
Forecasting PM2.5 Concentration Using a Single-Dense Layer BiLSTM Method

 , ,
, , 
Abstract
:1. Introduction
- To get reliable data, we employed hardware architecture based on edge computing to meet compatibility with the IIoT system.
- Using PM2.5 forecasting as a case study, we demonstrate that our Single-Dense Layer BiLSTM model can accurately forecast PM2.5 concentration.
- Our contribution centered on developing a system that provides computationally efficient, potent, and stable performance with a small number of parameters.
- Our findings show that compared with the LSTM, CNN-LSTM, and Transformer methods, the Single-Dense Layer BiLSTM achieves the lowest error.
2. System Overview
3. Methodology
3.1. Data Preprocessing
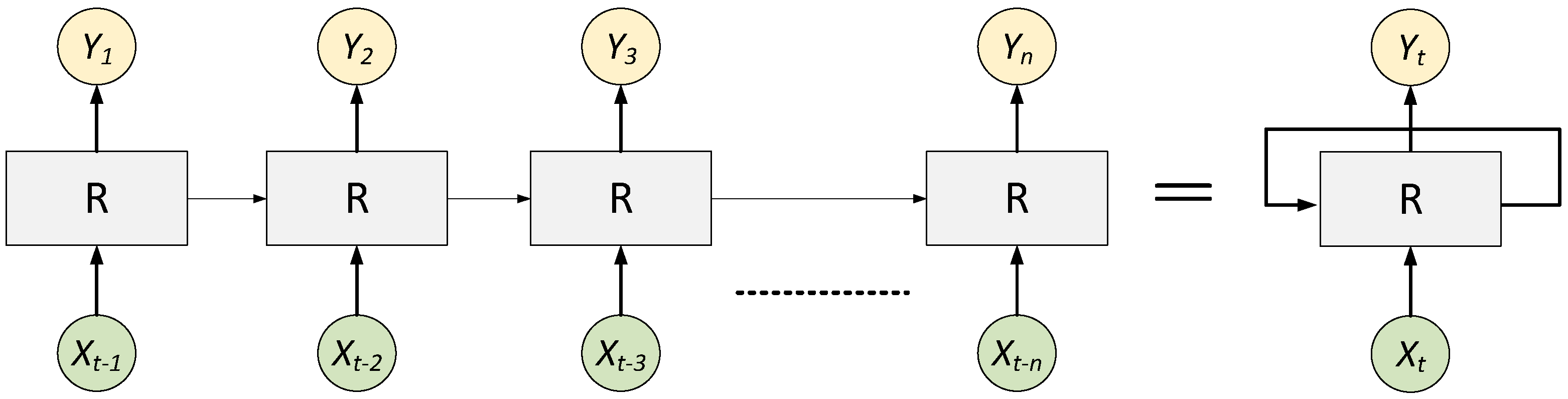
3.2. RNN Model
3.3. LSTM Model
3.4. CNN-LSTM Model
3.5. Transformer Model
3.6. Proposed Model Architecture
3.7. Optimizer
4. Experiment and Results
4.1. Experiment with Hyperparameters Setting
4.2. Performance Criteria
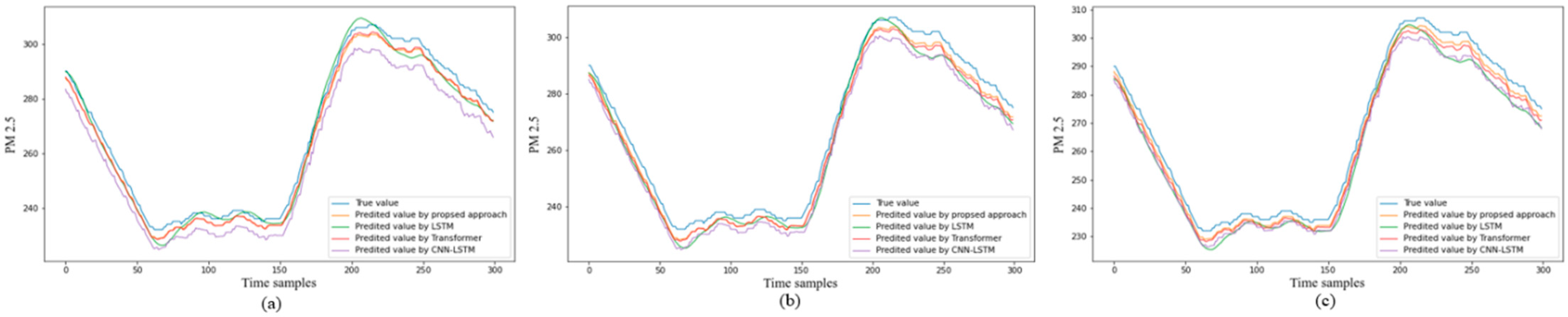
4.3. Results and Comparison
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ADAM | Adaptive Momentum Estimation |
| ANN | Artificial Neural Network |
| BiLSTM | Bidirectional Long Short-Term Memory |
| CNN-LSTM | Convolutional Neural Network—Long Short-Term Memory |
| CPS | Cyber-Physical System |
| DL | Deep Learning |
| IIoT | Industrial Internet of Things |
| IoE | Internet of Everything |
| KDD | Knowledge Discovery in Database |
| LOCF | Last Observation Carried Forward |
| LSTM | Long Short-Term Memory |
| MAE | Mean Absolute Error |
| MAPE | Mean Absolute Percentage Error |
| ML | Machine Learning |
| MSE | Mean Square Error |
| NLP | Natural Language Processing |
| NOCB | Next Observation Carried Backward |
| PLC | Programmable Logic Controller |
| PM | Particulate Matter |
| PM0.5 | Particulate Matter of 0.5 µm |
| PM1.0 | Particulate Matter of 1.0 µm |
| PM2.5 | Particulate Matter of 2.5 µm |
| PM5 | Particulate Matter of 5 µm |
| PM10 | Particulate Matter of 10 µm |
| RDBMS | Relational Database Management System |
| RMSE | Root Mean Square Error |
| RNN | Recurrent Neural Network |
| SGD | Stochastic Gradient Descent |
References
- Yao, X.; Zhou, J.; Lin, Y.; Li, Y.; Yu, H.; Liu, Y. Smart Manufacturing Based on Cyber-Physical Systems and Beyond. J. Intell. Manuf. 2019, 30, 2805–2817. [Google Scholar] [CrossRef] [Green Version]
- Dafflon, B.; Moalla, N.; Ouzrout, Y. The Challenges, Approaches, and Used Techniques of CPS for Manufacturing in Industry 4.0: A Literature Review. Int. J. Adv. Manuf. Technol. 2021, 113, 2395–2412. [Google Scholar] [CrossRef]
- Agency, E.P. Particulate Matter (PM) Pollution. Available online: https://www.epa.gov/air-trends/particulate-matter-pm25-trends (accessed on 22 April 2021).
- Kim, C.; Chen, S.; Zhou, J.; Cao, J.; Pui, D.Y.H. Measurements of Outgassing From PM 2.5 Collected Collected in Xi’an, China Through Soft X-Ray-Radiolysis. IEEE Trans. Semicond. Manuf. 2019, 32, 259–266. [Google Scholar] [CrossRef]
- Semiconductor & Microelectronics. Available online: https://www.gore.com/products/industries/semiconductor-microelectronics (accessed on 22 April 2021).
- National Research Council. Industrial Environmental Performance Metrics: Challenges and Opportunities; The National Academies Press: Washington, DC, USA, 1999; ISBN 978-0-30906-242-8. [Google Scholar]
- Athira, V.; Geetha, P.; Vinayakumar, R.; Soman, K.P. DeepAirNet: Applying Recurrent Networks for Air Quality Prediction. Procedia Comput. Sci. 2018, 132, 1394–1403. [Google Scholar] [CrossRef]
- Chen, Y.C.; Lei, T.C.; Yao, S.; Wang, H.P. PM2.5 Prediction Model Based on Combinational Hammerstein Recurrent Neural Networks. Mathematics 2020, 8, 2178. [Google Scholar] [CrossRef]
- Xayasouk, T.; Lee, H.M.; Lee, G. Air Pollution Prediction Using Long Short-Term Memory (LSTM) and Deep Autoencoder (DAE) Models. Sustainability 2020, 12, 2570. [Google Scholar] [CrossRef] [Green Version]
- Li, T.; Hua, M.; Wu, X.U. A Hybrid CNN-LSTM Model for Forecasting Particulate Matter (PM2.5). IEEE Access 2020, 8, 26933–26940. [Google Scholar] [CrossRef]
- Wu, N.; Green, B.; Ben, X.; O’Banion, S. Deep Transformer Models for Time Series Forecasting: The Influenza Prevalence Case. arXiv 2020, arXiv:2001.08317. [Google Scholar]
- González, I.; Calderón, A.J.; Barragán, A.J.; Andújar, J.M. Integration of Sensors, Controllers and Instruments Using a Novel OPC Architecture. Sensors 2017, 17, 1512. [Google Scholar] [CrossRef] [Green Version]
- Xiong, J.; Bu, X.; Huang, Y.; Shi, J.; He, W. Safety Verification of IEC 61131-3 Structured Text Programs. IEEE Trans. Ind. Inform. 2021, 17, 2632–2640. [Google Scholar] [CrossRef]
- Molina-Coronado, B.; Mori, U.; Mendiburu, A.; Miguel-Alonso, J. Survey of Network Intrusion Detection Methods from the Perspective of the Knowledge Discovery in Databases Process. IEEE Trans. Netw. Serv. Manag. 2020, 17, 2451–2479. [Google Scholar] [CrossRef]
- Cao, K.; Liu, Y.; Meng, G.; Sun, Q. An Overview on Edge Computing Research. IEEE Access 2020, 8, 85714–85728. [Google Scholar] [CrossRef]
- Shivali, J.B.G. Knowledge Discovery in Data-Mining. Int. J. Eng. Res. Technol. 2015, 3, 1–5. [Google Scholar]
- Eyada, M.M.; Saber, W.; El Genidy, M.M.; Amer, F. Performance Evaluation of IoT Data Management Using MongoDB Versus MySQL Databases in Different Cloud Environments. IEEE Access 2020, 8, 110656–110668. [Google Scholar] [CrossRef]
- Prihatno, A.T. Artificial Intelligence Platform Based for Smart Factory. In Proceedings of the Korea Artificial Intelligence Conference, Pyeongchang, Korea, 16–18 December 2020. [Google Scholar] [CrossRef]
- Mendez, K.M.; Pritchard, L.; Reinke, S.N.; Broadhurst, D.I. Toward Collaborative Open Data Science in Metabolomics Using Jupyter Notebooks and Cloud Computing. Metabolomics 2019, 15, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Morais, B.P. De Conversational AI: Automated Visualization of Complex Analytic Answers from Bots; Faculdade de Engenharia da Universidade do Porto: Porto, Portugal, 2018. [Google Scholar]
- Nguyen, V.-S.; Im, N.; Lee, S. The Interpolation Method for the Missing AIS Data of Ship. J. Navig. Port Res. 2015, 39, 377–384. [Google Scholar] [CrossRef] [Green Version]
- Hassani, H.; Kalantari, M.; Ghodsi, Z. Evaluating the Performance of Multiple Imputation Methods for Handling Missing Values in Time Series Data: A Study Focused on East Africa, Soil-Carbonate-Stable Isotope Data. Stats 2019, 2, 457–467. [Google Scholar] [CrossRef] [Green Version]
- Zhen, H.; Niu, D.; Wang, K.; Shi, Y.; Ji, Z.; Xu, X. Photovoltaic Power Forecasting Based on GA Improved Bi-LSTM in Microgrid without Meteorological Information. Energy 2021, 231, 120908. [Google Scholar] [CrossRef]
- Donald, F. Specht A General Regression Neural Network. IEEE Trans. Neural Netw. 1991, 2, 568–576. [Google Scholar]
- Meng, Y.; Jin, Y.; Yin, J. Modeling Activity-Dependent Plasticity in BCM Spiking Neural Networks with Application to Human Behavior Recognition. IEEE Trans. Neural Netw. 2011, 22, 1952–1966. [Google Scholar] [CrossRef]
- Singh, A. Anomaly Detection for Temporal Data Using Long Short-Term Memory (LSTM); Independent Thesis Advanced Level; School of Information and Communication Technology (ICT), KTH: Stockholm, Sweden, 2017. [Google Scholar]
- Zhao, B.; Li, X.; Lu, X. CAM-RNN: Co-Attention Model Based RNN for Video Captioning. IEEE Trans. Image Process. 2019, 28, 5552–5565. [Google Scholar] [CrossRef]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning Long-Term Dependencies with Gradient Descent Is Difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Ergen, T.; Kozat, S.S. Online Training of LSTM Networks in Distributed Systems for Variable Length Data Sequences. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 5159–5165. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zheng, C.; Wang, S.; Liu, Y.; Liu, C.; Xie, W.; Fang, C.; Liu, S. A Novel Equivalent Model of Active Distribution Networks Based on LSTM. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 2611–2624. [Google Scholar] [CrossRef] [PubMed]
- Qin, D.; Yu, J.; Zou, G.; Yong, R.; Zhao, Q.; Zhang, B. A Novel Combined Prediction Scheme Based on CNN and LSTM for Urban PM2.5 Concentration. IEEE Access 2019, 7, 20050–20059. [Google Scholar] [CrossRef]
- Acquarelli, J.; Marchiori, E.; Buydens, L.M.C.; Tran, T.; van Laarhoven, T. Spectral-Spatial Classification of Hyperspectral Images: Three Tricks and a New Learning Setting. Remote Sens. 2018, 10, 1156. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Process. Syst. 2017, 2017, 5999–6009. [Google Scholar]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in Vision: A Survey. arXiv 2021, arXiv:2101.01169. [Google Scholar]
- Yates, A.; Nogueira, R.; Lin, J. Pretrained Transformers for Text Ranking: BERT and Beyond. In Proceedings of the WSDM 2021—14th ACM International Conference on Web Search and Data Mining 2021, Jerusalem, Israel, 8–12 March 2021; pp. 1154–1156. [Google Scholar] [CrossRef]
- Xie, J.; Chen, B.; Gu, X.; Liang, F.; Xu, X. Self-Attention-Based BiLSTM Model for Short Text Fine-Grained Sentiment Classification. IEEE Access 2019, 7, 180558–180570. [Google Scholar] [CrossRef]
- Ronran, C.; Lee, S.; Jang, H.J. Delayed Combination of Feature Embedding in Bidirectional Lstm Crf for Ner. Appl. Sci. 2020, 10, 7557. [Google Scholar] [CrossRef]
- Rampurawala, M. Classification with TensorFlow and Dense Neural Networks. Available online: https://heartbeat.fritz.ai/classification-with-tensorflow-and-dense-neural-networks-8299327a818a (accessed on 1 June 2021).
- Kingma, D.P.; Ba, J.L. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Yu, X. Deep Learning Architecture for PM2.5 and Visibility Predictions; Delft University of Technology: Delft, The Netherlands, 2018. [Google Scholar]
- Ruder, S. An Overview of Gradient Descent Optimization Algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Hameed, Z.; Garcia-Zapirain, B. Sentiment Classification Using a Single-Layered BiLSTM Model. IEEE Access 2020, 8, 73992–74001. [Google Scholar] [CrossRef]
- Yang, H.; Pan, Z.; Tao, Q. Robust and Adaptive Online Time Series Prediction with Long Short-Term Memory. Comput. Intell. Neurosci. 2017, 2017, 9478952. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, A.; Liption, Z.C.; Li, M.; Smola, A.J. Dive into Deep Learning. Available online: https://d2l.ai/chapter_optimization/adam.html (accessed on 30 April 2021).
- Guo, C.; Liu, G.; Chen, C.H. Air Pollution Concentration Forecast Method Based on the Deep Ensemble Neural Network. Wirel. Commun. Mob. Comput. 2020, 2020, 8854649. [Google Scholar] [CrossRef]
- Jonathan, B.; Rahim, Z.; Barzani, A.; Oktavega, W. Evaluation of Mean Absolute Error in Collaborative Filtering for Sparsity Users and Items on Female Daily Network. In Proceedings of the 1st International Conference on Informatics, Multimedia, Cyber and Information System, ICIMCIS 2019, Jakarta, Indonesia, 24–25 October 2019; pp. 41–44. [Google Scholar] [CrossRef]
- Zhang, Y.F.; Thorburn, P.J.; Xiang, W.; Fitch, P. SSIM—A Deep Learning Approach for Recovering Missing Time Series Sensor Data. IEEE Internet Things J. 2019, 6, 6618–6628. [Google Scholar] [CrossRef]
- Ait-Amir, B.; Pougnet, P.; El Hami, A. Meta-model development. In Embedded Mechatronic Systems 2; El Hami, A., Pougnet, P.B.T., Eds.; ISTE: London, UK, 2020; pp. 157–187. ISBN 978-1-78548-190-1. [Google Scholar]
- Swamidass, P.M. MAPE (Mean Absolute Percentage Error) MEAN ABSOLUTE PERCENTAGE ERROR (MAPE) BT—Encyclopedia of Production and Manufacturing Management; Swamidass, P.M., Ed.; Springer: Boston, MA, USA, 2000; p. 462. ISBN 978-1-4020-0612-8. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | LSTM | CNN-LSTM | Transformer | Single-Dense Layer BiLSTM |
|---|---|---|---|---|
| Model nodes | 2 LSTM nodes | 64 LSTM nodes | N/A | 64 BiLSTM nodes |
| Epoch | 20, 30, 40 | 20, 30, 40 | 20, 30, 40 | 20, 30, 40 |
| Batch size | 16 | 16 | 16 | 16 |
| Interpolate method | linear | N/A | N/A | linear |
| Train data | 64% dataset | 64% dataset | 64% dataset | 64% dataset |
| Validation data | 16% dataset | 16% dataset | 16% dataset | 16% dataset |
| Test data | 20% dataset | 20% dataset | 20% dataset | 20% dataset |
| Optimizer | ADAM | SGD | ADAM | ADAM |
| Learning rate | 0.001 | 0.0001 | 0.001 | 0.001 |
| Dense layer | N/A | 64 | N/A | 1 |
| No. of Epoch | Model | MSE | RMSE | MAE | MAPE | Training Time (Minutes) |
|---|---|---|---|---|---|---|
| 20 | LSTM | 10.81 | 3.29 | 2.87 | 0.027 | 2.7 |
| CNN-LSTM | 16.4 | 4.20 | 4.06 | 0.034 | 5.2 | |
| Transformer | 8.80 | 2.96 | 2.86 | 0.017 | 7.4 | |
| Proposed approach | 9.89 | 3.14 | 3.04 | 0.019 | 6.7 | |
| 30 | LSTM | 13.7 | 3.66 | 4.16 | 0.015 | 4.1 |
| CNN-LSTM | 29.82 | 5.46 | 5.14 | 0.022 | 7.2 | |
| Transformer | 14.60 | 3.82 | 3.62 | 0.014 | 10.5 | |
| Proposed approach | 9.18 | 3.02 | 2.89 | 0.012 | 9.4 | |
| 40 | LSTM | 21.8 | 5.63 | 5.20 | 0.019 | 4.9 |
| CNN-LSTM | 33.05 | 5.74 | 5.50 | 0.020 | 9.1 | |
| Transformer | 16.94 | 4.11 | 3.75 | 0.014 | 12.3 | |
| Proposed approach | 7.46 | 2.73 | 2.65 | 0.009 | 11.7 |
| No. of Epoch | Model | MSE | RMSE | MAE | MAPE | Training Time (Minutes) |
|---|---|---|---|---|---|---|
| 20 | LSTM | 10.56 | 3.24 | 2.91 | 0.011 | 2.6 |
| CNN-LSTM | 25.02 | 5.01 | 4.57 | 0.020 | 5.0 | |
| Transformer | 16.13 | 4.01 | 3.77 | 0.013 | 7.2 | |
| Proposed approach | 7.75 | 2.78 | 2.36 | 0.009 | 6.6 | |
| 30 | LSTM | 11.07 | 3.32 | 2.67 | 0.017 | 4.0 |
| CNN-LSTM | 31.77 | 5.63 | 5.11 | 0.028 | 7.1 | |
| Transformer | 10.35 | 3.21 | 2.91 | 0.014 | 10.2 | |
| Proposed approach | 9.14 | 3.02 | 2.85 | 0.015 | 9.2 | |
| 40 | LSTM | 14.16 | 3.76 | 3.19 | 0.012 | 4.8 |
| CNN-LSTM | 29.56 | 5.43 | 5.16 | 0.019 | 9.2 | |
| Transformer | 13.76 | 3.70 | 3.37 | 0.015 | 12.4 | |
| Proposed approach | 13.60 | 3.68 | 3.52 | 0.013 | 11.6 |
| No. of Epoch | Model | MSE | RMSE | MAE | MAPE | Training Time (Minutes) |
|---|---|---|---|---|---|---|
| 20 | LSTM | 20.82 | 4.56 | 3.95 | 0.014 | 2.5 |
| CNN-LSTM | 26.44 | 5.14 | 5.03 | 0.031 | 4.8 | |
| Transformer | 31.40 | 5.60 | 5.52 | 0.20 | 7.1 | |
| Proposed approach | 9.19 | 3.03 | 3.98 | 0.013 | 6.4 | |
| 30 | LSTM | 21.49 | 4.63 | 3.97 | 0.023 | 3.9 |
| CNN-LSTM | 36.41 | 6.03 | 5.58 | 0.035 | 6.9 | |
| Transformer | 27.82 | 5.27 | 4.79 | 0.025 | 10.0 | |
| Proposed approach | 8.92 | 2.98 | 2.90 | 0.011 | 8.9 | |
| 40 | LSTM | 43.33 | 6.58 | 6.07 | 0.027 | 4.7 |
| CNN-LSTM | 48.81 | 6.97 | 6.23 | 0.029 | 9.0 | |
| Transformer | 22.33 | 4.72 | 4.67 | 0.017 | 12.1 | |
| Proposed approach | 8.18 | 2.86 | 2.47 | 0.014 | 11.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Prihatno, A.T.; Nurcahyanto, H.; Ahmed, M.F.; Rahman, M.H.; Alam, M.M.; Jang, Y.M. Forecasting PM2.5 Concentration Using a Single-Dense Layer BiLSTM Method. Electronics 2021, 10, 1808. https://doi.org/10.3390/electronics10151808
Prihatno AT, Nurcahyanto H, Ahmed MF, Rahman MH, Alam MM, Jang YM. Forecasting PM2.5 Concentration Using a Single-Dense Layer BiLSTM Method. Electronics. 2021; 10(15):1808. https://doi.org/10.3390/electronics10151808
Chicago/Turabian StylePrihatno, Aji Teguh, Himawan Nurcahyanto, Md. Faisal Ahmed, Md. Habibur Rahman, Md. Morshed Alam, and Yeong Min Jang. 2021. "Forecasting PM2.5 Concentration Using a Single-Dense Layer BiLSTM Method" Electronics 10, no. 15: 1808. https://doi.org/10.3390/electronics10151808
APA StylePrihatno, A. T., Nurcahyanto, H., Ahmed, M. F., Rahman, M. H., Alam, M. M., & Jang, Y. M. (2021). Forecasting PM2.5 Concentration Using a Single-Dense Layer BiLSTM Method. Electronics, 10(15), 1808. https://doi.org/10.3390/electronics10151808