Measuring Domain-Specific Knowledge: From Bach to Fibonacci


Abstract
:1. Introduction
1.1. Theoretical Models of Domain-Specific Knowledge
1.2. Construction of a New Gkn Test
1.3. Validation Strategy
- The data collected, reflecting Gkn, are arranged in a hierarchical structure with one factor at the top and three narrower factors below, which each can be divided into smaller knowledge facets.
- Criterion-related validity evidence will be provided based on a known-groups design. Participants with higher Gf scores will show overall significantly better test results than the unselected Gf participants (known-groups comparison), based on Cattell’s investment hypothesis. The greatest difference is expected in the Science domain due to the complex and abstract nature of Science knowledge. The reliability of the test scores will be estimated.
2. Method
2.1. Participants
2.2. Procedure
2.3. Measures
2.4. Statistical Analyses
3. Results
3.1. Structural Validity
3.1.1. Descriptive Statistics and CFAs of Knowledge Categories
3.1.2. CFAs of Knowledge Domains
3.1.3. CFAs of Gkn Models
3.1.4. Factor Loadings on Knowledge Domains and the Gkn-Factor
3.1.5. Measurement Invariance Analyses between High Gf and Unselected Gf Samples
3.2. Criterion-Related Validity
Mean Differences of Test Performance
4. Discussion
4.1. Hierarchical Structure of Gkn
4.2. Criterion-Related Validity and Measurement Invariance
4.3. Limitations and Further Research
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ackerman, Phillip L. 1996. A Theory of Adult Intellectual Development: Process, Personality Interests, and Knowledge. Intelligence 22: 227–57. [Google Scholar] [CrossRef]
- Ackerman, Phillip L. 2000. Domain-Specific Knowledge as the “Dark Matter” of Adult Intelligence: Gf/Gc, Personality and Interest Correlates. The Journals of Gerontology: Series B 55B: 69–84. [Google Scholar] [CrossRef] [Green Version]
- Ackerman, Phillip L., and Eric L. Rolfhus. 1999. The Locus of Adult Intelligence: Knowledge, Abilities, and Nonability Traits. Psychology and Aging 14: 314–30. [Google Scholar] [CrossRef]
- Akaike, Hirotugu. 1974. A new look at the statistical model identification. IEEE Transactions on Automatic Control 19: 716–23. [Google Scholar] [CrossRef]
- Alexander, Patricia A., and Judith E. Judy. 1988. The Interaction of Domain-Specific and Strategic Knowledge in Academic Performance. Review of Educational Research 58: 375–404. [Google Scholar] [CrossRef]
- Beier, Margaret E., and Phillip L. Ackerman. 2001. Current-events knowledge in adults: An investigation of age, intelligence, and nonability determinants. Psychology and Aging 16: 615–28. [Google Scholar] [CrossRef]
- Beier, Margaret. E., and Phillip L. Ackerman. 2003. Determinants of health knowledge: An investigation of age, gender, abilities, personality, and interests. Journal of Personality and Social Psychology 84: 439–48. [Google Scholar] [CrossRef]
- Bentler, Peter M. 1990. Comparative fit indexes in structural models. Psychological Bulletin 107: 238–46. [Google Scholar] [CrossRef]
- Bentler, Peter M. 1995. EQS Structural Equations Program Manual. Encino: Multivariate Software. [Google Scholar]
- Bessou, Annick, Jeanne Tyrrell, and Monique Yziquel. 2004. Parcours scolaire et professionnel de 28 adultes dits surdoués [Educational and career pathways of 28 gifted adults]. Neuropsychiatrie de l’Enfance et de l’Adolescence 52: 154–59. [Google Scholar] [CrossRef]
- Browne, Michael W., and Robert Cudeck. 1993. Alternative ways of assessing model fit. In Testing Structural Equation Models. Edited by Kenneth A. Bollen and J. Scott Long. Newbury Park: Sage, pp. 136–62. [Google Scholar]
- Cattell, Raymond B. 1943. The measurement of adult intelligence. Psychological Bulletin 40: 153–93. [Google Scholar] [CrossRef]
- Cattell, Raymond B. 1987. Intelligence: Its Structure, Growth and Action. New York: North-Holland. [Google Scholar]
- Chen, Fang Fang. 2007. Sensitivity of goodness of fit indexes to lack of measurement invariance. Structural Equation Modeling 14: 464–504. [Google Scholar] [CrossRef]
- Corley, Janie, Alan J. Gow, John M. Starr, and Ian J. Deary. 2012. Smoking, childhood IQ, and cognitive function in old age. Journal of Psychosomatic Research 73: 132–38. [Google Scholar] [CrossRef] [Green Version]
- Cronbach, Lee J., and Paul E. Meehl. 1955. Construct validity in psychological tests. Psychological Bulletin 52: 281–302. [Google Scholar] [CrossRef] [Green Version]
- Dijkstra, Pieternel, Dick Barelds, Sieuwke Ronner, and Arnolda Nauta. 2011. Humor Styles and their Relationship to Well-Being among the Gifted. Gifted and Talented International 26: 89–98. [Google Scholar] [CrossRef]
- Egeland, J. 2019. Emotion Perception in Members of Norwegian Mensa. Frontiers in Psychology 10: 27. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fogel, Max L. 1968. Mensa Society. American Psychologist 23: 457. [Google Scholar] [CrossRef]
- Gabel, D. 1999. Improving Teaching and Learning through Chemistry Education Research: A Look to the Future. Journal of Chemical Education 76: 548. [Google Scholar] [CrossRef]
- Ghisletta, Paolo, John J. McArdle, and Ulman Lindenberger. 2006. Longitudinal cognition-survival relations in old and very old age: 13-year data from the berlin aging study. European Psychologist 11: 204–23. [Google Scholar] [CrossRef]
- Gustafsson, Jan-Erik, and Gudrun Balke. 1993. General and Specific Abilities as Predictors of School Achievement. Multivariate Behavioral Research 28: 407–34. [Google Scholar] [CrossRef]
- Hancock, Gregory R. 2001. Effect size, power, and sample size determination for structured means modeling and mimic approaches to between-groups hypothesis testing of means on a single latent construct. Psychometrika 66: 373–88. [Google Scholar] [CrossRef]
- Hattie, John, and Ray W. Cooksey. 1984. Procedures for Assessing the Validities of Tests Using the “Known-Groups” Method. Applied Psychological Measurement 8: 295–305. [Google Scholar] [CrossRef]
- Hooper, Daire, Joseph Coughlan, and Michael R. Mullen. 2008. Structural Equation Modeling: Guidelines for Determining Model Fit. Electronic Journal of Business Research 6: 53–60. [Google Scholar] [CrossRef]
- Hu, Litze T., and Peter M. Bentler. 1999. Cutoff Criteria for Fit Indexes in Covariance Structure Analysis: Conventional Criteria versus New Alternatives. Structural Equation Modeling 6: 1–55. [Google Scholar] [CrossRef]
- Iqbal, Komal, Sana R. Chaudhry, Hifza N. Lodhi, Shagufta Khaliq, Muneeza Taseer, and Muniza Saeed. 2021. Relationship between IQ and academic performance of medical students. The Professional Medical Journal 28: 242–46. [Google Scholar] [CrossRef]
- Kuncel, Nathan R., Deniz S. Ones, and Paul R. Sackett. 2010. Individual differences as predictors of work, educational, and broad life outcomes. Personality and Individual Differences 49: 331–36. [Google Scholar] [CrossRef]
- Lawes, Mario, Martin Schultze, and Michael Eid. 2020. Making the Most of Your Research Budget: Efficiency of a Three-Method Measurement Design With Planned Missing Data. Assessment 27: 903–20. [Google Scholar] [CrossRef]
- Little, Roderick J., and Donald B. Rubin. 2019. Statistical Analysis with Missing Data, 3rd ed. Chichester: John Wiley & Sons, Ltd. [Google Scholar]
- McCrae, Robert R., John E. Kurtz, Shinji Yamagata, and A. Terracciano. 2011. Internal Consistency, Retest Reliability, and Their Implications for Personality Scale Validity. Personality and Social Psychology Review 15: 28–50. [Google Scholar] [CrossRef] [Green Version]
- Millar, Robin. 1991. Why is science so hard to learn? Journal of Computer Assisted Learning 7: 66–74. [Google Scholar] [CrossRef]
- R Core Team. 2016–2019. R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing. Available online: www.r-project.org/index.html (accessed on 17 August 2021).
- Revelle, William, David M. Condon, Joshua Wilt, Jason A. French, Ashley Brown, and Lorien G. Elleman. 2017. Web and Phone Based Data Collection Using Planned Missing Designs. Edited by Nigel G. Fielding, Raymond M. Lee and Grant Blank. Sage Handbook of Online Research Methods. Thousand Oaks: Sage, pp. 578–95. [Google Scholar]
- Rolfhus, Eric L. 1998. Assessing Individual Differences in Knowledge: Knowledge Structures and Traits. Unpublished doctoral dissertation, University of Minnesota, Minneapolis, MN, USA. [Google Scholar]
- Rolfhus, Eric L., and Phillip L. Ackerman. 1996. Self-report knowledge: At the crossroads of ability, interest, and personality. Journal of Educational Psychology 88: 174–88. [Google Scholar] [CrossRef]
- Rolfhus, Eric L., and Phillip L. Ackerman. 1999. Assessing Individual Differences in Knowledge: Knowledge, Intelligence, and Related Traits. Journal of Educational Psychology 91: 511–26. [Google Scholar] [CrossRef]
- Rosseel, Yves. 2012. lavaan: An R Package for Structural Equation Modeling. Journal of Statistical Software 48: 1–36. [Google Scholar] [CrossRef] [Green Version]
- RStudio Team. 2016–2019. RStudio: Integrated Development for R. Boston: RStudio. Available online: www.rstudio.com (accessed on 17 August 2021).
- Rusche, Marianna M., and Matthias Ziegler. 2022. The interplay between domain-specific knowledge and selected investment traits across the life span. Intelligence 92: 101647. [Google Scholar] [CrossRef]
- Satorra, Albert, and Peter M. Bentler. 2001. A scaled difference chi-square test statistic for moment structure analysis. Psychometrika 66: 507–14. [Google Scholar] [CrossRef] [Green Version]
- Scheffer, Judi. 2002. Dealing with missing data. Research Letters in the Information and Mathematical Sciences 3: 153–60. [Google Scholar]
- Schipolowski, Stefan, Oliver Wilhelm, and Ulrich Schroeders. 2020. BEFKI 11–12: Berliner Test zur Erfassung Fluider und Kristalliner Intelligenz für Die 11. bis 12. Jahrgangsstufe. Göttingen: Hogrefe. [Google Scholar]
- Schneider, W. Joel, and Kevin S. McGrew. 2018. The Cattell–Horn–Carroll theory of cognitive abilities. In Contemporary Intellectual Assessment: Theories, Tests, and Issues. Edited by Dawn Flanagan and Erin McDonough. New York: The Guilford Press, pp. 73–163. [Google Scholar]
- Schroeders, Ulrich, Luc Watrin, and Oliver Wilhelm. 2021. Age-related nuances in knowledge assessment. Intelligence 85: 101526. [Google Scholar] [CrossRef]
- Steger, Diana, Ulrich Schroeders, and Oliver Wilhelm. 2019. On the dimensionality of crystallized intelligence: A smartphone-based assessment. Intelligence 72: 76–85. [Google Scholar] [CrossRef]
- Steger, Diana, Ulrich Schroeders, and Timo Gnambs. 2020. A meta-analysis of test scores in proctored and unproctored ability assessments. European Journal of Psychological Assessment 36: 174–84. [Google Scholar] [CrossRef] [Green Version]
- Steger, Diana, Ulrich Schroeders, and Oliver Wilhelm. 2021. Caught in the act: Predicting cheating in unproctored knowledge assessment. Assessment 28: 1004–17. [Google Scholar] [CrossRef]
- Steiger, James H., and John C. Lind. 1980. Statistically-based tests for the number of common factors. Paper presented at Meeting of the Psychometric Society, Iowa City, IA, USA. [Google Scholar]
- Storek, Josephine, and Adrian Furnham. 2012. Gender and gender role differences in Domain-Masculine Intelligence and beliefs about intelligence: A study with Mensa UK members. Personality and Individual Differences 53: 890–95. [Google Scholar] [CrossRef]
- Trapp, Stefanie, Sigrid Blömeke, and Matthias Ziegler. 2019. The openness-fluid-crystallized-intelligence (OFCI) model and the environmental enrichment hypothesis. Intelligence 73: 30–40. [Google Scholar] [CrossRef]
- van Buuren, Stef, and Karin Groothuis-Oudshoorn. 2011. Mice: Multivariate Imputation by Chained Equations in R. Journal of Statistical Software 45: 1–67. [Google Scholar] [CrossRef] [Green Version]
- von Stumm, Sophie. 2013. Investment Traits and Intelligence in Adulthood: Assessment and Associations. Journal of Individual Differences 34: 82–89. [Google Scholar] [CrossRef]
- Wilhelm, Oliver, Ulrich Schroeders, and Stefan Schipolowski. 2014. BEFKI 8-10: Berliner Test zur Erfassung fluider und kristalliner Intelligenz für die 8. bis 10. Jahrgangsstufe [BEFKI 8-10: Berln Test for the Assessment of Fluid and Crystallized Intelligence for 8th till 10th grade]; Manual. Göttingen: Hogrefe. [Google Scholar]
- Ziegler, Matthias, and Dirk Hagemann. 2015. Testing the unidimensionality of items: Pitfalls and loopholes. European Journal of Psychological Assessment 31: 231–37. [Google Scholar] [CrossRef]
- Ziegler, Matthias, Maximilian Knogler, and Markus Bühner. 2009. Conscientiousness, achievement striving, and intelligence as performance predictors in a sample of German psychology students: Always a linear relationship? Learning and Individual Differences 19: 288–92. [Google Scholar] [CrossRef]
- Ziegler, Matthias, Erik Danay, Moritz Heene, Jens Asendorpf, and Markus Bühner. 2012. Openness, fluid intelligence, and crystallized intelligence: Toward an integrative model. Journal of Research in Personality 46: 173–83. [Google Scholar] [CrossRef]
- Ziegler, Matthias, Anja Cengia, Patrick Mussel, and Denis Gerstorf. 2015. Openness as a Buffer Against Cognitive Decline: The Openness-Fluid-Crystallized-Intelligence (OFCI) Model Applied to Late Adulthood. Psychology and Aging 30: 573–88. [Google Scholar] [CrossRef]
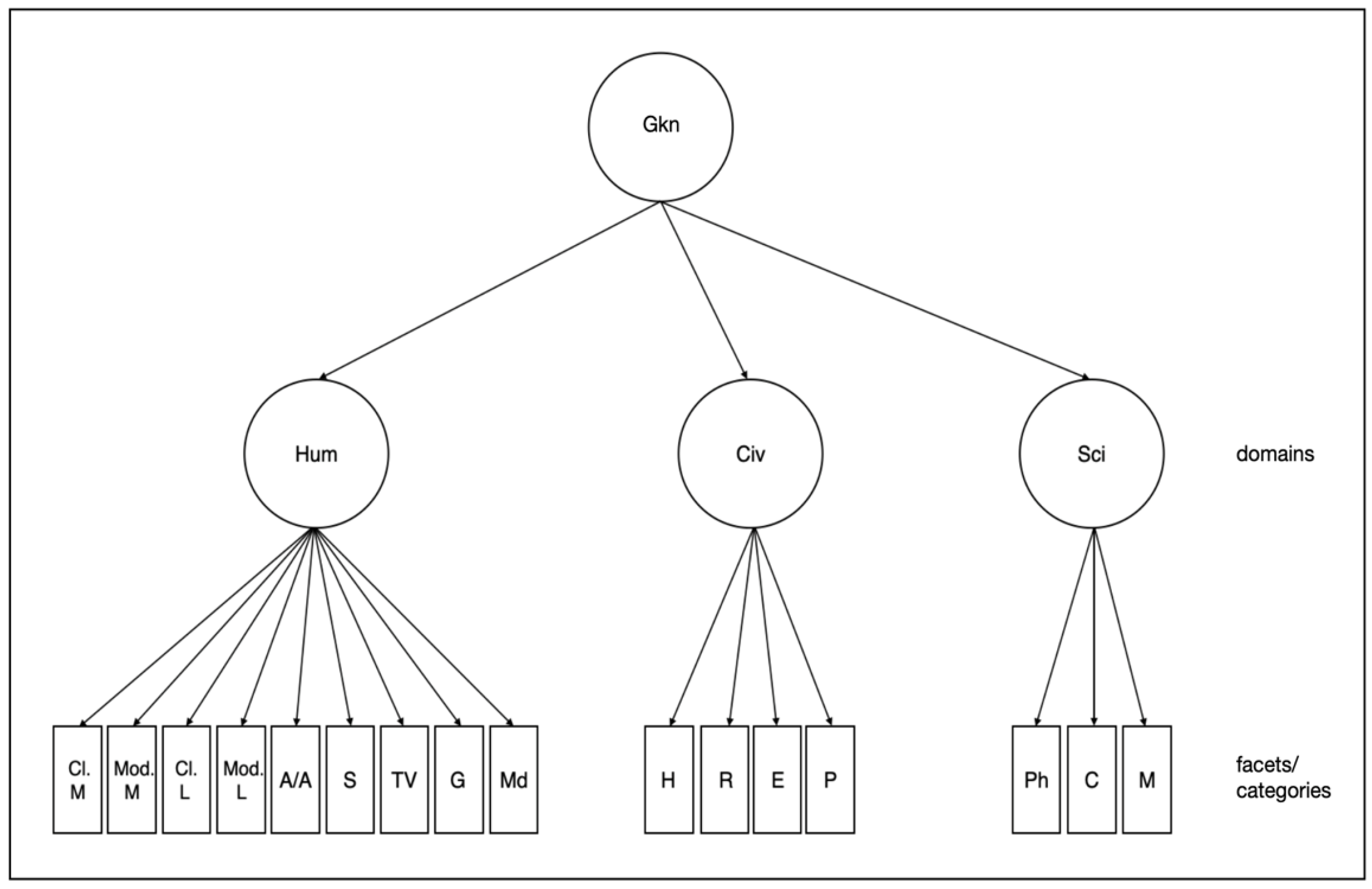

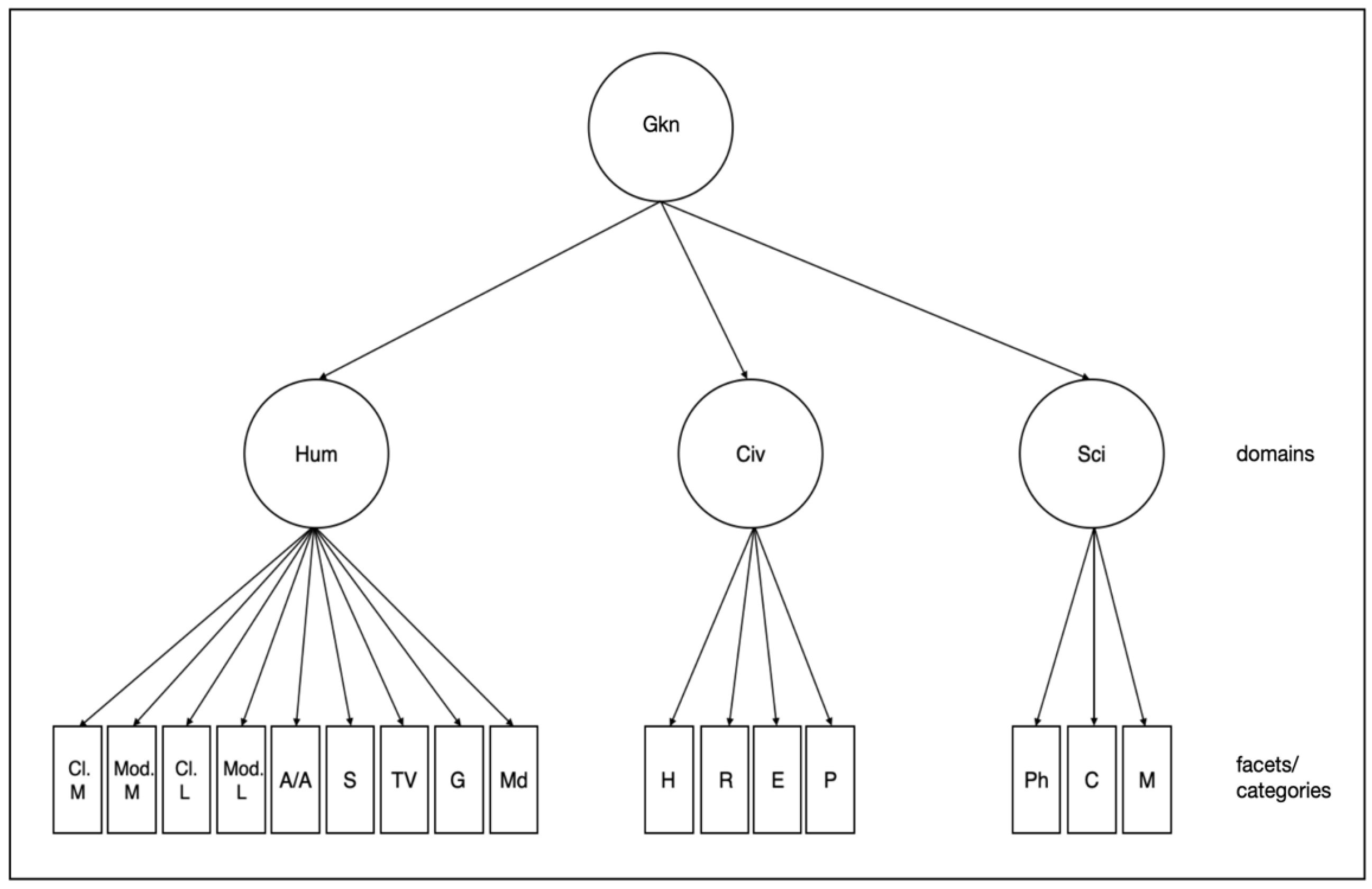{kind=link}
| Rolfhus and Ackerman | DoKnow Test | von Stumm | ||
|---|---|---|---|---|
| Humanities | -American Literature -World Literature -Music -Art -Geography | -Cl. + Mod. Literature -Cl. + Mod. Music -Art/Architecture -Geography -Sports -Television -Popular -Medicine | -Fashion -Music -Art -Sports -Film -Medicine -Health | Popular Knowledge |
| Civics | -American Government -American History -Law -Western Civilization | -Politics -Economics -History -Religion | -Politics -Economics -History -Geography | Academic Knowledge |
| Science | -Economics -Business/Management -Statistics -Technology -Psychology -Biology -Physics -Chemistry | -Mathematics -Technology -Biology -Physics -Chemistry | -Science -Technology -Literature | |
| Mechanical | -Astronomy -Electronics -Tools/Shop |
| Category | Item | Answer |
|---|---|---|
| Cl. Music | How many symphonies did Beethoven compose? | 9 |
| Mod. Music | Who is the lead singer of the band “Coldplay”? | Chris Martin |
| Cl. Literature | Goethe’s “the Sorrows of Young Werther” comes from which literary period or movement…? | Sturm und Drang |
| Mod. Literature | What is the name of the locomotive with which Jim Knopf and Lukas der Lokomotivführer travel? | Emma |
| Art/Architecture | To which movement in art does Salvador Dalí belong? | Surrealism |
| Sports | The five rings that make up the Olympic Games logo are blue, red, yellow, green and... | black |
| Television | Which fictitious character has been played by actors including Sean Connery, Roger Moore and Timothy Dalton? | James Bond |
| Geography | Which river is the longest river in Europe? | Volga |
| Medicine | What is the medical term for the heart’s main artery? | Aorta |
| History | The Hundred Years’ War from the 14th and 15th centuries was waged between England and… | France |
| Religion | Which book of the bible describes the journey of Moses and the Israelites out of Egypt? | Exodus |
| Economics | Who was the chairman of Deutsche Bank from 2006 to 2012? | Josef Ackermann |
| Politics | How many permanent members are on the UN Security Council? | 5 |
| Physics | What is “Mach 1”? | The speed of sound |
| Chemistry | Name the symbol for Lithium. | Li |
| Mathematics | When two vectors are multiplied, the result is a ... | Scalar |
| Popular * | In which city is the airport with the abbreviation CDG located? | Paris |
| Biology * | How many cells does an amoeba consist of? | 1 |
| Technology * | What is the most important material for the production of conventional solar cells? | Silicon |
| Knowledge Category | Number of Items | M | SD | ω |
|---|---|---|---|---|
| Humanities | ||||
| Classical Music | 8 | .59 | .20 | .46 |
| Modern Music | 8 | .51 | .20 | .70 |
| Classical Literature | 9 | .42 | .18 | .78 |
| Modern Literature | 6 | .37 | .21 | .64 |
| Art/Architecture | 10 | .49 | .19 | .86 |
| Sports | 9 | .58 | .17 | .68 |
| Television | 7 | .56 | .21 | .45 |
| Geography | 8 | .58 | .19 | .51 |
| Medicine | 7 | .51 | .20 | .54 |
| Popular * | 11 | - | - | - |
| Civics | ||||
| History | 12 | .59 | .17 | .83 |
| Religion | 9 | .54 | .16 | 1 |
| Economics | 7 | .51 | .20 | .33 |
| Politics | 9 | .43 | .17 | .98 |
| Science | ||||
| Physics | 9 | .67 | .20 | .90 |
| Chemistry | 10 | .51 | .20 | .73 |
| Mathematics | 9 | .34 | .19 | .74 |
| Biology * | 11 | - | - | - |
| Technology * | 11 | - | - | - |
| Final Test | 137 | .50 | .02 | .98 |
| Knowledge Category | χ2 | df | CFI | RMSEA | SRMR |
|---|---|---|---|---|---|
| Humanities | |||||
| Cl. Music | 28.20 | 19 | .916 | .018 | .037 |
| Mod. Music | 24.01 | 15 | .968 | .020 | .033 |
| Cl. Literature | 10.59 | 8 | .966 | .015 | .029 |
| Mod. Literature | 6.28 | 8 | 1 | >.001 | .026 |
| Art/Arch. | 44.49 | 32 | .978 | .016 | .037 |
| Sports | 37.95 * | 25 | .929 | .019 | .045 |
| Television | 22.40 * | 11 | .956 | .027 | .037 |
| Geography | 13.65 | 20 | 1 | >.001 | .027 |
| Medicine | 14.48 | 13 | .984 | .009 | .030 |
| Civics | |||||
| History | 90.02 ** | 51 | .932 | .023 | .044 |
| Religion | 34.46 | 24 | .950 | .017 | .048 |
| Economics | 13.89 | 14 | 1 | >.001 | .030 |
| Politics | 27.97 | 24 | .978 | .011 | .033 |
| Science | |||||
| Physics | 42.27 ** | 26 | .964 | .021 | .038 |
| Chemistry | 66.09 *** | 32 | .944 | .027 | .044 |
| Mathematics | 42.24 ** | 23 | .943 | .024 | .042 |
| Domain | χ2 | df | CFI | RMSEA | SRMR | ω |
|---|---|---|---|---|---|---|
| total sample (N = 1450) | ||||||
| Humanities | 96.13 *** | 19 | .943 | .053 | .031 | .72 |
| Civics | 1.14 | 2 | 1 | <.001 | .005 | .61 |
| Science | <.001 *** | 0 a | 1 | <.001 | <.001 | .72 |
| high Gf sample (n = 415) | ||||||
| Humanities | 48.25 ** | 26 | .919 | .045 | .040 | .66 |
| Civics | 3.28 | 2 | .993 | .039 | .017 | .66 |
| Science | <.001 *** | 0 | 1 | <.001 | <.001 | .64 |
| unselected Gf sample (n = 1035) | ||||||
| Humanities | 63.82 *** | 25 | .961 | .039 | .028 | .73 |
| Civics | 0.10 | 1 | 1 | <.001 | .002 | .61 |
| Science | <.001 *** | 0 | 1 | <.001 | <.001 | .66 |
| Humanities | Civics | Science | |
|---|---|---|---|
| Humanities | 1 | .58/.58 | .20/.31 |
| Civics | .56 | 1 | .25/.29 |
| Science | .29 | .29 | 1 |
| Gkn Model | χ2 | df | CFI | RMSEA | SRMR | AIC | BIC |
|---|---|---|---|---|---|---|---|
| total sample (N = 1450) | |||||||
| One-Factor | 585.88 *** | 101 | .867 | .058 | .045 | 37,419 | 37,688 |
| Hierarchical | 345.21 *** | 96 | .932 | .042 | .033 | 37,188 | 37,483 |
| high Gf sample (n = 415) | |||||||
| One-Factor | 223.28 *** | 101 | .848 | .054 | .052 | 11,382 | 11,587 |
| Hierarchical | 165.59 *** | 97 | .915 | .041 | .043 | 11,331 | 11,553 |
| unselected Gf sample (n = 1035) | |||||||
| One-Factor | 615.02 *** | 101 | .789 | .070 | .053 | 27,058 | 27,310 |
| Hierarchical | 306.29 *** | 98 | .915 | .045 | .036 | 26,755 | 27,022 |
| Category | Loadings Total Sample | Loadings High Gf | Loadings Unselected Gf |
|---|---|---|---|
| Humanities | |||
| Classical Music | .491 | .364 | .503 |
| Modern Music | .505 | .497 | .482 |
| Classical Literature | .421 | .240 | .459 |
| Modern Literature | .299 | .233 | .313 |
| Art/Architecture | .646 | .634 | .658 |
| Sports | .345 | .409 | .337 |
| Television | .477 | .332 | .432 |
| Geography | .519 | .486 | .515 |
| Medicine | .325 | .337 | .288 |
| Civics | |||
| History | .580 | .634 | .575 |
| Religion | .522 | .555 | .474 |
| Economics | .464 | .387 | .455 |
| Politics | .517 | .616 | .468 |
| Science | |||
| Physics | .614 | .779 | .808 |
| Chemistry | .553 | .301 | .554 |
| Mathematics | .593 | .699 | .577 |
| Gkn-Factor | |||
| Humanities | .858 | .750 | .909 |
| Civics | 1 | 1 | 1 |
| Science | .545 | .395 | .434 |
| χ2 | df | CFI | RMSEA | SRMR | |
|---|---|---|---|---|---|
| Configural | 442.41 | 192 | .926 | .042 | .037 |
| Metric | 476.20 | 207 | .921 | .042 | .043 |
| Scalar | 499.41 | 219 | .918 | .042 | .044 |
| ΔCFI | ΔRMSEA | ΔSRMR | |||
| Configural vs. Metric | .0055 | .0001 | −.0058 | ||
| Metric vs. Scalar | .0033 | .0003 | −.0013 |
| Humanities | Civics | Science | Gkn | |
|---|---|---|---|---|
| d | 0.427 | 0.349 *** | 1.138 *** | 0.510 *** |
| M | −0.08 | −0.10 | −0.38 | −0.14 |
| SD | 0.18 | 0.27 | 0.34 | 0.27 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rusche, M.M.; Ziegler, M. Measuring Domain-Specific Knowledge: From Bach to Fibonacci. J. Intell. 2023, 11, 47. https://doi.org/10.3390/jintelligence11030047
Rusche MM, Ziegler M. Measuring Domain-Specific Knowledge: From Bach to Fibonacci. Journal of Intelligence. 2023; 11(3):47. https://doi.org/10.3390/jintelligence11030047
Chicago/Turabian StyleRusche, Marianna Massimilla, and Matthias Ziegler. 2023. "Measuring Domain-Specific Knowledge: From Bach to Fibonacci" Journal of Intelligence 11, no. 3: 47. https://doi.org/10.3390/jintelligence11030047
APA StyleRusche, M. M., & Ziegler, M. (2023). Measuring Domain-Specific Knowledge: From Bach to Fibonacci. Journal of Intelligence, 11(3), 47. https://doi.org/10.3390/jintelligence11030047