Analysis of Document Pre-Processing Effects in Text and Opinion Mining

 , , , ,
, , , ,
Abstract
:1. Introduction
2. Theoretical Foundation
2.1. Document Pre-Processing
- Document selection: filters which documents will be used in the text mining task;
- Tokenization: identifies the terms that will be considered in the pre-processing;
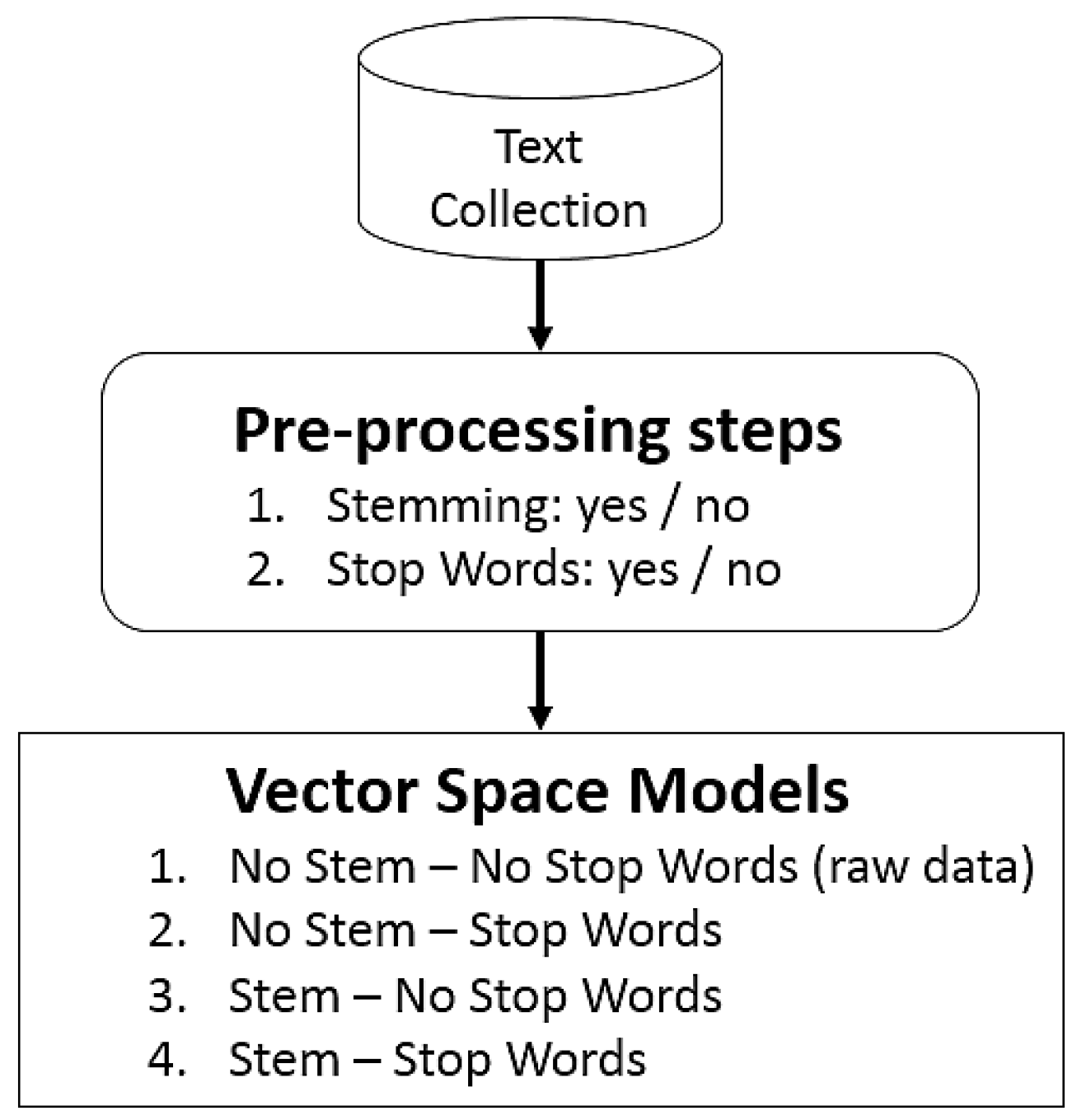
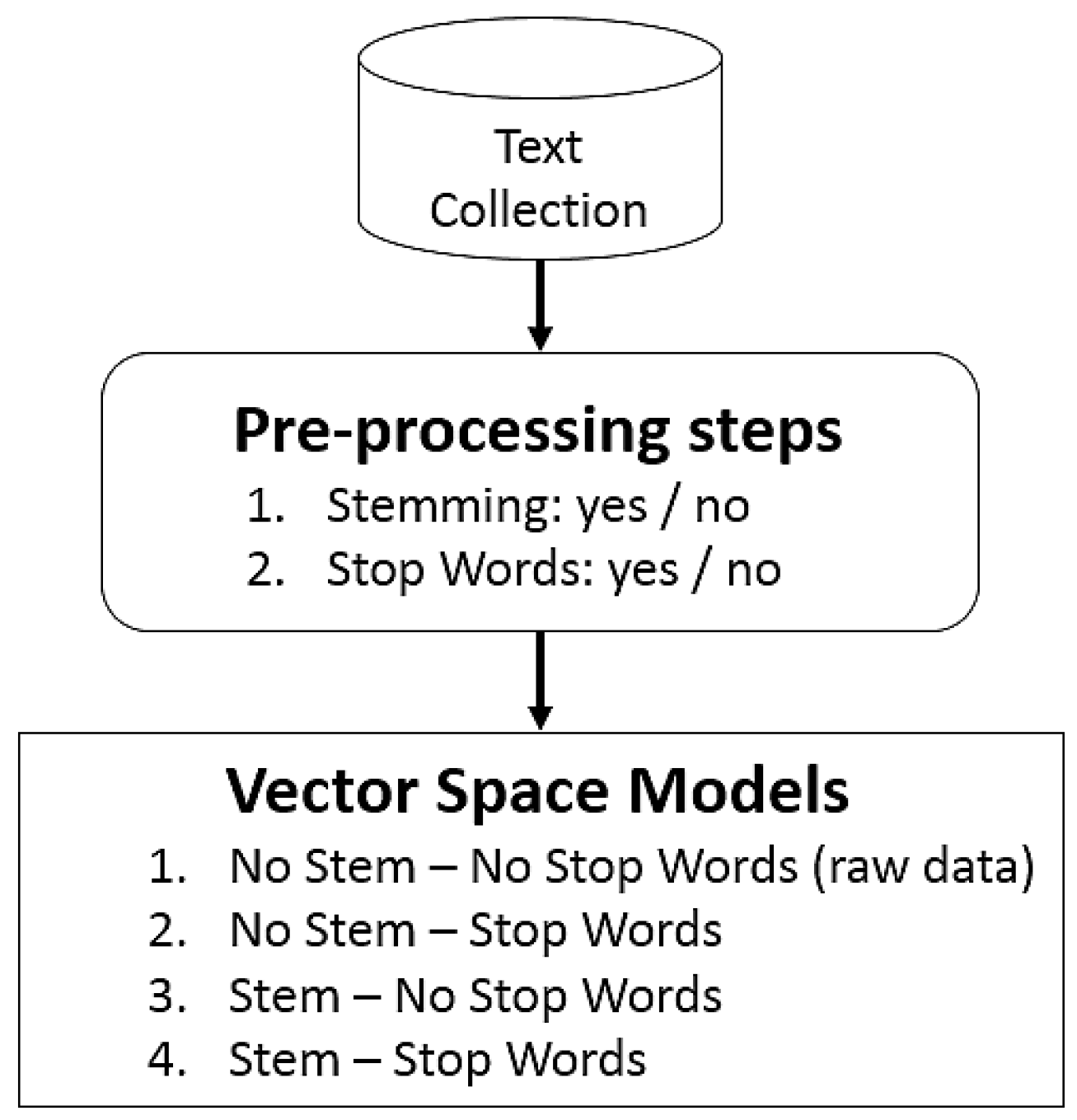
- Stop-word elimination: several terms are not relevant to mining tasks and can be eliminated in this step. Usually, these terms are words that commonly appear in any document (i.e., articles and prepositions);
- Stemming: in this step, each word is reduced to its minimized form, by extracting the root of the word. For example, the root form of “fishing” is “fish”;
- Luhn cut: this step can eliminate terms for which the frequency is below a given threshold;
- Weighting: is employed to minimize or maximize the term contribution on the mining tasks. For example, a well-known technique is TF-IDF (Term Frequency-Inverse Document Frequency).
2.2. Multidimensional Projection
2.3. Opinion Mining
3. Analysis of Document Pre-Processing Effects
- Labeled subset of data: the analyst has to create a labeled subset of data for decision making based on a small sample of the whole dataset;
- Run pre-processing methods: with the labeled subset of data, the analyst can run several pre-processing methods to compute distinct vector space models;
- Mining tasks: each vector space model is processed by a mining task in order to classify each document;
- Accuracy computation: after executing a mining task, the analyst has to analyze which method or combination of them produces the best accuracy value. For that, quality measures (e.g., correct classification rate) are computed allowing the comparison of the resulting vector space models;
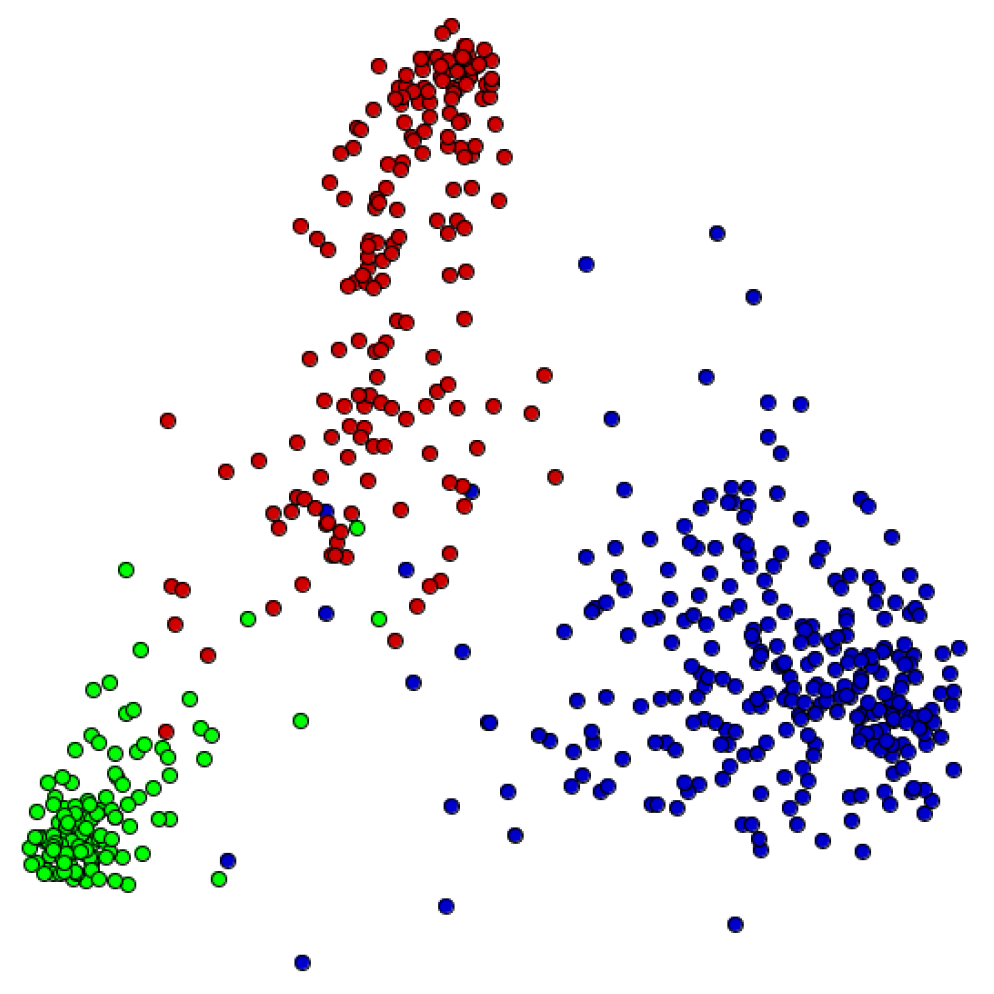
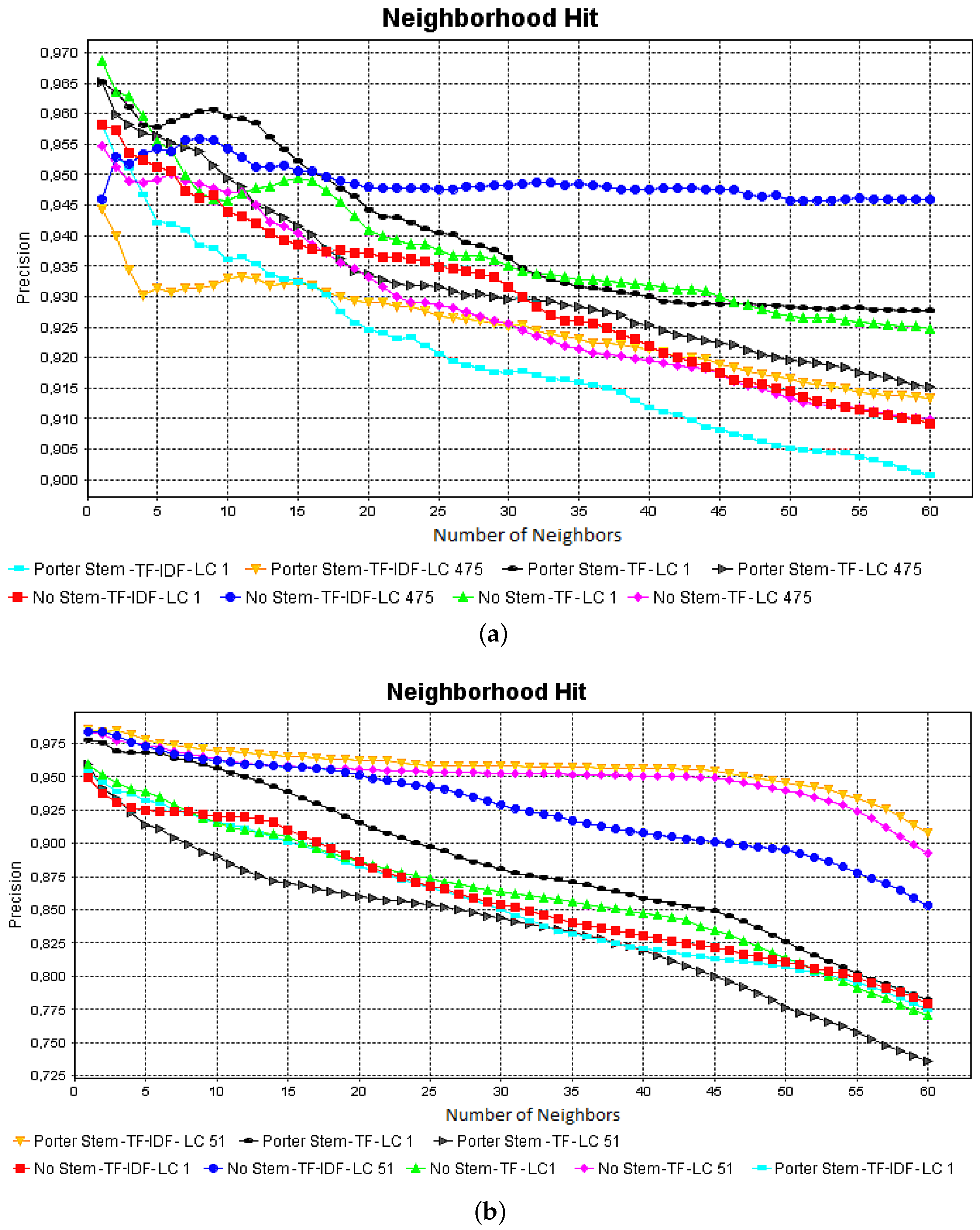
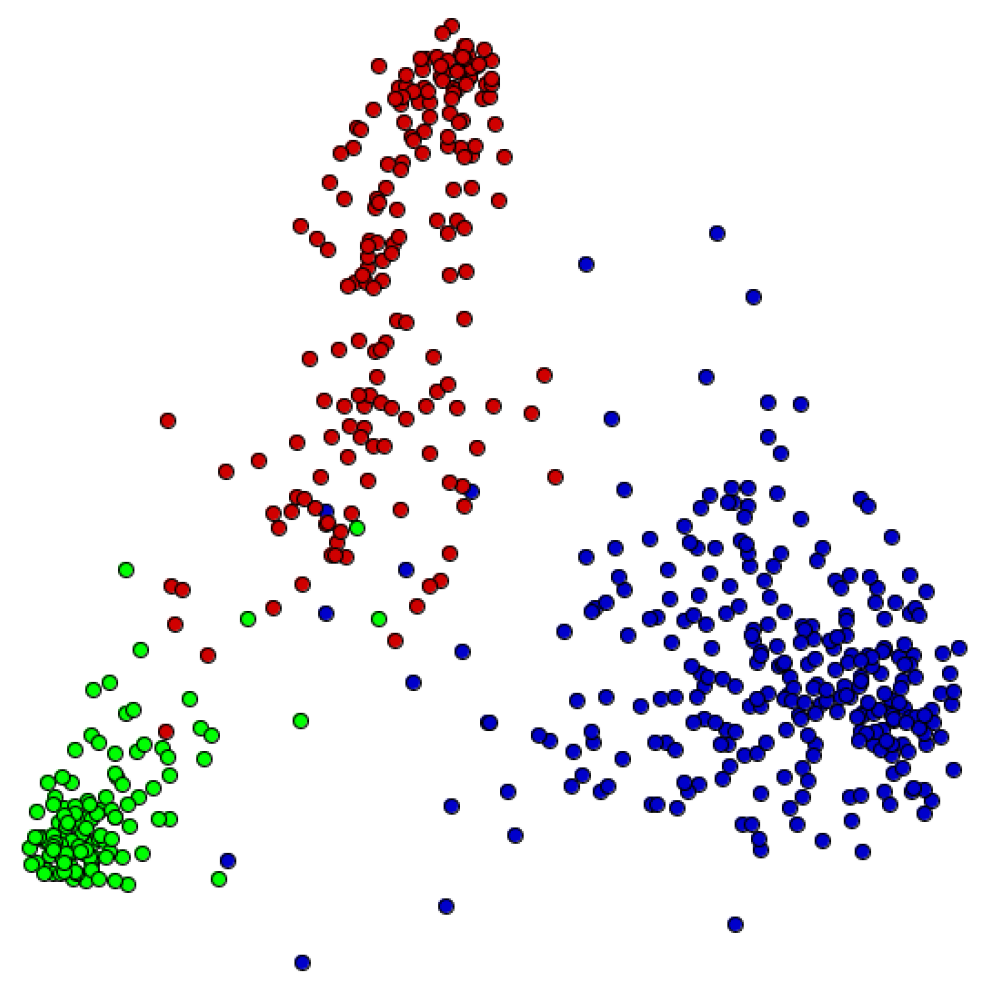
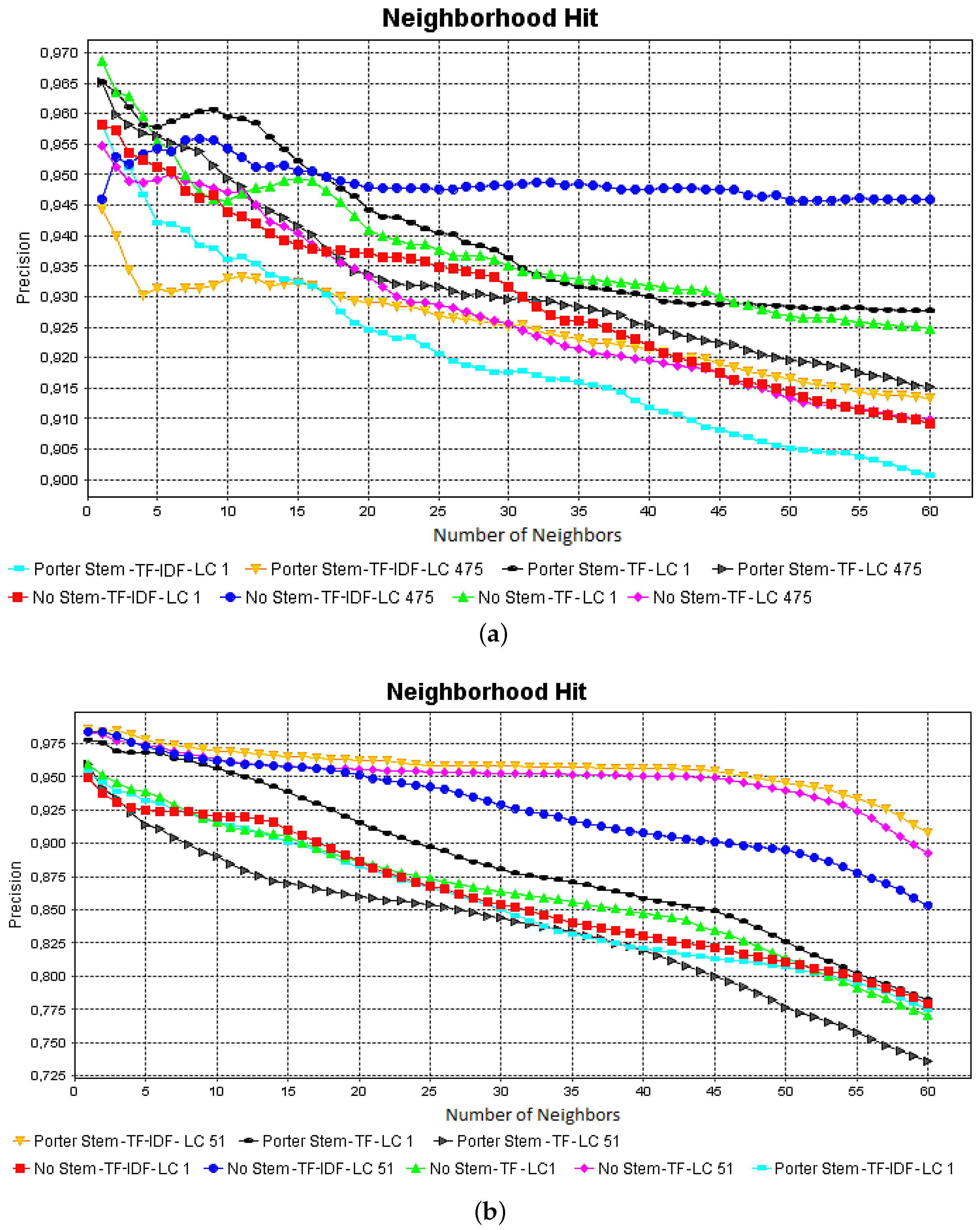
- Comparison: based on the accuracy computation, the analyst makes a decision about the best pre-processing methods that can be employed for a dataset. In addition, visualization techniques may be used to properly understand the impact of pre-processing methods in document similarities and group formation.
4. Experiments
4.1. Text Mining
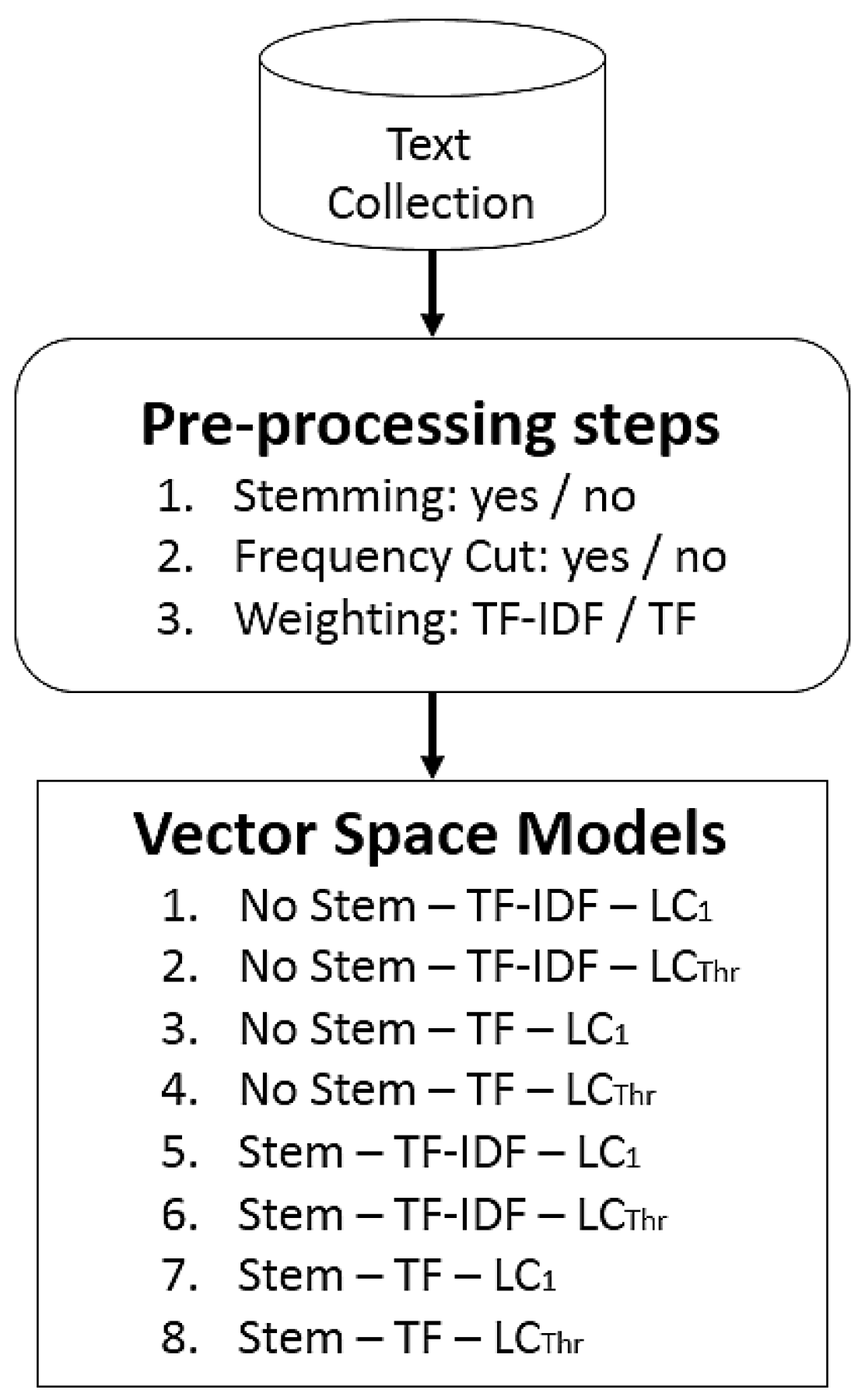
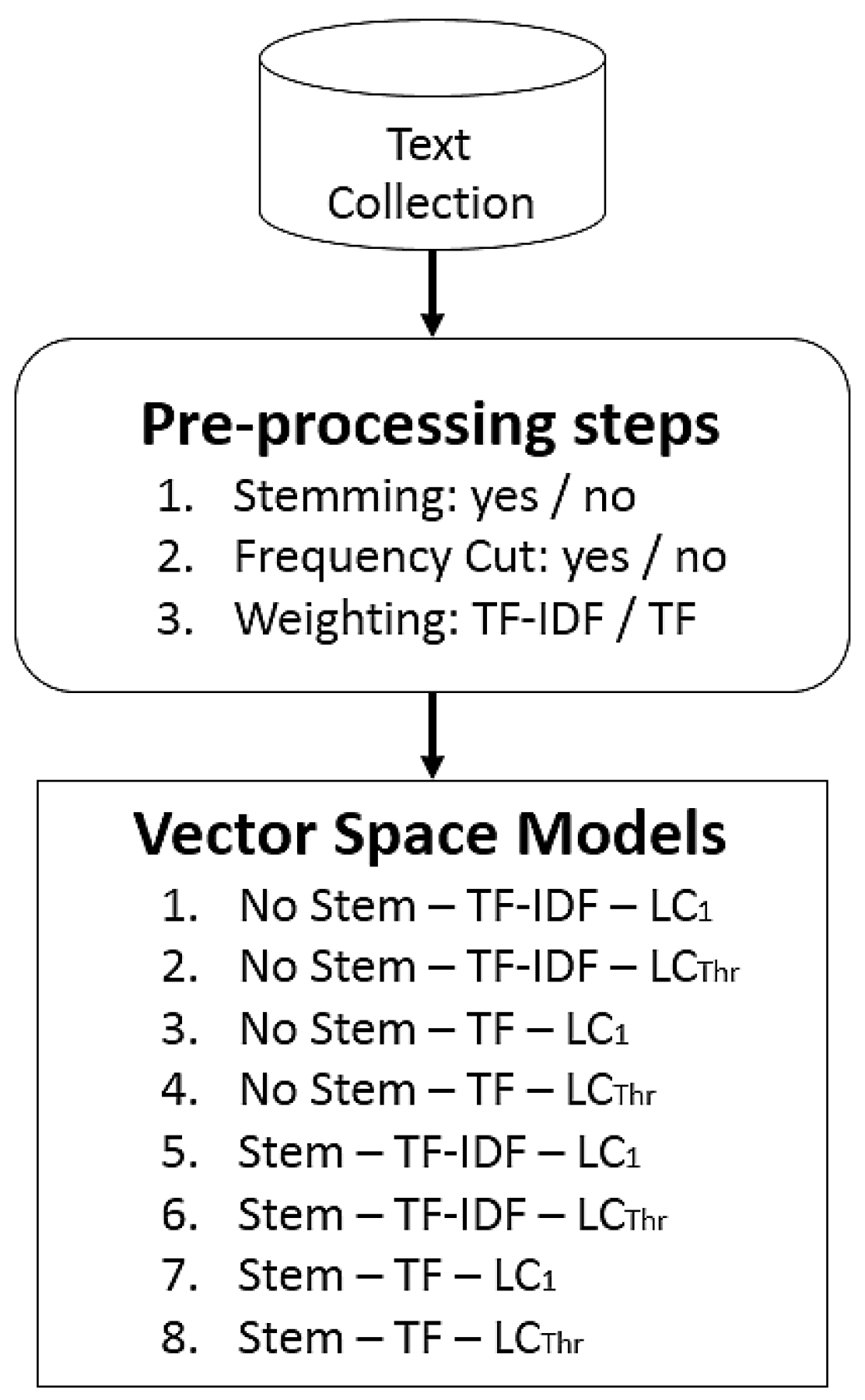
- Stemming: in this step, similar words can be grouped by obtaining the root of each work. In this paper, we used Porter’s stemming [9];
- Frequency cut: in this step, some terms can be discarded based on their frequency. For that, a low-frequency cut is chosen (), and all terms below this threshold are discarded. If no frequency cut is set (), all terms are used to compute the Vector Space Model (VSM). In this paper, we used an automatic approach based on Otsu’s threshold selection method [24], which is an approach proposed to estimate a good low-frequency cut;
- CBR-ILP-IR: 574 papers from three areas of artificial intelligence: Case-Based Reasoning (CBR), Inductive Logic Programming (ILP), Information Retrieval (IR);
- NEWS-8: 495 news from Reuters, AP, BBC and CNN, classified into eight classes;
4.2. Opinion Mining
4.3. Complete Application for Opinion Mining
5. Conclusions and Future Works
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Hu, Y.; Milios, E.E.; Blustein, J. Enhancing Semi-supervised Document Clustering with Feature Supervision. In Proceedings of the 27th Annual ACM Symposium on Applied Computing, Trento, Italy, 26–30 March 2012; ACM: New York, NY, USA, 2012; pp. 929–936. [Google Scholar]
- Nogueira, B.M.; Moura, M.F.; Conrado, M.S.; Rossi, R.G.; Marcacini, R.M.; Rezende, S.O. Winning Some of the Document Preprocessing Challenges in a Text Mining Process. In Proceedings of the Anais do IV Workshop em Algoritmos e Aplicações de Mineração de Dados—WAAMD, XXIII Simpósio Brasileiro de Banco de Dados—SBBD, Campinas, Sao Paulo, Brazil, 26–30 October 2008; pp. 10–18. [Google Scholar]
- Chandrasekar, P.; Qian, K. The Impact of Data Preprocessing on the Performance of a Naive Bayes Classifier; IEEE Computer Society: Los Alamitos, CA, USA, 2016; Volume 2, pp. 618–619. [Google Scholar]
- Tugizimana, F.; Steenkamp, P.; Piater, L.; Dubery, I. Conversation on Data Mining Strategies in LC-MS Untargeted Metabolomics: Pre-Processing and Pre-Treatment Steps. Metabolites 2016, 6, 40. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.L.; Yi, J.-S. Predicting Project’s Uncertainty Risk in the Bidding Process by Integrating Unstructured Text Data and Structured Numerical Data Using Text Mining. Appl. Sci. 2017, 7, 1141. [Google Scholar] [CrossRef]
- Roh, T.; Jeong, Y.; Yoon, B. Developing a Methodology of Structuring and Layering Technological Information in Patent Documents through Natural Language Processing. Sustainability 2017, 9, 2117. [Google Scholar] [CrossRef]
- Lee, B.; Park, J.; Kwon, L.; Moon, Y.; Shin, Y.; Kim, G.; Kim, H. About relationship between business text patterns and financial performance in corporate data. J. Open Innov. Technol. Mark. Complex. 2018, 4, 3. [Google Scholar] [CrossRef]
- Salton, G.; Wong, A.; Yang, C.S. A vector space model for automatic indexing. Commun. ACM 1975, 18, 613–620. [Google Scholar] [CrossRef]
- Porter, M.F. An Algorithm for Suffix Stripping; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1997; pp. 313–316. [Google Scholar]
- Salton, G.; Yang, C.S. On the specification of term values in automatic indexing. J. Doc. 1973, 29, 351–372. [Google Scholar] [CrossRef]
- Luhn, H.P. The automatic creation of literature abstracts. IBM J. Res. Dev. 1958, 2, 159–165. [Google Scholar] [CrossRef]
- Tejada, E.; Minghim, R.; Nonato, L.G. On improved projection techniques to support visual exploration of multidimensional datasets. Inf. Vis. 2003, 2, 218–231. [Google Scholar] [CrossRef]
- Paulovich, F.V.; Nonato, L.G.; Minghim, R.; Levkowitz, H. Least Square Projection: A fast high precision multidimensional projection technique and its application to document mapping. IEEE Trans. Vis. Comput. Graph. 2008, 14, 564–575. [Google Scholar] [CrossRef] [PubMed]
- Eler, D.M.; Paulovich, F.V.; de Oliveira, M.C.F.; Minghim, R. Coordinated and Multiple Views for Visualizing Text Collections. In Proceedings of the 12th International Conference Information Visualisation, London, UK, 9–11 July 2008; IEEE Computer Society: Washington, DC, USA, 2008; pp. 246–251. [Google Scholar]
- Eler, D.M.; Pola, I.R.V.; Garcia, R.E.; Teixeira, J.B.M. Visualizing the Document Pre-processing Effects in Text Mining Process. In Advances in Intelligent Systems and Computing, Proceedings of the 14th International Conference on Information Technology: New Generations (ITNG 2017), Las Vegas, NV, USA, 10–12 April 2017; Springer International Publishing: Cham, Switzerland, 2017; pp. 485–491. [Google Scholar]
- Tan, P.N.; Steinbach, M.; Kumar, V. Introduction to Data Mining, 1st ed.; Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 2005. [Google Scholar]
- Liu, B. Sentiment Analysis and Opinion Mining; Morgan and Claypool Publishers: San Rafael, CA, USA, 2012. [Google Scholar]
- Eler, D.M.; Almeida, A.; Teixeira, J.; Pola, I.R.V.; Pola, F.P.B.; Olivete, C. Feature Space Unidimensional Projections for Scatterplots. Colloq. Exactarum 2017, 9, 58–68. [Google Scholar] [CrossRef]
- Eler, D.; Nakazaki, M.; Paulovich, F.; Santos, D.; Andery, G.; Oliveira, M.; Batista, J.E.S.; Minghim, R. Visual analysis of image collections. Vis. Comput. 2009, 25, 923–937. [Google Scholar] [CrossRef]
- Paulovich, F.V.; Eler, D.M.; Poco, J.; Botha, C.; Minghim, R.; Nonato, L.G. Piecewise Laplacian-based Projection for Interactive Data Exploration and Organization. Comput. Graph. Forum 2011, 30, 1091–1100. [Google Scholar] [CrossRef]
- Bodo, L.; de Oliveira, H.C.; Breve, F.A.; Eler, D.M. Performance Indicators Analysis in Software Processes Using Semi-supervised Learning with Information Visualization. In Proceedings of the 13th International Conference on Information Technology, New Generations (ITNG 2016), Las Vegas, NV, USA, 10–13 April 2016; Springer International Publishing: Cham, Switzerland, 2016; pp. 555–568. [Google Scholar]
- Esuli, A.; Sebastiani, F. SENTIWORDNET: A Publicly Available Lexical Resource for Opinion Mining. In Proceedings of the 5th Conference on Language Resources and Evaluation, Genoa, Italy, 22–28 May 2006; pp. 417–422. [Google Scholar]
- Cambria, E.; Speer, R.; Havasi, C.; Hussain, A. SenticNet: A Publicly Available Semantic Resource for Opinion Mining. In AAAI Fall Symposium: Commonsense Knowledge; AAAI Technical Report; AAAI Press: Menlo Park, CA, USA, 2010; Volume FS-10-02. [Google Scholar]
- Eler, D.M.; Garcia, R.E. Using Otsu’s Threshold Selection Method for Eliminating Terms in Vector Space Model Computation. In Proceedings of the International Conference on Information Visualization, London, UK, 16–18 July 2013; pp. 220–226. [Google Scholar]
- Salton, G.; Buckley, C. Term-weighting approaches in automatic text retrieval. Inf. Process. Manag. 1988, 24, 513–523. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Vector Space Model | Silhouette | k-NN | Naive Bayes |
|---|---|---|---|
| No Stem-TF-IDF-LC1 | 0.48 | 48% | 97% |
| No Stem-TF-IDF-LC475 | 0.67 | 93% | 98% |
| No Stem-TF-LC1 | 0.57 | 48% | 97% |
| No Stem-TF-LC475 | 0.58 | 93% | 97% |
| Porter Stem-TF-IDF-LC1 | 0.43 | 57% | 97% |
| Porter Stem-TF-IDF-LC475 | 0.56 | 91% | 95% |
| Porter Stem-TF-LC1 | 0.58 | 57% | 97% |
| Porter Stem-TF-LC475 | 0.58 | 91% | 95% |
| Vector Space Model | Silhouette | k-NN | Naive Bayes |
|---|---|---|---|
| No Stem-TF-IDF-LC1 | 0.48 | 88% | 97% |
| No Stem-TF-IDF-LC51 | 0.65 | 97% | 98% |
| No Stem-TF-LC1 | 0.53 | 88% | 97% |
| No Stem-TF-LC51 | 0.75 | 96% | 98% |
| Porter Stem-TF-IDF-LC1 | 0.48 | 90% | 97% |
| Porter Stem-TF-IDF-LC51 | 0.77 | 97% | 98% |
| Porter Stem-TF-LC1 | 0.56 | 90% | 97% |
| Porter Stem-TF-LC51 | 0.53 | 97% | 98% |
| Vector Space Model | SentiWordNet | SenticNet | Naive Bayes |
|---|---|---|---|
| No Stem-No Stop Words | 72.04% | 62.90% | 55.91% |
| No Stem-Stop Words | 73.12% | 63.44% | 62.90% |
| Stem-No Stop Words | 77.42% | 62.37% | 62.37% |
| Stem-Stop Words | 72.58% | 62.37% | 65.05% |
| Vector Space Model | SentiWordNet | SenticNet | Naive Bayes |
|---|---|---|---|
| No Stem-No Stop Words | 69.09% | 58.43% | 95.54% |
| No Stem-Stop Words | 67.54% | 56.98% | 97.00% |
| Stem-No Stop Words | 66.76% | 63.18% | 95.64% |
| Stem-Stop Words | 66.86% | 67.15% | 97.00% |
| Vector Space Model | SentiWordNet | SenticNet | Naive Bayes |
|---|---|---|---|
| No Stem-No Stop Words | 75.74% | 57.66% | 57.04% |
| No Stem-Stop Words | 77.81% | 56.55% | 60.80% |
| Stem-No Stop Words | 67.87% | 66.72% | 58.26% |
| Stem-Stop Words | 64.94% | 70.30% | 63.33% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Eler, D.M.; Grosa, D.; Pola, I.; Garcia, R.; Correia, R.; Teixeira, J. Analysis of Document Pre-Processing Effects in Text and Opinion Mining. Information 2018, 9, 100. https://doi.org/10.3390/info9040100
Eler DM, Grosa D, Pola I, Garcia R, Correia R, Teixeira J. Analysis of Document Pre-Processing Effects in Text and Opinion Mining. Information. 2018; 9(4):100. https://doi.org/10.3390/info9040100
Chicago/Turabian StyleEler, Danilo Medeiros, Denilson Grosa, Ives Pola, Rogério Garcia, Ronaldo Correia, and Jaqueline Teixeira. 2018. "Analysis of Document Pre-Processing Effects in Text and Opinion Mining" Information 9, no. 4: 100. https://doi.org/10.3390/info9040100
APA StyleEler, D. M., Grosa, D., Pola, I., Garcia, R., Correia, R., & Teixeira, J. (2018). Analysis of Document Pre-Processing Effects in Text and Opinion Mining. Information, 9(4), 100. https://doi.org/10.3390/info9040100