
Automatic Detection of Camera Rotation Moments in Trans-Nasal Minimally Invasive Surgery Using Machine Learning Algorithm


Abstract
1. Introduction
2. Materials and Methods
2.1. Environment
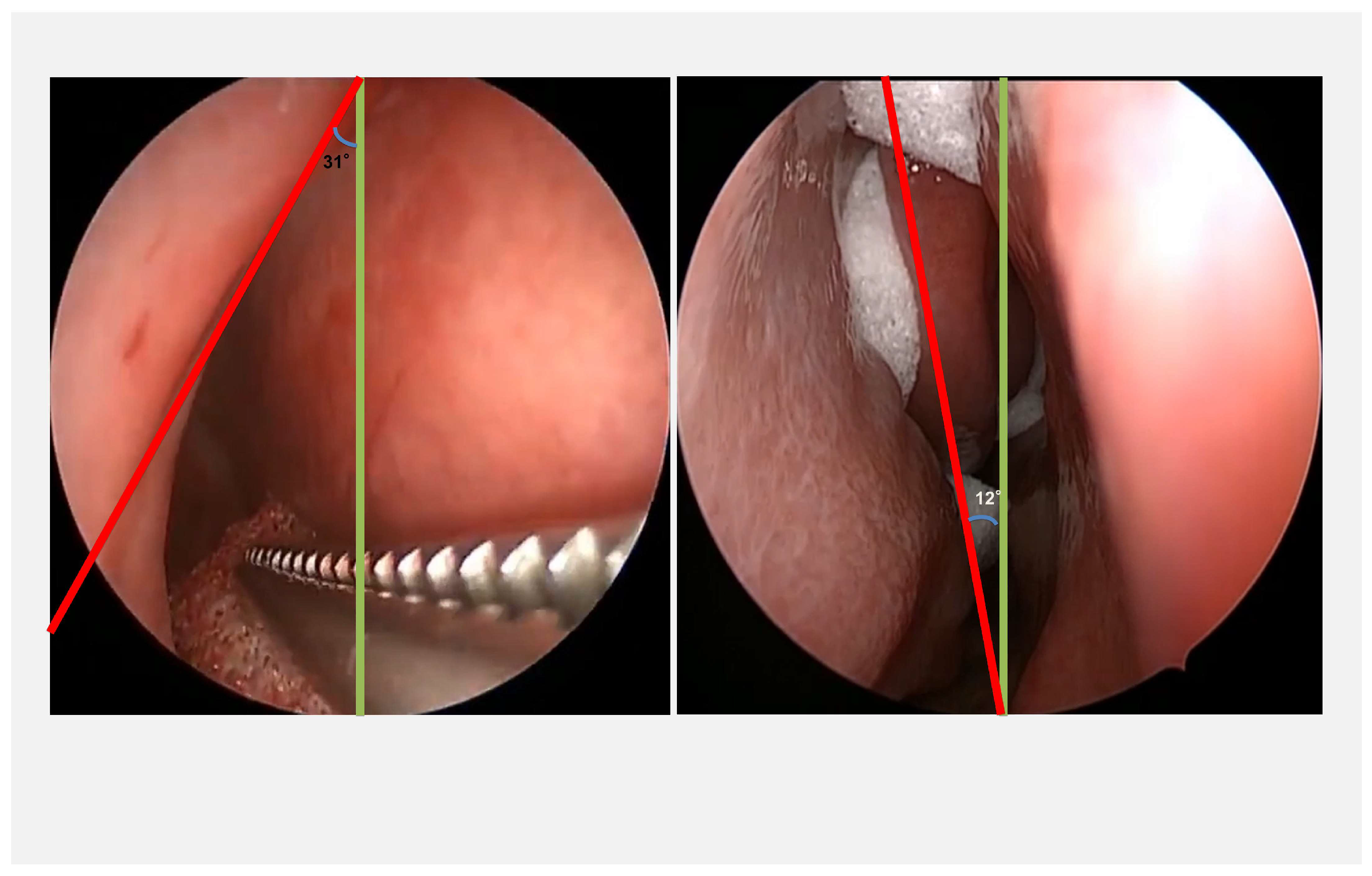
2.2. Data Selection and Image Processing
2.3. Model Selection and Training
3. Results
3.1. Validation Accuracy, Validation Loss, and Statistical Analysis
3.2. Accuracy Parameters and Confusion Matrix
4. Discussion
4.1. Dataset
4.2. Training, Validation, and Test
4.3. Limitations
4.4. Future Directions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Fuchs, K.H. Minimally Invasive Surgery. Endoscopy 2002, 34, 154–159. [Google Scholar] [CrossRef] [PubMed]
- Shah, P.C.; De Groot, A.; Cerfolio, R.; Huang, W.C.; Huang, K.; Song, C.; Li, Y.; Kreaden, U.; Oh, D.S. Impact of type of minimally invasive approach on open conversions across ten common procedures in different specialties. Surg. Endosc. 2022, 36, 6067–6075. [Google Scholar] [CrossRef]
- Darzi, A.; Munz, Y. The Impact of Minimally Invasive Surgical Techniques. Annu. Rev. Med. 2004, 55, 223–237. [Google Scholar] [CrossRef]
- Berguer, R.; Smith, W.D.; Chung, Y.H. Performing laparoscopic surgery is significantly more stressful for the surgeon than open surgery. Surg. Endosc. 2001, 15, 1204–1207. [Google Scholar] [CrossRef] [PubMed]
- Zheng, B.; Cassera, M.A.; Martinec, D.V.; Spaun, G.O.; Swanström, L.L. Measuring mental workload during the performance of advanced laparoscopic tasks. Surg. Endosc. 2010, 24, 45–50. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.S.; Wu, Y.; Zheng, B. A Review of Cognitive Support Systems in the Operating Room. Surg. Innov. 2024, 31, 111–122. [Google Scholar] [CrossRef]
- Wu, Y.; Zhang, Y.; Zheng, B. Workload Assessment of Operators: Correlation Between NASA-TLX and Pupillary Responses. Appl. Sci. 2024, 14, 11975. [Google Scholar] [CrossRef]
- Wu, Y.; Zhang, Z.; Aghazadeh, F.; Zheng, B. Early Eye Disengagement Is Regulated by Task Complexity and Task Repetition in Visual Tracking Task. Sensors 2024, 24, 2984. [Google Scholar] [CrossRef]
- Wu, Y.; Zhang, Z.; Zhang, Y.; Zheng, B.; Aghazadeh, F. Pupil Response in Visual Tracking Tasks: The Impacts of Task Load, Familiarity, and Gaze Position. Sensors 2024, 24, 2545. [Google Scholar] [CrossRef] [PubMed]
- Nema, S.; Mathur, A.; Vachhani, L. Plug-in for visualizing 3D tool tracking from videos of Minimally Invasive Surgeries. arXiv 2024, arXiv:2401.09472. [Google Scholar] [CrossRef]
- Zhang, Y.; Wu, Y.; Li, X.; Turner, S.R.; Zheng, B. Increased team familiarity for surgical time savings: Effective primarily in complex surgical cases. Surgeon 2024, 22, 80–87. [Google Scholar] [CrossRef] [PubMed]
- Hashemi, G.; Zhang, Y.; Wu, Y.; He, W.; Sun, L.; Lee, H.; Wilson-Keates, B.; Zheng, B. Perioperative inter-professional education training enhance team performance and readiness. Clin. Simul. Nurs. 2024, 97, 101655. [Google Scholar] [CrossRef]
- Wentink, M.; Breedveld, P.; Meijer, D.W.; Stassen, H.G. Endoscopic camera rotation: A conceptual solution to improve hand-eye coordination in minimally-invasive surgery. Minim. Invasive Ther. Allied Technol. 2000, 9, 125–131. [Google Scholar] [CrossRef]
- Swanstrom, L.; Zheng, B. Spatial Orientation and Off-Axis Challenges for NOTES. Gastrointest. Endosc. Clin. N. Am. 2008, 18, 315–324. [Google Scholar] [CrossRef] [PubMed]
- Abdelaal, A.E.; Hong, N.; Avinash, A.; Budihal, D.; Sakr, M.; Hager, G.D.; Salcudean, S.E. Orientation Matters: 6-DoF Autonomous Camera Movement for Minimally Invasive Surgery. arXiv 2020, arXiv:2012.02836. [Google Scholar] [CrossRef]
- El Naqa, I. Machine Learning in Radiation Oncology: Theory and Applications; Springer International Publishing AG: Cham, Switzerland, 2015. [Google Scholar]
- Sharma, S.; Guleria, K. Deep Learning Models for Image Classification: Comparison and Applications. In Proceedings of the 2022 2nd International Conference on Advance Computing and Innovative Technologies in Engineering (ICACITE), Greater Noida, India, 28–29 April 2022; pp. 1733–1738. [Google Scholar] [CrossRef]
- Ackerson, J.; Dave, R.; Seliya, N. Applications of Recurrent Neural Network for Biometric Authentication & Anomaly Detection. Information 2021, 12, 272. [Google Scholar] [CrossRef]
- Aggarwal, A.; Mittal, M.; Battineni, G. Generative adversarial network: An overview of theory and applications. Int. J. Inf. Manag. Data Insights 2021, 1, 100004. [Google Scholar] [CrossRef]
- Saxena, D.; Cao, J. Generative Adversarial Networks (GANs): Challenges, Solutions, and Future Directions. ACM Comput. Surv. 2022, 54, 1–42. [Google Scholar] [CrossRef]
- Al Hajj, H.; Lamard, M.; Conze, P.-H.; Cochener, B.; Quellec, G. Monitoring tool usage in surgery videos using boosted convolutional and recurrent neural networks. Med. Image Anal. 2018, 47, 203–218. [Google Scholar] [CrossRef]
- Laina, I.; Rieke, N.; Rupprecht, C.; Vizcaíno, J.P.; Eslami, A.; Tombari, F.; Navab, N. Concurrent Segmentation and Localization for Tracking of Surgical Instruments. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2017: 20th International Conference, Quebec City, QC, Canada, 11–13 September 2017. [Google Scholar] [CrossRef]
- Kurian, E.; Kizhakethottam, J.J.; Mathew, J. Deep learning based Surgical Workflow Recognition from Laparoscopic Videos. In Proceedings of the 2020 5th International Conference on Communication and Electronics Systems (ICCES), Coimbatore, India, 10–12 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 928–931. [Google Scholar] [CrossRef]
- Zhao, H.; Xie, J.; Shao, Z.; Qu, Y.; Guan, Y.; Tan, J. A Fast Unsupervised Approach for Multi-Modality Surgical Trajectory Segmentation. IEEE Access 2018, 6, 56411–56422. [Google Scholar] [CrossRef]
- Peng, Y.; Yang, X.; Li, D.; Ma, Z.; Liu, Z.; Bai, X.; Mao, Z. Predicting flow status of a flexible rectifier using cognitive computing. Expert Syst. Appl. 2025, 264, 125878. [Google Scholar] [CrossRef]
- Bihorac, A.; Ozrazgat-Baslanti, T.; Ebadi, A.; Motaei, A.; Madkour, M.; Pardalos, P.M.; Lipori, G.; Hogan, W.R.; Efron, P.A.; Moore, F.; et al. MySurgeryRisk: Development and Validation of a Machine-learning Risk Algorithm for Major Complications and Death After Surgery. Ann. Surg. 2019, 269, 652–662. [Google Scholar] [CrossRef]
- Martinez, O.; Martinez, C.; Parra, C.A.; Rugeles, S.; Suarez, D.R. Machine learning for surgical time prediction. Comput. Methods Programs Biomed. 2021, 208, 106220. [Google Scholar] [CrossRef]
- Mao, Z.; Kobayashi, R.; Nabae, H.; Suzumori, K. Multimodal Strain Sensing System for Shape Recognition of Tensegrity Structures by Combining Traditional Regression and Deep Learning Approaches. IEEE Robot. Autom. Lett. 2024, 9, 10050–10056. [Google Scholar] [CrossRef]
- Shepard, R.N.; Metzler, J. Mental Rotation of Three-Dimensional Objects. Science 1971, 171, 701–703. [Google Scholar] [CrossRef]
- Sun, Y.; Wong, A.K.C.; Kamel, M.S. Classification of imbalanced data: A review. Int. J. Pattern Recognit. Artif. Intell. 2009, 23, 687–719. [Google Scholar] [CrossRef]
- Japkowicz, N.; Stephen, S. The class imbalance problem: A systematic study. Intell. Data Anal. 2002, 6, 429–449. [Google Scholar] [CrossRef]
- Alaiz-Rodríguez, R.; Japkowicz, N. Assessing the Impact of Changing Environments on Classifier Performance. In Advances in Artificial Intelligence; Bergler, S., Ed.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 13–24. [Google Scholar] [CrossRef]
- Salman, S.; Liu, X. Overfitting Mechanism and Avoidance in Deep Neural Networks. arXiv 2019, arXiv:1901.06566. [Google Scholar] [CrossRef]
- Olliaro, P.; Torreele, E. Managing the risks of making the wrong diagnosis: First, do no harm. Int. J. Infect. Dis. 2021, 106, 382–385. [Google Scholar] [CrossRef]
- Mentis, H.M.; Chellali, A.; Manser, K.; Cao, C.G.L.; Schwaitzberg, S.D. A systematic review of the effect of distraction on surgeon performance: Directions for operating room policy and surgical training. Surg. Endosc. 2016, 30, 1713–1724. [Google Scholar] [CrossRef]
- Kanavel, A.B. The removal of tumors of the pituitary body by an infranasal route: A proposed operation with a description of the technic. J. Am. Med. Assoc. 1909, 53, 1704. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Non-Tilt, 0 | Tilt, 1 | |
|---|---|---|
| Train Set | 1146 | 336 |
| Validation Set | 319 | 105 |
| Test Set | 154 | 56 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.S.; Wu, Y.; Zheng, B. Automatic Detection of Camera Rotation Moments in Trans-Nasal Minimally Invasive Surgery Using Machine Learning Algorithm. Information 2025, 16, 303. https://doi.org/10.3390/info16040303
Zhang ZS, Wu Y, Zheng B. Automatic Detection of Camera Rotation Moments in Trans-Nasal Minimally Invasive Surgery Using Machine Learning Algorithm. Information. 2025; 16(4):303. https://doi.org/10.3390/info16040303
Chicago/Turabian StyleZhang, Zhong Shi, Yun Wu, and Bin Zheng. 2025. "Automatic Detection of Camera Rotation Moments in Trans-Nasal Minimally Invasive Surgery Using Machine Learning Algorithm" Information 16, no. 4: 303. https://doi.org/10.3390/info16040303
APA StyleZhang, Z. S., Wu, Y., & Zheng, B. (2025). Automatic Detection of Camera Rotation Moments in Trans-Nasal Minimally Invasive Surgery Using Machine Learning Algorithm. Information, 16(4), 303. https://doi.org/10.3390/info16040303