; Huang, F.; Si, L.; Li, Y. Space-2: Tree-Structured Semi-Supervised Contrastive Pre-Training for Task-Oriented Dialog Understanding. arXiv 2022, arXiv:2209.06638. [Google Scholar]
- Kim, B.; Wattenberg, M.; Gilmer, J.; Cai, C.; Wexler, J.; Viegas, F.; Sayres, R. Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (TCAV). In Proceedings of the 35th International Conference on Machine Learning (ICML), Stockholmsmässan, Stockholm, Sweden, 10–15 July 2018; Volume 80, pp. 2668–2677. [Google Scholar]
- Brundage, M.; Avin, S.; Clark, J.; Toner, H.; Eckersley, P.; Garfinkel, B.; Dafoe, A.; Scharre, P.; Zeitzoff, T.; Filar, B. The Malicious Use of Artificial Intelligence: Forecasting, Prevention, and Mitigation. arXiv 2018, arXiv:1802.07228. [Google Scholar]
- Lee, A.; Miranda, B.; Koyejo, S. Beyond Scale: The Diversity Coefficient as a Data Quality Metric Demonstrates LLMs Are Pre-Trained on Formally Diverse Data. arXiv 2023, arXiv:2306.13840. [Google Scholar]
- Mondal, R.; Tang, A.; Beckett, R.; Millstein, T.; Varghese, G. What Do LLMs Need to Synthesize Correct Router Configurations? arXiv 2023, arXiv:2307.04945. [Google Scholar]
- Mumtarin, M.; Chowdhury, M.S.; Wood, J. Large Language Models in Analyzing Crash Narratives—A Comparative Study of ChatGPT, BARD and GPT-4. arXiv 2023, arXiv:2308.13563. [Google Scholar]
- Tsai, C.-M.; Chao, C.-J.; Chang, Y.-C.; Kuo, C.-C.J.; Hsiao, A.; Shieh, A. Challenges and Opportunities in Medical Artificial Intelligence. APSIPA Trans. Signal Inf. Process. 2023, 12, e205. [Google Scholar] [CrossRef]
- Zhong, T.; Wei, Y.; Yang, L.; Wu, Z.; Liu, Z.; Wei, X.; Li, W.; Yao, J.; Ma, C.; Li, X. Chatabl: Abductive Learning via Natural Language Interaction with Chatgpt. arXiv 2023, arXiv:2304.11107. [Google Scholar]
- Liu, Y.; Han, T.; Ma, S.; Zhang, J.; Yang, Y.; Tian, J.; He, H.; Li, A.; He, M.; Liu, Z. Summary of ChatGPT-Related Research and Perspective Towards the Future of Large Language Models. Meta-Radiology 2023, 1, 100017. [Google Scholar] [CrossRef]
- Sellam, T.; Das, D.; Parikh, A.P. BLEURT: Learning Robust Metrics for Text Generation. arXiv 2020, arXiv:2004.04696. [Google Scholar]
- Rahm, E.; Do, H.H. Data Cleaning: Problems and Current Approaches. IEEE Data Eng. Bull. 2000, 23, 3–13. [Google Scholar]
- Candemir, S.; Nguyen, X.V.; Folio, L.R.; Prevedello, L.M. Training Strategies for Radiology Deep Learning Models in Data-Limited Scenarios. Radiol. Artif. Intell. 2021, 3, e210014. [Google Scholar] [CrossRef]
- Young, P.; Lai, A.; Hodosh, M.; Hockenmaier, J. From Image Descriptions to Visual Denotations: New Similarity Metrics for Semantic Inference over Event Descriptions. Trans. Assoc. Comput. Linguist. 2014, 2, 67–78. [Google Scholar] [CrossRef]
- Khot, T.; Sabharwal, A.; Clark, P. Scitail: A Textual Entailment Dataset from Science Question Answering. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18), Hilton New Orleans Riverside, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Xu, L.; Hu, H.; Zhang, X.; Li, L.; Cao, C.; Li, Y.; Xu, Y.; Sun, K.; Yu, D.; Yu, C. CLUE: A Chinese Language Understanding Evaluation Benchmark. arXiv 2020, arXiv:2004.05986. [Google Scholar]
- Hu, H.; Richardson, K.; Xu, L.; Li, L.; Kübler, S.; Moss, L.S. Ocnli: Original Chinese Natural Language Inference. arXiv 2020, arXiv:2010.05444. [Google Scholar]
- Liu, X.; Chen, Q.; Deng, C.; Zeng, H.; Chen, J.; Li, D.; Tang, B. Lcqmc: A Large-Scale Chinese Question Matching Corpus. In Proceedings of the the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 1952–1962. [Google Scholar]
- Chen, J.; Chen, Q.; Liu, X.; Yang, H.; Lu, D.; Tang, B. The Bq Corpus: A Large-Scale Domain-Specific Chinese Corpus for Sentence Semantic Equivalence Identification. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 4946–4951. [Google Scholar]
- Shankar Iyer, N.D. First Quora Dataset Release: Question Pairs. 2017. Available online: https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs (accessed on 21 May 2024).
- Marelli, M.; Menini, S.; Baroni, M.; Bentivogli, L.; Bernardi, R.; Zamparelli, R. A SICK Cure for the Evaluation of Compositional Distributional Semantic Models. In Proceedings of the the Ninth International Conference on Language Resources and Evaluation (LREC’14), Reykjavik, Iceland, 26–31 May 2014; pp. 216–223. [Google Scholar]
- Dolan, B.; Brockett, C. Automatically Constructing a Corpus of Sentential Paraphrases. In Proceedings of the Third International Workshop on Paraphrasing, Jeju Island, Korea, 14 October 2005; pp. 9–16. [Google Scholar]
- Li, J.; Sun, A.; Han, J.; Li, C. A Survey on Deep Learning for Named Entity Recognition. IEEE Trans. Knowl. Data Eng. 2020, 34, 50–70. [Google Scholar] [CrossRef]
- Zhu, G.; Iglesias, C.A. Exploiting Semantic Similarity for Named Entity Disambiguation in Knowledge Graphs. Expert. Syst. Appl. 2018, 101, 8–24. [Google Scholar] [CrossRef]
- Alkhidir, T.; Awad, E.; Alshamsi, A. Understanding the Progression of Educational Topics via Semantic Matching. arXiv 2024, arXiv:2403.05553. [Google Scholar]
- Hayden, K.A.; Eaton, S.E.; Pethrick, H.; Crossman, K.; Lenart, B.A.; Penaluna, L.-A. A Scoping Review of Text-Matching Software Used for Student Academic Integrity in Higher Education. Int. Educ. Res. 2021, 2021, 4834860. [Google Scholar] [CrossRef]
- Jeong, J.; Tian, K.; Li, A.; Hartung, S.; Adithan, S.; Behzadi, F.; Calle, J.; Osayande, D.; Pohlen, M.; Rajpurkar, P. Multimodal Image-Text Matching Improves Retrieval-Based Chest X-Ray Report Generation. In Proceedings of the Medical Imaging with Deep Learning, Paris, France, 3–5 July 2024; pp. 978–990. [Google Scholar]
- Luo, Y.-F.; Sun, W.; Rumshisky, A. A Hybrid Normalization Method for Medical Concepts in Clinical Narrative Using Semantic Matching. AMIA Jt. Summits Transl. Sci. Proc. 2019, 2019, 732. [Google Scholar]
- Wang, L.; Zhang, T.; Tian, J.; Lin, H. An Semantic Similarity Matching Method for Chinese Medical Question Text. In Proceedings of the 8th China Health Information Processing Conference, Hangzhou, China, 21–23 October 2022; pp. 82–94. [Google Scholar]
- Ajaj, S.H. AI-Driven Optimization of Job Advertisements through Knowledge-Based Techniques and Semantic Matching. Port-Said Eng. Res. J. 2024. [Google Scholar] [CrossRef]
- Ren, H.; Zhou, L.; Gao, Y. Policy Tourism and Economic Collaboration Among Local Governments: A Nonparametric Matching Model. Public Perform. Manag. Rev. 2024, 47, 476–504. [Google Scholar] [CrossRef]
- Gopalakrishnan, V.; Iyengar, S.P.; Madaan, A.; Rastogi, R.; Sengamedu, S. Matching Product Titles Using Web-Based Enrichment. In Proceedings of the 21st ACM International Conference on Information and Knowledge Management, Maui, HI, USA, 29 October–2 November 2012; pp. 605–614. [Google Scholar]
- Akritidis, L.; Fevgas, A.; Bozanis, P.; Makris, C. A Self-Verifying Clustering Approach to Unsupervised Matching of Product Titles. Artif. Intell. Rev. 2020, 53, 4777–4820. [Google Scholar] [CrossRef]
- De Bakker, M.; Frasincar, F.; Vandic, D. A Hybrid Model Words-Driven Approach for Web Product Duplicate Detection. In Proceedings of the 25th International Conference on Advanced Information Systems Engineering, Valencia, Spain, 17–21 June 2013; pp. 149–161. [Google Scholar]
- Zheng, K.; Li, Z. An Image-Text Matching Method for Multi-Modal Robots. J. Organ. End User Comput. 2024, 36, 1–21. [Google Scholar] [CrossRef]
- Song, Y.; Wang, M.; Gao, W. Method for Retrieving Digital Agricultural Text Information Based on Local Matching. Symmetry 2020, 12, 1103. [Google Scholar] [CrossRef]
- Xu, B.; Huang, S.; Sha, C.; Wang, H. MAF: A General Matching and Alignment Framework for Multimodal Named Entity Recognition. In Proceedings of the 15th ACM International Conference on Web Search and Data Mining, Tempe, AZ, USA, 21–25 February 2022; pp. 1215–1223. [Google Scholar]
- Gong, J.; Fang, X.; Peng, J.; Zhao, Y.; Zhao, J.; Wang, C.; Li, Y.; Zhang, J.; Drew, S. MORE: Toward Improving Author Name Disambiguation in Academic Knowledge Graphs. Int. J. Mach. Learn. Cybern. 2024, 15, 37–50. [Google Scholar] [CrossRef]
- Arifoğlu, D. Historical Document Analysis Based on Word Matching. 2011. Available online: https://www.proquest.com/openview/b2c216ab3f6a907e7ad65bbe855fa8cd/1?pq-origsite=gscholar&cbl=2026366&diss=y (accessed on 23 May 2024).
- Li, Y. Unlocking Context Constraints of Llms: Enhancing Context Efficiency of Llms with Self-Information-Based Content Filtering. arXiv 2023, arXiv:2304.12102. [Google Scholar]
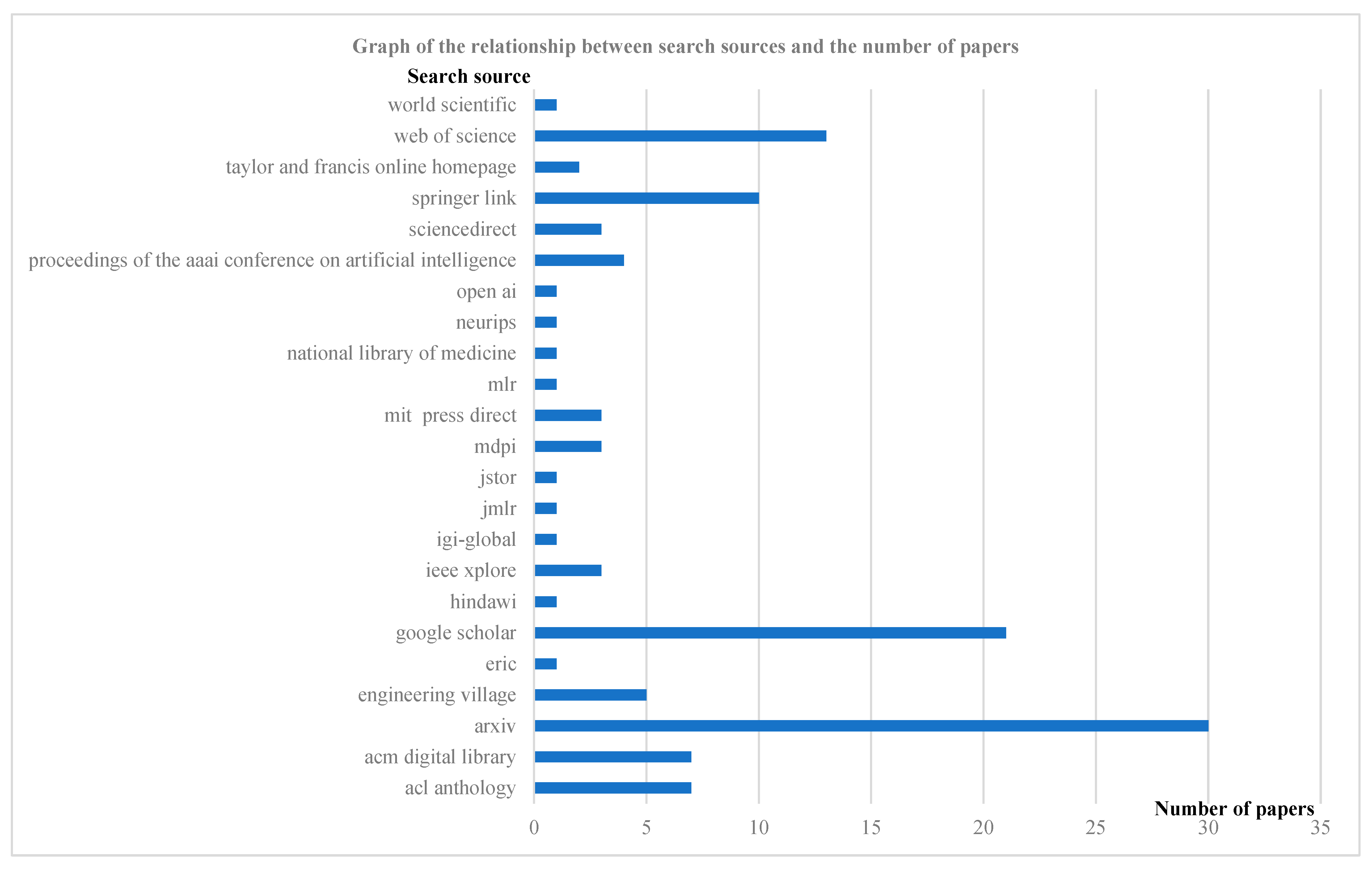

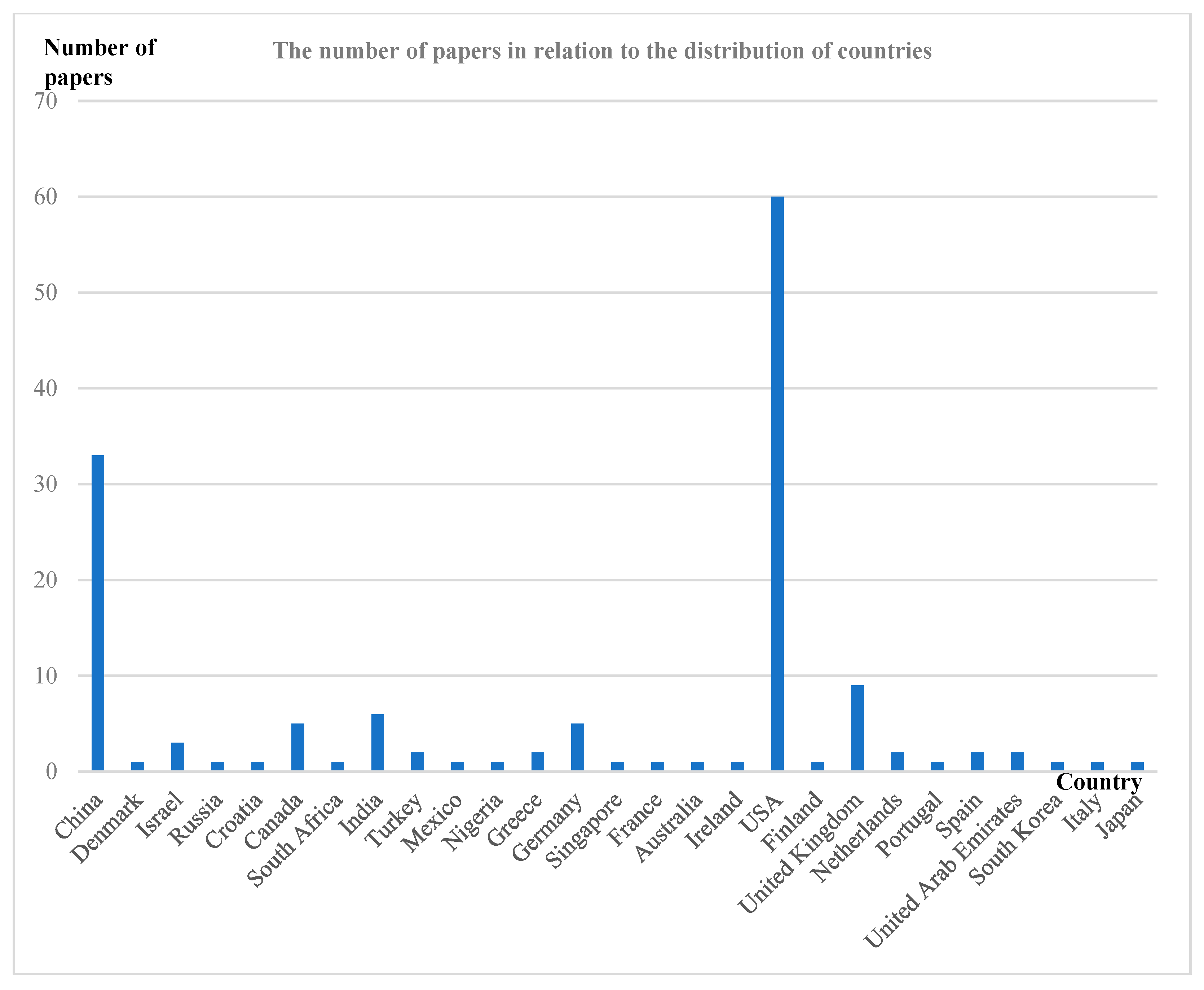







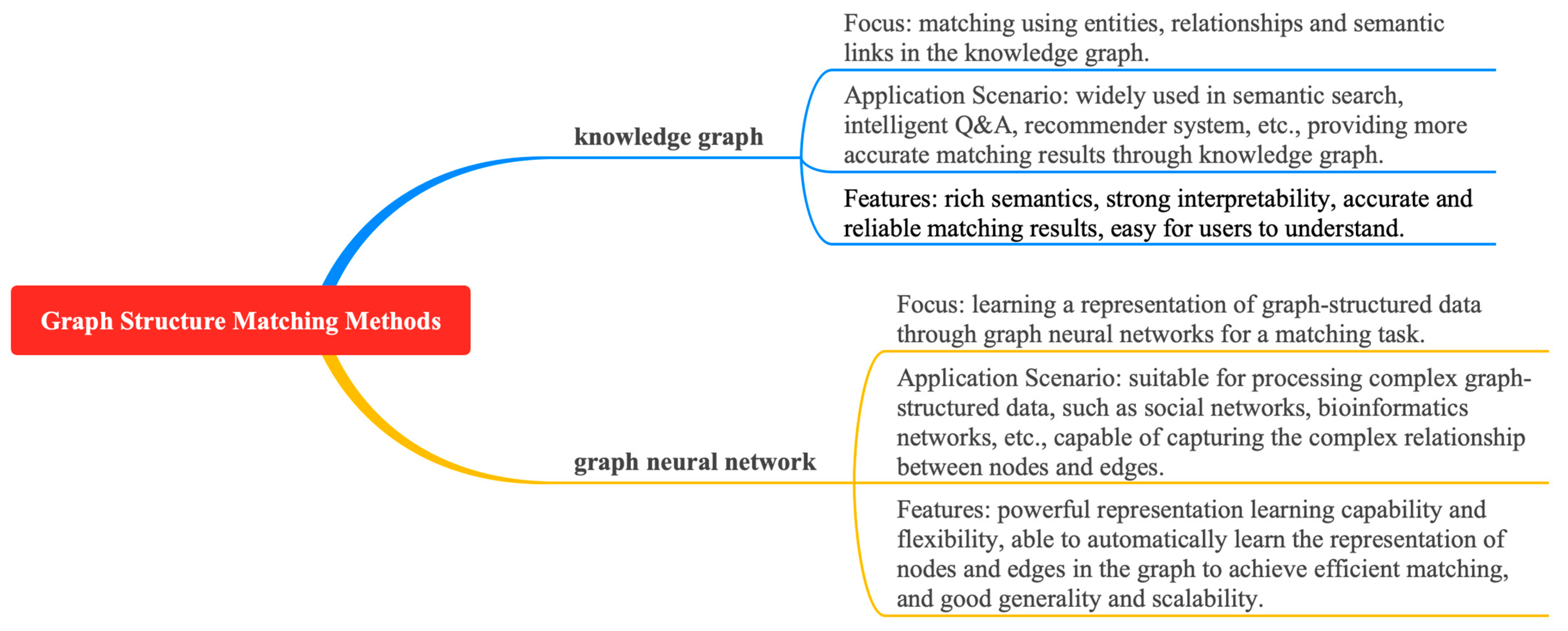


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).