
Leveraging Text Mining Techniques for Civil Aviation Service Improvement: Research on Key Topics and Association Rules of Passenger Complaints


Abstract
:1. Introduction
- What are the main topics of passenger complaints in public air transport?
- What are the causes or triggering mechanisms of service problems reflected in the topic of passenger complaints?
- How can we prevent or deal with identified service problems in public air transportation?
2. Literature Review
2.1. Complaint Application Research
2.2. Sentiment Analysis
2.3. Topic Modeling
2.4. Association Rule Mining
2.5. Summary and Contribution
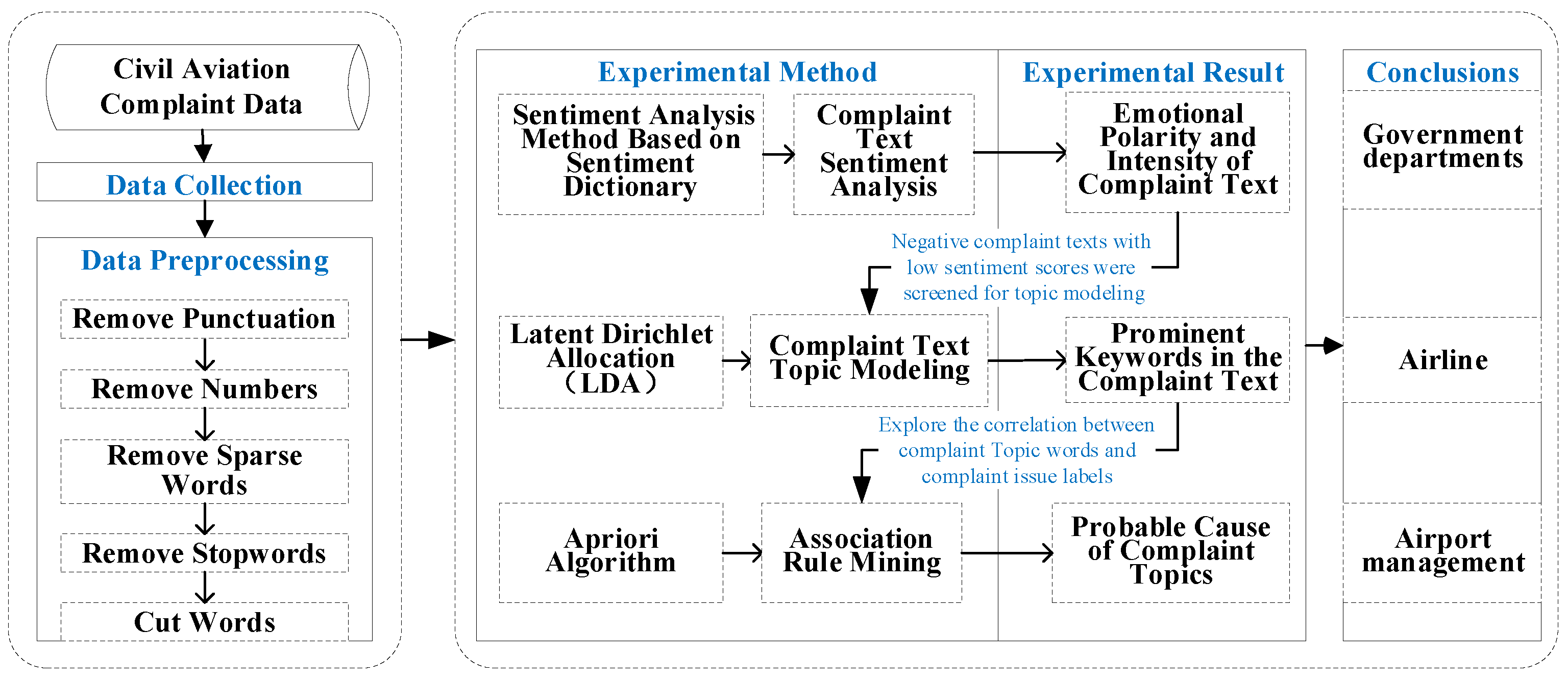
3. Model Methodology and Data
3.1. Model Methodology
3.2. Data Collection
3.3. Sentiment Calculation and Topic Modeling Methods
- Generate the topic distribution (m) of document (m) by sampling from the prior Dirichlet distribution ().
- Generate the topic (Zm,n) of the (n) word of document (m) by sampling from the polynomial distribution of topics (m).
- Generate the word distribution () of the topic (Zm,n) by sampling from the Dirichlet distribution () of the words.
- Sample from the polynomial distribution of the words () to finally generate the words (Wm,n).
3.4. Classical Algorithm for Association Rule Mining
4. Experimental Results and Analysis
4.1. Data Preprocessing
- Remove punctuation: We remove useless punctuation, such as [ !"♯)
- Remove numbers: Numbers mentioned in the text, such as phone numbers, ticket numbers, and mailbox numbers, are not needed; therefore, such elements are removed.
- Remove sparse words: Sometimes removing sparse words from the text data is necessary, which may include names of people, countries, cities, airports, etc.
- Remove stopwords: Stopwords are common intonational words used in language; we remove these words because they do not convey important semantic content.
- Cut words: The “jieba” python library based on Python third-party libraries is used for Chinese segmentation, and cuts the complaint text precisely.
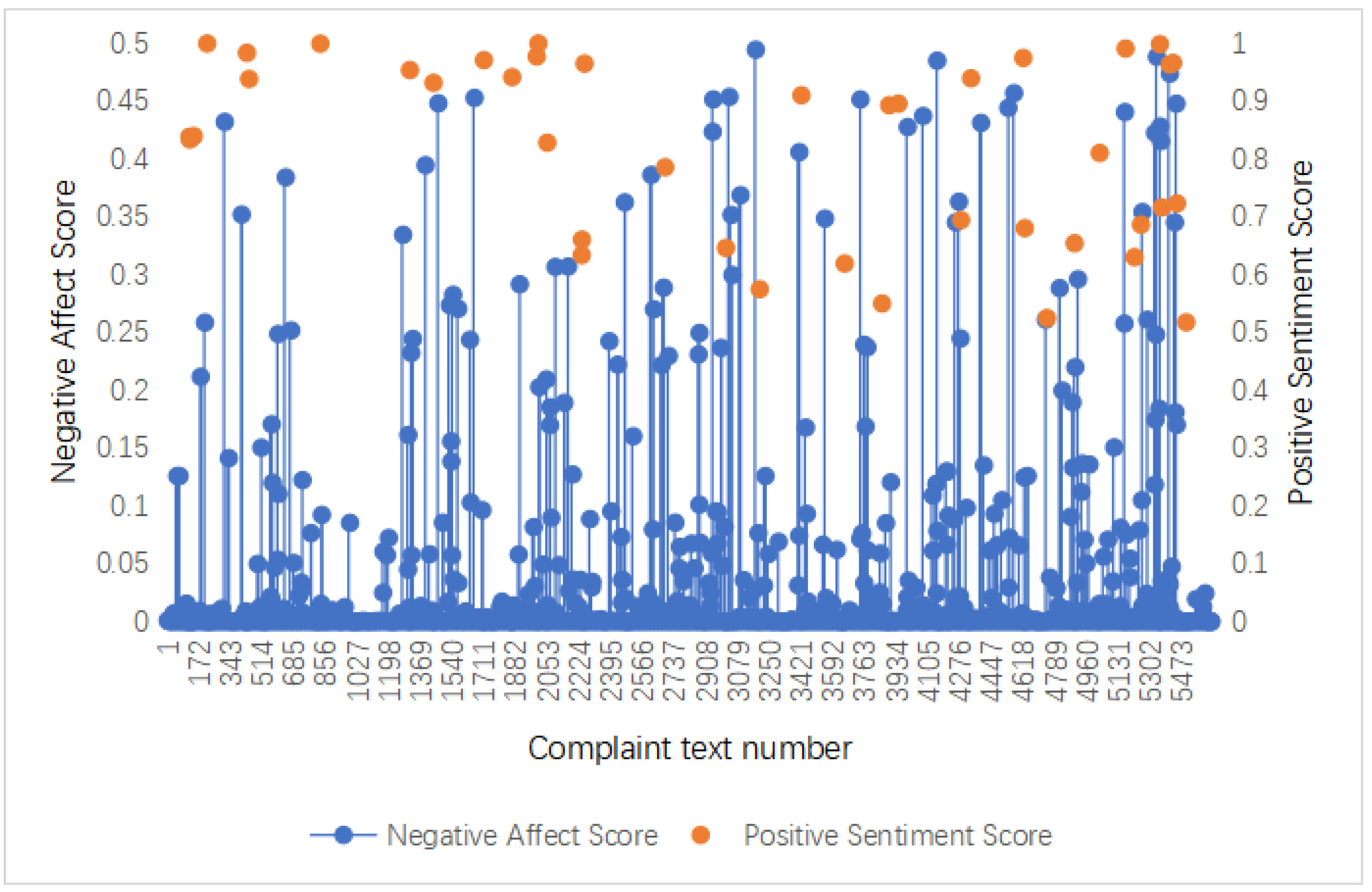
4.2. Sentiment Analysis of Text Based on a Sentiment Dictionary
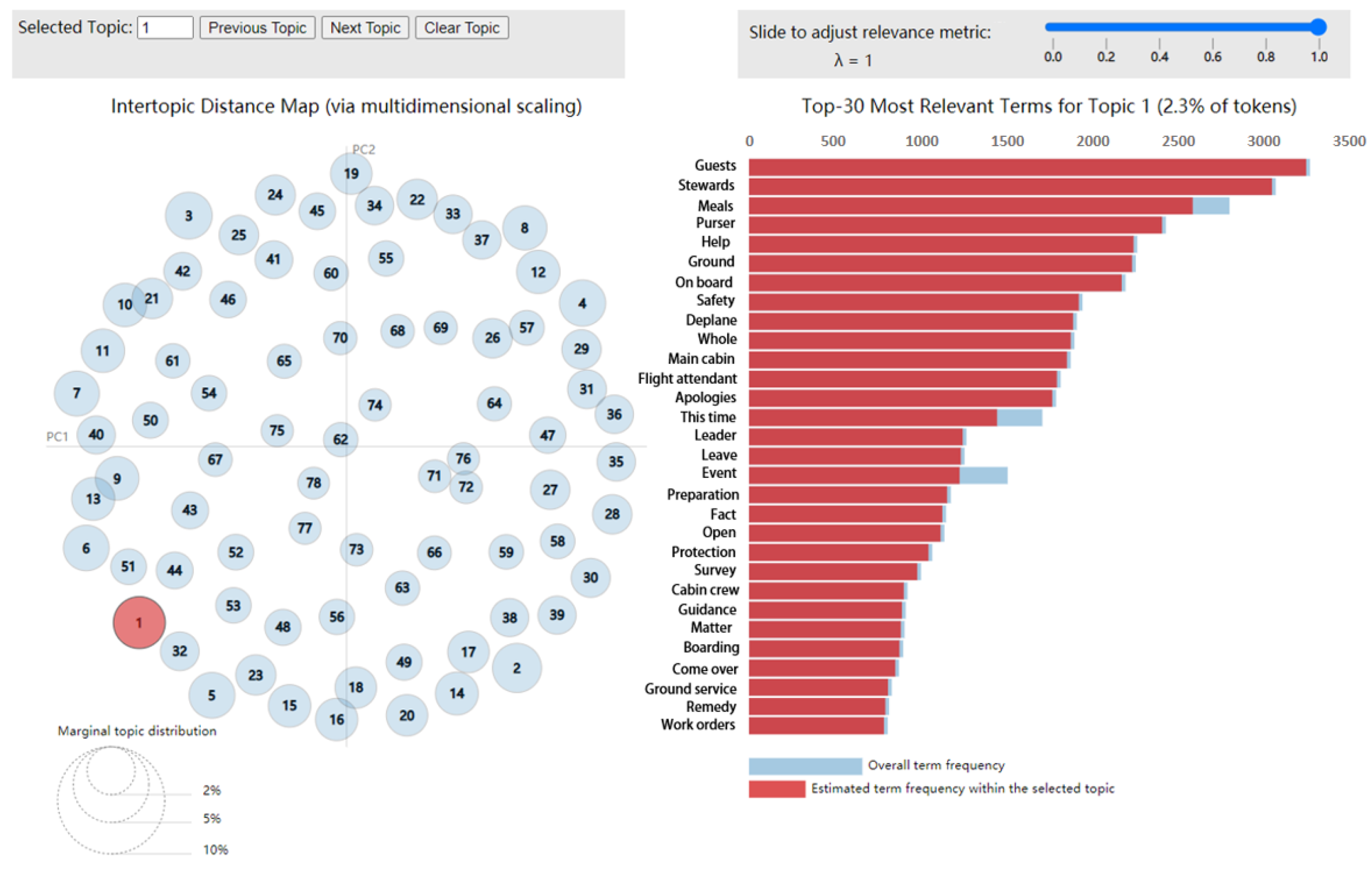
4.3. Text Topic Modeling Based on the LDA and LSA Models
4.3.1. Experimental Comparison of LDA and LSA Models
4.3.2. Discovered Topics
4.4. Mining Association Rules Based on the Apriori and FP-Growth Algorithms
4.4.1. Association Rule Results
4.4.2. Analyzing the Results of the Association Rules
5. Conclusions and Suggestions for Improvement
- We developed effective association rules with high frequencies and strong correlations.
- The topics with a high intensity of negative sentiments were mostly ticketing service problems or abnormal flight service problems.
- There were mainly refunding disputes due to sick refunds, price differences, handling fees, and wrong purchases.
- There were compensation disputes due to baggage damage, delays, missed flights, check-in issues, and other factors.
6. Limitations and Future Works
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Singh, A.; Saha, S.; Hasanuzzaman, M.; Jangra, A. Identifying complaints based on semi-supervised mincuts. Expert Syst. Appl. 2021, 186, 115668. [Google Scholar] [CrossRef]
- Li, Q.; Yang, Y.; Li, C.; Zhao, G. Energy vehicle user demand mining method based on fusion of online reviews and complaint information. Energy Rep. 2023, 9, 3120–3130. [Google Scholar] [CrossRef]
- Yan, N.; Xu, X.; Tong, T.; Huang, L. Examining consumer complaints from an on-demand service platform. Int. J. Prod. Econ. 2021, 237, 108153. [Google Scholar] [CrossRef]
- Siering, M. Explainability and fairness of RegTech for regulatory enforcement: Automated monitoring of consumer complaints. Decis. Support Syst. 2022, 158, 113782. [Google Scholar] [CrossRef]
- Coussement, K.; Van den Poel, D. Improving customer complaint management by automatic email classification using linguistic style features as predictors. Decis. Support Syst. 2008, 44, 870–882. [Google Scholar] [CrossRef]
- Chow, C.K.W. On-time performance, passenger expectations and satisfaction in the Chinese airline industry. J. Air Transp. Manag. 2015, 47, 39–47. [Google Scholar] [CrossRef]
- Kim, J.; Lim, C. Customer complaints monitoring with customer review data analytics: An integrated method of sentiment and statistical process control analyses. Adv. Eng. Inform. 2021, 49, 101304. [Google Scholar] [CrossRef]
- Sann, R.; Lai, P.-C.; Liaw, S.-Y. Online complaining behavior: Does cultural background and hotel class matter? J. Hosp. Tour. Manag. 2020, 43, 80–90. [Google Scholar] [CrossRef]
- Ghazzawi, A.; Alharbi, B. Analysis of Customer Complaints Data using Data Mining Techniques. Procedia Comput. Sci. 2019, 163, 62–69. [Google Scholar] [CrossRef]
- Eshaghi, M.S.; Afshardoost, M.; Lohmann, G.; Moyle, B.D. Drivers and outcomes of airline passenger satisfaction: A Meta-analysis. J. Air Transp. Res. Soc. 2024, 3, 100034. [Google Scholar] [CrossRef]
- Pereira, F.; Costa, J.M.; Ramos, R.; Raimundo, A. The impact of the COVID-19 pandemic on airlines’ passenger satisfaction. J. Air Transp. Manag. 2023, 112, 102441. [Google Scholar] [CrossRef] [PubMed]
- Sharan, S.; Surya, R. Passenger intelligence as a competitive opportunity: Unsupervised text analytics for discovering airline-specific insights from online reviews. Ann. Oper. Res. 2024, 333, 1045–1075. [Google Scholar]
- Xie, H.; Li, Y.; Pu, Y.; Zhang, C.; Huang, J. Evaluating airline service quality through a comprehensive text-mining and multi-criteria decision-making analysis. J. Air Transp. Manag. 2024, 120, 102655. [Google Scholar] [CrossRef]
- Diana, T. Using sentiment analysis to reinforce learning: The case of airport community engagement. J. Air Transp. Manag. 2022, 102, 102228. [Google Scholar] [CrossRef]
- Li, H.; Liu, H.; Zhang, Z. Online persuasion of review emotional intensity: A text mining analysis of restaurant reviews. Int. J. Hosp. Manag. 2020, 89, 102558. [Google Scholar] [CrossRef]
- Martin-Domingo, L.; Martín, J.C.; Mandsberg, G. Social media as a resource for sentiment analysis of Airport Service Quality (ASQ). J. Air Transp. Manag. 2019, 78, 106–115. [Google Scholar] [CrossRef]
- Oliveira, A.V.M.; Oliveira, B.F.; Vassallo, M.D. Airport service quality perception and flight delays: Examining the influence of psychosituational latent traits of respondents in passenger satisfaction surveys. Res. Transp. Econ. 2023, 102, 101371. [Google Scholar] [CrossRef]
- Iddrisu, A.M.; Mensah, S.; Boafo, F.; Yeluripati, G.R.; Kudjo, P. A sentiment analysis framework to classify instances of sarcastic sentiments within the aviation sector. Int. J. Inf. Manag. Data Insights 2023, 3, 100180. [Google Scholar] [CrossRef]
- Chang, Y.-C.; Ku, C.-H.; Le Nguyen, D.-D. Predicting aspect-based sentiment using deep learning and information visualization: The impact of COVID-19 on the airline industry. Inf. Manag. 2022, 59, 103587. [Google Scholar] [CrossRef]
- Piccinelli, S.; Moro, S.; Rita, P. Air-travelers’ concerns emerging from online comments during the COVID-19 outbreak. Tour. Manag. 2021, 85, 104313. [Google Scholar] [CrossRef]
- Hasib, K.M. Sentiment Analysis on Bangladesh Airlines Review Data using Machine Learning. Master’s Thesis, Bangladesh University of Business and Technology, Dhaka, Bangladesh, 2022. [Google Scholar]
- Lee, K.; Yu, C. Assessment of airport service quality: A complementary approach to measure perceived service quality based on Google reviews. J. Air Transp. Manag. 2018, 71, 28–44. [Google Scholar] [CrossRef]
- Song, C.; Guo, J. Analyzing passengers’ emotions following flight delays—A 2011–2019 case study on SKYTRAX comments. J. Air Transp. Manag. 2020, 89, 101903. [Google Scholar] [CrossRef]
- Pu, X.; Jiang, Q.; Fan, B. Chinese public opinion on Japan’s nuclear wastewater discharge: A case study of Weibo comments based on a thematic model. Ocean Coast. Manag. 2022, 225, 106188. [Google Scholar] [CrossRef]
- Dong, Y.; Li, Y.; Cao, J.; Zhang, N.; Sha, K. Identification and evaluation of competitive products based on online user-generated content. Expert Syst. Appl. 2023, 225, 120168. [Google Scholar] [CrossRef]
- Prabha, S.; Sardana, N. Question Tags or Text for Topic Modeling: Which is better. Procedia Comput. Sci. 2023, 218, 2172–2180. [Google Scholar] [CrossRef]
- Steyvers, M. Combining feature norms and text data with topic models. Acta Psychol. 2010, 133, 234–243. [Google Scholar] [CrossRef]
- Arun, R.; Suresh, V.; Veni, M.C.E.; Narasimha, M.M. On Finding the Natural Number of Topics with Latent Dirichlet Allocation: Some Observations. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Hyderabad, India, 21–24 June 2010. [Google Scholar]
- Kim, D.; Lim, C.; Ha, H.-K. Comparative analysis of changes in passenger’s perception for airline companies’ service quality before and during COVID-19 using topic modeling. J. Air Transp. Manag. 2024, 115, 102542. [Google Scholar] [CrossRef]
- Song, C.; Ma, X.; Ardizzone, C.; Zhuang, J. The adverse impact of flight delays on passenger satisfaction: An innovative prediction model utilizing wide & deep learning. J. Air Transp. Manag. 2024, 114, 102511. [Google Scholar]
- Korfiatis, N.; Stamolampros, P.; Kourouthanassis, P.; Sagiadinos, V. Measuring service quality from unstructured data: A topic modeling application on airline passengers’ online reviews. Expert Syst. Appl. 2019, 116, 472–486. [Google Scholar] [CrossRef]
- Kumar, S.; Zymbler, M. A machine learning approach to analyze customer satisfaction from airline tweets. J. Big Data 2019, 6, 62. [Google Scholar] [CrossRef]
- Farzadnia, S.; Vanani, I.R.; Hanafizadeh, P. An experimental study for identifying customer prominent viewpoints on different flight classes by topic modeling methods. Int. J. Inf. Manag. Data Insights 2024, 4, 100223. [Google Scholar] [CrossRef]
- Abdelrazek, A.; Eid, Y.; Gawish, E.; Medhat, W. Topic modeling algorithms and applications: A survey. Inf. Syst. 2023, 112, 102131. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Annisa, R.; Surjandari, I. Opinion Mining on Mandalika Hotel Reviews Using Latent Dirichlet Allocation. Procedia Comput. Sci. 2019, 161, 739–746. [Google Scholar] [CrossRef]
- Farzadnia, S.; Raeesi Vanani, I. Identification of opinion trends using sentiment analysis of airlines passengers’ reviews. J. Air Transp. Manag. 2022, 103, 102232. [Google Scholar] [CrossRef]
- Lucini, F.R.; Tonetto, L.M.; Fogliatto, F.S.; Anzanello, M.J. Text mining approach to explore dimensions of airline customer satisfaction using online customer reviews. J. Air Transp. Manag. 2020, 83, 101760. [Google Scholar] [CrossRef]
- Wang, W.; Feng, Y.; Dai, W. Topic analysis of online reviews for two competitive products using latent Dirichlet allocation. Electron. Commer. Res. Appl. 2018, 29, 142–156. [Google Scholar] [CrossRef]
- Du, Y.; Yi, Y.; Li, X.; Chen, X.; Fan, Y.; Su, F. Extracting and tracking hot topics of micro-blogs based on improved Latent Dirichlet Allocation. Eng. Appl. Artif. Intell. 2020, 87, 103279. [Google Scholar] [CrossRef]
- Bastani, K.; Namavari, H.; Shaffer, J. Latent Dirichlet allocation (LDA) for topic modeling of the CFPB consumer complaints. Expert Syst. Appl. 2019, 127, 256–271. [Google Scholar] [CrossRef]
- Pérez, J.; Pérez, A.; Casillas, A.; Gojenola, K. Cardiology record multi-label classification using latent Dirichlet allocation. Comput. Methods Programs Biomed. 2018, 164, 111–119. [Google Scholar] [CrossRef]
- Xie, R.; Chu, S.K.W.; Chiu, D.K.W.; Wang, Y. Exploring Public Response to COVID-19 on Weibo with LDA Topic Modeling and Sentiment Analysis. Data Inf. Manag. 2021, 5, 86–99. [Google Scholar] [CrossRef]
- Madzík, P.; Falát, L.; Zimon, D. Supply chain research overview from the early eighties to Covid era—Big data approach based on Latent Dirichlet Allocation. Comput. Ind. Eng. 2023, 183, 109520. [Google Scholar] [CrossRef]
- Rkia, A.; Fatima-Azzahrae, A.; Mehdi, A.; Lily, L. NLP and Topic Modeling with LDA, LSA, and NMF for Monitoring Psychosocial Well-being in Monthly Surveys. Procedia Comput. Sci. 2024, 251, 398–405. [Google Scholar] [CrossRef]
- Sokhangoee, Z.F.; Rezapour, A. A novel approach for spam detection based on association rule mining and genetic algorithm. Comput. Electr. Eng. 2022, 97, 107655. [Google Scholar] [CrossRef]
- Fister, I.; Fister, I.; Fister, D.; Podgorelec, V.; Salcedo-Sanz, S. A comprehensive review of visualization methods for association rule mining: Taxonomy, challenges, open problems and future ideas. Expert Syst. Appl. 2023, 233, 120901. [Google Scholar] [CrossRef]
- Telikani, A.; Gandomi, A.H.; Shahbahrami, A. A survey of evolutionary computation for association rule mining. Inf. Sci. 2020, 524, 318–352. [Google Scholar] [CrossRef]
- Agrawal, R.; Imieliński, T.; Swami, A. Mining association rules between sets of items in large databases. SIGMOD Rec. 1993, 22, 207–216. [Google Scholar] [CrossRef]
- Huang, D.; Liang, T.; Hu, S.; Loughney, S.; Wang, J. Characteristics analysis of intercontinental sea accidents using weighted association rule mining: Evidence from the Mediterranean Sea and Black Sea. Ocean Eng. 2023, 287, 115839. [Google Scholar] [CrossRef]
- Xiao, Q.; Luo, F.; Li, Y.; Pan, D. Risk prediction and early warning of pilots’ unsafe behaviors using association rule mining and system dynamics. J. Air Transp. Manag. 2023, 110, 102422. [Google Scholar] [CrossRef]
- Li, L.; Guo, H.; Cheng, L.; Li, S.; Lin, H. Research on causes of coal mine gas explosion accidents based on association rule. J. Loss Prev. Process Ind. 2022, 80, 104879. [Google Scholar] [CrossRef]
- Gakii, C.; Rimiru, R. Identification of cancer related genes using feature selection and association rule mining. Inform. Med. Unlocked 2021, 24, 100595. [Google Scholar] [CrossRef]
- Shabtay, L.; Fournier-Viger, P.; Yaari, R.; Dattner, I. A guided FP-Growth algorithm for mining multitude-targeted item-sets and class association rules in imbalanced data. Inf. Sci. 2021, 553, 353–375. [Google Scholar] [CrossRef]
- Fu, H.; Li, Y.; Sun, X. Design and Implementation of Rapid Information Acquisition and Analysis System. In Proceedings of the 2019 15th International Conference on Computational Intelligence and Security (CIS), Macau, China, 13–16 December 2019; pp. 399–401. [Google Scholar]
- Qin, M.; Qiu, S.; Zhao, Y.; Zhu, W.; Li, S. Graphic or short video? The influence mechanism of UGC types on consumers’ purchase intention—Take Xiaohongshu as an example. Electron. Commer. Res. Appl. 2024, 65, 101402. [Google Scholar] [CrossRef]
- Gupta, R.K.; Agarwalla, R.; Naik, B.H.; Evuri, J.R.; Thapa, A.; Singh, T.D. Prediction of research trends using LDA based topic modeling. Glob. Trans. Proc. 2022, 3, 298–304. [Google Scholar] [CrossRef]
- Yu, D.; Fang, A.; Xu, Z. Topic research in fuzzy domain: Based on LDA topic modelling. Inf. Sci. 2023, 648, 119600. [Google Scholar] [CrossRef]
- Yu, D.; Xiang, B. Discovering topics and trends in the field of Artificial Intelligence: Using LDA topic modeling. Expert Syst. Appl. 2023, 225, 120114. [Google Scholar] [CrossRef]
- Hassan, M.M.; Karim, A.; Mollick, S.; Azam, S.; Ignatious, E.; ASM Farhan Al Haque. An Apriori Algorithm-Based Association Rule Analysis to detect Human Suicidal Behaviour. Procedia Comput. Sci. 2023, 219, 1279–1288. [Google Scholar] [CrossRef]
- Zhao, L.; Zhang, M.; Tu, J.; Li, J.; Zhang, Y. Can users embed their user experience in user-generated images? J. Retail. Consum. Serv. 2023, 74, 103379. [Google Scholar] [CrossRef]
- Ali, T.; Omar, B.; Soulaimane, K. Analyzing tourism reviews using an LDA topic-based sentiment analysis approach. MethodsX 2022, 9, 101894. [Google Scholar] [CrossRef]
- Barravecchia, F.; Mastrogiacomo, L.; Franceschini, F. Digital voice-of-customer processing by topic modelling algorithms: Insights to validate empirical results. Int. J. Qual. Reliab. Manag. 2022, 39, 1453–1470. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Complaint Category | Complaint Issue Label | Type of Complaint | Complaint Text Content (Translated from Chinese to English) |
|---|---|---|---|
| Baggage service | The amount and standard of compensation | Domestic airlines | The luggage was damaged during the transportation. The airline promised to contact me, but it has not taken the initiative to contact me and deal with it. I have been very dissatisfied. |
| Ticket service | Refund rules | Foreign airlines and airlines from Hong Kong, Macao and Taiwan | I applied for a change a month in advance, can’t change it, applied for a refund, and got no money back, isn’t this blatant cheating? I can’t agree, I must file a complaint. |
| Air service | Service attitude issues | Aviation sales network platform | I was on this flight and the cabin crew missed my in-flight meal. I called twice in a row before I came over to ask. I think the in-flight solution is perfunctory. I think the quality of service is poor. |
| Check-in and boarding | Problems with check-in procedures | Domestic airport | The person in charge of check-in for this flight left his post without authorization and did not answer his phone, which prevented all passengers from checking in for more than 40 min, delaying the flight queue and causing delayed boarding. |
| Abnormal flight service | Refund and change rules | Domestic airlines | On my friend’s flight, the arrival time was changed, the traveler did not recognize it, and the airline refused to refund the full amount of the flight change. As a consumer, do I have the right to ask for a refund for the change? |
| Number | Preprocessing Complaint Text | Preprocessed Complaint Text |
|---|---|---|
| 1 | The passenger called and said the following: The passenger did not change successfully after paying the change fee, and the delay affected the passenger’s trip, so he complained. | Pay, change, fee, change, successful, delay, affect, trip |
| 2 | Passengers purchased tickets through the airline APP, paid for the meal beef stew, the beef was sour, the passengers checked the side dishes that did not have a sour taste in the ingredients, and complained to the flight attendant about mileage compensation, and the passengers were dissatisfied with the compensation and called to complain. | App, ticket, pay, buy, meal, beef, sour, view, ingredients, sour, side dish, flight attendant, give, miles, compensation, indemnity |
| 3 | Passengers called to say the following: Two passengers were planning to travel; due to a change in the itinerary, the friends buying tickets did not need to pay a handling fee to change, but the passengers needed to pay more than CNY 1000 to change. After the complaint platform’s customer service attitude was bad and did not give a good plan, the passengers were dissatisfied and called to complain. | Trip, itinerary, change, friend, purchase, ticket, don’t, pay, fee, change, payment, platform, customer service, bad attitude, give, program |
| 4 | The passenger called and said the following: There are four people in the group, two of whom are children, and they must be seated next to adults. The passengers were unable to check in through online channels and contacted the airline for feedback, and customer service could not assist with check-in, resulting in four passengers having to sit separately. Passengers were dissatisfied and called to complain. | Child, adult, seated, online, channel, check-in, procedure, contact, feedback, customer service, assist, handle, lead to, separate |
| 5 | The passenger called to say that after applying for a sick refund and submitting relevant information, the airline had not handled the review, and he was dissatisfied with this and called to complain. | Application, sick leave, submit, relevant, information, processing, review |
| … | …… | …… |
| Number | LDA Score | LSA Score |
|---|---|---|
| 1 | 0.4049 | 0.2985 |
| 2 | 0.4821 | 0.4200 |
| 3 | 0.4889 | 0.3781 |
| 4 | 0.5023 | 0.4267 |
| 5 | 0.5130 | 0.5100 |
| 6 | 0.5054 | 0.3521 |
| 7 | 0.4839 | 0.3786 |
| 8 | 0.4826 | 0.4391 |
| 9 | 0.4812 | 0.4527 |
| 10 | 0.4558 | 0.3973 |
| 11 | 0.4630 | 0.3514 |
| 12 | 0.4609 | 0.4018 |
| 13 | 0.4463 | 0.3922 |
| 14 | 0.4349 | 0.4183 |
| 15 | 0.4292 | 0.3613 |
| 16 | 0.4301 | 0.3491 |
| 17 | 0.4375 | 0.3612 |
| 18 | 0.4200 | 0.3760 |
| 19 | 0.4256 | 0.4077 |
| 20 | 0.4375 | 0.3572 |
| 21 | 0.4312 | 0.3524 |
| 22 | 0.4216 | 0.3720 |
| 23 | 0.4183 | 0.3649 |
| 24 | 0.4130 | 0.3518 |
| 25 | 0.4088 | 0.3426 |
| 26 | 0.4011 | 0.3807 |
| 27 | 0.3919 | 0.3826 |
| 28 | 0.4031 | 0.3439 |
| 29 | 0.4208 | 0.3588 |
| 30 | 0.4060 | 0.3392 |
| Number | Topic Category | Main Topic Characterization Words |
|---|---|---|
| 1 | Ticket services | Submission, sick leave, materials |
| 2 | Abnormal flight service | Delays, take-offs, weather |
| 3 | Check-in and boarding | Staff, boarding, arrival |
| 4 | Baggage services | Baggage, compensation, check through |
| 5 | In-air service | Guests, flight attendants, meals |
| 6 | Customer service | Personnel, attitude, economy class |
| 7 | Member services | Membership, points, manager |
| 8 | Information notice | Display, aircraft type, adjustment |
| 9 | Special passenger service | Application, minutes, full refund |
| 10 | Overselling | Ticketing, mailing, overselling |
| 11 | Other services | Transit, department, accommodation |
| Number | Lhs | Rhs | Support | Confidence | Lift |
|---|---|---|---|---|---|
| 1 | {Refund due to illness} | {Submission, sickness, material} | 0.0447 | 0.7754 | 9.6270 |
| 2 | {Delays, departures, weather} | {Dissatisfaction with compensation} | 0.0217 | 0.5460 | 4.1503 |
| 3 | {Price, difference, fare} | {Passenger ticket prices} | 0.0203 | 0.7281 | 14.4102 |
| 4 | {Fees, charges, high} | {Refund rules} | 0.0178 | 0.4371 | 4.5803 |
| 5 | {Free, booking, mistake} | {Wrong purchase} | 0.0142 | 0.6374 | 8.1095 |
| Number | Lhs | Rhs | Support | Confidence | Lift |
|---|---|---|---|---|---|
| 1 | {Submission, sick leave, material} | {Ticketing service} | 0.0316 | 0.9576 | 0.0004 |
| 2 | {Ticketing service} | {Submission, sickness, material} | 0.0316 | 0.1433 | 0.0004 |
| 3 | {Delays, take-offs, weather} | {Irregular flight service} | 0.0156 | 0.9571 | 0.0009 |
| 4 | {Irregular flight service} | {Delays, take-offs, weather} | 0.0156 | 0.1545 | 0.0009 |
| 5 | {Fees, charges, high amounts} | {Ticketing service} | 0.0154 | 0.9222 | 0.0004 |
| Number | Lhs | Rhs | Support | Confidence | Lift |
|---|---|---|---|---|---|
| 1 | {Damaged baggage} | {Baggage, compensation, consignment} | 0.0124 | 0.8095 | 23.8606 |
| 2 | {Refund due to illness} | {Submission, sickness, materials} | 0.0447 | 0.7754 | 9.6270 |
| 3 | {Price, difference, fare} | {Passenger ticket price} | 0.0203 | 0.7281 | 14.4102 |
| 4 | {Compensation, arrangement, impact} | {Dissatisfaction with compensation} | 0.0098 | 0.6452 | 4.9039 |
| 5 | {Free, booking, mistake} | {Wrong purchase} | 0.0142 | 0.6374 | 8.1095 |
| Number | Lhs | Rhs | Support | Confidence | Lift |
|---|---|---|---|---|---|
| 1 | {Itinerary, there is a change, the second} | {Ticketing service} | 0.0017 | 1.0000 | 0.0006 |
| 2 | {Provide, antigen, swim} | {Ticketing service} | 0.0015 | 1.0000 | 0.0006 |
| 3 | {Ground transportation services} | {Staff, boarding, arrival} | 0.0001 | 1.0000 | 0.0091 |
| 4 | {Feedback, put, privately} | {Ticketing service} | 0.0001 | 1.0000 | 0.0006 |
| 5 | {Submission, sickness, material} | {Ticketing service} | 0.0316 | 0.9576 | 0.0005 |
| Number | Lhs | Rhs | Support | Confidence | Lift |
|---|---|---|---|---|---|
| 1 | {Display, model, adjustments} | {Ticketing session flight main service information} | 0.0095 | 0.6094 | 26.0063 |
| 2 | {Baggage damage} | {Baggage, compensation, consignment} | 0.0124 | 0.8095 | 23.8606 |
| 3 | {Missing a ride} | {Staffing, boarding, arrivals} | 0.0073 | 0.5769 | 21.2942 |
| 4 | {Seat, choice, self} | {Seat selection} | 0.0056 | 0.5000 | 19.8883 |
| 5 | {Price, difference, fare} | {Ticket prices} | 0.0203 | 0.7281 | 14.4102 |
| Number | Lhs | Rhs | Support | Confidence | Lift |
|---|---|---|---|---|---|
| 1 | {Ticket purchase, mailing, overbooking} | {Overbooking} | 0.0009 | 0.4737 | 0.0206 |
| 2 | {Overbooking} | {Ticket purchase, mailing, overbooking} | 0.0009 | 0.3913 | 0.0206 |
| 3 | {Airport merchant services} | {Ride, on the day, pick up} | 0.0002 | 0.2857 | 0.0159 |
| 4 | {Ride, on the day, pick up} | {Airport merchant services} | 0.0002 | 0.1111 | 0.0159 |
| 5 | {Airport merchant services} | {Booking, knowing, channeling} | 0.0001 | 0.1429 | 0.0110 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cai, H.; Dong, T.; Zhou, P.; Li, D.; Li, H. Leveraging Text Mining Techniques for Civil Aviation Service Improvement: Research on Key Topics and Association Rules of Passenger Complaints. Systems 2025, 13, 325. https://doi.org/10.3390/systems13050325
Cai H, Dong T, Zhou P, Li D, Li H. Leveraging Text Mining Techniques for Civil Aviation Service Improvement: Research on Key Topics and Association Rules of Passenger Complaints. Systems. 2025; 13(5):325. https://doi.org/10.3390/systems13050325
Chicago/Turabian StyleCai, Huali, Tao Dong, Pengpeng Zhou, Duo Li, and Hongtao Li. 2025. "Leveraging Text Mining Techniques for Civil Aviation Service Improvement: Research on Key Topics and Association Rules of Passenger Complaints" Systems 13, no. 5: 325. https://doi.org/10.3390/systems13050325
APA StyleCai, H., Dong, T., Zhou, P., Li, D., & Li, H. (2025). Leveraging Text Mining Techniques for Civil Aviation Service Improvement: Research on Key Topics and Association Rules of Passenger Complaints. Systems, 13(5), 325. https://doi.org/10.3390/systems13050325