Text-to-Model Transformation: Natural Language-Based Model Generation Framework




Abstract
:1. Introduction
2. A Review of NLP-Based Systems Model Generation
2.1. Rule-Based Approach
2.2. Machine Learning-Based Approach
2.3. Hybrid Approach
2.4. Challenges
3. Automated System Model Generation Framework
3.1. Motivation
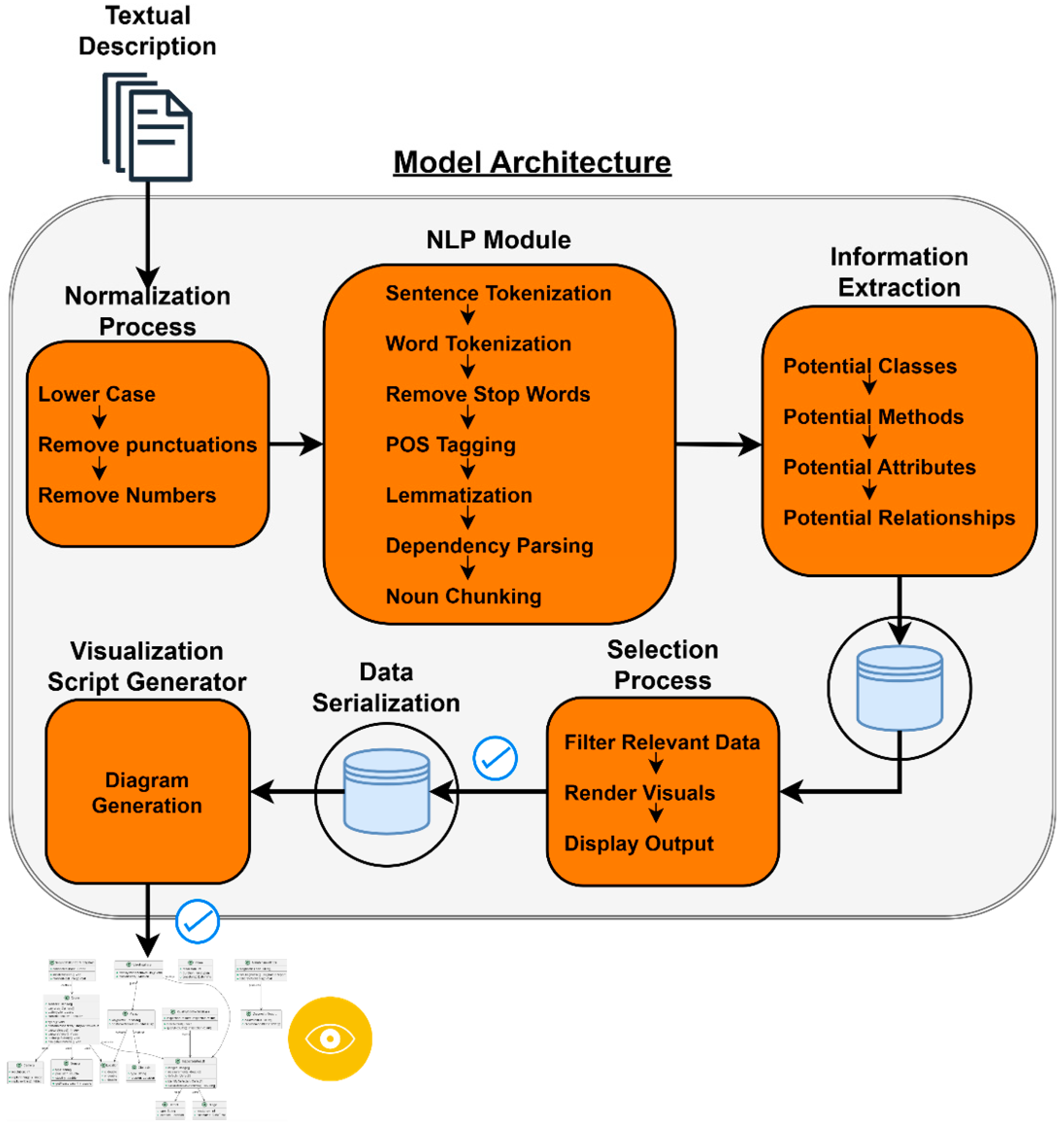
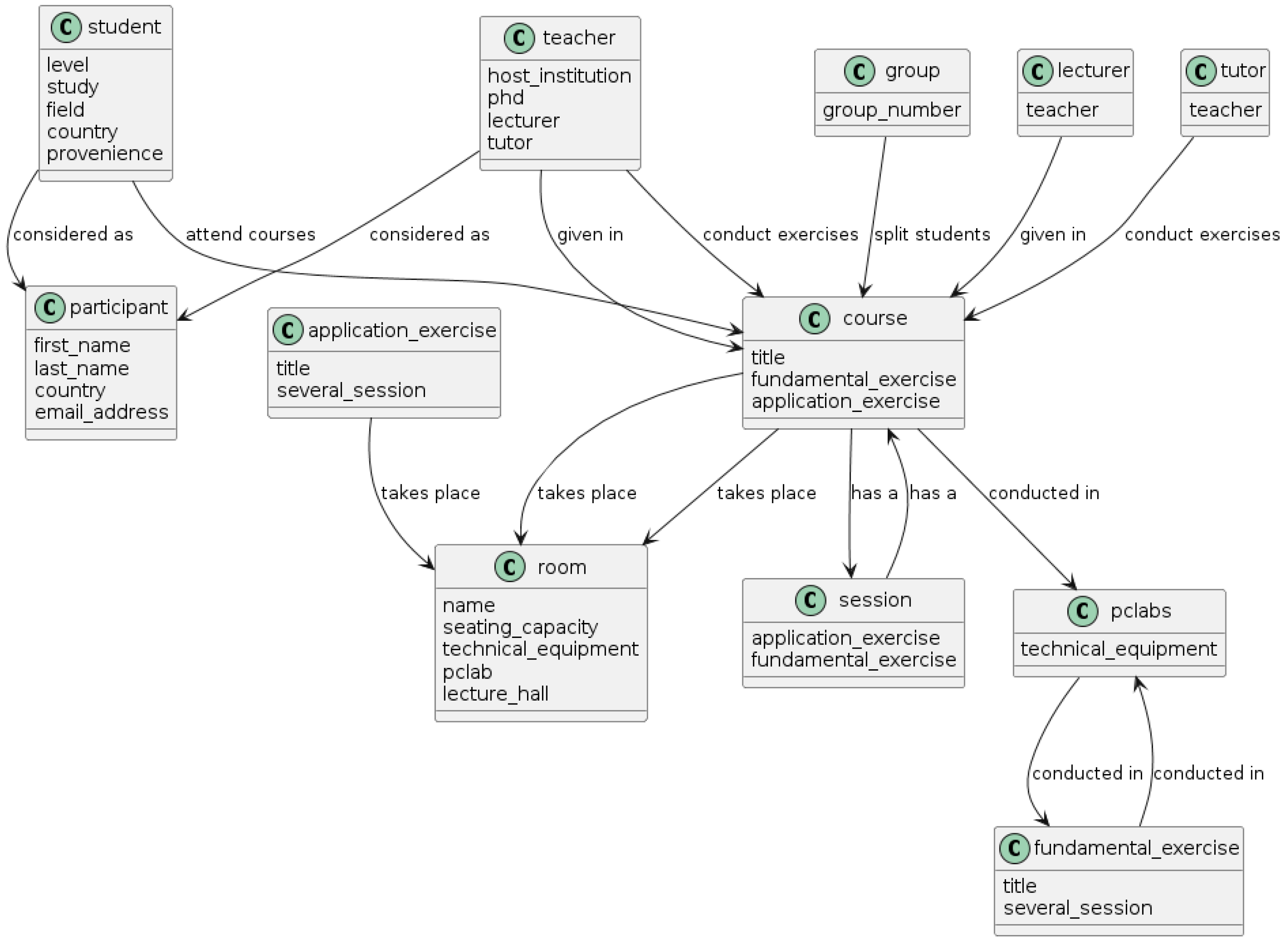
3.2. Model Generation Framework—An Approach to Generate Class/Block Definition Diagram
- Normalization—Step 1
- 2.
- NLP Module—Step 2
- (2a)
- Sentence Tokenization
- (2b)
- Word Tokenization
- (2c)
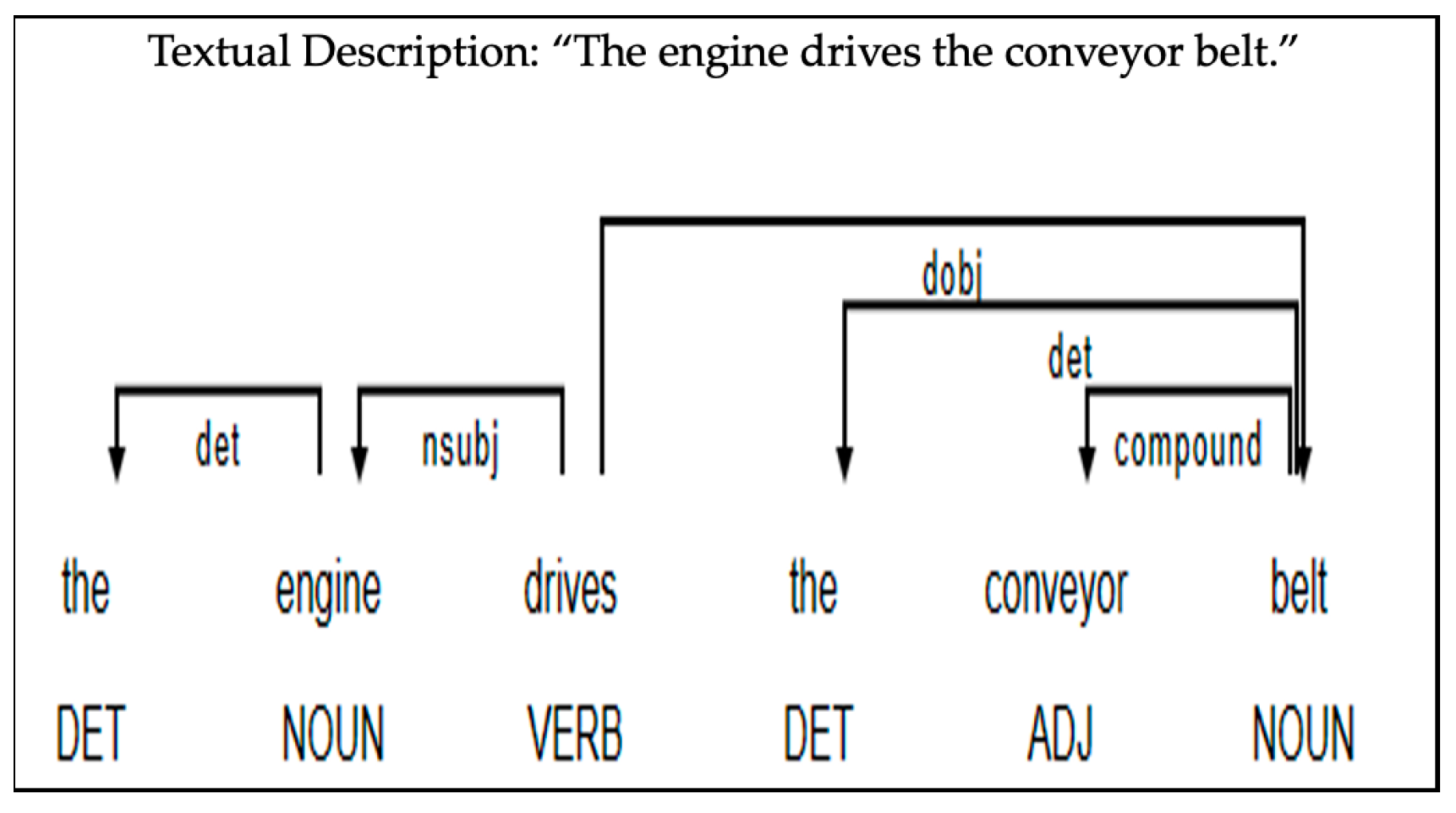
- Part-of-Speech (POS) Tagging
- (2d)
- Lemmatization
- (2e)
- Dependency Parsing
- (2f)
- Noun Chunking
- 3.
- Information Extraction—Step 3
- (3a)
- Extracting Potential Classes
- Class rule 1: If the POS tag contains [NOUNS] or [PROPN—Proper Noun], singular nouns are extracted for potential classes, capturing the lemmatized noun. These singular nouns form the base of potential class identification.
- Class rule 2: Multiword nouns adjacent to each other, which represent class names such as [NOUN] [NOUN] or [NOUN] [PROPN], are extracted.
- Class rule 3: Noun chunks that contain [NOUNS] and their modifiers are extracted to capture a class description. These chunks include a combination of [NOUNS] with their modifiers, which can be [VERBS], [ADJ—Adjective], or both their combinations. Noun chunking helps capture the full description of class attributes from simple to complex forms.
- Class rule 4: If the DEP tag, i.e., the syntactic dependency, the relation between tokens contains [NSUBJ—Nominal Subject] and [NSUBJPASS—Nominal Subject Passive], their tokens are extracted for potential classes, capturing the lemmatized token. If modifiers such as [COMPOUNDS] or [ADJ] precede the subjects, the subject and modifier are extracted to create a descriptive entity. These subjects are potential entities since they are assigned to the syntactic heads of nouns or pronouns.
- (3b)
- Extracting Potential Methods
- Method rule 1: Begin by creating a new set at the start of each sentence to capture verb–noun pairs to ensure the sentence is analyzed independently. This step helps prevent duplications in potential method identification and pairs actions with their objects.
- Method rule 2: Singular [VERBS] are identified after iterating over each sentence token and added to the potential method set considering their lemmatized word. The [VERB] is also stored for a possible pairing with the following noun in the next step.
- Method rule 3: Verb–noun pairs are extracted by identifying a [NOUN] or [PROPN] that is found after a [VERB] from the pairing list to capture a potential method by combining an action and their object. This step takes both lemmatized words for the pair.
- Method rule 4: The pairs are then added to a list of potential methods, identifying the actions and their respective objects within the system.
- Method rule 5: To provide deeper insight, this analysis can be extended to capture verb–noun triples that comprise a [VERB], its direct [NOUN], and an additional [NOUN]. This expands the context of understanding an action and extracts additional elements for a system being designed.
- (3c)
- Extracting Potential Attributes
- Attribute rule 1: POS tagging is used to identify [NOUNS] after iterating over each token in a sentence. These nouns are used for the next step to help capture a representative attribute.
- Attribute rule 2: For each [NOUN] captured, children tokens connected to it labeled [ADJ] or [compound] are identified with it. These modifiers provide a descriptive context for the noun.
- Attribute rule 3: The modifiers collected with the noun create a complete attribute phrase. This phrase captures a more sophisticated description of the attribute.
- Attribute rule 4: These attributes are added to a set to ensure each is unique and not duplicated, creating a list of potential attributes.
- (3d)
- Extracting Potential Relationships
- Relationships rule 1: The text is scanned for [VERBS] using the POS tagger, identifying actions within sentences for relationship identification.
- Relationships rule 2: For each [VERB] found, its child tokens are examined to see if it is associated with potential subjects. These subjects are considered among previously identified potential classes, such as [NOUNs] or [PROPN].
- Relationships rule 3: The [VERB] is matched with any potential subjects to see if it acts upon any entity recognized as a class from the previous analysis.
- Relationships rule 4: A relationship entry is created if a match is found, indicating that the subject is recognized as a potential class. This entry pairs the [VERB] in its lemma form with the subject’s text, capturing the action–entity relationship within the relationship set.
- Relationships rule 5: Relationships can be extracted by examining verb–direct object connections, capturing another action–entity within the text.
- Relationships rule 6: For each [VERB] found, its [dobj—direct object] is identified among the verb’s child tokens. If the direct object is found to the verb, they are both paired in their lemma form, creating a relationship entry.
- Relationships rule 7: Another relationship can be formed by identifying a [VERB] and a DEP tag [PREP—Preposition] that follows it. If the [PREP] is present, both [VERB] and [PREP] are paired, creating an association within the text.
- 4.
- Data Selection and Serialization Process
- 5.
- Visualization Script Generator—Step 4
4. Framework Implementation and Case Studies
- Precision = (Number of correct entities detected)/(Total number of correct and incorrect entities detected)
- Recall= (Number of correct entities detected)/(Total numbers of correct entities)
Case Studies
5. Discussion
- The inflexibility of rules in a rule-based system: A uniform set of rules developed for a context in a rule-based approach must accurately consider the language variability among different stakeholders while generating natural language-based text. Machine learning tools and techniques can aid in creating and adjusting rules and recognizing contexts in natural language text to address this inflexibility as data are augmented over time.
- The lack of ability to manually change a diagram once generated by an algorithm: This refers to the need to develop an interactive ML system where one can provide manual input during the training phase to improve accuracy when generating SysML diagrams from natural text. The proposed framework takes a step in this direction by enabling an interactive user interface for users to create a streamlined model.
- The lack of ML models to better interpret natural language nuances: This refers to the lack of advanced ML models that can capture contexts and compound semantics from natural language text in the context of SysML. This stresses the importance of deep learning models such as transformers [48] designed to understand context more effectively, leading to the development of famous large language models like GPTs (generative pretrained transformers). A similar model could be developed for tasks such as SysML diagram generation.
6. Scalability
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Qie, Y.; Zhu, W.; Liu, A.; Zhang, Y.; Wang, J.; Li, T.; Li, Y.; Ge, Y.; Wang, Y. A Deep Learning Based Framework for Textual Requirement Analysis and Model Generation. In Proceedings of the 2018 IEEE CSAA Guidance, Navigation and Control Conference (GNCC), Xiamen, China, 10–12 August 2018; pp. 1–6. [Google Scholar]
- Theobald, M.; Tatibouet, J. Using fUML Combined with a DSML: An Implementation using Papyrus UML/SysML Modeler. In Proceedings of the 7th International Conference on Model-Driven Engineering and Software Development, Prague, Czech Republic, 20–22 February 2019; pp. 248–255. [Google Scholar]
- Zhao, L.; Alhoshan, W.; Ferrari, A.; Letsholo, K.J.; Ajagbe, M.A.; Chioasca, E.-V.; Batista-Navarro, R.T. Natural language processing for requirements engineering: A systematic mapping study. ACM Comput. Surv. (CSUR) 2021, 54, 1–41. [Google Scholar] [CrossRef]
- Zhong, S.; Scarinci, A.; Cicirello, A. Natural Language Processing for systems engineering: Automatic generation of Systems Modelling Language diagrams. Knowl.-Based Syst. 2023, 259, 110071. [Google Scholar] [CrossRef]
- Ahmed, S.; Ahmed, A.; Eisty, N.U. Automatic Transformation of Natural to Unified Modeling Language: A Systematic Review. In Proceedings of the 2022 IEEE/ACIS 20th International Conference on Software Engineering Research, Management and Applications (SERA), Las Vegas, NV, USA, 25–27 May 2022; pp. 112–119. [Google Scholar]
- Petrotta, M.; Peterson, T. Implementing Augmented Intelligence In Systems Engineering. INCOSE Int. Symp. 2019, 29, 543. [Google Scholar] [CrossRef]
- Narawita, C.R.; Vidanage, K. UML generator—Use case and class diagram generation from text requirements. Int. J. Adv. ICT Emerg. Reg. (ICTer) 2017, 10, 1–10. [Google Scholar] [CrossRef]
- Hamza, Z.A.; Hammad, M. Generating UML Use Case Models from Software Requirements Using Natural Language Processing. In Proceedings of the 2019 8th International Conference on Modeling Simulation and Applied Optimization (ICMSAO), Manama, Bahrain, 15–17 April 2019; pp. 1–6. [Google Scholar]
- Chen, M.; Bhada, S.V. Converting natural language policy article into MBSE model. INCOSE Int. Symp. 2022, 32, 73–81. [Google Scholar] [CrossRef]
- Shinde, S.K.; Bhojane, V.; Mahajan, P. NLP based Object Oriented Analysis and Design from Requirement Specification. Int. J. Comput. Appl. 2012, 47, 30–34. [Google Scholar] [CrossRef]
- Abdelnabi, E.A.; Maatuk, A.M.; Abdelaziz, T.M.; Elakeili, S.M. Generating UML Class Diagram using NLP Techniques and Heuristic Rules. In Proceedings of the 2020 20th International Conference on Sciences and Techniques of Automatic Control and Computer Engineering (STA), Monastir, Tunisia, 20–22 December 2020; pp. 277–282. [Google Scholar]
- Chen, L.; Zeng, Y. Automatic Generation of UML Diagrams From Product Requirements Described by Natural Language. In Proceedings of the ASME 2009 International Design Engineering Technical Conferences and Computers and Information in Engineering Conference, San Diego, CA, USA, 30 August 2009. [Google Scholar] [CrossRef]
- Meziane, F.; Athanasakis, N.; Ananiadou, S. Generating natural language specifications from UML class diagrams. Requir. Eng. 2008, 13, 1–18. [Google Scholar] [CrossRef]
- Anandha Mala, G.S.; Uma, G.V. Automatic Construction of Object Oriented Design Models [UML Diagrams] from Natural Language Requirements Specification. In PRICAI 2006: Trends in Artificial Intelligence, Proceedings of the 9th Pacific Rim International Conference on Artificial Intelligence, Guilin, China, 7–11 August 2006; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4099, pp. 1155–1159. [Google Scholar] [CrossRef]
- de Biase, M.S.; Marrone, S.; Palladino, A. Towards Automatic Model Completion: From Requirements to SysML State Machines. In Proceedings of the 18th European Dependable Computing Conference (EDCC 2022), Zaragoza, Spain, 12–15 September 2022. [Google Scholar] [CrossRef]
- Dawood, O.S. Toward requirements and design traceability using natural language processing. Eur. J. Eng. Technol. Res. 2018, 3, 42–49. [Google Scholar]
- Frank, E.; Hall, M.A.; Witten, I.H. The WEKA Workbench. Online Appendix for “Data Mining: Practical Machine Learning Tools and Techniques”, 4th ed.; Morgan Kaufmann: Burlington, MA, USA, 2016. [Google Scholar]
- Kochbati, T.; Li, S.; Gérard, S.; Mraidha, C. From User Stories to Models: A Machine Learning Empowered Automation. In Proceedings of the 9th International Conference on Model-Driven Engineering and Software Development, Online Streaming, 8–10 February 2021. [Google Scholar] [CrossRef]
- Chami, M.; Zoghbi, C.; Bruel, J.M. A First Step towards AI for MBSE: Generating a Part of SysML Models from Text Using AI. In Proceedings of the AI4SE 2019: INCOSE Artificial Intelligence for Systems Engineering, Madrid, Spain, 12–13 November 2019. [Google Scholar]
- Riesener, M.; Dölle, C.; Becker, A.; Gorbatcheva, S.; Rebentisch, E.; Schuh, G. Application of natural language processing for systematic requirement management in model-based systems engineering. In Proceedings of the INCOSE International Symposium, Virtual Event, 17–22 July 2021; Volume 31, pp. 806–815. [Google Scholar] [CrossRef]
- Buchmann, R.; Eder, J.; Fill, H.G.; Frank, U.; Karagiannis, D.; Laurenzi, E.; Mylopoulos, J.; Plexousakis, D.; Santos, M.Y. Large language models: Expectations for semantics-driven systems engineering. Data Knowl. Eng. 2024, 152, 102324. [Google Scholar] [CrossRef]
- Seresht, S.M.; Ormandjieva, O. Automated assistance for use cases elicitation from user requirements text. In Proceedings of the 11th Workshop on Requirements Engineering (WER 2008), Barcelona, Spain, 12–13 September 2008; Volume 16, pp. 128–139. [Google Scholar]
- Elallaoui, M.; Nafil, K.; Touahni, R. Automatic Transformation of User Stories into UML Use Case Diagrams using NLP Techniques. Procedia Comput. Sci. 2018, 130, 42–49. [Google Scholar] [CrossRef]
- Osman, M.S.; Alabwaini, N.Z.; Jaber, T.B.; Alrawashdeh, T. Generate use case from the requirements written in a natural language using machine learning. In Proceedings of the 2019 IEEE Jordan International Joint Conference on Electrical Engineering and Information Technology (JEEIT), Amman, Jordan, 9–11 April 2019; pp. 748–751. [Google Scholar]
- Joshi, S.D.; Deshpande, D. Textual Requirement Analysis for UML Diagram Extraction by using NLP. Int. J. Comput. Appl. 2012, 50, 42–46. [Google Scholar] [CrossRef]
- Fantechi, A.; Gnesi, S.; Livi, S.; Semini, L. A spaCy-based tool for extracting variability from NL re-quirements. In Proceedings of the 25th ACM International Systems and Software Product Line Conference—Volume B, Leicester, UK, 6–11 September 2021; pp. 32–35. [Google Scholar]
- Spyder IDE Contributors. Spyder (Version 5.4.1) [Software]. 2023. Available online: https://www.spyder-ide.org/ (accessed on 1 August 2024).
- JetBrain. PyCharm 2023.2.1 (Community Edition) [Software]. Build #PC-232.9559.58, Built on 22 August 2023.. Available online: https://www.jetbrains.com/pycharm/ (accessed on 1 August 2024).
- PlantUML Integration. PlantUML Integration (Version 7.0.0-IJ2023.2) for PyCharm [Software Plugin]. 2023. Available online: https://plugins.jetbrains.com/plugin/7017-plantuml-integration (accessed on 1 August 2024).
- Claghorn, R.; Shubayli, H. Requirement Patterns in the Construction Industry. In Proceedings of the INCOSE International Symposium, Virtual Event, 17–22 July 2021; Volume 31, pp. 391–408. [Google Scholar] [CrossRef]
- Kulkarni, A.; Shivananda, A. Natural Language Processing Recipes; Apress: Berkeley, CA, USA, 2019. [Google Scholar]
- Octavially, R.P.; Priyadi, Y.; Widowati, S. Extraction of Activity Diagrams Based on Steps Performed in Use Case Description Using Text Mining (Case Study: SRS Myoffice Application). In Proceedings of the 2022 2nd International Conference on Electronic and Electrical Engineering and Intelligent System (ICE3IS), Yogyakarta, Indonesia, 4–5 November 2022; pp. 225–230. [Google Scholar]
- Mande, R.; Yelavarti, K.C.; JayaLakshmi, G. Regular Expression Rule-Based Algorithm for Multiple Documents Key Information Extraction. In Proceedings of the 2018 International Conference on Smart Systems and Inventive Technology (ICSSIT), Tirunelveli, India, 13–14 December 2018; pp. 262–265. [Google Scholar]
- Ismukanova, A.N.; Lavrov, D.N.; Keldybekova, L.M.; Mukumova, M.Z. Using the python library when classifying scientific texts. In European Research: Innovation in Science, Education and Technology; 2018; pp. 9–13. Available online: https://internationalconference.ru/images/PDF/2018/46/using-the-python-1.pdf (accessed on 1 August 2024).
- Srinivasa-Desikan, B. Natural Language Processing and Computational Linguistics: A Practical Guide to Text Analysis with Python, GenSim, SpaCy, and Keras; Packt Publishing Ltd.: Birmingham, UK, 2018. [Google Scholar]
- Jugran, S.; Kumar, A.; Tyagi, B.S.; Anand, V. Extractive automatic text summarization using SpaCy in Python & NLP. In Proceedings of the 2021 International Conference on Advance Computing and Innovative Technologies in Engineering (ICACITE), Greater Noida, India, 4–5 March 2021; pp. 582–585. [Google Scholar]
- Uysal, A.K.; Gunal, S. The impact of preprocessing on text classification. Inf. Process. Manag. 2014, 50, 104–112. [Google Scholar] [CrossRef]
- Explosion AI. SpaCy: Industrial-Strength Natural Language Processing in Python. 4 April 2024. Available online: https://spacy.io (accessed on 1 August 2024).
- Vasiliev, Y. Natural Language Processing with Python and SpaCy: A practical Introduction; No Starch Press: San Francisco, CA, USA, 2020. [Google Scholar]
- Bashir, N.; Bilal, M.; Liaqat, M.; Marjani, M.; Malik, N.; Ali, M. Modeling class diagram using NLP in object-oriented designing. In Proceedings of the 2021 National Computing Colleges Conference (NCCC), Taif, Saudi Arabia, 27–28 March 2021; pp. 1–6. [Google Scholar]
- Shuttleworth, D.; Padilla, J. From Narratives to Conceptual Models via Natural Language Processing. In Proceedings of the 2022 Winter Simulation Conference (WSC), Singapore, 11–14 December 2022; pp. 2222–2233. [Google Scholar] [CrossRef]
- Herchi, H.; Abdessalem, W.B. From user requirements to UML class diagram. arXiv 2012, arXiv:1211.0713. [Google Scholar]
- Almazroi, A.A.; Abualigah, L.; Alqarni, M.A.; Houssein, E.H.; AlHamad, A.Q.M.; Elaziz, M.A. Class diagram generation from text requirements: An application of natural language processing. In Deep Learning Approaches for Spoken and Natural Language Processing; Springer: Cham, Switzerland, 2021; pp. 55–79. [Google Scholar]
- Arachchi, K.D. AI Based UML Diagrams Generator. Ph.D. Thesis, University of Colombo School of Computing, Colombo, Srilanka, 19 August 2022. [Google Scholar]
- PlantUML. Available online: https://plantuml.com/ (accessed on 1 August 2024).
- Bozyiğit, F. Object Oriented Analysis and Source Code Validation Using Natural Language Processing. Ph.D. Thesis, Dokuz Eylül University, Izmir, Turkey, 2019. [Google Scholar]
- Baginski, J. Text Analytics for Conceptual Modelling. Master’s Thesis, University of Vienna, Vienna, Austria, 2018. [Google Scholar]
- Islam, S.; Elmekki, H.; Elsebai, A.; Bentahar, J.; Drawel, N.; Rjoub, G.; Pedrycz, W. A comprehensive survey on applications of transformers for deep learning tasks. Expert Syst. Appl. 2024, 241, 122666. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Components of a Class Diagram | Classification Rules |
|---|---|
| Classes | NN + NNP + VBP; NN + NNP; NNP + NN + VBZ; NN + VBZ, base form + NN; NNP + NNS, NNP + NN, NNS, NNP + NNS; NNP, NNP + VBZ past tense |
| Methods | NN + NN + NNP; NNP + NNP + NN + NN; non-3rd person singular present VBP + NN; third person singular present VBZ + NN + NN; non-third person singular present VBP + CC + NN + any words; IN + JJ + NN |
| Attributes | JJ + NN |
| Relationships | VBP + NN; VBP + NNP; VBP + VBG |
| Diagram Type | Associated Challenges |
|---|---|
| Use Case Diagrams |
|
| Activity and Sequence Diagrams |
|
| Class Diagram |
|
| Package Diagram |
|
| Block Definition Diagram | |
| Requirement Diagram |
|
| Internal Block Diagram |
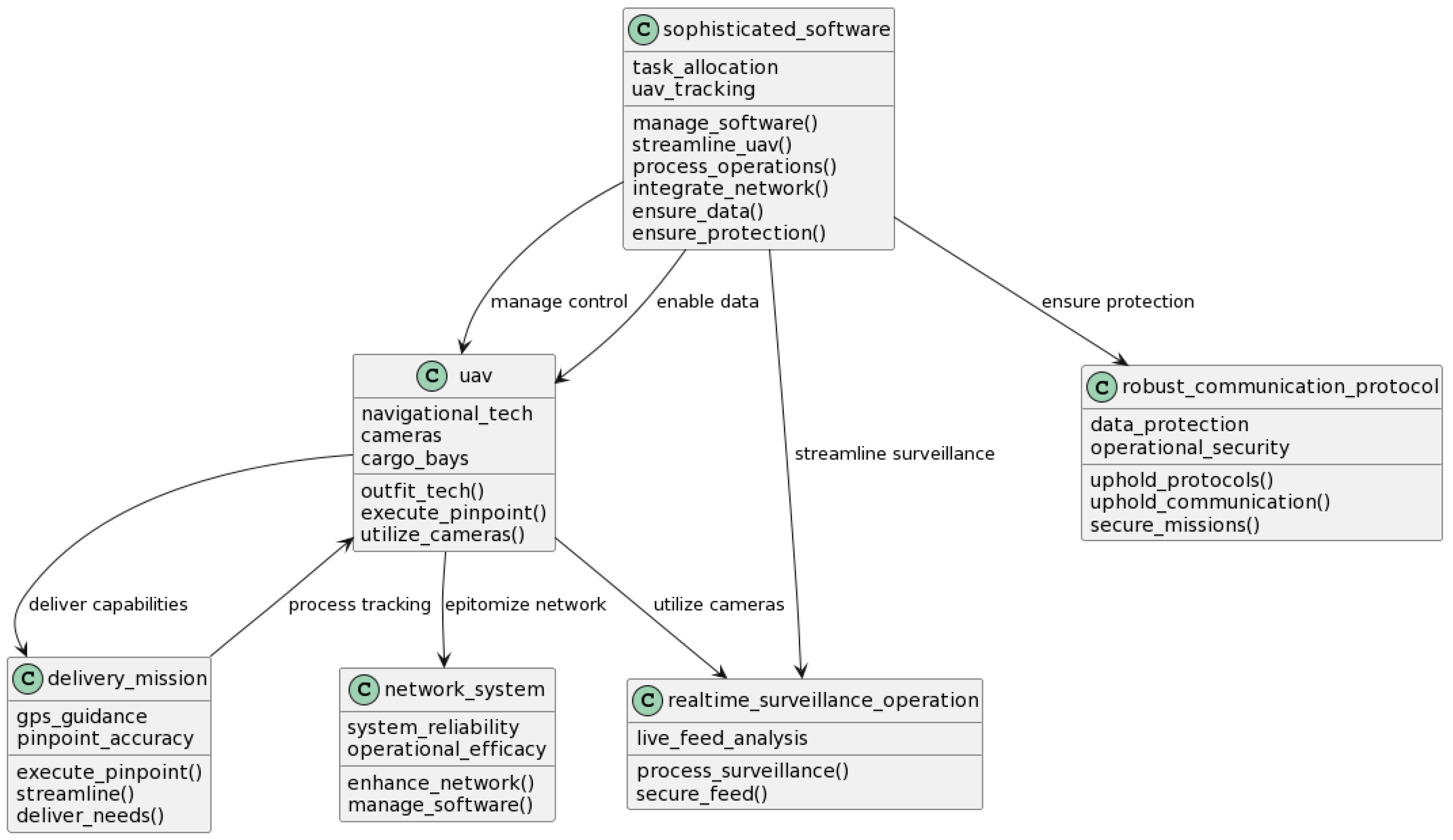
| Segmented Sentences from Requirements Sentence # 1: The system integrates a sophisticated UAV network, streamlining both surveillance and logistical deliveries. Sentence # 2: Each UAV, at the core of the network, is outfitted with leading-edge navigational tech and cameras for comprehensive monitoring tasks, alongside cargo bays designed for precise delivery missions. | |||
| Classes | Extracted Classes | Precision | Recall |
| System; UAV; network; surveillance; logistical delivery | ‘delivery’, ‘network’, ‘system’, ‘sophisticated uav network’, ‘surveillance’, ‘logistical delivery’ | 0.66 | 1.0 |
| UAV; network; navigational tech; camera; monitoring task; cargo bay; delivery mission | ‘delivery mission’, ‘tech’, ‘uav’, ‘delivery’, ‘comprehensive monitoring task’, ‘leading edge navigational tech’, ‘core’, ‘monitoring task’, ‘leadingedge’, ‘task’, ‘network’, ‘bay’, ‘monitoring’, ‘cargo’, ‘mission’, ‘camera’, ‘precise delivery mission’, ‘cargo bay’ | 0.38 | 1.0 |
| Methods | Extracted Methods | Precision | Recall |
| Integrates network; surveillance; deliveries | ‘streamline’, ‘streamline surveillance’, ‘integrate network’, ‘integrate’, ‘streamline deliveries’ | 0.6 | 1.0 |
| Tech; cameras; monitoring; task; delivery | ‘design’, ‘outfit’, ‘design delivery’, ‘design missions’, ‘outfit cameras’, ‘outfit tech’, ‘outfit cargo’, ‘outfit monitoring’, ‘outfit bays’, ‘outfit leadingedge’, ‘outfit tasks’ | 0.45 | 1.0 |
| Attributes | Extracted Attributes | Precision | Recall |
| UAV network; logistical delivery; surveillance | ‘logistical deliveries’, ‘system’, ‘sophisticated uav network’, ‘surveillance’ | 0.75 | 1.0 |
| Navigational tech; monitoring task; precise delivery; cargo bays; cameras | ‘monitoring tasks’, ‘uav’, ‘delivery’, ‘core’, ‘network’, ‘monitoring’, ‘cargo’, ‘navigational tech’, ‘cargo bays’, ‘precise delivery missions’, ‘cameras’ | 0.45 | 1.0 |
| Relationships | Extracted Relationships | Precision | Recall |
| System integrates; integrates network; integrates; streamline | ‘streamline surveillance’, ‘streamlining’, ‘integrates’, ‘integrate system’, ‘integrate network’ | 0.8 | 1.0 |
| outfitted with; designed for; outfitted | ‘outfitted with’, ‘outfit uav’, ‘design for’, ‘outfitted’ | 0.75 | 1.0 |
| Text 1 | Text 2 | |||
|---|---|---|---|---|
| Extracted Elements | Precision | Recall | Precision | Recall |
| Classes/Entities | 0.5 | 1.0 | 0.17 | 1.0 |
| Attributes | 0.57 | 1.0 | 0.45 | 0.96 |
| Relationships | 0.58 | 1.0 | 0.18 | 0.93 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Akundi, A.; Ontiveros, J.; Luna, S. Text-to-Model Transformation: Natural Language-Based Model Generation Framework. Systems 2024, 12, 369. https://doi.org/10.3390/systems12090369
Akundi A, Ontiveros J, Luna S. Text-to-Model Transformation: Natural Language-Based Model Generation Framework. Systems. 2024; 12(9):369. https://doi.org/10.3390/systems12090369
Chicago/Turabian StyleAkundi, Aditya, Joshua Ontiveros, and Sergio Luna. 2024. "Text-to-Model Transformation: Natural Language-Based Model Generation Framework" Systems 12, no. 9: 369. https://doi.org/10.3390/systems12090369
APA StyleAkundi, A., Ontiveros, J., & Luna, S. (2024). Text-to-Model Transformation: Natural Language-Based Model Generation Framework. Systems, 12(9), 369. https://doi.org/10.3390/systems12090369