
Automating Speech Audiometry in Quiet and in Noise Using a Deep Neural Network
 ,
,
Simple Summary
Abstract
1. Introduction
2. Materials and Methods
2.1. Automated Speech Recognition (ASR) System
2.2. Subjects
2.2.1. Subjects for Speech Audiometry in Quiet
- Normal hearing with PTA less than 20 dB (n = 37 ears);
- Mild hearing loss with PTA between 21 and 40 dB (n = 49 ears);
- Moderate hearing loss with PTA between 41 and 70 dB (n = 126 ears);
- Severe hearing loss with PTA between 71 and 90 dB (n = 6 ears).
2.2.2. Subjects for Speech Audiometry in Noise
- Normal hearing with PTA less than 20 dB (n = 85 subjects);
- Mild hearing loss with PTA between 21 and 40 dB (n = 50 subjects);
- Moderate hearing loss with PTA between 41 and 70 dB (n = 50 subjects).
2.3. Material and Calibration
2.4. Manual Air-Conduction Pure-Tone Audiometry to Obtain the Hearing Status of Subjects
2.5. Speech Audiometry in Quiet with Lafon’s Cochlear Lists
2.6. Speech Audiometry in Noise with Dodelé Logatoms
- 10 dB SNR = masking noise presented at 50 dB SPL;
- 5 dB SNR = masking noise presented at 55 dB SPL;
- 0 dB SNR = masking noise presented at 60 dB SPL;
- −5 dB SNR = masking noise presented at 65 dB SPL;
- −10 dB SNR = masking noise presented at 70 dB SPL;
- −15 dB SNR = masking noise presented at 75 dB SPL;
- −20 dB SNR = masking noise presented at 80 dB SPL.
2.7. Manual Scoring of Subjects’ Verbal Responses in Quiet and in Noise by an Experimenter
2.8. Automated Scoring of Subjects’ Verbal Responses in Quiet and in Noise by the ASR System
2.9. Statistics
3. Results
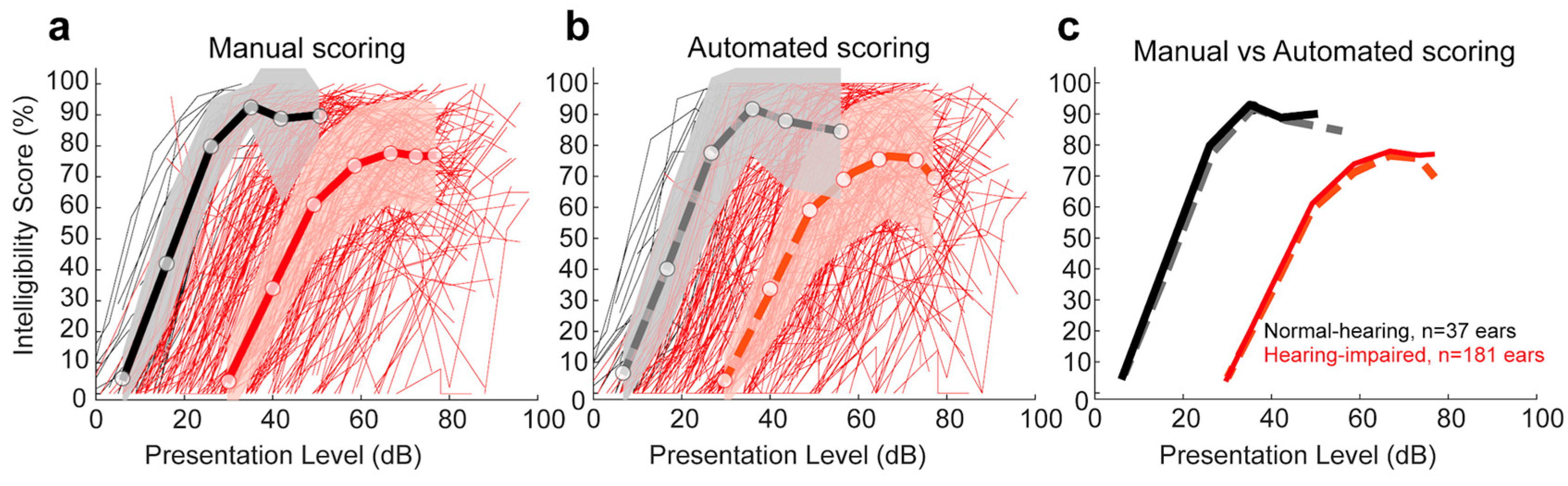
3.1. Speech Audiometry in Quiet with Lafon’s Cochlear Lists
3.1.1. Comparison of Manual and Automated Scoring for Each Lafon’s Cochlear Lists
3.1.2. Comparison of Manual and Automated Scoring for Lafon’s Cochlear Lists as a Function of Hearing Status
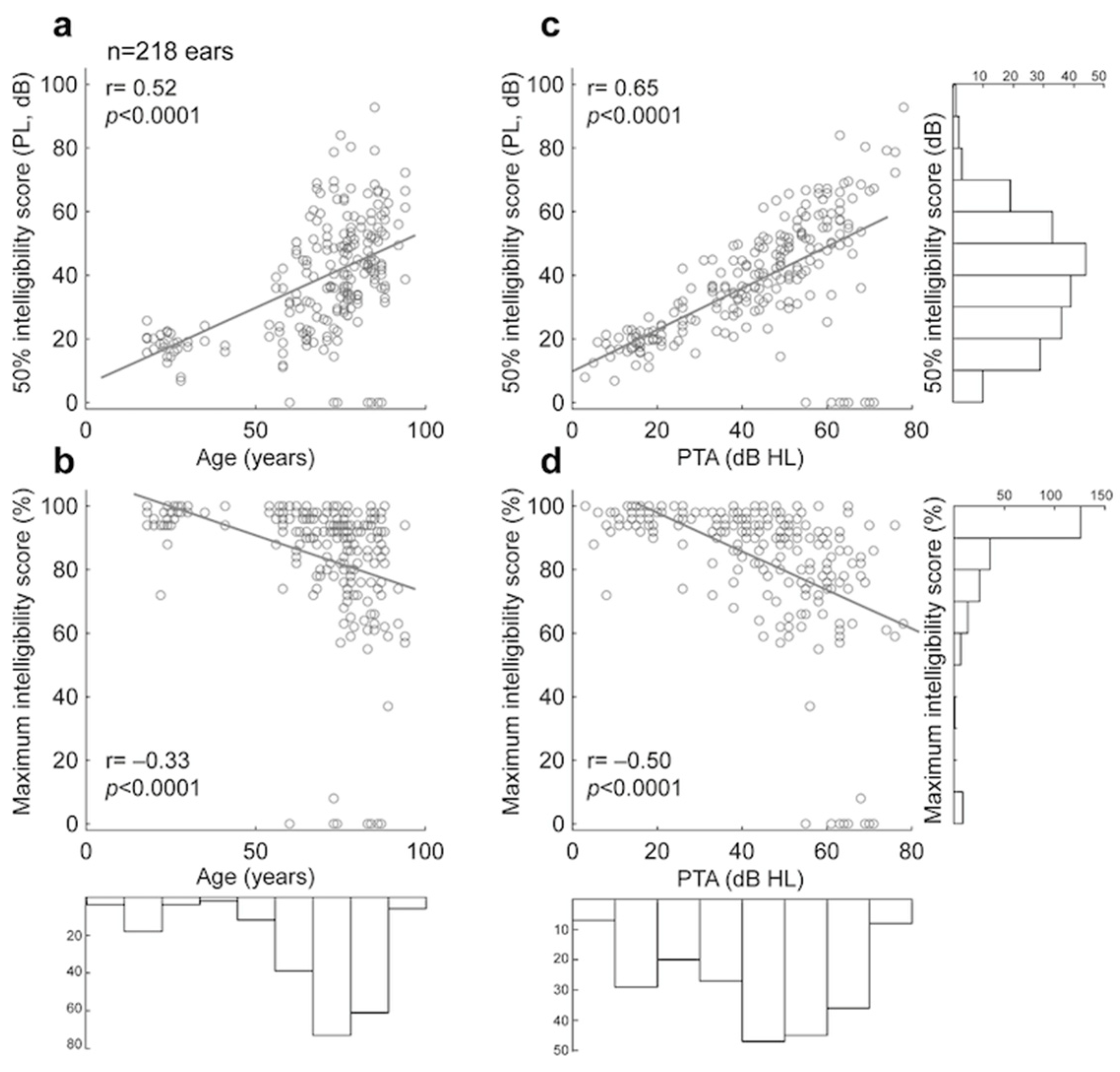
3.1.3. Comparison of Manual and Automated 50% and Maximum Intelligibility Scores for Lafon’s Cochlear Lists
3.1.4. Convergence of Scores for Each of Lafon’s Cochlear Lists
3.1.5. Test–Retest Reliability of Manual and Automated Scoring of Lafon’s Cochlear Lists
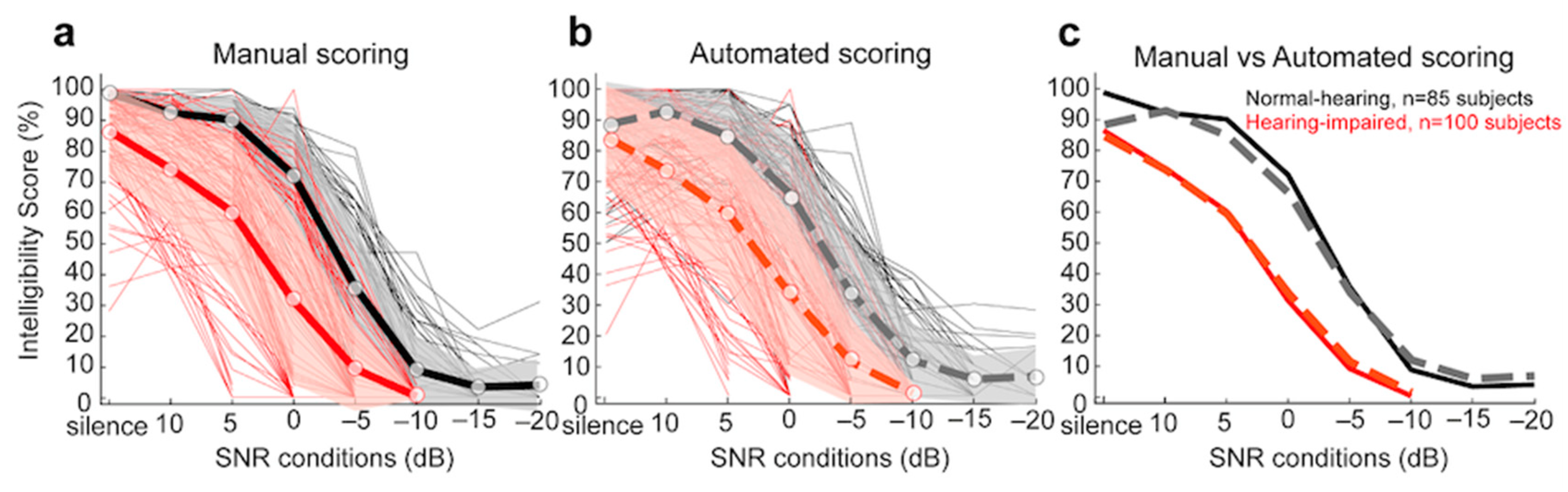
3.2. Speech Audiometry in Noise with Dodelé Logatoms
3.2.1. Comparison of Manual and Automated Scoring for Each Dodelé Logatom List
3.2.2. Comparison of Manual and Automated Scoring for Dodelé Logatom Lists as a Function of Hearing Status
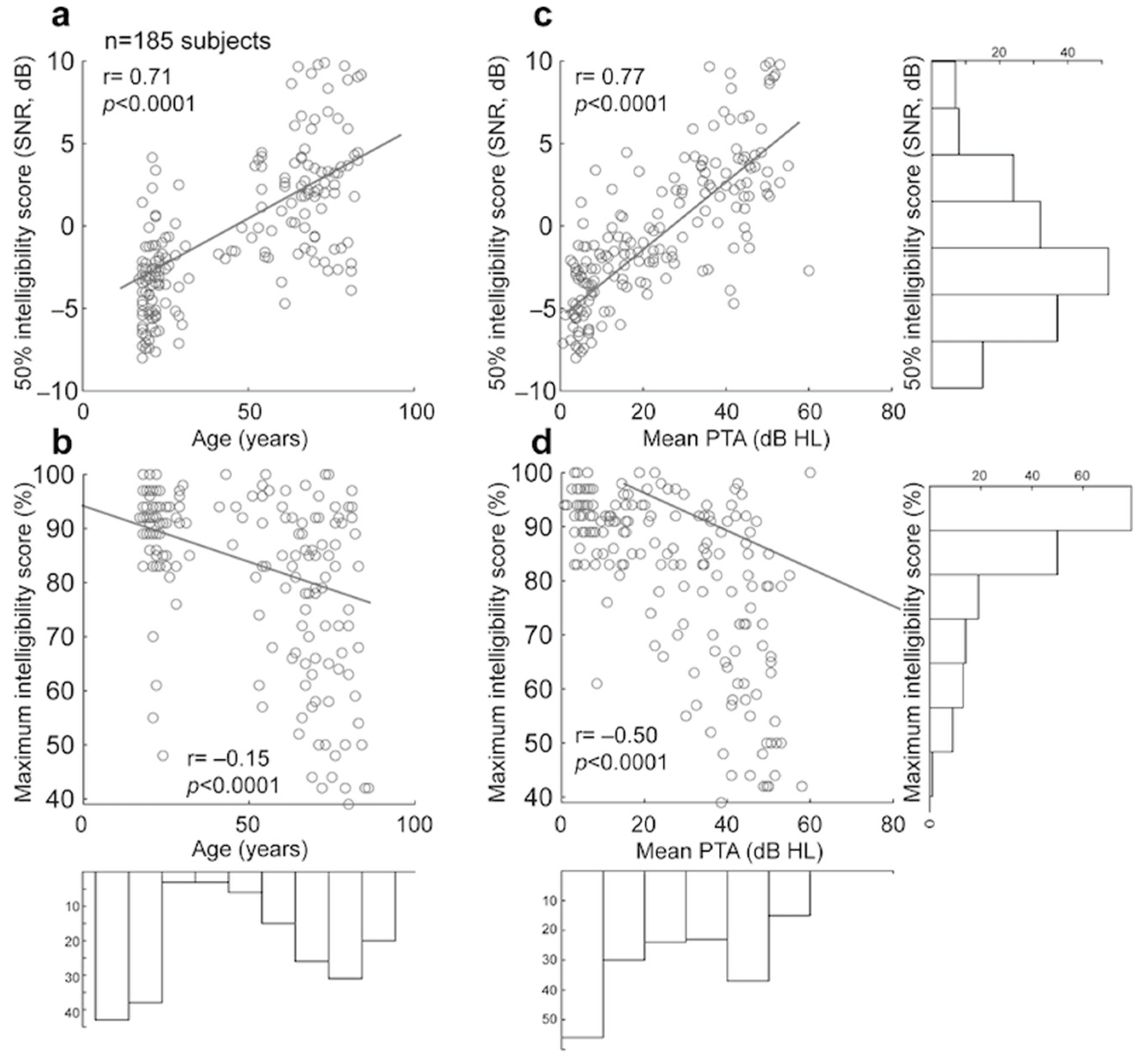
3.2.3. Comparison of Manual and Automated 50% and Maximum Intelligibility Scores for Dodelé Logatom Lists
3.2.4. Convergence of Scores for Each of Dodelé Logatom Lists
3.2.5. Test–Retest Reliability of Manual and Automated Scoring of Dodelé Logatom Lists
4. Discussion
5. Conclusions
6. Patents
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ASR | Automatic Speech Recognition |
| AC | Air conduction |
| PL | Presentation Level |
| PTA | Pure-tone average |
| ML | Machine learning |
| SRT | Speech reception threshold |
| NH | Normal hearing |
| HI | Hearing impaired |
| DNN | Deep neural network |
| SNR | Signal-to-noise ratio |
| std | Standard deviation |
| HMM | Hidden Markov model |
| ENT | Ear–Nose–Throat specialist |
References
- Carl, A.C.; Hohman, M.H.; Cornejo, J. Audiology pure tone evaluation. In StatPearls; StatPearls Publishing: Treasure Island, FL, USA, 2022. [Google Scholar] [PubMed]
- Hughson, W.A.; Westlake, H. Manual for program outline for rehabilitation of aural casualties both military and civilian. Trans. Am. Acad. Ophthalmol. Otolaryngol. 1944, 48, 1–15. [Google Scholar]
- EN ISO 8253-1:2010; Acoustics-Audiometric Test Methods-Part 1: Pure-Tone Air and Bone Conduction Audiometry. International Organization for Standardization: Geneva, Switzerland, 2010.
- Nieman, C.L.; Oh, E.S. Hearing loss. Ann. Intern. Med. 2020, 173, ITC81–ITC96. [Google Scholar] [CrossRef] [PubMed]
- Brotto, D.; Benvegnù, F.; Colombo, A.; de Filippis, C.; Martini, A.; Favaretto, N. Age-related changes in auditory perception. Hearing loss in the elderly: Aging ear or aging brain? Aging Clin. Exp. Res. 2023, 35, 2349–2354. [Google Scholar] [CrossRef] [PubMed]
- Parthasarathy, A.; Hancock, K.E.; Bennett, K.; DeGruttola, V.; Polley, D.B. Bottom-up and top-down neural signatures of disordered multi-talker speech perception in adults with normal hearing. Elife 2020, 9, e51419. [Google Scholar] [CrossRef]
- Carhart, R. Speech audiometry in clinical evaluation. Acta Oto-Laryngol. 1952, 41, 18–42. [Google Scholar] [CrossRef] [PubMed]
- Boothroyd, A. Developments in speech audiometry. Br. J. Audiol. 1968, 2, 3–10. [Google Scholar] [CrossRef]
- Jerger, J.; Speaks, C.; Trammell, J.L. A new approach to speech audiometry. J. Speech Hear. Disord. 1968, 33, 318–328. [Google Scholar] [CrossRef] [PubMed]
- Tillman, T.W.; Olsen, W.O. Speech audiometry. In Modern Developments in Audiology; Jerger, J., Ed.; Academic Press: New York, NY, USA, 1973; pp. 37–74. [Google Scholar]
- Hall, J.W. Diagnostic applications of speech audiometry. In Seminars in Hearing; Thieme Medical Publishers, Inc.: New York, NY, USA, 1983; Volume 4, pp. 179–203. [Google Scholar]
- Walker, H.K.; Hall, W.D.; Hurst, J.W. Clinical Methods: The History, Physical, and Laboratory Examinations; Butterworths: Boston, MA, USA, 1990. [Google Scholar]
- Joly, C.A.; Reynard, P.; Mezzi, K.; Bakhos, D.; Bergeron, F.; Bonnard, D.; Thai-Van, H. Guidelines of the French Society of Otorhinolaryngology-Head and Neck Surgery (SFORL) and the French Society of Audiology (SFA) for speech-in-noise testing in adults. Eur. Ann. Otorhinolaryngol. Head Neck Dis. 2022, 139, 21–27. [Google Scholar] [CrossRef] [PubMed]
- Taylor, B. Speech-in-noise tests: How and why to include them in your basic test battery. Hear. J. 2003, 56, 40–42. [Google Scholar] [CrossRef]
- Garnier, M.; Lamalle, L.; Sato, M. Neural correlates of phonetic convergence and speech imitation. Front. Psychol. 2013, 4, 600. [Google Scholar]
- Coene, M.; Krijger, S.; Meeuws, M.; De Ceulaer, G.; Govaerts, P.J. Linguistic factors influencing speech audiometric assessment. BioMed Res. Int. 2016, 7249848. [Google Scholar] [CrossRef]
- EN ISO 8253-3: 2022; Acoustics-Audiometric Test Methods-Part 3: Speech Audiometry. International Organization for Standardization: Geneva, Switzerland, 2022.
- Rembaud, F.; Fontan, L.; Fullgrabe, C. L’audiométrie vocale en France: État des lieux. Cah. De L’audition 2017, 6, 22–25. [Google Scholar]
- Reynard, P.; Lagacé, J.; Joly, C.A.; Dodelé, L.; Veuillet, E.; Thai-Van, H. Speech-in-noise audiometry in adults: A review of the available tests for French speakers. Audiol. Neurotol. 2022, 27, 185–199. [Google Scholar] [CrossRef] [PubMed]
- Favier, V.; Vincent, C.; Bizaguet, É.; Bouccara, D.; Dauman, R.; Frachet, B.; Venail, F. French Society of ENT (SFORL) guidelines (short version): Audiometry in adults and children. Eur. Ann. Otorhinolaryngol. Head Neck Dis. 2018, 135, 341–347. [Google Scholar] [CrossRef] [PubMed]
- Jansen, S.; Luts, H.; Wagener, K.C.; Kollmeier, B.; Del Rio, M.; Dauman, R.; van Wieringen, A. Comparison of three types of French speech-in-noise tests: A multi-center study. Int. J. Audiol. 2012, 51, 164–173. [Google Scholar] [CrossRef] [PubMed]
- Jansen, S.; Luts, H.; Wagener, K.C.; Frachet, B.; Wouters, J. The French digit triplet test: A hearing screening tool for speech intelligibility in noise. Int. J. Audiol. 2010, 49, 378–387. [Google Scholar] [CrossRef]
- Jansen, S.; Luts, H.; Dejonckere, P.; van Wieringen, A.; Wouters, J. Efficient hearing screening in noise-exposed listeners using the digit triplet test. Ear Hear. 2013, 34, 773–778. [Google Scholar] [CrossRef]
- Paglialonga, A.; Tognola, G.; Grandori, F. SUN-test (Speech Understanding in Noise): A method for hearing disability screening. Audiol. Res. 2011, 1, e13. [Google Scholar] [CrossRef] [PubMed]
- Cameron, S.; Boyle, C.; Dillon, H. The development of the Language-Independent Speech in Noise and Reverberation test (LISiNaR) and evaluation in listeners with English as a second language. Int. J. Audiol. 2023, 62, 756–766. [Google Scholar] [CrossRef] [PubMed]
- Wilson, R.H.; McArdle, R. Speech signals used to evaluate functional status of the auditory system. J. Rehabil. Res. Dev. 2005, 42, 79–94. [Google Scholar] [CrossRef] [PubMed]
- Margolis, R.H.; Wilson, R.H.; Saly, G.L.; Gregoire, H.M.; Madsen, B.M. Automated forced-choice tests of speech recognition. J. Am. Acad. Audiol. 2021, 32, 606–615. [Google Scholar] [CrossRef]
- Venail, F.; Legris, E.; Vaerenberg, B.; Puel, J.L.; Govaerts, P.J.; Ceccato, J.C. Validation of the French-language version of the OTOSPEECH automated scoring software package for speech audiometry. Eur. Ann. Otorhinolaryngol. Head Neck Dis. 2016, 133, 101–106. [Google Scholar] [CrossRef] [PubMed]
- Hammer, A.; Vaerenberg, B.; Kowalczyk, W.; ten Bosch, L.; Coene, M.; Govaerts, P.J. Balancing word lists in speech audiometry through large spoken language corpora. Proc. Interspeech 2013, 2013, 3613–3616. [Google Scholar]
- Deprez, H.; Yilmaz, E.; Lievens, S. Automating speech reception threshold measurements using automatic speech recognition. In Proceedings of the Fourth Workshop on Speech and Language Processing for Assistive Technologies, Grenoble, France, 21–22 August 2013; pp. 35–40. [Google Scholar]
- Meyer, B.T.; Kollmeier, B.; Ooster, J. Autonomous measurement of speech intelligibility utilizing automatic speech recognition. Proc. Interspeech 2015, 2015, 2982–2986. [Google Scholar]
- Yilmaz, E.; Pelemans, J.; Lievens, S. Speech reception threshold measurement using automatic speech recognition. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 1–4. [Google Scholar]
- Ooster, J.; Huber, R.; Kollmeier, B.; Meyer, B.T. Evaluation of an automated speech-controlled listening test with spontaneous and read responses. Speech Commun. 2018, 98, 85–94. [Google Scholar] [CrossRef]
- Van Zyl, M.; Swanepoel, D.W.; Myburgh, H.C. Modernising speech audiometry: Using a smartphone application to test word recognition. Int. J. Audiol. 2018, 57, 561–569. [Google Scholar] [CrossRef] [PubMed]
- Smits, C.; Kapteyn, T.S.; Houtgast, T. Development and validation of an automatic speech-in-noise screening test by telephone. Int. J. Audiol. 2004, 43, 15–28. [Google Scholar] [CrossRef] [PubMed]
- Dewyer, N.A.; Jiradejvong, P.; Henderson Sabes, J.; Limb, C.J. Automated smartphone audiometry: Validation of a word recognition test app. Laryngoscope 2018, 128, 707–712. [Google Scholar] [CrossRef]
- Pragt, L.; van Hengel, P.; Grob, D.; Wasmann, J.W.A. Preliminary evaluation of automated speech recognition apps for the hearing impaired and deaf. Front. Digit. Health 2022, 4, 806076. [Google Scholar] [CrossRef]
- Whitton, J.P.; Hancock, K.E.; Shannon, J.M.; Polley, D.B. Validation of a self-administered audiometry application: An equivalence study. Laryngoscope 2016, 126, 2382–2388. [Google Scholar] [CrossRef]
- Ooster, J.; Krueger, M.; Bach, J.H.; Wagener, K.C.; Kollmeier, B.; Meyer, B.T. Speech audiometry at home: Automated listening tests via smart speakers with normal-hearing and hearing-impaired listeners. Trends Hear. 2020, 24, 2331216520970011. [Google Scholar] [CrossRef] [PubMed]
- Smits, C.; Theo Goverts, S.; Festen, J.M. The digits-in-noise test: Assessing auditory speech recognition abilities in noise. J. Acoust. Soc. Am. 2013, 133, 1693–1706. [Google Scholar] [CrossRef] [PubMed]
- Ooster, J.; Tuschen, L.; Meyer, B.T. Self-conducted speech audiometry using automatic speech recognition: Simulation results for listeners with hearing loss. Comput. Speech Lang. 2023, 78, 101447. [Google Scholar] [CrossRef]
- Araiza-Illan, G.; Meyer, L.; Truong, K.P.; Başkent, D. Automated speech audiometry: Can it work using open-source pre-trained Kaldi-NL automatic speech recognition? Trends Hear. 2024, 28, 23312165241229057. [Google Scholar] [CrossRef]
- Stichting Open Spraaktechnologie. Kaldi NL. 2022. Available online: https://github.com/opensource-spraakherkenning-nl/Kaldi_NL (accessed on 1 January 2025).
- Fatehifar, M.; Schlittenlacher, J.; Almufarrij, I.; Wong, D.; Cootes, T.; Munro, K.J. Applications of automatic speech recognition and text-to-speech technologies for hearing assessment: A scoping review. Int. J. Audiol. 2024, 12, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Lafon, J.C. Phonetic test, phonation, audition. JFORL J. Fr. D’oto-Rhino-Laryngol. Audiophonol. Chir. Maxillo-Faciale 1972, 21, 223–229. [Google Scholar]
- Dodelé, L. La Mesure du Seuil D’inconfort. Phonak Focus: Bruxelles, Belgium, 1992. [Google Scholar]
- Dodelé, L.; Dodelé, D. L’audiométrie vocale en présence de bruit et filetest AVfB. Cah. L’audition 2000, 13, 15–22. [Google Scholar]
- Wallaert, N.; Perry, A.; Quarino, S.; Jean, H.; Creff, G.; Godey, B.; Paraouty, N. Performance and reliability evaluation of an improved machine learning-based pure-tone audiometry with automated masking. In World Journal of Otorhinolaryngology-Head and Neck Surgery; Wiley: Hoboken, NJ, USA, 2024. [Google Scholar]
- Wallaert, N.; Perry, A.; Quarino, S.; Jean, H.; Creff, G.; Godey, B.; Paraouty, N. Performance and reliability evaluation of an automated bone-conduction audiometry using machine-learning. Trends Hear. 2024, 28, 23312165241286456. [Google Scholar] [CrossRef]
- Baevski, A.; Zhou, Y.; Mohamed, A.; Auli, M. Wav2vec 2.0: A framework for self-supervised learning of speech representations. Adv. Neural Inf. Process. Syst. 2020, 33, 12449–12460. [Google Scholar]
- Devlin, J. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Billings, C.J.; Penman, T.M.; Ellis, E.M.; Baltzell, L.S.; McMillan, G.P. Phoneme and word scoring in speech-in-noise audiometry. Am. J. Audiol. 2016, 25, 75–83. [Google Scholar] [CrossRef] [PubMed]
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PE, USA, 25–29 June 2006; pp. 369–376. [Google Scholar]
- American National Standards Institute. Methods for Manual Pure-Tone Threshold Audiometry; Standards Secretariat, Acoustical Society of America: New York, NY, USA, 2004; Volume S3, p. 21. [Google Scholar]
- Société Française d’Audiologie. Guide des Bonnes Pratiques en Audiométrie de L’adulte; Société Française d’Audiologie: Rue Lalo, Paris, 2006. [Google Scholar]
- Kaernbach, C. Simple adaptive testing with the weighted up-down method. Percept Psychophys. 1991, 49, 227–229. [Google Scholar] [CrossRef] [PubMed]
- Bureau International d’AudioPhonologie (BIAP). 02/1 Bis: Audiometric Classification of Hearing Impairments. 1996. Available online: https://www.biap.org/es/recommandations/recommendations/tc-02-classification/213-rec-02-1-en-audiometric-classification-of-hearing-impairments/file (accessed on 1 January 2025).
- Jelassi, M.; Jemai, O.; Demongeot, J. Revolutionizing Radiological Analysis: The Future of French Language Automatic Speech Recognition in Healthcare. Diagnostics 2024, 14, 895. [Google Scholar] [CrossRef]
- Gutz, S.E.; Maffei, M.F.; Green, J.R. Feedback from Automatic Speech Recognition to Elicit Clear Speech in Healthy Speakers. Am. J. Speech-Lang. Pathol. 2023, 32, 2940–2959. [Google Scholar] [CrossRef]
- Fontan, L.; Cretin-Maitenaz, T.; Füllgrabe, C. Predicting speech perception in older listeners with sensorineural hearing loss using automatic speech recognition. Trends Hear. 2020, 24, 2331216520914769. [Google Scholar] [CrossRef]
- Carney, E.; Schlauch, R.S. Critical difference table for word recognition testing derived using computer simulation. J. Speech Lang. Hear. Res. 2007, 50, 1203–1209. [Google Scholar] [CrossRef] [PubMed]
- Margolis, R.H.; Wilson, R.H. Evaluation of binomial distribution estimates of confidence intervals of speech-recognition test scores. J. Acoust. Soc. Am. 2022, 152, 1404–1415. [Google Scholar] [CrossRef] [PubMed]
- Mueller, H.G. Speech audiometry and hearing aid fittings: Going steady or casual acquaintances? Hear. J. 2001, 54, 19–29. [Google Scholar] [CrossRef]
- Peng, Z.E.; Wang, L.M. Effects of noise, reverberation and foreign accent on native and non-native listeners’ performance of English speech comprehension. J. Acoust. Soc. Am. 2016, 139, 2772–2783. [Google Scholar] [CrossRef]
- Soltoggio, A.; Stanley, K.O.; Risi, S. Born to learn: The inspiration, progress, and future of evolved plastic artificial neural networks. Neural Netw. 2018, 108, 48–67. [Google Scholar] [CrossRef] [PubMed]
- Zador, A.M. A Critique of pure learning and what artificial neural networks can learn from animal brains. Nat. Commun. 2019, 10, 3770. [Google Scholar] [CrossRef] [PubMed]
- Seung, S. Connectome: How the Brain’s Wiring Makes Us Who We Are; Houghton Mifflin Harcourt: Boston, MA, USA, 2012. [Google Scholar]
- Fan, Z.; Li, M.; Zhou, S.; Xu, B. Exploring wav2vec 2.0 on speaker verification and language identification. arXiv 2020, arXiv:2012.06185. [Google Scholar]
- Frank, S.L.; Monaghan, P.; Tsoukala, C. Neural network models of language acquisition and processing. In Human Language: From Genes and Brain to Behavior; MIT Press: Cambridge, MA, USA, 2019; pp. 277–293. [Google Scholar]
- Hulme, C.; Hatcher, P.J.; Nation, K.; Brown, A.; Adams, J.; Stuart, G. Phoneme awareness is a better predictor of early reading skill than onset-rime awareness. J. Exp. Child Psychol. 2002, 82, 2–28. [Google Scholar] [CrossRef] [PubMed]
- Brown, T.H.; Kairiss, E.W.; Keenan, C.L. Hebbian synapses: Biophysical mechanisms and algorithms. Annu. Rev. Neurosci. 1990, 13, 475–511. [Google Scholar] [CrossRef] [PubMed]
- Bliss, T.; Fregnac, Y. Synaptic plasticity and cellular mechanisms of memory: An overview. J. Physiol. -Paris 1996, 90, 295–298. [Google Scholar] [CrossRef]
- Takehara-Nishiuchi, K. Neuronal ensemble dynamics in associative learning. Curr. Opin. Neurobiol. 2022, 73, 102530. [Google Scholar] [CrossRef] [PubMed]
- Halvagal, M.S.; Zenke, F. The combination of Hebbian and predictive plasticity learns invariant object representations in deep sensory networks. Nat. Neurosci. 2023, 26, 1906–1915. [Google Scholar] [CrossRef] [PubMed]
- Zhang, T.; Mustiere, F.; Micheyl, C. Intelligent hearing aids: The next revolution. In Proceedings of the 2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 16–20 August 2016; IEEE: Piscataway, NJ, USA, 2023; pp. 72–76. [Google Scholar]
- Andersen, A.H.; Santurette, S.; Pedersen, M.S.; Alickovic, E.; Fiedler, L.; Jensen, J.; Behrens, T. Creating clarity in noisy environments by using deep learning in hearing aids. In Seminars in Hearing; Thieme Medical Publishers, Inc.: New York, NY, USA, 2021; Volume 42, pp. 260–281. [Google Scholar]
- Beck, D. Hearing, listening and deep neural networks in hearing aids. J. Otolaryngol. ENT Res. 2021, 13, 5–8. [Google Scholar] [CrossRef]
- Raufer, S.; Kohlbauer, P.; Uhlemayr, F.; Kuhnel, V.; Preuss, M.; Hobi, S. Spheric Speech Clarity proven to outperform key competitors for clear speech in noise. 2024. Available online: https://www.phonak.com/evidence (accessed on 1 January 2025).
- Frosolini, A.; Franz, L.; Caragli, V.; Genovese, E.; de Filippis, C.; Marioni, G. Artificial Intelligence in Audiology: A Scoping Review of Current Applications and Future Directions. Sensors 2024, 24, 7126. [Google Scholar] [CrossRef] [PubMed]
- Leder, S.B.; Spitzer, J.B. A perceptual evaluation of the speech of adventitiously deaf adult males. Ear Hear. 1990, 11, 169–175. [Google Scholar] [CrossRef] [PubMed]
- Vipperla, R.; Renals, S.; Frankel, J. Longitudinal study of ASR performance on ageing voices. In Proceedings of the Annual Conference of the International Speech Communication Association, Brisbane, Australia, 22–26 September 2008; Interspeech: Dublin, Ireland, 2008; pp. 2550–2553. [Google Scholar]
- Moore, M.; Venkateswara, H.; Panchanathan, S. Whistle-Blowing ASRs: Evaluating the Need for More Inclusive Speech Recognition Systems; Interspeech: Dublin, Ireland, 2018. [Google Scholar]
- Gonçalves Braz, L.; Fontan, L.; Pinquier, J.; Stone, M.A.; Füllgrabe, C. OPRA-RS: A hearing-aid fitting method based on automatic speech recognition and random search. Front. Neurosci. 2022, 16, 779048. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Automated vs. Manual Scoring (Number of Ears Tested for Each Comparison) | Raw Differences (%) | Absolute Differences (%) | Post Hoc Comparisons (p-Value) |
|---|---|---|---|
| Lafon’s Cochlear List 1 (n = 58 ears) | 3.09 ± 15.52 | 8.40 ± 13.37 | 0.601 |
| List 2 (n = 59 ears) | 1.98 ± 16.01 | 9.24 ± 13.17 | 0.728 |
| List 3 (n = 61 ears) | 0.05 ± 8.90 | 4.34 ± 7.75 | 0.993 |
| List 4 (n = 63 ears) | 2.78 ± 6.92 | 4.30 ± 6.07 | 0.676 |
| List 5 (n = 66 ears) | 0.74 ± 7.27 | 4.35 ± 5.85 | 0.908 |
| List 6 (n = 67 ears) | −1.03 ± 7.43 | 4.31 ± 6.12 | 0.869 |
| List 7 (n = 61 ears) | 1.21 ± 6.70 | 5.05 ± 4.53 | 0.812 |
| List 8 (n = 67 ears) | −1.65 ± 12.65 | 6.60 ± 10.89 | 0.766 |
| List 9 (n = 27 ears) | 0.48 ± 8.37 | 5.00 ± 6.66 | 0.891 |
| List 10 (n = 70 ears) | 2.16 ± 16.82 | 6.49 ± 15.64 | 0.448 |
| List 11 (n = 69 ears) | −1.21 ± 11.75 | 6.31 ± 9.95 | 0.985 |
| List 12 (n = 65 ears) | −1.94 ± 9.77 | 5.66 ± 8.17 | 0.755 |
| List 13 (n = 66 ears) | −2.38 ± 12.34 | 6.48 ± 10.74 | 0.645 |
| List 14 (n = 62 ears) | 1.06 ± 15.75 | 7.45 ± 13.88 | 0.853 |
| List 15 (n = 64 ears) | 0.06 ± 7.25 | 4.59 ± 5.58 | 0.992 |
| List 16 (n = 61 ears) | −4.23 ± 13.97 | 7.54 ± 12.47 | 0.474 |
| List 17 (n = 62 ears) | −2.47 ± 11.79 | 6.47 ± 10.13 | 0.669 |
| List 18 (n = 62 ears) | 0.56 ± 16.18 | 7.64 ± 14.24 | 0.917 |
| List 19 (n = 61 ears) | −0.75 ± 9.27 | 6.44 ± 6.65 | 0.910 |
| List 20 (n = 58 ears) | −0.14 ± 13.97 | 7.79 ± 11.55 | 0.557 |
| All lists | −0.12 ± 12.03 | 6.22 ± 10.30 | 0.366 |
| Automated vs. Manual Scoring | Raw Difference (%) | Absolute Difference (%) |
|---|---|---|
| Normal hearing (NH) n = 37 ears | 0.93 ± 6.44 | 4.13 ± 5.02 |
| Hearing impaired (HI) n = 181 ears | −0.91 ± 9.88 | 5.57 ± 8.01 |
| Difference in Score of Given Word# Compared to Score for Word #17 (mean ± 1 std) | Absolute Differences (%) (per Ear Average) | Absolute Differences (%) (per List Average) |
|---|---|---|
| First word of given list: word #1 | 23.88 ± 7.02 | 24.19 ± 4.84 |
| word #2 | 15.24 ± 4.75 | 15.40 ± 2.18 |
| word #3 | 11.58 ± 3.81 | 11.63 ± 1.62 |
| word #4 | 9.66 ± 3.47 | 9.68 ± 1.82 |
| word #5 | 7.96 ± 2.83 | 8.02 ± 1.32 |
| word #6 | 6.99 ± 2.51 | 7.09 ± 1.03 |
| word #7 | 6.29 ± 2.56 | 6.38 ± 1.33 |
| word #8 | 5.75 ± 2.30 | 5.87 ± 0.92 |
| word #9 | 5.06 ± 1.91 | 5.17 ± 0.89 |
| word #10 | 4.50 ± 1.67 | 4.59 ± 0.60 |
| word #11 | 3.96 ± 1.48 | 4.05 ± 0.46 |
| word #12 | 3.42 ± 1.25 | 3.47 ± 0.36 |
| word #13 | 2.80 ± 1.00 | 2.86 ± 0.42 |
| word #14 | 2.21 ± 0.86 | 2.29 ± 0.58 |
| word #15 | 1.67 ± 0.68 | 1.67 ± 0.36 |
| word #16 | 1.13 ± 0.59 | 1.11 ± 0.18 |
| Last word of given list: word #17 | 0 | 0 |
| Test vs. Retest (n = 40 Ears) | Raw Differences | Absolute Differences | |
|---|---|---|---|
| Manual Scoring | All words tested (%) | −2.20 ± 13.03 | 8.31 ± 10.23 |
| 50% intelligibility score (dB) | −3.72 ± 15.81 | 5.95 ± 15.08 | |
| Maximum intelligibility score (%) | −2.00 ± 7.68 | 4.00 ± 6.81 | |
| Automated Scoring | All words tested (%) | −4.08 ± 17.22 | 10.05 ± 14.53 |
| 50% intelligibility score (dB) | 0.29 ± 6.06 | 3.44 ± 4.29 | |
| Maximum intelligibility score (%) | −1.94 ± 6.51 | 4.05 ± 5.40 | |
| Automated vs. Manual Scoring (All Subjects Tested for Each Comparison, n = 185) | Raw Differences (%) | Absolute Differences (%) | Post Hoc Comparisons (p-Value) |
|---|---|---|---|
| Dodelé Logatoms, List 1 (n = 185 subjects) | −1.09 ± 9.30 | 5.04 ± 7.87 | 0.225 |
| List 2 | −4.34 ± 11.14 | 9.18 ± 9.89 | 0.505 |
| List 3 | −6.51 ± 9.75 | 8.90 ± 7.57 | 0.055 |
| List 4 | −3.98 ± 10.27 | 7.62 ± 7.91 | 0.222 |
| List 5 | 2.98 ± 6.51 | 5.20 ± 4.87 | 0.297 |
| Automated vs. Manual Scoring | Raw Difference (%) | Absolute Difference (%) |
|---|---|---|
| Normal hearing (NH) n = 85 subjects | −3.50 ± 10.83 | 7.26 ± 8.76 |
| Hearing impaired (HI) n = 100 subjects | −1.56 ± 9.30 | 6.20 ± 7.09 |
| Difference in Score of Given Word# Compared to Score for Word #17 (mean ± std) | Absolute Differences (%) (per Ear Average) | Absolute Differences (%) (per List Average) |
|---|---|---|
| First word of given list: word #1 | 29.45 ± 11.40 | 21.28 ± 0.74 |
| word #2 | 16.15 ± 6.78 | 15.33 ± 1.18 |
| word #3 | 11.49 ± 4.72 | 13.07 ± 1.09 |
| word #4 | 9.69 ± 4.20 | 11.27 ± 1.12 |
| word #5 | 8.18 ± 3.72 | 9.76 ± 1.29 |
| word #6 | 7.11 ± 3.18 | 8.74 ± 0.81 |
| word #7 | 6.37 ± 2.79 | 7.28 ± 0.64 |
| word #8 | 5.32 ± 2.50 | 6.37 ± 0.50 |
| word #9 | 4.60 ± 2.16 | 5.59 ± 0.28 |
| word #10 | 4.08 ± 2.04 | 4.91 ± 0.62 |
| word #11 | 3.62 ± 1.80 | 4.02 ± 0.52 |
| word #12 | 2.83 ± 1.46 | 3.54 ± 0.42 |
| word #13 | 2.52 ± 1.11 | 2.91 ± 0.36 |
| word #14 | 1.95 ± 0.92 | 2.21 ± 0.32 |
| word #15 | 1.59 ± 0.71 | 1.59 ± 0.26 |
| word #16 | 0.94 ± 0.38 | 1.35 ± 0.44 |
| Last word of given list: word #17 | 0 | 0 |
| Test vs. Retest (n = 111 Subjects) | Raw Differences | Absolute Differences | |
|---|---|---|---|
| Manual Scoring | All words tested (%) | 2.61 ± 9.03 | 5.94 ± 7.28 |
| 50% intelligibility score (dB SNR) | −0.71 ± 1.37 | 1.18 ± 0.99 | |
| Maximum intelligibility score (%) | 1.33 ± 2.23 | 1.89 ± 1.75 | |
| Automated Scoring | All words tested (%) | 1.81 ± 11.53 | 8.06 ± 8.45 |
| 50% intelligibility score (dB SNR) | −0.64 ± 1.85 | 1.51 ± 1.25 | |
| Maximum intelligibility score (%) | −2.06 ± 5.69 | 2.94 ± 4.51 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jean, H.; Wallaert, N.; Dreumont, A.; Creff, G.; Godey, B.; Paraouty, N. Automating Speech Audiometry in Quiet and in Noise Using a Deep Neural Network. Biology 2025, 14, 191. https://doi.org/10.3390/biology14020191
Jean H, Wallaert N, Dreumont A, Creff G, Godey B, Paraouty N. Automating Speech Audiometry in Quiet and in Noise Using a Deep Neural Network. Biology. 2025; 14(2):191. https://doi.org/10.3390/biology14020191
Chicago/Turabian StyleJean, Hadrien, Nicolas Wallaert, Antoine Dreumont, Gwenaelle Creff, Benoit Godey, and Nihaad Paraouty. 2025. "Automating Speech Audiometry in Quiet and in Noise Using a Deep Neural Network" Biology 14, no. 2: 191. https://doi.org/10.3390/biology14020191
APA StyleJean, H., Wallaert, N., Dreumont, A., Creff, G., Godey, B., & Paraouty, N. (2025). Automating Speech Audiometry in Quiet and in Noise Using a Deep Neural Network. Biology, 14(2), 191. https://doi.org/10.3390/biology14020191