Abstract
D number theory removes the constraints of mutual exclusion and completeness in the frame of discernment of DS evidence theory, and is therefore widely used to deal with uncertain and incomplete information. EDAS (evaluation based on distance from average solution) selects the optimal solution according to the distance from each solution to the average. This method is very suitable for solving issues of multiple attribute decision making (MADM) with conflicting attributes. In this study, we propose an evaluation method that combines D numbers with the EDAS method. D number theory is used to express the evaluation of the alternatives for experts. Then, we use the SCRI (stepwise comparison and replacement integration) method of D numbers for data integration, and finally the EDAS method is used to select the optimal one by sorting the alternatives. We apply this method to address the user experience evaluation problems of platforms that offer online live courses and compare the evaluation results with other methods to verify the applicability and practicability of the method.
1. Introduction
Multiple attribute decision making (MADM) is an important part of modern decision science. In the decision-making process, most MADMs are uncertain types due to the uncertainty of decision-making information and the limitations of decision-makers’ cognitive abilities. The main research methods include: grey correlation analysis [1], Dempster–Shafer evidence theory (DS evidence theory) [2,3,4], fuzzy set theory [5,6,7] and rough set theory [8,9,10], etc. Among them, DS evidence theory can deal with uncertain information more effectively than other methods, and overcome the shortcomings of classical probability theory in uncertainty modeling such as belief expression and subjective cognition, thus has been widely used. D number theory [11] is an extension of DS evidence theory. It removes the constraints of mutual exclusivity and completeness in the framework of discernment of evidence theory and fits a more general framework than DS evidence theory. When faced with actual decision-making problems, the form of language level is more favored by decision-makers, because it is closer to human language habits, so the multi-attribute decision-making problem based on language evaluation has also attracted much attention. However, the traditional language evaluation implies that the confidence of each language value is 1, which cannot describe the degree of hesitation of the evaluator. In addition, in life many semantic evaluation levels such as “very good”, “good”, “average”, “poor” and “very poor” overlap with each other, and evaluators are often forced to make choices in fields they are not familiar with, resulting in distorted evaluation results. The application of D number theory allows evaluators to make choices according to their actual situation when obtaining expert information, or even choose to abstain, which preserves the authenticity of language evaluation to the greatest extent. Therefore, the use of D number theory for language decision-making has significant advantages.
In recent years, some scholars have done a lot of research into D number theory. For example, Guan et al. [12] proposed a new combination rule for the problem that the combination rules had failed to satisfy the associativity; regarding the use of language terms as the evaluation set of D numbers, Xiao [13] proposed an MADM model based on D numbers and linguistic variables, namely a linguistic D numbers model. Seiti et al. [14] extended linguistic D numbers to an interval-valued belief structure. Mo and Deng [15] proposed a new method to deal with a MADA problem under both probabilistic and fuzzy uncertainties based on D numbers. In response to semantic intersection data, the distance between two D numbers is defined according to the distance definition between two BPAs in DS evidence theory, so that under the same frame of discernment, the distance of D numbers is smaller than that of DS evidence theory [16]. Regarding the reliability of D numbers, Xia et al. [17] designed an entropy function of D numbers, and based on this, they proposed a reliability index of D numbers. To deal with the conversion issue between D numbers and real numbers, Deng [11] proposed a D numbers integration representation, which can convert a D number into a real number. However, if the information is incomplete, the method will simply ignore the missing part of the evaluation, and the result may go against common sense. To remedy this shortcoming, Wang et al. [18] proposed an improved D numbers integration method, which proportionally assigns missing information to the decision-making according to the original value of D numbers, but this method does not consider the evaluation objects in a large image, thus leading to a counter-intuitive result as well. Hou and Zhao [19] proposed a new D numbers integration method updated from Wang et al. [18], which horizontally compares the data of multiple evaluation projects and can fill in the missing information properly.
D numbers can also be combined with other MADM classic methods to deal with decision-making problems in uncertain environments. We summarize the relevant literature in Table 1. (The abbreviations used for the first time in the table: AHP (analytic hierarchy process), VIKOR (Vlsekriterijumska Optimizacija I Kompromisno Resenje method), TOPSIS (technique for order preference by similarity to ideal solution), TODIM (an acronym in Portuguese for interactive and multi-criteria decision making), the best–worst method (BWM), COPRAS (complex proportional assessment), WASPAS (weighted aggregates sum product assessment), FAHP (fuzzy analytic hierarchy process), BM (Bonferroni mean) operator, DNMA (double normalization-based multiple aggregation), CRITIC (criteria importance through inter-criteria correlation), MABAC (multi-attributive border approximation area comparison), SWOT (strengths–weaknesses–opportunities–threats), POWA (power ordered weighted averaging))

Table 1.
The review of the D numbers be combined with other MADM classic methods.
Keshavarz Ghorabaee et al. [38] proposed the EDAS method and studied the problems of multi-criteria inventory classification. Keshavarz Ghorabaee et al. [39] extended the EDAS approach to a fuzzy information environment and illustrated the applicability of the proposed approach with a case study of supplier selection. Keshavarz Ghorabaee et al. [40] proposed a stochastic extension of the EDAS method to handle MCDM problems with normally distributed data. In recent years, many scholars have extended the EDAS method to different information environments and combined it with other MCDM classical methods to solve problems in different fields, such as the supplier selection problem in the environment of interval type-2 fuzzy sets [41]; the construction contractor selection problem in the interval grey numbers environment [42]; combining with the fuzzy AHP method to solve a third-party logistics provider selection problem [43]; prioritization of sustainable development goals in an interval-valued neutrosophic environment [44]; evaluation of autonomous vehicles under Minkowski space [45]; combined with the MULTIMOORA approach to address a renewable energy adoption problem [46]; green supplier selection in the context of the probabilistic linguistic term sets (PLTSs) [47], and so on.
However, there is still much room to research into the EDAS model. The D numbers method has an advantage in collecting expert opinions, while the EDAS method does well in the selection of solutions with conflicting attributes. In the process of solving a multi-stage evaluation problem, we can comprehensively adopt advantageous methods in various phases to select the optimal solution for the problem. In the process of evaluating the user experience of the online live course platform, we found that the evaluation attributes are qualitative indicators with ambiguity and uncertainty, and it is difficult to carry out quantitative analysis. D numbers have certain advantages in dealing with uncertain information and individual preferences, and combined with the SCRI method, the incomplete evaluation information can also be quantified. At the same time, there is a certain conflict between the multi-criteria of online live courses. Compared with the common multi-attribute decision-making method, the EDAS method is more suitable for dealing with multi-attribute problems with conflict. Therefore, this paper attempts to evaluate the user experience of the online live course platform based on D number theory combined with the EDAS method.
Fan et al. [37] proposed an evaluation method that combines D numbers with BWM and the EDAS method to solve the problem of selecting battery suppliers for new energy vehicles. Firstly, in order to express the uncertainty of expert decision-making, D numbers are used to describe the evaluation information. Then the BWM method is applied to determine the weight of a given criterion, and finally the EDAS method is applied to rank the battery suppliers of new energy vehicles. We note that in the first stage of obtaining expert information, this method represents each expert’s opinion as a D number, and then applies the D number combination method proposed by Xiao [13] to obtain the comprehensive evaluation D number of each criterion, and then transforms each D number into a real number according to the integration method of Deng [11]. In the above-mentioned D number combination and integration process, the evaluation information will be distorted and discarded. When the number of experts is relatively large, after several D number combinations, the final comprehensive evaluation value may no longer effectively reflect the actual situation. For the evaluation problem that requires a large number of experts, this paper proposes another way of thinking. We use the form of language grading to let each expert choose the most suitable grade for each criterion of the alternative. If individual experts cannot give a choice for some reason, they are also allowed to abstain. After the evaluation, the choices of all experts will be converted into D number form. This D number form may be incomplete information. In order to avoid the loss of information as much as possible, we use the SCRI method of D numbers for data integration, and finally use the EDAS method to sort and evaluate the obtained real number evaluation results.
The structure of this paper is organized as follows: Section 2 briefly reviews the relevant definitions of DS evidence theory and D numbers. Section 3 gives the idea and calculation steps of the D–SCRI–EDAS method. Section 4 presents a specific case of user experience evaluation in the platform that offers online live broadcast courses to verify the feasibility of the proposed method. Section 5 presents the conclusion.
2. Preliminaries
2.1. Dempster–Shafer Theory
DS evidence theory is a numerical reasoning method for evidence reasoning. It was first proposed by Dempster in 1967 and later popularized by Shafer in 1976, hence named as Dempster–Shafer evidence theory. The essence of DS evidence theory is a generalization of classical probability theory. It expands the basic event space in probability theory into the power set space, and then establishes a basic probability assignment function to overcome the flaws of classical probability theory in uncertainty modeling such as incomprehensibility, subjective cognition, and so on. In addition, DS evidence theory also provides Dempster fusion rules for information fusion, which features a simple fusion algorithm structure and high fusion accuracy, and obeys the commutative and associative laws.
Definition 1.
Refs. [2,3] (basic probability assignment, BPA) Let be a nonempty finite set of hypotheses or propositions, which is called the frame of discernment. A basic probability assignment (BPA) is a function , which is called a mass function, satisfying:
whereis an empty set andis the power set of.
Shafer interprets the basic probability assignment function as a subjective representation of evidence, that is, the degree of trust in Proposition A represents the degree of support for it. The advantage of DS evidence theory’s BPA is that uncertainty is directly expressed by assigning basic probability numbers to subsets that consist of n objects rather than individual objects. is regarded as a focal element when , and the union of all focal elements is called the core of the mass function.
Definition 2.
Refs. [2,3] (Dempster’s combination rule) Suppose and are two independent BPAs from different sources, the Dempster combination rule, denoted by , is defined as follows:
With
whereis a normalization constant, called the conflict coefficient of two BPAs. When, it means thatandcompletely conflict, and they cannot be combined by Dempster’s combination rule.
2.2. D Number Theory
DS theory expands the basic event space in probability theory into the power-set space. Compared with traditional probability theory, DS evidence theory not only effectively expresses random uncertainty, but also illustrates incomplete information and subjective uncertainty information. However, some premises and strict constraints of DS evidence theory have caused DS evidence theory to be greatly restricted when dealing with fuzzy and uncertain information: First, the frame of discernment must be a mutually exclusive set, that is, the elements in the frame must be mutually exclusive, and it is often difficult to meet these conditions in the language environment of fuzzy evaluation, such as “satisfied”, “very satisfied”, “extremely satisfied”, all of which are personal discourses that are evaluated according to their very own set of reference objects. Therefore, it will inevitably contain many fuzzy areas that intersect with each other, meaning the mutual exclusivity of elements cannot be guaranteed. Second, in general, the use of BPA is subject to completeness, that is, the sum of the reliability of all focal elements must be equal to 1 (), which is difficult to satisfy in reality. As many evaluations and assessments are based on partial information, a complete BPA may not be obtained.
Deng improved the evidence theory to obtain D number theory [11] that overcomes the defects of DS evidence theory and expands the scope of application, so that D number theory can also be used in fuzzy contexts and under the condition that completeness constraints are not satisfied. D number theory is defined as follows:
Definition 3.
Ref. [11] Let be a finite nonempty set, D number is a mapping , such that
whereis an empty set andis a subset of. Note that, different from the concept of frame of discernment in Dempster–Shafer theory, in setthe elements do not require mutual exclusivity.
There is a special situation of D numbers.
Definition 4.
Ref. [11] For a discrete set , where (), and if , a special form of D numbers can be expressed by
Simple notes for , where and . If , the information is said to be complete; If , the information is said to be incomplete.
Definition 5.
Ref. [11] (D number theory combination rule) Suppose and are two D numbers, denoted by
The combination of and , indicated by , is defined by
Definition 6.
Ref. [11] (D numbers’ Integration) Let be a D number, the integration representation of D is defined as
whereis real number.
Example 1.
Suppose there is a D number: , then .
3. Proposed Method
In this section, we propose the D–SCRI–EDAS method, which takes into account incomplete information. D–SCRI method [19] is a new method proposed in 2021. This method can effectively avoid the problem of information distortion in the process of multiple combination and integration of D numbers, and solves the problem when multiple experts evaluate an evaluation object and some experts are unable to give accurate evaluation of all criteria due to the lack of knowledge and information, which leads to the problem of missing information, so D–SCRI is selected for expert opinion integration. In the process of program evaluation information integration, because the evaluation criteria of the program have certain conflicts, the EDAS method, which is effective for conflicting multi-attribute decision-making, is used for integration.
3.1. D Numbers Stepwise Comparison and Replacement Integration (SCRI) Method
In view of the incomplete information in the D numbers integration process, Wang et al. [18] put forward an improved D numbers integration method, but its result was biased due to the fact that the evaluation object was not considered globally. Based on Wang et al. [18], Hou and Zhao [19] proposed a SCRI integration method that not only considered the evaluation results of individual project, but also analyzed them horizontally with those of other projects. It can handle missing information in a more reasonable way, which is more efficient than previous integration methods. In this article, in order to supplement the D numbers of incomplete information into one with complete information, we have slightly modified the SCRI method and rephrased it as follows:
Suppose there are M Objects to be evaluated, and K experts are participating in the evaluation.
Step 1, As for the Object , sort the evaluation level from each expert in descending order, and record the non-evaluation ones as 0, that is to say, the evaluation results of the experts on the Object are arranged as a row vector in descending order, which constitutes the original evaluation matrix with the order ;
Step 2, observe whether there is a column in which elements are all 0. If so, go to step 3, otherwise, jump to step 4;
Step 3, Starting from the first column, check in turn whether element 0 emerges in any column. Here let us assume that 0 appears in the s + 1 column for the first time, that is, the elements corresponding to the previous s columns are initial integration value calculated from confirmed evaluations made by the experts, then the previous column elements in each row are added, and then average it, that is, the sum of each row is divided by s, which is called the basic evaluation reference value. As for the columns where all the column elements are 0, replace the 0 elements in this column with the basic evaluation reference value of the corresponding row. This is also equivalent to distributing this part of incomplete information proportionally to the results of the evaluation that have been clearly given in the preceding s columns.
Step 4, Check whether there is element 0 in each column. If yes, compare the non-zero elements of this column, and replace element 0 with the smallest value, That is to say, the incomplete information is replaced with the minimum evaluation value corresponding to the evaluation object through horizontal comparison, until all elements in the matrix are nonzero, which is called the modified integrated value matrix ;
Step 5, According to the integration value matrix , write the D numbers of the complete information, and then calculate the final integration value according to the integration formula (11).
Example 2.
Assume that 10 experts are invited to evaluate the performance of 3 alternatives (A, B, C), and also suppose the evaluation system as a set . When these 10 experts are evaluating the performance of A, 4 persons choose “9”, 2 persons choose “8”, 3 persons choose “7” and 1 person does not give any evaluation since he is unfamiliar with A. Thus, A’s evaluation is expressed as D numbers . When the same 10 experts are evaluating the performance of B, 3 of them choose “9”, 5 choose “8”, and 2 do not evaluate as they are not familiar with B, which is then expressed in the form of D numbers . When the same 10 experts are evaluating the performance of C, 4 choose “9” and 3 choose “8”, and 3 conduct no evaluations because they are not familiar with B, which is then expressed as in the form of D numbers .
Step 1, Build an original evaluation matrix R=
Step 2, Check whether there is a column whose column elements are all 0, where the last column is all 0, enter step 3;
Step 3, 0 appears in the eighth column for the first time, that is, the elements corresponding to the previous 7 columns are the interval integrated values calculated based on the clear evaluation given by the experts. Add the elements in each row of the first 7 columns, and then calculate the arithmetic mean, , , , respectively, and replace the last column element of the interval integrated value matrix with these values, thus:
Step 4, Check whether element 0 appears in each column. If there is, compare the non-zero elements of this column, and replace element 0 with the smallest value. In the eighth column, , replace 0 with 7, and in the ninth column, replace 0 with 7 to obtain the modified integrated value matrix :
Step 5, According to the modified integrated value matrix , write the D numbers of complete information. For example, there are four 9s, three 8s, two 7s, and one 60/7 in the third row of the matrix. We can convert this row into complete informative D numbers , and according to the Formula (11), the integrated value .
3.2. D–SCRI–EDAS Method
The EDAS method was raised by Keshavarz Ghorabaee et al. [37] in 2015 to solve the MADM problem with conflicting attributes. The method is to calculate the average solution of each solution, firstly, and then measure the difference between each solution and the average value, which will be recorded as either the positive distance from average or the negative distance from average. Generally speaking, the optimal solution is the one with the largest positive distance from the average and the smallest negative distance from the average. In this section, we propose the D–SCRI–EDAS method to solve the decision-making problem in the context of incomplete information D numbers. After obtaining the D numbers evaluation matrix of each scheme, use the SCRI method to convert all D numbers in the evaluation matrix into the form of complete information and obtain the integrated value, which is called the score value of each attribute in each scheme. Do an arithmetic mean of these scores to obtain the average score value of each attribute, and then calculate the positive distance and negative distance of each attribute of each scheme from the average score value, hence the weighted positive distance and negative distance of each scheme is obtained according to the weight of each attribute. Finally, sort the normalized score values and make the best choice.
Suppose there are m alternatives , n attributes and k experts . Let . be the attribute’s weighting vector which satisfy , and .
The D–SCRI–EDAS method works in the following seven steps:
Step 1. Construct the D numbers initial evaluation matrix ; of which represents the evaluation D numbers of the Attribute j of the Scheme i.
Step 2. Use the SCRI method to convert all the D numbers in the evaluation matrix into the form of complete information to obtain the D numbers matrix of complete information evaluation, and use the integrated Formula (11) to convert into a real number evaluation matrix ;
Step 3. Compute the value of average integration value matrix of the n attributes:
Step 4. Calculate the positive distance matrix and negative distance matrix according to Equations (13)–(16):
If jth attribute is beneficial type,
If jth attribute is cost type,
Step 5. Calculate the values of and which denotes the weighted sum of PDA and NDA, the computing formulae are provided as follows:
Step 6. The results of Equation (17) can be normalized as:
Step 7. Calculate the final evaluation score according to and The larger the value is, the better the alternative is.
The stepwise representation of the proposed method is given as follows. The flowchart of the proposed method is shown in Figure 1.
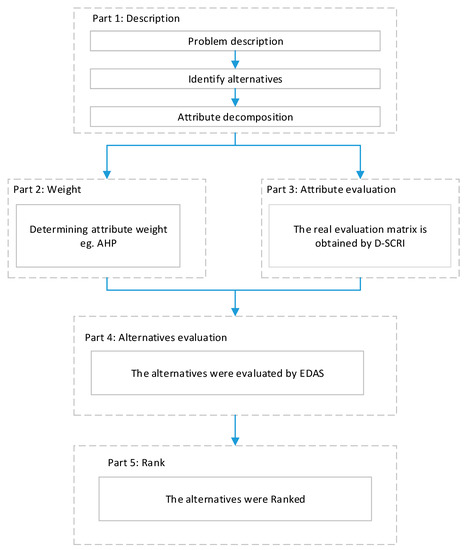
Figure 1.
The flowchart of the proposed method.
4. The Numerical Example and Comparative Analysis
4.1. A Numerical Example
During the rapid spreading time of COVID-19, online learning has emerged as a new way to prevent people from gathering and to contain the spread of the virus. Online live course platforms play an important role in online study, and they rely heavily on some remote office and conference software. However, these software cannot fully meet the needs of schools’ online live classes due to the original design purpose and the nature of the software. Because of this, the user experience evaluation and optimization of the online live course platform is particularly important [48,49]. For example, Wang et al. [49] adopted a combination of qualitative and quantitative methods, and from the perspective of user experience, integrated the data obtained through literature research, interviews, and network research to set evaluation indicators. Delphi method and AHP method are used to determine the weight of each index, and to set the rating scale. The t-test method is used to establish a comparative analysis method of model application, design a standardized process, and build a complete evaluation system. However, there is a major problem that is not well addressed in Wang et al. [49]: when evaluating different platforms, some experts may not be able to give clear ratings because they seldom know the rating items, and in such cases a reluctantly determined rating may greatly affect the final evaluation result. Instead, our proposed D numbers–SCRI method can solve this problem very well, and can deal with the uncertainty, ignorance and missing information that may occur, in a simple and effective way. In Wang et al. [49], the main factors affecting the user experience of the online live course platform are divided into four first-level indicators, namely ease of operation, functional completeness, interface rationality, and technical reliability. Each of the first-grade indicators can be divided into several secondary ones. The hierarchical structure and corresponding weights in the user experience evaluation of the online live course platform are given in Figure 2.
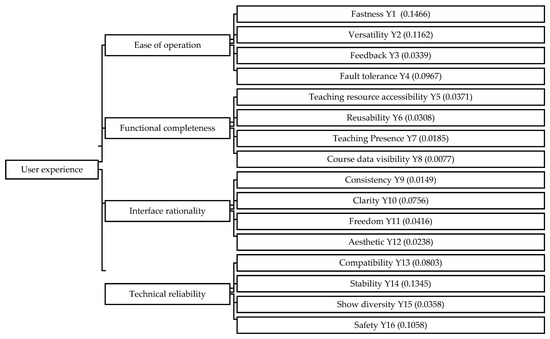
Figure 2.
Evaluation index system of the user experience of the online live course platform [49].
Step 1. Construct the initial D numbers initial evaluation matrix (see Table 2).
Table 2.
Assessment data for Ding Talk, Tencent Classroom and Tencent QQ are represented by D numbers.
Step 2. Use the SCRI method to convert all the D numbers in the evaluation matrix into the form of complete information to obtain the D numbers matrix of complete information evaluation (see Table 3), and convert into a real number evaluation matrix (see Table 4).
Table 3.
Assessment data for Ding Talk, Tencent Classroom and Tencent QQ are represented by complete information D numbers.
Table 4.
Integration of the assessment results.
Step 3. Compute the value of average integration value matrix of the n attributes (see Table 5).
Table 5.
Average integration value of each attribute.
Step 4. Because the attributes are both beneficial types, calculate the positive distance matrix and negative distance matrix according to Equations (13) and (14):
Step 5. Calculate the values of and (see Table 6) according to Equation (17).
Table 6.
WSP and WSN in three platforms.
Step 6. The results of Table 6 can be normalized as follows (see Table 7) according to Equation (18).
Table 7.
NWSP and NWSN in three platforms.
Step 7. Calculate the final evaluation score according to Equation (19). The larger the value is, the better the alternative is for the final evaluation score:
Thereby, we consider that object , in which the symbol ‘≫’ means ‘superior’. Hou and Zhao [19] used D numbers to collect evaluation information, and used the SCRI method to convert the evaluation information into real numbers to calculate the final evaluation scores of the three live broadcast platforms with the weight of each attribute considered. In order to compare it with the D–EDAS method in this paper, we normalized relevant scores by using the maximum normalization method and listed these in Table 8 and Figure 3.
Table 8.
Evaluation scores and normalized scores of the three platforms with two methods.
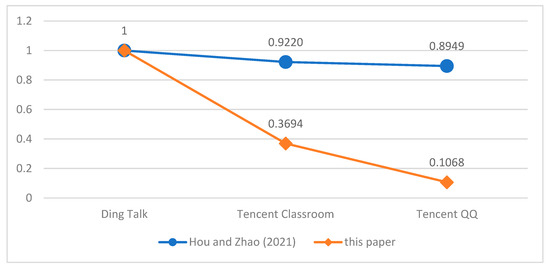
Figure 3.
Normalized scores of the three platforms in Hou and Zhao (2021) [19] and D-EDAS (this paper).
In order to verify the effectiveness of the method, we adopted the following means of sensitivity analysis: the weights of 16 basic attributes were randomly changed (see Table 9), the D–SCRI–EDAS method and the D–SCRI method proposed in [19] were, respectively, compared. The evaluation order of the two methods was the same, and the results obtained by the D–SCRI–EDAS method were more sensitive than those obtained by the D–SCRI method (see Table 10).
Table 9.
The weight of the evaluation attributes obtained randomly.
Table 10.
Normalized evaluation results after two weight adjustments.
As the gap between the ranks increases without changing the sort, it suggests that the second method is more sensitive to data differences and can handle more precise evaluation problems. This also indicates that the D–EDAS method is more effective than simply using D numbers in a MADM evaluation of incomplete information, showing more method advantages.
4.2. Comparative Analysis
Refs. [21,27] used the combination of D number theory and the VIKOR method to solve the problem of medicine provider selection. In this paper, the method is extended to D–SCRI–VIKOR method to evaluate the user experience of the online course live platform. In order to further demonstrate the effectiveness of the D–SCRI–EDAS method in dealing with multi-attribute decision-making problems, we compared and analyzed the evaluation results obtained by two methods.
The D–SCRI–VIKOR method is briefly described as follows:
Step 1~Step 2, The same as D–SCRI–EDAS method, a D-number evaluation matrix is transformed into a complete information D-number matrix, and then a real number evaluation matrix is obtained. In order to be consistent with the expression habits of the VIKOR method, the real number evaluation matrix is denoted as ;
Step 3, Identify the best values and worst values of each positive attribute by using Equations (20) and (21):
For the negative attribute, the indexes are computed using Equations (22) and (23):
Step 4, Let be the attribute’s weighting vector which satisfies , and . The and indexes are obtained for each alternative using Equations (24) and (25):
Step 5, The index is calculated for each alternative as in Equation (26):
where , indicates the strategy of maximum group utility.
Step 6, Rank the alternatives sorting by values S, R and Q in an ascending order.
Table 11.
The values of S, R and Q for each alternative.
Table 12.
The ascending ranks of the alternatives.
A compromise solution is obtained based on the three ranking lists, that is, Ding Talk Tencent Classroom Tencent QQ.
It can be seen from the results that the combination of D–SCRI and EDAS or VIKOR all obtain the same ranking result. However, the VIKOR method needs to comprehensively consider the comprehensive ranking results of the three indicators S, R and Q, especially when the ranking results of the three indicators are inconsistent; this may cause confusion in the comprehensive evaluation, and the VIKOR method requires a relatively large amount of calculation. Therefore, the combination of D–SCRI and EDAS has better applicability to the evaluation problems that require the participation of more evaluation experts and conflicting attributes.
5. Conclusions
This paper proposes an extended EDAS method to solve multi-attribute decision-making problems with incomplete evaluation information. D numbers are used to collect experts’ evaluation information, while the extended D–EDAS method is used to rank the alternatives. Finally, it is applied to solve the user experience evaluation problem in the platforms that offers online course live broadcasts. The implementation steps of the proposed method and the realization of specific situations are introduced in detail. To verify the stability and practicability of the method, we compare the computational results with the D numbers method of Hou and Zhao [19], and the experimental results demonstrate the good feasibility and superiority of the method. Admittedly, the limitation of this study is that the information filled by the SCRI method is only an inference of the missing part, which may not be strictly correct, and may not fully consider the weight of information of experts as well.
In future work, we can apply this method to other fields, such as green supplier selection, new energy sustainability assessment, and more. Furthermore, the simple operation of the EDAS method allows further research into uncertain and incomplete information environments, such as two-dimensional belief function [50] and Z-probabilistic linguistic information [51], amongst others.
Author Contributions
Conceptualization, H.H. and C.Z.; methodology, H.H. and C.Z.; formal analysis, H.H. and C.Z.; data curation, H.H. and C.Z.; writing—original draft preparation, H.H.; writing—review and editing, C.Z.; project administration, C.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Key projects of soft science of Zhejiang Province (No. 2021C25035); Zhejiang Higher Education Teaching Reform Research Project (jg20190206).
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Deng, J.L. The control problem of gray systems. Syst. Control. Lett. 1982, 1, 288–294. [Google Scholar]
- Dempster, A.P. Upper and lower probabilities induced by a multivalued mapping. Ann. Math. Stat. 1967, 38, 325–339. [Google Scholar] [CrossRef]
- Shafer, G. A Mathematical Theory of Evidence; Princeton University Press: Princeton, NJ, USA, 1976. [Google Scholar]
- Yager, R.R. Generalized dempster–shafer structures. IEEE Trans. Fuzzy Syst. 2019, 27, 428–435. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy sets. Inf. Control. 1965, 8, 338–353. [Google Scholar] [CrossRef]
- Atanassov, K. Intuitionistic fuzzy sets. Fuzzy Sets Syst. 1986, 20, 87–96. [Google Scholar] [CrossRef]
- Yager, R.R.; Reformat, M.; To, N.D. Drawing on the ipad to input fuzzy sets with an application to linguistic data science. Inf. Sci. 2019, 479, 277–291. [Google Scholar] [CrossRef]
- Pawlak, Z. Rough sets. Int. J. Inf. Comput. Sci. 1982, 11, 341–356. [Google Scholar] [CrossRef]
- Xiong, W.; Su, Q.; Li, J. The group decision-making rules based on rough sets on large scale engineering emergency. Syst. Eng. Procedia 2012, 4, 331–337. [Google Scholar] [CrossRef]
- Eisa, M. Improving group decision support systems using rough set. Int. J. Comput. Appl. 2013, 69, 9–13. [Google Scholar] [CrossRef]
- Deng, Y. D numbers: Theory and applications. J. Inf. Comput. Sci. 2012, 9, 2421–2428. [Google Scholar]
- Guan, X.; Liu, H.Q.; Yi, X.; Zhao, J. The improved combination rule of D numbers and its application in radiation source identification. Math. Probl. Eng. 2018, 2018, 6025680. [Google Scholar] [CrossRef]
- Xiao, F. A novel multi-criteria decision making method for assessing health-care waste treatment technologies based on D numbers. Eng. Appl. Artif. Intell. 2018, 71, 216–225. [Google Scholar] [CrossRef]
- Seiti, H.; Hafezalkotob, A.; Herrera-Viedma, E.E. A novel linguistic approach for multi-granular information fusion and decision-making using risk-based linguistic D numbers. Inf. Sci. 2020, 530, 43–65. [Google Scholar] [CrossRef]
- Mo, H.M.; Deng, Y. A new MADA methodology based on D numbers. Int. J. Fuzzy Syst. 2018, 20, 2458–2469. [Google Scholar] [CrossRef]
- Li, M.Z.; Hu, Y.; Zhang, Q.; Deng, Y. A novel distance function of D numbers and its application in product engineering. Eng. Appl. Artif. Intell. 2016, 47, 61–67. [Google Scholar] [CrossRef]
- Xia, J.; Feng, Y.; Liu, L.; Liu, D.; Fei, L. On entropy function and reliability indicator for d numbers. Appl. Intell. 2019, 49, 3248–3266. [Google Scholar] [CrossRef]
- Wang, N.K.; Liu, X.M.; Wei, D.J. A modified D numbers’ integration for multiple attributes decision making. Int. J. Fuzzy Syst. 2018, 20, 104–115. [Google Scholar] [CrossRef]
- Hou, H.; Zhao, C. A Novel Integration Method for D Numbers Based on Horizontal Comparison. Axioms 2021, 10, 312. [Google Scholar] [CrossRef]
- Deng, X.Y.; Hu, Y.; Deng, Y.; Mahadevan, S. Supplier selection using AHP methodology extended by D numbers. Expert Syst. Appl. 2014, 41, 156–167. [Google Scholar] [CrossRef]
- Han, X.; Chen, X. A D-VIKOR Method for Medicine Provider Selection. In Proceedings of the Seventh International Joint Conference on Computational Sciences & Optimization, Beijing, China, 4–6 July 2014; pp. 419–423. [Google Scholar]
- Fei, L.; Hu, Y.; Xiao, F.; Chen, L.; Deng, Y. A Modified TOPSIS Method Based on D Numbers and Its Applications in Human Resources Selection. Math. Probl. Eng. 2016, 2016, 6145196. [Google Scholar] [CrossRef]
- Zhou, X.; Deng, X.; Deng, Y.; Mahadevan, S. Dependence assessment in human reliability analysis based on D numbers and AHP. Nucl. Eng. Des. 2017, 313, 243–252. [Google Scholar] [CrossRef]
- Zong, F.; Wang, L. Evaluation of university scientific research ability based on the output of sci-tech papers: A D-AHP approach. PLoS ONE 2017, 12, e0171437. [Google Scholar] [CrossRef] [PubMed]
- Bian, T.; Zheng, H.; Yin, L.; Deng, Y. Failure mode and effects analysis based on D numbers and topsis. Qual. Reliab. Eng. Int. 2018, 34, 501–515. [Google Scholar] [CrossRef]
- Liu, P.; Zhang, X. A Multicriteria Decision-Making Approach with Linguistic D Numbers Based on the Choquet Integral. Cogn. Comput. 2019, 11, 560–575. [Google Scholar] [CrossRef]
- Liu, P.; Zhang, X.; Wang, Z. An Extended VIKOR Method for Multiple Attribute Decision Making with Linguistic D Numbers Based on Fuzzy Entropy. Int. J. Inf. Technol. Decis. Mak. 2020, 19, 143–167. [Google Scholar] [CrossRef]
- Tian, Y.; Mi, X.; Liu, L.; Kang, B. A New Soft Likelihood Function Based on D Numbers in Handling Uncertain Information. Int. J. Fuzzy Syst. 2020, 22, 2333–2349. [Google Scholar] [CrossRef]
- Hadi Mousavi-Nasab, S.; Sotoudeh-Anvari, A. An extension of best-worst method with D numbers: Application in evaluation of renewable energy resourcesSustain. Energy Technol. Assess. 2020, 40, 100771. [Google Scholar] [CrossRef]
- Mo, H. A New Evaluation Methodology for Quality Goals Extended by D Number Theory and FAHP. Information 2020, 11, 206. [Google Scholar] [CrossRef]
- Liu, P.; Zhang, X. A novel approach to multi-criteria group decision-making problems based on linguistic D numbers. Comp. Appl. Math. 2020, 39, 132. [Google Scholar] [CrossRef]
- Mi, X.; Tian, Y.; Kang, B. A hybrid multi-criteria decision making approach for assessing health-care waste management technologies based on soft likelihood function and D-numbers. Appl. Intell. 2021, 51, 6708–6727. [Google Scholar] [CrossRef]
- Lai, H.; Liao, H. A multi-criteria decision making method based on DNMA and CRITIC with linguistic D numbers for blockchain platform evaluation. Eng. Appl. Artif. Intell. 2021, 101, 104200. [Google Scholar] [CrossRef]
- Pamučar, D.; Puška, A.; Stević, Ž.; Cirovic, G. A new intelligent MCDM model for HCW management: The integrated BWM-MABAC model based on D numbers. Expert Syst. Appl. 2021, 175, 114862. [Google Scholar] [CrossRef]
- Mo, H. A SWOT method to evaluate safety risks in life cycle of wind turbine extended by D number theory. J. Intell. Fuzzy Syst. 2021, 40, 4439–4452. [Google Scholar] [CrossRef]
- Mi, X.; Tian, Y.; Kang, B. MADA Problem: A New Scheme Based on D Numbers and Aggregation Functions. J. Intell. Fuzzy Syst. 2021, 40, 11231–11255. [Google Scholar] [CrossRef]
- Fan, J.; Fang, W.; Wu, M. Selection of Battery Suppliers for New Energy Vehicles by an Integrated Model Based on D Numbers. J. Intell. Fuzzy Syst. 2022, 43, 3293–3309. [Google Scholar] [CrossRef]
- Keshavarz Ghorabaee, M.; Zavadskas, E.K.; Olfat, L.; Turskis, Z. Multi-criteria inventory classification using a new method of Evaluation Based on Distance from Average Solution (EDAS). Informatica 2015, 26, 435–451. [Google Scholar] [CrossRef]
- Keshavarz Ghorabaee, M.; Zavadskas, E.K.; Amiri, M.; Turskis, Z. Extended EDAS method for fuzzy multi-criteria decision-making: An application to supplier selection. Int. J. Comput. Commun. Control 2016, 11, 358–371. [Google Scholar] [CrossRef]
- Keshavarz Ghorabaee, M.; Amiri, M.; Zavadskas, E.K.; Turskis, Z.; Antucheviciene, J. Stochastic EDAS method for multi-criteria decision-making with normally distributed data. J. Intell. Fuzzy. Syst. 2017, 33, 1627–1638. [Google Scholar] [CrossRef]
- Ghorabaee, M.K.; Amiri, M.; Zavadskas, E.K.; Turskis, Z.; Antucheviciene, J. A new multi-criteria model based on interval type-2 fuzzy sets and EDAS method for supplier evaluation and order allocation with environmental considerations. Comput. Ind. Eng. 2017, 112, 156–174. [Google Scholar] [CrossRef]
- Stanujkic, D.; Zavadskas, E.K.; Ghorabaee, M.K.; Turskis, Z. An Extension of the EDAS Method Based on the Use of Interval Grey Numbers. Stud. Inform. Control. 2017, 26, 5–12. [Google Scholar] [CrossRef]
- Ecer, F. Third-party logistics (3PLs) provider selection via Fuzzy AHP and EDAS integrated model. Technol. Econ. Dev. Econ. 2018, 24, 615–634. [Google Scholar] [CrossRef]
- Karaşan, A.; Kahraman, C. A novel interval-valued neutrosophic EDAS method: Prioritization of the United Nations national sustainable development goals. Soft Comput. 2018, 22, 4891–4906. [Google Scholar] [CrossRef]
- Zavadskas, E.K.; Stević, Ž.; Turskis, Z.; Tomašević, M. A Novel Extended EDAS in Minkowski Space (EDAS-M) Method for Evaluating Autonomous Vehicles. Stud. Inform. Control. 2019, 28, 255–264. [Google Scholar] [CrossRef]
- Asante, D.; He, Z.; Adjei, N.O.; Asante, B. Exploring the barriers to renewable energy adoption utilising MULTIMOORA-EDAS method. Energy Policy 2020, 142, 111479. [Google Scholar] [CrossRef]
- Wei, G.; Wei, C.; Guo, Y. EDAS method for probabilistic linguistic multiple attribute group decision making and their application to green supplier selection. Soft Comput. 2021, 25, 9045–9053. [Google Scholar] [CrossRef]
- Chen, T.; Peng, L.; Jing, B.; Wu, C.; Yang, J.; Cong, G. The Impact of the COVID-19 Pandemic on User Experience with Online Education Platforms in China. Sustainability 2020, 12, 7329. [Google Scholar] [CrossRef]
- Wang, S.R.; Liu, Y.; Song, F.H.; Xie, X.; Yu, D. Research on evaluation system of user experience with online live course platform. IEEE Access 2021, 9, 23863–23875. [Google Scholar] [CrossRef]
- Li, Y.; Deng, Y. TDBF: Two Dimension Belief Function. Intl. J. Intell. Syst. 2019, 34, 1968–1982. [Google Scholar] [CrossRef]
- Chai, J.; Xian, S.; Lu, S. Z probabilistic linguistic term sets and its application in multi-attribute group decision making. Fuzzy Optim. Decis. Making 2021, 20, 529–566. [Google Scholar] [CrossRef]



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).