

Transfer Learning for Facial Expression Recognition

 ,
, 
 , and
, and
Abstract
1. Introduction
Datasets and Model Overview
- It uses a cutting-edge CNN model to identify emotions from facial expressions;
- It includes a suitable number of layers in the CNN model for effective emotion detection and classification from facial images;
- It aids in the creation of more sophisticated real-world applications for multimodal (visual) expression-based emotion detection systems;
- Deep learning models, including VGG-19 and ResNet-152, are used to categorize various facial emotions, including neutral, happy, sad and furious.
2. Related Work on Facial Expression Recognition
3. DoctorLINK: Integrating Deep Learning for Facial Expression Recognition
3.1. Functional Principles of Remote Monitoring
3.2. Platform Description, Usability, Security and Privacy
4. Materials and Methods
4.1. Face Detection
- Preprocess the input images (sequential images) from the dataset through filtering and normalization techniques.
- Separate training and testing phases: the former includes balancing and training the images; the latter converts the images to feature vectors and defines the trained model.
- Include the CNN architecture by defining the training schemes and further choosing the right activation function. The testing and validation results in the form of seven features of facial expressions.
- Present the accuracy, precision, recall and F1-score (Section 5) of the overall methodology.
4.2. Datasets and Settings
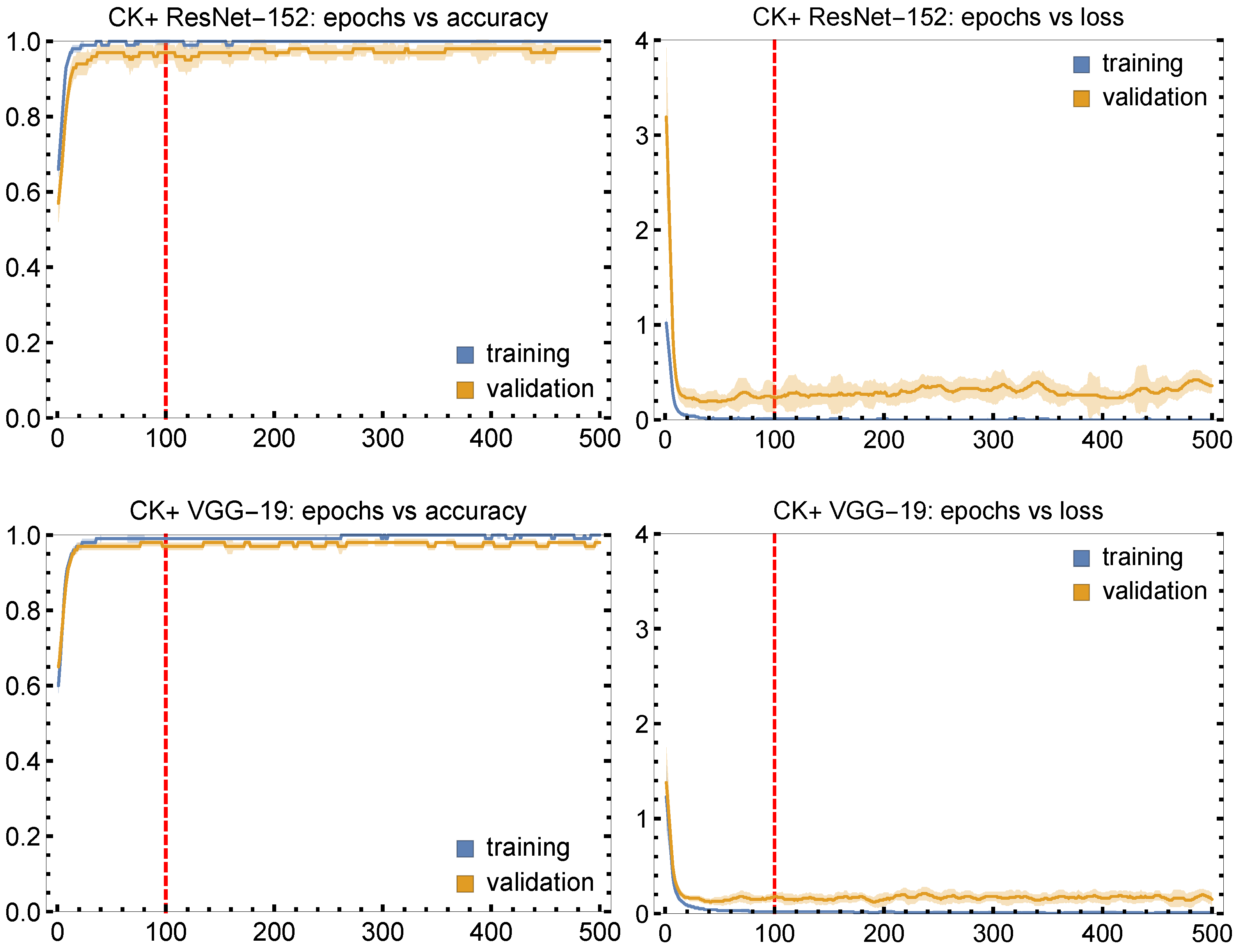
5. Results and Discussion
- TP: correctly predicted positive samples (true positives);
- FP: incorrectly predicted positive samples (false positives);
- FN: missed positive samples (false negatives);
- TN: correctly predicted negative samples (true negatives)).
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shan, K.; Guo, J.; You, W.; Lu, D.; Bie, R. Automatic facial expression recognition based on a deep convolutional-neural-network structure. In Proceedings of the 15th International Conference on Software Engineering Research, Management and Applications, London, UK, 7–9 June 2017; pp. 123–128. [Google Scholar]
- Ghosh, S.; Priyankar, A.; Ekbal, A.; Bhattacharyya, P. Multitasking of sentiment detection and emotion recognition in code-mixed Hinglish data. Knowl. Based Syst. 2023, 260, 110182. [Google Scholar] [CrossRef]
- Karilingappa, K.; Jayadevappa, D.; Ganganna, S. Human emotion detection and classification using modified Viola-Jones and convolution neural network. IAES Int. J. Artif. Intell. 2023, 12, 79. [Google Scholar] [CrossRef]
- Banskota, N.; Alsadoon, A.; Prasad, P.; Dawoud, A.; Rashid, T.; Alsadoon, O. A novel enhanced convolution neural network with extreme learning machine: Facial emotional recognition in psychology practices. Multimed. Tools Appl. 2023, 82, 6479–6503. [Google Scholar] [CrossRef]
- Li, S.; Deng, W. Deep facial expression recognition: A survey. Trans. Affect. Comput. 2020, 13, 1195–1215. [Google Scholar] [CrossRef]
- Ashok Kumar, P.; Maddala, J.; Martin Sagayam, K. Enhanced facial emotion recognition by optimal descriptor selection with the neural network. IETE J. Res. 2023, 69, 2595–2614. [Google Scholar] [CrossRef]
- Gupta, S.; Kumar, P.; Tekchandani, R. Facial emotion recognition based real-time learner engagement detection system in online learning context using deep learning models. Multimed. Tools Appl. 2023, 82, 11365–11394. [Google Scholar] [CrossRef]
- Shahzad, T.; Iqbal, K.; Khan, M.; Iqbal, N. Role of zoning in facial expression using deep learning. IEEE Access 2023, 11, 16493–16508. [Google Scholar] [CrossRef]
- Meena, G.; Mohbey, K.; Kumar, S. Sentiment analysis on images using convolutional neural networks-based Inception-V3 transfer learning approach. Int. J. Inf. Manag. Data Insights 2023, 3, 100174. [Google Scholar] [CrossRef]
- Singh, P.; Pandey, S.; Sharma, A.; Gupta, T. Implemented Model for CNN Facial Expressions: Emotion Recognition. In Proceedings of the International Conference on Sustainable Emerging Innovations in Engineering and Technology, Ghaziabad, India, 14–15 September 2023; pp. 732–737. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the Computer Vision and Pattern Recognition, Kauai, HI, USA, 8–14 December 2001; Volume 1. [Google Scholar]
- Halder, S.; Afsari, K. Robots in inspection and monitoring of buildings and infrastructure: A systematic review. Appl. Sci. 2023, 13, 2304. [Google Scholar] [CrossRef]
- Tembhurne, J.V.; Diwan, T. Sentiment analysis in textual, visual and multimodal inputs using recurrent neural networks. Multimed. Tools Appl. 2021, 80, 6871–6910. [Google Scholar] [CrossRef]
- Chandrasekaran, G.; Antoanela, N.; Andrei, G.; Monica, C.; Hemanth, J. Visual sentiment analysis using deep learning models with social media data. Appl. Sci. 2022, 12, 1030. [Google Scholar] [CrossRef]
- Swarnkar, M.; Rajput, S. (Eds.) Artificial Intelligence for Intrusion Detection Systems; CRC Press: Boca Raton, FL, USA, 2023. [Google Scholar]
- Jang, G.; Kim, D.; Lee, I.; Jung, H. Cooperative Beamforming with Artificial Noise Injection for Physical-Layer Security. IEEE Access 2023, 11, 22553–22573. [Google Scholar] [CrossRef]
- Lucey, P.; Cohn, J.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The extended Cohn-Kanade dataset (CK+): A complete dataset for action unit and emotion-specified expression. In Proceedings of the Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 94–101. [Google Scholar]
- Goodfellow, I.; Erhan, D.; Carrier, P.; Courville, A.; Mirza, M.; Hamner, B.; Cukierski, W.e.a. Challenges in representation learning: A report on three machine learning contests. In Proceedings of the 20th International Conference on Neural Information Processing, Daegu, Republic of Korea, 3–7 November 2013; Springer: Berlin/Heidelberg, Germany, 2013; Volume 20, pp. 117–124. [Google Scholar]
- Lyons, M.; Akamatsu, S.; Kamachi, M.; Gyoba, J. Coding facial expressions with Gabor wavelets. In Proceedings of the 3rd International Conference on Automatic Face and Gesture Recognition, Nara, Japan, 14–16 April 1998; pp. 200–205. [Google Scholar]
- Mollahosseini, A.; Chan, D.; Mahoor, M.H. Going deeper in facial expression recognition using deep neural networks. In Proceedings of the Applications of Computer Vision, Lake Placid, NY, USA, 7–10 March 2016; pp. 1–10. [Google Scholar]
- Miolla, A.; Cardaioli, M.; Scarpazza, C. Padova Emotional Dataset of Facial Expressions (PEDFE): A unique dataset of genuine and posed emotional facial expressions. Behav. Res. 2023, 55, 2559–2574. [Google Scholar] [CrossRef]
- Romani-Sponchiado, A.; Sanvicente-Vieira, B.; Mottin, C.; Hertzog-Fonini, D.; Arteche, A. Child Emotions Picture Set (CEPS): Development of a database of children’s emotional expressions. Psychol. Neurosci. 2015, 8, 467. [Google Scholar] [CrossRef]
- Benitez-Quiroz, F.; Srinivasan, R.; Martinez, A.M. Emotionet: An accurate, real-time algorithm for the automatic annotation of a million facial expressions in the wild. In Proceedings of the Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5562–5570. [Google Scholar]
- Mascaró-Oliver, M.; Mas-Sansó, R.; Amengual-Alcover, E.; Roig-Maimó, M.F. UIBVFED-mask: A dataset for comparing facial expressions with and without face masks. Data 2023, 8, 17. [Google Scholar] [CrossRef]
- Zhang, W.; Song, P.; Zheng, W. Joint local-global discriminative subspace transfer learning for facial expression recognition. Trans. Affect. Comput. 2022, 14, 2484–2495. [Google Scholar] [CrossRef]
- Li, X.; Xiao, Z.; Li, C.; Li, C.; Liu, H.; Fan, G. Facial expression recognition network with slow convolution and zero-parameter attention mechanism. Optik 2023, 283, 170892. [Google Scholar] [CrossRef]
- Fan, S.; Jiang, M.; Shen, Z.; Koenig, B.; Kankanhalli, M.; Zhao, Q. The role of visual attention in sentiment prediction. In Proceedings of the 25th ACM international conference on Multimedia, Mountain View, CA, USA, 13–37 October 2017; pp. 217–225. [Google Scholar]
- Chen, T.; Borth, D.; Darrell, T.; Chang, S. Deepsentibank: Visual sentiment concept classification with deep convolutional neural networks. arXiv 2014, arXiv:1410.8586. [Google Scholar]
- Marab, S.; Pawar, M. Feature Learning for Effective Content-Based Image Retrieval. In Proceedings of the Computer Vision and Image Processing: 4th International Conference, Bangkok, Thailand, 9 –11 December 2020; Springer: Singapore, 2020; Volume 4, pp. 395–404. [Google Scholar]
- Ali, L.; Alnajjar, F.; Jassmi, H.; Gocho, M.; Khan, W.; Serhani, M. Performance evaluation of deep CNN-based crack detection and localization techniques for concrete structures. Sensors 2021, 21, 1688. [Google Scholar] [CrossRef]
- Ali, M.; Khatun, M.; Turzo, N. Facial emotion detection using neural network. Int. J. Sci. Eng. Res. 2020, 11, 1318–1325. [Google Scholar]
- Helaly, R.; Messaoud, S.; Bouaafia, S.; Hajjaji, M.; Mtibaa, A. DTL-I-ResNet18: Facial emotion recognition based on deep transfer learning and improved ResNet18. Signal Image Video Process. 2023, 17, 2731–2744. [Google Scholar] [CrossRef]
- Liu, J.; Fu, F. Convolutional neural network model by deep learning and teaching robot in keyboard musical instrument teaching. PLoS ONE 2023, 18, e0293411. [Google Scholar] [CrossRef] [PubMed]
- Taha, B.; Hatzinakos, D. Emotion recognition from 2D facial expressions. In Proceedings of the Canadian Conference of Electrical and Computer Engineering, Edmonton, AB, Canada, 5–8 May 2019; pp. 1–4. [Google Scholar]
- Wu, C.; Chai, L.; Yang, J.; Sheng, Y. Facial expression recognition using convolutional neural network on graphs. In Proceedings of the Chinese Control Conference, Guangzhou, China, 27–30 July 2019; pp. 7572–7576. [Google Scholar]
- Rasamoelina, A.; Adjailia, F.; SinČàk, P. Deep convolutional neural network for robust facial emotion recognition. In Proceedings of the International Symposium on INnovations in Intelligent SysTems and Applications, Sofia, Bulgaria, 3–5 July 2019; pp. 1–6. [Google Scholar]
- Cambria, E.; Das, D.; Bandyopadhyay, S.; Feraco, A. A Practical Guide to Sentiment Analysis; Springer International Publishing: Berlin/Heidelberg, Germany, 2017; Volume 5. [Google Scholar]
- Islam, J.; Zhang, Y. Visual sentiment analysis for social images using transfer learning approach. In Proceedings of the International Conference on Big Data and Cloud Computing, Macau, China, 16–18 November 2016; pp. 124–130. [Google Scholar]
- Meena, G.; Mohbey, K.; Indian, A. Categorizing sentiment polarities in social networks data using convolutional neural network. SN Comput. Sci. 2022, 3, 116. [Google Scholar] [CrossRef]
- Ben, X.; Ren, Y.; Zhang, J.; Wang, S.J.; Kpalma, K.; Meng, W.; Liu, Y.J. Video-based facial micro-expression analysis: A survey of datasets, features and algorithms. Trans. Pattern Anal. Mach. Intell. 2021, 44, 5826–5846. [Google Scholar] [CrossRef] [PubMed]
- Lei, Y.; Cao, H. Audio-Visual Emotion Recognition with Preference Learning Based on Intended and Multi-Modal Perceived Labels. Trans. Affect. Comput. 2023, 14, 2954–2969. [Google Scholar] [CrossRef]
- Karnati, M.; Seal, A.; Bhattacharjee, D.; Yazidi, A.; Krejcar, O. Understanding deep learning techniques for recognition of human emotions using facial expressions: A comprehensive survey. Trans. Instrum. Meas. 2023, 72, 5006631. [Google Scholar] [CrossRef]
- Kanna, R.K.; Kripa, N.; Vasuki, R. Systematic Design of Lie Detector System Utilizing EEG Signals Acquisition. Int. J. Sci. Technol. Res. 2023, 9, 610–612. [Google Scholar]
- Ekundayo, O.; Viriri, S. Facial expression recognition: A review of trends and techniques. IEEE Access 2021, 9, 136944–136973. [Google Scholar] [CrossRef]
- Saurav, S.; Singh, S.; Saini, R.; Yadav, M. Facial expression recognition using improved adaptive local ternary pattern. In Proceedings of the 3rd International Conference on Computer Vision and Image Processing, Prayagraj, India, 4–6 December 2020; pp. 39–52. [Google Scholar]
- Niu, B.; Gao, Z.; Guo, B. Facial expression recognition with LBP and ORB features. Comput. Intell. Neurosci. 2021, 2021, 8828245. [Google Scholar] [CrossRef]
- Lu, F.; Zhang, L.; Tian, G. User Emotion Recognition Method Based on Facial Expression and Speech Signal Fusion. In Proceedings of the 16th Conference on Industrial Electronics and Applications, Chengdu, China, 1–4 August 2021; pp. 1121–1126. [Google Scholar]
- Zhang, J.; Yu, H. Improving the facial expression recognition and its interpretability via generating expression pattern-map. Pattern Recognit. 2022, 129, 108737. [Google Scholar] [CrossRef]
- Poux, D.; Allaert, B.; Ihaddadene, N.; Bilasco, I.; Djeraba, C.; Bennamoun, M. Dynamic facial expression recognition under partial occlusion with optical flow reconstruction. Trans. Image Process. 2021, 31, 446–457. [Google Scholar] [CrossRef] [PubMed]
- Poux, D.; Allaert, B.; Mennesson, J.; Ihaddadene, N.; Bilasco, I.; Djeraba, C. Facial expressions analysis under occlusions based on specificities of facial motion propagation. Multimed. Tools Appl. 2021, 80, 22405–22427. [Google Scholar] [CrossRef]
- Kumar, R.; Hussain, S. A review of the deep convolutional neural networks for the analysis of facial expressions. J. Innov. Technol. 2024, 6, 41–49. [Google Scholar]
- Tang, Y.; Zhang, X.; Hu, X.; Wang, S.; Wang, H. Facial expression recognition using frequency neural network. Trans. Image Process. 2020, 30, 444–457. [Google Scholar] [CrossRef] [PubMed]
- Patel, K.; Mehta, D.; Mistry, C.; Gupta, R.; Tanwar, S.; Kumar, N.; Alazab, M. Facial sentiment analysis using AI techniques: State-of-the-art, taxonomies, and challenges. IEEE Access 2020, 8, 90495–90519. [Google Scholar] [CrossRef]
- Zhang, Y.; Yang, Z.; Lu, H.; Zhou, X.; Phillips, P.; Liu, Q.; Wang, S. Facial emotion recognition based on biorthogonal wavelet entropy, fuzzy support vector machine, and stratified cross validation. IEEE Access 2016, 4, 8375–8385. [Google Scholar] [CrossRef]
- Siqueira, H.; Magg, S.; Wermter, S. Efficient facial feature learning with wide ensemble-based convolutional neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 5800–5809. [Google Scholar]
- Fu, X.; Wu, Z.; Wang, W.; Xie, T.; Keten, S.; Gomez-Bombarelli, R.; Jaakkola, T. Forces are not enough: Benchmark and critical evaluation for machine learning force fields with molecular simulations. arXiv 2022, arXiv:2210.07237. [Google Scholar]
- Lu, R.; Zhao, X.; Li, J.; Niu, P.; Yang, B.; Wu, H.; Wang, W.; Song, H.; Huang, B.; Zhu, N.; et al. Genomic characterisation and epidemiology of 2019 novel coronavirus: Implications for virus origins and receptor binding. Lancet 2020, 395, 565–574. [Google Scholar] [CrossRef]
- Abdullah, S.M.S.; Abdulazeez, A.M. Facial expression recognition based on deep learning convolution neural network: A review. J. Soft Comput. Data Min. 2021, 2, 53–65. [Google Scholar]
- Huang, Y.; Chen, F.; Lv, S.; Wang, X. Facial expression recognition: A survey. Symmetry 2019, 11, 1189. [Google Scholar] [CrossRef]
- Zheng, H.; Wang, R.; Ji, W.; Zong, M.; Wong, W.; Lai, Z.; Lv, H. Discriminative deep multi-task learning for facial expression recognition. Inf. Sci. 2020, 533, 60–71. [Google Scholar] [CrossRef]
- Poruşniuc, G.; Leon, F.; Timofte, R.; Miron, C. Convolutional neural networks architectures for facial expression recognition. In Proceedings of the E-Health and Bioengineering Conference, Iasi, Romania, 21–23 November 2019; pp. 1–6. [Google Scholar]
- Hung, J.C.; Lin, K.C.; Lai, N.X. Recognizing learning emotion based on convolutional neural networks and transfer learning. Appl. Soft Comput. 2019, 84, 105724. [Google Scholar] [CrossRef]
- Kusuma, G.P.; Jonathan, J.; Lim, A. Emotion recognition on fer-2013 face images using fine-tuned vgg-16. Adv. Sci. Technol. Eng. Syst. J. 2020, 5, 315–322. [Google Scholar] [CrossRef]
- eHealth Products by Italtel. Available online: https://www.italtel.com/doctorlink-digital-health-in-your-hands (accessed on 13 April 2025).
- Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016. Available online: https://eur-lex.europa.eu/eli/reg/2016/679/oj (accessed on 15 April 2025).
- Bagherian, E.; Rahmat, R. Facial feature extraction for face recognition: A review. In Proceedings of the International Symposium on Information Technology, Kuala Lumpur, Malaysia, 26–29 August 2008; Volume 2, pp. 1–9. [Google Scholar]
- Zhang, N.; Luo, J.; Gao, W. Research on face detection technology based on MTCNN. In Proceedings of the International Conference on Computer Network, Electronic and Automation, Xi’an, China, 25–27 September 2020; pp. 154–158. [Google Scholar]
- Sandeep, P.; Kumar, N.S. Pain detection through facial expressions in children with autism using deep learning. Soft Comput. 2024, 28, 4621–4630. [Google Scholar] [CrossRef]
- Yang, W.; Zheng, Z. Real-time face detection based on YOLO. In Proceedings of the Knowledge Innovation and Invention, Jeju Island, Repunlic of Korea, 23–27 July 2018; pp. 221–224. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- McKinney, W. Data Structures for Statistical Computing in Python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A System for Large-Scale Machine Learning. Version 2.5. 2021. Available online: https://www.tensorflow.org (accessed on 15 April 2025).
- Jupyter, P. Jupyter Notebook: An Open Source Platform for Interactive Computing. Version 3.0.14. 2020. Available online: https://jupyter.org (accessed on 15 April 2025).
- Foundation, P.S. Python Language Reference, Version 3.9. 2020. Available online: https://www.python.org (accessed on 15 April 2025).
- Anaconda, I. Anaconda: The Open Data Science Platform. 2021. Available online: https://www.anaconda.com (accessed on 15 April 2025).
- Punuri, S.; Kuanar, S.; Kolhar, M.; Mishra, T.; Alameen, A.; Mohapatra, H.; Mishra, S. Efficient net-XGBoost: An implementation for facial emotion recognition using transfer learning. Mathematics 2023, 11, 776. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Categorical Cross-Entropy: Unraveling Its Potentials in Multi-Class Classification. 2020. Available online: https://medium.com/@vergotten/categorical-cross-entropy-unraveling-its-potentials-in-multi-class-classification-705129594a01 (accessed on 15 April 2025).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Number of Images | Original Dimensions | Resized Dimensions |
|---|---|---|---|
| CK+ | 593 | 640 × 480 | 124 × 124 |
| FER2013 | 35,887 | 48 × 48 | 124 × 124 |
| JAFFE | 213 | 256 × 256 | 124 × 124 |
| Layer (Type) | Output Shape | Parameters |
|---|---|---|
| input_5 (inputlayer) | (none, 124, 124, 3) | 0 |
| block1_conv1 (conv2d) | (none, 124, 124, 64) | 1792 |
| block1_conv2 (conv2d) | (none, 124, 124, 64) | 36,928 |
| block1_pool (maxpooling2d) | (none, 62, 62, 64) | 0 |
| block2_conv1 (conv2d) | (none, 62, 62, 128) | 73,856 |
| block2_conv2 (conv2d) | (none, 62, 62, 128) | 147,584 |
| block2_pool (maxpooling2d) | (none, 31, 31, 128) | 0 |
| block3_conv1 (conv2d) | (none, 31, 31, 256) | 295,168 |
| block3_conv2 (conv2d) | (none, 31, 31, 256) | 590,080 |
| block3_conv3 (conv2d) | (none, 31, 31, 256) | 590,080 |
| block3_conv4 (conv2d) | (none, 31, 31, 256) | 590,080 |
| block3_pool (maxpooling2d) | (none, 15, 15, 256) | 0 |
| block4_conv1 (conv2d) | (none, 15, 15, 512) | 1,180,160 |
| block4_conv2 (conv2d) | (none, 15, 15, 512) | 2,359,808 |
| block4_conv3 (conv2d) | (none, 15, 15, 512) | 2,359,808 |
| block4_conv4 (conv2d) | (none, 15, 15, 512) | 2,359,808 |
| block4_pool (maxpooling2d) | (none, 7, 7, 512) | 0 |
| block5_conv1 (conv2d) | (none, 7, 7, 512) | 2,359,808 |
| block5_conv2 (conv2d) | (none, 7, 7, 512) | 2,359,808 |
| block5_conv3 (conv2d) | (none, 7, 7, 512) | 2,359,808 |
| block5_conv4 (conv2d) | (none, 7, 7, 512) | 2,359,808 |
| block5_pool (maxpooling2d) | (none, 3, 3, 512) | 0 |
| flatten_4 (flatten) | (none, 4,608) | 0 |
| dense_12 (dense) | (none, 256) | 1,179,904 |
| batch_normalization_8 (batchnormalization) | (none, 256) | 1024 |
| dropout_8 (dropout) | (none, 256) | 0 |
| dense_13 (dense) | (none, 512) | 131,584 |
| batch_normalization_9 (batchnormalization) | (none, 512) | 2048 |
| dropout_9 (dropout) | (none, 512) | 0 |
| dense_14 (dense) | (none, 7) | 3591 |
| total params | 21,342,535 | |
| trainable params | 8,396,039 | |
| frozen (non-trainable) params | 12,946,496 | |
| Layer (Type) | Output Shape | Parameters |
|---|---|---|
| input layer | (124, 124, 3) | 0 |
| conv1 (conv2d, 7x7, stride=2) | (62, 62, 64) | 9472 |
| maxpooling (3x3, stride=2) | (31, 31, 64) | 0 |
| conv2_x (residual blocks x3) | (31, 31, 256) | ∼200,000 |
| conv3_x (residual blocks x8, stride=2) | (16, 16, 512) | ∼1,200,000 |
| conv4_x (residual blocks x36, stride=2) | (8, 8, 1024) | ∼7,000,000 |
| conv5_x (residual blocks x3, stride=2) | (4, 4, 2048) | ∼14,000,000 |
| global average pooling | (1, 1, 2048) | 0 |
| flatten layer | (2048) | 0 |
| dense (256 units, relu) | (256) | 524,544 |
| batch normalization | (256) | 1024 |
| dropout (30%) | (256) | 0 |
| dense (512 units, relu) | (512) | 131,584 |
| batch normalization | (512) | 2048 |
| dropout (30%) | (512) | 0 |
| dense (7 units, softmax) | (7) | 3591 |
| total params | 58,370,944 | |
| trainable params | 58,219,520 | |
| frozen (non-trainable) params | 151,424 | |
| Model & Dataset | L () | A () | Validation L () | Validation A () |
|---|---|---|---|---|
| ResNet-152 & CK+ | 0.00 ± 0.02 | 1.00 ± 0.01 | 0.24 ± 0.15 | 0.97 ± 0.03 |
| VGG-19 & CK+ | 0.02 ± 0.01 | 0.99 ± 0.02 | 0.18 ± 0.04 | 0.98 ± 0.01 |
| ResNet-152 & JAFFE | 1.07 ± 0.14 | 0.60 ± 0.06 | 2.94 ± 2.90 | 0.31 ± 0.09 |
| VGG-19 & JAFFE | 0.26 ± 0.17 | 0.91 ± 0.06 | 0.83 ± 0.28 | 0.82 ± 0.05 |
| ResNet-152 & FER2013 | 1.65 ± 0.00 | 0.35 ± 0.00 | 1.67 ± 0.09 | 0.35 ± 0.03 |
| VGG-19 & FER2013 | 1.53 ± 0.00 | 0.40 ± 0.00 | 1.51 ± 0.00 | 0.41 ± 0.00 |
| Model | Dataset | A | P | R | |
|---|---|---|---|---|---|
| DDMTL [60] | CK+ | 0.98 | — | — | — |
| miniXception ensemble [61] | FER2013 | 0.64 | — | — | — |
| Dense_FaceLiveNet [62] | JAFFE | 0.91 | — | — | — |
| Proposed ResNet-152 | CK+ | 0.98 | 0.81 | 0.97 | 0.93 |
| FER2013 | 0.39 | 0.69 | 0.68 | 0.68 | |
| JAFFE | 0.64 | 0.68 | 0.59 | 0.65 | |
| Proposed VGG-19 | CK+ | 0.98 | 0.98 | 0.96 | 0.97 |
| FER2013 | 0.44 | 0.71 | 0.72 | 0.70 | |
| JAFFE | 0.89 | 0.91 | 0.90 | 0.91 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kumar, R.; Corvisieri, G.; Fici, T.F.; Hussain, S.I.; Tegolo, D.; Valenti, C. Transfer Learning for Facial Expression Recognition. Information 2025, 16, 320. https://doi.org/10.3390/info16040320
Kumar R, Corvisieri G, Fici TF, Hussain SI, Tegolo D, Valenti C. Transfer Learning for Facial Expression Recognition. Information. 2025; 16(4):320. https://doi.org/10.3390/info16040320
Chicago/Turabian StyleKumar, Rajesh, Giacomo Corvisieri, Tullio Flavio Fici, Syed Ibrar Hussain, Domenico Tegolo, and Cesare Valenti. 2025. "Transfer Learning for Facial Expression Recognition" Information 16, no. 4: 320. https://doi.org/10.3390/info16040320
APA StyleKumar, R., Corvisieri, G., Fici, T. F., Hussain, S. I., Tegolo, D., & Valenti, C. (2025). Transfer Learning for Facial Expression Recognition. Information, 16(4), 320. https://doi.org/10.3390/info16040320