



ET-Mamba: A Mamba Model for Encrypted Traffic Classification


Abstract

1. Introduction
2. Related Work
3. Methods
3.1. Balancing in Data Processing
3.2. ET-Mamba Model
3.2.1. Model Design
3.2.2. Random Masking
3.2.3. Mamba Encoder and Decoder
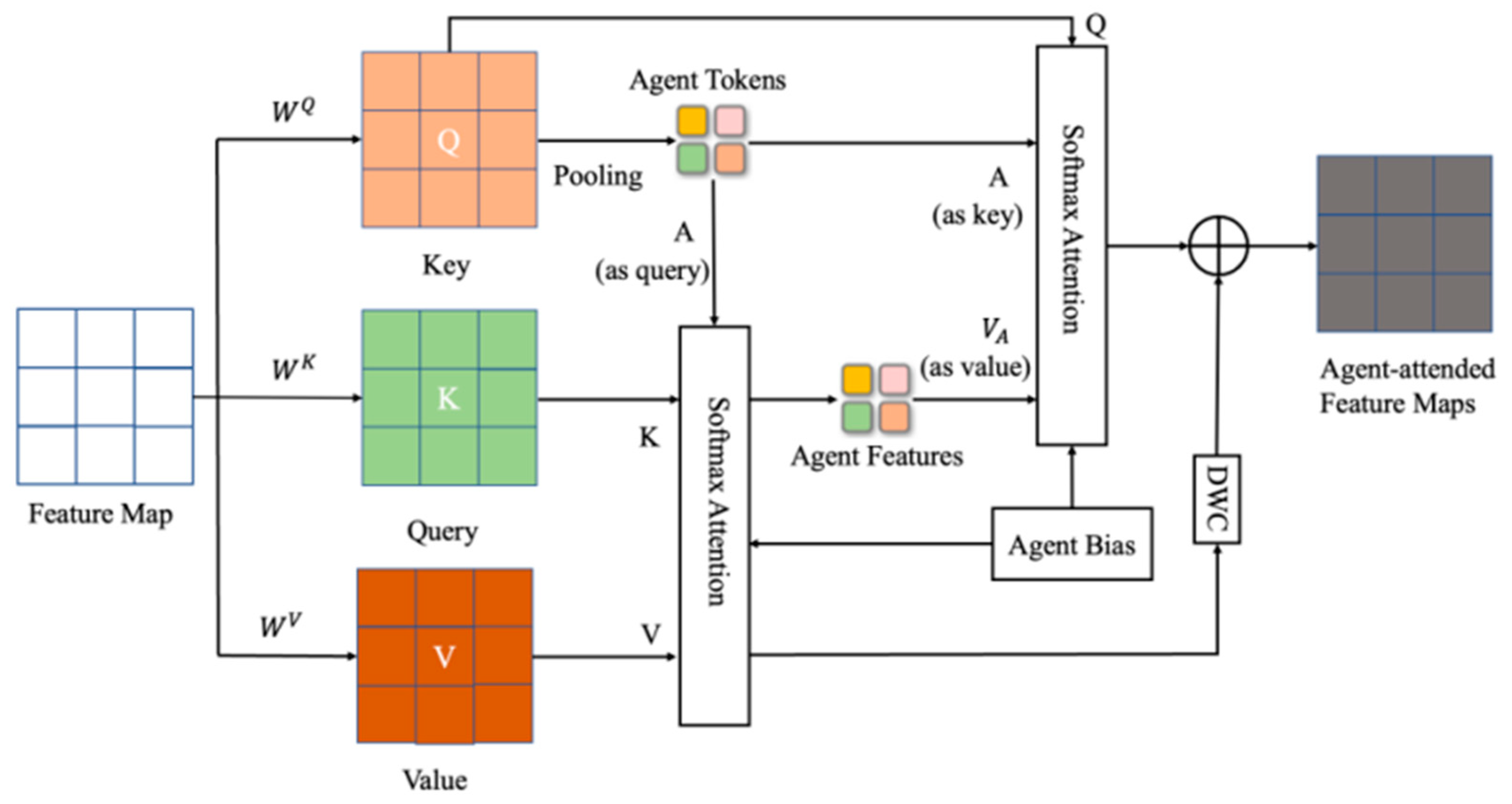
3.2.4. Agent Attention Module
3.2.5. SmoothLoss Function
4. Experiments
4.1. Comparison Experiments
4.2. Ablation Experiments
4.3. Generalization Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gu, A.; Dao, T. Mamba: Linear-time sequence modeling with selective state spaces. arXiv 2023, arXiv:2312.00752. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Bar-Yanai, R.; Langberg, M.; Peleg, D. Realtime classification for encrypted traffic. In Proceedings of the International Symposium on Experimental Algorithms, Naples, Italy, 20–22 May 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 373–385. [Google Scholar]
- Rezaei, S.; Liu, X. Deep learning for encrypted traffic classification: An overview. IEEE Commun. Mag. 2019, 57, 76–81. [Google Scholar] [CrossRef]
- Huang, Y.F.; Lin, C.B.; Chung, C.M. Research on qos classification of network encrypted traffic behavior based on machine learning. Electronics 2021, 10, 1376. [Google Scholar] [CrossRef]
- Wang, W.; Zhu, M.; Wang, J.; Zeng, X.; Yang, Z. End-to-end encrypted traffic classification with one-dimensional convolution neural networks. In Proceedings of the IEEE International Conference on Intelligence and Security Informatics, Beijing, China, 22–24 July 2017; pp. 43–48. [Google Scholar]
- Ren, X.; Gu, H.; Wei, W. Tree-RNN: Tree structural recurrent neural network for network traffic classification. Expert Syst. Appl. 2021, 167, 114363. [Google Scholar] [CrossRef]
- Mei, Y.; Luktarhan, N.; Zhao, G.; Yang, X. An Encrypted Traffic Classification Approach Based on Path Signature Features and LSTM. Electronics 2024, 13, 3060. [Google Scholar] [CrossRef]
- Huoh, T.L.; Luo, Y.; Zhang, T. Encrypted network traffic classification using a geometric learning model. In Proceedings of the 2021 IFIP/IEEE International Symposium on Integrated Network Management, Bordeaux, France, 17–21 May 2021; pp. 376–383. [Google Scholar]
- Zou, Z.; Ge, J.; Zheng, H.; Wu, Y.; Han, C.; Yao, Z. Encrypted traffic classification with a convolutional long short-term memory neural network. In Proceedings of the 2018 IEEE 20th International Conference on High Performance Computing and Communications; IEEE 16th International Conference on Smart City; IEEE 4th International Conference on Data Science and Systems, Exeter, UK, 28–30 June 2018; pp. 329–334. [Google Scholar]
- Wang, K.; Gao, J.; Lei, X. MTC: A Multi-Task Model for Encrypted Network Traffic Classification Based on Transformer and 1D-CNN. Intell. Autom. Soft Comput. 2023, 37, 619. [Google Scholar] [CrossRef]
- Lin, X.; Xiong, G.; Gou, G.; Li, Z.; Shi, J.; Yu, J. Et-bert: A contextualized datagram representation with pre-training transformers for encrypted traffic classification. In Proceedings of the ACM Web Conference, Lyon, France, 25–29 April 2022; pp. 633–642. [Google Scholar]
- Wang, T.; Xie, X.; Wang, W.; Wang, C.; Zhao, Y.; Cui, Y. Netmamba: Efficient network traffic classification via pre-training unidirectional mamba. In Proceedings of the 2024 IEEE 32nd International Conference on Network Protocols (ICNP), Charleroi, Belgium, 28–31 October 2024; pp. 1–11. [Google Scholar]
- Almomani, A. Classification of virtual private networks encrypted traffic using ensemble learning algorithms. Egypt. Inform. J. 2022, 23, 57–68. [Google Scholar] [CrossRef]
- Qin, J.; Liu, G.; Duan, K. A New Imbalanced Encrypted Traffic Classification Model Based on CBAM and Re-Weighted Loss Function. Appl. Sci. 2022, 12, 9631. [Google Scholar] [CrossRef]
- Rao, Y.N.; Suresh Babu, K. An imbalanced generative adversarial network-based approach for network intrusion detection in an imbalanced dataset. Sensors 2023, 23, 550. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Zhu, M.; Zeng, X.; Ye, X.; Sheng, Y. Malware traffic classification using convolutional neural network for representation learning. In Proceedings of the 2017 International Conference on Information Networking, Da Nang, Vietnam, 11–13 January 2017; pp. 712–717. [Google Scholar]
- Draper-Gil, G.; Lashkari, A.H.; Mamun, M.S.I.; Ghorbani, A.A. Characterization of encrypted and vpn traffic using time-related. In Proceedings of the 2nd International Conference on Information Systems Security and Privacy, Rome, Italy, 19–21 February 2016; pp. 407–414. [Google Scholar]
- Lashkari, A.H.; Gil, G.D.; Mamun, M.S.I.; Ghorbani, A.A. Characterization of tor traffic using time based features. In Proceedings of the International Conference on Information Systems Security and Privacy, Funchal, Portugal, 19–21 February 2017; pp. 253–262. [Google Scholar]
- Shapira, T.; Shavitt, Y. Flowpic: Encrypted internet traffic classification is as easy as image recognition. In Proceedings of the IEEE INFOCOM 2019-IEEE Conference on Computer Communications Workshops, Paris, France, 29 April–2 May 2019; pp. 680–687. [Google Scholar]
- Heinsen, F.A. Softmax Attention with Constant Cost per Token. arXiv 2024, arXiv:2404.05843. [Google Scholar]
- Katharopoulos, A.; Vyas, A.; Pappas, N.; Fleuret, F. Transformers are rnns: Fast autoregressive transformers with linear attention. In Proceedings of the International Conference on Machine Learning, Virtual, 12–18 July 2020; pp. 5156–5165. [Google Scholar]
- Han, D.; Ye, T.; Han, Y.; Xia, Z.; Song, S.; Huang, G. Agent attention: On the integration of softmax and linear attention. arXiv 2023, arXiv:2312.08874. [Google Scholar]
- Mao, A.; Mohri, M.; Zhong, Y. Cross-entropy loss functions: Theoretical analysis and applications. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; pp. 23803–23828. [Google Scholar]
- El Moutaouakil, K.; Roudani, M.; Ouhmid, A.; Zhilenkov, A.; Mobayen, S. Decomposition and Symmetric Kernel Deep Neural Network Fuzzy Support Vector Machine. Symmetry 2024, 16, 1585. [Google Scholar] [CrossRef]
- Lotfollahi, M.; Jafari Siavoshani, M.; Shirali Hossein Zade, R.; Saberian, M. Deep packet: A novel approach for encrypted traffic classification using deep learning. Soft Comput. 2020, 24, 1999–2012. [Google Scholar] [CrossRef]
- Liu, C.; He, L.; Xiong, G.; Cao, Z.; Li, Z. Fs-net: A flow sequence network for encrypted traffic classification. In Proceedings of the IEEE INFOCOM 2019-IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019; pp. 1171–1179. [Google Scholar]
- He, H.Y.; Yang, Z.G.; Chen, X.N. PERT: Payload encoding representation from transformer for encrypted traffic classification. In Proceedings of the 2020 ITU Kaleidoscope: Industry-Driven Digital Transformation, Hanoi, Vietnam, 7–11 December 2020; pp. 1–8. [Google Scholar]
- Lin, K.; Xu, X.; Gao, H. TSCRNN: A novel classification scheme of encrypted traffic based on flow spatiotemporal features for efficient management of IIoT. Comput. Netw. 2021, 190, 107974. [Google Scholar] [CrossRef]
- Goyal, P.; Dollár, P.; Girshick, R. Accurate, large minibatch sgd: Training imagenet in 1 hour. arXiv 2017, arXiv:1706.02677. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Traffic Category | File Size |
|---|---|
| chat | 57 MB |
| 21 MB | |
| file | 17.6 GB |
| p2p | 458 MB |
| streaming | 2.9 GB |
| voip | 4.84 GB |
| Traffic Category | File Size |
|---|---|
| audio | 1.4 GB |
| browsing | 2 GB |
| chat | 45 MB |
| file | 13 GB |
| 16 MB | |
| p2p | 359 MB |
| Traffic Category | File Size | Traffic Category | File Size |
|---|---|---|---|
| BitTorrent | 7 MB | Cridex | 94 MB |
| Facetime | 2 MB | Geodo | 29 MB |
| FTP | 60 MB | Htbot | 84 MB |
| Gmail | 9 MB | Miuref | 16 MB |
| MySQL | 22 MB | Neris | 90 MB |
| Outlook | 11 MB | Nsis-ay | 281 MB |
| Skype | 4 MB | Shifu | 58 MB |
| SMB | 1.2 GB | Tinba | 2 MB |
| 1.6 GB | Virut | 109 MB | |
| WorldOfWarcraft | 15 MB | Zeus | 13 MB |
| Methods | Params | Ac | Pr | Re | F1 |
|---|---|---|---|---|---|
| DeepPacket [26] | 4.8 M | 96.40 | 96.50 | 96.31 | 96.41 |
| FS-Net [27] | 5.3 M | 69.82 | 84.83 | 70.40 | 76.75 |
| PERT [28] | 110.2 M | 99.10 | 99.10 | 99.10 | 99.10 |
| TSCRNN [29] | 2.9 M | 98.78 | 98.70 | 98.60 | 98.70 |
| ET-BERT [12] | 136.4 M | 99.15 | 99.15 | 99.16 | 99.16 |
| ET-Mamba | 1.8 M | 99.84 | 99.85 | 99.84 | 99.84 |
| Methods | Params | Ac | Pr | Re | F1 |
|---|---|---|---|---|---|
| DeepPacket [26] | 4.8 M | 93.29 | 93.77 | 93.06 | 93.41 |
| FS-Net [27] | 5.3 M | 67.84 | 69.17 | 67.75 | 68.45 |
| PERT [28] | 110.2 M | 93.50 | 94.40 | 93.50 | 93.70 |
| TSCRNN [29] | 2.9 M | 92.89 | 92.70 | 92.60 | 92.60 |
| ET-BERT [12] | 136.4 M | 98.90 | 98.91 | 98.90 | 98.90 |
| ET-Mamba | 1.8 M | 98.19 | 98.23 | 99.19 | 98.71 |
| Methods | Params | Ac | Pr | Re | F1 |
|---|---|---|---|---|---|
| DeepPacket [26] | 4.8 M | 74.49 | 75.49 | 73.99 | 74.73 |
| FS-Net [27] | 5.3 M | 80.73 | 81.46 | 81.41 | 81.43 |
| PERT [28] | 110.2 M | 82.30 | 70.90 | 71.70 | 69.90 |
| TSCRNN [29] | 2.9 M | 95.16 | 94.90 | 94.80 | 94.80 |
| ET-BERT [12] | 136.4 M | 99.21 | 99.23 | 99.21 | 99.21 |
| ET-Mamba | 1.8 M | 99.65 | 99.66 | 99.65 | 99.65 |
| Methods | DeepPacket | FS-Net | PERT | TSCRNN | ET-BERT | ET-Mamba |
|---|---|---|---|---|---|---|
| Run Time | 6.4 s | 7.1 s | 147.2 s | 3.9 s | 180.2 s | 2.4 s |
| Resample | Agent | Smooth | CrossEntry | Ac | Pr | Re | F1 |
|---|---|---|---|---|---|---|---|
| × | × | × | √ | 96.20 | 95.83 | 94.88 | 95.35 |
| √ | × | × | √ | 97.13 | 95.88 | 97.95 | 96.90 |
| × | × | √ | × | 97.35 | 95.40 | 95.85 | 95.62 |
| √ | × | √ | × | 98.97 | 96.63 | 96.44 | 96.54 |
| × | √ | × | √ | 96.95 | 96.87 | 96.33 | 96.60 |
| √ | √ | × | √ | 99.12 | 99.50 | 98.25 | 98.87 |
| × | √ | √ | × | 98.78 | 98.29 | 98.75 | 98.52 |
| √ | √ | √ | × | 99.84 | 99.85 | 99.84 | 99.84 |
| Resample | Agent | Smooth | CrossEntry | Ac | Pr | Re | F1 |
|---|---|---|---|---|---|---|---|
| × | × | × | √ | 96.35 | 95.80 | 96.24 | 96.02 |
| √ | × | × | √ | 96.79 | 98.26 | 98.48 | 98.37 |
| × | × | √ | × | 97.25 | 97.15 | 98.11 | 97.63 |
| √ | × | √ | × | 99.29 | 98.77 | 98.06 | 98.41 |
| × | √ | × | √ | 97.32 | 96.55 | 97.29 | 96.92 |
| √ | √ | × | √ | 97.77 | 98.80 | 98.92 | 98.86 |
| × | √ | √ | × | 97.18 | 96.84 | 98.55 | 97.69 |
| √ | √ | √ | × | 98.19 | 98.23 | 99.19 | 98.71 |
| Resample | Agent | Smooth | CrossEntry | Ac | Pr | Re | F1 |
|---|---|---|---|---|---|---|---|
| × | × | × | √ | 96.35 | 96.24 | 95.89 | 96.06 |
| √ | × | × | √ | 97.21 | 96.23 | 97.21 | 96.72 |
| × | × | √ | × | 97.25 | 96.88 | 97.53 | 97.20 |
| √ | × | √ | × | 98.49 | 98.49 | 97.13 | 97.81 |
| × | √ | × | √ | 98.12 | 97.79 | 98.11 | 97.95 |
| √ | √ | × | √ | 98.06 | 98.95 | 97.10 | 98.02 |
| × | √ | √ | × | 98.12 | 97.98 | 98.67 | 98.32 |
| √ | √ | √ | × | 99.65 | 99.66 | 99.65 | 99.65 |
| Model | Test Set from ISCX-VPN2016 | Test Set from ISCX-TOR2016 | ||
|---|---|---|---|---|
| Ac | F1 | Ac | F1 | |
| Model trained on ISCX-VPN2016 | 98.19 | 98.71 | 99.65 | 99.65 |
| Model trained on ISCX-TOR2016 | 99.18 | 99.40 | 99.65 | 99.65 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, J.; Chen, L.; Xu, W.; Dai, L.; Wang, C.; Hu, L. ET-Mamba: A Mamba Model for Encrypted Traffic Classification. Information 2025, 16, 314. https://doi.org/10.3390/info16040314
Xu J, Chen L, Xu W, Dai L, Wang C, Hu L. ET-Mamba: A Mamba Model for Encrypted Traffic Classification. Information. 2025; 16(4):314. https://doi.org/10.3390/info16040314
Chicago/Turabian StyleXu, Jian, Liangbing Chen, Wenqian Xu, Longxuan Dai, Chenxi Wang, and Lei Hu. 2025. "ET-Mamba: A Mamba Model for Encrypted Traffic Classification" Information 16, no. 4: 314. https://doi.org/10.3390/info16040314
APA StyleXu, J., Chen, L., Xu, W., Dai, L., Wang, C., & Hu, L. (2025). ET-Mamba: A Mamba Model for Encrypted Traffic Classification. Information, 16(4), 314. https://doi.org/10.3390/info16040314