


Sliding and Adaptive Windows to Improve Change Mining in Process Variability


Abstract
1. Introduction
2. Concepts and Definitions
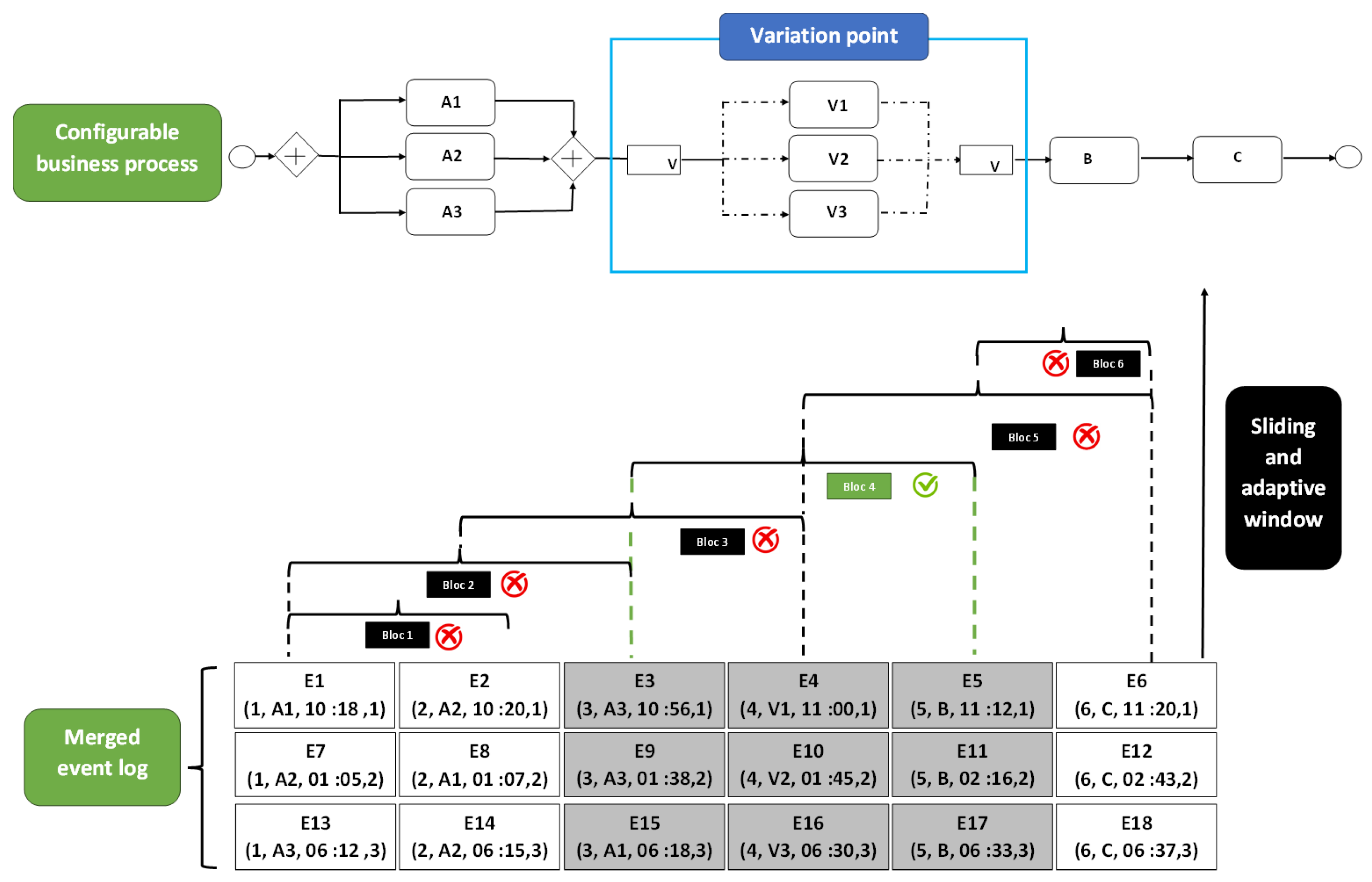
2.1. Configurable Process
- The variation points: Elements likely to be changed.
- Variations: Options available for each variation point.
- Configuration: The process of creating a configurable process variant by selecting an option for each variation point. The options include choosing a specific variant, excluding a variant, or making a selection based on certain conditions.
2.2. Changes of Configurable Process
- Control flow: the sequence of tasks or activities that make up a process;
- Tasks: distinct activities or steps within a process;
- Roles and responsibilities: the distribution of tasks among specific individuals or groups;
- Inputs and outputs: the data or information that flows into and out of a process;
- Performance metrics: the measures used to evaluate the success of a process;
- Policies and procedures: the rules and guidelines that govern a process.
2.3. Change Mining
3. Framework of Configurable Process Change Mining
3.1. Overview of Configurable Process Change Mining Framework
- First Component: Preprocessing. This component builds the event log of variable fragments. It contains two modules: the first module merges event logs related to a family of process variants, and the second module filters events related to variable fragments of the merged event log.
- Second Component: Change Mining Algorithm. This component involves the Change Mining algorithm, which is based on an extension of the STAGGER algorithm [36] dedicated to detecting concept drift.
- Third Component: Generating the Change Log. This component is responsible for generating the change log of variable fragments for the configurable process.
3.2. First Component: Preprocessing
3.2.1. Merging Approach


3.2.2. Filtering Approach
3.3. Second Component: Change Mining Approach
- Classification: In this step, all possible fragments are created by generating all possible combinations that can form variable fragments. The data used for this purpose is solely the variability file. This step is performed only once, and the algorithm does not loop through it. The loop starts from the second step.
- Initialization: This step involves selecting the fragment of events for analysis.
- Projection: In this step, events are compared to elements on the list of variable fragments.
- Evaluation: This step allows us to determine if the fragment being analyzed is subject to change and to identify the element that changes.
- Aggregation: During this step, an identifier is assigned to each variable fragment that changes.
- Storage: In this step, events with detected changes are saved in the change grid.
3.4. Third Component: Generating Change Log of Variable Fragments
- Change date and time;
- Trace identifier;
- Identifier of the process variant;
- Variation point;
- Type of change;
- Changed item name;
- The name of the new item as a result of the change.
4. The Sliding and Adaptive Window for a Collection of Preprocessing Event Logs
4.1. Types of Windowing Approaches Used in Change Mining
- Fixed Window: The size and properties of the window used for fragment selection are fixed and specified at the beginning of the analysis [39].
- Time Window: This change detection method uses one window to show past events and another window to show recent events. It then compares the distributions over these two windows using statistical hypothesis testing [41].
- Adaptive and Sliding Windows: A window of fixed size determines the instances of incoming data used for learning. Depending on the case, this window will be adapted to determine the new characteristics of the window [42].
4.2. The Sliding and Adaptive Windows to Improve Configurable Process Change Mining
- Uniform block: All elements of the block must have the same trace identifier (TRACE-ID) and the same process variant identifier.
- Parallel Gateway Handling: If a parallel gateway, also known as an AND gateway, is the first element of the block, we loop through the events of the AND gateway until we reach its last element. This last element will then be the first element of the new block.
- End-of-Block with an AND Gateway: If an element of an AND gateway is at the end of a block, we keep the block as is. For the selection of the next block, we advance to the last element of the AND gateway, making it the first element of the new block.
- One of the block elements exists in the variability file.
- The position of this element within the block corresponds to the same position predefined in the variability file. Specifically:
- If the element corresponds to a variant, it must be in the middle, as this is the position considered for building variable fragments of the configurable process.
- If the element is predefined in the file as “next”, it must be at the end of the block.
- If the element is predefined as “previous”, it must be at the beginning of the block.
5. Experience
5.1. Data Used for the Test
5.2. Experiences and Results
5.2.1. Illustrative Graphs
5.2.2. Detailed Analysis
5.2.3. Summary
6. Conclusion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Casati, F.; Ceri, S.; Pernici, B.; Pozzi, G. Workflow evolution. Data Knowl. Eng. 1998, 24, 211–238. [Google Scholar] [CrossRef]
- Austin, S.; Baldwin, A.; Li, B.; Waskett, P. Analytical design planning technique (ADePT): A dependency structure matrix tool to schedule the building design process. Constr. Manag. Econ. 2000, 18, 173–182. [Google Scholar] [CrossRef]
- Weber, B.; Reichert, M.; Rinderle-Ma, S. Change patterns and change support features–enhancing flexibility in process-aware information systems. Data Knowl. Eng. 2008, 66, 438–466. [Google Scholar] [CrossRef]
- Van Der Aalst, W. Process mining: Overview and opportunities. ACM Trans. Manag. Inf. Syst. (TMIS) 2012, 3, 7.1–7.17. [Google Scholar] [CrossRef]
- Seidl, T. Concept drift detection on streaming data with dynamic outlier aggregation. In Process Mining Workshops, Proceedings of the ICPM 2020 International Workshops, Padua, Italy, 5–8 October 2020; Revised Selected Papers; Springer Nature: Berlin/Heidelberg, Germany, 2021; Volume 406, p. 206. [Google Scholar]
- Spenrath, Y.; Hassani, M. Predicting Business Process Bottlenecks In Online Events Streams Under Concept Drifts. In Proceedings of the ECMS, Wildau, Germany, 9–12 June 2020; pp. 190–196. [Google Scholar]
- Stertz, F.; Rinderle-Ma, S. Process histories-detecting and representing concept drifts based on event streams. In On the Move to Meaningful Internet Systems, Proceedings of the OTM 2018 Conferences: Confederated International Conferences: CoopIS, C&TC, and ODBASE 2018, Valletta, Malta, 22–26 October 2018; Proceedings, Part I; Springer: Berlin/Heidelberg, Germany, 2018; pp. 318–335. [Google Scholar]
- Seeliger, A.; Nolle, T.; Mühlhäuser, M. Detecting concept drift in processes using graph metrics on process graphs. In Proceedings of the 9th Conference on Subject-Oriented Business Process Management, Darmstadt, Germany, 30–31 March 2017; pp. 1–10. [Google Scholar]
- Becker, J.; Kugeler, M.; Rosemann, M. Process Management: A Guide for the Design of Business Processes: With 83 Figures and 34 Tables; Springer Science & Business Media: Dordrecht, The Netherlands, 2003. [Google Scholar]
- Laguna, M.; Marklund, J. Business Process Modeling, Simulation and Design; CRC Press: Boca Raton, FL, USA, 2013. [Google Scholar]
- Keller, G.; Nüttgens, M.; Scheer, A. Semantische Prozeßmodellierung auf der Grundlage; Ereignisgesteuerter Prozeßketten (EPK), Institut für Wirtschaftsinformatik (IWi), Universität des Saarlandes: Saarbrücken, Germany, 1992. [Google Scholar]
- Dumas, M.; Ter Hofstede, A.H. UML activity diagrams as a workflow specification language. In Modeling Languages, Concepts, and Tools, Proceedings of the Unified Modeling Language, UML-2001— 4th International Conference, Toronto, ON, Canada, 1–5 October 2001; Proceedings 4; Springer: Berlin/Heidelberg, Germany, 2001; pp. 76–90. [Google Scholar]
- Chinosi, M.; Trombetta, A. BPMN: An introduction to the standard. Comput. Stand. Interfaces 2012, 34, 124–134. [Google Scholar] [CrossRef]
- Bosch, J.; Florijn, G.; Greefhorst, D.; Kuusela, J.; Obbink, J.H.; Pohl, K. Variability issues in software product lines. In Software Product-Family Engineering, Proceedings of the 4th International Workshop, PFE 2001 Bilbao, Spain, October 3–5; Springer: Berlin/Heidelberg, Germany, 2002; pp. 13–21. [Google Scholar]
- Kang, K.C.; Cohen, S.G.; Hess, J.A.; Novak, W.E.; Peterson, A.S. Feature-Oriented Domain Analysis (FODA) Feasibility Study; Technical Report; Carnegie-Mellon Univ Pittsburgh Pa Software Engineering Inst.: Pittsburgh, PA, USA, 1990. [Google Scholar]
- Zhang, M.; Tseng, M.M. A product and process modeling based approach to study cost implications of product variety in mass customization. IEEE Trans. Eng. Manag. 2007, 54, 130–144. [Google Scholar] [CrossRef]
- Zaaboub Haddar, N.; Makni, L.; Ben Abdallah, H. Literature review of reuse in business process modeling. Softw. Syst. Model. 2014, 13, 975–989. [Google Scholar] [CrossRef]
- Buijs, J.; Van Dongen, B.; Van Der Aalst, W. Towards cross-organizational process mining in collections of process models and their executions. Complexity 2011, 5, 10–26. [Google Scholar]
- Gottschalk, F.; Wagemakers, T.A.; Jansen-Vullers, M.H.; van der Aalst, W.M.; La Rosa, M. Configurable process models: Experiences from a municipality case study. In Advanced Information Systems Engineering, Proceedings of the 21st International Conference, CAiSE 2009, Amsterdam, The Netherlands, 8–12 June 2009; Proceedings 21; Springer: Berlin/Heidelberg, Germany, 2009; pp. 486–500. [Google Scholar]
- Sharma, D.K.; Hitesh; Rao, V. Individualization of process model from configurable process model constructed in C-BPMN. In Proceedings of the International Conference on Computing, Communication & Automation, Greater Noida, India, 15–16 May 2015; pp. 750–754. [Google Scholar]
- Sikal, R.; Sbai, H.; Kjiri, L. Configurable process mining: Variability Discovery Approach. In Proceedings of the 2018 IEEE 5th International Congress on Information Science and Technology (CiSt), Marrakech, Morocco, 21–27 October 2018; pp. 137–142. [Google Scholar]
- Kadam, S.V. A survey on classification of concept drift with stream data. ACM Comput. Surv. (CSUR) 2019, 46, 1–37. [Google Scholar]
- Omori, N.J.; Tavares, G.M.; Ceravolo, P.; Barbon, S., Jr. Comparing concept drift detection with process mining tools. In Proceedings of the XV Brazilian Symposium on Information Systems, Aracaju, Brazil, 20–24 May 2019; pp. 1–8. [Google Scholar]
- Küster, J.M.; Gerth, C.; Förster, A.; Engels, G. Detecting and resolving process model differences in the absence of a change log. In Business Process Management, Proceedings of the 6th International Conference, BPM 2008, Milan, Italy, 2–4 September 2008; Proceedings 6; Springer: Berlin/Heidelberg, Germany, 2008; pp. 244–260. [Google Scholar]
- Kaes, G.; Rinderle-Ma, S. On the similarity of process change operations. In Advanced Information Systems Engineering, Proceedings of the 29th International Conference, CAiSE 2017, Essen, Germany, 12–16 June 2017; Proceedings 29; Springer: Berlin/Heidelberg, Germany, 2017; pp. 348–363. [Google Scholar]
- Jacob, B.; Promod, K. Change sequence mining for interdependent context aware service processes using partial derivatives. In Proceedings of the 2009 World Congress on Nature & Biologically Inspired Computing (NaBIC), Coimbatore, India, 9–11 December 2009; pp. 1486–1491. [Google Scholar]
- Lu, X.; Fahland, D.; van den Biggelaar, F.J.; van der Aalst, W.M. Detecting deviating behaviors without models. In Business Process Management Workshops, Proceedings of the BPM 2015, 13th International Workshops, Innsbruck, Austria, 31 August–3 September 2015; Revised Papers 13; Springer: Berlin/Heidelberg, Germany, 2016; pp. 126–139. [Google Scholar]
- Dijkman, R. Diagnosing differences between business process models. In Business Process Management, Proceedings of the 6th International Conference, BPM 2008, Milan, Italy, 2–4 September 2008; Proceedings 6; Springer: Berlin/Heidelberg, Germany, 2008; pp. 261–277. [Google Scholar]
- Zheng, C.; Wen, L.; Wang, J. Detecting process concept drifts from event logs. In On the Move to Meaningful Internet Systems, Proceedings of the OTM 2017 Conferences: Confederated International Conferences: CoopIS, C&TC, and ODBASE 2017, Rhodes, Greece, 23–27 October 2017; Proceedings, Part I; Springer: Berlin/Heidelberg, Germany, 2017; pp. 524–542. [Google Scholar]
- Hompes, B.; Buijs, J.C.; van der Aalst, W.M.; Dixit, P.M.; Buurman, H. Detecting Change in Processes Using Comparative Trace Clustering. SIMPDA 2015, 2015, 95–108. [Google Scholar]
- Luengo, D.; Sepúlveda, M. Applying clustering in process mining to find different versions of a business process that changes over time. In Business Process Management Workshops, Proceedings of the BPM 2011 International Workshops, Clermont-Ferrand, France, 29 August 2011; Revised Selected Papers, Part I 9; Springer: Berlin/Heidelberg, Germany, 2012; pp. 153–158. [Google Scholar]
- Baier, L.; Reimold, J.; Kühl, N. Handling concept drift for predictions in business process mining. In Proceedings of the 2020 IEEE 22nd Conference on Business Informatics (CBI), Antwerp, Belgium, 22–24 June 2020; Volume 1, pp. 76–83. [Google Scholar]
- Hassani, M. Concept Drift Detection Of Event Streams Using An Adaptive Window. In Proceedings of the ECMS, Caserta, Italy, 11–14 June 2019; pp. 230–239. [Google Scholar]
- Tan, W.; Liu, X. Research on modeling and extraction of a dominant business process fragment. In Proceedings of the 2nd Annual International Conference on Electronics, Electrical Engineering and Information Science (EEEIS 2016), Xi’an, China, 2–4 December 2016; Atlantis Press: Paris, France, 2016; pp. 878–885. [Google Scholar]
- Hmami, A.; Fredj, M.; Sbai, H. A new Framework to improve Change Mining in Configurable Process. In Proceedings of the 3rd International Conference on Networking, Information Systems & Security (NISS), Marrakech, Morocco, 31 March–2 April 2020; pp. 1–6. [Google Scholar]
- Schlimmer, J.C.; Granger, R.H. Beyond incremental processing: Tracking concept drift. In Proceedings of the AAAI, Philadelphia, PA, USA, 11–15 August 1986; pp. 502–507. [Google Scholar]
- Hmami, A.; Sbai, H.; Fredj, M. Enhancing Change Mining from a collection of event logs: Merging and Filtering approaches. In Journal of Physics: Conference Series, Proceedings of the International Conference on Mathematics & Data Science (ICMDS), Khouribga, Morocco, 29–30 June 2020; IOP Publishing: Bristol, UK, 2021; Volume 1743, p. 012020. [Google Scholar]
- Sbaï, H.; Fredj, M.; Kjiri, L. Towards a Process Patterns based Approach for Promoting Adaptability in Configurable Process Models. In Proceedings of the ICEIS (3), Crete, Greece, 4–7 July 2013; pp. 382–387. [Google Scholar]
- Bose, R.J.C.; Van Der Aalst, W.M.; Žliobaitė, I.; Pechenizkiy, M. Dealing with concept drifts in process mining. IEEE Trans. Neural Netw. Learn. Syst. 2013, 25, 154–171. [Google Scholar] [CrossRef] [PubMed]
- Hmami, A.; Fredj, M.; Sbai, H. Handling Sudden and Recurrent Changes in Business Process Variability: Change Mining based Approach. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 632–640. [Google Scholar] [CrossRef]
- Carmona, J.; Gavalda, R. Online techniques for dealing with concept drift in process mining. In Advances in Intelligent Data Analysis XI, Proceedings of the 11th International Symposium, IDA 2012, Helsinki, Finland, 25–27 October 2012; Proceedings 11; Springer: Berlin/Heidelberg, Germany, 2012; pp. 90–102. [Google Scholar]
- Maisenbacher, M.; Weidlich, M. Handling concept drift in predictive process monitoring. In Proceedings of the 2017 IEEE International Conference on Services Computing (SCC), Honolulu, HI, USA, 25–30 June 2017; pp. 1–8. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| N° | NVP 1 | Nbr Variants 2 | Types 3 | N logs IN C 4 |
|---|---|---|---|---|
| 1 | 3 | [3,2,3] | [N.N] | 6 |
| 2 | 3 | [3,2,3] | [Y.Y] | 6 |
| 3 | 4 | [3,4,3,4] | [N.N] | 8 |
| 4 | 4 | [3,4,3,4] | [Y.N] | 8 |
| 5 | 5 | [3,4,5,3,4] | [N.N] | 10 |
| 6 | 5 | [3,4,5,3,4] | [N.Y] | 10 |
| 7 | 6 | [3,4,5,3,4,5] | [N.N] | 12 |
| 8 | 6 | [3,4,5,3,4,5] | [Y.Y] | 12 |
| 9 | 7 | [3,4,5,3,4,5,3] | [N.N] | 14 |
| 10 | 7 | [3,4,5,3,4,5,3] | [Y.Y] | 14 |
| First Experience 1 | Second Experience 2 | |||||||
|---|---|---|---|---|---|---|---|---|
| N° | Variable Fragments | Applied Changes | DF 3 | DC 4 | % | DF 3 | DC 4 | % |
| 1 | 1800 | 153 | 1797 | 149 | 97% | 1800 | 149 | 97% |
| 2 | 1800 | 493 | 1184 | 239 | 49% | 1799 | 492 | 99% |
| 3 | 3200 | 546 | 3198 | 544 | 100% | 3201 | 544 | 100% |
| 4 | 3200 | 186 | 3198 | 184 | 99% | 3200 | 186 | 100% |
| 5 | 5000 | 629 | 4998 | 629 | 100% | 4950 | 501 | 80% |
| 6 | 5000 | 600 | 3999 | 404 | 67% | 4923 | 546 | 91% |
| 7 | 7200 | 630 | 7200 | 607 | 96% | 7200 | 558 | 89% |
| 8 | 7200 | 464 | 5984 | 311 | 67% | 7156 | 461 | 99% |
| 9 | 9800 | 1129 | 9800 | 1125 | 99.6% | 9800 | 1125 | 99.6% |
| 10 | 9800 | 439 | 8400 | 271 | 61.7% | 9793 | 431 | 98% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hmami, A.; Sbai, H.; Baina, K.; Fredj, M. Sliding and Adaptive Windows to Improve Change Mining in Process Variability. Information 2024, 15, 445. https://doi.org/10.3390/info15080445
Hmami A, Sbai H, Baina K, Fredj M. Sliding and Adaptive Windows to Improve Change Mining in Process Variability. Information. 2024; 15(8):445. https://doi.org/10.3390/info15080445
Chicago/Turabian StyleHmami, Asmae, Hanae Sbai, Karim Baina, and Mounia Fredj. 2024. "Sliding and Adaptive Windows to Improve Change Mining in Process Variability" Information 15, no. 8: 445. https://doi.org/10.3390/info15080445
APA StyleHmami, A., Sbai, H., Baina, K., & Fredj, M. (2024). Sliding and Adaptive Windows to Improve Change Mining in Process Variability. Information, 15(8), 445. https://doi.org/10.3390/info15080445