

Enhancing Intrusion Detection Systems Using a Deep Learning and Data Augmentation Approach

 ,
,  , , and
, , and
Abstract
1. Introduction
2. Related Works
3. Materials and Methods
3.1. Datasets
3.2. Data Preprocessing and Augmentation
3.3. Deep Learning Architectures
3.4. Model Training
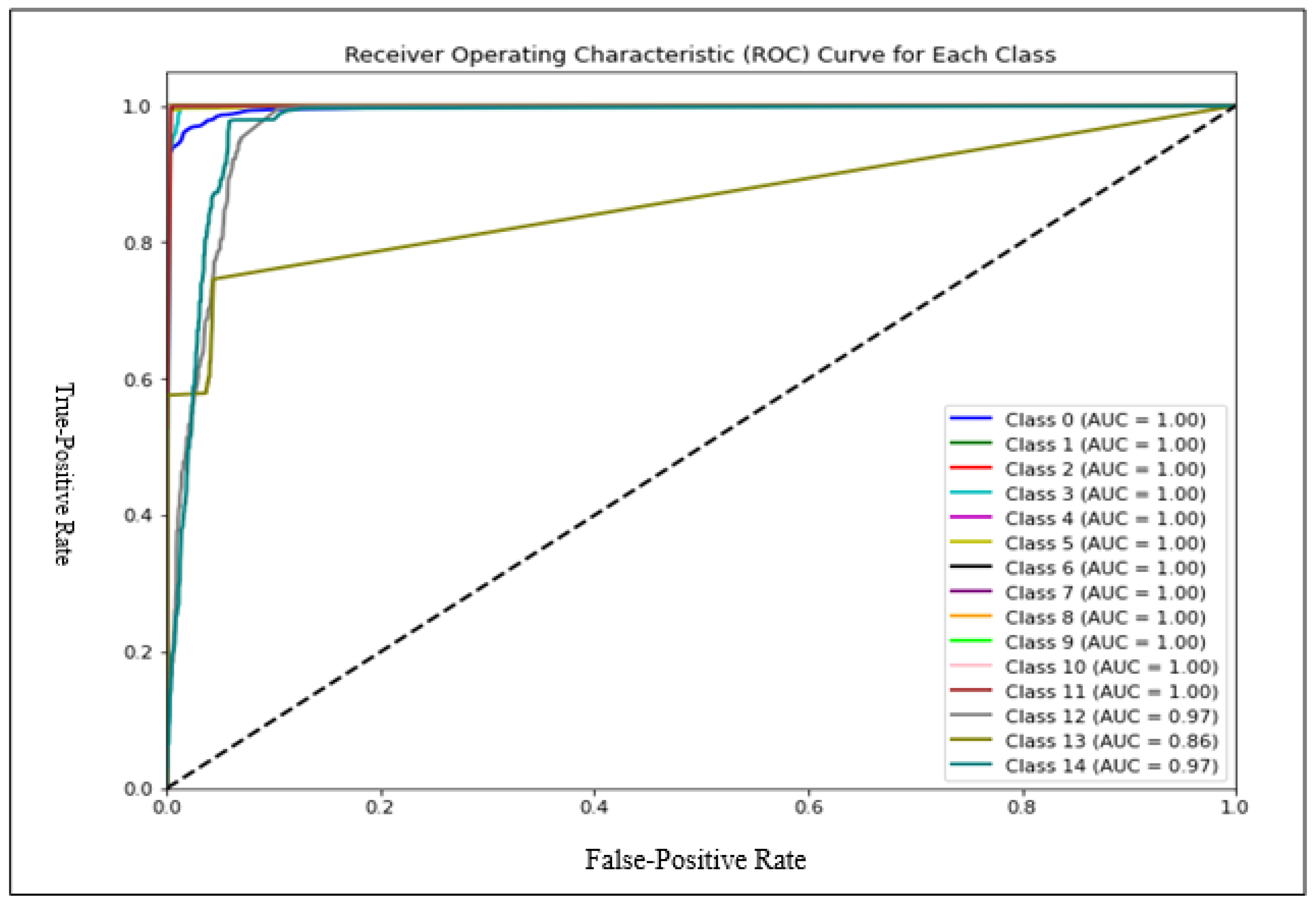
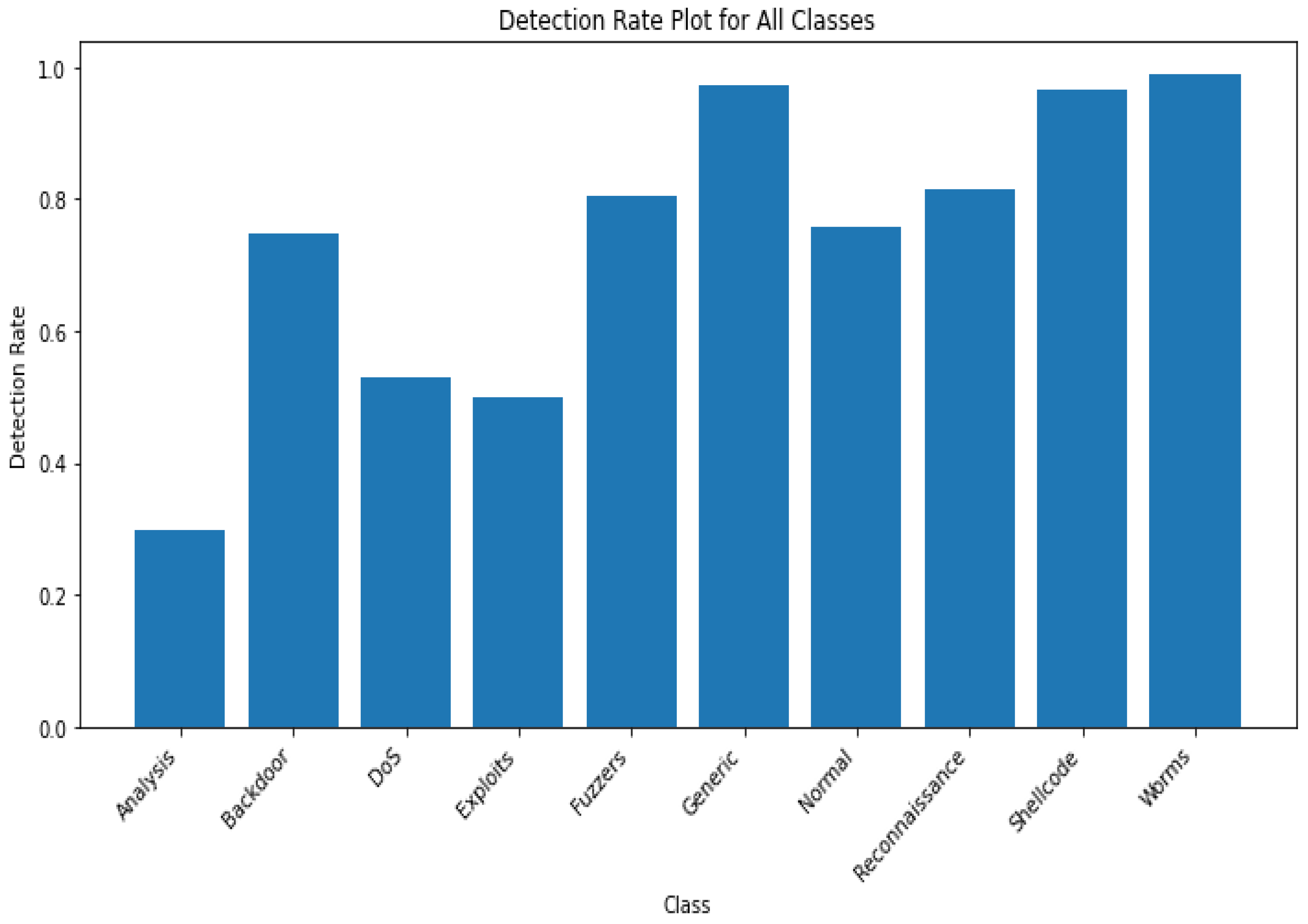
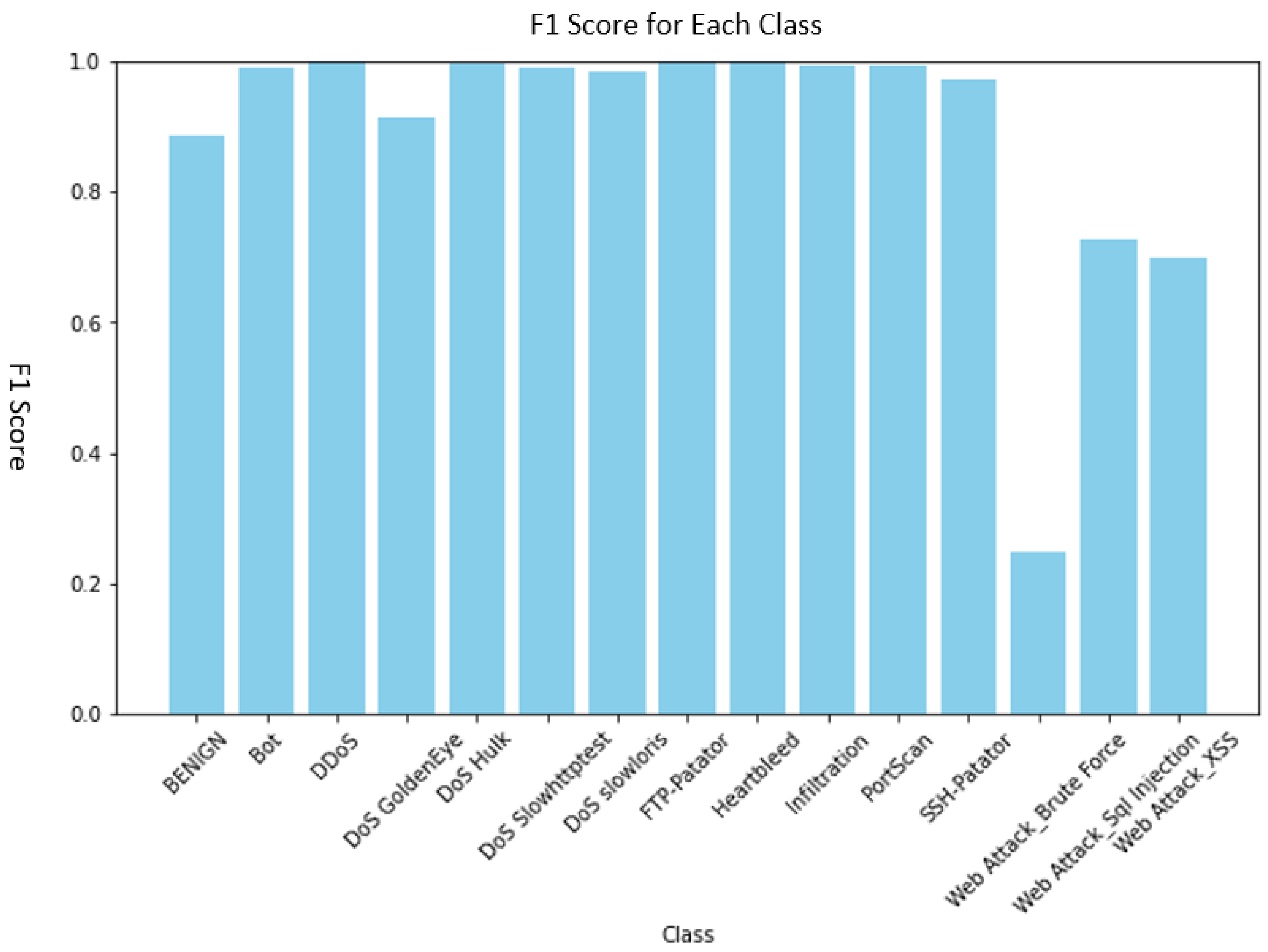
4. Results
4.1. Binary Classification
4.2. Multiple Classifications
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ieracitano, C.; Adeel, A.; Gogate, M.; Dashtipour, K.; Morabito, C.F.; Larijani, H.; Raza, A.; Hussain, A. Statistical analysis driven optimized deep learning system for intrusion detection. In Advances in Brain Inspired Cognitive Systems; Springer Nature: Cham, Switzerland, 2018; Volume 10989, pp. 759–769. [Google Scholar] [CrossRef]
- Rodríguez, M.; Alesanco, Á.; Mehavilla, L.; García, J. Evaluation of Machine Learning Techniques for Traffic Flow-Based Intrusion Detection. Sensors 2022, 22, 9326. [Google Scholar] [CrossRef] [PubMed]
- Sinha, J.; Manollas, M. Efficient Deep CNN-BiLSTM Model for Network Intrusion Detection the 2020. In Proceedings of the 3rd International Conference on Artificial Intelligence and Pattern Recognition, Xiamen, China, 26–28 June 2020. [Google Scholar]
- Markevych, M.; Dawson, M. A review of enhancing intrusion detection systems for cybersecurity using artificial intelligence (ai). In Proceedings of the International Conference Knowledge-Based Organization, Sibiu, Romania, 19 July 2023; Volume 29, pp. 30–37. [Google Scholar]
- Dini, P.; Elhanashi, A.; Begni, A.; Saponara, S.; Zheng, Q.; Gasmi, K. Overview on Intrusion Detection Systems Design Exploiting Machine Learning for Networking Cybersecurity. Appl. Sci. 2023, 13, 7507. [Google Scholar] [CrossRef]
- Vigneswaran, R.K.; Vinayakumar, R.; Soman, K.P.; Poornachandran, P. Evaluating Shallow and Deep Neural Networks for Network Intrusion Detection Systems in Cyber Security. In Proceedings of the 9th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Bengaluru, India, 10–12 July 2018. [Google Scholar]
- Nour, M.; Slay, J. The evaluation of Network Anomaly Detection Systems: Statistical analysis of the UNSW-NB15 dataset and the comparison with the KDD99 dataset. Inf. Secur. J. A Glob. Perspect. 2016, 25, 18–31. [Google Scholar]
- Nour, M.; Slay, J. UNSW-NB15: A comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set). In Proceedings of the Military Communications and Information Systems Conference (MilCIS), Canberra, ACT, Australia, 10–12 November 2015. [Google Scholar]
- Su, T.; Huazhi, S.; Zhu, J.; Want, S.; Li, Y. BAT: Deep Learning Methods on Network Intrusion Detection Using NSL-KDD Dataset. IEEE Access 2020, 8, 29575–29585. [Google Scholar] [CrossRef]
- Vinayakumar, R.; Soman, K.; Poornachandran, P. Evaluation of recurrent neural network and its variants for intrusion detection system (IDS). Int. J. Inf. Syst. Model. Des. Clin. Res. 2017, 8, 43–63. [Google Scholar] [CrossRef]
- Balakrishnan, V.; Shi, Z.; Law, C.; Lim, R.; Teh, L.; Fan, Y. A deep learning approach in predicting products’ sentiment ratings: A comparative analysis. J. Supercomput. 2022, 78, 7206–7226. [Google Scholar] [CrossRef] [PubMed]
- Zheng, B.; Liu, B. A Scalable Purchase Intention Prediction System Using Extreme Gradient Boosting Machines with Browsing Content Entropy. In Proceedings of the 2018 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 12–14 January 2018. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Khan, R.U.; Zhang, X.; Alazab, M.; Kumar, R. An improved convolutional neural network model for intrusion detection in networks. In Proceedings of the Cybersecurity and Cyberforensics Conference (CCC), Melbourne, VIC, Australia, 8–9 May 2019. [Google Scholar]
- Wang, W.; Sheng, Y.; Wang, J.; Zeng, X.; Ye, X.; Huang, Y.; Zhu, M. HAST-IDS: Learning hierarchical spatial-temporal features using deep neural networks to improve intrusion detection. IEEE Access 2018, 6, 1792–1806. [Google Scholar] [CrossRef]
- Yang, S. Research on network behavior anomaly analysis based on bidirectional LSTM IEEE 3rd Information Technology, Networking. In Proceedings of the Electronic and Automation Control Conference (ITNEC), Chengdu, China, 15–17 March 2019. [Google Scholar]
- Ayantayo, A.; Kaur, A.; Kour, A.; Schmoor, X.; Shah, F.; Vickers, I.; Kearney, P.; Abdelsamea, M.M. Network intrusion detection using feature fusion with deep learning. J. Big Data 2023, 10, 167. [Google Scholar] [CrossRef]
- Pratap, P.C.; Pandey, P. Time Series Forecasting Using Machine Learning Models: A Survey. In Proceedings of the 9th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Bengaluru, India, 10–12 July 2018. [Google Scholar]
- Zhao, Z.; Chen, H.R.; Liu, R. Deep Learning in Time-Series Analysis: A Survey. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Hajirahimi, Z.; Khashei, M. Hybrid structures in time series modeling and forecasting: A review. Eng. Appl. Artif. Intell. 2019, 86, 83–106. [Google Scholar] [CrossRef]
- Bachl, M.; Hartl, A.; Fabini, J.; Zseby, T. Walling up Backdoors in Intrusion Detection Systems. In Proceedings of the the 3rd ACM CoNEXT Workshop on Big Data, Machine Learning and Artificial Intelligence for Data Communication Networks, Orlando, FL, USA, 9 December 2019. [Google Scholar]
- Sharma, N.; Yadav, N.; Singh; Sharma, S. Classification of UNSW-NB15 dataset using Exploratory Data Analysis using Ensemble Learning. Trans. Ind. Netw. Intell. Syst. 2021, 8, e4. [Google Scholar] [CrossRef]
- Sharafaldin, I.; Lashkari, A.; Habibi; Ghorbani, A.A. Toward Generating a New Intrusion Detection Dataset and Intrusion Traffic. In Proceedings of the Characterization the 4th International Conference on Information Systems Security and Privacy, Funchal, Portugal, 22–24 January 2018. [Google Scholar]
- Duan, L.; Xue, W.; Huang, J.; Zheng, X. Joint Sample Position Based Noise Filtering and Mean Shift Clustering for Imbalanced Classification Learning. Tsinghua Sci. Technol. 2024, 29, 216–231. [Google Scholar] [CrossRef]
- Samarakoon, S.; Siriwardhana, Y.; Porambage, P.; Liyanage, M.; Chang, S.; Kim, J.; Kim, J.; Ylianttila, M. 5G-NIDD: A Comprehensive Network Intrusion Detection Dataset Generated over 5G Wireless Network. IEEE Dataport 2022. [Google Scholar] [CrossRef]
- Kumar, P.; Liu, J.; Tayeen, A.S.M.; Misra, S.; Cao, H.; Harikumar, J.; Perez, O. FLNET2023: Realistic Network Intrusion Detection Dataset for Federated Learning. In Proceedings of the MILCOM 2023–2023 IEEE Military Communications Conference (MILCOM), Boston, MA, USA, 30 October–3 November 2023; pp. 345–350. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Elreedy, D.; Atiya, A.F. A comprehensive analysis of synthetic minority oversampling technique (SMOTE) for handling class imbalance. Inf. Sci. 2019, 505, 32–64. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Volume 1. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Bengio, Y. Learning deep architectures for AI. Found. Trends Mach. Learn. 2009, 2, 1–127. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Zhang, C.; Bengio, S.; Hardt, M.; Recht, B.; Vinyals, O. Understanding deep learning requires rethinking generalization. arXiv 2017, arXiv:1611.03530. [Google Scholar] [CrossRef]
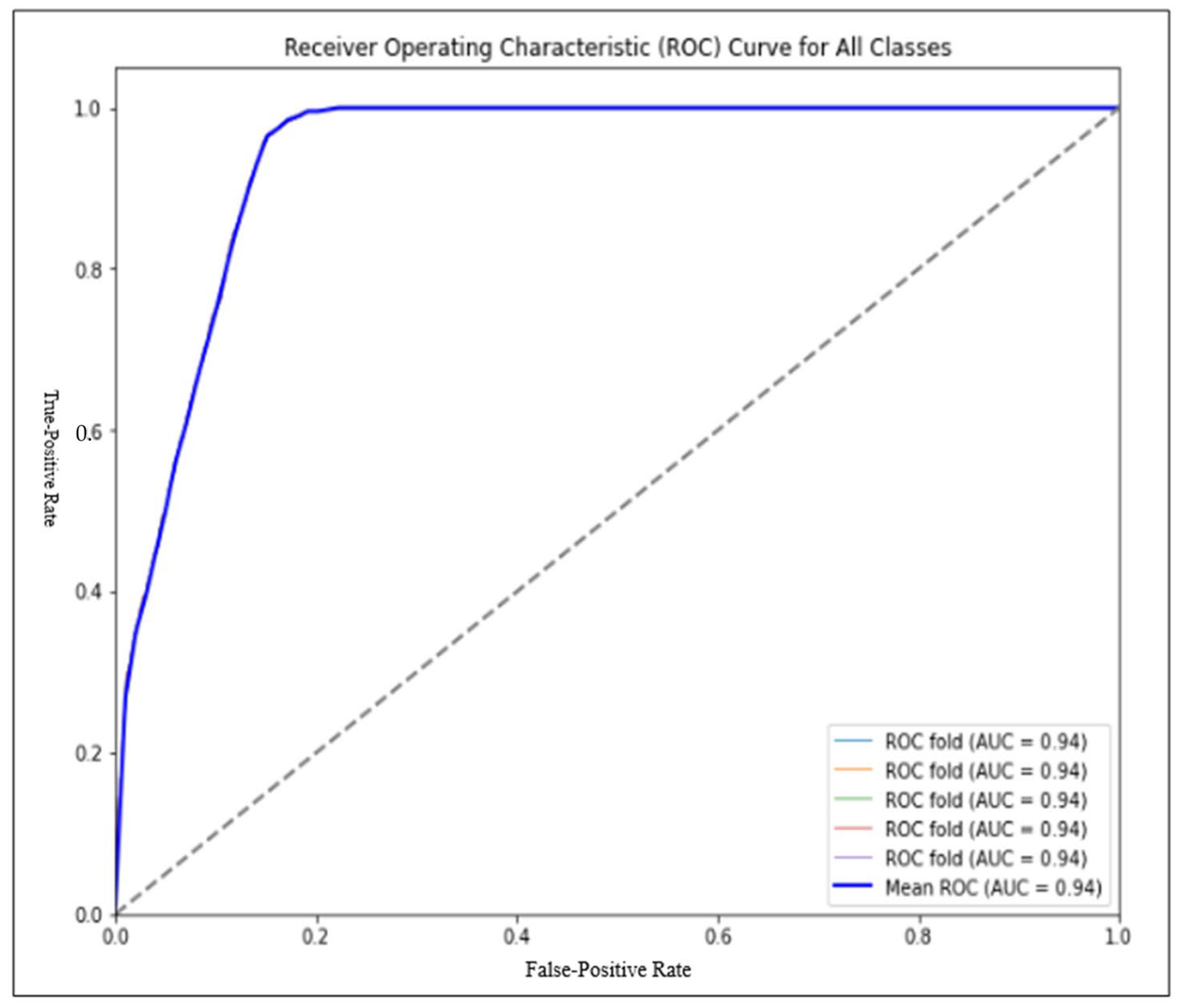
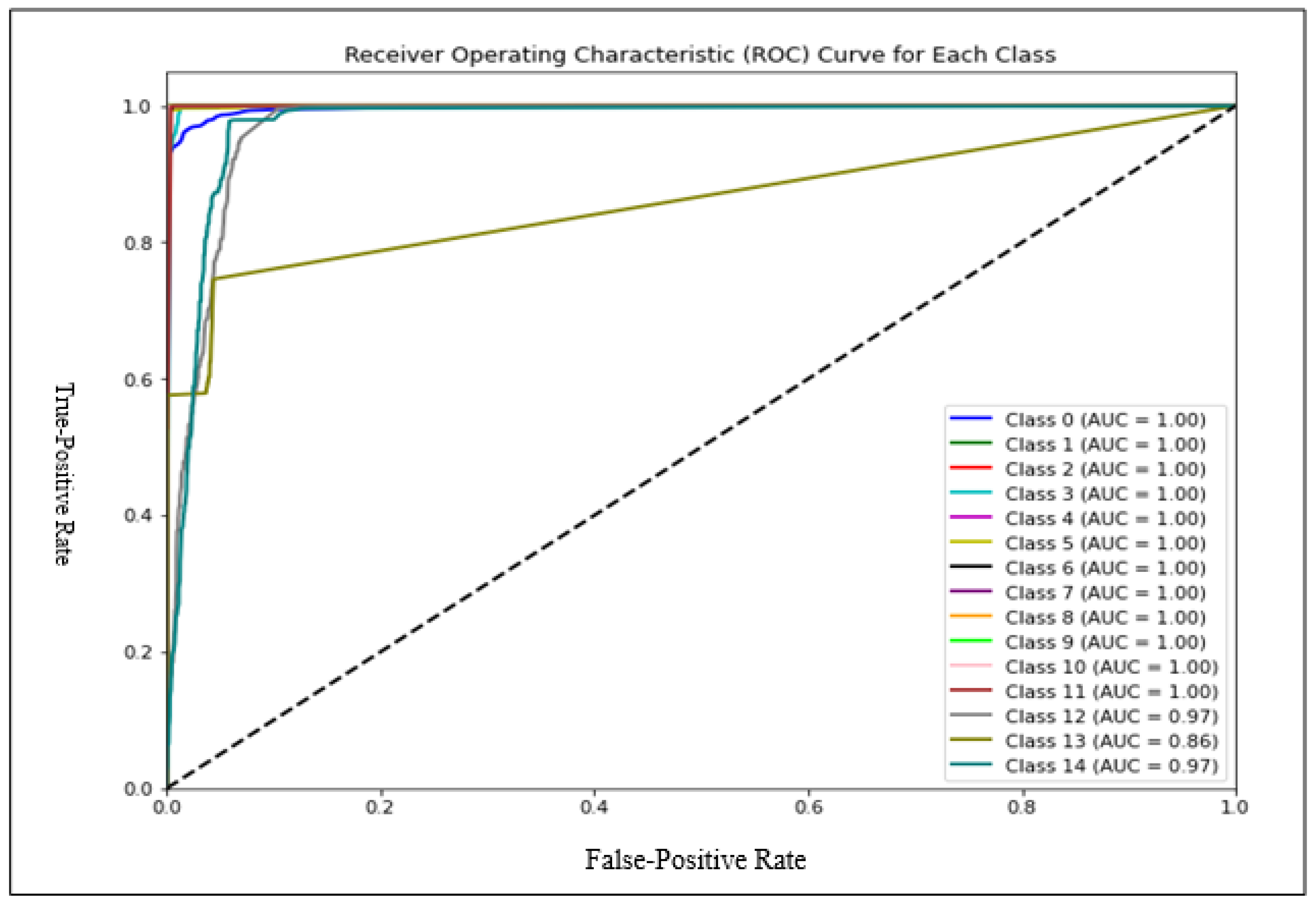
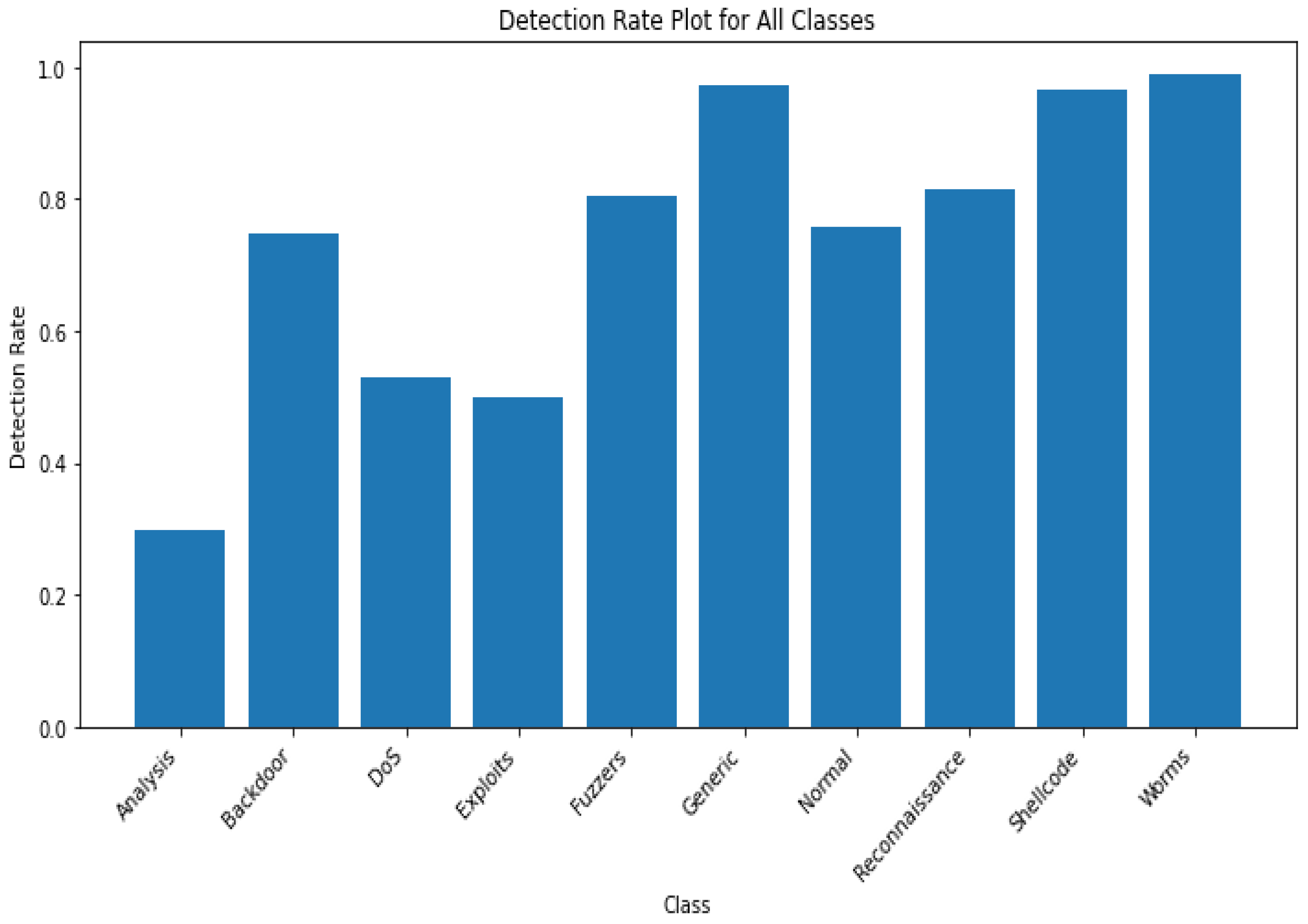
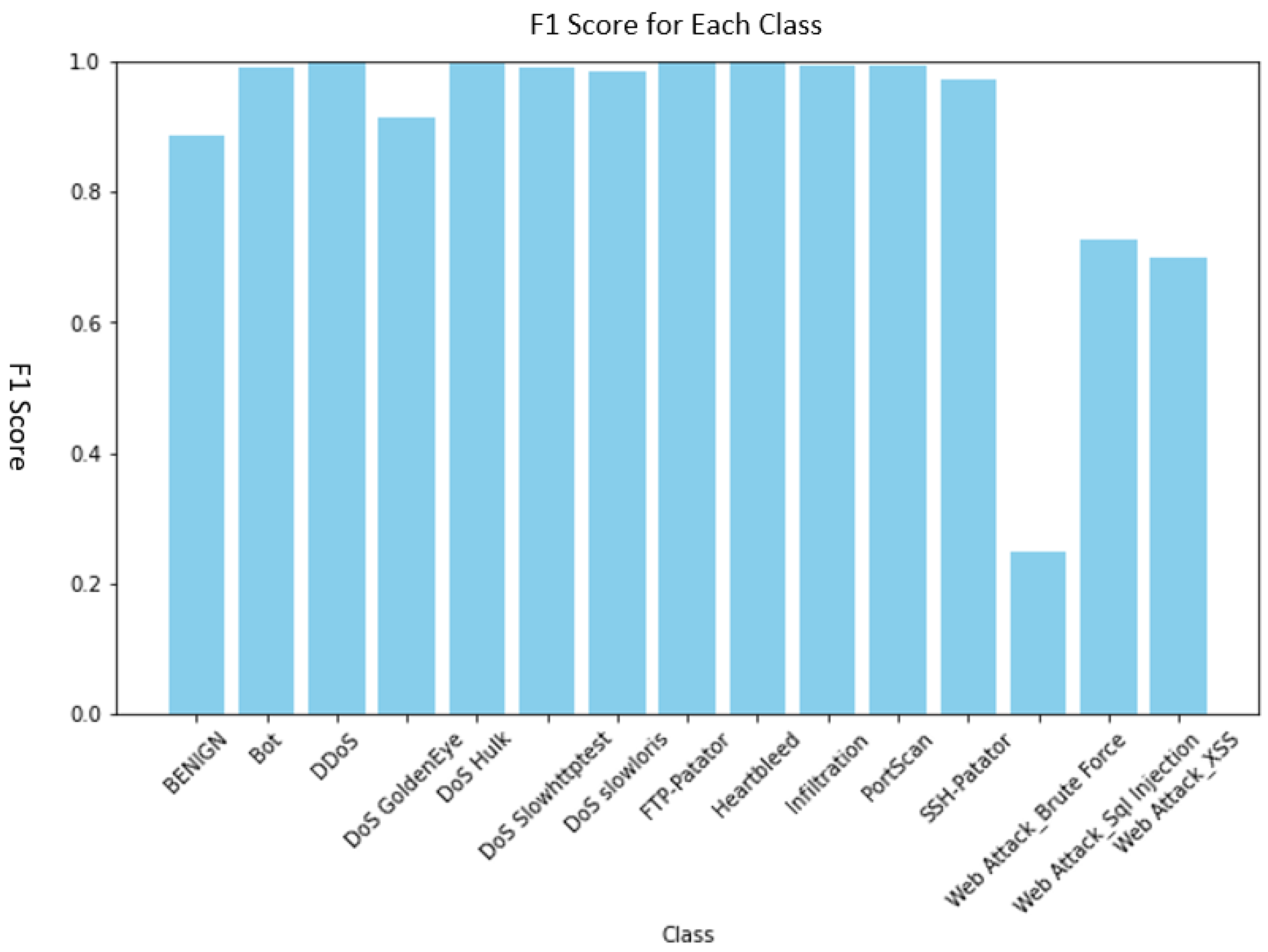

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category (UNSW-NB15) | Quantity (UNSW-NB15) | Category (CIC-IDS-2017) | Quantity (CIC-IDS-2017) |
|---|---|---|---|
| Normal Analysis Fuzzers Backdoor DoS Generic Exploit Reconnaissance Shellcode Worms | 93,000 2677 24,246 2329 16,353 58,871 44,525 13,987 1511 174 | Heartbleed Infiltration DoS Hulk Web Attack—XSS Benign DoS GoldenEye PortScan Web Attack—SQL Injection Bot DDoS FTP-Patator Web Attack—Brute Force SSH-Patator DoS Slowhttptest DoS Slowloris | 11 36 231,072 652 2,359,087 10,293 158,930 21 1966 41,835 7938 1507 5897 5499 5796 |
| Overall | 257,673 | 2,830,540 |
| Layer Type | Output Shape | Parameters | Explanation |
|---|---|---|---|
| Conv1D | (192, 128) | 768 | Convolutional layer processing 1D input with 128 filters. |
| MaxPooling1D | (96, 128) | 0 | Reduces dimensionality for computational efficiency. |
| Conv1D | (92, 64) | 41,024 | Second Conv1D layer with 64 filters for feature extraction. |
| MaxPooling1D | (46, 64) | 0 | Further dimensionality reduction. |
| Flatten | (2944) | 0 | Flattens input for the dense layer. |
| Dense | (64) | 188,480 | Fully connected layer for classification. |
| Dropout | (64) | 0 | Prevents overfitting by randomly dropping units. |
| Dense | (10) | 650 | Output layer with 10 units for class prediction. |
| Layer Type | Output Shape | Parameters | Explanation |
|---|---|---|---|
| Conv1D | (192, 128) | 768 | Convolutional layer for feature extraction with 128 filters |
| MaxPooling1D | (96, 128) | 0 | Reduces the spatial dimensions for efficiency. |
| Conv1D | (92, 64) | 41,024 | Second convolutional layer with 64 filters for deeper feature extraction. |
| MaxPooling1D | (46, 64) | 0 | Further reduces dimensions and helps prevent overfitting. |
| Flatten | (2944) | 0 | Flattens the 2D feature maps into a 1D vector for the dense layer. |
| Dense | (128) | 376,960 | Fully connected layer to learn non-linear combinations of features. |
| Dropout | (128) | 0 | Drops out units randomly to prevent overfitting. |
| Dense | (64) | 8256 | Another dense layer for further processing of features. |
| Dropout | (64) | 0 | Additional dropout layer for regularization. |
| Dense | (10) | 650 | Final output layer with 10 units for class prediction. |
| Layer Type | Output Shape | Parameters | Explanation |
|---|---|---|---|
| Conv1D | (196, 64) | 4160 | Initial convolutional layer with 64 filters for feature extraction. |
| MaxPooling1D | (19, 64) | 0 | Reduces dimensionality for computational efficiency. |
| BatchNormalization | (19, 64) | 256 | Normalizes the output of the previous layer to speed up training. |
| GRU | (64) | 24,960 | GRU layer for processing temporal sequence data. |
| Reshape | (64, 1) | 0 | Reshapes the output for compatibility with subsequent layers. |
| MaxPooling1D | (6, 1) | 0 | Further reduces sequence length for efficiency. |
| BatchNormalization | (6, 1) | 4 | Further normalization to stabilize learning. |
| GRU | (128) | 50,304 | Second GRU layer for more complex sequence modeling. |
| Dropout | (128) | 0 | Prevents overfitting by randomly omitting units. |
| Dense | (10) | 0 | Output layer for class prediction with 10 units. |
| Layer Type | Output Shape | Parameters | Explanation |
|---|---|---|---|
| Conv1D. | (196, 64) | 4160 | Convolutional layer for initial feature extraction. |
| MaxPooling1D | (19, 64) | 0 | Dimensionality reduction. |
| BatchNormalization | (19, 64) | 256 | Normalizes layer inputs to accelerate training. |
| GRU | (64) | 24,960 | GRU layer for temporal data processing. |
| Reshape | (64, 1) | 0 | Prepares data for subsequent bidirectional layer. |
| MaxPooling1D | (6, 1) | 0 | Reduces sequence length for computational efficiency. |
| BatchNormalization | (6, 1) | 4 | Further normalization. |
| Bidirectional | (256) | 133,120 | LSTM layer wrapped in a bidirectional layer for enhanced temporal feature extraction. |
| Dropout | (256) | 0 | Mitigates overfitting. |
| Dense | (10) | 2570 | Output layer for classification. |
| Activation | (10) | 0 | Output layer activation function. |
| Layer Type | Output Shape | Parameters | Explanation |
|---|---|---|---|
| Conv1D | (76, 64) | 2112 | Initial convolutional layer with 64 filters for extracting basic features from the input. |
| MaxPooling1D | (15, 64) | 0 | Reduces the dimensionality of the features, which helps in computational efficiency and mitigating overfitting. |
| BatchNormalization | (15, 64) | 256 | Normalizes the activations from the previous layer, stabilizing the learning process. |
| Bidirectional | (128) | 66,048 | LSTM layer wrapped in a bidirectional layer to process the sequential data in both forward and reverse directions for enhanced temporal understanding. |
| Reshape | (128, 1) | 0 | Reshapes the output for compatibility with subsequent layers. |
| MaxPooling1D | (25, 1) | 0 | Further reduces the length of the sequence, focusing on the most significant features. |
| BatchNormalization | (25, 1) | 4 | Additional normalization to ensure smooth training. |
| Bidirectional | (256) | 133,120 | Second bidirectional LSTM layer for deep and complex sequence modeling. |
| Dropout | (256) | 0 | Implemented early in the network to prevent overfitting by randomly dropping units. |
| Dense | (4) | 1028 | Dense layer for processing the extracted features before the final classification. |
| Activation | (10) | 0 | Applies the output layer activation function for final class prediction. |
| Classes | Precision | Recall | F1 Score |
|---|---|---|---|
| Analysis | 0.79 | 0.03 | 0.05 |
| Backdoor | 0.65 | 0.09 | 0.16 |
| DoS | 0.62 | 0.05 | 0.09 |
| Exploits | 0.60 | 0.05 | 0.09 |
| Fuzzers | 0.73 | 0.48 | 0.58 |
| Generic | 1.00 | 0.98 | 0.99 |
| Normal | 0.88 | 0.95 | 0.92 |
| Reconnaissance | 0.87 | 0.75 | 0.57 |
| Shellcode | 0.61 | 0.53 | 0.57 |
| Worms | 0.29 | 0.63 | 0.40 |
| Accuracy | 0.82 |
| Classes | Precision | Recall | F1 Score |
|---|---|---|---|
| Analysis | 0.65 | 0.30 | 0.41 |
| Backdoor | 0.40 | 0.75 | 0.52 |
| DoS | 0.44 | 0.53 | 0.48 |
| Exploits | 0.79 | 0.50 | 0.61 |
| Fuzzers | 0.77 | 0.80 | 0.79 |
| Generic | 1.00 | 0.97 | 0.99 |
| Normal | 0.93 | 0.76 | 0.84 |
| Reconnaissance | 0.88 | 0.81 | 0.85 |
| Shellcode | 0.90 | 0.97 | 0.93 |
| Worms | 0.98 | 0.99 | 0.99 |
| Accuracy | 0.74 |
| Classes | Precision | Recall | F1 Score |
|---|---|---|---|
| BENIGN | 1.00 | 0.98 | 0.99 |
| Bot | 0.25 | 0.27 | 0.24 |
| DDoS | 1.00 | 0.99 | 0.99 |
| DoS GoldenEye | 0.98 | 0.98 | 0.98 |
| DoS Hulk | 0.94 | 1.00 | 0.97 |
| DoS Slowhttptest | 0.87 | 0.98 | 0.92 |
| DoS slowloris | 0.98 | 0.95 | 0.97 |
| FTP-Patator | 0.99 | 0.99 | 0.99 |
| Heartbleed | 0.15 | 0.13 | 0.16 |
| Infiltration | 0.19 | 0.21 | 0.21 |
| PortScan | 0.88 | 0.97 | 0.92 |
| SSH-Patator | 0.88 | 0.98 | 0.93 |
| Attack_Brute Force | 0.36 | 0.40 | 0.45 |
| Attack_Sql Injection | 0.24 | 0.28 | 0.32 |
| Attack_XSS | 0.56 | 0.59 | 0.60 |
| Accuracy | 0.98 |
| Classes | Precision | Recall | F1 Score |
|---|---|---|---|
| BENIGN | 0.99 | 0.99 | 0.99 |
| Bot | 0.99 | 0.34 | 0.51 |
| DDoS | 1.00 | 0.99 | 0.99 |
| DoS GoldenEye | 0.98 | 0.98 | 0.98 |
| DoS Hulk | 0.97 | 0.98 | 0.97 |
| DoS Slowhttptest | 0.89 | 0.99 | 0.94 |
| DoS slowloris | 0.98 | 0.99 | 0.98 |
| FTP-Patator | 1.00 | 0.64 | 0.78 |
| Heartbleed | 0.15 | 0.17 | 0.15 |
| Infiltration | 0.13 | 0.12 | 0.15 |
| PortScan | 0.90 | 0.95 | 0.92 |
| SSH-Patator | 1.00 | 0.49 | 0.66 |
| Attack_Brute Force | 0.91 | 0.05 | 0.09 |
| Attack_Sql Injection | 0.11 | 0.13 | 0.10 |
| Attack_XSS | 0.09 | 0.08 | 0.12 |
| Accuracy | 0.98 |
| Classes | Precision | Recall | F1 Score |
|---|---|---|---|
| BENIGN | 0.67 | 0.91 | 0.77 |
| Bot | 0.97 | 0.99 | 0.98 |
| DDoS | 0.99 | 1.00 | 1.00 |
| DoS GoldenEye | 0.84 | 0.99 | 0.91 |
| DoS Hulk | 0.98 | 1.00 | 0.99 |
| DoS Slowhttptest | 0.99 | 0.99 | 0.99 |
| DoS slowloris | 0.99 | 0.99 | 0.99 |
| FTP-Patator | 1.00 | 0.99 | 0.99 |
| Heartbleed | 1.00 | 0.80 | 0.89 |
| Infiltration | 0.99 | 0.79 | 0.88 |
| PortScan | 0.99 | 1.00 | 0.99 |
| SSH-Patator | 0.91 | 0.49 | 0.64 |
| Attack_Brute Force | 0.90 | 0.15 | 0.25 |
| Attack_Sql Injection | 0.56 | 0.72 | 0.63 |
| Attack_XSS | 0.53 | 0.97 | 0.69 |
| Accuracy | 0.85 |
| Classes | Precision | Recall | F1 Score |
|---|---|---|---|
| BENIGN | 0.85 | 0.96 | 0.90 |
| Bot | 0.99 | 1.00 | 0.99 |
| DDoS | 1.00 | 1.00 | 1.00 |
| DoS GoldenEye | 0.80 | 0.99 | 0.89 |
| DoS Hulk | 0.99 | 1.00 | 1.00 |
| DoS Slowhttptest | 0.99 | 0.99 | 0.99 |
| DoS slowloris | 0.99 | 0.99 | 0.99 |
| FTP-Patator | 1.00 | 1.00 | 1.00 |
| Heartbleed | 1.00 | 1.00 | 1.00 |
| Infiltration | 1.00 | 1.00 | 0.99 |
| PortScan | 0.99 | 1.00 | 0.99 |
| SSH-Patator | 0.94 | 1.00 | 0.97 |
| Attack_Brute Force | 0.66 | 0.50 | 0.57 |
| Attack_Sql Injection | 0.99 | 0.59 | 0.74 |
| Attack_XSS | 0.63 | 0.75 | 0.68 |
| Accuracy | 0.92 |
| Classes | Precision | Recall | F1 Score |
|---|---|---|---|
| BENIGN | 0.99 | 0.95 | 0.97 |
| UDPFlood | 0.95 | 0.99 | 0.97 |
| HTTPFlood | 0.99 | 1.00 | 0.99 |
| SlowrateDoS | 0.99 | 0.98 | 0.99 |
| TCPConnectScan | 1.00 | 0.99 | 1.00 |
| SYNScan | 1.00 | 1.00 | 1.00 |
| UDPScan | 1.00 | 1.00 | 1.00 |
| SYNFlood | 1.00 | 0.99 | 0.99 |
| ICMPFlood | 0.99 | 1.00 | 1.00 |
| Accuracy | 0.97 |
| Classes | Precision | Recall | F1 Score |
|---|---|---|---|
| BENIGN | 0.99 | 0.95 | 0.97 |
| UDPFlood | 0.95 | 0.99 | 0.97 |
| HTTPFlood | 0.99 | 1.00 | 1.00 |
| SlowrateDoS | 1.00 | 0.99 | 0.99 |
| TCPConnectScan | 1.00 | 1.00 | 1.00 |
| SYNScan | 1.00 | 1.00 | 1.00 |
| UDPScan | 1.00 | 1.00 | 1.00 |
| SYNFlood | 1.00 | 1.00 | 1.00 |
| ICMPFlood | 0.99 | 1.00 | 1.00 |
| Accuracy | 0.98 |
| Classes | Precision | Recall | F1 Score |
|---|---|---|---|
| DDoS-bot | 1.00 | 0.99 | 0.99 |
| DDoS-dyn | 0.99 | 1.00 | 1.00 |
| DDoS-stomp | 1.00 | 1.00 | 1.00 |
| DDos-tcp | 1.00 | 1.00 | 1.00 |
| DDoS-hulk | 1.00 | 1.00 | 1.00 |
| DoS-slowhttp | 0.99 | 1.00 | 1.00 |
| Infiltration-mitm | 1.00 | 1.00 | 1.00 |
| Normal | 1.00 | 1.00 | 1.00 |
| Web-command-injection | 0.96 | 0.98 | 0.97 |
| Web-sql-injection | 1.00 | 0.89 | 0.94 |
| Web-xss | 0.99 | 1.00 | 0.99 |
| Accuracy | 1.00 |
| Classes | Precision | Recall | F1 Score |
|---|---|---|---|
| DDoS-bot | 1.00 | 0.99 | 0.99 |
| DDoS-dyn | 0.99 | 1.00 | 1.00 |
| DDoS-stomp | 1.00 | 1.00 | 1.00 |
| DDos-tcp | 1.00 | 1.00 | 1.00 |
| DDoS-hulk | 1.00 | 1.00 | 1.00 |
| DoS-slowhttp | 0.99 | 1.00 | 1.00 |
| Infiltration-mitm | 1.00 | 1.00 | 1.00 |
| Normal | 1.00 | 1.00 | 1.00 |
| Web-command-injection | 0.97 | 0.99 | 0.98 |
| Web-sql-injection | 1.00 | 0.91 | 0.96 |
| Web-xss | 0.99 | 1.00 | 0.99 |
| Accuracy | 1.00 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mohammad, R.; Saeed, F.; Almazroi, A.A.; Alsubaei, F.S.; Almazroi, A.A. Enhancing Intrusion Detection Systems Using a Deep Learning and Data Augmentation Approach. Systems 2024, 12, 79. https://doi.org/10.3390/systems12030079
Mohammad R, Saeed F, Almazroi AA, Alsubaei FS, Almazroi AA. Enhancing Intrusion Detection Systems Using a Deep Learning and Data Augmentation Approach. Systems. 2024; 12(3):79. https://doi.org/10.3390/systems12030079
Chicago/Turabian StyleMohammad, Rasheed, Faisal Saeed, Abdulwahab Ali Almazroi, Faisal S. Alsubaei, and Abdulaleem Ali Almazroi. 2024. "Enhancing Intrusion Detection Systems Using a Deep Learning and Data Augmentation Approach" Systems 12, no. 3: 79. https://doi.org/10.3390/systems12030079
APA StyleMohammad, R., Saeed, F., Almazroi, A. A., Alsubaei, F. S., & Almazroi, A. A. (2024). Enhancing Intrusion Detection Systems Using a Deep Learning and Data Augmentation Approach. Systems, 12(3), 79. https://doi.org/10.3390/systems12030079