1. Introduction
Classic security Intrusion Detection Systems/Intrusion Detection and Prevention Systems (IDS/IDPS) tend to become obsolete on their own. The wide variety of both direct and indirect attack patterns makes it next to impossible to ensure the security of all digital data and computer systems. One may employ state-of-the-art firewall and antivirus solutions to enforce security policies, but still be vulnerable to zero-day attacks that can pass through. It is no longer enough to have security check-points in the infrastructure, no matter how reliable they supposedly are. Organizations also need to make sure that their security solutions are consistently working and capable enough to detect and prevent any potential attack. Behavior-based detection of the unknown is the main challenge in cybersecurity nowadays. Galal et al. in [
1] proposed a behavior-based feature model to describe the malicious actions exhibited by malware at runtime. Their approach is based on the known fact that malware variants do indeed imply code change techniques such as polymorphism and metamorphism, resulting in different syntactic structures that share similar behaviors. Only two years later, a single spam campaign, that led to a GandCrab v2.1 sample being delivered as a payload, revealed hundreds of different hashes in an attempt to evade specific file signatures. There are many such cases, but this singular example alone is enough to state that signature-based detection is no longer enough. Cybersecurity research is moving towards behavior-based detection and attempts to model threats according to an access pattern continuum scale (
Table 1—adapted from the Advanced Email Security Solution webinar by the Fortinet NSE Institute). There is a no-man’s-land that implies huge technological effort between the clearly defined extremes of the scale: the “Known Good” and the “Known Bad”. It is the zone that is targeted by our approach. Specifically, “Probably Good” and “Might be Good” is a theoretical situation because it allows the traffic to pass. “Completely Unknown” is a dedicated problem for sandboxing and malware analysts. “Somewhat Suspicious” and “Very Suspicious” is usually covered by security solutions providers and is partially mirrored by “Might be Good” and “Probably Good”, respectively. These borders are very fragile because a zero-day detonated in a sandbox that enacts some illegitimate actions will be labelled as “Suspicious”, or more directly, “Known Bad”. The time-frame required to reach such a decision ranges from a few minutes to a couple of hours. This sandboxing technique involves a continuous process and, as such, just the simple usage of powerful security tools is simply not enough anymore. Thus, Bruce Schneier’s well-known statement that “security is a process, not a product” [
2] is more meaningful than ever before.
Modern approaches to security architectures implement this idea of security as a process, ensuring both adequate/proportional responses to various threats and increased visibility of the whole system and of the events that occur within such a system. Dedicated tools and software agents are employed to monitor and audit both the security solutions and the underlying physical and virtual systems. Inbound/outbound traffic, behavior of IDS/IDPS, security events, server applications’ requests and responses, and so on become log data that undergo thorough analyses. The purpose is to determine whether or not the chosen security tools performed well. The results provided by these analytical tasks are in turn used to validate security configuration and enforce any eventually identified weak spots of IDS/IDPS and of the target system. This process follows through almost indefinitely.
Two major ideas spawned from the security is a process concept. The first approach focuses on understanding the huge amount of gathered log data by using data-mining (DM), big data and AI/machine learning (ML) techniques, and will be further discussed in
Section 2. The second pathway focuses on modelling the attack patterns and attempts to provide abstract descriptions for these attacks. Following through with this idea, the Lockheed Martin Corporation developed the Cyber Kill Chain Framework in 2011 [
3]—an IT reworking of the military Find Fix Track Target Engage Assess (F2T2EA) term. The purpose of this theoretical framework is to enhance visibility into an attack and enrich an analyst’s understanding of an adversary’s tactics, techniques, and procedures. The model identifies reconnaissance, weaponisation, delivery, exploitation, installation, command and control, and actions on the objective to describe cyber attack processes. The authors also refer to the Department of Defense Information operations doctrine to depict a course-of-action matrix using actions of “detect, deny, disrupt, degrade, deceive and destroy” to identify the tools and means that can be used to mitigate the phases of a cyber attack [
3]. A more technical approach is the MITRE ATT&CK
® globally accessible knowledge base of adversary tactics and techniques that has been built on real-world observations, initially developed in 2013 [
4]. A comparison between these two techniques for modelling cybersecurity attacks and defence was made in [
5].
The purpose of this paper is to present a novel approach to robust security solutions. This approach is named the Experimental Cyber Attack Detection Framework (ECAD) and is developed with the purpose to facilitate research of on-the-fly/online security applications. The vast majority of solutions for security systems focuses on offline modelling and data analytics tools. We consider that these offline results could be integrated in on-the-fly/online approaches. Suspicious traffic would be detected and any potential attacks would be prevented during the early reconnaissance stage. Thus, ECAD has the benefit of strengthening existing IDS/IDPS instruments and providing better responses to security threats.
In particular, we bring the following contributions:
We design and implement a cyber attack detection framework that can employ multiple reconnaissance agents. These agents provide useful low-level information about the network traffic and system logs. The framework then employs a specialised module that collects these data and decides whether to allow or drop a potentially suspicious connection.
We validate the effectiveness of the framework by testing it against various scenarios related to the reconnaissance phase of the Cyber Kill Chain Framework.
The remainder of the paper is structured as follows.
Section 2 presents the literature overview for the field addressed by our solution. The next two sections share our approach: the architecture considered for ECAD (
Section 3) and the practical approach to its implementation (
Section 4). The initial results and discussion are given in
Section 5 and
Section 6, respectively. The final
Section 7 draws the much-needed conclusions and hints on some prospective development.
2. Related Work
The escalating number of cyber attacks and related security events, and the increase and variety of attack patterns are met with renewed research efforts invested in developing new, better, and more robust IDS/IDPS solutions. These next-generation protection and prevention systems are being developed based on results supplied by data analytics tools and are ideally meant to prevent attackers from causing any effects on their targets. By the end of 2003, Taipale summarizes in [
6] a first set of such attempts and focuses on how data-mining tools might or might not be appropriate for security purposes. The study identifies two equally important trends. Arguably, inconsistent, erroneous data could lead to misleading conclusions. Moreover, data-mining tools are usually statistical methods and could yield false-positive results. This could lead, for instance, to an improper classification of network traffic and could allow a potential attacker to pass through unhindered. On the other hand, one should take into account the fact that data-mining algorithms and tools are not synonyms for the whole knowledge-discovery process. A good understanding of the data, proper modelling and selection of input data, and adequate interpretation of the results are also key stages that require appropriate consideration.
In 2011, Liu [
7] outlined two distinct approaches for data-mining/knowledge-discovery-based security solutions: top-down and bottom-up. This perspective is based on whether or not a hypothesis exists with respect to the analyzed security event. A top-down model implies that such a hypothesis exists and attempts to validate it through data-mining. On the other hand, the bottom-up method first attempts to analyze the security data and determine patterns and then formulate a model/hypothesis that encompasses the induced behavior. Liu then focuses on identifying the actual data-mining tools that are most commonly used [
7]. Both unsupervised and supervised learning techniques are employed to either determine groups of similar access patterns from historical data, or attempt to categorise newly acquired data into existing classes. Association rule-mining is also used alongside clustering and classification to identify potentially interesting patterns and relations between security audit data.
Most analytical approaches are based on classic DM tools and on using these results for improving IDS/IDPS solutions. The idea in itself is not something new, but it still raises significant challenges. Lee and Stolfo presented one such possible concept as early as 1998 in [
8]. Their focus is on audit data, such as access logs, protocol-specific data (such as FTP and SMTP), or dedicated monitoring commands (such as tcpdump) to build classifiers or to mine association rules. The purpose of these tasks is to contribute to building a set of decision rules for a potentially automated agent-based IDS. Enhancing their research, a subsequent study shows how modified association rule-mining and frequent episodes can be improved and therefore strengthen the aforementioned IDS [
9]. Data subject to this research are off-line data gathered from network and system audit data. The achieved results are the base building-blocks in determining features of intrusion patterns, features that are then used for intrusion detection models. In [
10], Lee summarizes both the progress and the issues that also arise from using DM and incipient forms of ML in IDS/IDPS: efficiency and credibility. DM/ML are mostly statistical instruments that could yield false-positives and false-negatives, as previously mentioned.
A more recent survey was presented by Jin et al. in [
11]. The authors identify that both descriptive and predictive DM techniques are employed in security analysis. The paper includes a comprehensive comparison between approaches—12 solutions are carefully considered—and identifies the strengths and drawbacks related to different types of attacks. The comparison criteria are based on the detection efficiency, the detection accuracy over four types of attacks, the false-positive rate for non-attack data, and also on the characteristics of the DM method(s). The authors of [
11] start their analysis with solutions destined to counteract Distributed Denial-of-Service (DDoS) attacks. According to the review, classification based on one-class SVM modelling achieves good results in identifying TCP-SYN, ICMP, and UDP flooding while having a potential disadvantage with respect to the dimensionality of data. This can be addressed by a PCA preprocessing stage. An interesting result is that this classifier achieves 98% accuracy in successfully detecting DDoS attacks and 100% accuracy in identifying normal traffic patterns [
11]. This suggests that rather than focusing on identifying attack patterns, one could focus on normal, clean ones (“Known Good”, as depicted in
Table 1) and guide the security decision based on these clearly known facts. While the actual practicality of such an approach might be questionable (i.e., how good the actual classifier is), we consider it could still be investigated further.
The next types of attacks considered by Jin et al. are remote-to-local (R2L) and user-to-root (U2R) [
11]. These types of intrusions are better addressed by a combination of two classic descriptive DM techniques: clustering (K-Means Clustering, for instance) and association rule-mining (Apriori/FP-Growth and as such). Yet again, the dimensionality of data could impose on the timeliness of the results. This could also be solved by relying on Big Data concepts (Map-Reduce/stream-processing or as such), especially when real-time security solutions are in focus. It is a well-known fact that traditional classification and clustering algorithms rely on the premise of “absolute definitions”: a data object either belongs to a class/cluster, or does not. This may not necessarily be an advantage when applying these methods over security data. The heterogeneity and variety of data sources and the high degree of correlations that need to be performed might not be most suitable [
11], especially in on-the-fly or real-time scenarios dealing with highly complex attack patterns. Jin et al. also analyzed the potential benefits of fuzzy-based approaches and sequence pattern mining applied over security-related data.
Jin et al. concluded their survey [
11] with two more important remarks that reinforced Lee’s results [
10] almost 20 years later. The first such note is that one must pay a great deal of attention to the actual preprocessing stages of data selection and data modelling when dealing with DM tools and algorithms. These stages definitely impact on the quality of the results and on the success of the solution. The second important idea is that a single analysis technique is usually insufficient in providing trustworthy information. Both descriptive and predictive solutions must be considered and mixed before actually reaching a security decision. We have taken this into account in the early design stages of the ECAD framework. Details are provided in
Section 3 and
Section 4. Our approach relies on (a) performing multiple analyses over the same data in parallel and (b) having a voting agent that makes use of these analytical results in supplying a security decision.
A novel approach, based on ML tools, is presented by Bartos et al. in [
12]. The authors propose a solution, entitled the “Network Entity Reputation Database System” (NERDS), focused on estimating the probability of future attacks. The concept in itself is rather intriguing. Instead of focusing on identifying attacks and attack patterns, Bartos et al. focused on the network entities that interact with the monitored system(s). Network entities are assigned a so-called “Future Misbehaviour Probability” (FMP) score based on meta-data about previously reported alerts related to the entities and on auxiliary, relevant third-party security information on those respective entities. The purpose is to estimate whether or not an entity would behave maliciously within an upcoming time-frame which the authors call the prediction window. The FMP score is determined using supervised machine learning techniques based on the aforementioned characteristics included in a past time-frame called the history window [
12]. The presented test results highlight the potential benefits of NERDS, especially when compared against deny-list searching for identifying potentially malicious entities. Moreover, Bartos et al. emphasized the generic character of the FMP score (i.e., it may be used to predict the overall behavior of an entity or it may model only particular behavior, such as the probability of a scan or a DDoS or an access attack) and on including NERDS within collaborative IDS [
12].
Research efforts are also invested in both the pre- and post-processing stages of DM/ML-based security approaches. Ahsan et al. focused on enhancing ML techniques used in detecting malware from packet information to strengthen cybersecurity [
13]. Their research is directed at reducing the dimensionality of data while still maintaining adequate levels of precision. The authors consider this can be achieved through eliminating highly correlated features. Dynamic Feature Selectors (DFS) based on univariate/correlated feature elimination, gradient-boosting, information gain, and the wrapper method application are presented and are then tested as preprocessing stages for five ML methods. Achieved results support the DFS approach with overall increases in both accuracy and precision. It is worth mentioning that Ahsan et al. conducted their research on NSL-KDD and UNSW-NB15 data sets [
13]. Kotenko et al. analyzed how combining multiple AI/ML techniques may improve the detection of distributed cyber attacks [
14]. They focus on weighted ensembles of classifiers and compare decision support solutions based on three voting schemas: weighted voting, soft voting, and AdaBoost. Kotenko et al. developed their own architecture for a distributed IDS [
14]. Data collected through different sets of analyzer entities are pushed to different classifiers. Each such classifier supplies its results to weighted ensembles, and thus a decision is made with respect to the nature of the access: normal/benign, DDoS or port-scanning. Tests are conducted against the CICIDS2017 offline data set and show the benefits of voting-based approaches in combining different ML results.
Hofer–Schmitz et al. [
15] has presented another, more recent study that emphasizes the importance of the data preprocessing and data modelling in attack detection. The authors target the Advanced Persistent Threat (APT) scenario. They focus on the later stages of APTs and on the whole attack in itself, rather than only on the initial intrusion phase. Supervised ML techniques are analyzed based on the feature set that constitutes the input data. Hofer–Schmitz et al. clearly prove that dimensionality reduction is a must—there are a great deal of features that yield repetitive, less, or no significant data, alongside the much-needed improvement of the response time. Another key note is that the actual datasets could be lacking with respect to the features identifying APTs. Hofer–Schmitz et al. solved this issue through a combination of facts: normal/benign data (the authors refer to this as background data) and some known knowledge on APTs. Thus, attack-identifying data are randomly inserted into the background, such that only one attack pattern would be observable during a one-hour interval [
15]. The results they obtain underline the importance of adequate feature set selection on different datasets.
The previously presented examples clearly show that DM/ML are useful in improving existing IDS/IDPS solutions, especially when combined into more comprehensive approaches. The subject addressed by our paper is focused on efficient architectures and practical implementations that would combine and use such analytical results in a real-time response scenario. Thuraisingham et al. [
16] established the challenges and direction from the perspective of data-driven approaches to cyber security as a science. Their main reasoning premise is that IDPSs are nowadays useless against APTs and slow attack vectors. The aforementioned Hofer–Schmitz et al. [
15] actually prove Thuraisingham reasoning a few years later. Thuraisingham et al. also establish one possible direction in developing a data-driven framework using a context model and related context representation for knowledge-sharing. This is based on the remark that “no single component will have complete knowledge about its context” [
16]. This approach was one of the mottoes in our design of the ECAD framework. Another key concept is that the logic of context-reasoning must be implemented separately from the monitored system and from the actual behavior of its underlying IDS/IDPS components. Our approach, ECAD, closely relates to this concept and allows the dynamic modification and/or replacement of these reasoning modules. Attacks such as APTs could thus be detected through forensic approaches—using rules over the sensed knowledge and data that describe a potential attack—in (near) real-time. Our experiments are focused on streaming data and facts and reasoning based on what is available for the currently inquired suspicious action. Thuraisingham et al. consider that, at least from a theoretical perspective, such investigations could only be performed post-factum. There was a real challenge to solve this issue: in the context of streaming, how can there be established a set of rules while the underlying facts that feed these rules require contextual analysis induced by those same rules? This cyclic dependency led us to design the ECAD framework as a state machine with a feature of storing historical metadata for later analyses. From the state machine perspective, we use security states that affect context and assume that a certain latency is therefore acceptable for this particular case. Establishing these particular contexts was another challenge that we needed to manage. This led us to the idea of using stream-based classification in detecting attacks. We study the problems of “concept-drift” and “concept-evolution” first stated in [
17]. There are real problems in a context of evolution of attacker methods or evolution of benign software usage patterns, that makes previously trained models outdated and therefore necessitates the continuous refinement of the classification model in response to new incoming data. It is clear for us that the ECAD framework must also deal with the emergence of novel classes over time. This is due to the implied fact that, for instance, new APTs would update and enhance existing attack methodologies and/or be based on entirely new ones. Given this perspective, we do not consider that the ECAD framework is a one-time deal, and we have designed it to be highly adaptable. This is detailed in
Section 3 and
Section 4. We therefore include an analytical overview of some of the data-driven security frameworks for the remainder of this current section.
Ankang Ju et al. [
18] proposed an architecture related to timely detection of comprehensive intrusions–HeteMSD (Heterogeneous Multisource Data). They differentiate between traditional attacks and targeted cyber attacks based on the complexity of the attack, on the motivation of the potential bad actor, and on the specificity of the attacked target. Based on this note, Ju et al. argued that the Kill Chain model is appropriate only for targeted cyber attacks. We consider that this is an artificial difference because complex attacks mingle both traditional and targeted approaches and make use of a high variety of techniques in exploiting a wide range of vulnerabilities. Moreover, we believe that one of the main goals of a potential attacker is to pass through unhindered. This is usually achieved by hiding malicious intentions within normal data or traffic. If we consider the case of remote system access, then a potential attacker would first scan the target to identify open network ports. One could use the Nmap tool which offers fine-grained timing controls alongside six predefined timing templates for IDS evasion. Some of these are based on arbitrary time-frames between consecutive scans such that it would appear as a common traffic error. This implies that a potentially targeted cyber attack relies on a first reconnaissance phase similar to a traditional attack. Ju et al. also consider that vulnerability data and threat intelligence could prove to be a valuable information source for any potential security solutions [
18]. We do take this into account in our approach, and we attempt to integrate these data in our practical implementation. On a last note on [
18], it is not clearly specified whether or not their model is only theoretical and whether or not they rely on offline or online data. At this point, we set our solution aside by directly aiming at online data as the target of our analysis, having offline knowledge as the basic building blocks for our decision system.
A closely related idea to the first two layers of our architecture was presented in [
14]. Their challenge was to develop the architecture of a distributed system capable of detecting cyber attacks based on Big Data technologies. One of their concerns was to reduce the number of lost packets, thus reducing the likelihood of losing information about a possible attack on high-speed computer networks. They are applying the method of balancing at client level, for distributing the load of network packets leaving the client-sensors and entering as input for packet classifiers at the server collector level, as a solution to reduce the number of dropped packets. Their basic architectural idea consists of several client-sensors and one server-collector. Each sensor includes one balancer and several network analyzers. At their estimated transfer rate at 600 kilopackets per second, even legit traffic may have DDoS behavior when full packet capture is performed. In our early experiments with the implementation of the ECAD framework, we extract only the traffic metadata because we investigate the behavior and not the payload, which is usually encrypted. However, this traffic behavior might still occur, and for this reason, we imply the usage of load balancers in order to scale out on demand, as described in
Section 4.2.1.
The “Universal Cyber Security Toolkit” (UCST) is intended to enhance the cyber protection of the healthcare IT ecosystem and ensures the patients’ data privacy and integrity. UCST is developed as part of the SPHINX project under the grant agreement H2020-EU.3.1.5.1-ID 826183. Authors have developed the architecture and its corresponding technical specifications focusing on the proactive assessment and mitigation of cyber security vulnerabilities and threats [
19]. The authors determine, through a Vulnerability-Assessment-as-a-Service, a so-called “Common Vulnerability Score” that is used to dynamically assess vulnerabilities of network entities. UCST, as the core component of SPHINX, is meant to operate with online traffic data, and the initial tests have been performed over the NSL-KDD Train 20 variant intrusion detection data set. SPHINX is therefore another solution that attempts to integrate ML analytics into an online approach. However, it seems that this approach does not make use of multiple analytical tools and does not combine their respective results [
20]. What sets our solution aside is that we do combine results from different sources (threat intelligence, DM/ML solutions, etc.) in an attempt to: (a) achieve good response/reaction times; (b) increase the degree of confidence in a decision; and (c) provide the means to further analyze these outcomes and better understand the results. With this purpose in focus, we have included a voting agent within ECAD and support for persistent decision storage (see
Section 3). Similar vote-based decision solutions in security systems are therefore further reviewed.
We have previously mentioned that the model submitted by Kotenko et al. [
14] also employs a voting approach due to the inherent errors of DM/ML tools. The authors suggest a weighted voting mechanism, having the actual coefficients assigned to the basic classifiers with respect to the correctness over the training instances. They also make use of tools that keep track of the results supplied by each individual classifier. These historical data are used both to adjust the assigned weight and to improve these classifiers. Improvement is achieved by retraining faulty modules focusing on the previously incorrectly classified objects. Babić et al. [
21] also emphasized the fact that a voting mechanism should be used alongside DM/ML modules. They rely on a Triple Modular Redundancy (TMR) approach and focus on identifying DDoS attacks. The input data for the TMR module are collected from three classifiers (EWMA, CUSUM, and KNN), where the result is binary and indicates whether an attack is happening or not. Babić et al. [
21] also stated that TMR may be generalised into a n-modular redundancy (n being odd) provided that multiple analytical tools are available.
As a research and educational framework, our approach allows the opportunity to share the evidence on which the decision was based on an integrated information-sharing platform, for later studies. New knowledge gained on both existing and new attack patterns are invaluable in strengthening IDS/IDPS solutions and successfully reducing the potential impact of security breaches.
Wagner et al. presented in [
22] a malware information-sharing platform and threat-sharing project platform. Their purpose is to collect and share the important Indicator of Compromise (IoC) of targeted attacks as an open-source software solution. It is worth noting that this approach is mainly developed by the Belgian Defense CERT and the NATO Computer Incident-Response Capability (NCIRC). The gathered data include both technical and non-technical information about malware and attacks and is stored as a so-called event using a standardized format. Sharing and distribution is intended for trusted parties established in a trusted environment. The MISP—Open-Source Threat Intelligence Platform and Open Standards For Threat Information-Sharing (formerly known as the Malware Information-Sharing Platform)—provides functionalities to support the exchange and consumption of information by NIDS, LIDS, log analysis tools, and SIEMs. One of the most interesting features of MISP is the correlation engine. Its purpose is to identify all relationships between events based on their attributes. This is performed through one-to-one, fuzzy hashing correlation techniques and/or Classless Inter-Domain Routing block-matching. We consider this to be a very useful approach, since it could allow security specialists to preemptively address potential threats. ECAD had therefore been designed to embed both this validated threat intelligence data source and its corresponding correlation functions.
There are many open-source projects and commercial products that offer the means to deal with threat intelligence. Solutions like IBM X-Force Exchange, Alienvault OTX Pulse, Checkpoint IntelliStore, Crowdstrike intelligence exchange, CRITs, Soltra Edge, and CIF v3, to name a few, are presented comparatively in extenso in [
23].
Throughout
Section 2 we have analyzed the concept of security in a digital age. It is clear that simply configuring adequate IDS/IDPS solutions is not enough to ensure a trustworthy degree of safety. Attack patterns and malicious activities vary in both diversity and number, and new threats arise almost every day. Working on the concept of security as a process, we have identified two major research investments for this field. The first one relates to using DM/ML techniques to strengthen existing solutions. The reason for having a review on DM/ML techniques is only to reiterate their prospective advantages in security solutions. This approach is furthermore justified by the basic need to first understand and know your data—security data in this case—and to understand your target results. Association rule-mining, clustering, and classification techniques are just a few of the analytical tools we have centered our attention on within this review. Usually, these are applied over what we call offline data, such as audit logs, behavior, connection patterns, and so forth. The natural evolution is to then include these results dynamically in IDS/IDPS solutions, and it offers the second analyzed research field: security frameworks. This represents the main topic presented in our paper: a research and educational framework that allows the study of utilising intelligence threat data and DM/ML results in (near) real-time reactions/responses to security threats. The literature survey therefore includes the required analysis on the necessity of reliable threat intelligence data-sources (e.g., MISP and other enumerated projects) and on some theoretical and practical approaches to security frameworks that make use of the aforementioned concepts (HeteMSD, the framework submitted in [
14], and Sphinx). We have chosen to analyze these frameworks because we consider them to be somewhat similar to our own with respect to having a voting mechanism that validates the decisions. This is indeed to be expected since DM/ML results are subject to probability.
Our contributions for this section are summarized below:
An analysis on DM/ML approaches in cybersecurity;
An overview of some of the frameworks that could make use of DM/ML data in strengthening IDS/IDPS solutions;
A contextual link between the literature review and our solution.
3. ECAD Framework Architecture
It is generally accepted that an intrusion is an unauthorized mechanism designed to access system resources and/or data. Intruders can be classified as external and internal. External intruders attempt to gain unauthorized access to system resources from outside the target network. Internal intruders attempt to elevate their limited privileges by abusing it. Our research is focused on creating a security framework that provides mechanisms to detect behavior of external intruders in the early stages of a cyber attack. We consider that an attacker becomes an internal intruder after successfully gaining access to internal resources. Vertical and, at least partially, horizontal privilege escalation (e.g., lateral movement) are successfully dealt with by antivirus programs and other commercial security products. This is beyond the purpose of the paper. We focus on prevention and pro-active decisions rather than on post-factum detection and containment. The software solutions available for our approach are varied, and both open-source and proprietary software could be used in a proof-of-concept implementation. One of our main concerns is to provide interoperability and enable collaborative security approaches, and not to compete with or replace an existing product. The ECAD framework is thus designed to be pluggable by default and include and/or interact with various other systems. This interoperability will also emerge later in this section, from the description of the tools that can be used, as well as the solutions chosen for the implementation of the ECAD platform prototype.
Our aims are to: (a) provide a guideline on how to integrate tools in order to obtain the desired results; (b) provide an environment for testing and analyzing the performance of custom tools in attack detection scenarios; and (c) provide a (near) real-time solution for addressing the initial phases of cyber attacks. Thus, the ECAD architecture we submit has the potential of inducing a new methodology for preventing cyber attacks in (near) real-time. This approach focuses on analyzing live traffic data and metadata and issue feedback that would facilitate adequate responses. Therefore, the architecture encompasses two external layers that are included within any cybersecurity context to mimic real-case scenarios and to trigger responses from the framework. These layers are shown in
Figure 1 and briefly explained bellow.
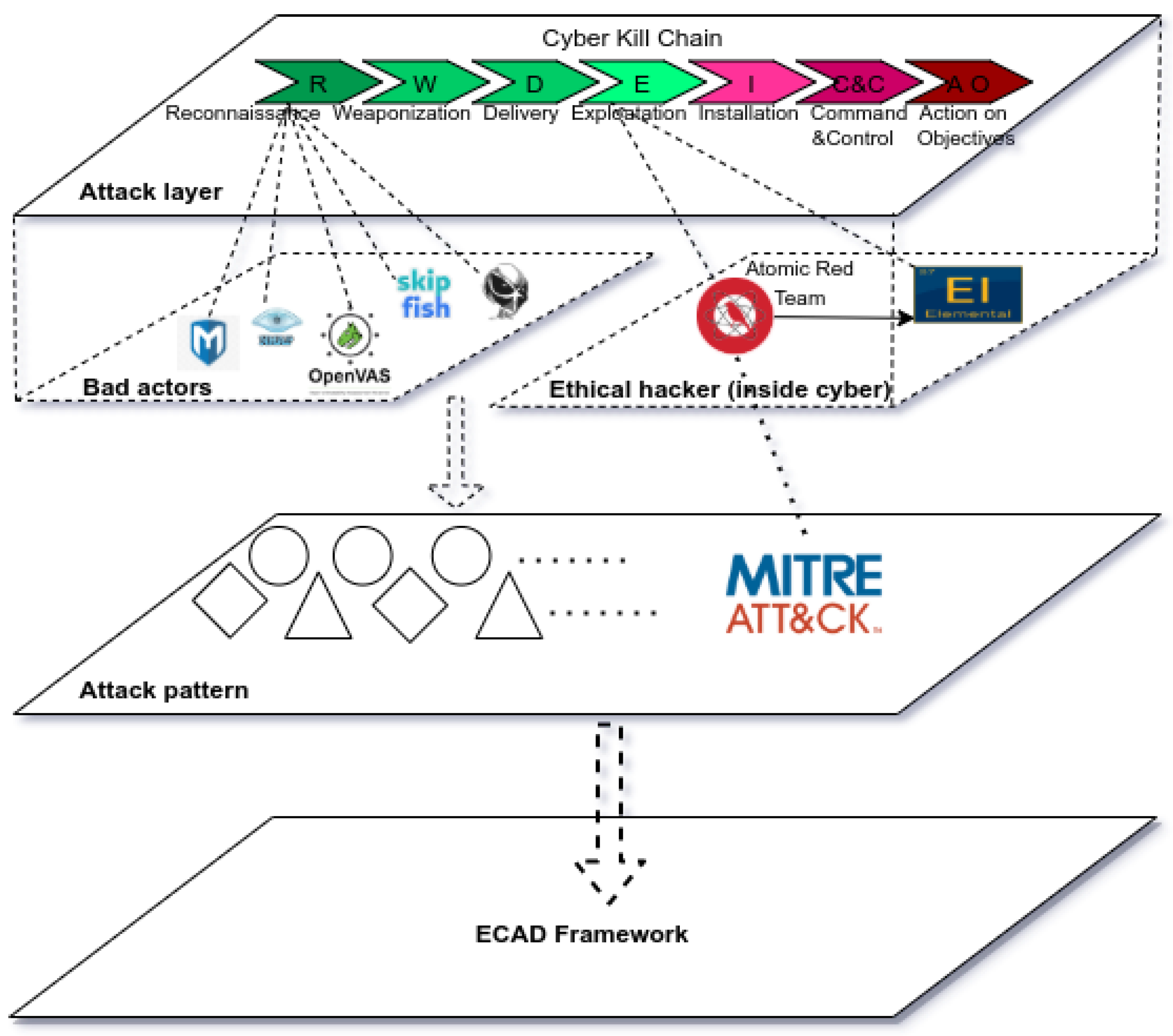
Attack Layer: Any kind of attack scenario can be modeled using the Cyber Kill Chain pattern presented in [
3]. Nowadays, an attack scenario includes more and more sophisticated techniques that are used by both malicious (“Bad Actors” in
Figure 1) and well-meaning actors (“Ethical Hacker” in
Figure 1—security specialists who analyze the ability of the defended system to cope with an attack). Each such attack begins with a much-needed reconnaissance phase. During this stage, actors try to analyze their target(s) to obtain as much useful data as possible and, at the same time, try to avoid raising suspicions. These data are used during the weaponisation phase to build a payload that is served within a so-called delivery stage. A subsequent exploitation stage is then in place, when the malicious actors try to execute auxiliary commands to ensure the persistence of the delivered payload. Well-meaning actors, who know the infrastructure of the protected network, will perform the same steps in order to identify what their opponents might discover or use.
We noticed that the reconnaissance phase is usually neglected by most IDS/IDPS systems. The actions performed during this stage are considered borderline legal and cannot directly incriminate a potentially malicious actor. This is one of the key points of our approach. We do consider that the information gained from this phase could be extremely valuable in identifying the actual target of a potential attack. Therefore, the ECAD framework has been designed to also analyze these types of data. Furthermore, we consider that operating on these two incipient stages (i.e., reconnaissance and delivery) is a mandatory first step to be taken in a (near) real-time response scenario.
Attack Pattern: There are multiple scenarios and combinations of scenarios that an attacker can follow so as to disguise their action as much as possible. The actions performed during this weaponisation stage involve enriching existing successful scenarios with new, innovative techniques and delivering highly diversified attack patterns. It is a well-known fact that the actual weaponisation phase is usually hidden for the target. One should take into account that both attackers and defenders could use the same knowledge base, such as the MITRE ATT&CK
® framework. Defenders use ATT&CK to test the defensive capabilities of the monitored targets and to discover unknown gaps in networks and products alike, or to perform tabletop exercises, assessments, and hands-on evaluations, as shown in
Figure 1—the Ethical Hacker (Inside cyber) sub-layer. Aside from the actual beneficial security results, we also consider these data as valuable input for our own analytical layer. Relying on some clearly known, verifiable data implies strengthening the accuracy of DM/ML tools and is well within the purpose of ECAD.
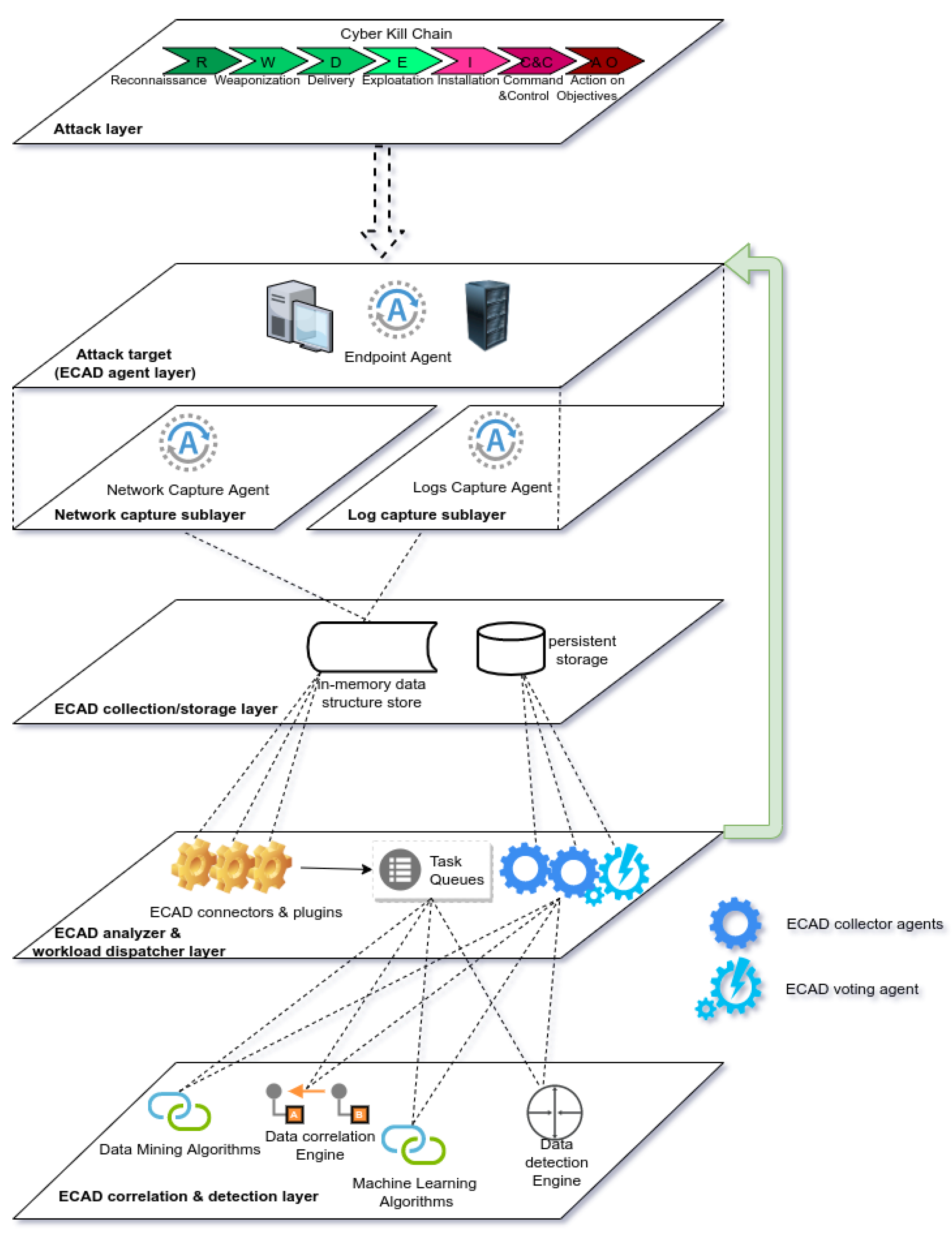
The ECAD framework is comprised of four tiers, as shown in
Figure 2: the Attack target (ECAD agent layer), ECAD collection/storage layer, ECAD analyzer and workload dispatcher layer, and ECAD correlation and detection layer.
Attack target (ECAD agent layer): The targeted system is the tier where the first elements of the detection chain within ECAD acts. These elements collect raw data from network traffic (Network capture sub-layer) and/or log files of protected systems (Log capture sub-layer). Additionally, at this tier, the system reacts through actions such as communication-blocking or redirecting to a controllable area, using security deception as an emerging cyber-defence tactic. This latter security approach may not be mandatory for common analytical frameworks, but we consider it does hold some potential in strengthening the actual study of cyber-attacks. Even though they are not explicitly represented in
Figure 2, security deception tools like honeypots and sandboxing mechanisms allows further observation of the behavior of attackers once they have gained access to what they think is the targeted network. The actions of the attacker could be tracked trough honeypots to reveal how the real threat actor behaves, and their actions could be detected without repercussions on the defended system. This provides support for the much-needed interoperability between ECAD and other detection and analysis systems. Furthermore, depending on the system’s protected services, the Network capture sub-layer and the Log capture sub-layer components may be configured accordingly. Moreover, this tier ensures some form of data-preprocessing through filtering. At the Network capture sub-layer, only metadata obtained from levels 2, 3, and 4 of the OSI model are taken into account, depending on the actual communication protocols that are being used. At the Log capture sub-layer level, the filtering is done according to their format and the services that generate the data.
ECAD collection/storage layer: We have designed this tier as an intermediate one between the information collection and decision-making tiers. There are two main goals for this approach. The first one is related to the fact that we need to perform multiple, independent analytical tasks over the raw incoming data from the previous tier. This is indeed required due to the fact that various DM/ML tools have different strengths and weaknesses. A (near) real-time approach must eliminate those weaknesses in order to reach a proper security decision. Moreover, different DM/ML tools might require different data models. We addressed these issues through In-Memory Databases (IMDBs). Raw data are temporarily stored within these fast storage tools. The underlying agents read their corresponding data chunks, with the last agent triggering clean-up stages. This ensures speed while minimizing the chances of data loss (i.e., all the agents are required to perform analytical tasks on the same data who would actually receive that data). The second goal is to offer the means required to review and further investigate the results supplied by the lower tiers. We have considered persistent storage databases in order to solve this problem. The role of this persistent storage is to keep data that can be related with previous events and that have been analyzed and classified. Persistent storage improves the previously acquired raw data with the corresponding results supplied by the agents included in the lower tiers. This implies an UPDATE-like operation. Persistent storage is separated from the actual processing chain—that is, raw data are collected from a different source (IMDBs) and results are stored through a logging-like procedure. This ensures that the limitations of persistent storage do not impede on the speed of the system while still allowing the required audit information.
ECAD analyzer and workload dispatcher layer: We have designed this tier focusing on three key goals. First of all, we have stated that the same raw data should undergo multiple analyses that would compensate for the inherent probabilistic nature of DM/ML tools. Consequently, the same input data from the upper tier are modeled into different tasks. Each such task is processed independently from the others, in parallel. Once this processing is completed, the task is pushed to a dedicated queue (see
Figure 2—Task Queues). This allows us to identify the actual analytical task rather quickly, without having an actual task selector module. The second goal is to be able to map the analytical results to the corresponding raw input data, issue a decision through the voting agent, and store the results for further investigations. These analytical results are received by both dedicated collector agents and the voting agent. The collector agents are responsible for persistently storing the results, while the voting agent is responsible for issuing a decision. This approach allowed us to also achieve the third goal: completely separated routes for the input and output data for this layer. This is, in our opinion, an essential property of a (near) real-time design: an asynchronous behavior through dedicated processing entities and communication channels that greatly diminishes the possibility of bottlenecks.
Further enhancing the idea of (near) real-time responses, we consider that it is better to have some initial reaction during a potential attack than a delayed one (or even not a reaction at all). The voting agent is designed to reach a decision as soon as possible, while at the same time being able to self-amend any potential false result. A schematic representation of the actions performed by this particular agent is given in
Figure 3.
The core principle is that the voting agent would not wait for all these tools to offer a decision with respect to the analyzed data. Decisions are reached as soon as an acceptable confidence degree is obtained. To exemplify this behavior further, let us assume the following simple example: consider the case of a port scanning attack performed by a known entity. This entity has not yet attacked our protected endpoint(s), but has been previously reported for malicious behavior, and these reports have been acquired within the integrated malware information-sharing platform—denoted agent A1. There are other analytical modules that can provide responses based on behavior using DM/ML techniques—denoted agents A2, A3, A4. Let us assume that the weights are 30%, 10%, 20%, and 40%, respectively. A1 will provide the first response, followed by the others. If we further assume that a threshold of 40% is an acceptable confidence degree (
Figure 3), then any second agent that responds would also trigger a reaction from the voting agent to the upper-layer endpoint agent. Late responses are also acknowledged and stored alongside previous ones. Moreover, if these late responses reverse the decision, then the entity is once more permitted to access the protected endpoint(s). We thus mitigate the probably good and might be good scenarios (see
Table 1). Such clients would only perceive our response as a network glitch, which in turn might still be acceptable since we could actually provide a better degree of protection.
ECAD correlation and detection layer: This last tier of the ECAD framework is the actual computational one. It is meant to integrate threat intelligence data sources and analytical tools based on DM/ML techniques. Each resource is embedded within its own service. We chose this approach due to the fact that it allows parallel, independent processing over the same input data. Furthermore, it allows on-the-fly deployment of new modules or removal of faulty ones. For instance, adding a new analysis tool implies running a new service, two dedicated agents included in the upper tier and a new task queue associated to this new service. We consider that a proper implementation of this approach theoretically implies zero downtime.
Another reason that justifies our approach is related to the previously presented voting mechanism. The enhanced flexibility of this design might allow developers to integrate faulty tools in their implementation. Additionally, some analytical tools might be more suitable for some particular types of attack. Threat intelligence data may not include the latest accurate details required to reach a decision. To counteract these potential pitfalls, we have designed this layer such that each analytical service is assigned a weight based on a given degree of confidence one has over a specific tool or another. Moreover, it is not guaranteed that all services would supply the results at the same time, as we have previously shown (see
Figure 3). Services that do not supply their results in due time would still be able to contribute to the decision as a “second opinion” on the already taken course of action. We opted for this design model because it supports both self-amending a previously erroneous action and the opportunity to recalibrate the tools and improve the results.
Each analytical service needs to be designed as that it would closely follow the functions of the underlying detection component. Threat intelligence data sources are usually meant to search for correlated events, based on stored knowledge. We therefore designed such services to include the retrieval function, as well as to analyze the found data and determine whether or not there is an undergoing attack. DM/ML techniques could be classified in descriptive and predictive groups. While predictive analyses are more suited to be used in (near) real-time solutions, descriptive ones need to be adapted for such scenarios. Both techniques are relevant through their actual result data rather than the means of achieving those results. We considered this last remark and designed these services accordingly.
Section 4 and
Section 5 provide more details on how we actually achieved this behavior.
Section 3 is dedicated to presenting our architectural model for a framework that aims to improve security solutions and provide timely responses to undergoing attacks. We focus on the early reconnaissance and delivery phases and on prevention rather than post-factum responses. The architecture is organised on four tiers, modular by design, and allows fast integration with new security and analytical tools. We consider that this approach is suitable for modern implementation techniques and is meant to be implemented in virtualised environments, based on concepts such as Infrastructure as Code (IaC) and Software-Defined Networks (SDN).
5. Results
The main topic of this paper is to submit a potentially new methodology for studying and preventing cyber attacks and to provide a framework to support this methodology. Our key focus is on an IDS/IDPS solution that offers near real-time reactions to potential attacks. This approach is not meant to obsolete existing security tools; it rather represents a means to integrate appropriate DM/ML instruments, security intelligence data, and so forth into collaborative defensive solutions. The ECAD framework is at present in its prototype implementation stage. Closely following the architecture described in
Section 3, the practical realisation described in
Section 4 heavily relies on virtualisation tools and pluggable components. We consider that these are the first important results that we have achieved through the proposed approach. All the underlying components of ECAD are running in dedicated containers and are being exposed through uniform access interfaces. This implies that we have achieved a platform agnostic solution that may be deployed on any system capable of running container software. To further demonstrate this portability, we have deployed the prototype ECAD implementation on three different environments:
Seven systems (with Intel® CoreTM i5-7500 CPU @ 3.40 GHz, 6 M Cache, 8 GB RAM and Gigabit Ethernet);
Seven virtual machines running in an OpenStack Ussuri private cloud based on a CentOS 8 cluster with 8 Raspberry Pi 4 Model B Rev 1.4 (Broadcom BCM2711, Quad core Cortex-A72 (ARM v8) 64-bit SoC @ 1.5 GHz, 8 GB RAM and Gigabit Ethernet);
Seven virtual machines running in a Proxmox Virtual Environment private cloud (8 GB RAM and Gigabit Ethernet).
All running CentOS 7 with dockers installed in swarm mode—three managers and four workers. All clusters are organized on 8 stacks, 44 containers, 21 services, 77 images, 50 volumes, and 65 networks, as reported by Portainer.
Moreover, container-based architectures support scalability through container orchestration means. We made use of these advantages: an analytical tool included in the ECAD correlation and detection layer would run as an independent task, replicated on a need-to basis. It allows for parallel analysis over the same packet capture data for a dynamic voting agent, and speeds-up the decision-making process with respect to the nature of the data being investigated. There is yet another important note on the architecture we submit. The actual data-flow we have proposed for ECAD is somewhat circular by nature (see
Figure 2). Data collected by the dedicated agents are forwarded through dedicated channels to the underlying layers, while responses and reactions are obtained through different routes. Alongside the aforementioned scalability benefits, our circular approach diminishes the risk of data-flow bottle-necks and potentially further reduces the actual response/reaction times.
We enforced the pluggable behavior of ECAD by applying Viktor Farcic’s [
28] project Docker Flow Proxy recommendations to our particular environment. The reverse proxy we have used will thus automatically detect new components that could be included within ECAD and forward requests appropriately. As expected, the same level of automation is achieved when an unused or a faulty module needs to be taken down.
We have shown in
Section 4 how we have integrated the MISP threat security intelligence data source and correlation engine in ECAD. There are two main reasons to support our decision. The first is the obvious one: since there already exists a tool that can help detect and prevent attacks, why not include, under the AGPL (Affero General Public License), such a tool within a Collaborative IDS/IDPS? It is especially useful on new server/application deployments that have gained the attention of malicious actors and could be subject to attacks. In the following, we present a use-case we have successfully resolved using this approach.
The experiment is related to malware injection performed within an APT. We assumed the aforementioned malware had already been delivered onto the monitored system. It is a common case for traditional solutions that analyze malware based on the signatures of the underlying program files. The dedicated ECAD endpoint agent identified the collateral movements with respect to application behavior and data transfer patterns. The data collected on the potential victim is modeled into an event according to the MISP attribute system. Moreover, this event is labeled with threat level 4 (i.e., the lowest threat level admissible in MISP). The event is then embedded in an analytical task by the agents included in the ECAD analyzer and workload dispatcher layer (see
Figure 2). The corresponding module in the ECAD correlation and detection layer pushes this event data in MISP. This threat intelligence platform would in turn update the event through its own analytical means. We target the identified related events and their corresponding sources and update the threat level of our own event through a weighted schema based on the degree of confidence in an organisation and on the threat level of its corresponding event. The following decisions are then issued to the voting agent:
Threat level 4 (unmodified)—enhance monitoring, no other attack-related action; this is the case of a raised suspicion that does not provide sufficient data for an actual decision, but still needs monitoring;
Threat level 3—issue a temporary quarantine of the suspicious applications and a temporary traffic ban to/from the eventual remote IPs; this is the case of potentially materialized suspicion, actions are required to be taken, but there is still a level of uncertainty with respect to the source;
Threat levels 2 and 1—issue permanent quarantine of the suspicious applications and permanent traffic ban to/from the eventual remote IPs; there is definitely an undergoing attack, the actions are meant to be taken immediately.
Observed response times are of the order of several tens of seconds until the actual decision is made and the corresponding actions are issued. While these results have been obtained in simulated environments and there is room for further improvement, the simulated attack had been contained. Moreover, data related to the attack and the related issued actions had been stored for further analysis. These results are also meant to exemplify our idea of having an initial reaction rather than no reaction at all, as stated throughout
Section 3.
The second reason for our approach is less obvious and applied to all analytical tools, including MISP. A successful implementation of security tools does not expose its internal components and reaction/response data to any potential attacker. In our approach, ECAD embeds these decision support tools within its innermost tier, and this hides their existence from malicious entities. Moreover, each communication between these components is at least secured with respect to its transport layer and each component undergoes authentication and validation stages. This is possible due to the automated certification mechanisms we have adopted for our practical implementation.
The ECAD correlation and detection layer also includes some of our own approaches for different DM/ML tools. While these components are still undergoing testing and are not the main focus of this paper, we will present some of the preliminary results we have obtained. Reconnaissance phases performed to identify available exploits targeting Web CMS (Content Management Systems) solutions usually aim to identify specific resources that are known to be vulnerable (such as JavaScript modules or PHP script files). An attacker having obtained knowledge on such weak spots may then directly perform the delivery phase. Using association rule-mining techniques on OSI L7 log data, we have noticed that most such discovery stages directly target those vulnerable resources, without having a referrer entry in the HTTP server log. Based on this note and on previously known HTTP access logs, we have modeled an itemset as a tuple of
, having:
The INTERNAL value above implies that the resource is not meant to be accessed directly. We then model the actual association rule obtained from such an itemset as having:
antecedent
consequent .
These rules are then mapped over search-specific data structures that allow parsing the antecedent down to the point where the consequent may be uniquely identified. A navigation pattern that reaches an INTERNAL target with a NULL referrer included in the antecedent is considered to be malicious and such an agent would immediately yield an attack alert. This implies that our endpoint agent on the monitored entity would therefore inject a DROP rule into the firewall and would thus at least hinder the potential attacker. This implies that such a potential approach would not supply the complete results required to perform a successful attack.
We are testing a similar approach for detecting and preventing HTTP flood attacks. These may be perceived either as reconnaissance (i.e., determine information on the defensive tools), or delivery phases. We also make use of association rules for one of the ECAD analytical agent, but this time, the consequent of the rule (i.e., TARGET item) has a different set of values: (i) VALID—meaning a legitimate URL and (ii) INVALID—meaning a randomly generated URL that identifies no actual resource. The case we address is the one of brute-force HTTP GET flood. Rules that end with consequent indicate a definite denial-of-service attempt. Alongside this agent, there are also dedicated ones that analyze OSI L3 data in order to check the corresponding underlying TCP connection patterns. A host attempting to establish a high number of connections with the same target network service (i.e., the HTTP server for this scenario) represents an indication of an attack. Through the described voting algorithm (see Algorithm 1), the decision is issued to DROP all connections to that particular host. While these initial results are promising enough, another interesting remark may be formulated: we deny any further connections with any attacking host. This implies that all attacking hosts would be denied access, should the monitored system be subject to a distributed attempt (i.e., DDoS) on the same network service. The reaction time is indeed higher, but we still have the benefit of recovering rather quickly.
One more important result that we have observed is that responses/decisions/reactions are received from the ECAD Voting Agent (see
Figure 2 and
Figure 3) within, at most, minutes after the suspicious access occurred. This is possible due to the design of the ECAD Voting Agent: the first reaction is based on a confidence threshold and it still allows for possible amendments if the initial decision was incorrect. Our approach could be rephrased as: Can we act on a suspicious action pattern before it is actually finalized? While, at present, these data have been observed in simulated conditions, and while response/reaction times still need further thorough assessment, we consider them to be promising. As we previously mentioned throughout this paper, our main target with ECAD is to detect and isolate/act on malicious actions during the reconnaissance phase. In doing so, we are able to slow down or actually impede potential attackers during the very initial stages of their actions. We do not target the clearly “Known Bad” (see
Table 1)—for these scenarios, there already are trustworthy security tools that solve them.
6. Discussion
We have designed and implemented the ECAD framework as a research and educational tool that allows the study of cyber attacks and the corresponding actions to prevent them. The main focus had been on the concept of (near) real-time responses to online threats through means of data analyses and DM/ML techniques. We strongly believe that prevention during the early reconnaissance and delivery phases is a key property of any proper security suite. We would like to point out that the correctness of the results is still undergoing testing, as this framework is in the initial development phases. We focused only on getting the workflow done and having the decision system up and running. We pointed out throughout
Section 3 and
Section 4 that it is better to have a reaction during an active attack than a post-factum analysis or no reaction at all. The voting algorithm we have submitted and developed is based on this idea. Moreover, the solution we have proposed has a self-amending behavior—that is, the initial decision reached by our voting mechanism may be modified on-the-fly provided that there are enough results that revert the original course of action.
We have shown through the literature survey presented in
Section 2 that complex attacks require several stages of setting up and preparation prior to the actual actions. Potentially harmful actors need to first assess the target system’s defence capabilities, to identify the strengths and the weaknesses of the underlying security measures and of the target applications. While some of these initial stages may be hidden to the victim (such as the weaponisation phase with respect to the Cyber Kill Chain), actions taken during reconnaissance and delivery are almost always observable provided that adequate monitoring instruments are in place. This is the proactive approach we base our reasoning on, and we make use of such data in at least hindering the actions of bad actors. We consider that an attack cannot be successfully performed if the aggressors do not acquire enough information on their target. This implies that the agents included within the ECAD framework would actually be able to stop a cyber assault before any actual damage is incurred on the target. This proactive reasoning could also prove to be successful on some classic attack patterns, such as DDoS. We presented one such study on preventing HTTP GET flood attacks using association rule-mining techniques in
Section 5. While we have not focused on a thorough assessment of reaction times, we noticed that the attack had been dealt within a few minutes. This is a significant result, especially if we consider the most recent report published by ENISA in [
30] on DDoS attacks. Of such attacks, 52% are performed in under 15 min. This 15 min time-frame is usually observed for brute-force, aggressive DDoS which could also be solved through existing IDS/IDPS solutions. The remaining 48% is reported for more persistent attack patterns and could pass through classical defence mechanisms. The preliminary results we have obtained emphasize the potential benefits of our approach even for this second category of sustained DDoS attacks.
The pluggable architecture we have developed for ECAD is another important advantage of our approach. This allows the dynamic integration of new detection and prevention modules. Let us consider the example of brute-force FTP attacks. Bad actors employ novel, more aggressive distributed techniques and are able to avoid detection through constantly changing their IP addresses after a predetermined, limited number of unsuccessful attempts. The solution utilised in HTTP GET flood attacks could be modified through changing the meaning of the association rules presented in
Section 5: the antecedent of the rule could include a sequence of failed attempts, and the
item in the rule consequent could point to a value included in the targeted users’ pool. The flexible implementation of ECAD would require: (a) a new module that includes the corresponding patterns deployed within the correlation and detection layer, and (b) a new job dispatcher and a new queue for the analyzer and workload dispatcher layer. This is made possible through our IaC-based solution. Other existing threat intelligence data sources or analytical tools (such as ELK, Splunk, MISP, or OSSEC) could supply adjacent results for the voting agent to either strengthen or weaken the attack decision. These multiple different analyses performed over the same input data are another particularity of our solution (see
Section 4.2.4). It allows us to take different perspectives of the same data into account, having different meanings and targeting different components of an attack, instead of just focusing on multiple tools that belong to the same analysis category.
We would like to also discuss the concepts of (near) real-time detection (and prevention) vs. post-factum detection. We consider that post-factum detection begins with the onward exploitation phase with respect to the Cyber Kill Chain model. This implies that the reconnaissance and the delivery phases had been successful—that is, the attacker already gained some sort of access to the monitored system. We argue that this involves a late decision solution and does not comply with the purpose of the ECAD framework. We address the concept of first-hand prevention, and we emphasize that this is merely the first step to be taken. It is not the only step, and it does require further analyses to be performed over the monitored system, as well as auditing the chain of decisions that has triggered a given course of action. We address this through the persistent storage tools we have made use of (refer to
Section 3 and
Section 4—the collection/storage layer). This represents one key element of Bruce’s Schneier “security-as-a-process” concept. It also relates to “security as a science” and “science driven by data” notions [
16]. We make use of existing data (by employing different analytical agents and tools) and we produce even more data for further investigations and potential improvements. We have repeatedly acknowledged throughout this paper that good data-driven solutions rely on a profound understanding of the input information available and on the results that are to be obtained.
More and more data are always a challenge in itself, and we need to focus future research efforts on this as well. We must ensure that every processor or service we distribute in the swarm does not receive a larger volume of data than it can process. A less-than-optimal data split between tasks could severely impede on the (near) real-time characteristic of ECAD. A possible solution is to develop a system that aggregates usage metrics and gives us the ability to issue alerts or make certain decisions when a given threshold has been exceeded. We identified a possible solution for this—Prometheus, but it is not the only tool that should be considered. Results supplied by Prometheus could be used in Auto-Scaling Docker Swarm Services.
We have previously stated that ECAD has been designed and implemented such that it would consider multiple analyses over the same data (access pattern, application behavior, etc.). Our preliminary testing phases have been focused on OSI L3, L4, and/or L7 data. However, the Network capture agents are also collecting OSI L2 information (see
Section 4.2.1). This could prove to be yet another useful feature encompassed in ECAD. MAC address spoofing attacks are rather difficult (if not next to impossible) to detect. Harmful actors could try and use this course of action in order to gain unauthorized network access. A correlation analysis including L2 MAC addresses, probable time-frames for the physical location of the monitored devices (e.g., AP migration in WiFi environments), OS identification tags, and so on could prove beneficial in detecting suspicious elements. Such an approach would enforce the prevention capabilities that ECAD could offer in scenarios that rely on the Zero-trust security policy model. This model implies that complex networks’ security is always at risk to both external and internal factors. A practical use case for this ECAD development is the well-known bring-your-own-device (BYOD) policy within such Zero-trust environments. Of course, the second valid use case would be the actual research that could be performed over this extensive set of data.
Another desirable enhancement of ECAD would target the concept of proactive defensive techniques. It is our belief that most IDS/IDPS suites are rather reactive with respect to detecting threats. Moreover, performance evaluation and auditing are also made post-factum. A possible approach to counter-acting this behavior is employing teams of security specialists to mimic attacks on the protected systems and their components. The purpose is to identify potential weaknesses and issue corresponding corrections and amendments for the affected security modules and/or faulty application modules. Projects such as Elemental (developed at the Berkeley University of California) provide the means to integrate threat libraries, Atomic Red Team test suites, and other such relevant data. The ECAD framework includes two main modules to support such a study: the external Ethical hacker (inside cyber) sublayer (see
Figure 1—
Section 3) and the MITRE ATT&CK
® framework within the internal correlation and detection layer. These modules could be configured to perform controlled attacks and identify the vulnerable components of the monitored system and applications. The ECAD Testing agent (see
Figure 6—
Section 4.2.1) is included specifically for these tasks. Alongside the previously mentioned benefits, such testing scenarios could be used to strengthen the DM/ML techniques that are being used within our framework. Instead of merely reacting to incoming threats, one could make use of this framework to actually conceive and model new attack patterns and better prepare for an eventual real-world intrusion.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}