
LPG Semantic Ontologies: A Tool for Interoperable Schema Creation and Management



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Related Work
2.1. Semantic Web Technologies
2.2. Role of Ontologies
2.2.1. Digital Libraries
2.2.2. Healthcare
2.2.3. Finance
2.2.4. Other Domains
2.3. Graph Databases and LPGs
2.4. Integration of Semantic Web Technologies and Graph Databases
2.5. Hybrid Approaches Combining Semantic Web and Graph Databases
3. OntoBuilder
- LPG schema model creation: OntoBuilder facilitates the creation of ontology schema models based on existing knowledge graph classes and properties. This allows users to utilize and adapt well-established data structures, improving efficiency and consistency in the construction of new ontologies.
- Automated ontology construction: OntoBuilder automates the extraction of concepts and relationships from unstructured data, connecting them to the OntoBuilder schema model. This significantly simplifies the knowledge creation process, reducing manual workload and increasing accuracy.
- Semantic integration: By integrating semantics, OntoBuilder ensures data interoperability. This enables smooth data exchange and high consistency across different systems and platforms, enhancing the quality and usability of information.
- Support for ontology evolution: OntoBuilder supports the continuous evolution of ontologies, allowing for constant updates and refinements as new data become available. This ensures that ontologies remain current and relevant, adapting to changes in data and domain requirements.
- Scalability: Designed to handle large datasets, OntoBuilder is scalable and adaptable to various fields, including digital libraries, healthcare, and finance. This scalability ensures that the tool can grow with the users’ needs, maintaining high performance even with expanding data volumes.
- Enhanced querying capabilities: Utilizing LPG models, OntoBuilder provides advanced querying capabilities, enabling more sophisticated data retrieval and analysis. Users can perform complex queries and gain detailed insights, improving the quality of data-driven analyses and decision-making.
- •
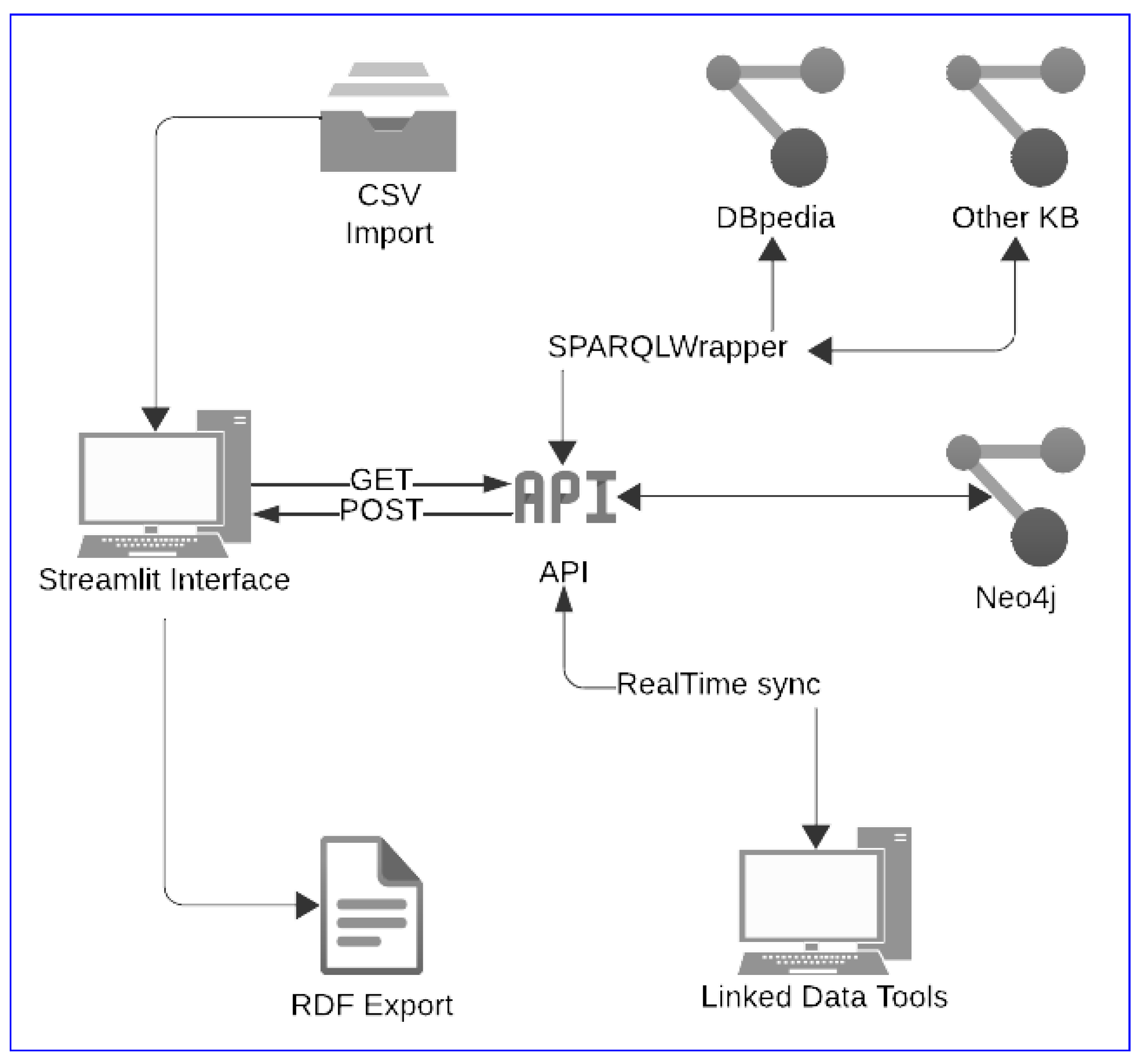
- Streamlit. (https://streamlit.io, accessed on 16 July 2024) functions as the primary interface, facilitating user interactions with the system. It allows users to perform operations such as selecting classes from DBpedia (https://dbpedia.org, accessed on 16 July 2024), creating new classes within Neo4j, and dynamically managing ontology properties. This front-end component enhances system accessibility for users with varying levels of technical proficiency, providing a clear and intuitive interface that simplifies the execution of complex tasks.
- •
- SPARQLWrapper. (https://rdflib.github.io/sparqlwrapper, accessed on 16 July 2024) is employed for querying DBpedia, an organized version of Wikipedia that offers public access to its content in RDF format. This utility sends queries to DBpedia’s SPARQL endpoint to retrieve RDF class information. Users can utilize this data to define or augment their ontologies with real-world datasets, thereby increasing the semantic richness and applicability of the developed ontologies.
- •
- Neo4j. (https://neo4j.com/, accessed on 16 July 2024) is the core graph database used to store and manage the ontological structures defined by users. Neo4j supports the Label Property Graph (LPG) model, which is particularly well-suited for representing the intricate relationships and attributes inherent in each node (class or entity). Neo4j’s selection was driven by its robust graph database capabilities, which align perfectly with the demands of semantic data modeling and linked data production. Its schema-less nature allows for the dynamic representation of complex relationships inherent in ontologies, making it an ideal intermediary between ontology design and linked data generation. Moreover, Neo4j’s support for the Cypher query language and its ability to efficiently manage and traverse large-scale graphs significantly enhance the performance and scalability of the system. This makes Neo4j not only a storage solution but also a powerful engine for executing graph-specific queries, ensuring data integrity and responsiveness in ontology management.
4. Functional Flow
- 1.
- Start application: The process begins when the user accesses the web application. This action activates the system and prepares it for subsequent interactions.
- 2.
- Interface: Upon launch, the user is greeted by an interface developed using Streamlit. This interface serves as the main conduit for user interaction with the system.
- 3.
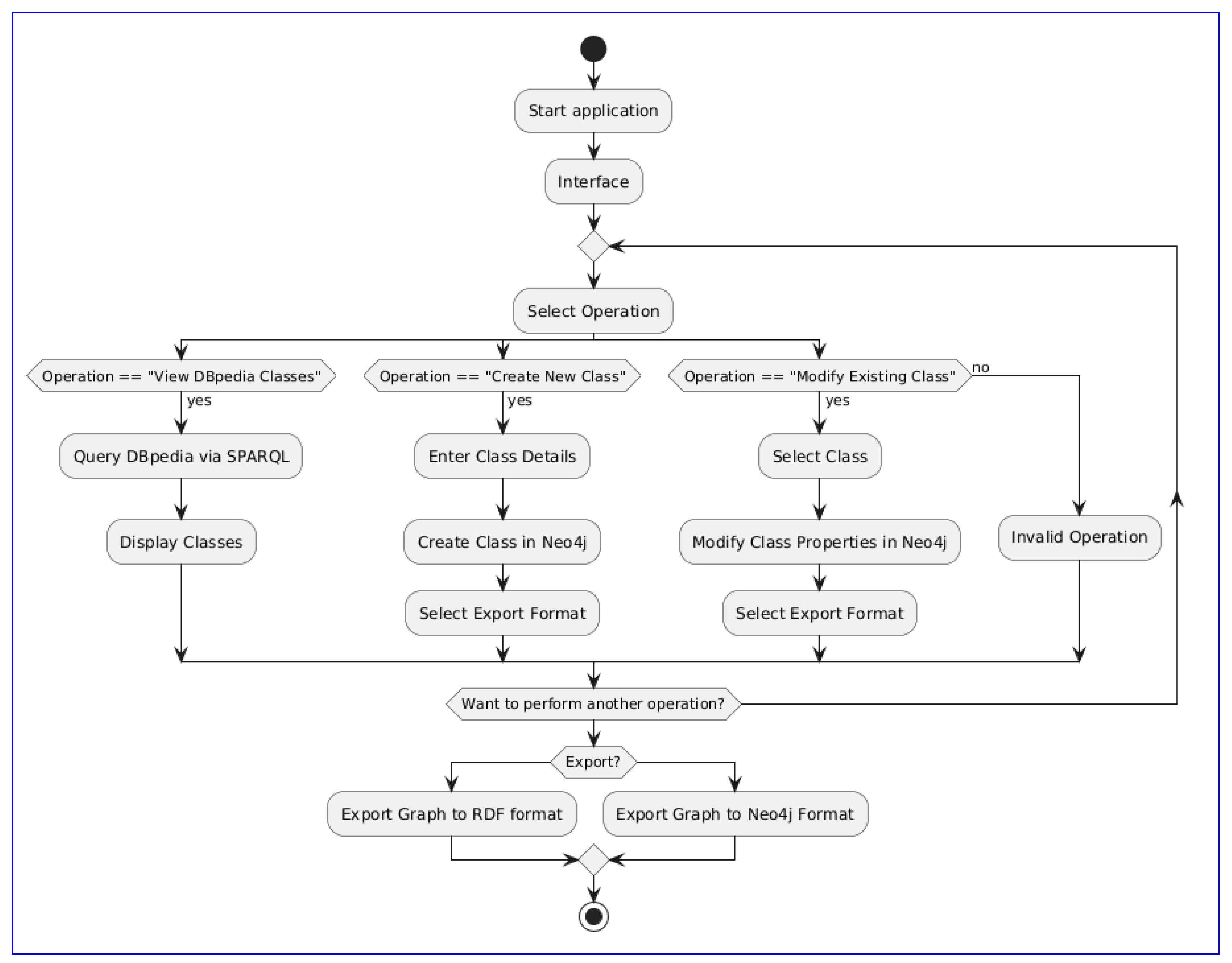
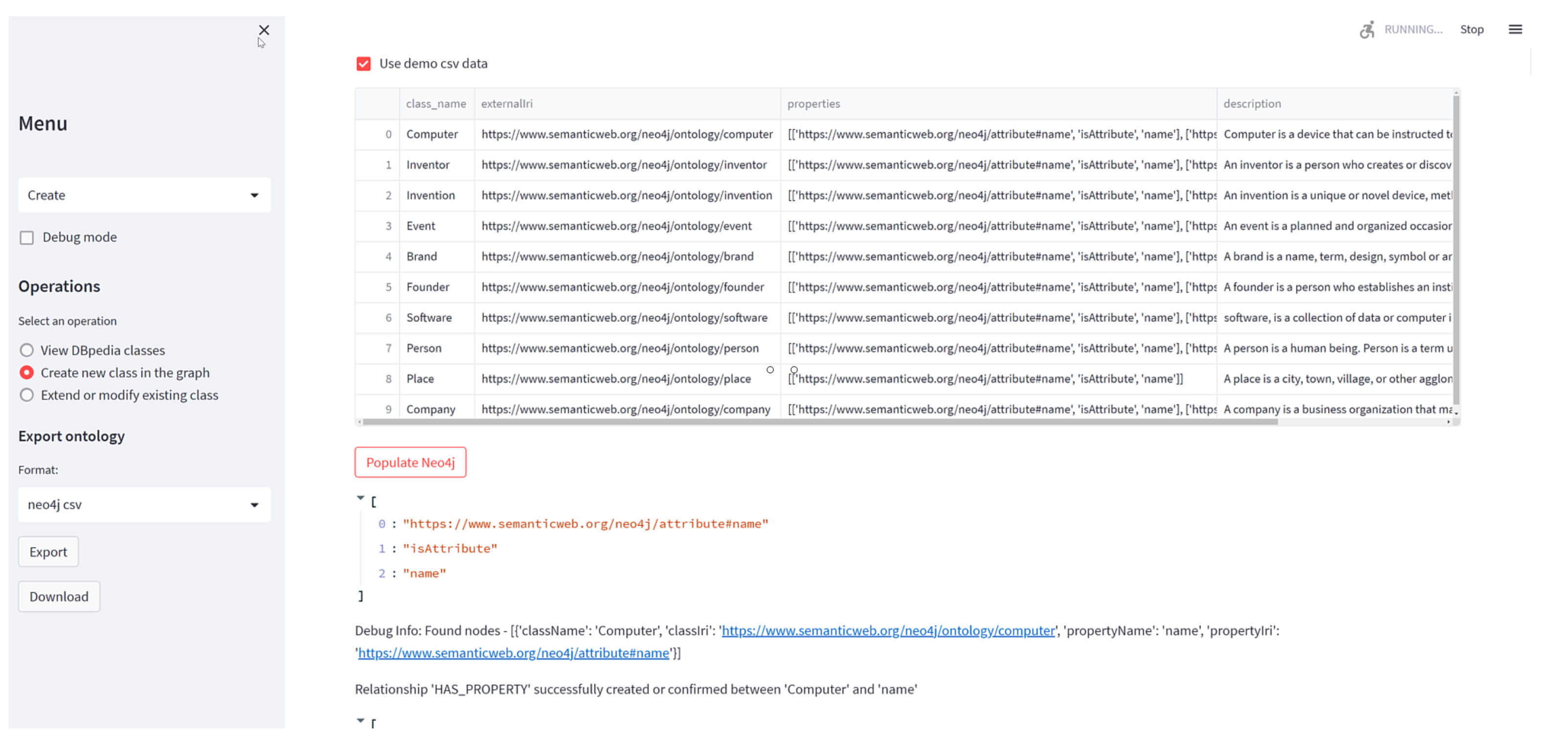
- Select operation: The system offers multiple operations that the user can perform, each catering to different needs (see Figure 2). These operations include:
- View DBpedia classes. This feature allows users to create ontological classes based on existing ones in DBpedia, a key semantic web resource that automatically extracts structured information. Users can search for a specific class within DBpedia, view, and analyze all associated properties of that class. Subsequently, they can select and assign a specific type to each class, which may be:
- -
- Attribute: An attribute is a characteristic or a piece of data that belongs to a specific entity or class. For instance, rdfs:comment can be associated with the Book class as an attribute providing comments or descriptions. Attributes are typically used to store additional information about an entity that does not require a relationship with another class.
- -
- Property: A property defines a relationship between two classes or entities. For example, dbp:firstPublicationDate can be designated as a property of the Book class, indicating the date of the first publication. Properties often define the connections between different entities within the ontology and are used to model relationships.
- -
- Class: For instance, dbo:Author can be treated as a class linked to Book, implying that each instance of Book can have a relationship with an instance of the Author class, thereby strengthening the semantic link between book and author.
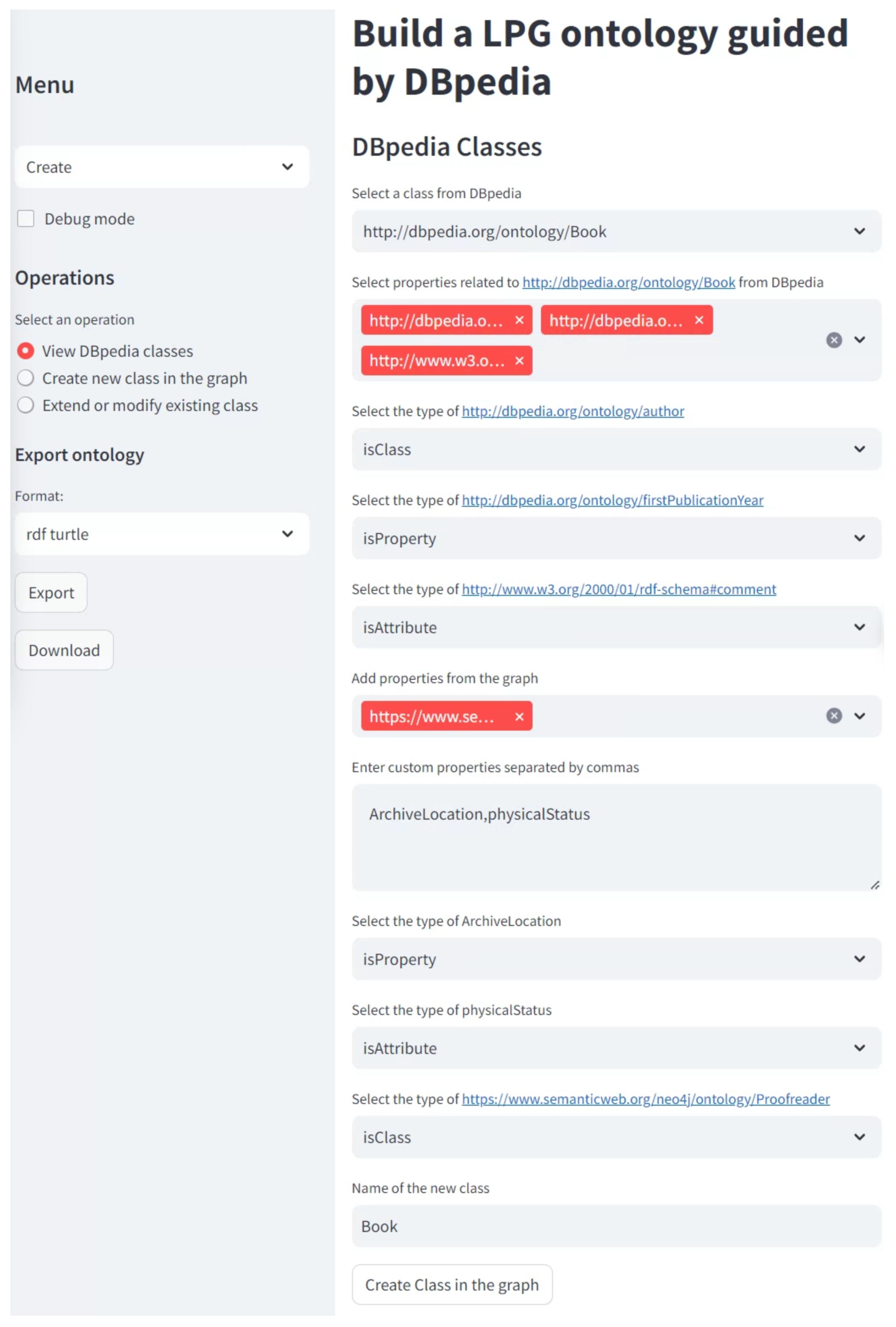
Users can also add new properties that are not present in DBpedia but are relevant to the ontology they are developing. These new properties can be defined as attributes, properties, or classes and can be linked to a custom namespace, for example, https://www.semanticweb.org/neo4j/ (the semanticweb.org domain is used purely as an example of an IRI for the ontology, and does not represent an actual domain). Examples include: NMProperty#:ArchiveLocation to denote the physical location of a book within an organization that maintains a physical copy, or NMAttribute#physicalStatus to describe the condition of the book, or even NMClass#Proofreaders to refer to the individuals responsible for proofreading (see Figure 3).The NM prefix is a custom namespace used within the ontology to uniquely identify properties, attributes, or classes that are specifically defined by the user. This prefix helps prevent naming conflicts and ensures that these custom-defined terms remain distinct from those imported from external sources like DBpedia, thus maintaining the integrity and clarity of the ontology. - Create new class. This option enables users to create new ontological classes directly within the graph, independent of the guidance from DBpedia’s information. This approach is beneficial when the desired classes are not pre-existing or when the user wishes to develop a completely original structure that diverges from DBpedia models.
- Modify existing class. This option allows users to access and modify classes and properties already defined in their ontological system as needed. Modifications may include updating definitions, adding or removing relationships, or adjusting properties to better reflect an evolving context or emerging needs. This functionality is crucial for keeping the ontology updated and relevant in response to changes in the application domain.
- 4.
- Select Export Format: After creating or modifying a class, users decide the format for exporting their graph (see Figure 2):
- If the export option is selected, users choose between RDF format and Neo4j format, based on their specific needs for compatibility or integration.
- 5.
- Export graph: Depending on the selected format, the graph is exported:
- Export to RDF format: Suitable for systems requiring RDF data models, enhancing interoperability and data sharing.
- Export to Neo4j format: Keeps the ontology in Neo4j’s native format, optimizing for graph-specific features.
This adopted mapping into the export functions ensures that the transition from LPG to RDF adheres to semantic web standards, enhancing the interoperability, expressiveness, and usability of the data across various platforms. - 6.
- Repeat or Stop: Users can choose to continue with additional operations or complete their session, allowing for dynamic interaction with the system (see Figure 2).
4.1. Initialization of RDF Export
@prefix ns1: <https://www.semanticweb.org/neo4j/>.@prefix owl: <http://www.w3.org/2002/07/owl#>.@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>.@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#>.
4.2. Node Processing in Neo4j
- DBpedia and NS1 Classes are mapped to OWL:Class to denote that the node represents a class definition in the ontology.
- DBpedia and NS1 Properties are designated as RDF:Property, indicating that the node serves as an ontological property.
- DBpedia and NS1 Attributes are designated as RDF:Property, indicating that the node serves as an ontological property.
- Neo4j Instances are classified as NS:ClassName, highlighting that the node is an instance of a specific class (defined by ClassName).
- Other Nodes default to a custom resource, RDFS:Resource, allowing for flexibility in representing additional data types.
4.3. Relationship Processing
- INSTANCE_OF relationships are mapped to RDF.type, establishing essential class-instance relationships for RDF ontologies.
- HAS_PROPERTY relationships are linked with RDFS.isDefinedBy, useful for describing properties associated with a class or instance.
- Custom Relationships are handled via specific mappings that accommodate unique or complex interactions within the graph.
4.4. Serialization of RDF Graph
- Interoperability: Facilitates data integration with other semantic web technologies.
- Expressiveness: Allows for the expression of complex relationships and constraints.
- Scalability: Supports expansions in data volume and complexity without losing the benefits of semantic structuring.
- Advanced Querying and Inference: Enables sophisticated data analysis and reasoning capabilities.
5. OntoBuilder Demo
5.1. Domain: Digital Library
- comment: A brief description or annotation of the book.
- author: The name of the person who wrote the book.
- subject: The main topics or themes addressed in the book.
- publisher: The company or organization responsible for publishing the book.
- publicationDate: The date when the book was first published.
- isbn: The International Standard Book Number, a unique identifier for books.
- bookStatus: Indicates the current availability status of the book (e.g., available, checked out).
- editingContributors: Names of the individuals involved in the editing process of the book.
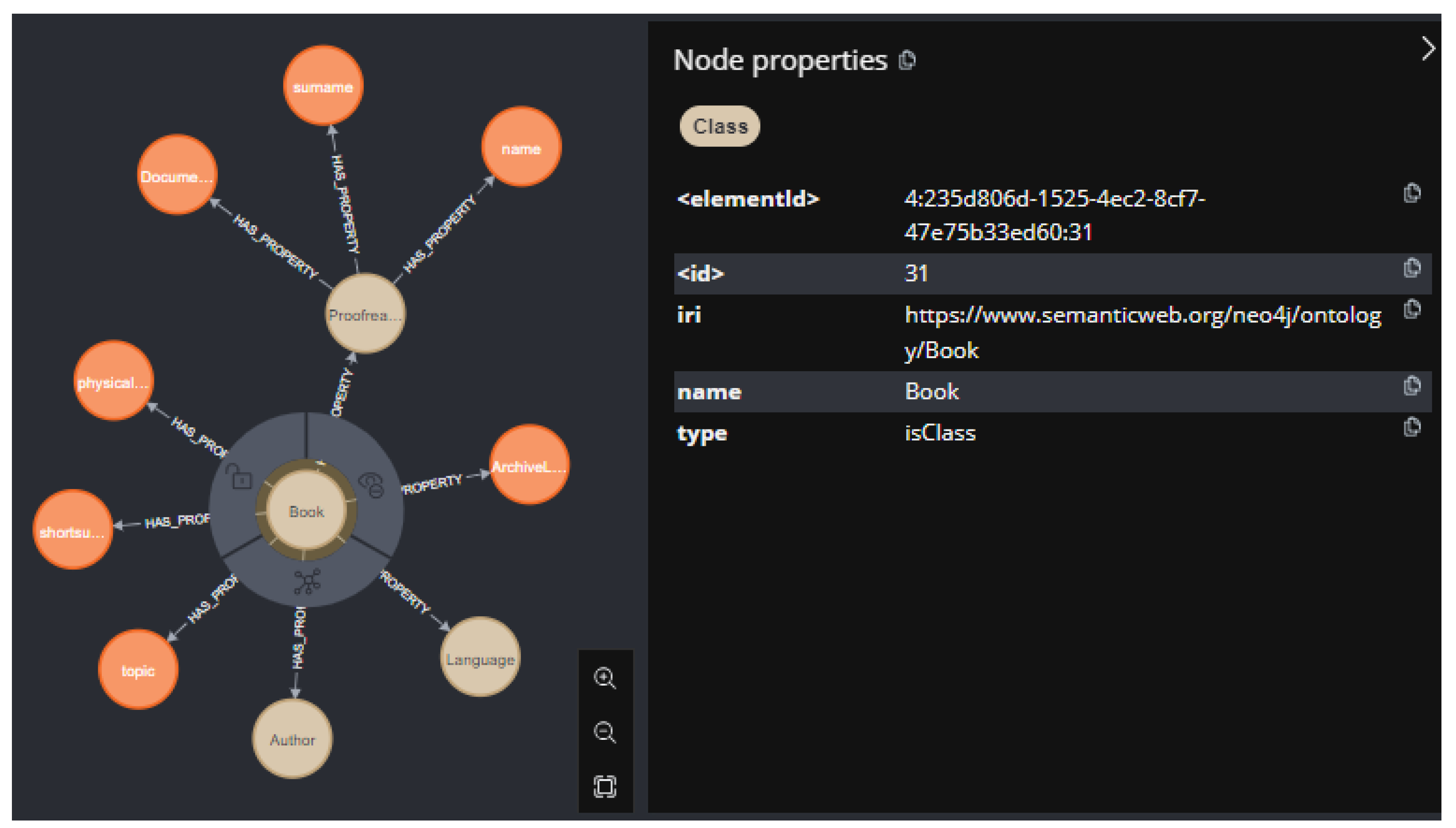
- Name: Book
- DBpedia Properties:
- -
- comment: A description of the book.
- -
- author: Umberto Eco.
- -
- subject: Historical novel, Mystery.
- -
- publisher: Bompiani.
- -
- publicationDate: 1980.
- -
- isbn: 978-88-452-1523-5.
- Custom Properties:
- -
- bookStatus: Available.
- -
- editingContributors: Maria Bonfantini.
- comment: “The Name of the Rose” is a historical novel and mystery written by Umberto Eco, set in a Benedictine monastery in the 14th century.”
- author: Umberto Eco.
- subject: Historical novel, Mystery.
- publisher: Bompiani.
- publicationDate: 1980.
- isbn: 978-88-452-1523-5.
- bookStatus: Available.
- editingContributors: Maria Bonfantini.
5.2. Domain: History of Computer Science
6. Evaluation
- Junior Researchers (3 participants): Less than 2 years of experience with ontologies.
- Senior Researchers (4 participants): Between 2 and 5 years of experience with ontologies.
- Expert Researchers (3 participants): More than 5 years of experience with ontologies.
- Beginner (2 participants): Limited experience with ontology tools.
- Intermediate (5 participants): Moderate experience with ontology tools.
- Advanced (3 participants): Extensive experience with ontology tools.
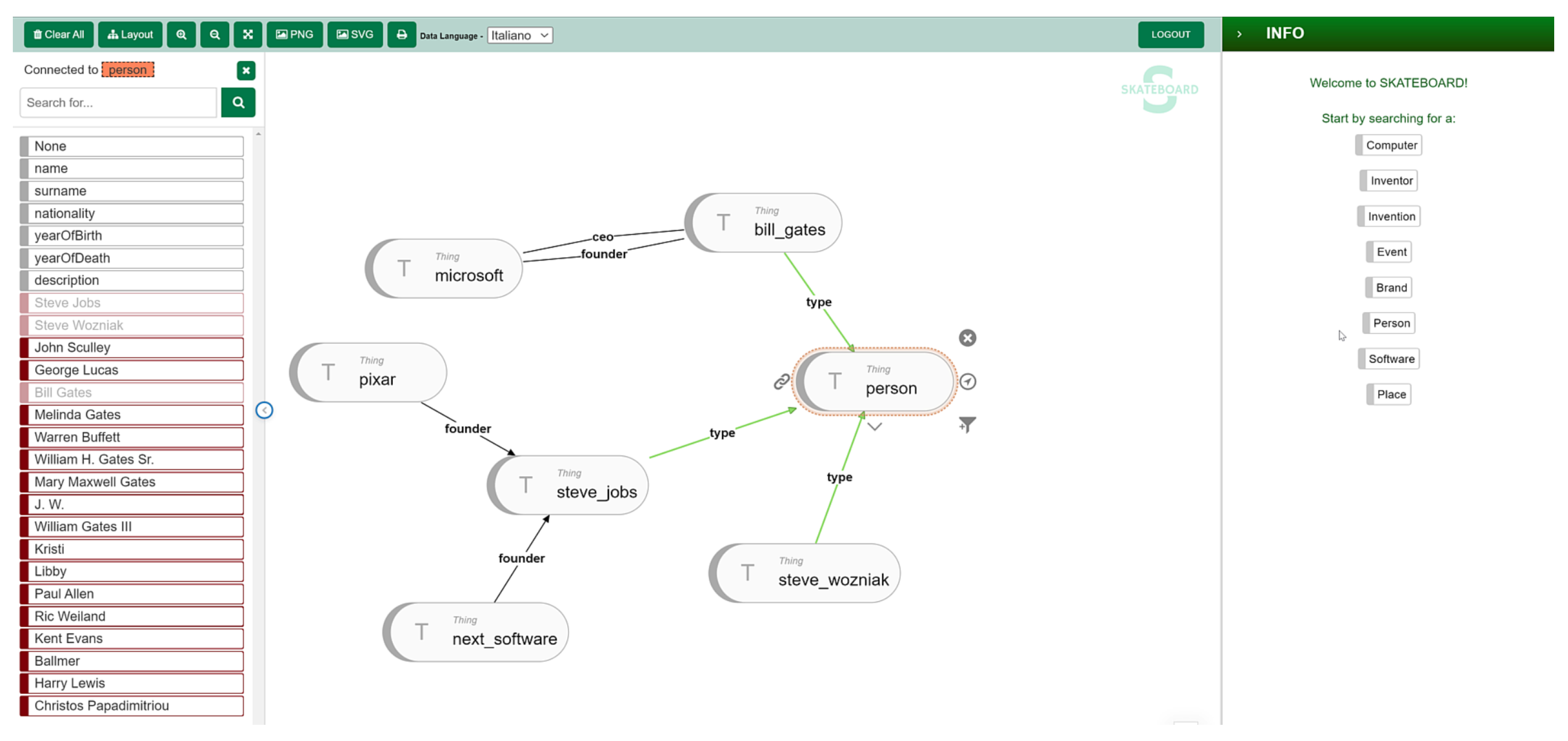
- Task 1: Integrate an ontology created with OntoBuilder into SKATEBOARD and explore the dataset.
- Task 2: Use RDF Explorer to query and visualize a complex ontology generated by OntoBuilder.
- Task 3: Visualize an ontology using LD-VOWL, focusing on the clarity and effectiveness of the visual representation.
- Task 4: Explore a large linked dataset using LOD-Live, starting from a single resource and expanding connections.
6.1. Evaluation Questions
- Integration compatibility: The tool integrates seamlessly with OntoBuilder, effectively supporting the ontologies it produces.
- Ontology representation accuracy: The tool accurately represents the ontologies generated by OntoBuilder, reflecting their structure and semantics as intended.
- Performance: The tool performs efficiently when handling ontologies and datasets created by OntoBuilder, even when they are large or complex.
- Support for OntoBuilder specific features: The tool supports and enhances any unique features of ontologies produced by OntoBuilder (e.g., specific relationships, custom classes).
- Overall effectiveness in task execution: The tool, in conjunction with OntoBuilder, effectively supports the tasks designed for this evaluation.
6.2. Tools Description and Evaluation
- 1.
- SKATEBOARD
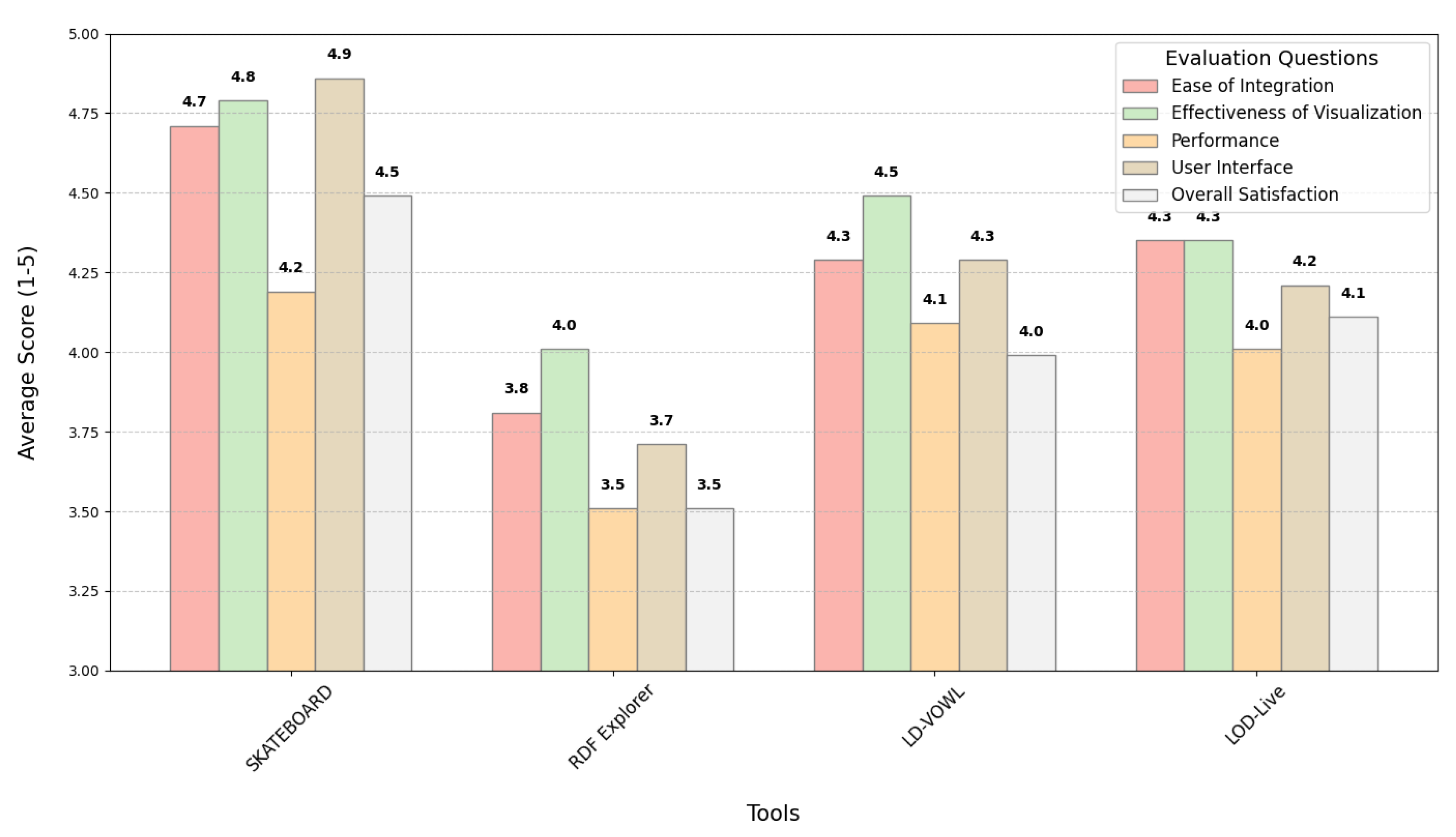
- Integration compatibility 4.7. users found the integration process straightforward.
- Ontology representation accuracy 4.8. The ease of visualizing complex relationships and the real-time modification capabilities of OntoBuilder were highly praised.
- Performance with OntoBuilder ontologies 4.2. users noted occasional performance issues when handling very large datasets.
- Support for OntoBuilder specific features 4.6. SKATEBOARD supported OntoBuilder-specific features effectively.
- Overall Effectiveness in Task Execution 4.5. users expressed high satisfaction with the tool’s effectiveness in completing tasks.
- 2.
- RDF Explorer
- Integration compatibility 3.8. The integration with RDF Explorer involves OntoBuilder’s automated ontology construction, which simplifies the data import process. RDF Explorer accurately reflects the structure and queries of OntoBuilder-created ontologies.
- Ontology representation accuracy 4. The visualizations were found effective.
- Performance with OntoBuilder ontologies 3.5. Users found the performance adequate but noted some challenges with large datasets.
- Support for OntoBuilder specific features 3.7. Support for specific features was noted but could be enhanced.
- Overall effectiveness in task execution 3.5. Users were generally satisfied, with room for improvement.
- 3.
- LD-VOWL
- Integration compatibility 4.3. Users found the integration relatively easy.
- Ontology representation accuracy 4.5. The visual representations were highly praised.
- Performance with OntoBuilder ontologies 4.1. Performance was generally good.
- Support for OntoBuilder specific features 4.2. LD-VOWL effectively supported OntoBuilder’s unique features.
- Overall effectiveness in task execution 4.3. Users were very satisfied with the tool’s effectiveness.
- 4.
- LOD-Live
- Integration compatibility 4.3. The integration process was found to be easy.
- Ontology representation accuracy 4.3. The flexibility and real-time navigation features were highly effective.
- Performance with OntoBuilder ontologies 4.0. Performance was generally good, though some users suggested enhanced data filtering.
- Support for OntoBuilder specific features 4.1. The tool supported OntoBuilder specific features effectively.
- Overall Satisfaction 4.1. Users were satisfied overall.
6.3. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Smith, B. Ontology and Information Systems; Stanford Encyclopedia of Philosophy. Available online: http://ontology.buffalo.edu/ontology_long.pdf (accessed on 29 November 2020).
- Riaño, D.; Real, F.; López-Vallverdú, J.A.; Campana, F.; Ercolani, S.; Mecocci, P.; Annicchiarico, R.; Caltagirone, C. An ontology-based personalization of health-care knowledge to support clinical decisions for chronically ill patients. J. Biomed. Inform. 2012, 45, 429–446. [Google Scholar] [CrossRef] [PubMed]
- Allemang, D.; Hendler, J. Semantic Web for the Working Ontologist: Effective Modeling in RDFS and OWL; Morgan Kaufmann: Cambridge, MA, USA, 2011. [Google Scholar]
- Purohit, S.; Van, N.; Chin, G. Semantic property graph for scalable knowledge graph analytics. In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 15–18 December 2021; pp. 2672–2677. [Google Scholar]
- Angles, R.; Gutierrez, C. Survey of graph database models. ACM Comput. Surv. 2008, 40, 1–39. [Google Scholar] [CrossRef]
- Robinson, I.; Webber, J.; Eifrem, E. Graph Databases: New Opportunities for Connected Data; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2013. [Google Scholar]
- Berners-Lee, T.; Hendler, J.; Lassila, O. The Semantic Web. Sci. Am. 2001, 284, 34–43. [Google Scholar] [CrossRef]
- Ferilli, S.; Basili, R.; Esposito, F. Hybrid approaches to semantic data management. J. Data Semant. 2023, 12, 123–145. [Google Scholar]
- Di Pierro, D.; Ferilli, S.; Redavid, D. Lpg-based knowledge graphs: A survey, a proposal and current trends. Information 2023, 14, 154. [Google Scholar] [CrossRef]
- Ferilli, S.; Bernasconi, E.; Di Pierro, D.; Redavid, D. A Graph DB-Based Solution for Semantic Technologies in the Future Internet. Future Internet 2023, 15, 345. [Google Scholar] [CrossRef]
- Klyne, G.; Carroll, J.J. Resource Description Framework (RDF): Concepts and Abstract Syntax; W3C Recommendation. Available online: https://www.w3.org/TR/rdf11-concepts/ (accessed on 9 September 2024).
- Patel-Schneider, P.F.; Horrocks, I. OWL 2 Web Ontology Language: Structural Specification and Functional-Style Syntax; W3C Recommendation. Available online: https://www.w3.org (accessed on 9 September 2024).
- Sporny, M.; Kellogg, G.; Lanthaler, M. JSON-LD 1.0: A JSON-Based Serialization for Linked Data; W3C Recommendation. 2014. Available online: https://www.w3.org (accessed on 9 September 2024).
- Bizer, C.; Heath, T.; Berners-Lee, T. Linked Data—The Story So Far. In Linking the World’s Information: Essays on Tim Berners-Lee’s Invention of the World Wide Web, 1st ed.; Association for Computing Machinery: New York, NY, USA, 2023; pp. 115–143. [Google Scholar]
- Saleem, M. Storage, Indexing, Query Processing, and Benchmarking in Centralized and Distributed RDF Engines: A Survey. Preprints. 2023. Available online: https://www.authorea.com/doi/pdf/10.36227/techrxiv.12813698.v2 (accessed on 9 September 2024).
- Bernasconi, E.; Ceriani, M.; Mecella, M.; Catarci, T. Design, realization, and user evaluation of the ARCA system for exploring a digital library. Int. J. Digit. Libr. 2023, 24, 1–22. [Google Scholar] [CrossRef]
- Schwartz, C.; Smith, J. Enhancing Metadata for Digital Libraries: Ontology-Based Approaches. J. Digit. Inf. 2008, 9, 1–10. [Google Scholar]
- Hunter, J. Combining RDF and XML Schemas to Enhance Interoperability Between Metadata Application Profiles. Int. J. Digit. Curation 2002, 7, 5–18. [Google Scholar]
- Bandrowski, A.; Brinkman, R.; Brochhausen, M.; Brush, M.H.; Bug, B.; Chibucos, M.C.; Clancy, K.; Courtot, M.; Derom, D.; Dumontier, M.; et al. The ontology for biomedical investigations. PLoS ONE 2016, 11, e0154556. [Google Scholar] [CrossRef]
- Bodenreider, O. The Unified Medical Language System (UMLS): Integrating Biomedical Terminology. Nucleic Acids Res. 2004, 32, 267–270. [Google Scholar] [CrossRef] [PubMed]
- Ashburner, M.; Ball, C.A.; Blake, J.A. Gene Ontology: Tool for the Unification of Biology. Nat. Genet. 2000, 25, 25–29. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, C.; Ong, S.S. Building an ontology for financial investment. In Intelligent Data Engineering and Automated Learning, Proceedings of the IDEAL 2000. Data Mining, Financial Engineering, and Intelligent Agents. IDEAL 2000, Hong Kong, China, 13–15 December 2000; Springer: Berlin/Heidelberg, Germany, 2000; pp. 308–313. [Google Scholar]
- Harrington, R.; Jones, E. Ontologies for Financial Data: Enhancing Decision Making and Compliance. Financ. Res. Lett. 2011, 8, 150–160. [Google Scholar]
- Yu, L.; Johnson, M. The Role of Ontologies in Financial Data Integration and Analysis. J. Financ. Data Sci. 2018, 3, 77–91. [Google Scholar]
- El Bouhissi, H.; Patel, A.; Debnath, N.C. Recommender System for E-Commerce: How Ontologies Support Recommendations. In Data Science with Semantic Technologies; CRC Press: Boca Raton, FL, USA, 2023; pp. 287–297. [Google Scholar]
- Hepp, M. Ontology-Based Product Classification in E-Commerce. Electron. Commer. Res. Appl. 2008, 9, 12–25. [Google Scholar]
- Madin, J.S.; Bowers, S.; Schildhauer, M.P. Advancing Ecological Research with Ontologies. Trends Ecol. Evol. 2008, 23, 159–168. [Google Scholar] [CrossRef] [PubMed]
- Mizoguchi, R.; Ikeda, M.; Yano, Y. Ontological Engineering for Learning Technology. J. Educ. Technol. Soc. 2006, 9, 38–50. [Google Scholar]
- Miller, J.J. Graph database applications and concepts with Neo4j. In Proceedings of the Southern Association for Information Systems Conference, Atlanta, GA, USA, 23–24 March 2013; Volume 2324, pp. 141–147. [Google Scholar]
- Fernandes, D.; Bernardino, J. Graph Databases Comparison: AllegroGraph, ArangoDB, InfiniteGraph, Neo4J, and OrientDB. Data 2018, 10, 0006910203730380. [Google Scholar]
- Ritter, D.; Dell’Aquila, L.; Lomakin, A.; Tagliaferri, E. OrientDB: A NoSQL, Open Source MMDMS. In Proceedings of the BICOD, London, UK, 28 March 2022; pp. 10–19. [Google Scholar]
- Apache Tinkerpop. 2021. Available online: https://tinkerpop.apache.org/ (accessed on 9 September 2024).
- Nguyen, V.; Yip, H.Y.; Thakkar, H.; Li, Q.; Bolton, E.; Bodenreider, O. Singleton Property Graph: Adding A Semantic Web Abstraction Layer to Graph Databases. BlockSW/CKG@ ISWC. 2019, Volume 2599, pp. 1–13. Available online: https://ceur-ws.org/Vol-2599/CKG2019_paper_4.pdf (accessed on 20 July 2024).
- Angles, R.; Thakkar, H.; Tomaszuk, D. Mapping RDF databases to property graph databases. IEEE Access 2020, 8, 86091–86110. [Google Scholar] [CrossRef]
- Hristovski, D.; Kastrin, A.; Dinevski, D.; Rindflesch, T.C. Towards implementing semantic literature-based discovery with a graph database. In Proceedings of the DBKDA 2015, Rome, Italy, 24–29 May 2015; p. 190. [Google Scholar]
- Bernasconi, E.; Di Pierro, D.; Redavid, D.; Ferilli, S. SKATEBOARD: Semantic Knowledge Advanced Tool for Extraction, Browsing, Organisation, Annotation, Retrieval, and Discovery. Appl. Sci. 2023, 13, 1782. [Google Scholar] [CrossRef]
- Bernasconi, E.; Ceriani, M.; Di Pierro, D.; Ferilli, S.; Redavid, D. Linked Data Interfaces: A Survey. Information 2023, 14, 483. [Google Scholar] [CrossRef]
- Vargas, H.; Aranda, C.B.; Hogan, A.; López, C. RDF Explorer: A Visual SPARQL Query Builder. In The Semantic Web—ISWC 2019, Proceedings of the 18th International Semantic Web Conference, Auckland, New Zealand, 26–30 October 2019; Proceedings, Part I; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2019; Volume 11778, pp. 647–663. [Google Scholar] [CrossRef]
- Weise, M.; Lohmann, S.; Haag, F. Ld-vowl: Extracting and visualizing schema information for linked data. In Proceedings of the 2nd International Workshop on Visualization and Interaction for Ontologies and Linked Data, Kobe, Japan, 17 October 2016; pp. 120–127. [Google Scholar]
- Camarda, D.; Mazzini, S.; Antonuccio, A. Lodlive, exploring the web of data. In Proceedings of the I-SEMANTICS 2012—8th International Conference on Semantic Systems, I-SEMANTICS’12, Graz, Austria, 5–7 September 2012; ACM: New York, NY, USA, 2012; pp. 197–200. [Google Scholar]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bernasconi, E.; Ceriani, M.; Ferilli, S. LPG Semantic Ontologies: A Tool for Interoperable Schema Creation and Management. Information 2024, 15, 565. https://doi.org/10.3390/info15090565
Bernasconi E, Ceriani M, Ferilli S. LPG Semantic Ontologies: A Tool for Interoperable Schema Creation and Management. Information. 2024; 15(9):565. https://doi.org/10.3390/info15090565
Chicago/Turabian StyleBernasconi, Eleonora, Miguel Ceriani, and Stefano Ferilli. 2024. "LPG Semantic Ontologies: A Tool for Interoperable Schema Creation and Management" Information 15, no. 9: 565. https://doi.org/10.3390/info15090565
APA StyleBernasconi, E., Ceriani, M., & Ferilli, S. (2024). LPG Semantic Ontologies: A Tool for Interoperable Schema Creation and Management. Information, 15(9), 565. https://doi.org/10.3390/info15090565