
Multi-Ported GC-eDRAM Bitcell with Dynamic Port Configuration and Refresh Mechanism †


Abstract
1. Introduction
Contributions
- This work presents the first reported 2R2W and 6R2W GC-eDRAM memory, as well as a general design guideline for N-ported dynamic memories.
- The resulting bitcell is the smallest multi-ported memory reported in the literature.
- A novel opportunistic refresh port approach for dynamic memory arrays with NRMW access ports is provided.
- The proposed array can be dynamically configured to support an internal refresh operation without sacrificing memory availability.
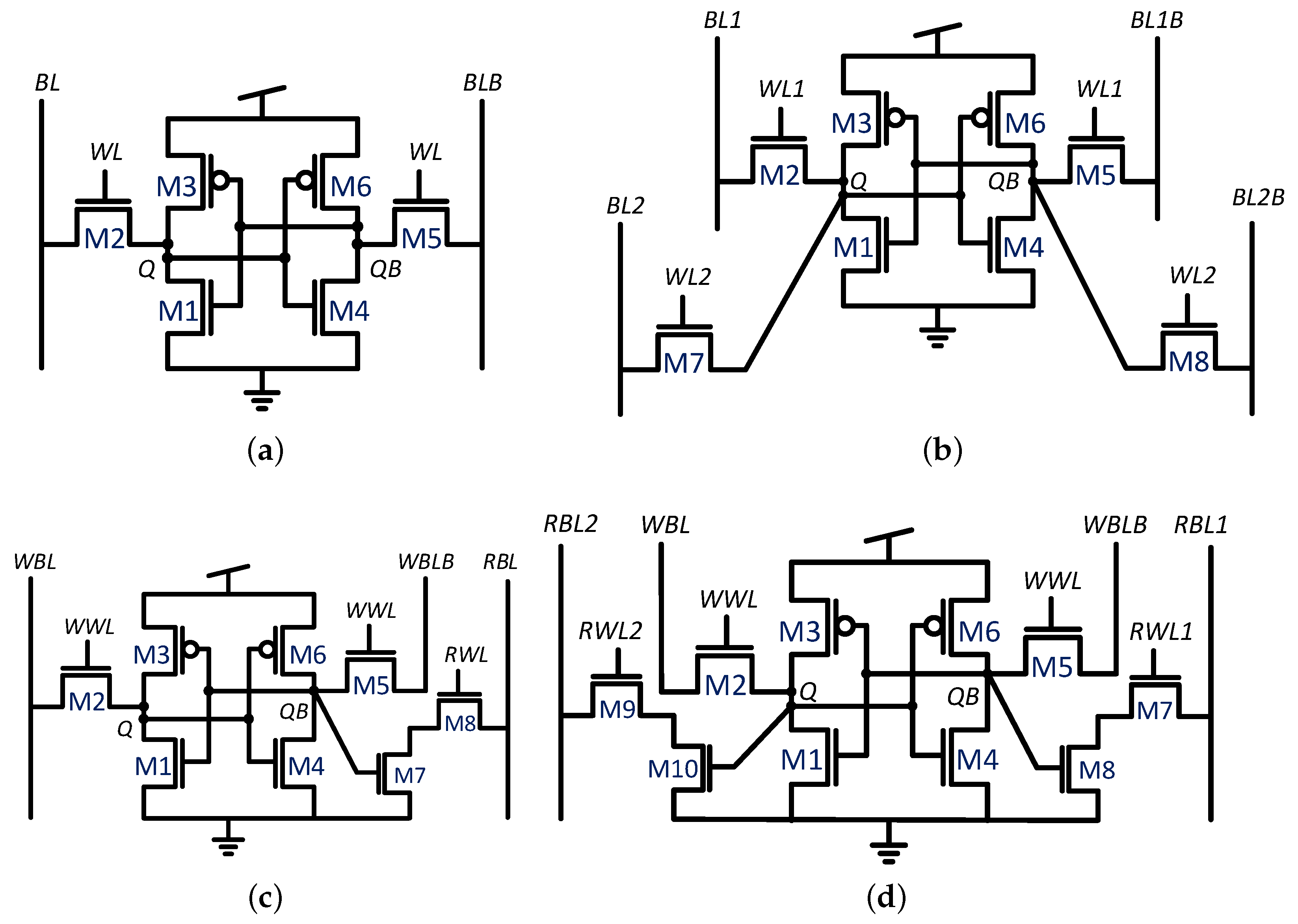
2. Multi-Ported Gain Cell Design
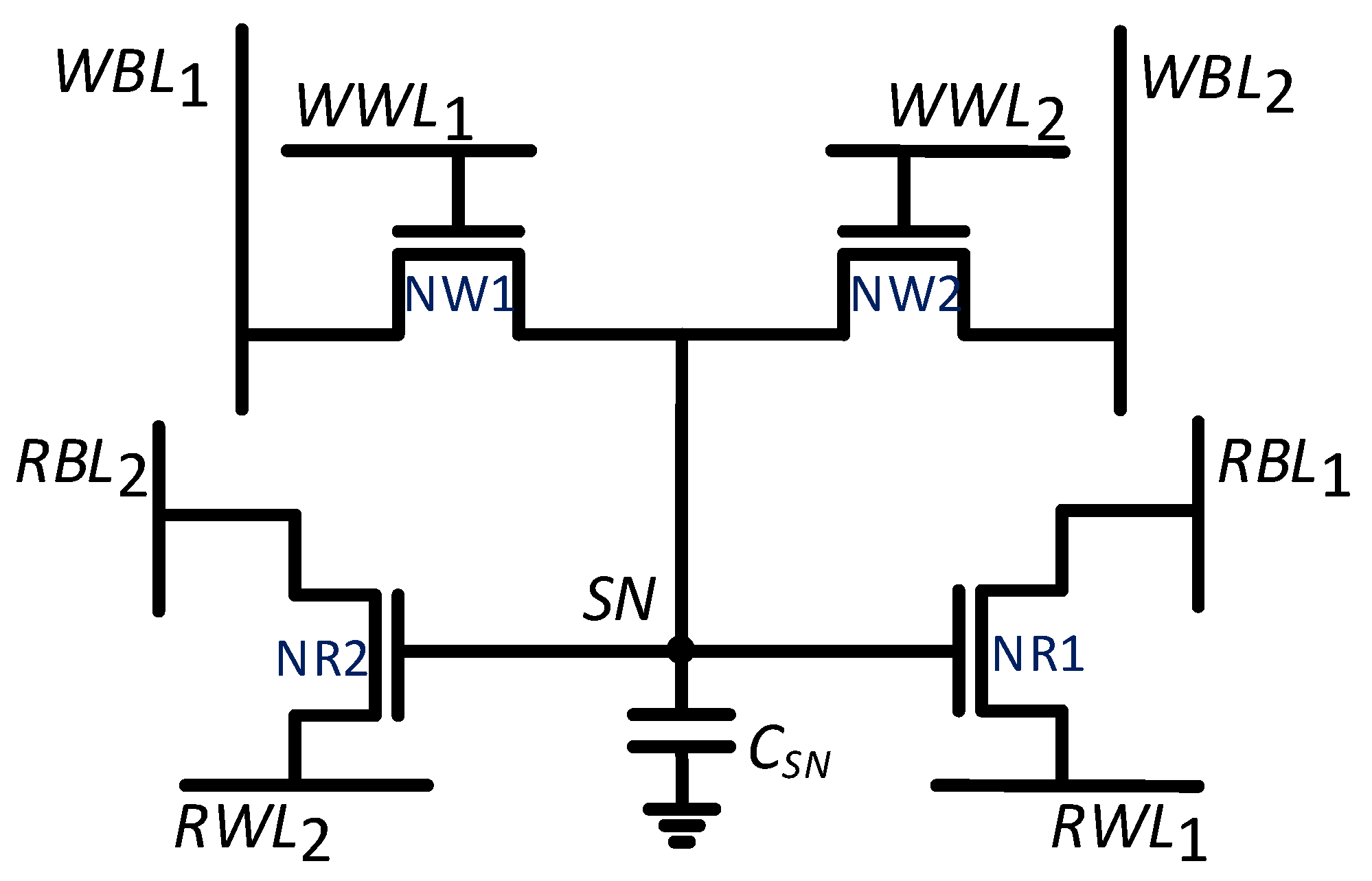
2.1. 2R2W Cell Design and Operating Mechanism
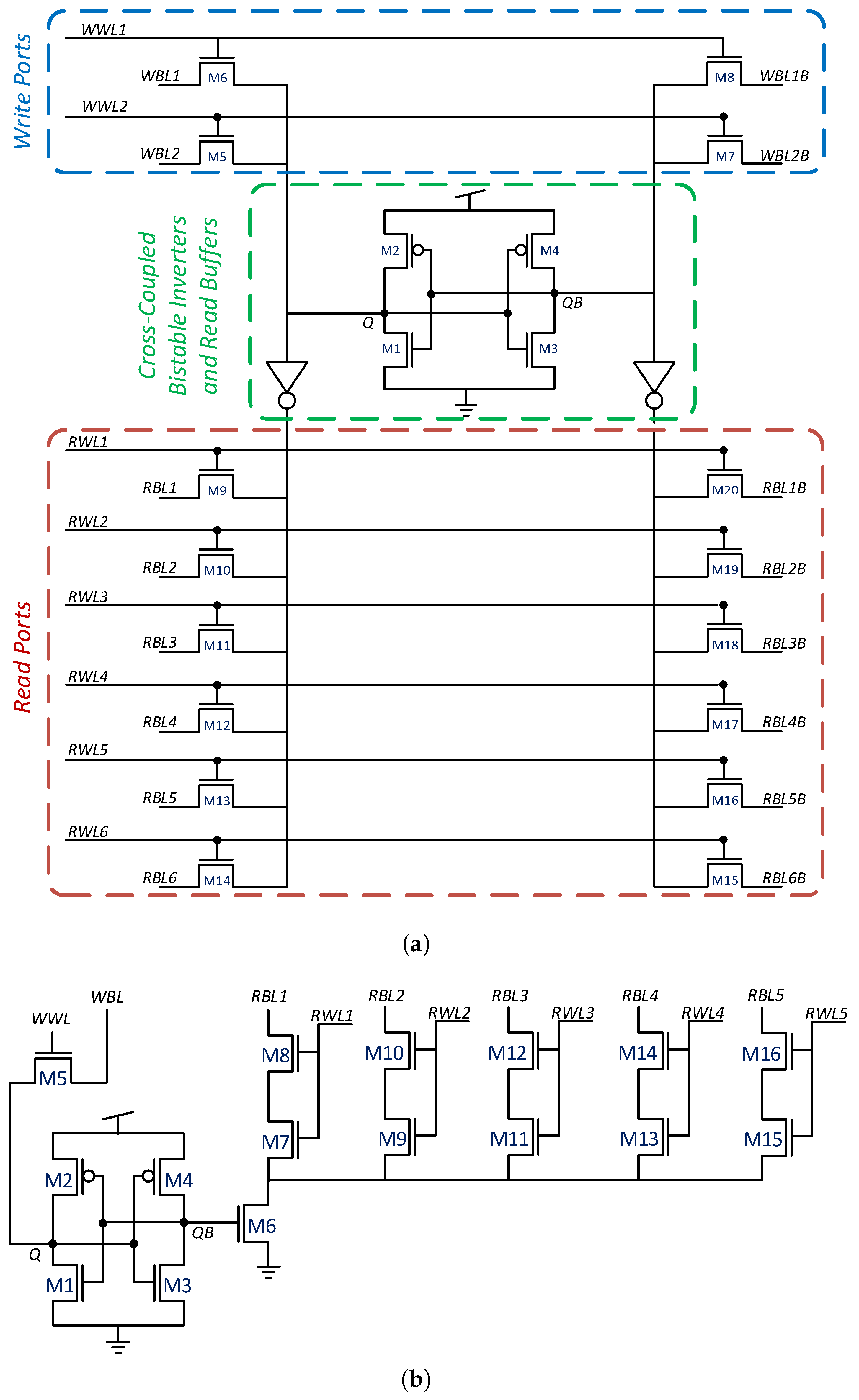
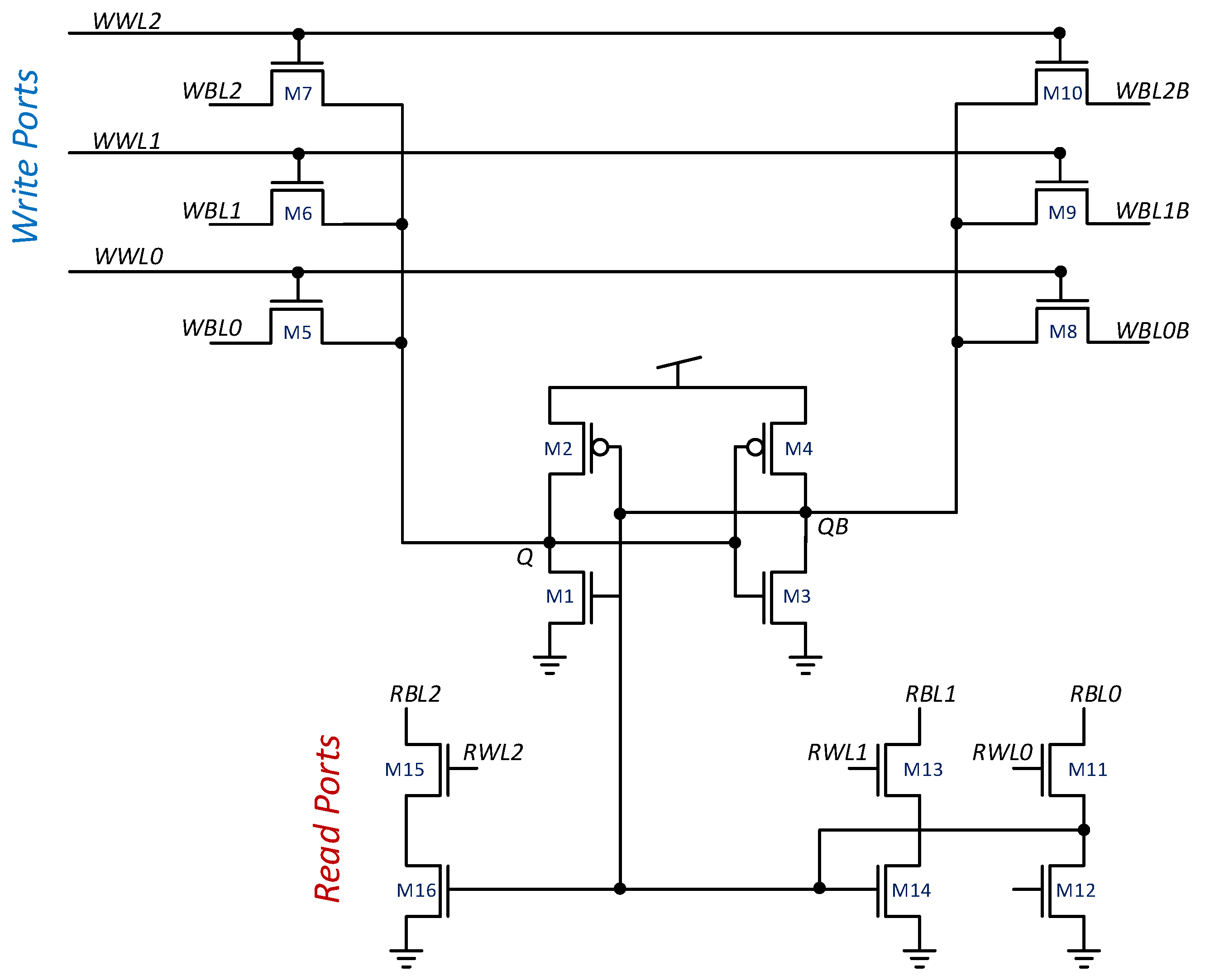
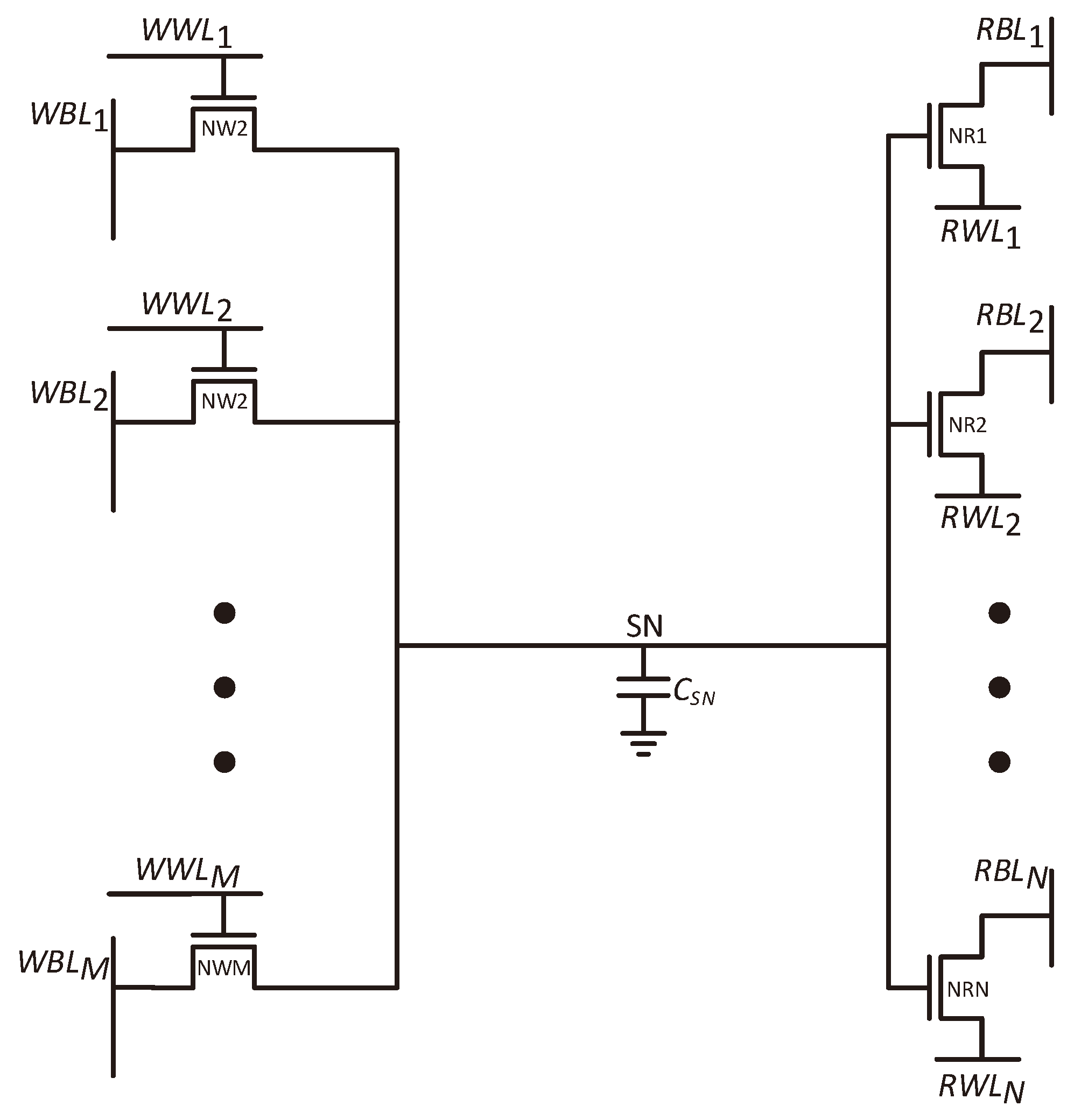
2.2. Expanding the Number of Read Ports
3. Implementation and Simulation Results
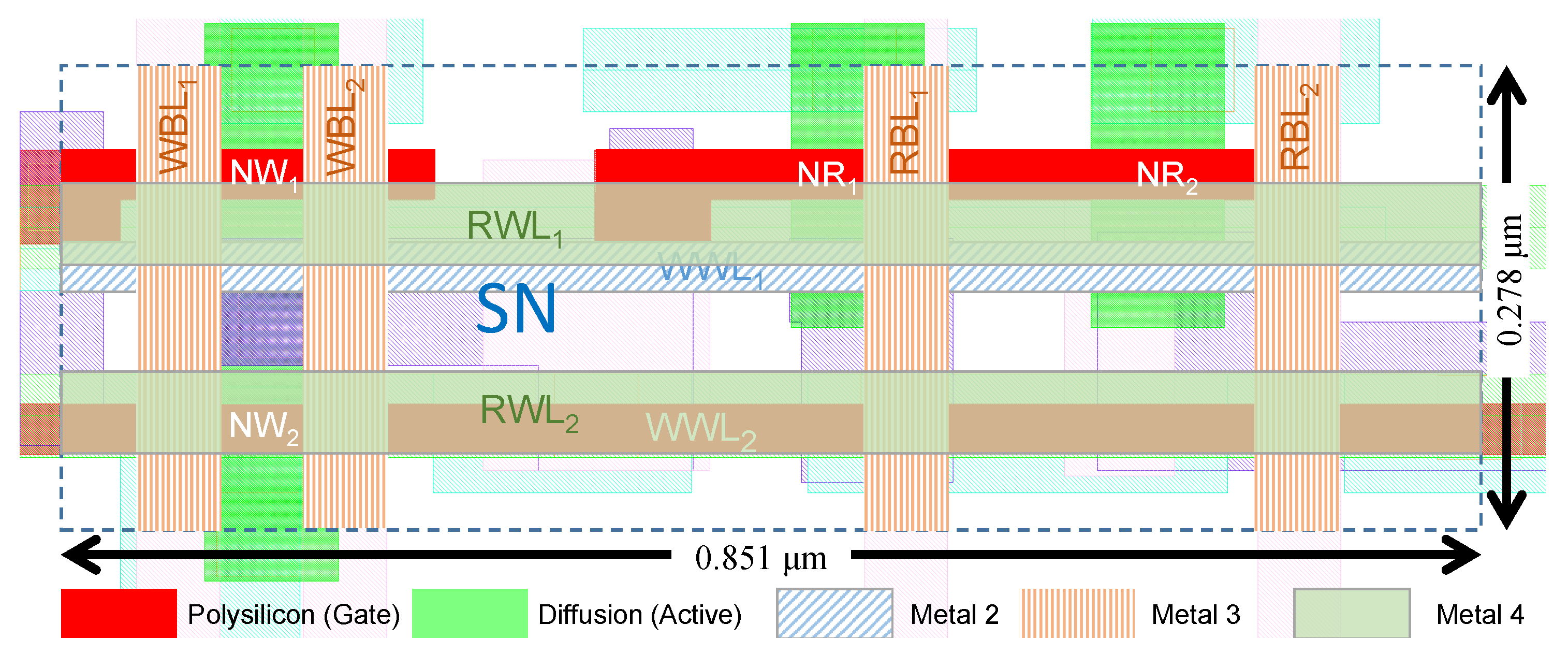
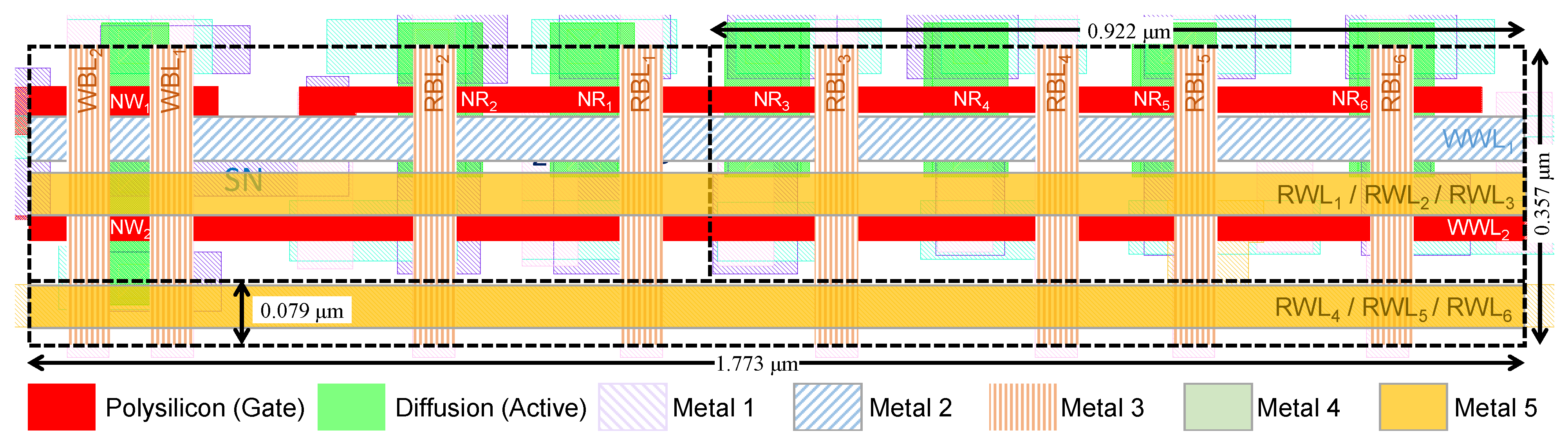
3.1. 2R2W Bitcell Layout
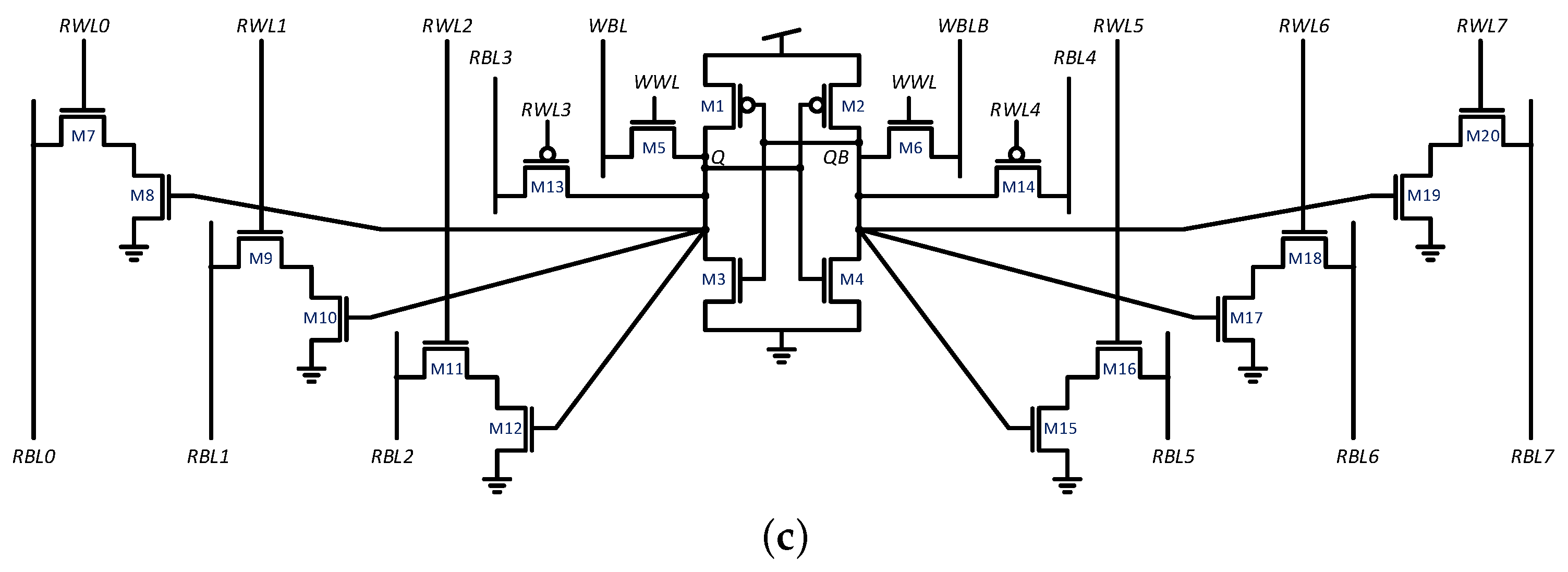
3.2. Expanding the Layout to Accommodate Additional Read Ports
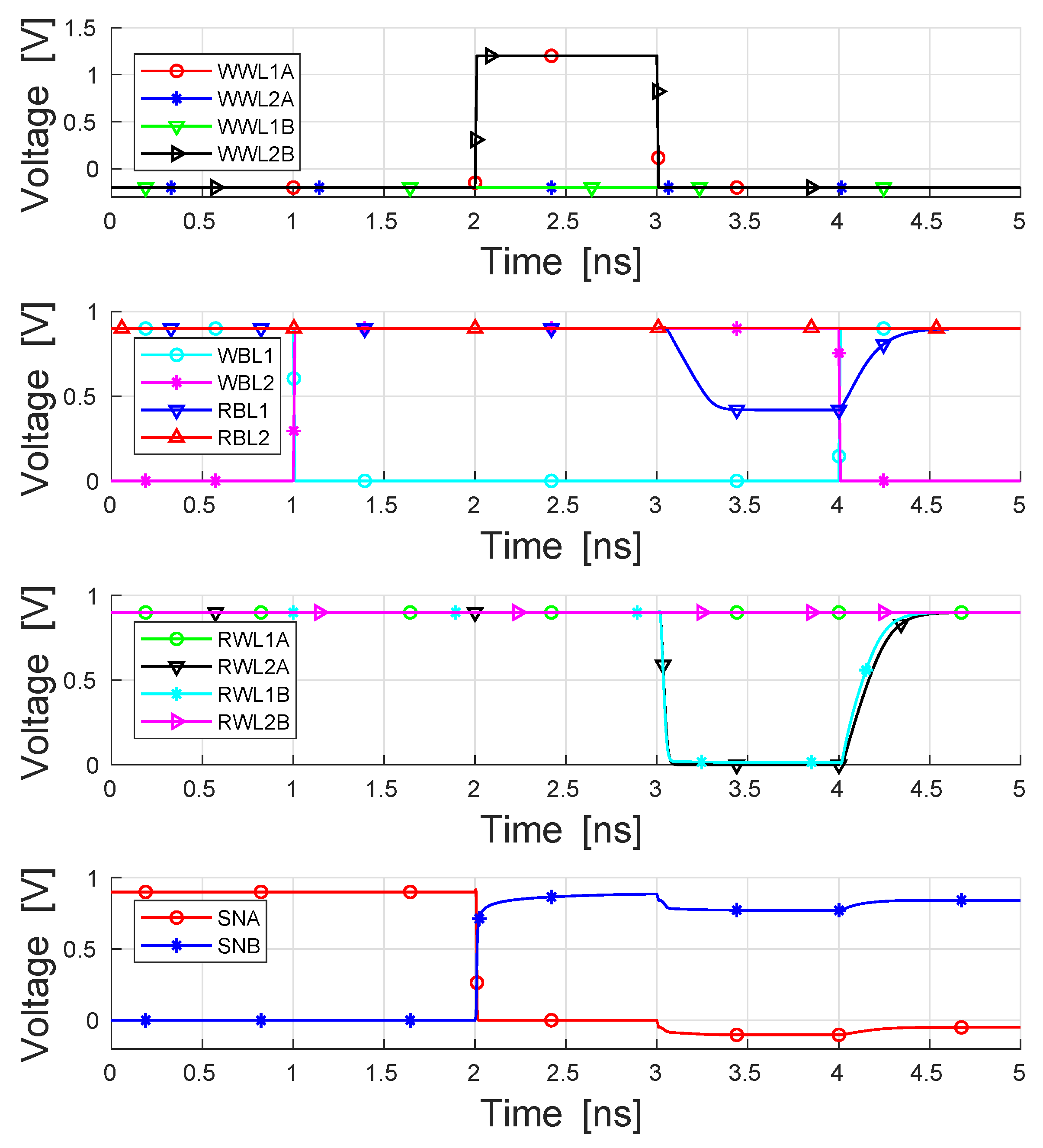
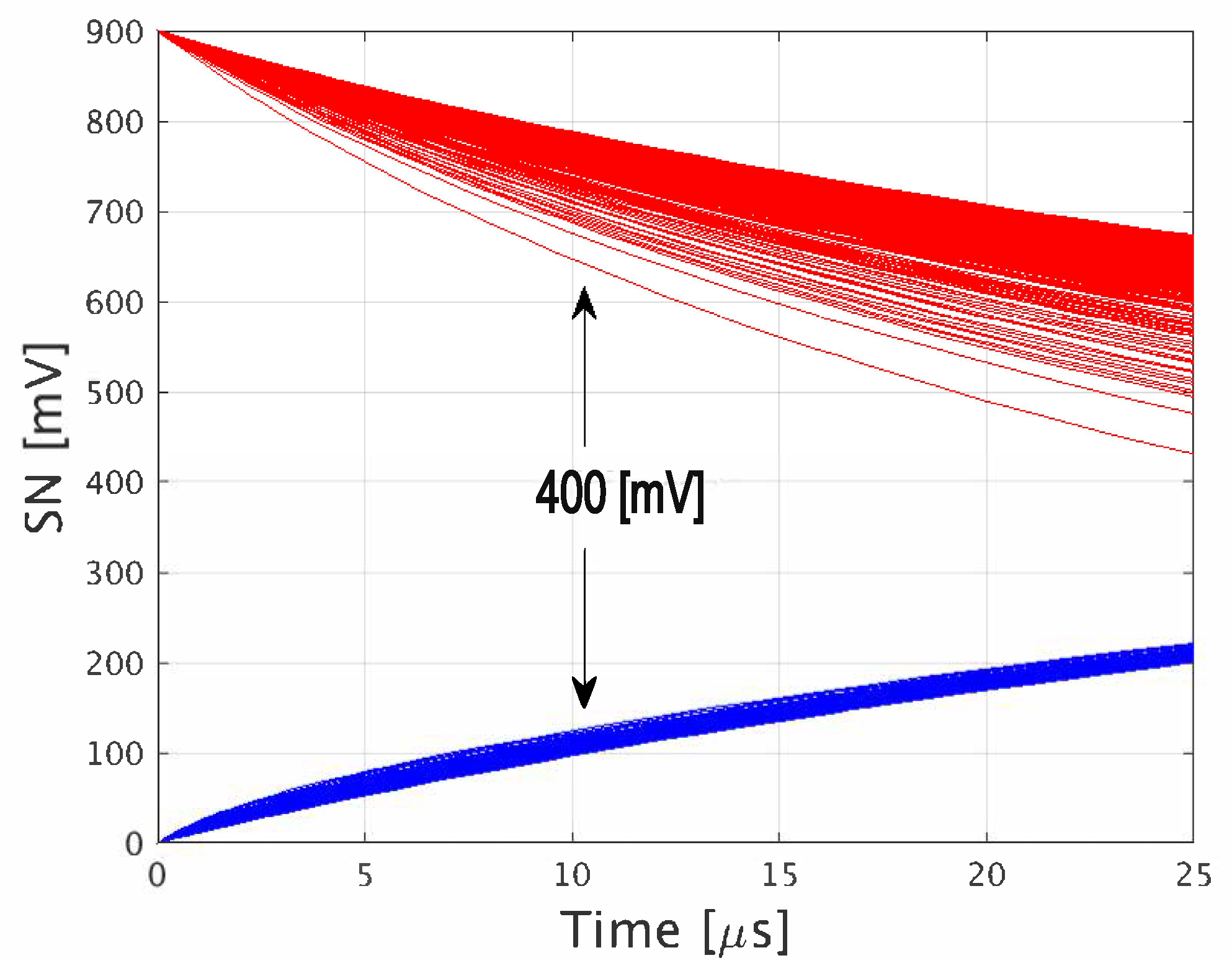
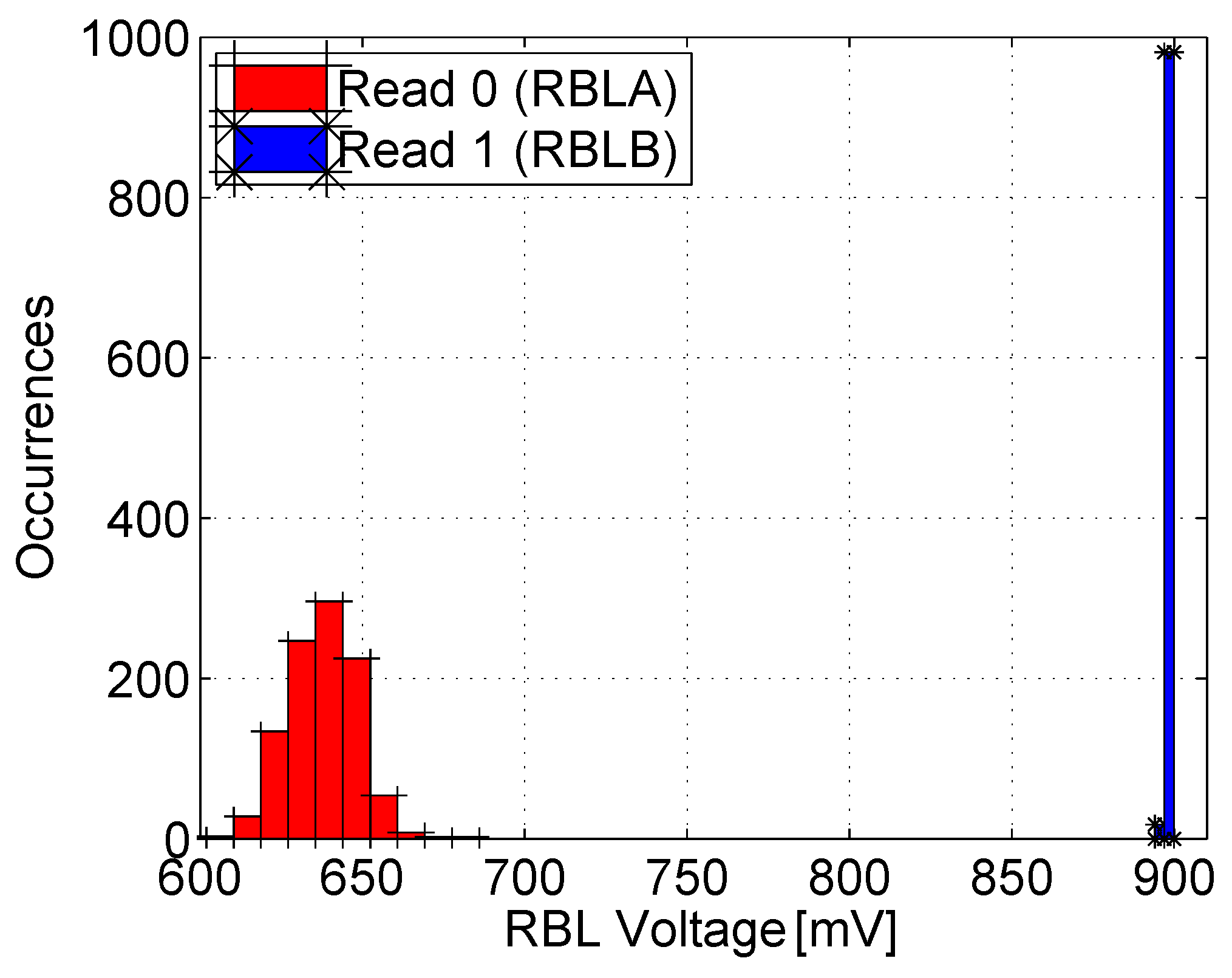
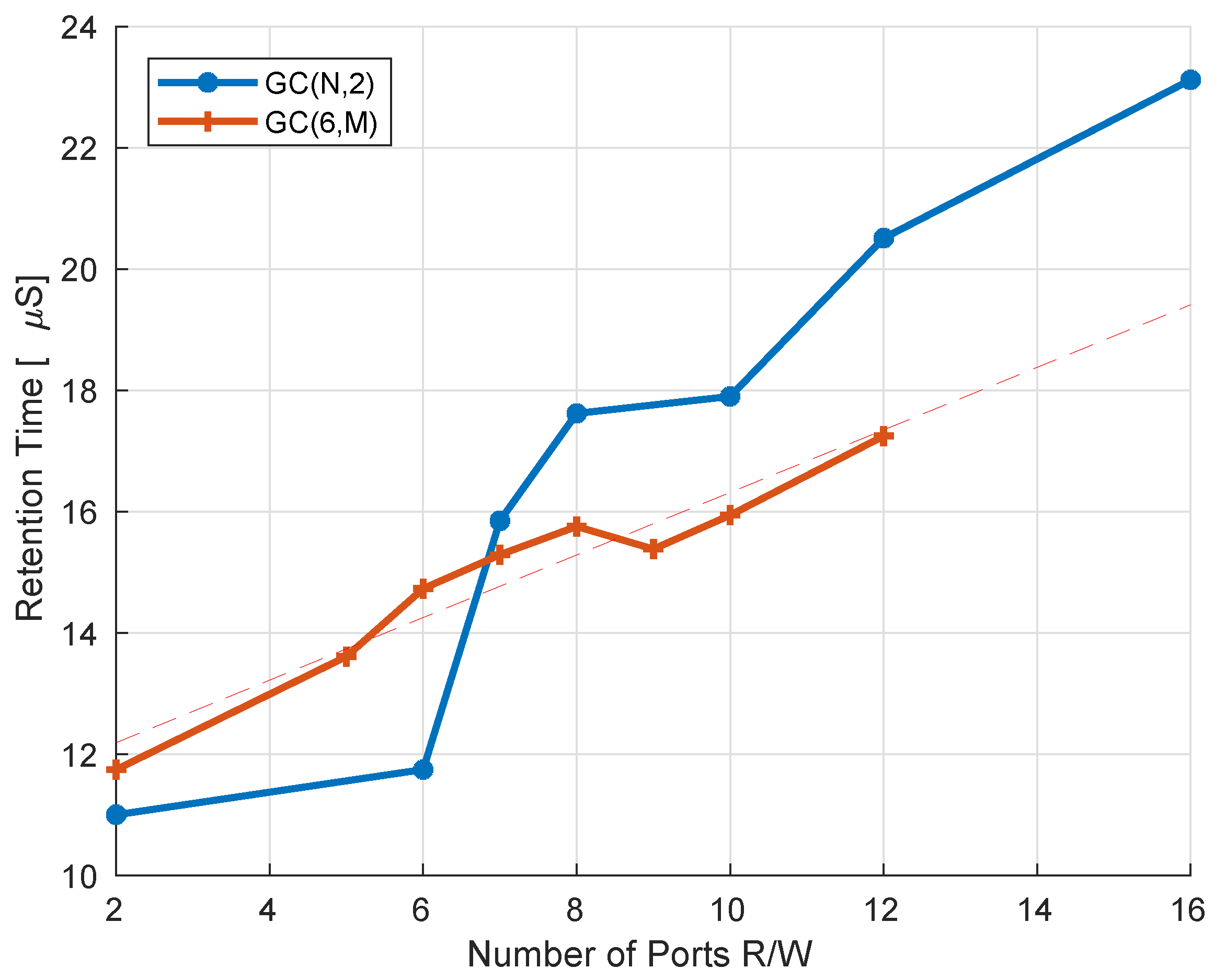
3.3. Simulation Results
4. Configurable Operation
4.1. NRMW Operation Mode
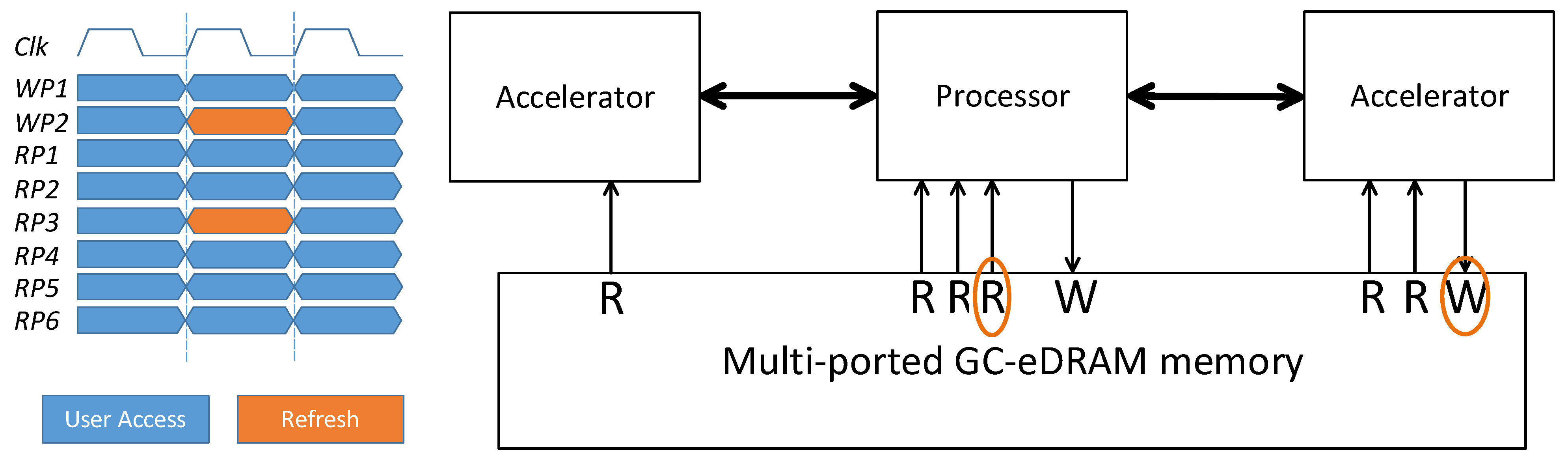
4.2. Internal Refresh Mode
4.3. High Performance Opportunistic Refresh Port Mode
- The previous data is written back into the array at the current cycle.
- There is no data in the buffer.
| Algorithm 1 Refresh Controller Algorithm |
|
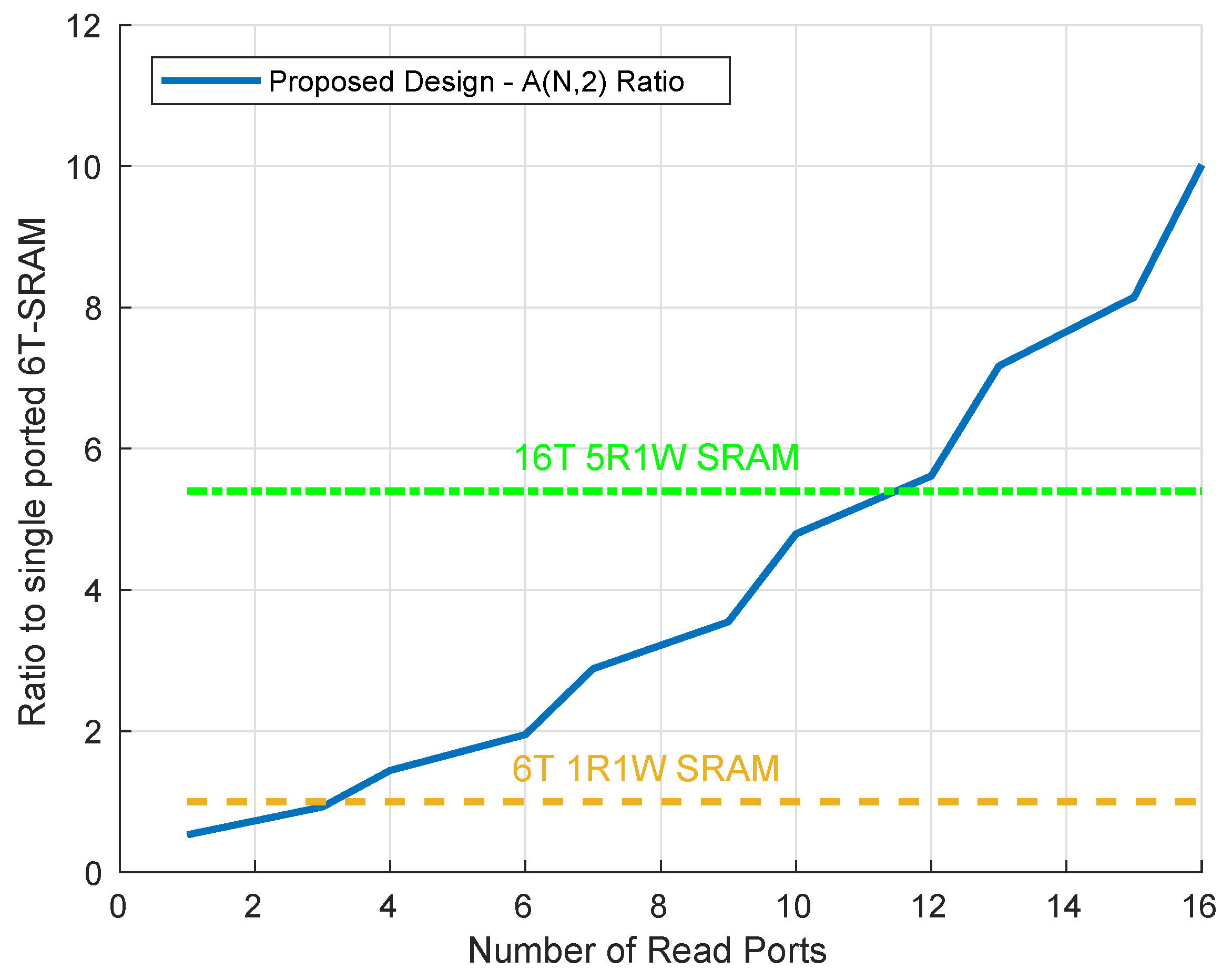
5. Comparison to SRAM
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- IEEE. International Technology Roadmap for Semiconductors (IRDS)—2023 Update. 2023. Available online: https://irds.ieee.org/editions/2023 (accessed on 26 December 2023).
- Noguchi, H.; Okumura, S.; Iguchi, Y.; Fujiwara, H.; Morita, Y.; Nii, K.; Kawaguchi, H.; Yoshimoto, M. Which is the Best Dual-Port SRAM in 45-nm Process Technology? 8T, 10T single end, and 10T differential. In Proceedings of the ICICDT 2008, Grenoble, France, 2–4 June 2008; pp. 55–58. [Google Scholar]
- Nii, K.; Tsukamoto, Y.; Yabuuchi, M.; Masuda, Y.; Imaoka, S.; Usui, K.; Ohbayashi, S.; Makino, H.; Shinohara, H. Synchronous ultra-high-density 2RW dual-port 8T-SRAM with circumvention of simultaneous common-row-access. IEEE J. Solid-State Circuits 2009, 44, 977–986. [Google Scholar] [CrossRef]
- Ohara, R.; Masaya, K.; Taichi, M.; Fukunaga, A.; Yasuda, Y.; Hamabe, R.; Izumi, S.; Kawaguchi, H. A 1W8R 20T SRAM Codebook for 20% Energy Reduction in Mixed-Precision Deep-Learning Inference Processor System. In Proceedings of the 2023 IEEE 5th International Conference on Artificial Intelligence Circuits and Systems (AICAS), Hangzhou, China, 11–13 June 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Hsiao, S.; Wu, P. Design of low-leakage multi-port SRAM for register file in graphics processing unit. In Proceedings of the 2014 IEEE International Symposium on Circuits and Systems (ISCAS), Melbourne, VIC, Australia, 1–5 June 2014; pp. 2181–2184. [Google Scholar] [CrossRef]
- Ataei, S.; Gaalswyk, M.; Stine, J.E. A high performance multi-port SRAM for low voltage shared memory systems in 32 nm CMOS. In Proceedings of the 2017 IEEE 60th International Midwest Symposium on Circuits and Systems (MWSCAS), Boston, MA, USA, 6–9 August 2017; pp. 1236–1239. [Google Scholar] [CrossRef]
- Fetzer, E.S.; Dahle, D.; Little, C.; Safford, K. The Parity protected, multithreaded register files on the 90-nm itanium microprocessor. IEEE J. Solid-State Circuits 2006, 41, 246–255. [Google Scholar] [CrossRef]
- Abdelhadi, A.M.S.; Lemieux, G.G.F. A Multi-ported Memory Compiler Utilizing True Dual-Port BRAMs. In Proceedings of the 2016 IEEE 24th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), Washington, DC, USA, 1–3 May 2016; pp. 140–147. [Google Scholar] [CrossRef]
- Tseng, J.H.; Asanovic, K. Banked multiported register files for high-frequency superscalar microprocessors. In Proceedings of the 30th Annual International Symposium on Computer Architecture, San Diego, CA, USA, 9–11 June 2003; pp. 62–71. [Google Scholar] [CrossRef]
- Chang, P.Y.; Lin, T.J.; Wang, J.S.; Yu, Y.H. A 4R/2W Register File Design for UDVS Microprocessors in 65-nm CMOS. IEEE Trans. Circuits Syst. II Express Briefs 2012, 59, 908–912. [Google Scholar] [CrossRef]
- Zhang, X.; Li, Y.; Xiong, B.; Han, J.; Zhang, Y.; Dong, F.; Zhang, Z.; Yu, Z.; Cheng, X.; Zeng, X. Robust and low power register file in 65 nm technology. J. Semicond. 2012, 33, 035010. [Google Scholar] [CrossRef]
- Ditlow, G.S.; Montoye, R.K.; Storino, S.N.; Dance, S.M.; Ehrenreich, S.; Fleischer, B.M.; Fox, T.W.; Holmes, K.M.; Mihara, J.; Nakamura, Y.; et al. A 4R2W register file for a 2.3 GHz wire-speed POWER™ processor with double-pumped write operation. In Proceedings of the 2011 IEEE International Solid-State Circuits Conference, San Francisco, CA, USA, 20–24 February 2011; pp. 256–258. [Google Scholar]
- Marinberg, H.; Garzón, E.; Noy, T.; Lanuzza, M.; Teman, A. Efficient Implementation of Many-Ported Memories by Using Standard-Cell Memory Approach. IEEE Access 2023, 11, 94885–94897. [Google Scholar] [CrossRef]
- Kulkarni, J.P.; Keane, J.; Koo, K.H.; Nalam, S.; Guo, Z.; Karl, E.; Zhang, K. 5.6 Mb/mm2 1R1W 8T SRAM Arrays Operating Down to 560 mV Utilizing Small-Signal Sensing with Charge Shared Bitline and Asymmetric Sense Amplifier in 14 nm FinFET CMOS Technology. IEEE J. Solid-State Circuits 2017, 52, 229–239. [Google Scholar] [CrossRef]
- Golman, R.; Giterman, R.; Teman, A. Configurable Multi-Port Dynamic Bitcell with Internal Refresh Mechanism. In Proceedings of the 2018 25th IEEE International Conference on Electronics, Circuits and Systems (ICECS), Bordeaux, France, 9–12 December 2018; pp. 589–592. [Google Scholar]
- Nguyen, H.; Jeong, J.; Atallah, F.; Yingling, D.; Bowman, K. A 7-nm 6R6W Register File With Double-Pumped Read and Write Operations for High-Bandwidth Memory in Machine Learning and CPU Processors. IEEE Solid-State Circuits Lett. 2018, 1, 225–228. [Google Scholar] [CrossRef]
- Kadomoto, J.; Irie, H.; Sakai, S. Multiport Register File Design for High-Performance Embedded Cores. In Proceedings of the 2021 IEEE 14th International Symposium on Embedded Multicore/Many-core Systems-on-Chip (MCSoC), Singapore, 20–23 December 2021; pp. 281–286. [Google Scholar] [CrossRef]
- Andersson, O.; Mohammadi, B.; Meinerzhagen, P.; Burg, A.; Rodrigues, J.N. Ultra Low Voltage Synthesizable Memories: A Trade-Off Discussion in 65 nm CMOS. IEEE Trans. Circuits Syst. I Regul. Pap. 2016, 63, 806–817. [Google Scholar] [CrossRef]
- Fan, X.; Stuijt, J.; Liu, B.; Gemmeke, T. Synthesizable Memory Arrays Based on Logic Gates for Subthreshold Operation in IoT. IEEE Trans. Circuits Syst. I Regul. Pap. 2019, 66, 941–954. [Google Scholar] [CrossRef]
- Ramesh, T.; Abed, K. Reconfigurable Many-Core Embedded Computing Platform with Geometrical Bus Interconnection. In Proceedings of the 2020 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 16–18 December 2020; pp. 1256–1259. [Google Scholar] [CrossRef]
- Ramesh, T.; Abed, K. An efficient multi-level cache system for geometrically interconnected many-core chip multiprocessor. Int. J. Reconfigurable Embed. Syst. 2022, 11, 93. [Google Scholar] [CrossRef]
- Zhang, C.; Sun, H.; Li, S.; Wang, Y.; Chen, H.; Liu, H. A Survey of Memory-Centric Energy Efficient Computer Architecture. IEEE Trans. Parallel Distrib. Syst. 2023, 34, 2657–2670. [Google Scholar] [CrossRef]
- Wu, P.C.; Su, J.W.; Chung, Y.L.; Hong, L.Y.; Ren, J.S.; Chang, F.C.; Wu, Y.; Chen, H.Y.; Lin, C.H.; Hsiao, H.M.; et al. A 28nm 1Mb Time-Domain Computing-in-Memory 6T-SRAM Macro with a 6.6ns Latency, 1241GOPS and 37.01TOPS/W for 8b-MAC Operations for Edge-AI Devices. In Proceedings of the 2022 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 20–26 February 2022; Volume 65, pp. 1–3. [Google Scholar] [CrossRef]
- Si, X.; Chen, J.J.; Tu, Y.N.; Huang, W.H.; Wang, J.H.; Chiu, Y.C.; Wei, W.C.; Wu, S.Y.; Sun, X.; Liu, R.; et al. 24.5 A Twin-8T SRAM Computation-In-Memory Macro for Multiple-Bit CNN-Based Machine Learning. In Proceedings of the 2019 IEEE International Solid-State Circuits Conference—(ISSCC), San Francisco, CA, USA, 17–21 February 2019; pp. 396–398. [Google Scholar] [CrossRef]
- Dong, Q.; Sinangil, M.E.; Erbagci, B.; Sun, D.; Khwa, W.S.; Liao, H.J.; Wang, Y.; Chang, J. 15.3 A 351TOPS/W and 372.4GOPS Compute-in-Memory SRAM Macro in 7 nm FinFET CMOS for Machine-Learning Applications. In Proceedings of the 2020 IEEE International Solid-State Circuits Conference—(ISSCC), San Francisco, CA, USA, 16–20 February 2020; pp. 242–244. [Google Scholar] [CrossRef]
- Garzon, E.; Yavits, L.; Lanuzza, M.; Teman, A. Emerging Memory Structures for VLSI Circuits. In Wiley Encyclopedia of Electrical and Electronics Engineering; Wiley: Hoboken, NJ, USA, 2022. [Google Scholar] [CrossRef]
- Hung, J.M.; Xue, C.X.; Kao, H.Y.; Huang, Y.H.; Chang, F.C.; Huang, S.P.; Liu, T.W.; Jhang, C.J.; Su, C.I.; Khwa, W.S.; et al. A four-megabit compute-in-memory macro with eight-bit precision based on CMOS and resistive random-access memory for AI edge devices. Nat. Electron. 2021, 4, 921–930. [Google Scholar] [CrossRef]
- Wei, Q.; Gao, B.; Tang, J.; Qian, H.; Wu, H. Emerging Memory-Based Chip Development for Neuromorphic Computing: Status, Challenges, and Perspectives. IEEE Electron. Devices Mag. 2023, 1, 33–49. [Google Scholar] [CrossRef]
- Chiu, Y.C.; Yang, C.S.; Teng, S.H.; Huang, H.Y.; Chang, F.C.; Wu, Y.; Chien, Y.A.; Hsieh, F.L.; Li, C.Y.; Lin, G.Y.; et al. A 22nm 4Mb STT-MRAM Data-Encrypted Near-Memory Computation Macro with a 192GB/s Read-and-Decryption Bandwidth and 25.1-55.1TOPS/W 8b MAC for AI Operations. In Proceedings of the 2022 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 20–26 February 2022; Volume 65, pp. 178–180. [Google Scholar] [CrossRef]
- Biswas, A.; Chandrakasan, A.P. Conv-RAM: An energy-efficient SRAM with embedded convolution computation for low-power CNN-based machine learning applications. In Proceedings of the 2018 IEEE International Solid-State Circuits Conference—(ISSCC), San Francisco, CA, USA, 11–15 February 2018; pp. 488–490. [Google Scholar] [CrossRef]
- Nguyen, V.T.; Kim, J.S.; Lee, J.W. 10T SRAM Computing-in-Memory Macros for Binary and Multibit MAC Operation of DNN Edge Processors. IEEE Access 2021, 9, 71262–71276. [Google Scholar] [CrossRef]
- Chen, Y.; Mu, J.; Kim, H.; Lu, L.; Kim, T.T.H. A Reconfigurable 8T SRAM Macro for Bit-Parallel Searching and Computing In-Memory. In Proceedings of the 2022 IEEE International Symposium on Circuits and Systems (ISCAS), Austin, TX, USA, 27 May–1 June 2022; pp. 2556–2560. [Google Scholar] [CrossRef]
- Kang, G.; Choi, W.; Park, J. Embedded DRAM-Based Memory Customization for Low-Cost FFT Processor Design. IEEE Trans. Very Large Scale Integr. Syst. 2017, 25, 3484–3494. [Google Scholar] [CrossRef]
- Meinerzhagen, P.; Teman, A.; Giterman, R.; Edri, N.; Burg, A.; Fish, A. Gain-Cell Embedded DRAMs for Low-Power VLSI Systems-on-Chip; Springer International Publishing: Cham, Switzerland, 2018. [Google Scholar]
- Giterman, R.; Fish, A.; Burg, A.; Teman, A. A 4-Transistor nMOS-Only Logic-Compatible Gain-Cell Embedded DRAM With Over 1.6-ms Retention Time at 700 mV in 28-nm FD-SOI. IEEE Trans. Circuits Syst. I 2017, 65, 1245–1256. [Google Scholar] [CrossRef]
- Giterman, R.; Fish, A.; Geuli, N.; Mentovich, E.; Burg, A.; Teman, A. An 800-MHz Mixed-VT 4T IFGC Embedded DRAM in 28-nm CMOS Bulk Process for Approximate Storage Applications. IEEE J. Solid-State Circuits 2018, 53, 2136–2148. [Google Scholar] [CrossRef]
- Harel, O.; Casarrubias, E.N.; Eggimann, M.; Gürkaynak, F.; Benini, L.; Teman, A.; Giterman, R.; Burg, A. 64kB 65nm GC-eDRAM with Half-Select Support and Parallel Refresh Technique. IEEE Solid-State Circuits Lett. 2022, 5, 170–173. [Google Scholar] [CrossRef]
- Hsieh, E.R.; Huang, C.F.; Huang, S.Y.; Miu, M.L.; Lu, S.M.; Wu, Y.S.; Ye, Y.H. A Logic Fully Comparable Single-Supply Capacitor-Less 1-FinFET-1-Source-Channel-Drain-Diode (1T1D) Embedded DRAM MACRO in 16-nm FinFET. IEEE Solid-State Circuits Lett. 2023, 6, 249–252. [Google Scholar] [CrossRef]
- Xie, S.; Ni, C.; Sayal, A.; Jain, P.; Hamzaoglu, F.; Kulkarni, J.P. 16.2 eDRAM-CIM: Compute-In-Memory Design with Reconfigurable Embedded-Dynamic-Memory Array Realizing Adaptive Data Converters and Charge-Domain Computing. In Proceedings of the 2021 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 13–22 February 2021; Volume 64, pp. 248–250. [Google Scholar] [CrossRef]
- Chen, Z.; Chen, X.; Gu, J. 15.3 A 65 nm 3T Dynamic Analog RAM-Based Computing-in-Memory Macro and CNN Accelerator with Retention Enhancement, Adaptive Analog Sparsity and 44TOPS/W System Energy Efficiency. In Proceedings of the 2021 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 13–22 February 2021; Volume 64, pp. 240–242. [Google Scholar] [CrossRef]
- Lee, I.; Kim, E.; Kang, N.; Oh, H.; Kim, J.J. In-Memory Neural Network Accelerator based on eDRAM Cell with Enhanced Retention Time. In Proceedings of the 2023 60th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 9–13 July 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Yu, C.; Yoo, T.; Kim, H.; Kim, T.T.H.; Chuan, K.C.T.; Kim, B. A Logic-Compatible eDRAM Compute-In-Memory With Embedded ADCs for Processing Neural Networks. IEEE Trans. Circuits Syst. I Regul. Pap. 2021, 68, 667–679. [Google Scholar] [CrossRef]
- Zhao, Y.; Shen, Z.; Xu, J.; Chai, K.C.; Wu, Y.; Wang, C. A Novel Transpose 2T-DRAM based Computing-in-Memory Architecture for On-chip DNN Training and Inference. In Proceedings of the 2023 IEEE 5th International Conference on Artificial Intelligence Circuits and Systems (AICAS), Hangzhou, China, 11–13 June 2023; pp. 1–4. [Google Scholar] [CrossRef]
- Golman, R.; Giterman, R.; Harel, O.; Teman, A. Improved Read Access in GC-eDRAM Memory by Dual-Negative Word-Line Technique. In Proceedings of the 2020 IEEE International Symposium on Circuits and Systems (ISCAS), Seville, Spain, 12–14 October 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Chang, K.K.W.; Lee, D.; Chishti, Z.; Alameldeen, A.R.; Wilkerson, C.; Kim, Y.; Mutlu, O. Improving DRAM performance by parallelizing refreshes with accesses. In Proceedings of the 2014 IEEE 20th International Symposium on High Performance Computer Architecture (HPCA), Orlando, FL, USA, 15–19 February 2014; pp. 356–367. [Google Scholar] [CrossRef]
- Bhati, I.; Chang, M.T.; Chishti, Z.; Lu, S.L.; Jacob, B. DRAM Refresh Mechanisms, Penalties, and Trade-Offs. IEEE Trans. Comput. 2016, 65, 108–121. [Google Scholar] [CrossRef]
- Kotra, J.B.; Shahidi, N.; Chishti, Z.A.; Kandemir, M.T. Hardware-software co-design to mitigate DRAM refresh overheads: A case for refresh-aware process scheduling. ACM SIGPLAN Not. 2017, 52, 723–736. [Google Scholar] [CrossRef]
- Pan, X.; Mueller, F. The Colored Refresh Server for DRAM. In Proceedings of the 2019 IEEE 22nd International Symposium on Real-Time Distributed Computing (ISORC), Valencia, Spain, 7–9 May 2019; pp. 27–34. [Google Scholar] [CrossRef]
- Yağlikçi, A.G.; Olgun, A.; Patel, M.; Luo, H.; Hassan, H.; Orosa, L.; Ergin, O.; Mutlu, O. HiRA: Hidden Row Activation for Reducing Refresh Latency of Off-the-Shelf DRAM Chips. In Proceedings of the 2022 55th IEEE/ACM International Symposium on Microarchitecture (MICRO), Chicago, IL, USA, 1–5 October 2022; pp. 815–834. [Google Scholar] [CrossRef]
- Kazimirsky, A.; Wimer, S. Opportunistic Refreshing Algorithm for eDRAM Memories. IEEE Trans. Circuits Syst. I Regul. Pap. 2016, 63, 1921–1932. [Google Scholar] [CrossRef]
- Zulian, É.F.; Weis, C.; Wehn, N. Access-Aware Per-Bank DRAM Refresh for Reduced DRAM Refresh Overhead. In Proceedings of the 2020 IEEE International Symposium on Circuits and Systems (ISCAS), Seville, Spain, 12–14 October 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Liu, J.; Jaiyen, B.; Veras, R.; Mutlu, O. RAIDR: Retention-aware intelligent DRAM refresh. In Proceedings of the 2012 39th Annual International Symposium on Computer Architecture (ISCA), Portland, OR, USA, 9–13 June 2012; pp. 1–12. [Google Scholar] [CrossRef]
- Herman, R.; Frankel, B.; Wimer, S. Optimal queuing-based memory refreshing algorithm for energy efficient processors. Comput. Electr. Eng. 2018, 71, 505–514. [Google Scholar] [CrossRef]
- Mori, H.; Nakagawa, T.; Kitahara, Y.; Kawamoto, Y.; Takagi, K.; Yoshimoto, S.; Izumi, S.; Kawaguchi, H.; Yoshimoto, M. A low-energy 8T dual-port SRAM for image processor with selective sourceline drive scheme in 28-nm FD-SOI process technology. In Proceedings of the 2016 IEEE International Conference on Electronics, Circuits and Systems (ICECS), Monte Carlo, Monaco, 11–14 December 2016; pp. 532–535. [Google Scholar] [CrossRef]
- Guo, Z.; Carlson, A.; Pang, L.T.; Duong, K.T.; Liu, T.J.K.; Nikolic, B. Large-Scale SRAM Variability Characterization in 45 nm CMOS. IEEE J. Solid-State Circuits 2009, 44, 3174–3192. [Google Scholar] [CrossRef][Green Version]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 6T SRAM [54] | 8T 1W1R SRAM [54] | 8T 2WR SRAM [3] | 10T 1W2R SRAM [2] | Conventional 2T-NMOS Gain-Cell [34] | Proposed 4T Gain-Cell [This Work] | |
|---|---|---|---|---|---|---|
| Technology Node | 28 nm FD-SOI | 28 nm FD-SOI | 65 nm CMOS | 45 nm CMOS | 28 nm FD-SOI | 28 nm FD-SOI |
| Supply Voltage | 0.7 V | 0.48–0.7 V | 1.2 V | 1 V | 0.9 V | 0.9 V |
| Availability | 100% | 100% | 100% | 100% | 97.3% * | 100% |
| Cell Size | ||||||
| Ratio to 6TSRAM | 1 X | 1.3 X | 1.44 X | 2.14 X | 0.47 X | 0.71 X |
| Data Retention Time | Static | Static | Static | Static | ||
| Leakage Power (In 28 nm FD-SOI) | 12.9 pW/bit | 16.3 pW/bit | 13.1 pW/bit | 16.7 pW/bit | 576 fW/bit | 1.25 pW/bit |
| 6T 1W5R Gain Cell [This Work] | 16T 1W5R SRAM [5] | 9T 1W8R Gain Cell [This Work] | 20T 1W8R SRAM [4] | 12T 6W6R Gain Cell [This Work] | 16T 3W3R/6W6R SRAM [16] | |
|---|---|---|---|---|---|---|
| Technology Node | 28 nm FD-SOI | 90 nm CMOS | 28 nm FD-SOI | 40 nm CMOS | 28 nm FD-SOI | 7 nm CMOS |
| Supply Voltage | 0.9 V | Not Reported | 0.9 V | 1.1 V | 0.9 V | 0.9 V |
| Availability * | 97.3% * | 100% | 97.3% * | 100% | 99.1% * | 100% |
| Cell Size | ||||||
| Ratio to 6TSRAM | 1.7 X | 7.36 X | 3.2 X | 12.9 X | 5.46 X | 14.25 X |
| Data Retention Time | Static | Static | Static | |||
| Leakage Power (In 28 nm FD-SOI) | 3.12 pW/bit | 34.6 pW/bit | 3.45 pW/bit | 90 pW/bit | 12.6 pW/bit | 108 pW/bit |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Golman, R.; Giterman, R.; Teman, A. Multi-Ported GC-eDRAM Bitcell with Dynamic Port Configuration and Refresh Mechanism. J. Low Power Electron. Appl. 2024, 14, 2. https://doi.org/10.3390/jlpea14010002
Golman R, Giterman R, Teman A. Multi-Ported GC-eDRAM Bitcell with Dynamic Port Configuration and Refresh Mechanism. Journal of Low Power Electronics and Applications. 2024; 14(1):2. https://doi.org/10.3390/jlpea14010002
Chicago/Turabian StyleGolman, Roman, Robert Giterman, and Adam Teman. 2024. "Multi-Ported GC-eDRAM Bitcell with Dynamic Port Configuration and Refresh Mechanism" Journal of Low Power Electronics and Applications 14, no. 1: 2. https://doi.org/10.3390/jlpea14010002
APA StyleGolman, R., Giterman, R., & Teman, A. (2024). Multi-Ported GC-eDRAM Bitcell with Dynamic Port Configuration and Refresh Mechanism. Journal of Low Power Electronics and Applications, 14(1), 2. https://doi.org/10.3390/jlpea14010002