
Deep Character-Level Anomaly Detection Based on a Convolutional Autoencoder for Zero-Day Phishing URL Detection



Abstract
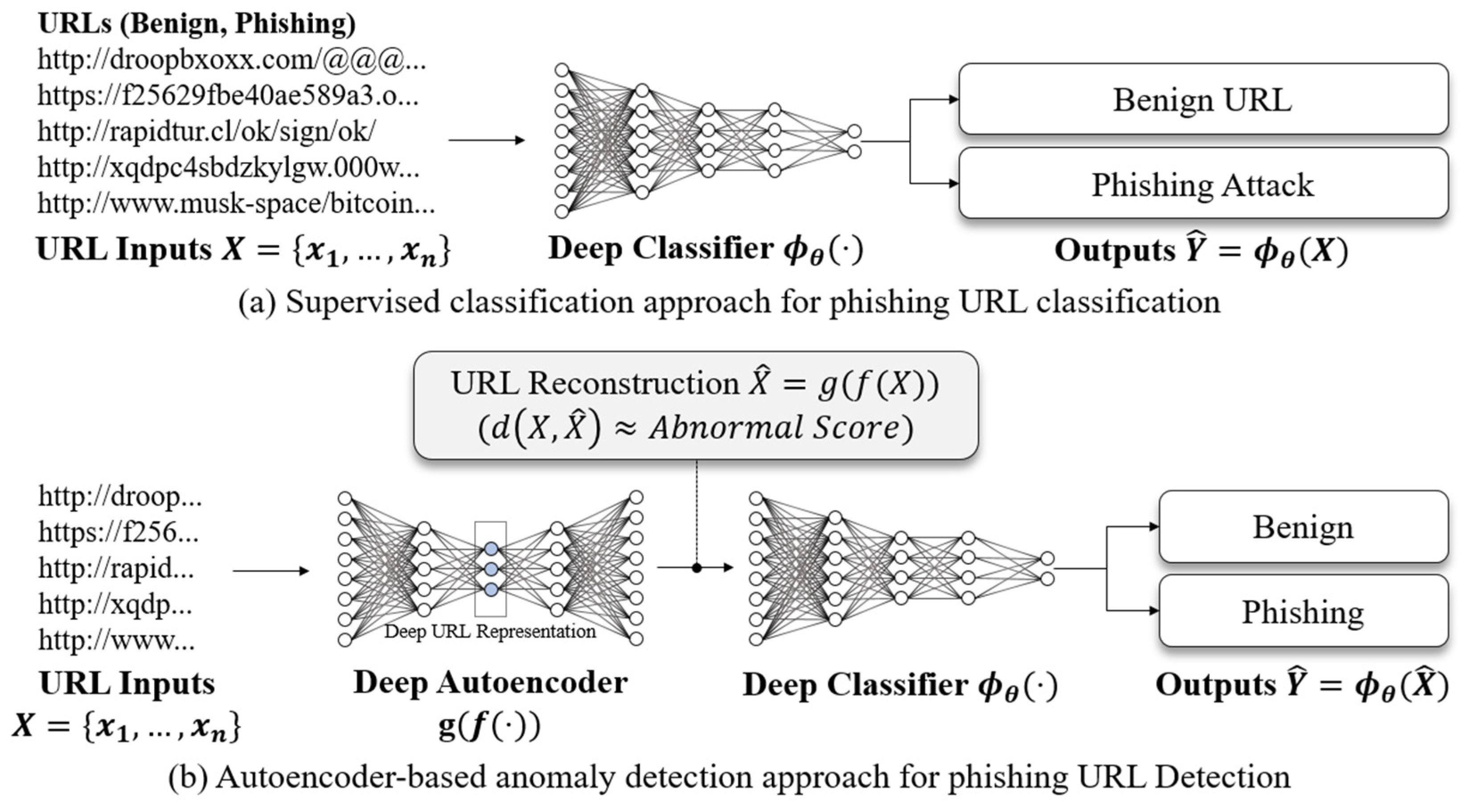
:1. Introduction
- The convolutional autoencoder works well for modeling the deep representation of benign URLs, resulting in the best accuracy for phishing detection.
- The abnormal score defined based on the reconstruction error of the autoencoder is suitable for the phishing detection, resulting in a significant improvement in recall.
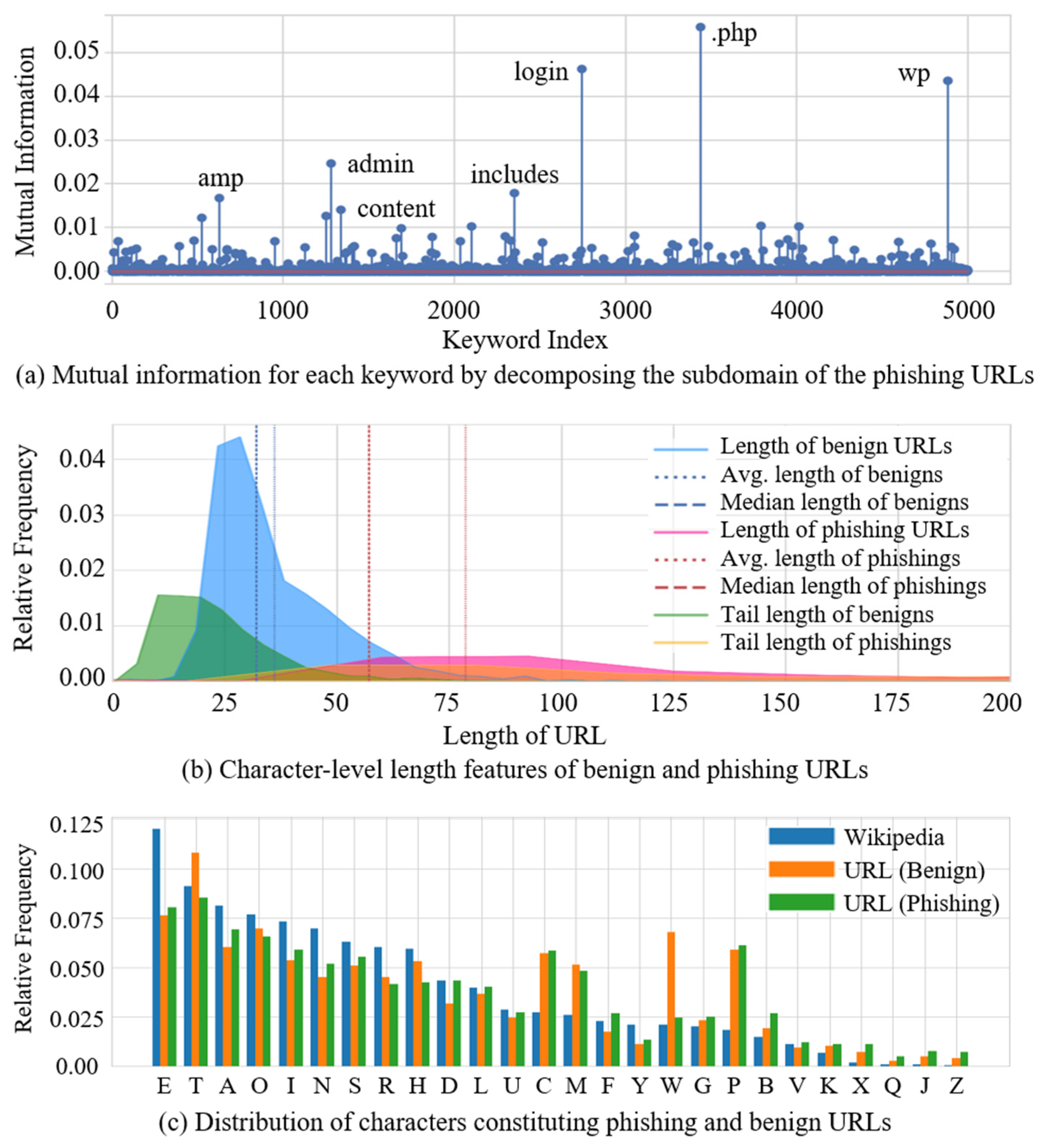
2. Related Works
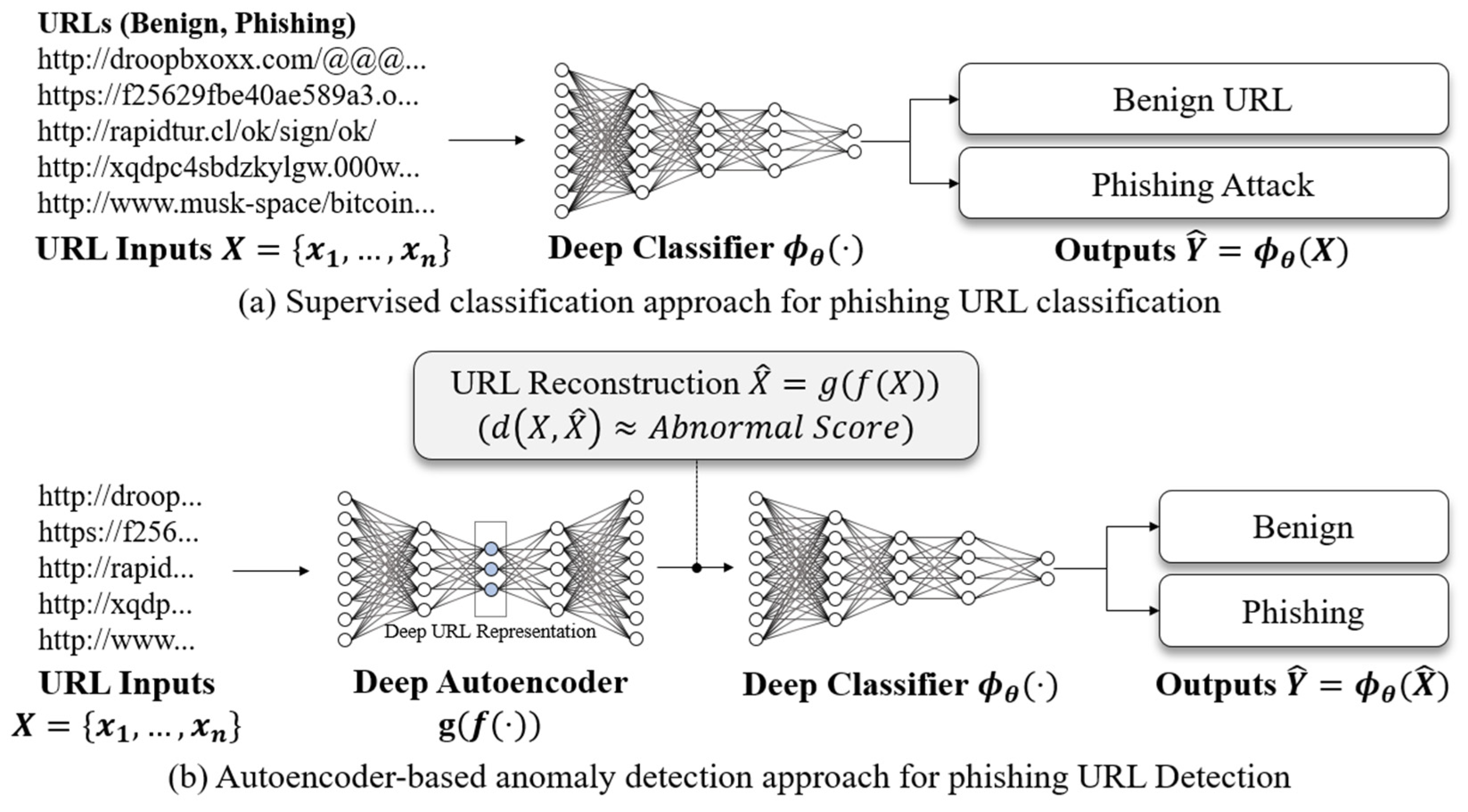
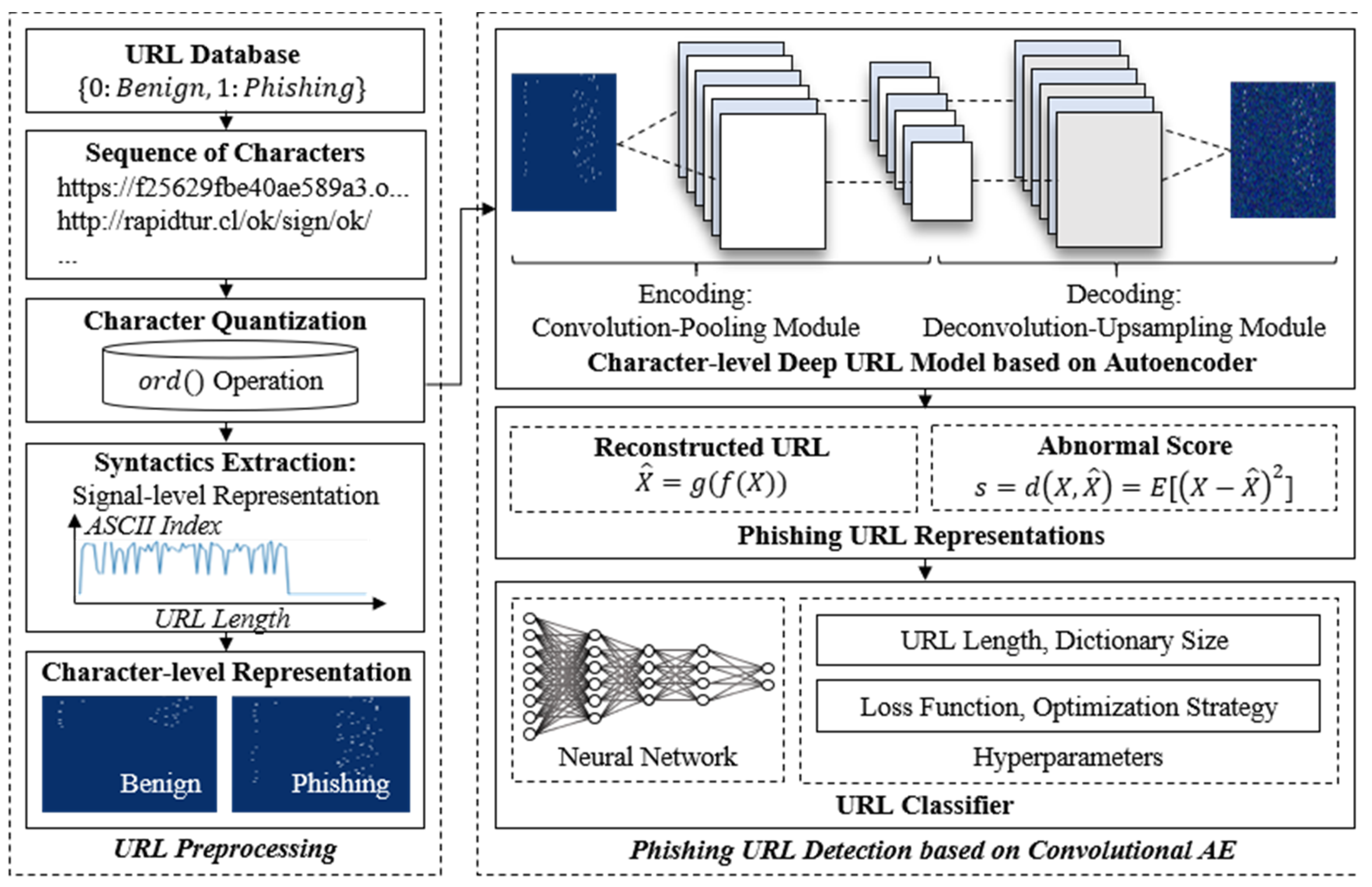
3. Proposed Method
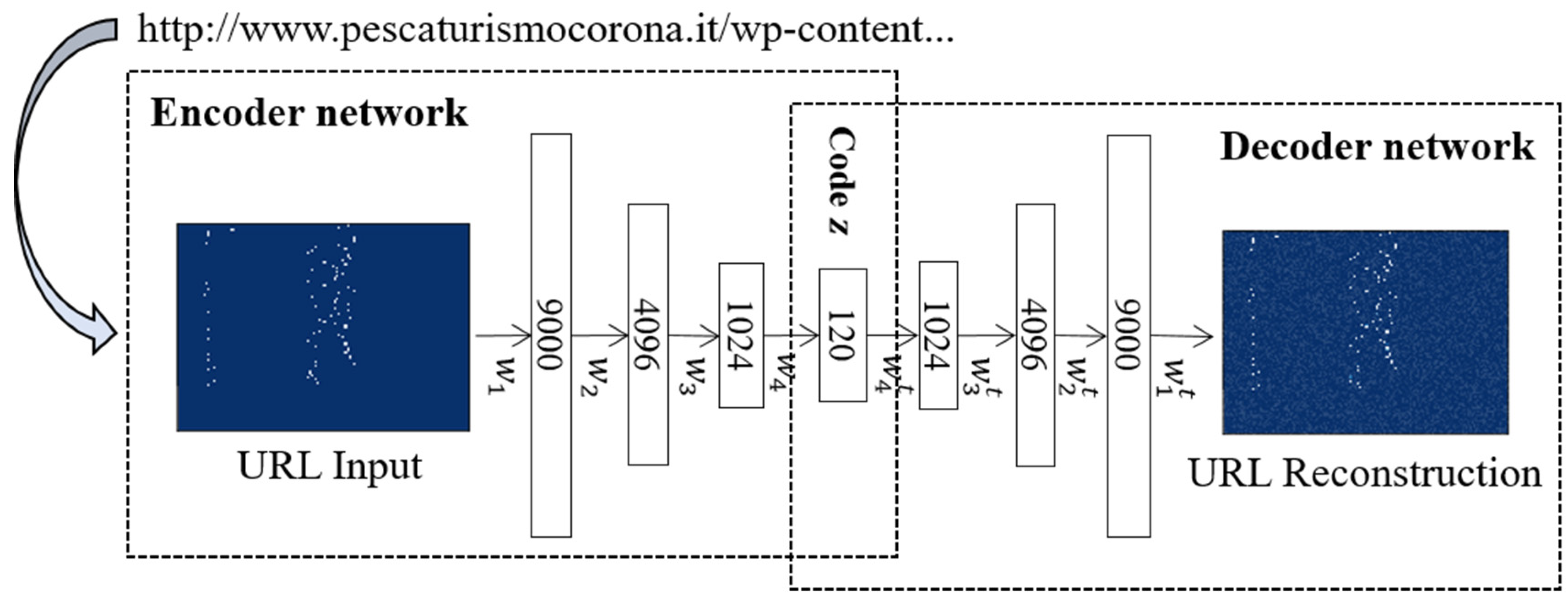
3.1. Character-Level URL Model Based on a Convolutional Autoencoder
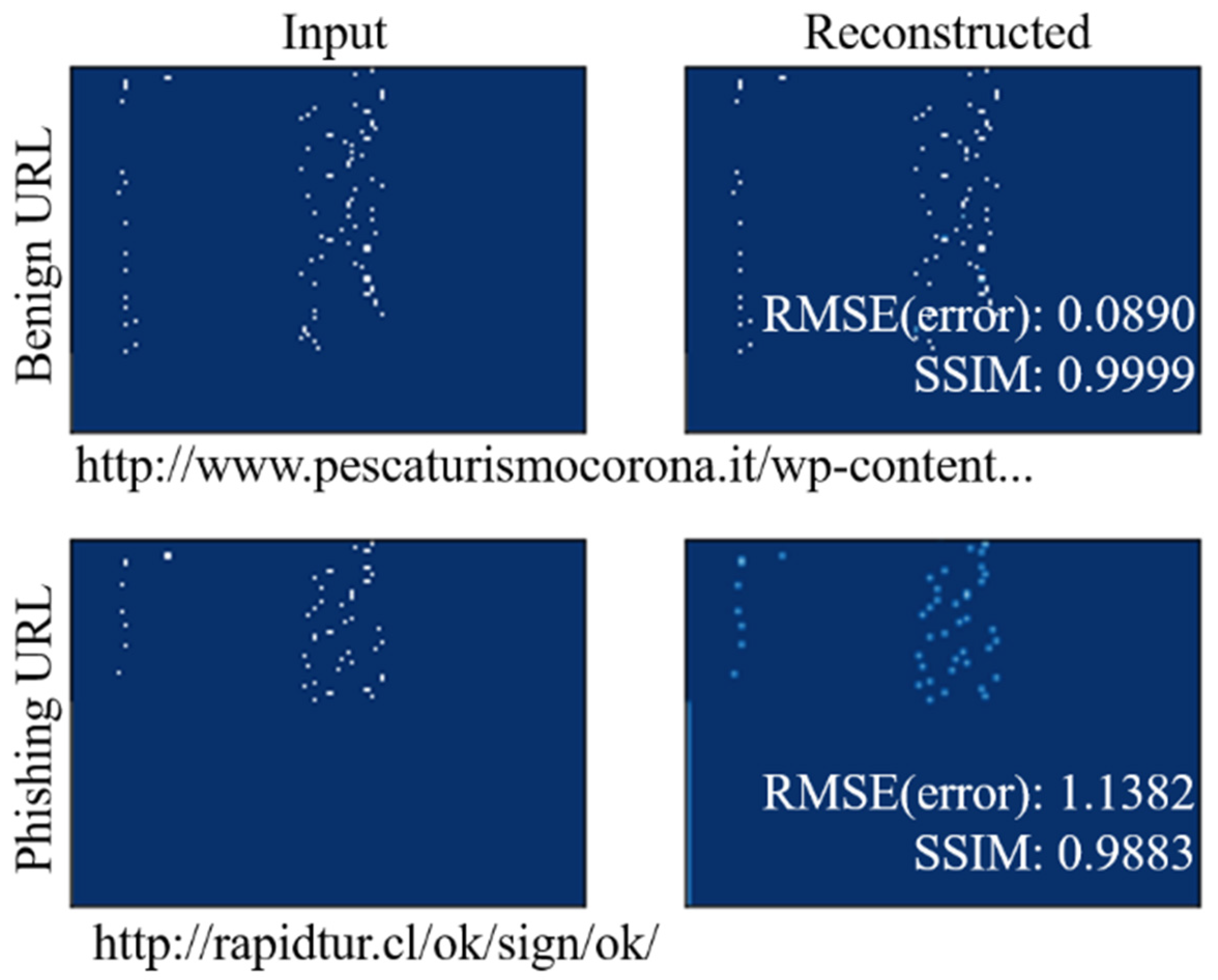
3.2. Phishing URL Classification Based on Reconstruction Errors
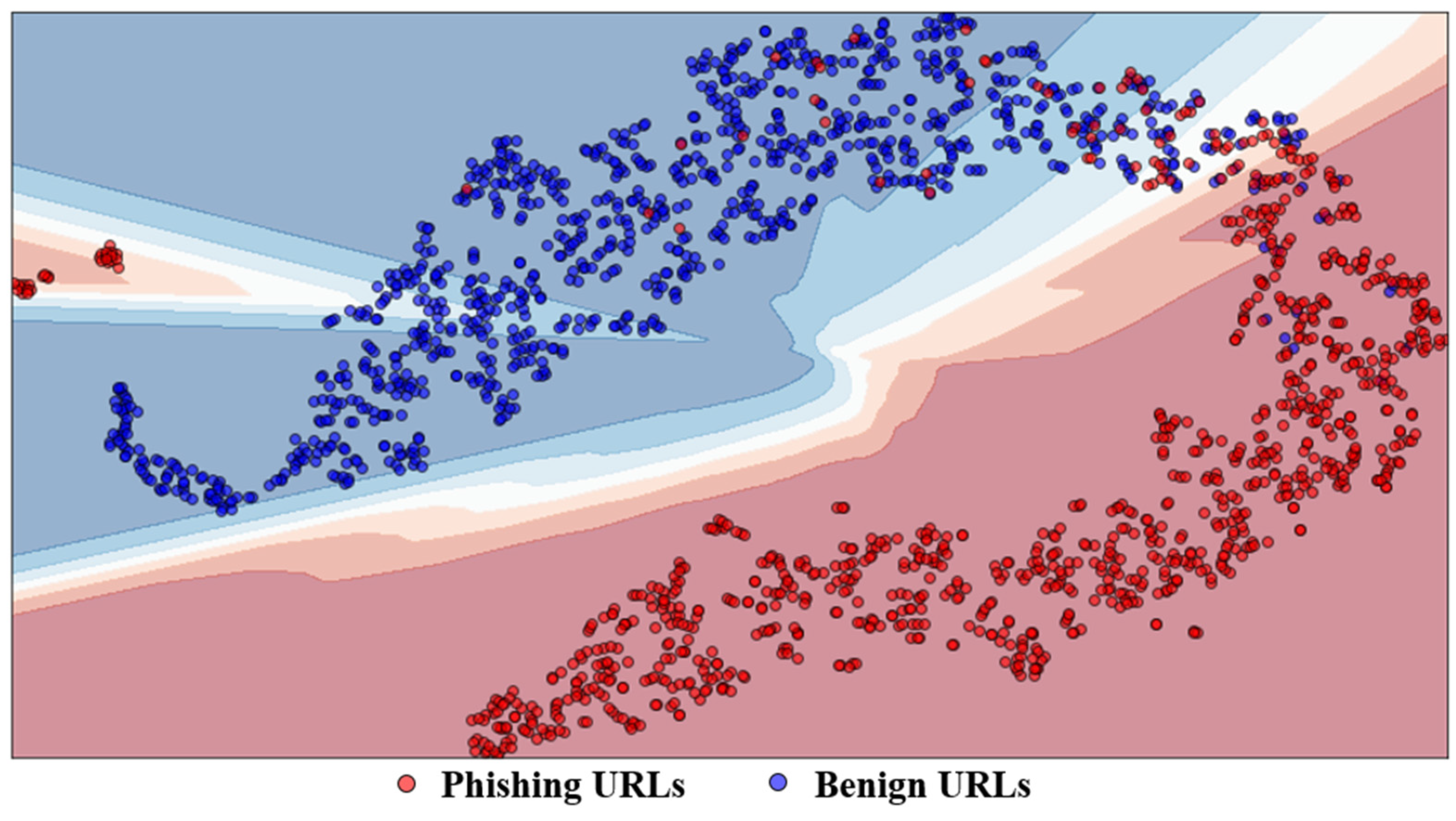
4. Experimental Results
4.1. Dataset and Implementation
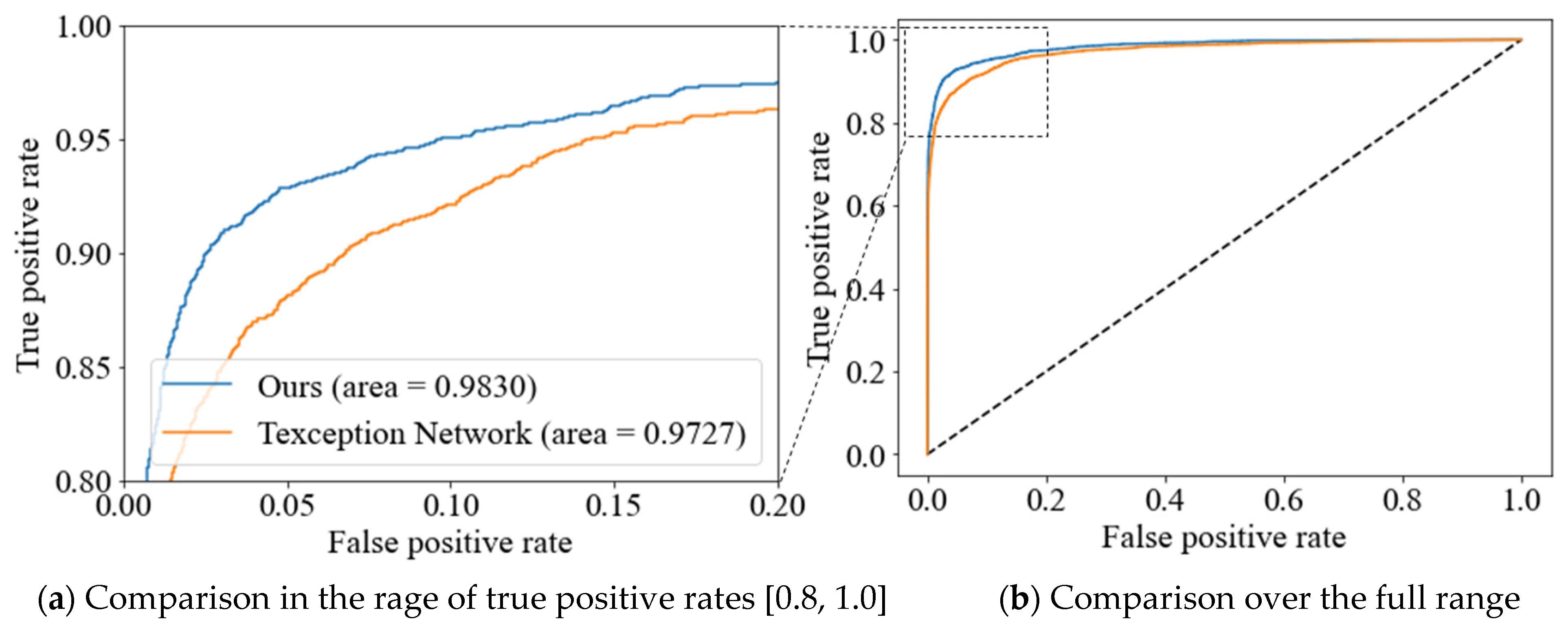
4.2. Phishing Detection Performance
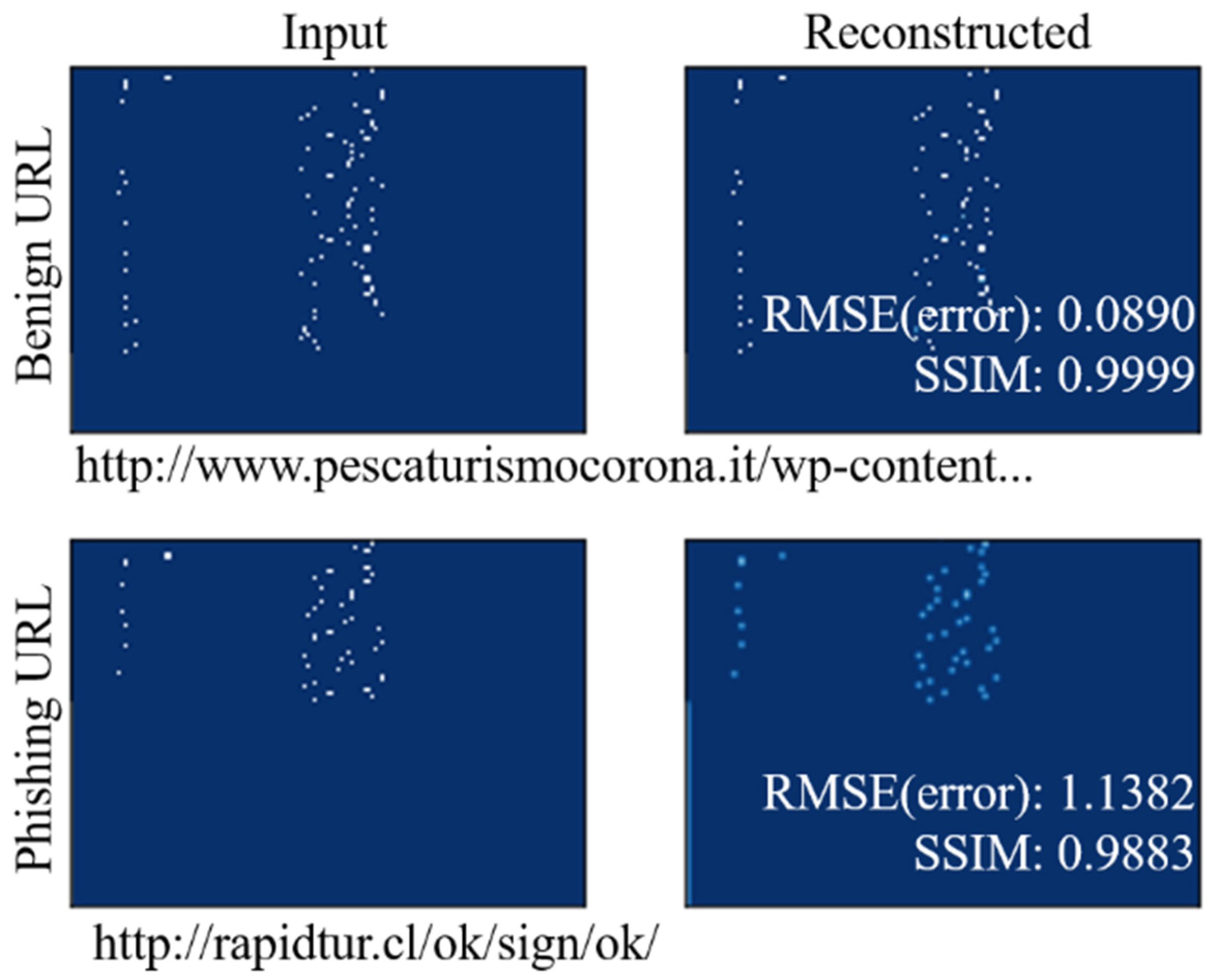
4.3. Performance Evaluation by Component: URL Reconstruction and Effect of the Auxiliary Classifier
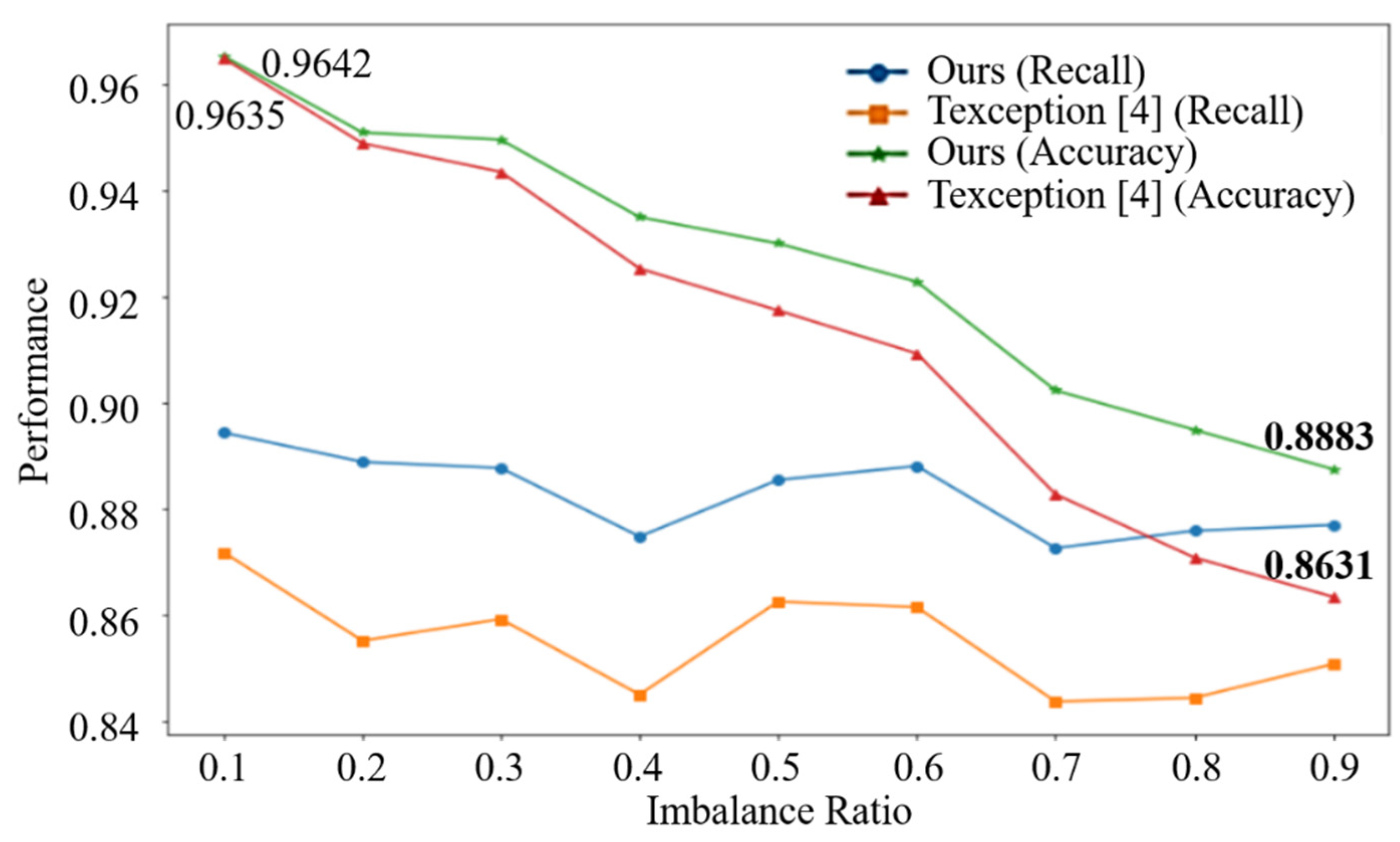
4.4. Discussions
5. Concluding Remarks
Author Contributions
Funding
Conflicts of Interest
References
- Lastdrager, E.E. Achieving a consensual definition of phishing based on a systematic review of the literature. Crime Sci. 2014, 3, 9. [Google Scholar] [CrossRef]
- Liu, W.; Zhong, S. Web malware spread modelling and optimal control strategies. Sci. Rep. 2017, 7, 42308. [Google Scholar] [CrossRef] [Green Version]
- Yang, C.; Harkreader, R.; Gu, G. Empirical evaluation and new design for fighting evolving twitter spammers. IEEE Trans. Inf. Forensics Secur. 2013, 8, 1280–1293. [Google Scholar] [CrossRef]
- Fazil, M.; Abulaish, M. A hybrid approach for detecting automated spammers in twitter. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2707–2719. [Google Scholar] [CrossRef]
- Le, H.; Pham, Q.; Sahoo, D.; Hoi, S.C. URLNet: Learning a URL representation with deep learning for malicious URL detection. arXiv 2018, arXiv:1802.03162. [Google Scholar]
- Tajaddodianfar, F.; Stokes, J.W.; Gururajan, A. Texception: A Character/Word-Level Deep Learning Model for Phishing URL Detection. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 2857–2861. [Google Scholar]
- Bu, S.-J.; Cho, S.-B. A convolutional neural-based learning classifier system for detecting database intrusion via insider attack. Inf. Sci. 2020, 512, 123–136. [Google Scholar] [CrossRef]
- Bu, S.-J.; Cho, S.-B. Time Series Forecasting with Multi-Headed Attention-Based Deep Learning for Residential Energy Consumption. Energies 2020, 13, 4722. [Google Scholar] [CrossRef]
- Souri, A.; Hosseini, R. A state-of-the-art survey of malware detection approaches using data mining techniques. Hum. Cent. Comput. Inf. Sci. 2018, 8, 3. [Google Scholar] [CrossRef]
- Cui, Q.; Jourdan, G.-V.; Bochmann, G.V.; Couturier, R.; Onut, I.-V. Tracking phishing attacks over time. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 667–676. [Google Scholar]
- Andresini, G.; Appice, A.; Malerba, D. Autoencoder-based deep metric learning for network intrusion detection. Inf. Sci. 2021, 569, 706–727. [Google Scholar] [CrossRef]
- Wei, W.; Ke, Q.; Nowak, J.; Korytkowski, M.; Scherer, R.; Woźniak, M. Accurate and fast URL phishing detector: A convolutional neural network approach. Comput. Netw. 2020, 178, 107275. [Google Scholar] [CrossRef]
- Azeez, N.A.; Salaudeen, B.B.; Misra, S.; Damaševičius, R.; Maskeliūnas, R. Identifying phishing attacks in communication networks using URL consistency features. Int. J. Electron. Secur. Digit. Forensics 2020, 12, 200–213. [Google Scholar] [CrossRef]
- Mohammad, R.M.; Thabtah, F.; McCluskey, L. An assessment of features related to phishing websites using an automated technique. In Proceedings of the 2012 International Conference for Internet Technology and Secured Transactions, London, UK, 10–12 December 2012; pp. 492–497. [Google Scholar]
- Osho, O.; Oluyomi, A.; Misra, S.; Ahuja, R.; Damasevicius, R.; Maskeliunas, R. Comparative Evaluation of Techniques for Detection of Phishing URLs. In Proceedings of the International Conference on Applied Informatics, Madrid, Spain, 7–9 November 2019; pp. 385–394. [Google Scholar]
- Chiew, K.L.; Tan, C.L.; Wong, K.; Yong, K.S.; Tiong, W.K. A new hybrid ensemble feature selection framework for machine learning-based phishing detection system. Inf. Sci. 2019, 484, 153–166. [Google Scholar] [CrossRef]
- Anand, A.; Gorde, K.; Moniz, J.R.A.; Park, N.; Chakraborty, T.; Chu, B.-T. Phishing URL detection with oversampling based on text generative adversarial networks. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 1168–1177. [Google Scholar]
- Chou, E.J.; Gururajan, A.; Laine, K.; Goel, N.K.; Bertiger, A.; Stokes, J.W. Privacy-Preserving Phishing Web Page Classification Via Fully Homomorphic Encryption. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 2792–2796. [Google Scholar]
- Arachie, C.; Huang, B. Adversarial label learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 3183–3190. [Google Scholar]
- Yan, H.; Zhang, X.; Xie, J.; Hu, C. Detecting Malicious URLs Using a Deep Learning Approach Based on Stacked Denoising Autoencoder. In Proceedings of the Chinese Conference on Trusted Computing and Information Security, Wuhan, China, 18 October 2018; pp. 372–388. [Google Scholar]
- Mamun, M.S.I.; Rathore, M.A.; Lashkari, A.H.; Stakhanova, N.; Ghorbani, A.A. Detecting malicious urls using lexical analysis. In Proceedings of the International Conference on Network and System Security, Taipei, Taiwan, 28–30 September 2016; pp. 467–482. [Google Scholar]
- Iuga, C.; Nurse, J.R.; Erola, A. Baiting the hook: Factors impacting susceptibility to phishing attacks. Hum. Cent. Comput. Inf. Sci. 2016, 6, 8. [Google Scholar] [CrossRef] [Green Version]
- Om, K.; Boukoros, S.; Nugaliyadde, A.; McGill, T.; Dixon, M.; Koutsakis, P.; Wong, K.W. Modelling email traffic workloads with RNN and LSTM models. Hum. Cent. Comput. Inf. Sci. 2020, 10, 1–16. [Google Scholar] [CrossRef]
- Marchal, S.; François, J.; State, R.; Engel, T. PhishStorm: Detecting phishing with streaming analytics. IEEE Trans. Netw. Serv. Manag. 2014, 11, 458–471. [Google Scholar] [CrossRef] [Green Version]
- Burnap, P.; French, R.; Turner, F.; Jones, K. Malware classification using self organising feature maps and machine activity data. Comput. Secur. 2018, 73, 399–410. [Google Scholar] [CrossRef]
- Vasan, D.; Alazab, M.; Wassan, S.; Safaei, B.; Zheng, Q. Image-based malware classification using ensemble of CNN architectures (IMCEC). Comput. Secur. 2020, 92, 101748. [Google Scholar] [CrossRef]
- Qin, Z.-Q.; Ma, X.-K.; Wang, Y.-J. ADSAD: An unsupervised attention-based discrete sequence anomaly detection framework for network security analysis. Comput. Secur. 2020, 99, 102070. [Google Scholar] [CrossRef]
- Yuan, B.; Wang, J.; Liu, D.; Guo, W.; Wu, P.; Bao, X. Byte-level malware classification based on markov images and deep learning. Comput. Secur. 2020, 92, 101740. [Google Scholar] [CrossRef]
- Xayasouk, T.; Lee, H.; Lee, G. Air Pollution Prediction Using Long Short-Term Memory (LSTM) and Deep Autoencoder (DAE) Models. Sustainability 2020, 12, 2570. [Google Scholar] [CrossRef] [Green Version]
- Sureda Riera, T.; Bermejo Higuera, J.-R.; Bermejo Higuera, J.; Martínez Herraiz, J.-J.; Sicilia Montalvo, J.-A. Prevention and Fighting against Web Attacks through Anomaly Detection Technology. A Systematic Review. Sustainability 2020, 12, 4945. [Google Scholar] [CrossRef]
- Zhang, X.; Zhao, J.; LeCun, Y. Character-level convolutional networks for text classification. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 649–657. [Google Scholar]
- Yang, P.; Zhao, G.; Zeng, P. Phishing website detection based on multidimensional features driven by deep learning. IEEE Access 2019, 7, 15196–15209. [Google Scholar] [CrossRef]
- Blum, A.; Wardman, B.; Solorio, T.; Warner, G. Lexical feature based phishing URL detection using online learning. In Proceedings of the 3rd ACM Workshop on Artificial Intelligence and Security, Chicago, IL, USA, 8 October 2010; pp. 54–60. [Google Scholar]
- Jang, U.; Suh, K.H.; Lee, E.C. Low-quality banknote serial number recognition based on deep neural network. J. Inf. Process. Syst. 2020, 16, 224–237. [Google Scholar]
- Wen, J. Gait recognition based on GF-CNN and metric learning. J. Inf. Process. Syst. 2020, 16, 1105–1112. [Google Scholar]
- Bu, S.-J.; Cho, S.-B. A hybrid deep learning system of CNN and LRCN to detect cyberbullying from SNS comments. In Proceedings of the International Conference on Hybrid Artificial Intelligence Systems, Oviedo, Spain, 20–22 June 2018; pp. 561–572. [Google Scholar]
- Bu, S.-J.; Park, N.; Nam, G.-H.; Seo, J.-Y.; Cho, S.-B. A Monte Carlo Search-Based Triplet Sampling Method for Learning Disentangled Representation of Impulsive Noise on Steering Gear. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 3057–3061. [Google Scholar]
- Ni, S.; Qian, Q.; Zhang, R. Malware identification using visualization images and deep learning. Comput. Secur. 2018, 77, 871–885. [Google Scholar] [CrossRef]
- Er, M.J.; Zhang, Y.; Wang, N.; Pratama, M. Attention pooling-based convolutional neural network for sentence modelling. Inf. Sci. 2016, 373, 388–403. [Google Scholar] [CrossRef]
- Pei, X.; Yu, L.; Tian, S. AMalNet: A deep learning framework based on graph convolutional networks for malware detection. Comput. Secur. 2020, 93, 101792. [Google Scholar] [CrossRef]
- Novoselov, S.; Shchemelinin, V.; Shulipa, A.; Kozlov, A.; Kremnev, I. Triplet Loss Based Cosine Similarity Metric Learning for Text-independent Speaker Recognition. In Proceedings of the Interspeech, Hyderabad, India, 2–6 September 2018; pp. 2242–2246. [Google Scholar]
- Carrasco, R.S.M.; Sicilia, M.-A. Unsupervised intrusion detection through skip-gram models of network behavior. Comput. Secur. 2018, 78, 187–197. [Google Scholar] [CrossRef]

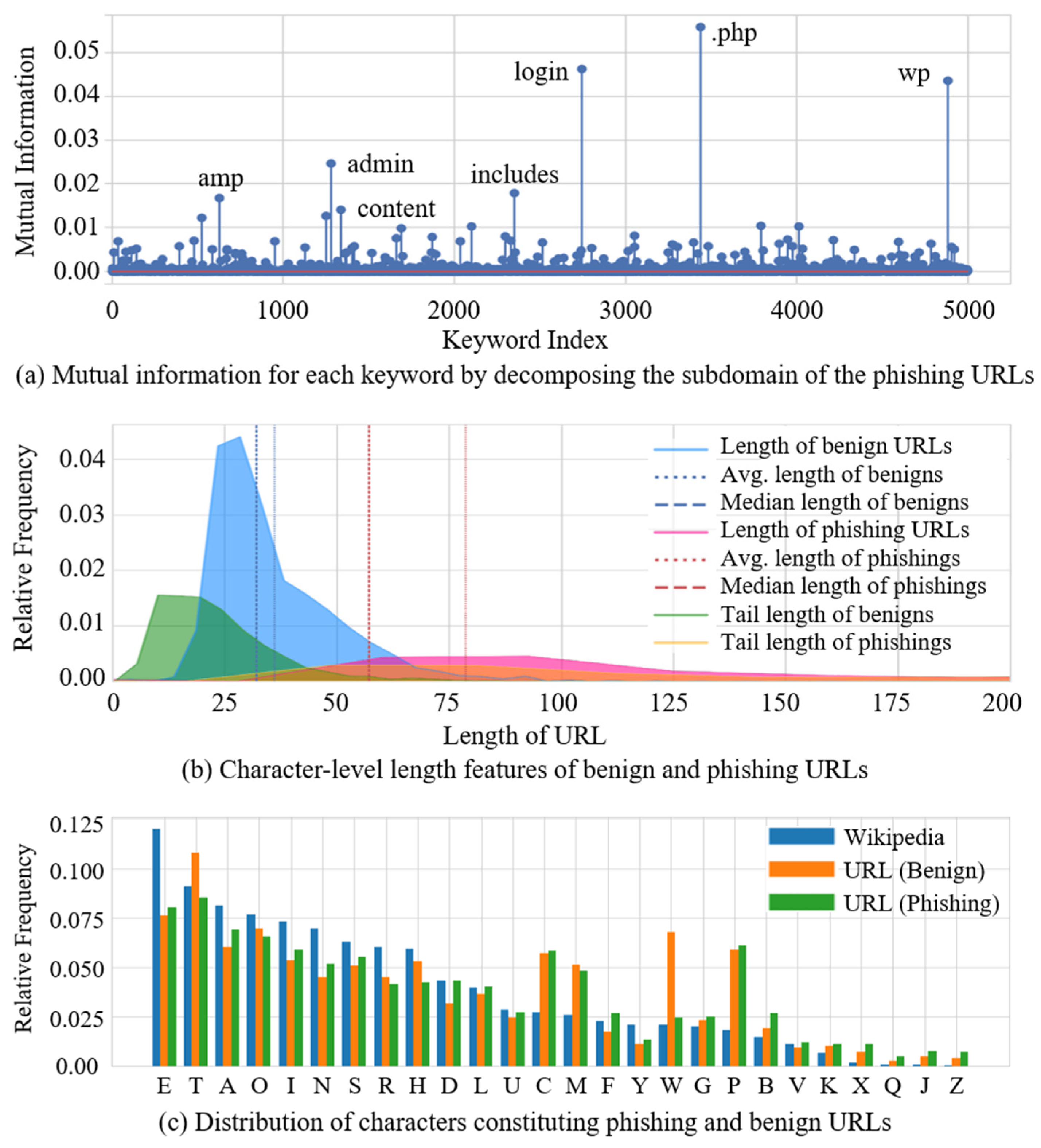


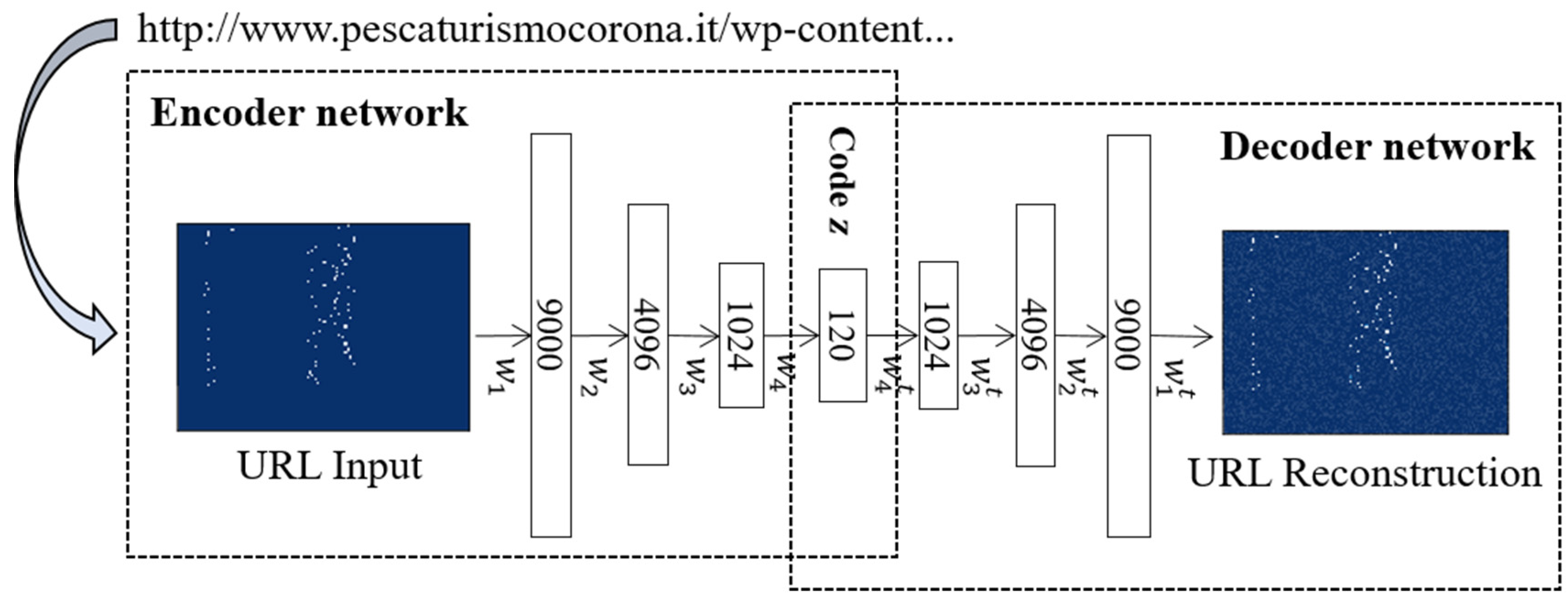
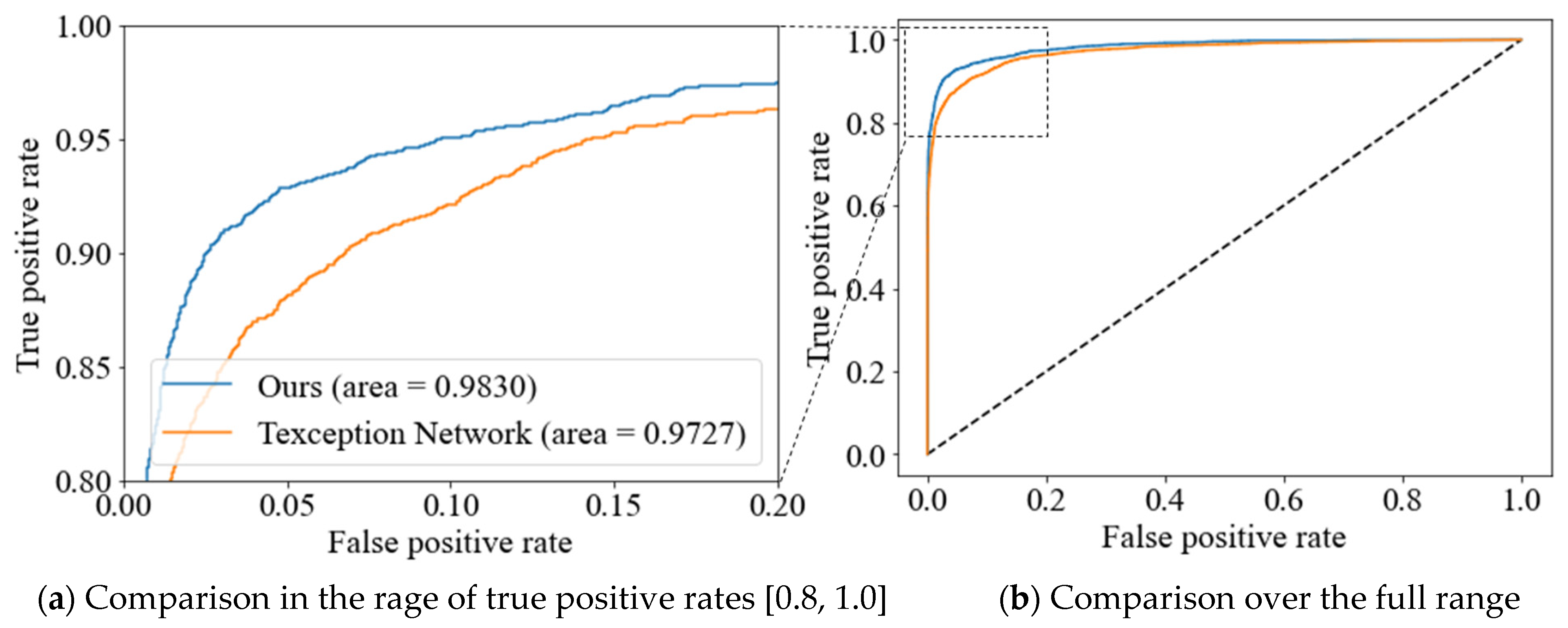
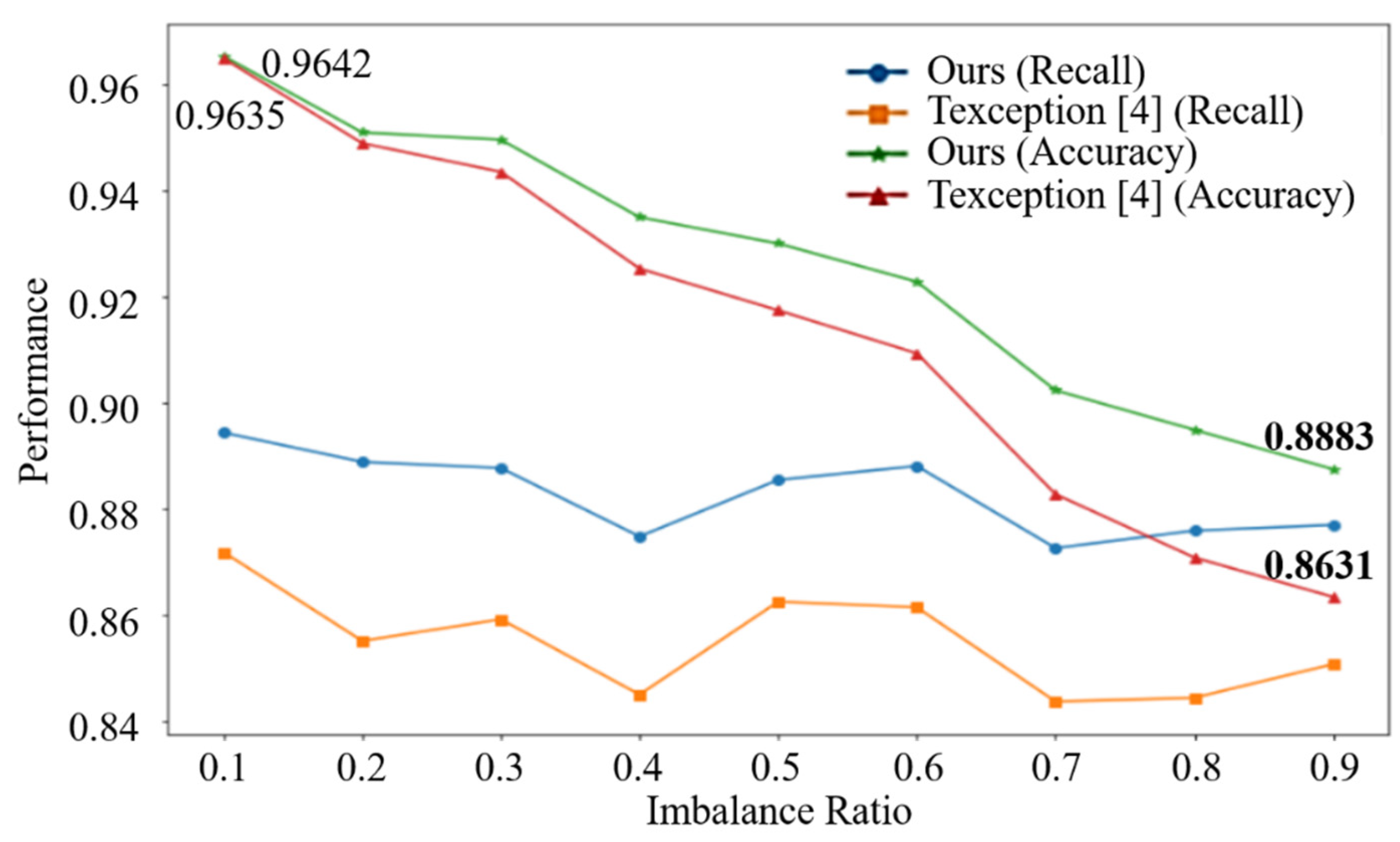


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | URL Representation | Method | Dataset | Author |
|---|---|---|---|---|
| Supervised | Text | Transition diagram | PhishStorm | Liu [2] |
| Selected URL features | Rule-based detection algorithm | PhishTank | Azeez [13] | |
| Hierarchical classifier based on feature group | PhishTank | Mohammad [14] | ||
| Machine-learning methods: AdaBoost, BN, Decision Table, NB, RF, etc. | UCI phishing Huddersfield URL | Osho [15] | ||
| Text | Machine-learning methods: NB, DT, RF, SVM | UCI phishing | Chiew [16] | |
| Char.-/word-level embedding | URLNet: CNN concatenation | VirusTotal | Le [5] | |
| Selected URL features | LSTM-based text GAN | PhishTank | Anand [17] | |
| URL with screenshots | Optical character recognition with ResNet, homomorphic encryption | MS URL screenshots | Chou [18] | |
| Char.-/word-level embedding | Texception: CNN concatenation with Inception | MS anonymized URLs | Tajaddodanfar [6] | |
| Weakly supervised | Text | Adversarial label learning | PhishTank | Arachie [19] |
| Anomaly detection | Char.-level encoding | Denoising autoencoder | PhishTank, hpHost | Yan [20] |
| Source | URL Label | Instances | e.g., (Accessed Date: 19 October 2020) |
|---|---|---|---|
| ISCX-URL-2016 [21] | Benign | 35,000 | http://metro.co.uk/2015/05 |
| Phishing | 9000 | http://standardprincipal.pt/ | |
| Malware | 11,000 | http://9779.info/%E5%88% | |
| Spam | 12,000 | http://adverse*s.co.uk/scr/cl | |
| PhishStorm [24] | Benign | 47,682 | en.wikipedia.org/wiki/Walkingdead |
| Phishing | 47,859 | nobell.it/70ffb52d079109dc | |
| PhishTank [10] | DMOZ Open Directory Project (Benign) | 45,000 | http://geneba**.org/ftp/ |
| OpenDNS (Phishing) | 15,000 | http://droopbxoxx.com/@@@ |
| Operation | No. of Convolution Filters | Kernel Size | Stride | Activation Function | No. of Parameters |
|---|---|---|---|---|---|
| Reshape2D | - | - | - | - | 0 |
| Convolution 2D | 256 | 2 × 2 | 1 | tanh | 1280 |
| MaxPooling 2D | - | 2 × 2 | 2 | - | 0 |
| Convolution 2D | 512 | 2 × 2 | 1 | tanh | 524,800 |
| MaxPooling 2D | - | 2 × 2 | 2 | - | 0 |
| BatchNormalization | - | - | - | - | 2048 |
| Convolution 2D | 1024 | 1 × 1 | 1 | tanh | 525,312 |
| Upsampling 2D | - | - | - | - | 0 |
| Deconvolution 2D | 512 | 2 × 2 | 1 | tanh | 2,097,664 |
| Upsampling 2D | - | - | - | - | 0 |
| Deconvolution 2D | 512 | 2 × 2 | 1 | tanh | 524,544 |
| BatchNormalization | - | - | - | - | 1024 |
| Convolution 2D | 1 | 2 × 2 | 1 | tanh | 257 |
| Reshape 2D | - | - | - | - | 0 |
| Benchmark Dataset | ISCX-URL-2016 | PhishStorm | PhishTank | |||
|---|---|---|---|---|---|---|
| Metrics | Acc. | Recall | Acc. | Recall | Acc. | Recall |
| Base Network | ||||||
| Character-CNN [31] | 0.9363 ± 0.0060 | 0.8909 ± 0.0212 | 0.9016 ± 0.0042 | 0.8565 ± 0.0352 | 0.8852 ± 0.0120 | 0.8034 ± 0.0294 |
| LSTM | 0.9175 ± 0.0166 | 0.8803 ± 0.0181 | 0.8777 ± 0.0219 | 0.8440 ± 0.0277 | 0.8544 ± 0.0242 | 0.7865 ± 0.0383 |
| CNN-LSTM [8] | 0.9424 ± 0.0057 | 0.9015 ± 0.0147 | 0.9229 ± 0.0142 | 0.8785 ± 0.0183 | 0.9070 ± 0.0084 | 0.8374 ± 0.0244 |
| Comparative Studies | ||||||
| URLNet [5] | 0.9450 ± 0.0043 | 0.9390 ± 0.0110 | 0.9395 ± 0.0050 | 0.8864 ± 0.0192 | 0.9226 ± 0.0123 | 0.8785 ± 0.0212 |
| Texception [6] | 0.9765 ± 0.0049 | 0.9462 ± 0.0097 | 0.9710 ± 0.0031 | 0.9227 ± 0.0187 | 0.9319 ± 0.0108 | 0.9075 ± 0.0114 |
| Triplet Network [41] | 0.9505 ± 0.0122 | 0.9064 ± 0.0227 | 0.9473 ± 0.0085 | 0.8902 ± 0.0249 | 0.9081 ± 0.0221 | 0.8469 ± 0.0274 |
| Monte Carlo Search based Triplet Net. [37] | 0.9673 ± 0.0133 | 0.9227 ± 0.0282 | 0.9664 ± 0.0071 | 0.9065 ± 0.0265 | 0.9237 ± 0.0237 | 0.8665 ± 0.0285 |
| Convolutional Autoencoder-based Phishing Detection (Proposed) | ||||||
| Thresholding using Anomaly Score | 0.9734 ± 0.0035 | 0.9338 ± 0.0085 | 0.9532 ± 0.0041 | 0.9091 ± 0.0166 | 0.9120 ± 0.0071 | 0.8655 ± 0.0221 |
| Threshold Learning with Auxiliary CNN | 0.9780 ± 0.0027 | 0.9590 ± 0.0074 | 0.9732 ± 0.0018 | 0.9338 ± 0.0131 | 0.9690 ± 0.0084 | 0.9132 ± 0.0185 |
| Confusion Matrix | Predicted (w/o Auxiliary Classifier) | |||
|---|---|---|---|---|
| Benign | Phishing | Recall- | ||
| Actual | Benign | 8854 (8377) | 187 (781) | 0.9793 (0.9147) |
| Phishing | 281 (824) | 2678 (2018) | 0.9050 (0.7101) | |
| Precision | 0.9692 (0.9104) | 0.9347 (0.7209) | Accuracy: 0.9610 (0.8663) | |
| Classification Result | Label | URL (Accessed Date: 19 October 2020) | |
|---|---|---|---|
| Correctly classified | Phishing | https://1drv.ms/xs/s!AhtvzT3KrwqMZzLMKnTc8clHnRA?wdFormId=%7BA0F7982D%2D71A4%2D4DE0%2DB4C4%2DC16A | 0.9874 |
| Benign | http://market.security***.net | 0.0031 | |
| Misclassified | Benign | http://archives.seattletimes.nwsou***.com/cgi-bin/texis.cgi/web/vortex/display?slug=will&date=199903 | 0.8815 |
| Phishing | http://tesla-present.site/ethereum/ | 0.0584 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bu, S.-J.; Cho, S.-B. Deep Character-Level Anomaly Detection Based on a Convolutional Autoencoder for Zero-Day Phishing URL Detection. Electronics 2021, 10, 1492. https://doi.org/10.3390/electronics10121492
Bu S-J, Cho S-B. Deep Character-Level Anomaly Detection Based on a Convolutional Autoencoder for Zero-Day Phishing URL Detection. Electronics. 2021; 10(12):1492. https://doi.org/10.3390/electronics10121492
Chicago/Turabian StyleBu, Seok-Jun, and Sung-Bae Cho. 2021. "Deep Character-Level Anomaly Detection Based on a Convolutional Autoencoder for Zero-Day Phishing URL Detection" Electronics 10, no. 12: 1492. https://doi.org/10.3390/electronics10121492
APA StyleBu, S. -J., & Cho, S. -B. (2021). Deep Character-Level Anomaly Detection Based on a Convolutional Autoencoder for Zero-Day Phishing URL Detection. Electronics, 10(12), 1492. https://doi.org/10.3390/electronics10121492