5.3.1. The Analysis of Production Efficiency
Table 5 demonstrates the production efficiency of 30 provinces in China, categorized as eastern, central, and western provinces and cities. The results reveal that eight provinces and cities, namely Shanghai, Shandong, Jiangsu, Beijing, Hubei, Anhui, Jilin, and Tianjin, have exhibited higher production efficiency throughout the period from 2010 to 2019, exceeding the benchmark of 0.80. In contrast, Ningxia and Yunnan have demonstrated lower production efficiency levels below 0.60. Notably, the majority of provinces presented their highest production efficiency in 2011, with a slight decline observed in 2018 and 2019. These findings suggest that China has witnessed some degree of redundancy in its industrial development, which has underpinned the supply-side reform of zombie enterprises. However, there is still room for enhancing productivity efficiency.
The findings suggest that the eastern region displays the highest level of efficiency among provinces in China, followed by the central region, and the western region performs with the least efficiency. The current study supplements earlier research, which similarly established such a trend.
The eastern region, widely recognized as the most developed in China, encompasses cities such as Beijing, Tianjin, and Hebei, and hosts industrial activity that fluctuates in productivity but remains substantially elevated. The Yangtze River Delta region, consisting of Shanghai, Zhejiang, and Jiangsu, and the Pearl River Delta region, located in Guangdong province, reveal relatively higher production efficiency, with both regions recording productivity levels above 0.75. These outcomes indicate the leading position of these regions in industrial development.
Coastal regions, such as Fujian, have experienced slow growth. Fujian province primarily focuses on light industry and has experienced relatively minor impacts from overcapacity reduction and environmental regulations, allowing for gradual growth. In the eastern region, Hainan has the lowest industrial production efficiency, ranking only 20th among all provinces. This is due to the weak industrial base in Hainan.
Three northeastern provinces (Liaoning, Jilin, and Heilongjiang) are rich in natural resources and have been important heavy industry bases in China in the past. Consequently, the region has experienced expedited development rates accompanied by heightened pollution levels. However, increased public attention to environmental degradation has led to the implementation of industrial restructuring processes to reduce environmental impact, resulting in a trend of fluctuating production efficiency. Among them, the change in production efficiency in Jilin Province is very steady, indicating a smooth transition in industrial restructuring without a significant impact on production efficiency. Meanwhile, Liaoning and Heilongjiang could benefit from emulating Jilin’s measured approach to avoid adverse effects on industrial production output.
The industrial development in the central provinces of Jiangxi and Anhui has always been at a relatively high and stable level. Jiangxi prioritizes non-ferrous metal smelting, machinery manufacturing, and agricultural and food processing, and maintains closer trade relationships with coastal regions. Meanwhile, Anhui’s manufacturing prowess extends to emerging high-technology sectors, such as display industries, equipment manufacturing, and industrial robotics. These provinces play significant roles in manufacturing, and their consistent production efficiency attests to their leading positions across various fields.
The overall production efficiency in the western region is relatively low. Although there are provinces with moderate production efficiency, such as Chongqing, Sichuan, and Guangxi, there is a significant gap compared to the eastern and central regions. There are multiple factors contributing to this situation. First, the industrial base in the western region is weak. Second, the western region is less economically developed compared to the eastern region, with lower per capita income and weaker consumption capacity for industrial products, leading to lower industrial scale efficiency. Third, the geographical environment in the western region results in higher transportation costs. Finally, the western region has a lower population density of highly skilled industrial laborers, which does not meet the labor demand of factories.
Through these results, we can identify the factors contributing to the growth in production efficiency across various provinces as follows:
Developed Infrastructure and Industrial Clusters: Cities in the eastern region, such as Beijing, Tianjin, and Shanghai, not only possess developed infrastructure but have also formed efficient industrial clusters. These clusters facilitate the effective flow of information, technology, and resources, further enhancing production efficiency.
Policy Support: Some regions have benefited from national policy support and measures to improve the environment, contributing to efficiency gains.
Differences in Economic Development Levels: Coastal provinces in the eastern region, especially Jiangsu, Shanghai, and Zhejiang, exhibit the highest production efficiency. Due to their open economic policies, advanced industrial bases, and convenient transportation and logistics conditions, these areas attract substantial domestic and foreign investment. This, in turn, promotes the development of high-tech industries and the improvement of production efficiency.
The risks to the development of production efficiency include:
Weak Industrial Base: Western regions, such as Gansu, Guizhou, and Ningxia, have a weaker industrial base, leading to generally lower production efficiency. The lower level of industrialization and technological base restricts the improvement of production efficiency.
Geographical and Transportation Limitations: The complex terrain and inconvenient transportation in the western regions result in higher logistics costs, which also limit production efficiency.
Shortage of Talent: The issues of low population density and a shortage of high-skilled industrial labor are particularly pronounced in the western regions, affecting the production efficiency and technological innovation capabilities of factories.
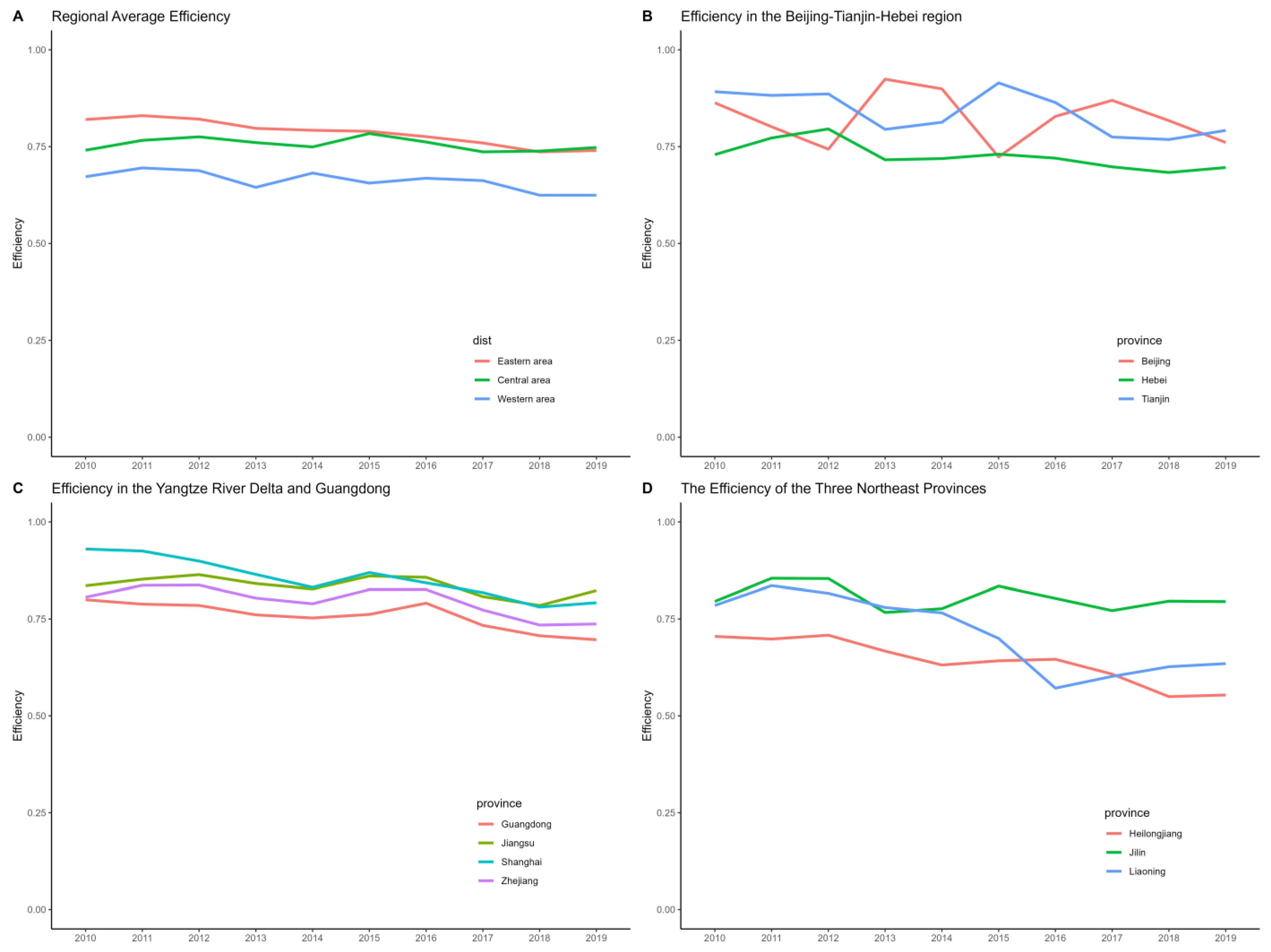
We further analyzed the efficiency change trends of various regions during this period.
Figure 3A displays the average efficiency changes of the three regions, highlighting the temporal trends. The figure illustrates a gradual decline in average efficiency in the eastern region, contrasted with a slow increase in the efficiency of the central region. This trend mirrors shifts in China’s industrial distribution over the years, indicating a gradual reallocation of industrial development focus from the eastern to the central regions.
Figure 3B depicts the changes within the Beijing-Tianjin-Hebei triangle area over this period. From 2010 to 2019, Beijing and Tianjin’s production efficiency showed significant fluctuations, in contrast to Hebei’s relatively stable efficiency. Notably, Beijing’s efficiency dipped in 2012, 2015, and 2019. A significant factor in Beijing’s efficiency decline is the underutilization of its expanding capital stock. By examining the raw data, we found that Beijing’s capital stock experienced substantial growth in these three years, increasing by 817.56 billion, 802.99 billion, and 265.05 billion yuan (in constant prices), with the first two increases being nearly 15%. Meanwhile, Beijing’s gross industrial output did not experience significant growth. This indicates that delays in production startup or year-end completions of new factories likely contributed to Beijing’s reduced efficiency. Tianjin’s case differs from Beijing’s. The reason for Tianjin’s lower production efficiency in 2013 is due to the growth of its capital stock by 948.98 billion yuan (in constant prices). Tianjin’s efficiency decline in 2017 can be attributed to supply-side reform policies, leading to a significant capital stock decrease. In 2017, Tianjin’s capital stock and total output value saw reductions of 1845.49 billion yuan and 8771.15 billion yuan, respectively, the latter constituting roughly a quarter of 2016’s total output.
Figure 3C reveals minimal fluctuations in productivity trends within the Yangtze River Delta region (Shanghai, Zhejiang, Jiangsu), indicating consistency. This consistency suggests that productivity in the region grew steadily, in a balanced and mutually reinforcing manner. Likewise, Guangdong’s productivity trend mirrored that of the Yangtze River Delta, indicating synchronized development patterns among major coastal cities.
Figure 3D illustrates a gradual decline in production efficiency in Heilongjiang, contrasted with an increase in Jilin, among the three northeastern provinces. This trend reflects a significant shift in industrial emphasis within the northeast region. Beginning in 2016, Liaoning Province saw a notable decrease in output value, resulting in a marked reduction in production efficiency. One reason for this downturn is the previously overstated data in Liaoning Province. In 2016, Liaoning disclosed its actual GDP as 2203.7 billion yuan, reflecting a 670.5 billion yuan reduction from 2015—an exaggeration rate of 23.3%. Following this disclosure, Liaoning’s national GDP ranking fell from 10th to 14th. Subsequently, its growth rate remained among the lowest in the country for several years. Additionally, beginning in 2011, Liaoning has been focusing on developing its service industry, signifying a strategic adjustment in its development priorities.
5.3.2. The Analysis on Total Factor Energy Efficiency
From the total factor energy efficiency proposed by hu et al. [
34], the total factor energy efficiency can be calculated as follows.
In the SBM game cross-efficiency model, the total factor energy efficiency is calculated as follows.
The total factor energy efficiency of 30 provinces and cities in China is shown in
Table 6. Overall, energy efficiency is still the highest in eastern cities, followed by central cities, and the lowest in western cities. From 2010 to 2019, Beijing, Guangdong, Zhejiang, Jiangsu, and Shanghai had relatively high average total factor energy efficiencies, all exceeding 0.80. In contrast, Ningxia, Qinghai, Xinjiang, Gansu, and Shanxi had lower energy efficiencies, all below 0.35, indicating significant room for improvement. Most provinces and cities show an upward trend in energy efficiency, although the changes are relatively stable.
Shanghai and Shandong have experienced a declining trend in energy efficiency. Among them, Shanghai decreased from 0.9517 to 0.8018, a drop of 0.1499, or 15.75%. The slow decline in Shanghai is due to the gradual decrease in industrial capital stock and labor since 2015, while energy input increased. As a result, Shanghai improved its capital and labor utilization efficiency while experiencing a decrease in energy efficiency. Shandong’s decline in energy efficiency is consistent with that of Shanghai.
Most provinces maintain stable or improved industrial energy efficiency; meanwhile, most provinces also maintain stable or decreased production efficiency. This reflects China’s growing focus on environmental and energy improvements in industrial development.
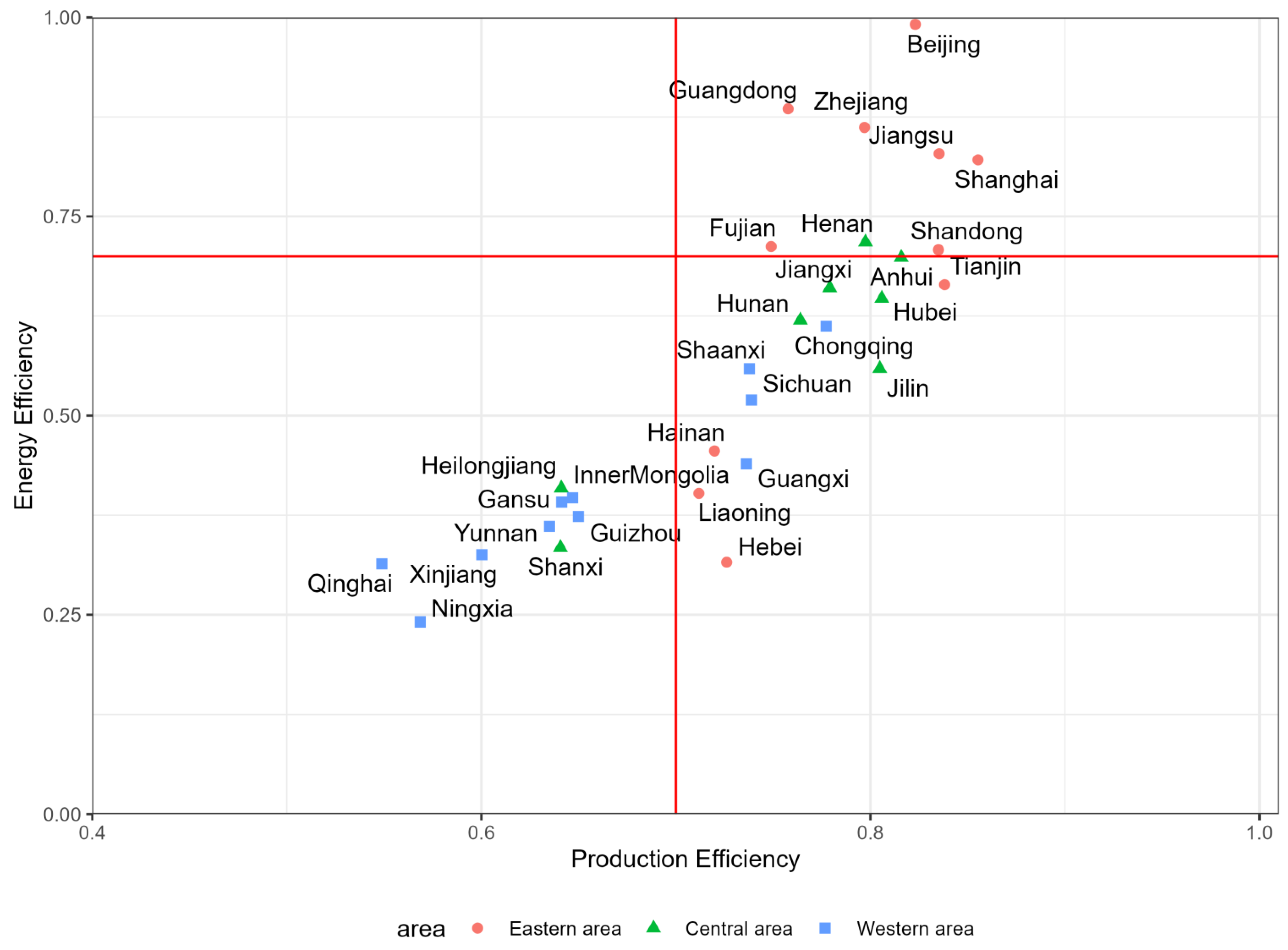
In
Figure 4, we present a comprehensive analysis by integrating the average production efficiency and total factor energy efficiency for every province. Subsequently, we categorized the decision units into four distinct groups using a dividing line of 70%. The first group, located in the upper-left quadrant, represents DMUs with low production efficiency but high energy efficiency. In particular, factors such as labor productivity and capital utilization require significant improvement. However, we acknowledge that decision units in this category are less prevalent due to the high dependence of energy efficiency on labor productivity and capital utilization.
The second group, located in the upper-right quadrant, represents DMUs with exemplary performance in terms of both productivity and total factor energy efficiency. This group serves as a model for other decision-making units to learn from. Notably, provinces and cities such as Guangdong, Beijing, Jiangsu, Zhejiang, and Shanghai demonstrate remarkable performance in this category.
In contrast, the third group, located in the lower-left quadrant, represents DMUs with low performance in both production efficiency and total factor energy efficiency. With significant room for improvement, provinces and cities such as Qinghai, Yunnan, Shanxi, Ningxia, and Xinjiang display significant potential for efficiency enhancements.
The fourth type of region is the bottom right corner region, where the DMUs have a relatively high production efficiency but low total factor energy efficiency. These regions are characterized by a focus on production without considering environmental protection, prioritizing economic development. Therefore, they are called high-consumption economic areas.
There continue to be significant disparities in both production efficiency and energy efficiency levels among the eastern, central, and western regions. In the western region, production efficiency is below 0.80, and energy efficiency ratings fall under 0.70, with four provinces even recording ratings lower than 0.35. In contrast, in the eastern region, only three provinces have production efficiencies below 0.75. These provinces also have higher energy efficiencies, none dropping below 0.60. The central region demonstrates a spectrum of production efficiency and energy efficiency ranks, with some provinces showing elevated energy efficiency and production efficiency levels and others reporting lower rates. Notably, Guangdong in the Pearl River Delta region exhibits high levels of both production efficiency and total factor energy efficiency. Similarly, Shanghai, Zhejiang, and Jiangsu in the Yangtze River Delta area also demonstrate high levels of these efficiencies. The data results align with our real-life impressions. In these economically developed regions, high production efficiency is required to cover higher costs and increased industry competition. The total factor energy efficiency is related to government policies. Guangdong and Beijing have stricter energy and carbon emission regulations, leading to higher total factor energy efficiency in these areas.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}