
Low-Power Ultra-Small Edge AI Accelerators for Image Recognition with Convolution Neural Networks: Analysis and Future Directions


Abstract
:1. Introduction
- Edge AI can improve the user experience when AI technology and data processing are near customers more and more.
- Edge AI can reduce the data transition latency, which implies real-time processing ability.
- Edge AI can run under no internet coverage to offer privacy through local processing.
- Edge AI pursues the compact size and manages power consumption to meet the mobility and limited power source.
2. System Platform for AI Algorithms
3. Edge AI Accelerators
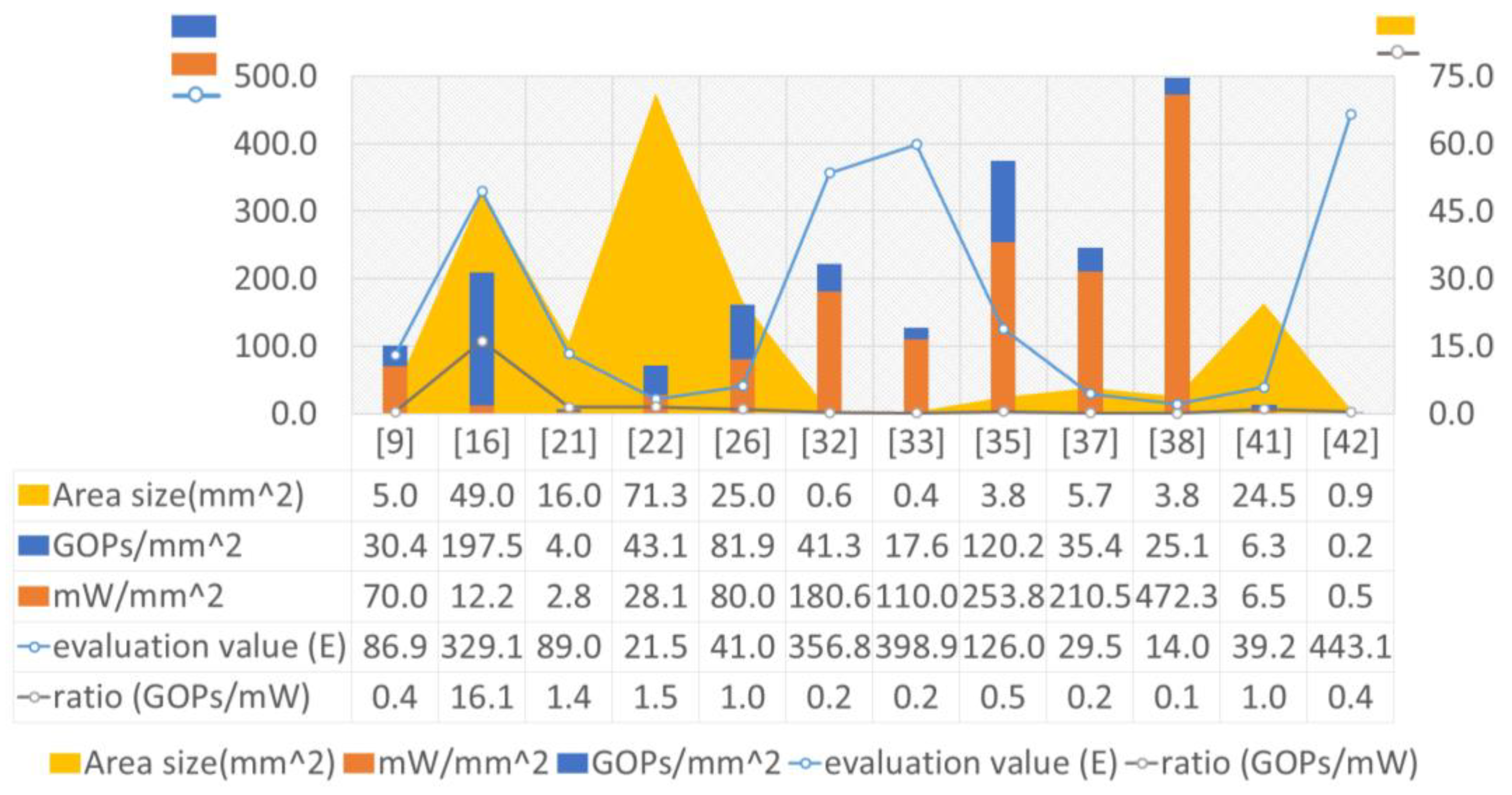
3.1. Specification Normalization and Evaluation
3.2. Prior Art Edge AI Accelerators
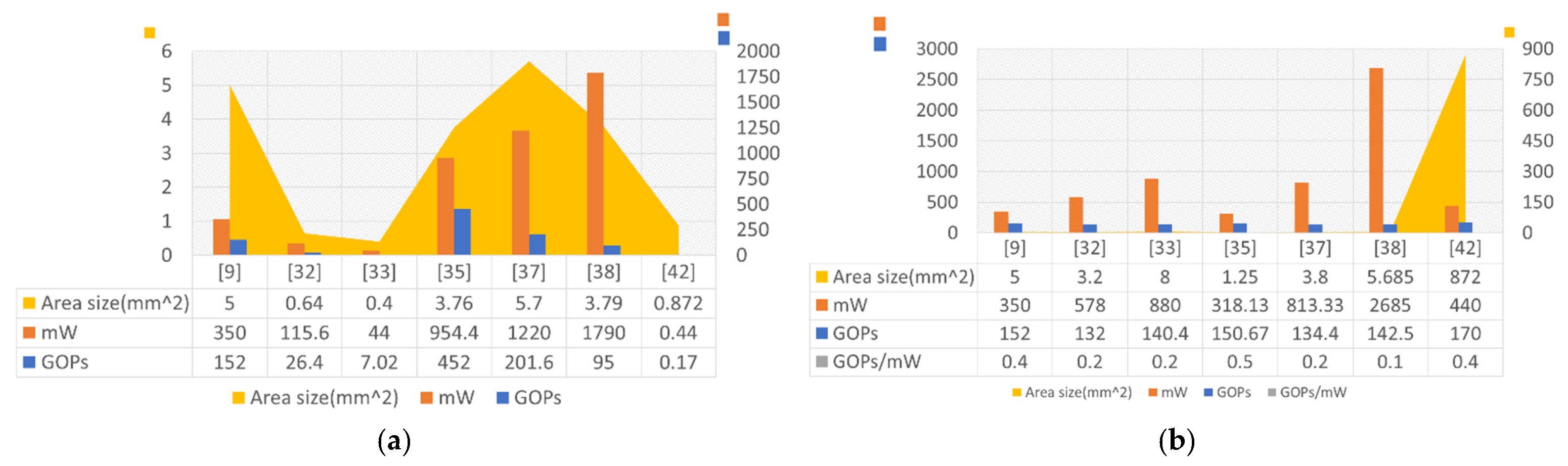
3.3. Coarse-Grained Cell Array Accelerators
3.4. Implementation Technology
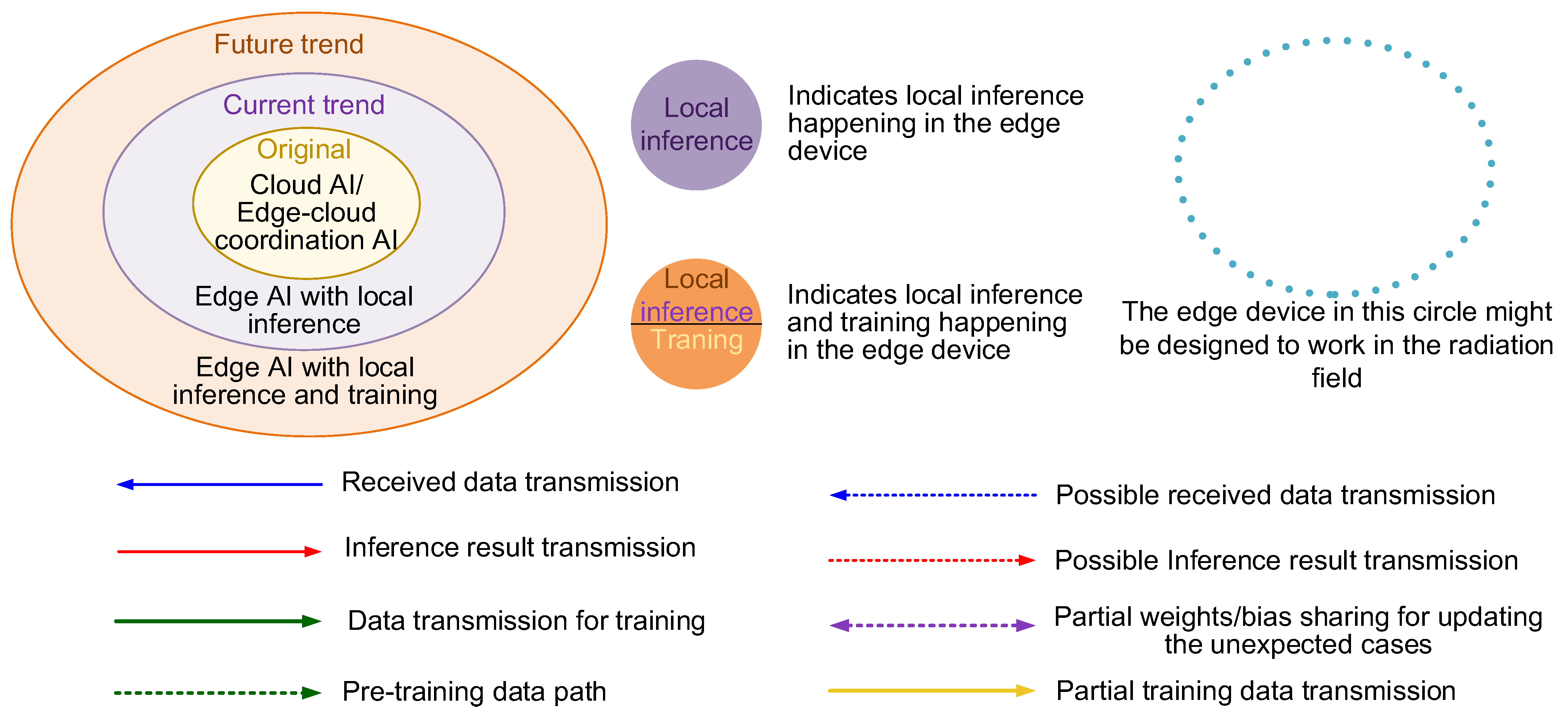
4. Architecture Analysis and Design Direction
5. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hoang, L.-H.; Hanif, M.A.; Shafique, M. FT-ClipAct: Resilience Analysis of Deep Neural Networks and Improving their Fault Tolerance using Clipped Activation. In Proceedings of the 2020 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 9–13 March 2020. [Google Scholar]
- Zhang, J.J.; Gu, T.; Basu, K.; Garg, S. Analyzing and mitigating the impact of permanent faults on a systolic array based neural network accelerator. In Proceedings of the 2018 IEEE 36th VLSI Test Symposium (VTS), San Francisco, CA, USA, 22–25 April 2018. [Google Scholar]
- Hanif, M.A.; Shafique, M. Dependable Deep Learning: Towards Cost-Efficient Resilience of Deep Neural Network Accelerators against Soft Errors and Permanent Faults. In Proceedings of the 2020 IEEE 26th International Symposium on On-Line Testing and Robust System Design (IOLTS), Napoli, Italy, 13–15 July 2020. [Google Scholar]
- Yasoubi, A.; Hojabr, R.; Modarressi, M. Power-Efficient Accelerator Design for Neural Networks Using Computation Reuse. IEEE Comput. Archit. Lett. 2017, 16, 72–75. [Google Scholar]
- Venkataramani, S.; Ranjan, A.; Roy, K.; Raghunathan, A. AxNN: Energy-efficient neuromorphic systems using approximate computing. In Proceedings of the 2014 IEEE/ACM International Symposium on Low Power Electronics and Design (ISLPED), La Jolla, CA, USA, 11–13 August 2014. [Google Scholar]
- You, Z.; Wei, S.; Wu, H.; Deng, N.; Chang, M.-F.; Chen, A.; Chen, Y.; Cheng, K.-T.T.; Hu, X.S.; Liu, Y.; et al. White Paper on AI Chip Technologies; Tsinghua University and Beijing Innovation Centre for Future Chips: Beijing, China, 2008. [Google Scholar]
- Montaqim, A. Top 25 AI Chip Companies: A Macro Step Change Inferred from the Micro Scale. Robotics and Automation News 2019. Available online: https://roboticsandautomationnews.com/2019/05/24/top-25-ai-chip-companies-a-macro-step-change-on-the-micro-scale/22704/ (accessed on 4 May 2021).
- Simonyan, K.; Zisserman, A. Very deep convolution networks for large-scale image recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Du, L.; Du, Y.; Li, Y.; Su, J.; Kua, Y.-C.; Liu, C.-C.; Chang, M.C.F. A Reconfigurable Streaming Deep Convolutional Neural Network Accelerator for Internet of Things. IEEE Trans. Circuits Syst. 2018, 65, 198–208. [Google Scholar] [CrossRef] [Green Version]
- Clark, C.; Logan, R. Power Budgets for Mission Success; Clyde Space Ltd.: Glasgow, UK, 2011; Available online: http://mstl.atl.calpoly.edu/~workshop/archive/2011/Spring/Day%203/1610%20-%20Clark%20-%20Power%20Budgets%20for%20CubeSat%20Mission%20Success.pdf (accessed on 4 May 2021).
- Yazdanbakhsh, A.; Park, J.; Sharma, H.; Lotfi-Kamran, P.; Esmaeilzadeh, H. Neural acceleration for GPU throughput processors. In Proceedings of the 48th International Symposium on Microarchitecture, Waikiki, HI, USA, 5–9 December 2015. [Google Scholar]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.-R.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; et al. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, New York, NY, USA, 3–7 November 2014. [Google Scholar]
- Vasudevan, A.; Anderson, A.; Gregg, D. Parallel multi channel convolution using general matrix multiplication. In Proceedings of the 2017 IEEE 28th International Conference on Application-Specific Systems, Architectures and Processors (ASAP), Seattle, WA, USA, 10 July 2017. [Google Scholar]
- Guo, K.; Sui, L.; Qiu, J.; Yu, J.; Wang, J.; Yao, S.; Han, S.; Wang, Y.; Yang, H. Angel-eye: A complete design flow for mapping CNN onto embedded FPGA. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2018, 37, 35–47. [Google Scholar] [CrossRef]
- Gyrfalcon Technology Inc. (GTI). Lightspeeur® 2801S. Available online: https://www.gyrfalcontech.ai/solutions/2801s/ (accessed on 4 May 2021).
- Farahini, N.; Li, S.; Tajammul, M.A.; Shami, M.A.; Chen, G.; Hemani, A.; Ye, W. 39.9 GOPs/watt multi-mode CGRA accelerator for a multi-standard basestation. In Proceedings of the 2013 IEEE International Symposium on Circuits and Systems (ISCAS), Beijing, China, 19–23 May 2013. [Google Scholar]
- Abdelfattah, A.; Anzt, H.; Boman, E.G.; Carson, E.; Cojean, T.; Dongarra, J.; Gates, M.; Grützmacher, T.; Higham, N.J.; Li, S.; et al. A survey of numerical methods utilizing mixed precision arithmetic. arXiv 2020, arXiv:2007.06674. [Google Scholar]
- Chen, Y.-H.; Krishna, T.; Emer, J.S.; Sze, V. Eyeriss: An energy-efficient reconfigurable accelerator for deep convolutional neural networks. IEEE J. Solid State Circuits 2017, 52, 262–263. [Google Scholar] [CrossRef] [Green Version]
- Zhang, C.; Li, P.; Sun, G.; Guan, Y.; Xiao, B.; Cong, J. Optimizing FPGA-based accelerator design for deep convolution neural networks. In Proceedings of the 2015 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2015. [Google Scholar]
- Sim, J.; Park, J.-S.; Kim, M.; Bae, D.; Choi, Y.; Kim, L.-S. A 1.42TOPS/W deep convolution neural network recognition processor for intelligent IoE systems. In Proceedings of the 2016 IEEE International Solid-State Circuits Conference, San Francisco, CA, USA, 31 January–4 February 2016. [Google Scholar]
- Oh, N. Intel Announces Movidius Myriad X VPU, Featuring ‘Neural Compute Engine’, AnandTech 2017. Available online: https://www.anandtech.com/show/11771/intel-announces-movidius-myriad-x-vpu (accessed on 4 May 2021).
- NVIDIA. JETSON NANO. Available online: https://developer.nvidia.com/embedded/develop/hardware (accessed on 4 May 2021).
- Wikipedia, T. Available online: https://en.wikipedia.org/wiki/Tegra#cite_note-103 (accessed on 4 May 2021).
- Toybrick. TB-RK1808M0. Available online: http://t.rock-chips.com/portal.php?mod=view&aid=33 (accessed on 5 May 2021).
- Coral. USB Accelerator. Available online: https://coral.ai/products/accelerator/ (accessed on 5 May 2021).
- DIY MAKER. Google Coral edge TPU. Available online: https://s.fanpiece.com/SmVAxcY (accessed on 5 May 2021).
- Texas Instruments. AM5729 Sitara Processor. Available online: https://www.ti.com/product/AM5729 (accessed on 5 May 2021).
- Shafiee, A.; Nag, A.; Muralimanohar, N.; Balasubramonian, R.; Paul Strachan, J.; Hu, M.; Williams, R.S.; Srikumar, V. ISAAC: A convolutional neural network accelerator with in-situ analog arithmetic in crossbars. In Proceedings of the 2016 ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), Seoul, Korea, 18–22 June 2016. [Google Scholar]
- Arensman, R. Despite HPs Delays, Memristors Are Now Available. Electronics 360. 2016. Available online: https://electronics360.globalspec.com/article/6389/despite-hp-s-delays-memristors-are-now-available (accessed on 4 May 2021).
- Podobas, A.; Sano, K.; Matsuoka, S. A Survey on Coarse-Grained Reconfigurable Architectures from a Performance Perspective. IEEE Access 2020, 8, 146719–146743. [Google Scholar] [CrossRef]
- Karunaratne, M.; Mohite, A.K.; Mitra, T.; Peh, L.-S. HyCUBE: A CGRA with Reconfigurable Single-cycle Multi-hop Interconnect. In Proceedings of the 2017 54th ACM/EDAC/IEEE Design Automation Conference (DAC), Austin, TX, USA, 18–22 June 2017. [Google Scholar]
- Lopes, J.D.; de Sousa, J.T. Versat, a Minimal Coarse-Grain Reconfigurable Array. In Proceedings of the International Conference on Vector and Parallel Processing, Porto, Portugal, 28–30 June 2016. [Google Scholar]
- Prasad, R.; Das, S.; Martin, K.; Tagliavini, G.; Coussy, P.; Benini, L.; Rossi, D. TRANSPIRE: An energy-efficient TRANSprecision floatingpoint Programmable archItectuRE. In Proceedings of the 2020 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 9–13 March 2020. [Google Scholar]
- Nowatzki, T.; Gangadhar, V.; Ardalani, N.; Sankaralingam, K. Stream-Dataflow Acceleration. In Proceedings of the 2017 ACM/IEEE 44th Annual International Symposium on Computer Architecture (ISCA), Toronto, ON, Canada, 24–28 June 2017. [Google Scholar]
- Cong, J.; Huang, H.; Ma, C.; Xiao, B.; Zhou, P. A Fully Pipelined and Dynamically Composable Architecture of CGRA. In Proceedings of the 2014 IEEE 22nd Annual International Symposium on Field-Programmable Custom Computing Machines, Boston, MA, USA, 11–13 May 2014. [Google Scholar]
- Mahale, G.; Mahale, H.; Nandy, S.K.; Narayan, R. REFRESH: REDEFINE for Face Recognition Using SURE Homogeneous Cores. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 3602–3616. [Google Scholar] [CrossRef]
- Fan, X.; Li, H.; Cao, W.; Wang, L. DT-CGRA: Dual-Track Coarse Grained Reconfigurable Architecture for Stream Applications. In Proceedings of the 2016 26th International Conference on Field Programmable Logic and Applications (FPL), Lausanne, Switzerland, 29 August–2 September 2016. [Google Scholar]
- Fan, X.; Wu, D.; Cao, W.; Luk, W.; Wang, L. Stream Processing Dual-Track CGRA for Object Inference. IEEE Trans. VLSI Syst. 2018, 26, 1098–1111. [Google Scholar] [CrossRef]
- Lopes, J.; Sousa, D.; Ferreira, J.C. Evaluation of CGRA architecture for real-time processing of biological signals on wearable devices. In Proceedings of the 2017 International Conference on ReConFigurable Computing and FPGAs (ReConFig), Cancun, Mexico, 4–6 December 2017. [Google Scholar]
- Chen, Y.-H.; Yang, T.-J.; Emer, J.; Sze, V. Eyeriss v2: A Flexible Accelerator for Emerging Deep Neural Networks on Mobile Devices. IEEE Trans. Emerg. Sel. Topics Circuits Syst. 2019, 9, 292–308. [Google Scholar] [CrossRef] [Green Version]
- Das, S.; Martin, K.J.; Coussy, P.; Rossi, D. A Heterogeneous Cluster with Reconfigurable Accelerator for Energy Efficient Near-Sensor Data Analytics. In Proceedings of the 2018 IEEE International Symposium on Circuits and Systems (ISCAS), Florence, Italy, 27–30 May 2018. [Google Scholar]
- Nikolskiy, V.; Stegailov, V. Floating-point performance of ARM cores and their efficiency in classical molecular dynamics. J. Phys. Conf. Ser. 2016, 681, 012049. [Google Scholar] [CrossRef]
- Kim, J.Y.; Kim, M.; Lee, S.; Oh, J.; Kim, K.; Yoo, H. A 201.4 GOPS 496 mW Real-Time Multi-Object Recognition Processor with Bio-Inspired Neural Perception Engine. IEEE J. Solid-State Circuits 2010, 45, 32–45. [Google Scholar] [CrossRef]
- Gautschi, M.; Schiavone, P.D.; Traber, A.; Loi, I.; Pullini, A.; Rossi, D.; Flamand, E.; Gürkaynak, F.K.; Benini, L. Near-Threshold RISC-V Core with DSP Extensions for Scalable IoT Endpoint Devices. IEEE Trans. Very Large Scale Integr. Syst. 2017, 25, 2700–2713. [Google Scholar] [CrossRef] [Green Version]
- Shawahna, A.; Sait, S.M.; El-Maleh, A. FPGA-Based Accelerators of Deep Learning Networks for Learning and Classification: A Review. IEEE Access 2019, 7, 7823–7859. [Google Scholar] [CrossRef]
- Lavagno, L.; Sangiovanni-Vincentelli, A. System-level design models and implementation techniques. In Proceedings of the 1998 International Conference on Application of Concurrency to System Design, Fukushima, Japan, 23–26 March 1998. [Google Scholar]
- Takouna, I.; Dawoud, W.; Meinel, C. Accurate Mutlicore Processor Power Models for Power-Aware Resource Management. In Proceedings of the 2011 IEEE Ninth International Conference on Dependable, Autonomic and Secure Computing, Sydney, NSW, Australia, 12–14 December 2011. [Google Scholar]
- Wikipedia. Tesla Autopilot. Available online: https://en.wikipedia.org/wiki/Tesla_Autopilot#Hardware_3 (accessed on 6 August 2021).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pros and Cons | Processor | ||
|---|---|---|---|
| CPU | GPU | Edge AI accelerator | |
| Advantage |
|
|
|
| Disadvantage |
|
|
|
| Application platform |
|
|
|
| Three Key Features and the Evaluation Value | Edge AI Accelerators | ||
|---|---|---|---|
| Kneron 2018 [9] | Eyeriss (MIT) 2016 [19] | 1.42TOPS/W 2016 [21] | |
| Computation ability | 152 GOPs | 84 GOPs | 64 GOPs |
| Precision | 16-bit Fixed | 16-bit Fixed | 16-bit Fixed [9] |
| Power consumption | 350 mW | 278 mW | 45 mW |
| Size | TSMC 65 nm RF 1P6M Core area 2 mm × 2.5 mm | TSMC 65 nm LP 1P9M Chip size 4.0 mm × 4.0 mm Core area 3.5 mm × 3.5 mm | TSMC 65 nm LP 1P8M Chip size 4.0 mm × 4.0 mm |
| Evaluation value E | 86.86 (core) | 18.88 24.66 (core) | 88.88 |
| Implementation | Implemented in TSMC 65 nm technology | Implemented in TSMC 65 nm technology | Implemented in TSMC 65 nm technology |
| Commercial product example |  Packaged in a USB stick |  Packaged on a PCIe interface card (no public sales channel found) | - |
| Three Key Features and the Evaluation Value | Edge AI Accelerators | |||
|---|---|---|---|---|
| Myriad x (Intel) 2017 [22] | NVIDIA Tegra X1 TM660M 2019 [23,24] | Rockchip RK1808 2018 [25] | Texas Instruments AM5729 2019 [28] | |
| Computation ability | 1 TFlops =3 TOPs | 472 GFlops =1.42 TOPs | 100 GFlops =300 GOPs | 120 GOP/s |
| Precision | 16-bit FP | 16-bit FP | 16-bit FP 300 GOPs@ INT16 | 16-bit Fixed |
| Power consumption | <2 Watt | 5–10 Watts (module-level) | ~3.3 W (module-level) | ≈6.5 W (module-level) |
| Size | 8.1 mm × 8.8 mm (package) | 28-nm 23 mm × 23 mm | 22 nm ≈13.9 mm × 13.9 mm | 28-nm 23 mm × 23 mm |
| Evaluation value E | 21.55 (package s) | 5.34 × 10−4 (module-level p) | 3.81 (module-level p) | 3.5 × 10−5 (module-level p) |
| Implementation | Implemented in TSMC 16 nm technology | Implemented as system on chip (probably TSMC 16 nm technology) | Implemented as system on chip (22 nm technology) | Implemented as system on chip (28 nm technology) |
| Commercialized product example |  Packaged in a USB stick |  Packaged on a PCIe interface card |  Packaged in a USB stick |  Packaged on a developing board |
| Three Key Features and the Evaluation Value | Edge AI Accelerators | ||
|---|---|---|---|
| GTI Lightspeeur SPR2801S 2019 [16] | Optimizing FPGA-based 2015 [20] | Google Edge TPU 2018 [26,27] | |
| Computation ability | 5.6 TFlops =9.45 TOPs | 61.62 GFlops =61.62 GOPS [20] | 4 TOPs =2 TOPs |
| Precision | Input activations: 9-bit FP Weights: 14-bit FP | 32-bit FP | INT8 |
| Power consumption | 600 mW 2.8 TOPs@300 mW | 18.61 Watt | 2 W (0.5 W/TOPs) |
| Size | 28 nm 7.0 × 7.0 mm | On Virtex7 VX485T | 5.0 mm × 5.0 mm |
| Evaluation value E | 329.14 | -- | 40.96 |
| Implementation | Implemented in TSMC 28 nm technology | Implemented on the VC707 board which has a Xilinx FPGA chip Virtex7 485t | Implemented in ASIC (undisclosed technology) |
| Commercialized product example |  Packaged in a USB stick | -- |  Packaged in a USB stick |
| Three Key Features and the Evaluation Value | Coarse-Grained Cell Array ACCELERATORS | |||
|---|---|---|---|---|
| ADRES 2017 [32] | VERSAT 2016 [33] | FPCA 2014 [36] | SURE Based REDEFINE 2016 [37] | |
| Computation ability | 4.4 GFlops =26.4 GOPs (A9) | 1.17 GFlops =7.02 GOPs (A9) | 9.1 GFlops =54.6 GOPs (A9) | 450 Faces/s ≈201.6 GOPs (Reference) |
| Precision | 32-bit FP (A9) | 32-bit Fixed | 32-bit FP (A9) | 32-bit Fixed |
| Power consumption | 115.6 mW | 44 mW | 12.6 mW | 1.22 W |
| Size | 0.64 mm2 | 0.4 mm2 | Xilinx Virtex6 XC6VLX240T | 5.7 mm2 |
| Evaluation value E | 356.84 | 398.86 | -- | 29.48 |
| Implementation | Implemented in TSMC 28 nm technology | Implemented in UMC 130 nm technology | Implemented in Xilinx Virtex-6 FPGA XC6VLX240T | Implemented in 65 nm technology |
| Three Key Features and the Evaluation Value | Coarse-Grained Cell Array Accelerators | ||
|---|---|---|---|
| TRANSPIRE 2020 [34] | DT-CGRA 2016 [38,39] | Heterogenous PULP 2018 [42] | |
| Computation ability | 136MOPs (binary8 benchmark) | 95 GOPs | 170 MOPs |
| Precision | 8/16-bit Fixed | 16-bit Fixed | 16-bits Fixed |
| Power consumption | 0.57 mW | 1.79 W | 0.44 mW |
| Size | N/A | 3.79 mm2 | 0.872 mm2 |
| Evaluation value E | -- | 14 | 443.08 |
| Implementation | Implemented in 28 nm technology | Implemented in SMIC 55 nm process | Implemented in STMicroelectronics 28 nm technology |
| Three Key Features and the Evaluation Value | Coarse-Grained Cell Array Accelerators | ||
|---|---|---|---|
| SOFTBRAIN 2017 [35] | Lopes et al. 2017 [40] | Eyeriss v2 2016 [41] | |
| Computation ability | 452 GOPs (test under 16-bit mode) | 1.03 GOPs =1.545 GOPs | 153.6 GOPs |
| Precision | 64-bit Fixed (DianNao) | 24-bit Fixed | Weight/iacts: 8-bit Fixed psum: 20-bit Fixed |
| Power consumption | 954.4 mW | 1.996 mW | 160 mW |
| Size | 3.76 mm2 | 0.45 mm2 (not including the buffer, memory, and control systems) | 24.5 mm2 (2 times of v1 [19]) |
| Evaluation value E | 125.96 | 1720.1 | 39.18 |
| Implementation | Implemented in 55 nm technology | Implemented in 90 nm technology | Implemented in a 65 nm technology. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, W.; Adetomi, A.; Arslan, T. Low-Power Ultra-Small Edge AI Accelerators for Image Recognition with Convolution Neural Networks: Analysis and Future Directions. Electronics 2021, 10, 2048. https://doi.org/10.3390/electronics10172048
Lin W, Adetomi A, Arslan T. Low-Power Ultra-Small Edge AI Accelerators for Image Recognition with Convolution Neural Networks: Analysis and Future Directions. Electronics. 2021; 10(17):2048. https://doi.org/10.3390/electronics10172048
Chicago/Turabian StyleLin, Weison, Adewale Adetomi, and Tughrul Arslan. 2021. "Low-Power Ultra-Small Edge AI Accelerators for Image Recognition with Convolution Neural Networks: Analysis and Future Directions" Electronics 10, no. 17: 2048. https://doi.org/10.3390/electronics10172048
APA StyleLin, W., Adetomi, A., & Arslan, T. (2021). Low-Power Ultra-Small Edge AI Accelerators for Image Recognition with Convolution Neural Networks: Analysis and Future Directions. Electronics, 10(17), 2048. https://doi.org/10.3390/electronics10172048