1. Introduction
Manufacturers often design multiple colors when creating color schemes to meet consumers’ personalized needs while achieving product diversification and serialization at a lower cost [
1,
2]. Understanding consumer color preferences accurately and promoting product sales has long been a concern for researchers.
In the past, color design relied heavily on the intuition and experience of designers [
3]. With the advancement of technology, computer-aided design can provide more assistance in product color design and satisfy consumer preferences. For example, Tian et al. [
4] developed a computer-aided custom sofa color system, which can improve the efficiency and quality of consumer color selection and customer satisfaction with customized sofas. Hsiao et al. [
5] built a color design/selection system for designing colors and helping consumers choose suitable clothing colors based on their skin color. Whether relying on the abilities of designers or utilizing computer algorithms, one of the critical tasks in the early stages of the design is to investigate users’ aesthetic preferences. Currently, research for this purpose mainly focuses on existing products and employs small sample statistics. However, the widespread use of big data technology offers the possibility of extensive user research and market trend analysis. Data mining can rapidly acquire a large amount of user behavioral data, from which numerous diverse and fragmented types of information can be obtained.
This article aimed to extract valuable information from big data and apply this method to rapidly collect user behavior data for color preference analysis and quantitative color research. This research approach has broader applications and provides more accurate results. It offers manufacturers a more scientific, accurate, and efficient way to understand consumer color preferences and consumption behavior. The present research not only focuses on consumers’ choices and purchasing behavior in product colors but also establishes a quantitative relationship among the HSV attributes of color models of popular products using mathematical models. This quantitative color research can assist manufacturers in gaining a more accurate understanding of consumer demands and optimizing product color designs.
2. Literature Review
The research on color is extensive, among which studies on individual color preference are the most concentrated. These studies covered external factors influencing color preferences (such as gender, age, educational background, et al. [
6]) and the reasons behind color preference formation [
7]. Internal factors like RGB and HSV also impact color preference. For example, Gou et al. [
8] studied residents’ preferences for the color of urban buildings and found that several factors influence citizens’ hue preferences, including gender, age, occupation, monthly income, and cultural background, such as men engaged in business management or professional occupations tending to prefer red–blue, blue, blue–green, green, and neutral colors. On the other hand, women who are teachers or white-collar workers tend to prefer warmer and more vibrant colors like yellow, red, and red–yellow. The younger population, below 30, tends to lean toward green, red–yellow, and red–blue colors. Additionally, individuals with a monthly income above 10,000 yuan prefer green and green–yellow colors. In another study, Zhang et al. [
9] examined the influence of age and gender on color preferences among Chinese adults. Their study found that Chinese women prefer cyan, white, pink, and light colors more than men, while they have a lower preference for red, orange, and dark colors. Additionally, preferences for blue, purple, yellow, white, black, and light colors gradually decrease with age.
However, personal color preferences are not the sole criterion for purchasing decisions in specific consuming behaviors. Jiang et al. [
10] found that color preference has some influence on teenagers’ furniture selection, but the extent varies according to functional spaces and furniture categories. Yu et al. [
11] found that consumers tend to buy their favorite colors. However, personal color preferences are secondary factors, and the impacts of color functionality and product category on purchasing decisions are critical. That means people’s color preferences are diverse and will be affected by the functions and categories of products, showing different color preferences for different products. Therefore, many studies have focused on consumers’ color preferences for different types of products.
In previous studies, researchers typically used questionnaire surveys and interviews to obtain information about consumers’ color preferences. For example, Yu et al. [
12] used interviews to understand why people choose a particular color of a product when shopping, inferring the relationship between personal color associations and product purchasing decisions. Bakker et al. [
6] used questionnaire surveys to research the relationship between color preferences and personal characteristics of different topics.
Although questionnaire surveys and interviews are widely used, they also have limitations. First, due to the influence of individual differences and subjective feelings, the conclusions obtained are essentially a subjective evaluation and may not have universal adaptability. Second, the information provided about colors in the questions is mainly verbal (such as the names of colors like “blue” and “red”) or images that express colors more intuitively (such as products being modified in Adobe Photoshop to become different colors). Sometimes, this limits the accuracy of the subjects’ color selection, which may lead to a lack of authenticity in the results. In addition, the sample size of questionnaire surveys and interviews is usually between 50–200 people. If the sample size is insufficient, it may affect the research results on color preferences. Therefore, it is necessary to use objective and quantitative color data in the experimental design and ensure that the sample size is sufficient to make the study of product color preference more scientific and reliable.
Currently, more and more methods and tools are available to obtain consumers’ preferences for product colors objectively. For example, Yu et al. [
13] used eye-tracking movement technology to research consumers’ preferences for red sandalwood and wenge wood furniture with different hue (H) and lightness (L) values, providing a more reliable research method for studying color preferences through quantitative analysis of physiological data. Some tools can obtain specific color data. Li et al. [
14] obtained the hue (H), saturation (S), and value (V) of ancient Chinese clothing with a Datacolor650 spectrophotometer. Zheng [
15] et al. used Adobe Clour CC to obtain HSV values from interior photographs. Many scholars have proposed methods for transforming color features into numerical values for quantitative research, laying the foundation for building a regularity or prediction model. Zhou et al. [
16] used a CHN Spec color picker to extract the hue (H), value (V), and chroma (C) values of wardrobe furniture, analyzed the data characteristics, and established a color selection system for wardrobe furniture based on the Munsell color system, the Mont-Spencer principle of color harmony, and the Birkhoff beauty rating system. It was used to help the company re-plan the color scheme of its wardrobe products. Zhao et al. [
17] utilized the K-Means clustering method to analyze the objective law of Yi costume colors. Based on the features of Yi costume’s primary colors in the HSV color space, they proposed objective evaluation indicators to evaluate the color scheme and help improve it. After data processing and mathematical modeling, these studies showed that quantified color features can be applied in specific fields and assist product color design.
We found that the HSV, HVC, and HSL color spaces are commonly used in color extraction. These color spaces are based on human visual perception characteristics and provide a more direct description of color appearance, including brightness and saturation, which align with our everyday description of color. Additionally, they can better overcome issues such as uneven surface colors caused by intense light, shadow, occlusion, or texture [
18,
19]. This paper employed the HSV color model for our research. Compared to other models, HSV offers more advantages in computer graphics processing, ensuring accurate color information extraction on computer screens.
Based on the above content, this research used data mining to obtain sales data and pictures of thermos cups to solve the problems of limited sample size and color information in questionnaire surveys and interviews. Due to user privacy, this study does not delve into potential factors influencing color preferences. However, the objectivity of consumer data reflects their actual color selection behavior. By utilizing Adobe Color, we extracted the HSV values of product images to analyze consumers’ preferences for thermos cup color quantitatively. According to these numerical values, we explored whether there was a mathematical law in the color of hot-selling products and built a mathematical model.
3. Methods
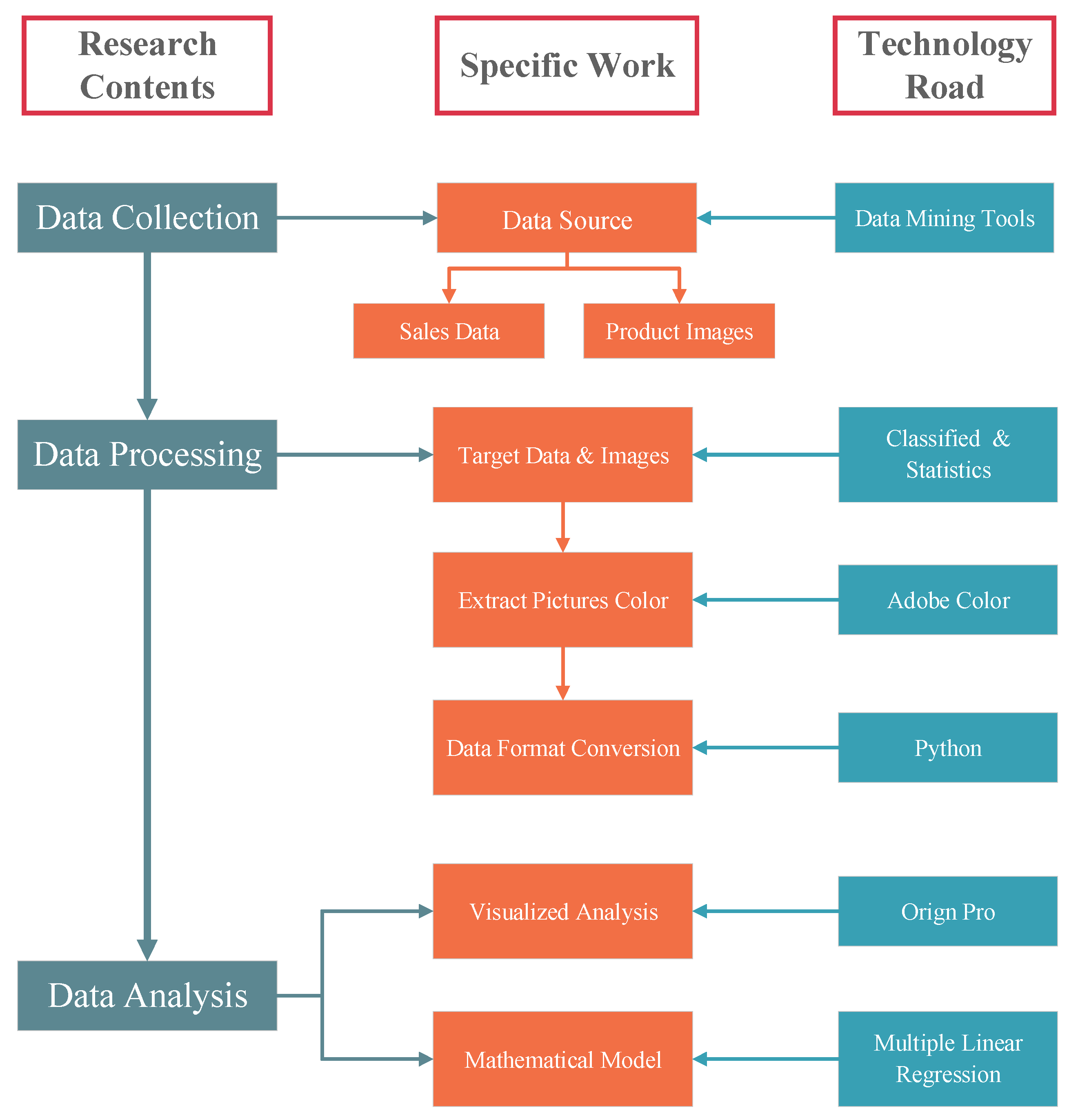
Based on the guidance of data mining, this paper explored and researched the data set. Data mining (DM) analyzes observed data sets and discovers unknown relationships through six stages: problem definition, creating target data sets, data processing, data visualization, building a mathematical model, and problem-solving, thus allowing data owners to understand data relationships and summarize their data [
20,
21]. The details are as follows.
3.1. Step 1: Problem Definition
First, determine the problem being attempted to solve and determine the goal of data mining. A data mining plan is then devised based on this goal. Generally, data mining tasks can be divided into two main categories: descriptive tasks and predictive tasks. Descriptive tasks identify patterns and relationships in the data, whereas predictive tasks use existing data to make predictions [
22]. This study aimed to explore the possible patterns in the HSV values of popular products and establish a mathematical model using data mining, which falls under the definition of a descriptive task. The research framework is shown in
Figure 1.
3.2. Step 2: Creating Target Data Sets
Based on the first stage’s questions, the necessary dataset for the study needs to be determined. Simple investigations are needed in this process to ensure high-quality data can be obtained. In this step, we need to get information, such as online shopping platforms, product sales rankings, and product pictures. These data are available from Jingcanmou, a professional e-commerce data analysis online platform that provides free access to sales data from JD and Tmall (two popular online shopping platforms in China) from February to April 2022. Sales data can be obtained for the top 200 items on JD and the top 100 on Tmall. All images of products with the same name could be collected (
Table 1). The samples were selected from different styles of thermos cups under the brand FUGUA, as indicated by the intersection in
Figure 2. JD.com and Tmall are the two largest e-commerce shopping platforms in China, with the majority of their user base consisting of urban residents spanning a wide age range, typically between 20 and 50 years old. This diversity allows these two e-commerce platforms to attract and serve consumers from different age groups and regions, providing a rich and diverse selection of goods to meet users’ personalized needs.
3.3. Step 3: Data Processing
Data acquisition can obtain massive amounts of data, but not all are suitable for follow-up research. Therefore, this step needs to select the data from the collected data, eliminate irrelevant data, and convert the data into a unified format suitable for data modeling.
In this study, the classification defined the research scope first. Classification can improve information processing efficiency and cognitive stability, allowing us to identify new projects or events and observe consumers’ preferences [
23]. We mainly focused on categorizing the capacity and colors of thermos cups. The most popular objects proceeded to the following research stage.
After selecting the research objects, Adobe Color was used to extract the dominant colors of the images. Adobe Color is a web application that establishes and edits various color themes. When pixelated, it can recognize five characteristic colors and obtain colors from images [
24].
Due to individual differences in color perception, this study invited three experts with color research experience to extract the colors. We randomly selected five samples and prepared two devices, Device 1 and 2, which had undergone color calibration, and Device 3, which had not undergone color calibration. The experimental design was as follows:
- 1.
Experiment 1: The screen brightness of Device 1 was set to 50%, and the experts first extracted colors from the sample on Device 1. After extraction, we calculated the average values of H, S, and V to present as the final data.
It should be noted that ambient light may affect visual perception, and consumers usually use mobile phones for shopping. The screen brightness will automatically adjust with the intensity of the ambient light. Therefore, we conducted Experiment 2 by changing the screen brightness of the device to simulate changes in the ambient light:
- 2.
Experiment 2: The screen brightness of Device 2 was set to 0% and 100% for two separate experiments. Experts observed the sample on Device 2 for 5 s before selecting the color on Device 1.
However, in practical applications, there are differences in screen calibration among consumers’ mobile phones. Therefore, we conducted Experiment 3:
- 3.
Experiment 3: The screen brightness of Device 3 was set to 50%, and we repeated Experiment 1.
The experimenters found that when the screen brightness was set to 0%, we observed a deviation of approximately 10% in V value, while hue and saturation remained relatively unchanged. This finding indicates a stable characteristic of human color perception. This conclusion is supported by related studies, such as the research conducted by Emery and Webster [
25], which also pointed out similar color perception stability phenomena. According to Smithson [
26], perceptual constancy refers to the phenomenon in which the color of an object appears unchanged despite changes in the conditions of observation. Therefore, color extraction for other samples can be continued as in Experiment 1.
It is worth noting that our results demonstrated that changes in brightness have a negligible impact on hue and saturation perception. However, as the brightness decreases to a certain extent, color discrimination abilities are affected, showing a gradual decline. This finding is consistent with the research results of Brown et al. [
27]. In subsequent studies, the factor of value can be reduced in consideration of these results.
3.4. Step 4: Data Analysis and Visualization
The results of data mining are intuitively displayed through charts and graphs. Information visualization is the process of linking abstract information with visual forms. If the visualization format matches the message, it can help with understanding and leave a more profound impression on the audience.
In the HSV color model, the hue (H) ranges from 0°~360°. The warm color range is from 0° to 90° and 330° to 360°; the warm-to-cold neutral range is from 90° to 150°; the cool color range is from 150° to 270°; and the cold-to-warm neutral range is from 270°~330°. Saturation (S) represents the proportion of colored parts as a percentage from a minimum of 0% to a maximum of 100%. The low saturation range is 0% to 30%; the medium saturation range is 31%~69%; and the high saturation range is 70%~100%. Value (V), the percentage of black 0% to white 100% indicates the color’s value, with 0% to 30% being the low-value area; 31%~69% the medium-value area; and 70%~100% the high-value area. These measures can objectively describe consumer color preferences during data analysis.
The primary purpose of the visualization was to display the distribution characteristics of HSV values in the data and analyze consumer color preferences. The process was illustrated through 3D scatter plots in Origin Pro 2022. The scatter size can also reflect the influence of other variables on the scatter points.
Visualization charts were also applied to the results of data classification in the earlier stage, and this part used other statistical charts to represent the differences in quantity.
3.5. Step 5: Building a Mathematical Model
Next, select a data analysis method for the data and output of the model. There are two commonly used quantitative methods for data analysis: Bayesian analysis and regression analysis [
28]. Many constraints, such as economics and cultural customs, must be considered when applying Bayesian analysis. These factors can critically impact consumers’ demand and color choices and are challenging to define. Regression methods have fewer constraints and are applicable in more fields.
Regression methods include linear regression, non-linear regression, logistic regression, and so on. This paper aimed to study the relationship between the dependent and multiple independent variables. In
Section 4.4, we used two regression methods for pre-experiments. By comparing the performance of the two models, we evaluated their advantages and disadvantages and selected a more adaptable model.
3.6. Step 6: Problem Solution
Finally, evaluate whether the output model can answer the questions raised in Step 1 and clarify the model’s limitations. This part is explained in the Discussion.
5. Discussion
According to the established color mathematical model, this study explained the mathematical pattern of the hot-selling single-color thermos cup. Initially, we randomly selected 100 data sets for the pre-experiment. We found a significant positive correlation between H and S. In the subsequent regression training model, we also prioritized the influence of S on the fitting result. Adjusting the power of S was optimal at 0.5 for fitting. The coefficient for S was 26.91, the coefficient for V was 0.06, and the intercept was 21.8, indicating that S has a more significant influence on H, consistent with the pre-experiment findings.
The visualized results showed that low saturation and high-value scatter plots were more concentrated, which was consistent with the research conclusion of Beneke J et al. [
29]: consumers generally prefer neutral colors. The hue values were particularly noticeable within the range of 0–60. Upon examining the original images, we found that most scatter points in the light yellow color range corresponded to gold. The white and light pink data points constituted a significant portion of the original data set. There were also a few silver and rose gold data points exhibiting characteristics of high brightness. Since the data were artificially extracted, similar colors had slight numerical changes during color extraction, resulting in data points not overlapping but densely distributed in a specific area in the chart. In addition, the HSV values in the graph were notably broad, which can be attributed to factors such as color functionality and usage scenarios [
30]. Individuals typically use thermos cups in various scenarios. Different types of products exhibit different color styles. For instance, air purifiers commonly utilize white color schemes. This indicates that color schemes for different products are entirely different, and appropriate color schemes help establish a powerful brand image [
11].
Although we had obtained a large amount of data through data mining, many steps still required manual input. For example, for color extraction, we attempted to utilize K-means clustering to obtain product colors efficiently and quickly. However, the color acquired through this method did not meet our expectations. Furthermore, during the initial stages of data selection, we discovered that retailers injected numerous keywords into their product names, which may ensure that consumers find their products as easily as possible to increase the exposure and clicks on the goods. Therefore, data cannot be batch-selected.
Furthermore, it is essential to note that the color of the actual product may be different from the images provided by the manufacturers due to processes such as photography and color adjustments. Additionally, owing to individual differences and technological constraints, it is hard to eliminate perceptual errors in color. Therefore, the method of color extraction cannot guarantee scientific accuracy. Despite our efforts to enhance the precision of the color data, limitations persist. Consequently, when interpreting these research findings, caution is warranted regarding the accuracy of the color data.
Although the volume of data obtained through data mining is substantial, due to consumers’ privacy, we cannot consider consumers’ color preferences from factors such as gender, age, cultural background, and educational background. As a result, our research findings tend to lean toward a general conclusion—that most consumers favor colors with low saturation and lightness. Nevertheless, our study retains validity. Through the analysis of data, a universal trend in color preference can be observed. This discovery may be associated with consumers’ pursuit of soft, warm, and tranquil sensations. However, it is essential to note that this trend is merely a general inclination and does not represent the preferences of every consumer. Future studies can improve this study from the perspective of influencing factors.
This paper conducted preliminary experiments to compare linear regression with random forest regression models. Based on the evaluation of model performance using metrics such as R2 and MSE, it was determined that the linear regression model showed better performance, leading to the successful establishment of a multiple linear regression model. Subsequently, we statistically tested the test and prediction sets’ max, min, and mean values. The results revealed that only the average values of the two sets are close to each other, while the other values have large differences. These differences may be related to the characteristics of our data, but the predictive results can elucidate the current patterns. After successfully establishing the linear regression model, this study did not test the model’s applicability. Tens of thousands of samples are required to establish a good prediction model. However, due to the focus on best-selling products as the research subject, collecting excessive samples would deviate from the central theme. Given the constraints of the research subject, this model is limited to descriptive tasks, which is the same as the first step in data mining tasks.
6. Conclusions
This study acquired a significant amount of sales data through data mining. Through classification, this study focused on single-color thermos cups as the research object. The colors of the thermos cups were extracted and converted into an HSV color model. By using visualized charts, this paper demonstrated consumers’ color preferences and found that consumers tend to purchase thermos cups with neutral colors. A mathematical model was established using linear regression to explore the relationships among HSV values. It was discovered that there is a significant correlation between S and H values in the popular single-color thermos cups within the HSV color model. However, a predictive model was not established due to the limitations of the regression model methodology and research object. Therefore, the determination of the accuracy and generalizability of this model will remain for future research.
This paper presents a novel approach to color design practice, utilizing information technology to assist color designers in collecting a vast amount of user demand information and sales data. This method challenges the traditional approach of relying solely on talent or intuition to design color schemes. Furthermore, it effectively simplifies the color design process. Moreover, the proposed method can also be applied to color design research across diverse products, enabling products to meet various service demands better.
In summary, this study’s research methods and findings make significant academic contributions as follows:
Methodological Innovation: This paper introduces a novel color design practice that utilizes information technology to assist color designers in gathering extensive user demand information and sales data. This approach departs from the traditional reliance on “talent” or “intuition” for color scheme design by designers, effectively streamlining the color design process and offering new perspectives and methods to the field of color design;
Knowledge Contribution: Through analyzing the colors of thermos cups and establishing mathematical models, this paper reveals consumer preferences for neutral-colored thermos cups and uncovers mathematical relationships within the HSV color model of popular products. These findings enrich the research domain of color preferences and color correlations.
Furthermore, the research in this paper can be applied to the following practices:
Optimized Color Design: The proposed method can be applied to color design research for different products, enabling designers to gain a more accurate understanding of consumer preferences for product colors and optimize product design to meet various service needs better;
Cross-Industry Application: The method proposed in this paper applies not only to color design research for thermos cups but also to color design research for other products. Gathering user demand information and sales data can help companies adapt products to meet diverse needs.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



































