1. Introduction
Satellites are essential assets for space exploration and data collection. Therefore, their fault-free operation is critical, which relies on the health of their subsystems and components. For example, one of the major systems of any satellite is the attitude control subsystem (ACS) that uses different actuators such as reaction wheels, momentum wheels, and control moment gyros (CMGs), among others. If the ACS fails, the satellite cannot complete its mission. Hence, if a fault occurs in any part of the CMGs, it may fail if unattended. Fault isolation can prevent failure and increase satellite reliability by identifying any occurring fault and conducting remedial actions in time. Different fault isolation approaches include the model-based and data-driven categories [
1,
2,
3,
4].
The application of different data-driven methods in fault isolation has become popular in recent years. Specifically, different machine learning methods, such as support vector machines (SVM), neural networks, and gradient boosting machines, along with different deep learning methods, are widely used for this application [
2,
5]. These methods establish a fault isolation scheme by classifying given data to distinguish between different possible faults.
Several research publications cover the fault diagnosis of satellite ACS using SVM, among other data-driven approaches [
6,
7,
8,
9]. The SVM is a supervised learning method with reasonable flexibility and can adapt to any application. As each fault scenario can be considered as a class, the SVM can be used for fault diagnosis. In [
6], a multi-classifier model is formed based on the Dempster–Shafer theory and SVM, while nonlinear principal component analysis (NPCA) is adopted to reduce the feature size. In [
8], SVM and neural networks are used to build a model for the satellite power supply system’s health monitoring. In [
7], the combination of random forest (RF), partial least square, SVM, and Naïve Bayes is used to form a framework for detecting and isolating faults. In [
9], telemetry data is used as input to extract the features, and principal component analysis (PCA) is used for feature reduction, which is followed by an optimized SVM model using the particle swarm optimization (PSO) method adopted for FDI.
Neural networks (NN) and deep learning methods are also employed for satellite ACS FDI [
10,
11,
12,
13]. In [
10], Prony analysis is used for feature extraction, and a feed-forward NN is developed for anomaly classification. In [
12], first, a model is established to find the characteristics that express the faults using a deep neural network. Next, the fault-to-noise ratio and characteristics differences are amplified using a sliding window. Then, the proposed method is used for fault identification of a satellite ACS. A feed-forward wavelet-based NN is adopted to form an adaptive observer for fault detection. Adopting a feed-forward wavelet-based neural network with a single hidden layer, the proposed method can be applied to nonlinear systems [
13]. In [
14], Chebyshev Neural Network and genetic algorithm are used to isolate CMG faults using satellite attitude rate data. However, the fault injection in that study does not accommodate in-phase faults, meaning that the faults occur out-of-phase or non-concurrently. That can be a limitation considering that multiple CMGs can become faulty simultaneously. In [
15], the authors propose a new third-order nonlinear dynamics for double gimbal control moment gyros (DGCMGs) affected by friction and coupling torques, unmodeled dynamics, or parameter uncertainties that does not directly address the fault isolation and identification challenge and focuses on the dynamics and control of the CMGs under uncertain circumstances.
Various other machine learning approaches such as minimum error minimax probability machine [
16], gradient boosting machines (GBM) [
17], and kernel principal component analysis [
18] are used for fault detection and isolation in aerospace applications.
While several articles exist on ACS fault isolation, most focus on systems that only have one active fault [
14]. The proposed models cannot handle cases with multiple in-phase (concurrent) faults, while these cases are likely to occur during a real-life satellite operation. When there is more than one fault present simultaneously, the effect of each fault on the overall system and other subsystem units makes the isolation task more challenging. The only work that has evaluated the multiple in-phase faults [
19] reported a maximum accuracy of 66.6%, which is not sufficient for real applications. Thus, there is a need for a specific approach to handle this problem while achieving reasonable accuracy of higher than 90%.
In this work, a new data-driven scheme is developed for fault isolation of multiple in-phase faults on a CMG assembly used in ACS to control a three-axis stabilized satellite in orbit. The proposed method can handle multiple in-phase faults in satellite CMGs to address the shortcomings mentioned above in the literature. Specifically, the fault isolation of multiple concurrent faults with high accuracy. The initial results of this work have been published in [
20]. However, the accuracy reported in [
20] was low for real-life applications. This paper contains the complete work that has solved the accuracy issue and includes additional insights into the different aspects of the problem, including a comprehensive sensitivity analysis. The challenges faced in addressing this problem include (1) the multiple faults that are active simultaneously, (2) the randomness of the faults inception, duration, and severity, and (3) the fact that the satellite is fully controlled so the effect of faults can be compensated for by the controller and leave the fault isolation scheme blind to the underlying conditions. It is also important to note that (4) the proposed data-driven approach is using satellite level measurements (satellite orientation and angular velocities) to isolate a fault at the actuator level.
The remaining of this paper is organized as follows: In
Section 2, the problem at hand is defined. In
Section 3, the proposed fault isolation scheme is introduced and described.
Section 4 is devoted to the algorithm complexity analysis of the methods used in this paper. In
Section 5, a case study is presented to assess the proposed method’s performance. Results are presented and discussed in
Section 6. Finally,
Section 7 concludes the paper with final remarks and recommendations for future work.
2. Problem Definition
In general, any nonlinear dynamical system can be modeled in state-space as:
where
is the state vector,
is the control input,
is the system parameter,
is the measurement, and
are the additive process noise for states and parameters, respectively.
is the additive measurement noise,
is the time step of the process, and measurement models are represented by
and
, respectively.
Assuming that any change in the physical parameters of the satellite is accompanied by a change in one of the parameters of the system [
21], a fault isolation problem can be expressed as:
where
is a vector demonstrating the nominal parameter values,
is a vector representing the parameter values in the presence of a fault, and
is the number of possible scenarios for faults that can be considered for the satellite. Equation (2) is a demonstration of a multi-parameter model and can be split into
single parameter models as [
21]:
Equation (3) expresses a classification problem with classes for which a data-driven approach can be used to find a solution. Then, the data-driven method is set to predict the class of the current system state, considering the potential cases. This can be done once a fault is detected through each fault model shown in (3), where the model captures the system parameter and its severity through . The assumptions made in this work are as follows:
The induced faults are in phase. Each data instance has assigned fault inception and duration times, which are the same for all CMG units that are faulty.
The assigned fault severity for each instance is from 0 to 1 to cover all possible fault severities.
All state measurements are available.
There is no source of noise nor missing values in the raw input data.
This work aims to design and develop a data-driven fault isolation scheme that can use the system outputs and predict the presence of any possible fault as well as isolate the fault location under the assumptions mentioned above.
3. Proposed Fault Isolation Scheme
A data-driven fault isolation method is introduced that comprises an optimized machine learning model for isolating multiple in-phase faults of the satellite CMG. First, the features are calculated using the CMG data, and then, feature reduction is made through the PCA. Next, the chosen features are fed to the machine learning model as inputs for the training and testing steps. For improving the performance, the machine learning model is tuned by finding the optimal values of its parameters. Finally, the optimized machine learning model is used for performance evaluation in a case study for isolating multiple in-phase faults of a CMG assembly on a three-axis stabilized satellite in orbit.
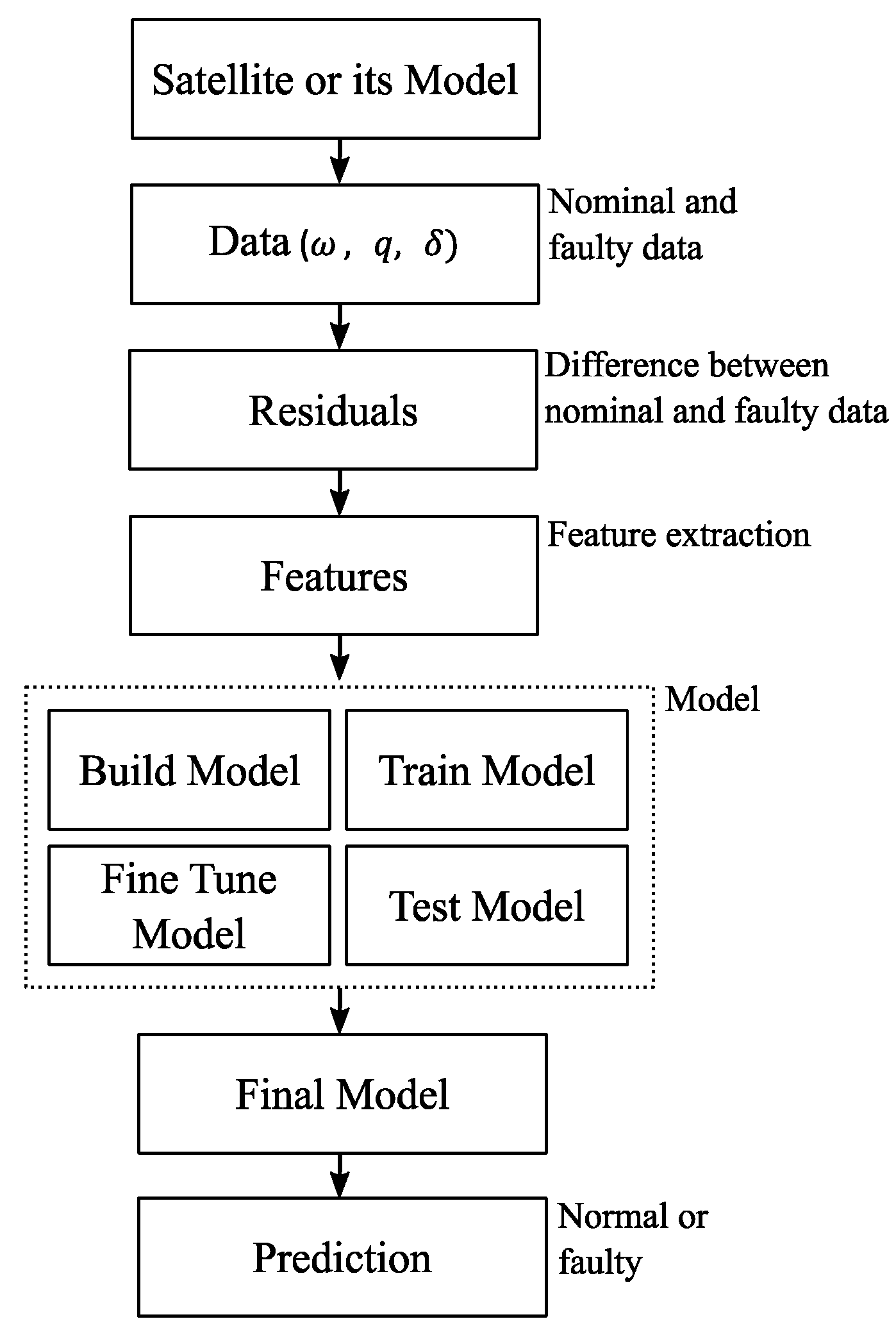
Figure 1 shows the flow diagram of the proposed fault isolation scheme. As can be seen in
Figure 1, the data can be obtained from either a model of the system or the actual physical system. Once data are collected, residuals are generated as the difference between the healthy and faulty unit measurements. Next, essential features are extracted from the residuals that capture the essence of the data for fault isolation. Once features are extracted, model training and tuning start. Once the model is trained, tuned, and tested, the final model is used to evaluate the performance of the proposed scheme in isolating faults in various scenarios. Further details of the proposed scheme are described in
Section 3.1,
Section 3.2,
Section 3.3 and
Section 3.4.
3.1. Data Acquisition
The raw data are acquired from a satellite telemetry system or a satellite mathematical model. In this study, a high-fidelity satellite model with four CMG units is used to generate the required data described in
Section 5. The raw data comprise satellite attitude quaternions, angular speeds, and the CMGs gimbal angles. The data are stored in a time-series format, with each set representing one of the fault scenarios shown in
Table 1. There is a total of 16 scenarios. Scenario 0 represents the system without any fault. Scenarios 1 to 15 represent the system with one, two, three, or four faulty units.
3.2. Data Preprocessing
3.2.1. Residual Calculation
The raw data are used to calculate the residuals. Residuals represent the difference between the system outputs in a nominal and faulty condition. The residuals can be calculated using:
where
represents the system measurable states/outputs for faulty model
,
denotes the desired fault scenario,
is the system states/outputs for a healthy model, and
is the measurement time step.
3.2.2. Feature Extraction
The features are extracted from the residual time series. Feature selection/reduction methods are used to reduce the extracted features while looking for the most representative features. There are various methods for feature extraction/reduction/selection that are described in
Section 5.6. Then, the chosen feature set is split into training and testing subsets that are fed into the machine learning model.
3.3. Machine Learning Model Selection
The machine learning model is developed to be used for the classification of data. There are a variety of methods suitable for machine learning that are described in
Section 5.7. Fault scenarios are used as labels, and as each instance of the input feature sets belongs to a specific fault scenario, the developed machine learning model aims to predict the true label for every instance of the input feature set. This is achieved by training the model with the available feature sets with the known label and then testing and tuning the model.
3.4. Training, Testing, and Tuning the Model
The training portion of the feature sets is used to train the machine learning model. Then, the model is tested by the test portion of the feature sets, and finally, the optimum values for the model hyperparameters are obtained through an optimization process to avoid over- or under-fitting.
4. Algorithm Complexity
Table 2 shows the time complexity for the machine learning models used in this work. In this table,
is the number of training samples,
is the feature numbers,
, demonstrates support vector numbers,
is the number of trees,
is the maximum depth of trees,
is the number of epoches, and
is the number of neurons of layer
.
Complexity analysis of neural networks is not straightforward, while [
22,
23] provide some insights into this analysis. The SVM algorithms include solving the constrained quadratic equation that is equivalent to the calculation of the inversion of an
size square matrix, which has the complexity of
In [
24], an extended time complexity analysis is done for different steps of implementing an SVM classifier. The time complexity of training with a gradient boosting machine is
and prediction for a new sample takes
[
25]. Assuming trees are free to grow to maximum height
, training time complexity for random forest is
), and prediction of a new sample takes
[
26].












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}