Opportunistic Design Margining for Area and Power Efficient Processor Pipelines in Real Time Applications

Abstract
:1. Introduction
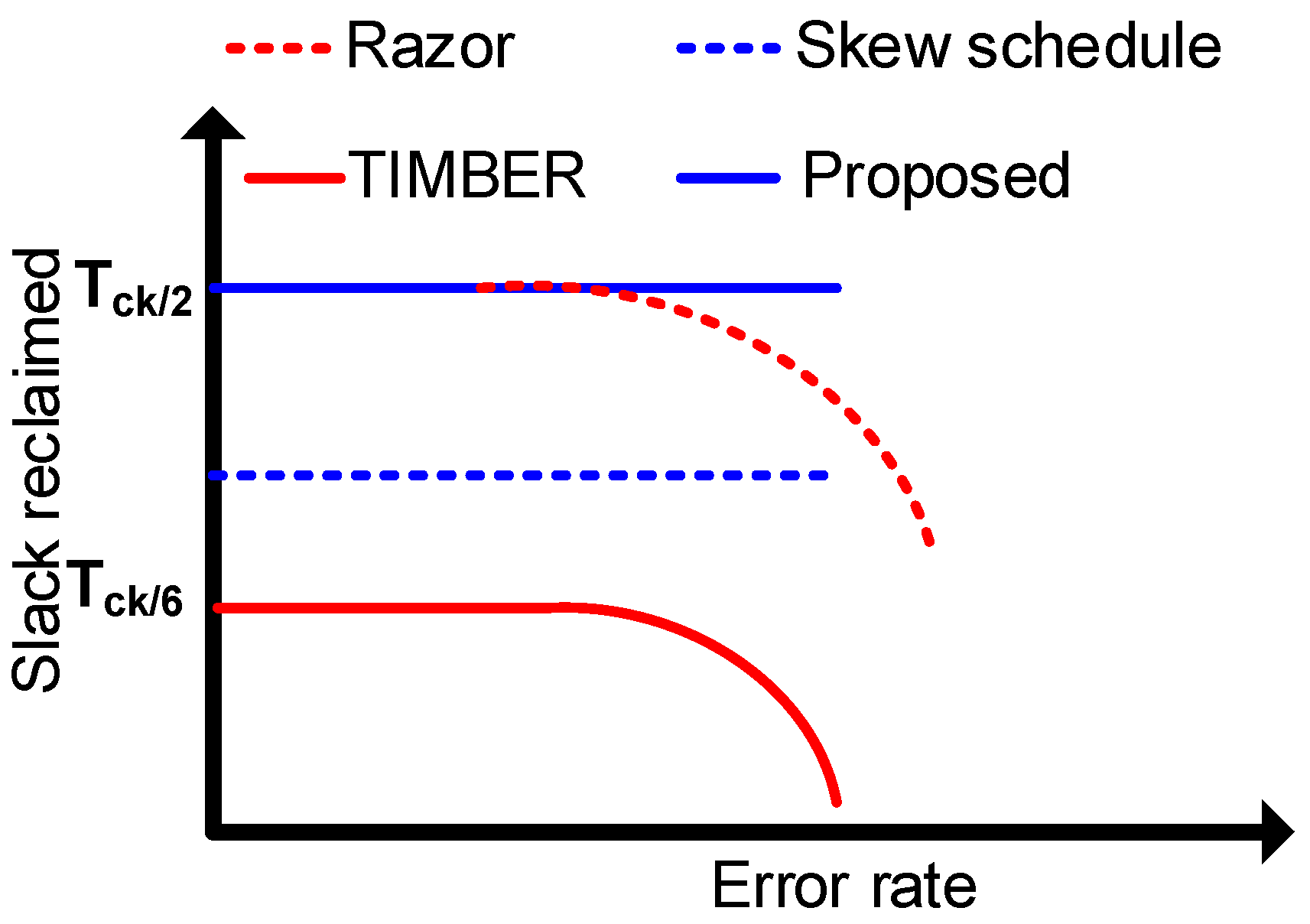
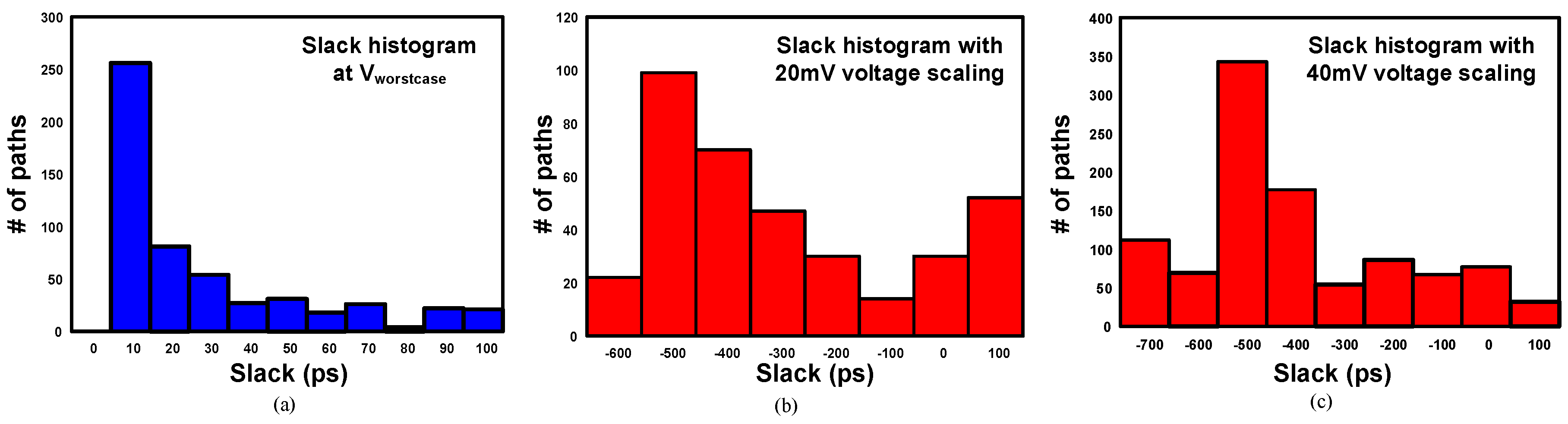
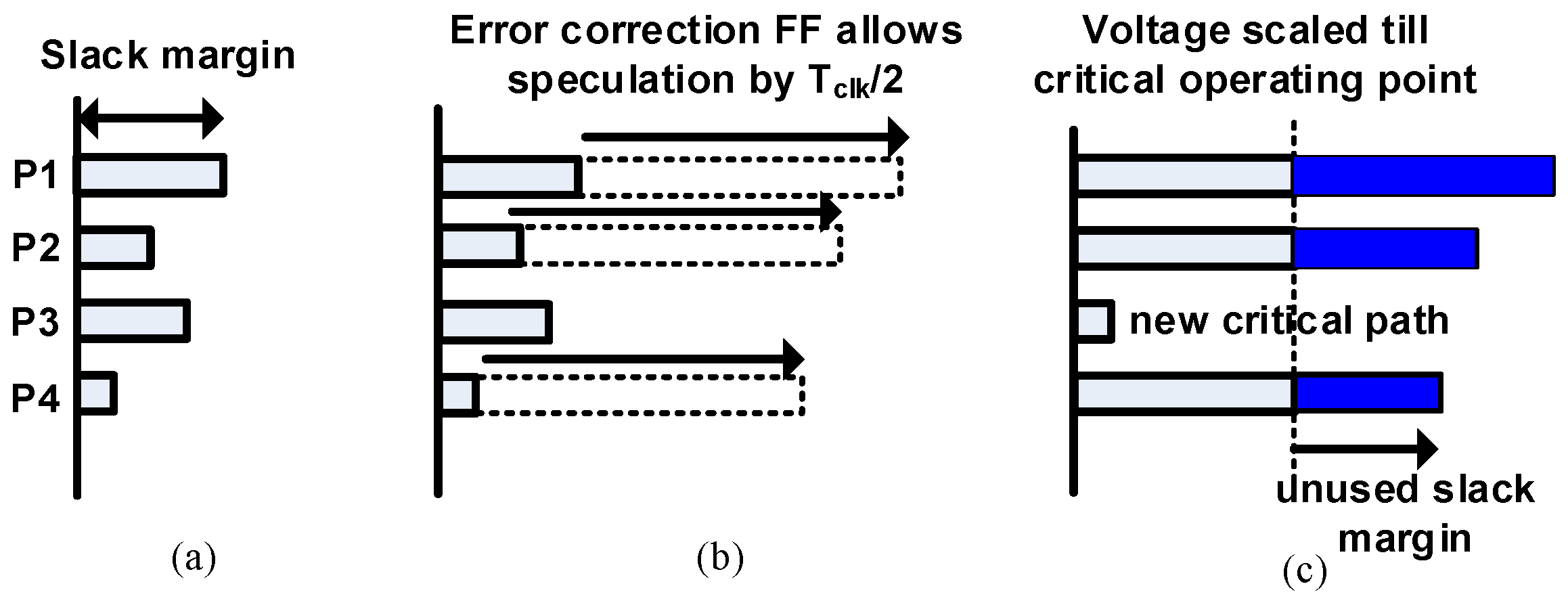
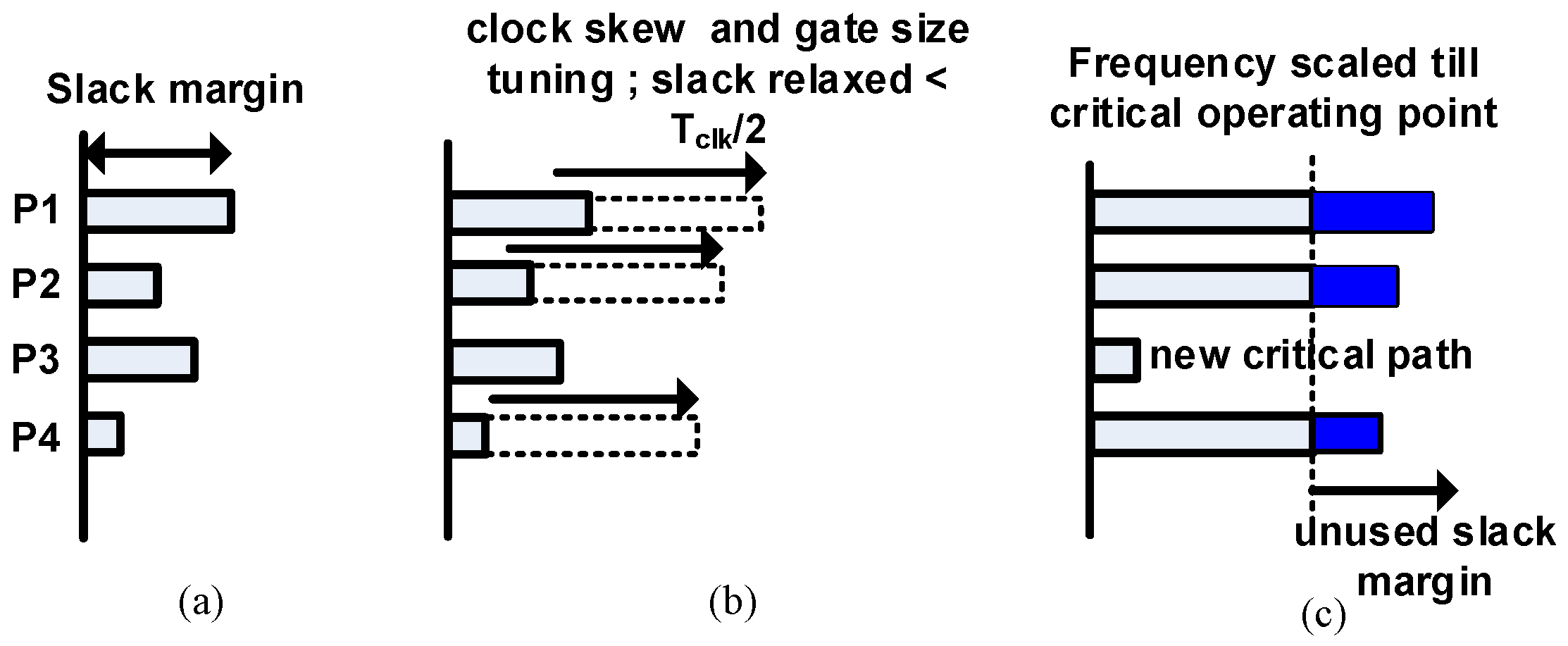
2. Motivation
3. Proposed Variation Tolerant Pipeline Design
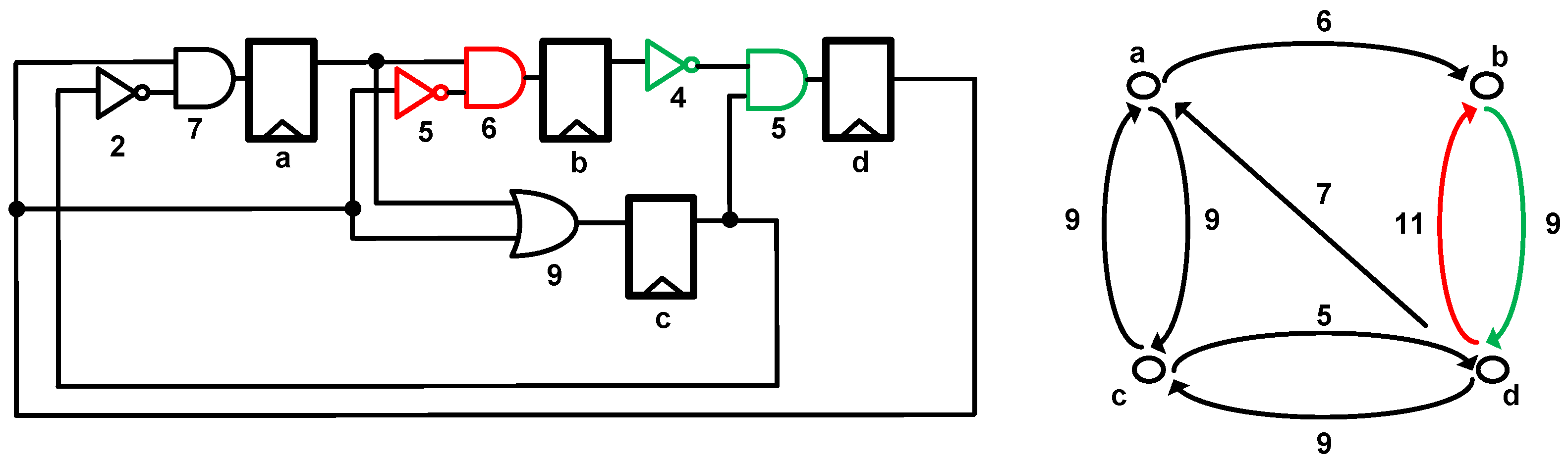
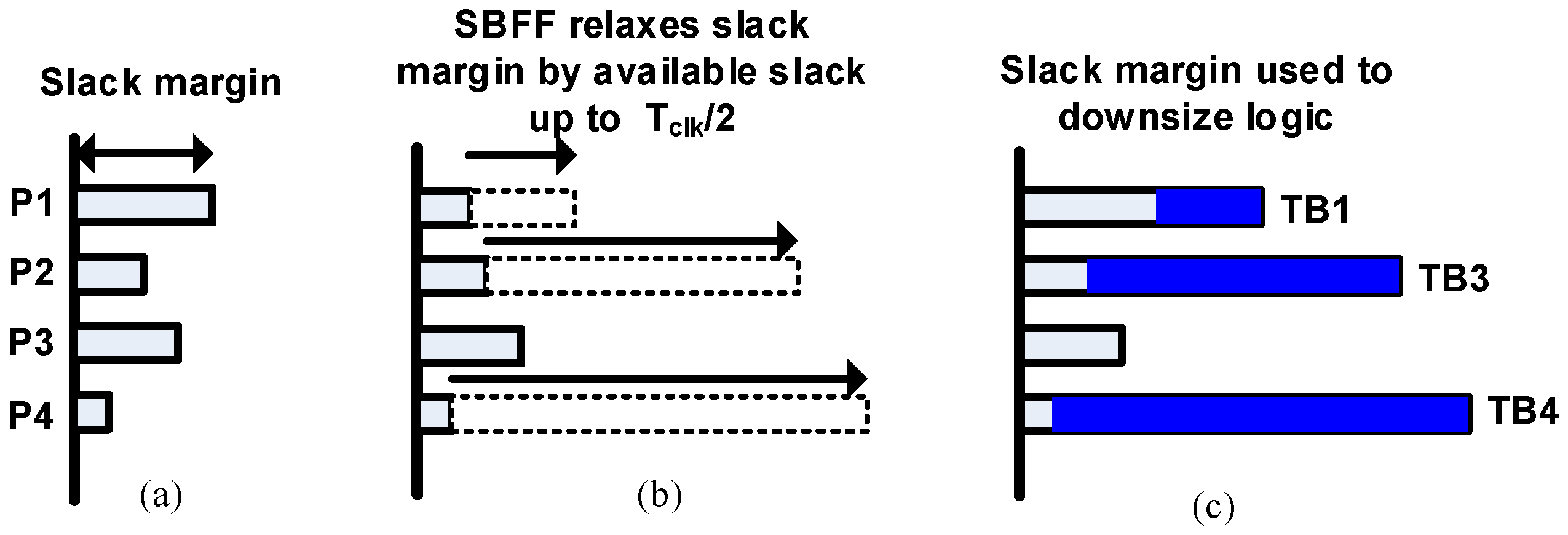
3.1. Slack Balancing Principle
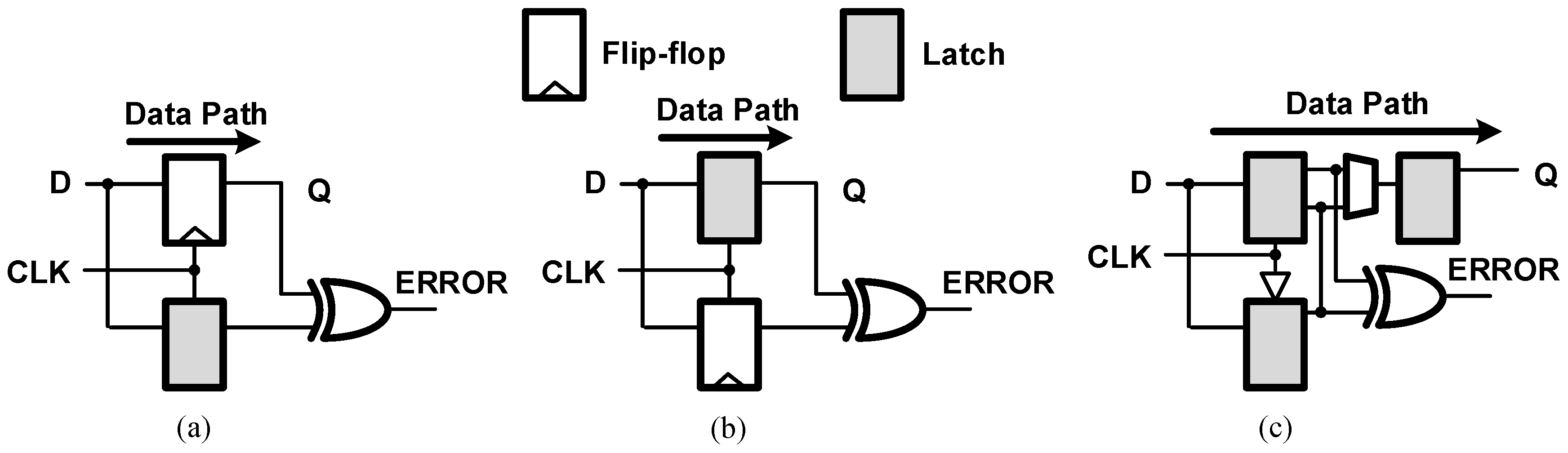
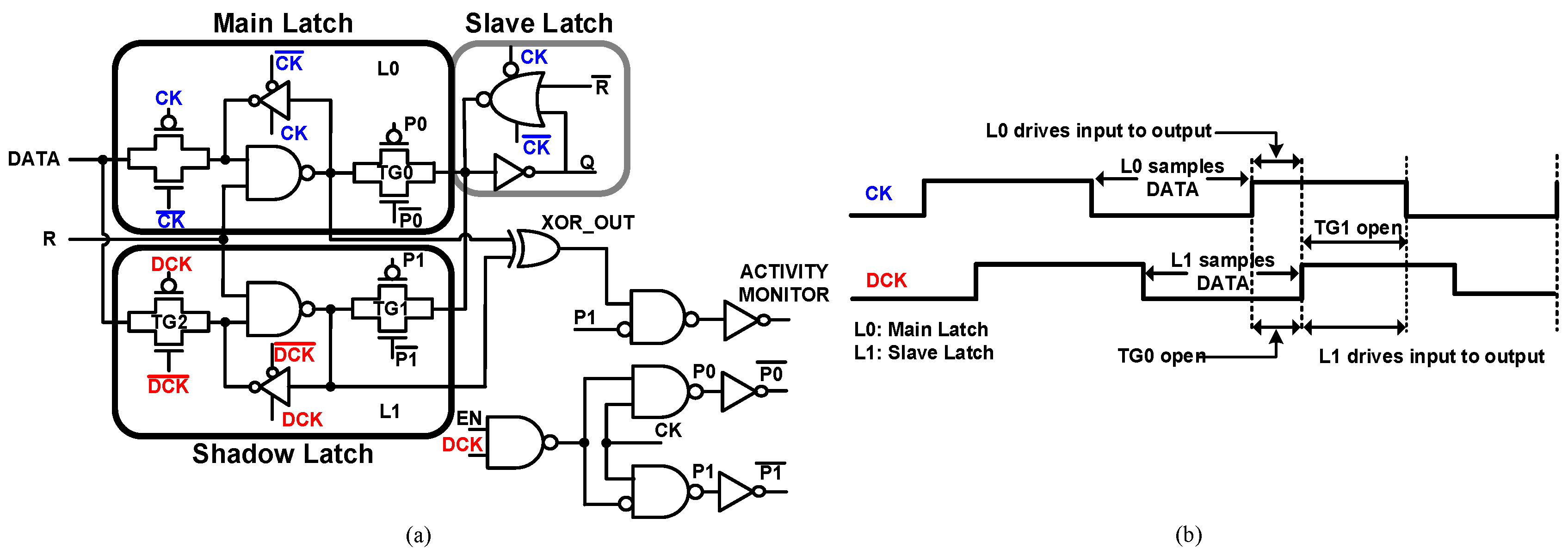
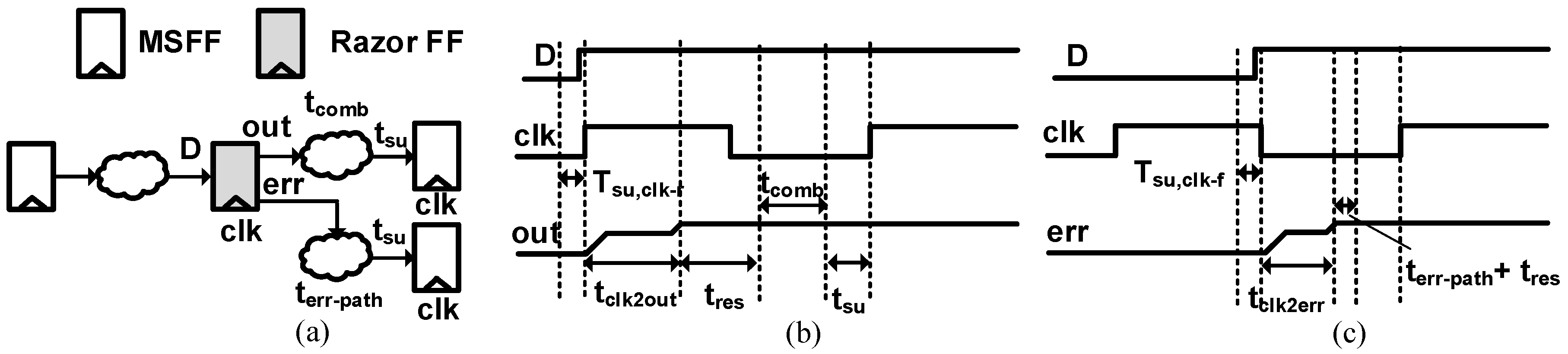
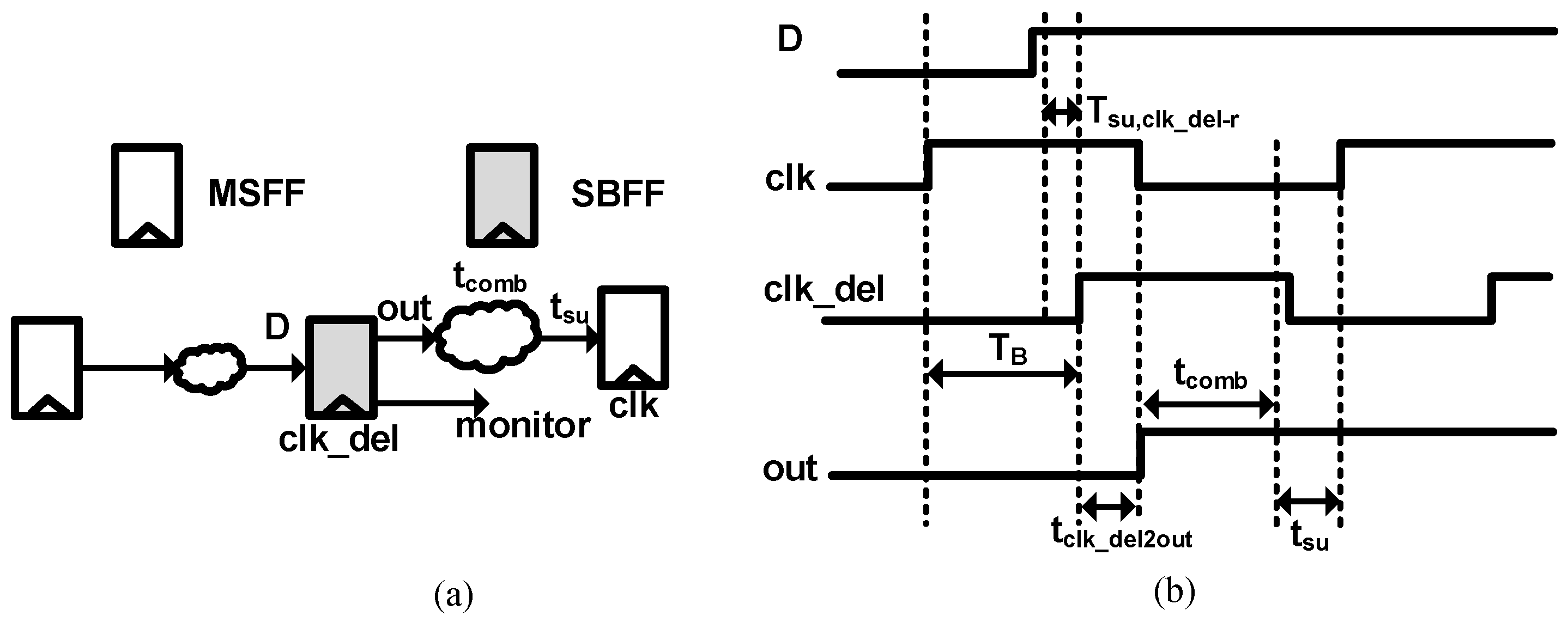
3.2. Slack Balancing Flip-Flop
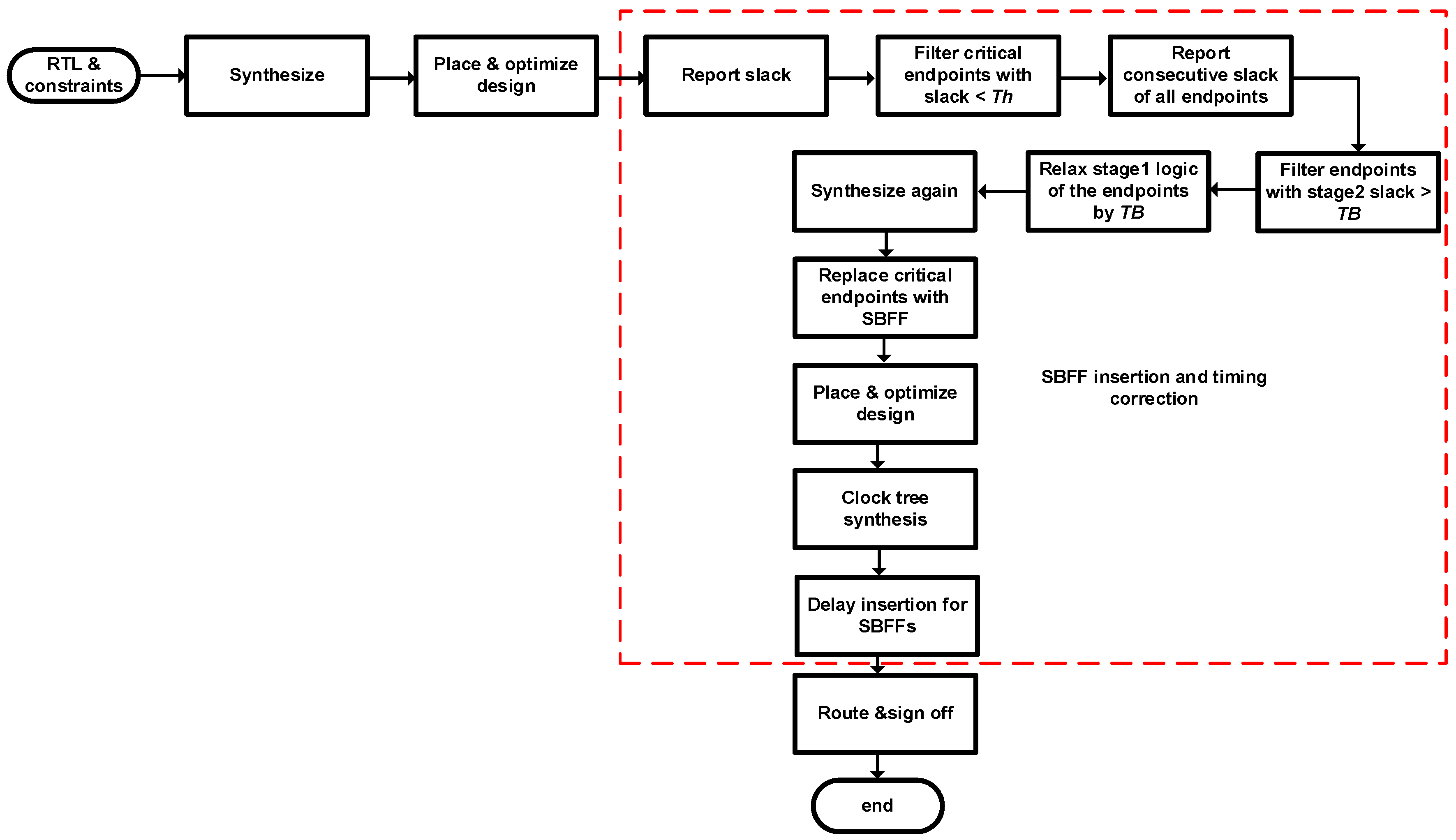
3.3. Pipeline Design Flow Using SBFF
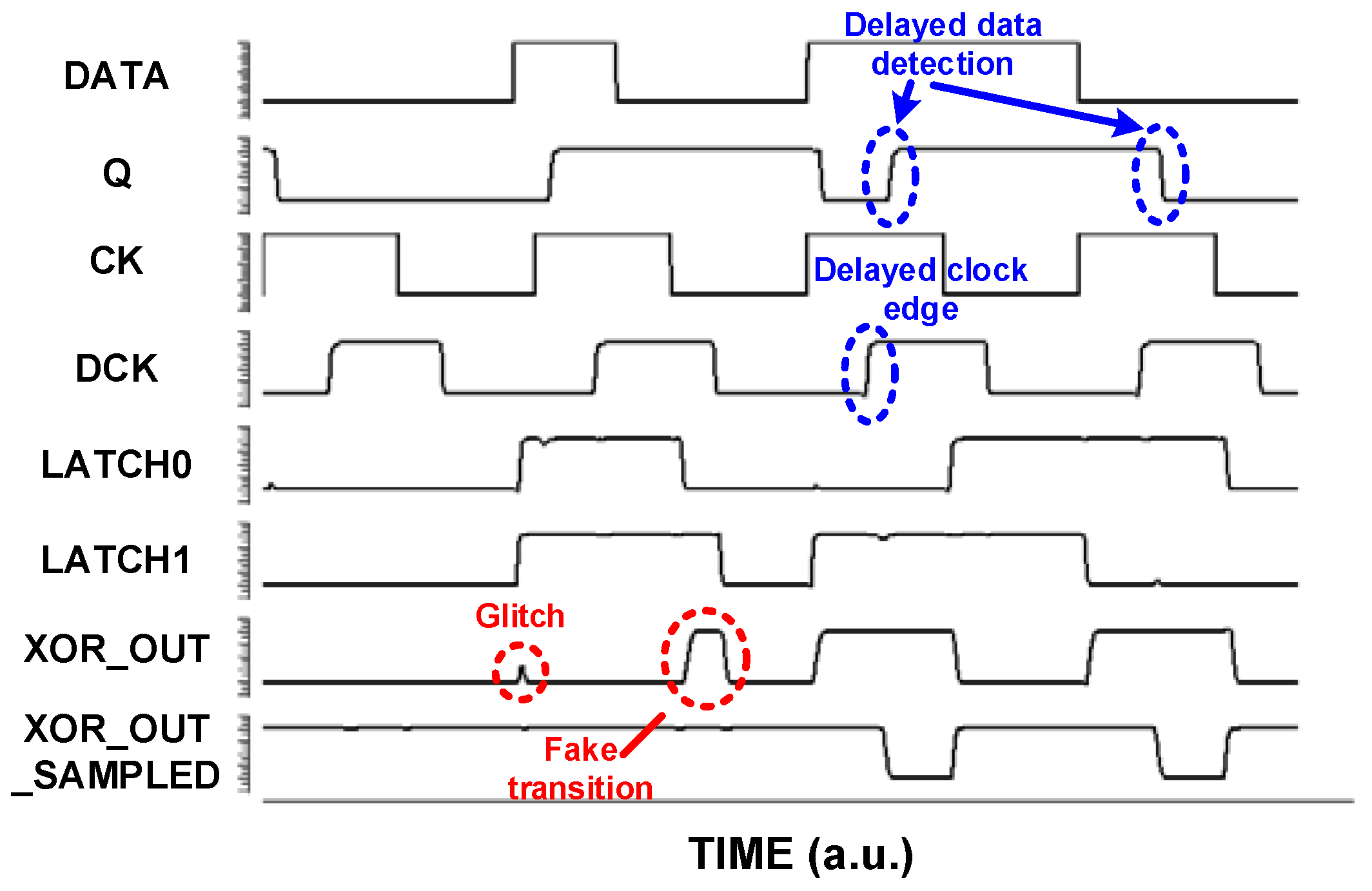
3.4. Metastability and Hold Issues
4. Power Optimization Algorithm
| Algorithm 1: Slack Analysis and Downsizing (SizeOpt) |
| Input: Initial Netlist Output: Netlist with SBFF and optimized cells
|
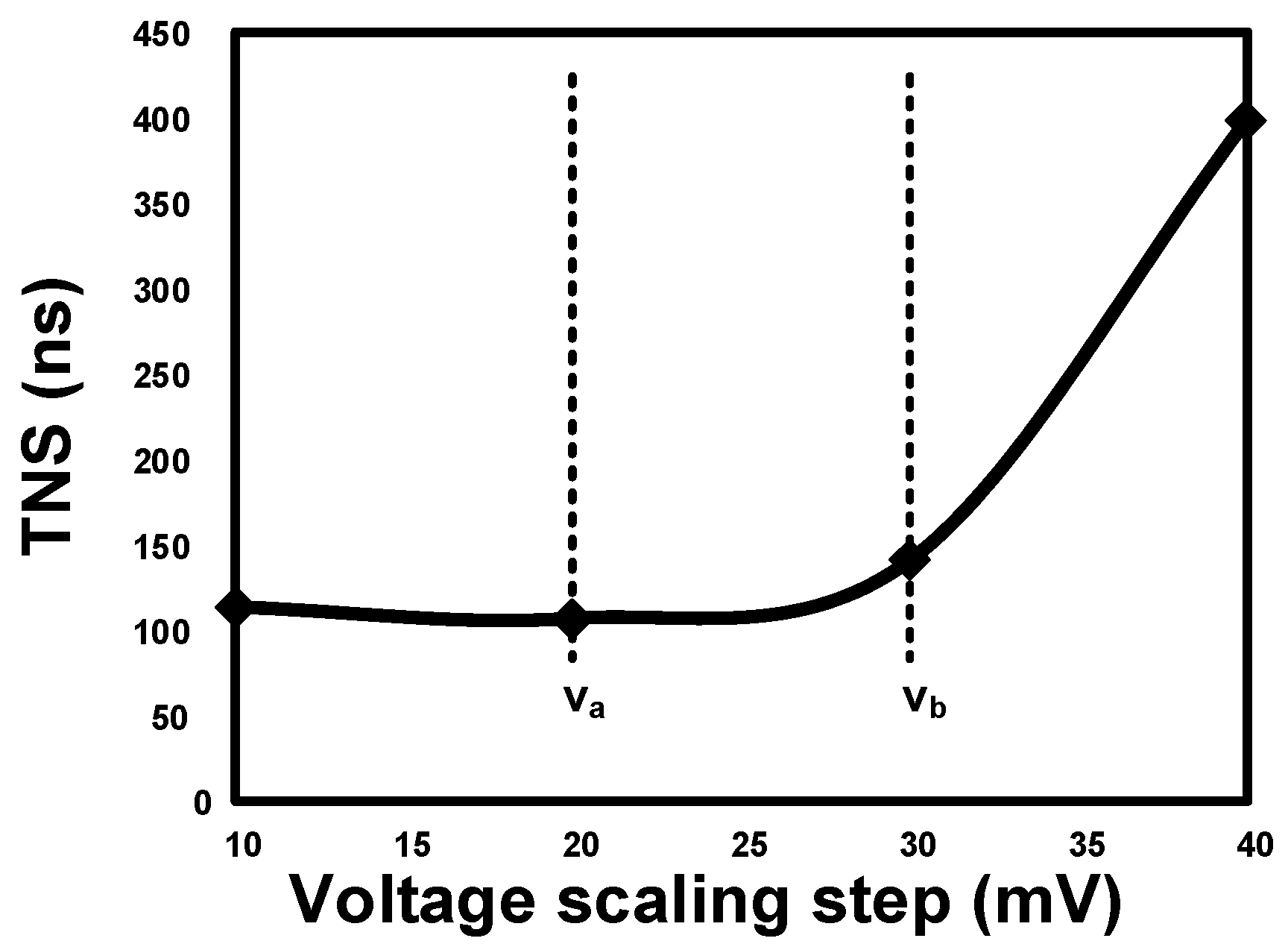
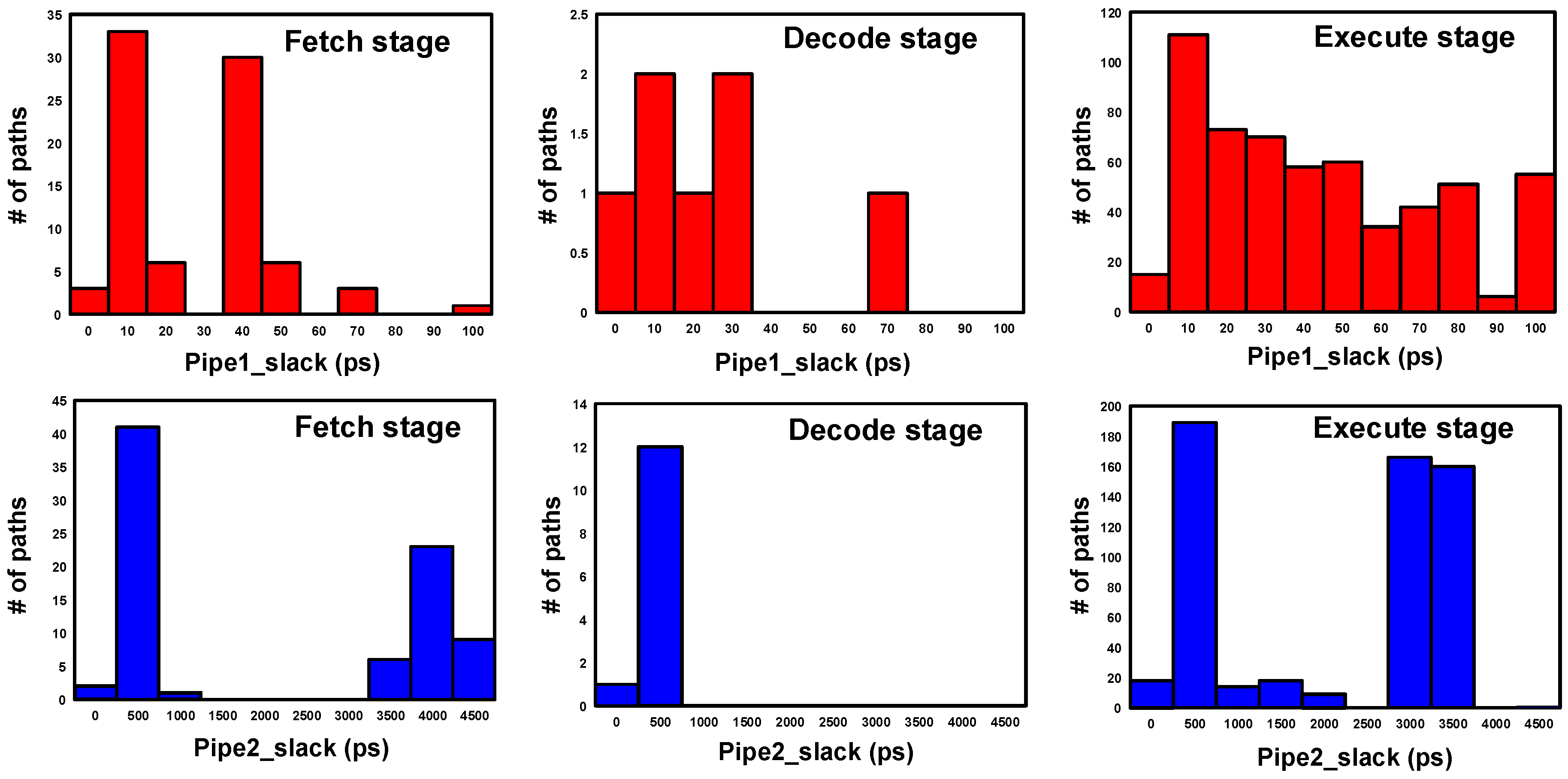
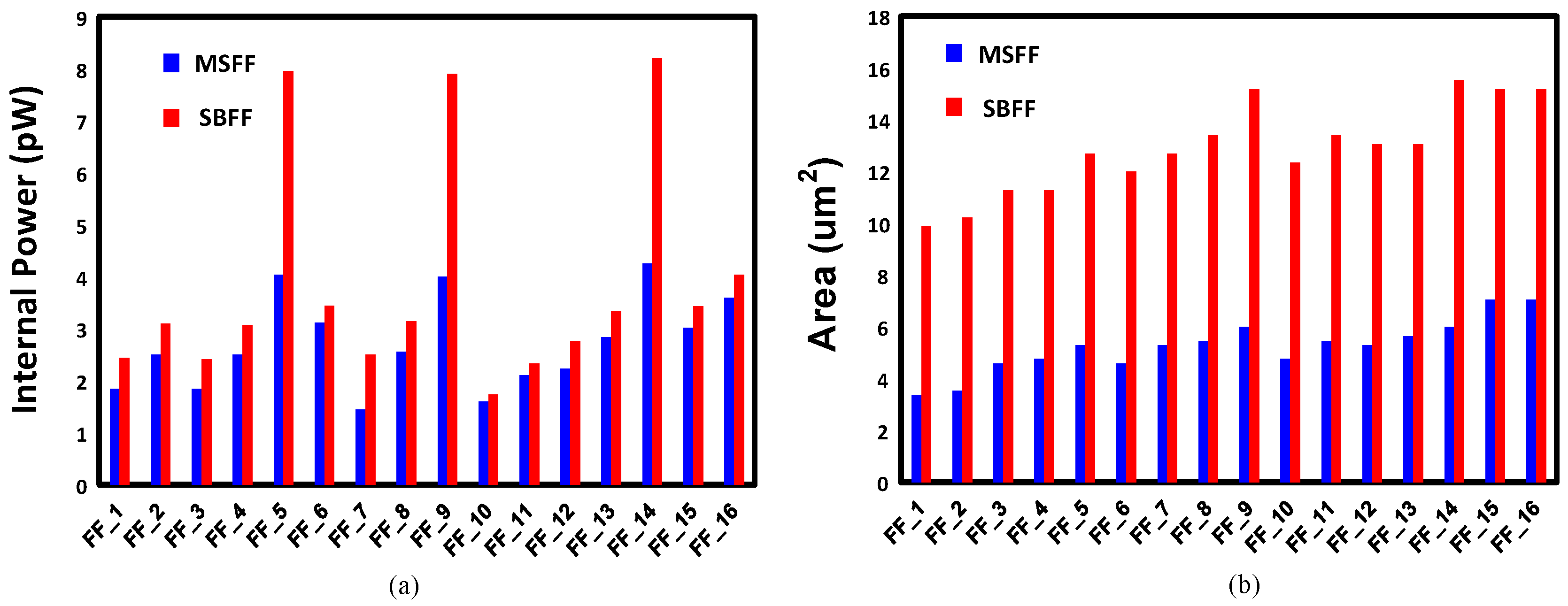
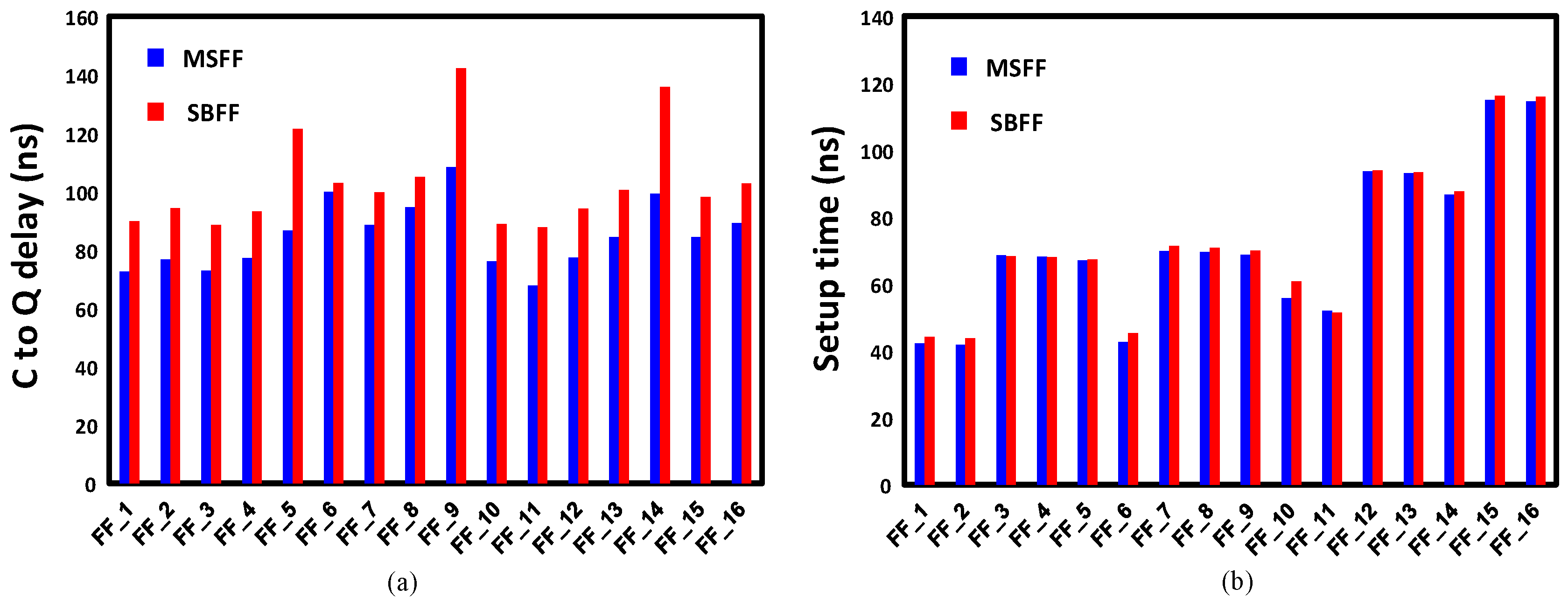
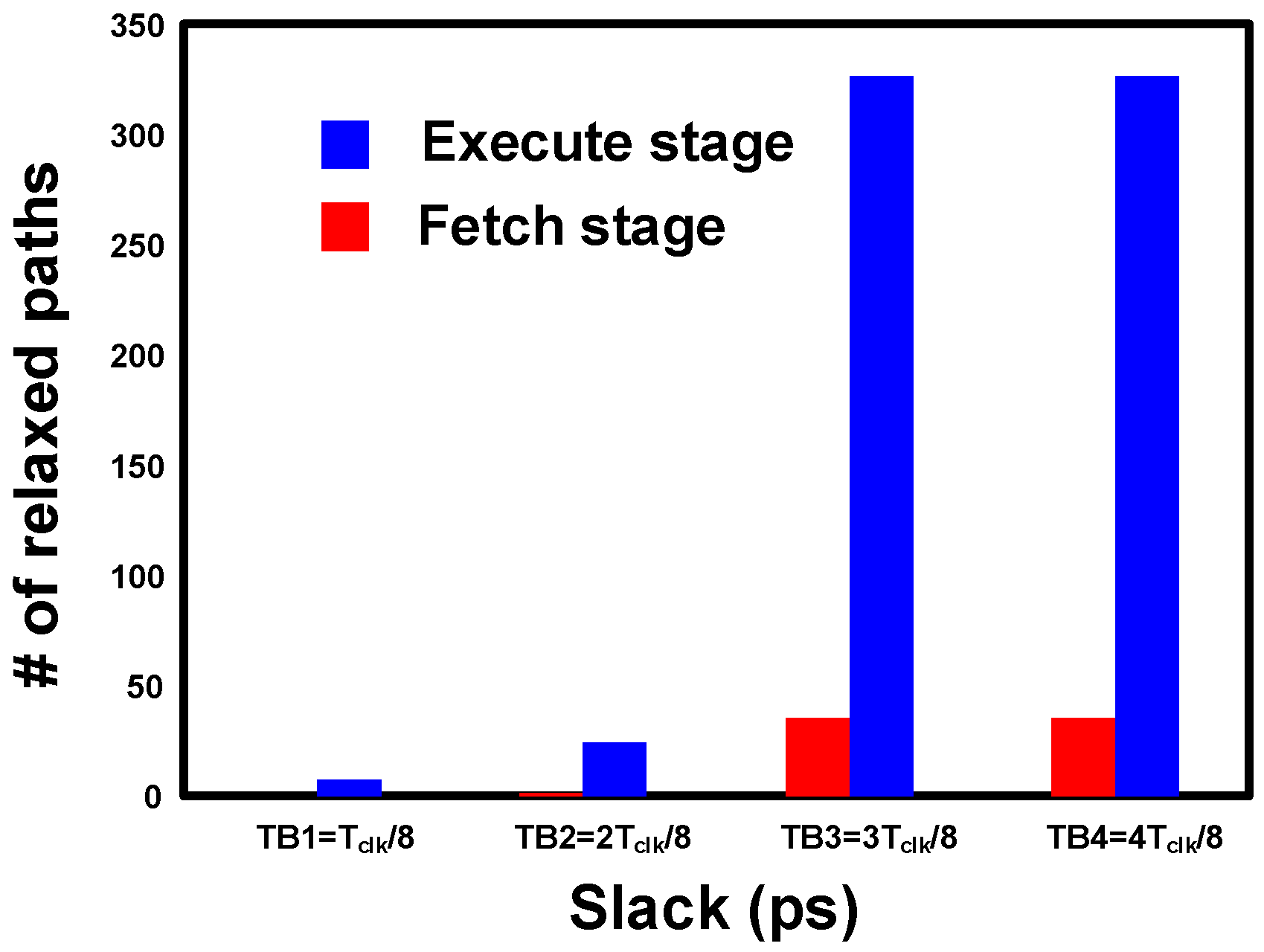
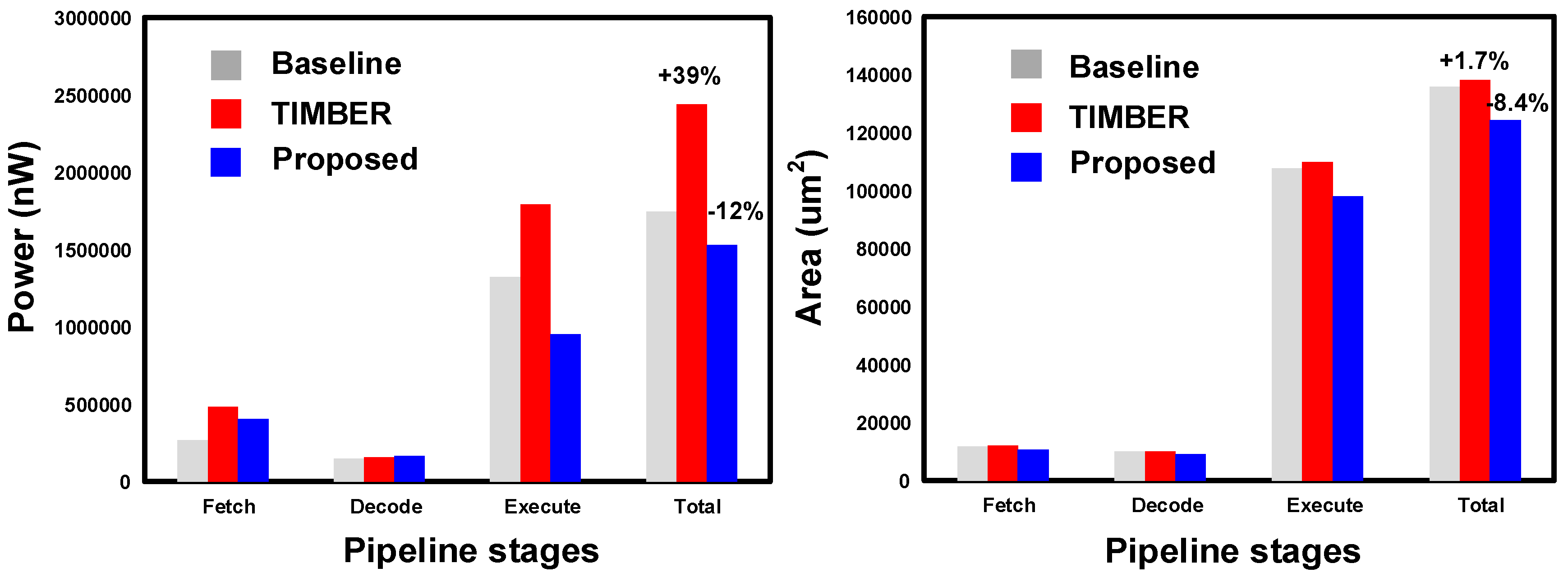
5. Results and Analysis
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Borkar, S.; Karnik, T.; Narendra, S.; Tschanz, J.; Keshavarzi, A.; De, V. Parameter Variations and Impact on Circuits and Microarchitecture. In Proceedings of the 40th Annual Design Automation Conference (DAC), Anaheim, CA, USA, 2–6 June 2003. [Google Scholar]
- Ghosh, S.; Roy, K. Parameter variation tolerance and error resiliency: New design paradigm for the nanoscale era. Proc. IEEE 2010, 98, 1718–1751. [Google Scholar] [CrossRef]
- Asenov, A.; Brown, A.R.; Davies, J.H.; Kaya, S.; Slavcheva, G. Simulation of intrinsic parameter fluctuations in decananometer and nanometer-scale MOSFETs. IEEE Trans. Electron Devices 2003, 50, 1837–1852. [Google Scholar] [CrossRef]
- Nassif, S.R. Modeling and analysis of manufacturing variations. In Proceedings of the Custom Integrated Circuit Conference, San Diego, CA, USA, 9 May 2001. [Google Scholar]
- Borkar, S. Designing Reliable Systems from Unreliable Components: The Challenges of Transistor Variability and Degradation. IEEE Micro 2005, 25, 10–16. [Google Scholar] [CrossRef]
- Bowman, K.A.; Duvall, S.G.; Meindl, J.D. Impact of Die-to-Die and With-in-Die Parameter Fluctuations on the Maximum Clock Frequency Distribution for Gigascale Integration. IEEE J. Solid State Circuits 2002, 37, 183–190. [Google Scholar] [CrossRef]
- Dreslinski, R.G.; Wieckowski, M.; Blaauw, D.; Sylvester, D.; Mudge, T. Near-Threshold Computing: Reclaiming Moore’s Law through Energy Efficient Integrated Circuits. Proc. IEEE 2010, 98, 253–266. [Google Scholar] [CrossRef]
- Meijer, M.; Liu, B.; van Veen, R.; de Gyvez, J.P. Post-Silicon Tuning Capabilities of 45 nm Low-Power CMOS Digital Circuits. In Proceedings of the Symposium on VLSI Circuits, Kyoto, Japan, 16–18 June 2009. [Google Scholar]
- Kim, T.; Persaud, R.; Kim, C.H. Silicon odometer: An on-chip reliability monitor for measuring frequency degradation of digital circuits. In Proceedings of the Very Large Scale Integration (VLSI) Circuits Symposium, Kyoto, Japan, 14–16 June 2007. [Google Scholar]
- Gupta, P.; Agarwal, Y.; Dolecek, L.; Dutt, N.; Gupta, R.K.; Kumar, R.; Mitra, S.; Nicolau, A.; Rosing, T.S.; Srivastava, M.B.; et al. Underdesigned and Opportunistic Computing in Presence of Hardware Variability. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2013, 32, 8–23. [Google Scholar] [CrossRef]
- Tschanz, J.; Bowman, K.; Walstra, S.; Agostinelli, M.; Karnik, T.; De, V. Tunable Replica Circuits and Adaptive Voltage-Frequency Techniques for Dynamic Voltage, Temperature, and Aging Variation Tolerance. In Proceedings of the Symposium on VLSI Circuits, Kyoto, Japan, 16–18 June 2009. [Google Scholar]
- Ernst, D.; Kim, N.S.; Das, S.; Pant, S.; Rao, R.; Pham, T.; Ziesler, C.; Blaauw, D.; Austin, T.; Mudge, T.; et al. Razor: A Low-Power Pipeline Based on Circuit-Level Timing Speculation. In Proceedings of the 36th Symposium on Microarchitecture (MICRO-36), San Diego, CA, USA, 3–5 December 2003. [Google Scholar]
- Das, S.; Tokunaga, C.; Pant, S.; Ma, W.; Kalaiselvan, S.; Lai, K.; Bull, D.; Blaauw, D. Razor II: In Situ Error Detection and Correction for PVT and SER Tolerance. IEEE J. Solid-State Circuits 2009, 44, 32–48. [Google Scholar] [CrossRef]
- Bowman, K.; Tschanz, J.; Kim, N.; Lee, J.; Wilkerson, C.; Lu, S.; Karnik, T.; De, V. Energy-Efficient and Metastability-Immune Resilient Circuits for Dynamic Variation Tolerance. IEEE J. Solid-State Circuits 2009, 44, 49–63. [Google Scholar] [CrossRef]
- Fojtik, M.; Fick, D.; Kim, Y.; Pinckney, N.; Harris, D.M.; Blaauw, D.; Sylvester, D. Bubble Razor: Eliminating timing margins in an ARM cortex-M3 processor in 45 nm CMOS using architecturally independent error detection and correction. IEEE J. Solid-State Circuits 2013, 48, 66–81. [Google Scholar] [CrossRef]
- Joshi, V.; Blaauw, D.; Sylvester, D. Soft-edge flip-flops for improved timing yield: Design and optimization. In Proceedings of the IEEF/ACM International Conference on Computer-Aided Design, San Jose, CA, USA, 5–8 November 2007. [Google Scholar]
- Choudhury, M.; Chandra, V.; Mohanram, K.; Aitken, R. TIMBER: Time borrowing and error relaying for online timing error resilience. In Proceedings of the Design, Automation & Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 8–12 March 2010. [Google Scholar]
- Bull, D.; Das, S.; Shivashankar, K.; Dasika, G.; Flautner, K.; Blaauw, D. A power-efficient 32-bit ARM processor using timing-error detection and correction for transient-error tolerance and adaptation to PVT variation. IEEE J. Solid-State Circuits 2011, 46, 18–31. [Google Scholar] [CrossRef]
- Das, S.; Roberts, D.; Lee, S.; Pant, S.; Blaauw, D.; Austin, T.; Flautner, K.; Mudge, T.T. A self-tuning DVS processor using delay error detection and correction. IEEE J. Solid-State Circuits 2006, 41, 792–804. [Google Scholar] [CrossRef]
- Austin, T.; Bertacco, V.; Blaauw, D.; Mudge, T. Opportunities and Challenges for Better Than Worst-Case Design. In Proceedings of the Asia and South Pacific Design Automation Conference, Shanghai, China, 18–21 January 2005. [Google Scholar]
- Liu, X.; Papaefthymiou, M.C.; Friedman, E.G. Maximizing performance by retiming and clock skew scheduling. In Proceedings of the 36th Design Automation Conference, New Orleans, LA, USA, 21–25 June 1999. [Google Scholar]
- Monteiro, J.; Devadas, S.; Ghosh, A. Retiming sequential circuits for low power. In Proceedings of the IEEE/ACM International Conference on Computer-Aided Design, Santa Clara, CA, USA, 7–11 November 1993. [Google Scholar]
- Neves, J.L.; Friedman, E.G. Optimal clock skew scheduling tolerant to process variations. In Proceedings of the 33rd Annual Design Automation Conference, Las Vegas, NV, USA, 3–7 June 1996. [Google Scholar]
- Sathyamurthy, H.; Sapatnekar, S.; Fishburn, J. Speeding up pipelined circuits through a combination of gate sizing and clock skew optimization. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 1998, 17, 173–182. [Google Scholar] [CrossRef]
- Xi, J.G.; Dai, W.W.M. Useful-skew clock routing with gate sizing for low power design. In Proceedings of the 33rd Annual Design Automation Conference, Las Vegas, NV, USA, 3–7 June 1996. [Google Scholar]
- Sarangi, S.R.; Greskamp, B.; Tiwari, A.; Torrellas, J. EVAL: Utilizing processors with variation-induced timing errors. In Proceedings of the International Symposium on Microarchitecture, Lake Como, Italy, 8–12 November 2008. [Google Scholar]
- Greskamp, B.; Wan, L.; Karpuzcu, W.R.; Cook, J.J.; Torrellas, J.; Chen, D.; Zilles, C. BlueShift: Designing Processors for Timing Speculation from the Ground Up. In Proceedings of the IEEE International Symposium on High Performance Computer Architecture, Raleigh, NC, USA, 14–18 February 2009. [Google Scholar]
- Patel, J. CMOS Process Variations: A Critical Operation Point Hypothesis. Available online: https://web.stanford.edu/class/ee380/Abstracts/080402-jhpatel.pdf (accessed on 19 March 2018).
- Kahng, A.B.; Kang, S.; Li, J. A New Methodology for Reduced Cost of Resilience. In Proceedings of the GLSVLSI, Houston, TX, USA, 21–23 May 2014. [Google Scholar]
- Alidash, H.K.; Oklobdzija, V.G. Low-power soft error hardened latch. J. Low Power Electron. Appl. 2010, 6, 218–226. [Google Scholar] [CrossRef]
- Paik, S.; Nam, G.J.; Shin, Y. Implementation of pulsed-latch and pulsed-register circuits to minimize clocking power. In Proceedings of the International Conference on Computer-Aided Design, San Jose, CA, USA, 7–10 November 2011. [Google Scholar]
- Sartori, J.; Kumar, R. Characterizing the Voltage Scaling Limitations of Razor-Based Designs; Technical Report; Coordinated Science Laboratory, The University of Illinois at Urbana-Champaign: Champaign, IL, USA, 2009. [Google Scholar]
- Wirnshofer, M. A Variation-Aware Adaptive Voltage Scaling Technique Based on In-Situ Delay monitoring. In Proceedings of the IEEE International Symposium on Design and Diagnostics of Electronic Circuits and Systems, Cottbus, Germany, 13–15 April 2012. [Google Scholar]
- Ghosh, S.; Martin, S.; Stelmach, S. Reliability for IoT and Automotive markets. In Proceedings of the System-on-Chip Conference (SOCC), Munich, Germany, 5–8 September 2017. [Google Scholar]
- Jayakrishnan, M.; Chang, A.; De Gyvez, J.P.; Hyoung, K.T. Slack-aware Timing Margin Redistribution Technique Utilizing Error Avoidance Flip-Flops and Time Borrowing. In Proceedings of the IFIP/IEEE International Conference on Very Large-Scale Integration (VLSI-SoC), Daejeon, Korea, 5–7 October 2015. [Google Scholar]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Speculative | Non-Speculative | |||
|---|---|---|---|---|---|
| Techniques | EVAL [26], Blueshift [27] | Razor [12], DSTB, TDTB [14], TIMBER [17], soft edge flip-flop [16] | SlackOptimizer, SkewOptimizer, CombOpt [29] | Retiming [21], skew scheduling [23], gate sizing [24] | Proposed SBFF + logic downsizing |
| Trade-off | Error rate vs. performance | Error rate vs. power | Error rate vs. power | No | No |
| Error handling | Duplicate paths | Duplicate Latch/FFs | Duplicate Latch/FFs | No error | No error |
| Clock tree loading | No | Yes | Yes | No | Yes |
| Short path padding | No | Yes | Yes | Yes | No |
| Metastability | Yes | Yes | Yes | No | No |
| Sequential overhead | Large | Large | Large | Small | Large |
| Combinational overhead | Large | Small | Large | Small | Small |
| Area overhead | Yes | Yes | Yes | Yes | No |
| Margin relaxation | Small | Up to Tck/2 | Tck/2 | Small | Tck/2 |
| Reference | Drive Strength | Description |
|---|---|---|
| FF_1, FF_2 | 1X, 2X | D-flip-flop, positive-edge triggered, q-only |
| FF_3, FF_4, FF_5 | 1X, 2X, 8X | D-flip-flop, positive-edge triggered, q-only |
| FF_6 | 1X | D-flip-flop, positive-edge triggered, low-asynchronous-clear, q-only |
| FF_7, FF_8, FF_9 | 1X, 2X, 8X | D-flip-flop, positive-edge triggered, low-asynchronous-clear, q-only |
| FF_10, FF_11 | 1X, 2X | D-flip-flop, positive-edge triggered, low-asynchronous-clear/set, q-only |
| FF_12, FF_13, FF_14 | 1X, 2X, 8X | D-flip-flop, positive-edge triggered, low-asynchronous-clear/set, q-only |
| FF_15, FF_16 | 1X, 2X, 8X | D-flip-flop, positive-edge triggered, low-asynchronous-clear/set, sync hold, q-only |
| Technology Node | 40 nm |
|---|---|
| Std. cells: | ~50 K-gates |
| Flip-flops | ~7000 |
| Memory: | 32 KB ISRAM, 32 KB DSRAM |
| 4 KB ROM | |
| Max. Frequency | 180 MHz |
| Typ. Voltage | 1.1 Volts |
| Power (nW) | Baseline | TIMBER [17] | Proposed | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| #Cells | Leakage | Dynamic | Total | #Cells | Leakage | Dynamic | Total | #Cells | Leakage | Dynamic | Total | |
| Fetch | 1976 | 1463 | 265,127 | 266,590 | 2014 | 1481 | 482,389 | 483,870 | 1751 | 1103 | 401,268 | 402,372 |
| Decode | 1874 | 920 | 149,114 | 150,034 | 1900 | 805 | 154,762 | 155,567 | 1796 | 573 | 162,912 | 163,485 |
| Execute | 16,414 | 14,825 | 1,307,869 | 1,322,695 | 16,356 | 14,714 | 1,777,447 | 1,792,162 | 15,053 | 11,039 | 941,299 | 952,339 |
| Area (µm2) | Baseline | TIMBER [17] | Proposed | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| #Cells | Cell Area | Net Area | Total | #Cells | Cell Area | Net Area | Total | #Cells | Cell Area | Net Area | Total | |
| Fetch stage | 1976 | 4980 | 6714 | 11,695 | 2014 | 5217 | 6928 | 12,145 | 1751 | 4391 | 6236 | 10,627 |
| Decode stage | 1874 | 3316 | 6640 | 9955 | 1900 | 3264 | 6677 | 9940 | 1796 | 2768 | 6430 | 9199 |
| Execute stage | 16,414 | 44,741 | 62,899 | 107,639 | 16,356 | 46,919 | 62,784 | 109,702 | 15,053 | 39,790 | 58,245 | 98,034 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jayakrishnan, M.; Chang, A.; Kim, T.T.-H. Opportunistic Design Margining for Area and Power Efficient Processor Pipelines in Real Time Applications. J. Low Power Electron. Appl. 2018, 8, 9. https://doi.org/10.3390/jlpea8020009
Jayakrishnan M, Chang A, Kim TT-H. Opportunistic Design Margining for Area and Power Efficient Processor Pipelines in Real Time Applications. Journal of Low Power Electronics and Applications. 2018; 8(2):9. https://doi.org/10.3390/jlpea8020009
Chicago/Turabian StyleJayakrishnan, Mini, Alan Chang, and Tony Tae-Hyoung Kim. 2018. "Opportunistic Design Margining for Area and Power Efficient Processor Pipelines in Real Time Applications" Journal of Low Power Electronics and Applications 8, no. 2: 9. https://doi.org/10.3390/jlpea8020009
APA StyleJayakrishnan, M., Chang, A., & Kim, T. T.-H. (2018). Opportunistic Design Margining for Area and Power Efficient Processor Pipelines in Real Time Applications. Journal of Low Power Electronics and Applications, 8(2), 9. https://doi.org/10.3390/jlpea8020009