Abstract
In this work, a virtual sensor for concentration monitoring is presented. The sensor is based on wavenet models and uses daily mean concentration and meteorological variables (wind speed and rainfall) as input. The methodology has been applied to the reconstruction of levels measured from 14 monitoring stations in Lombardy region (Italy). This region, usually affected by high levels of , is a challenging benchmarking area for the implemented sensors. Neverthless, the performances are good with relatively low bias and high correlation.
1. Introduction
Exposure to high levels of particulate matter () is a big social problem [1] due to its impacts on human health, with effects including pulmonary and cardio-vascular diseases [2,3]. One of the main challenges in decision making related to control is that, usually, win–win solutions that also consider other pollutants, such as nitrogen oxides () and ozone (), are complex to identify and implement [4,5,6,7]. For this reason, having detailed information about the level of all of the significant air pollutants over a certain area is a key issue in decision-making processes. In this context, the use of integrated information coming from regional networks and novel/private networks supported by low-cost technology [8,9] has become more and more important, which has been mainly due to the fact that they can provide suitable information for chemical transport models (CTMs), allowing them to compute concentrations far away from the official monitoring network stations [10,11,12].
In principle, four main techniques for the measurement of are presented in literature [13]: (1) gravimetric analysis of pumped and filtered particles; (2) tapering element oscillating microbalance (TEOM); (3) beta-attenuation; (4) light scattering. The first three of these techniques are quite expensive, so their use is limited to regional authorities, private companies and research groups [13]. Light scattering, instead, is a relatively low-cost technique, but it is often affected by consistent biases [14].
The objective of this work is to evaluate the possibility of implementing a virtual sensor for daily mean concentration starting from the data measured by sensors detecting other pollutants and meteorological variables. In particular, the virtual sensors applied in this work are based on daily mean concentration and meteorological variables, such as wind speed, rainfall, relative humidity and temperature.
As indicated by the name, virtual sensors can be broadly described as a software that allows us to compute the value of a certain variable without direct measurement considering measurements that are physically/chemically related to the variable that should be reproduced [15]. They assume a key role when it is not possible to place a physical sensor due to any kind of limitations (e.g., unreachable position, high cost). There are two possible approaches to virtual sensor implementation:
- 1.
- Data-driven: in this approach, time series of input and output variables are collected from direct measurement and are used to compute a mathematical, approximated relationship between the measured variables’ and sensors’ output [16];
- 2.
- Deterministic: in this approach, the (eventually approximated) physical/chemical relationships among input and output variables are used to compute the unmeasured variable through the virtual sensor [17].
This work presents a data-driven approach based on wavenet models to implement a virtual sensor using and meteorological variables. All these variables are strictly related to the phenomena involved in the formation and accumulation of in atmosphere; their choice is due to the presence in the literature of low-cost sensors with performances that are adequate [18] enough to identify a virtual sensor, therefore allowing the definition of a low-cost measuring network. Wavenets are data-driven models resulting from the integration of wavelet theory and neural network models [19]. Their main applications are related to sound management/filtering [20], even if their nonlinear function approximation (and thus forecasting) properties have been applied with good results also in other fields such as energy systems [19,21]. These approximation properties make them suitable for environmental monitoring and forecasting applications, but still, there is no literature related to their application to reproduce or other air quality pollutants. Therefore, since artificial neural networks are widely used in this field [4,22,23], wavenets could also be useful for the definition of a virtual sensor. The paper is organized in two main parts, a methodological one (Section 2) where the basics of the artificial neural network, wavelet theory and wavenets are introduced and a second part presenting the evaluation of the results on a test case.
2. Materials and Methods
In this section, the theoretical framework used to derive a virtual air quality sensor based on wavenets [24] is presented.
2.1. Artificial Neural Networks
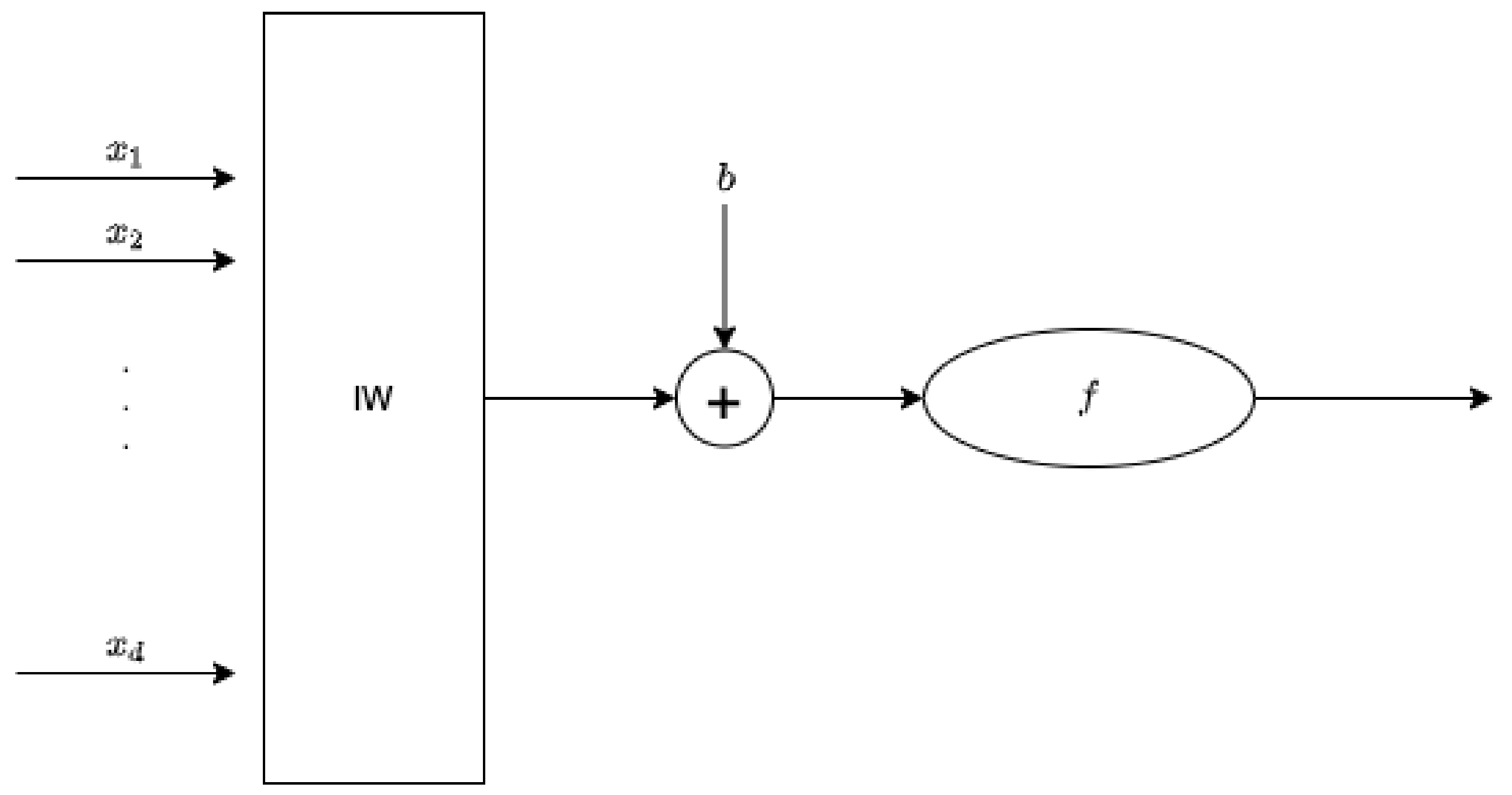
Artificial Neural Networks (ANNs) are functions approximating human brain behavior, considered as a network of smaller units, called neurons, representing the information processing unit (Figure 1).
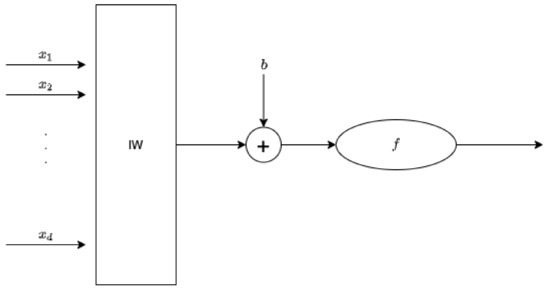
Figure 1.
Typical neuron model.
Each input of the network is multiplied by a corresponding weight , analogous to a synaptic force; then all the weighted inputs are added together, including also a bias b term in order to compute the activation level x of the neuron. The output signal is usually a nonlinear function of the activation level. Hence, the typical neuron model is represented as (1):
where d is the length of the input vector.
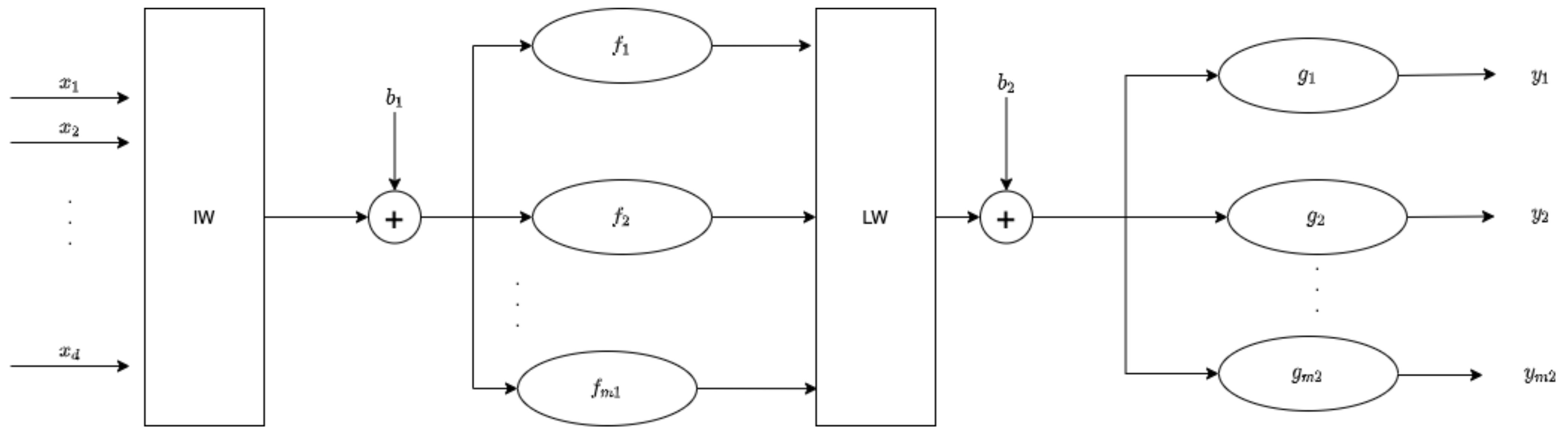
The approximation capacity of a single neuron is quite limited; to overcome this, they are collected in layers sharing the same input. The final structure of a neural network is obtained by connecting several layers, as in the case of the two-layer feedforward neural network in Figure 2.
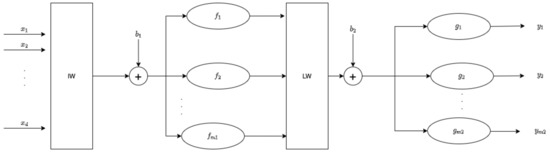
Figure 2.
Two-layer feedforward neural network structure.
In this case, the output can be computed as:
where is the output of the network, is its input vector, and are the activation functions of the hidden and output layers, respectively, and, finally, and are the lengths of the activation function output and the neural network output. The bias terms , and the weight matrices and are computed during the training phase. Even if the number of layers of an artificial neural network can be higher than 2, following the proof of the Cybenko approximation theorem, and in order to limit the complexity of the network, in real applications only a two layers neural network is used [25].
2.2. Wavelets and Wavenet Models
Wavelets are a family of orthonormal basis functions that can be used to perform transformations among spaces. Their use ranges from function approximation to audio compression [26,27,28]. The wavelet approximation theory is strictly related to multi-resolution analysis [26]. In this context, a function can be approximated using the so-called wavelet (mother) and scaling (father) functions, as:
where:
- are the scaling coefficients;
- are the details (wavelet) coefficient;
- is the selected scaling (father) function family;
- is the selected wavelet (mother) function family.
The computation of the scaling and wavelet coefficient is strongly connected to the selected wavelet family (considered as the couple wavelet/scaling functions). Up to now, a number of different functions has been considered and are currently used. More details about wavelet transformation can be found in [26,27,28].
Wavenets (wavelet networks) [24] can be considered as a one hidden layer network with wavelets as activation functions. In particular, the wavenet output for an input can be computed as:
where , is the scaling function, , is the wavelet function, is the row vector input of the wavenet, , , , , , and are the parameters to be computed during the training.
The comparison between Equations (2) and (4) shows that the wavenet can be considered as a neural network with the function:
as the activation function of the hidden layer.
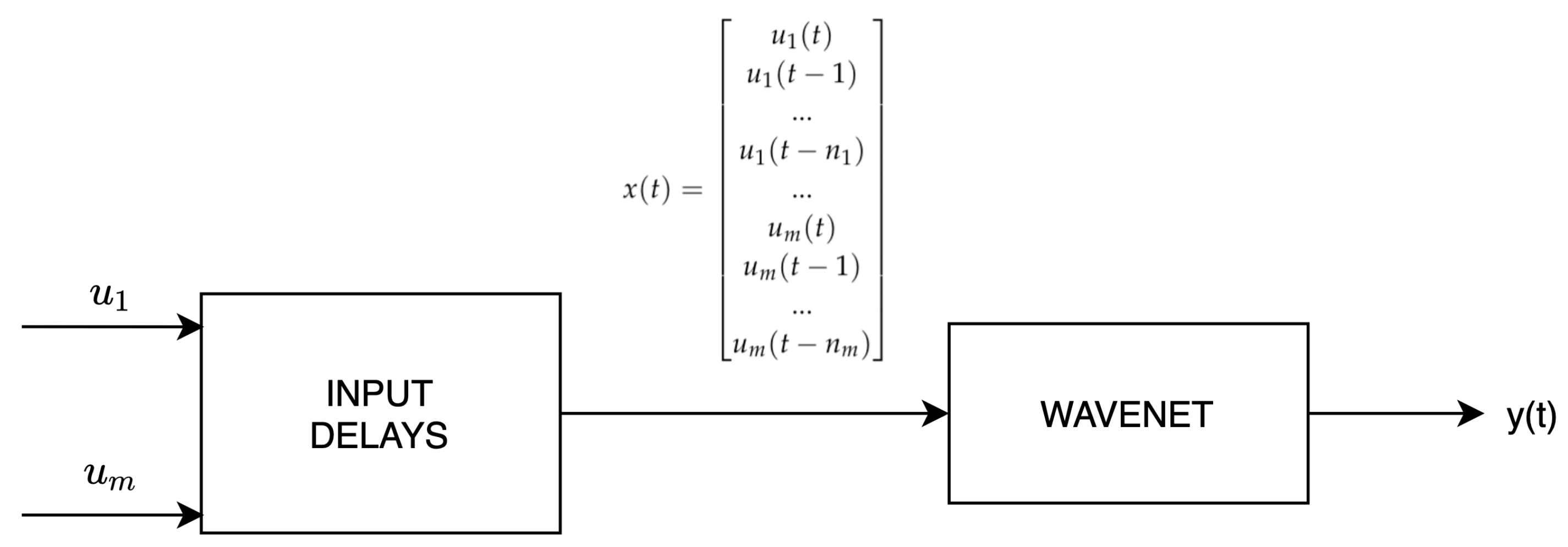
When the phenomena to model with the wavenet is dynamical, the wavenet is feeded by an input vector that is the output of a time delay phase:
where are the variables selected to compute the output of the overall system. In this work, since the formation, accumulation and removal are clearly dynamical processes, the system structure presented in Figure 3 is used.
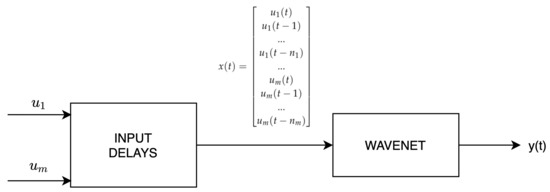
Figure 3.
Wavenet structure.
3. Results and Discussion
3.1. Case Study and Dataset Definition
The aim of this work is the definition of a virtual sensor to compute daily average concentrations starting from the measured data of daily average concentration and the measured values of two meteorological variables: average daily wind speed , total daily rainfall , average daily relative humidity and average daily temperature T. The selection of as the input variable is due to the fact that its levels are strongly related to ones, as they shared some emission drivers (i.e., road traffic, domestic heating) and chemical paths (i.e., formation of secondary inorganic aerosol starting from the ammonium nitrates). On the other hand, the selected meteorological variables can be related to general deposition or dispersion conditions (mainly rainfall and wind speed) or to the formation of secondary aerosol by condensation. Thus, the in Equation (4) is the daily concentration computed by the model, which is referred to as n from now on. Moreover, the input x of the wavenet function is time dependent, so , and it includes both concentrations and meteorological variables for the day t and the previous days, as in:
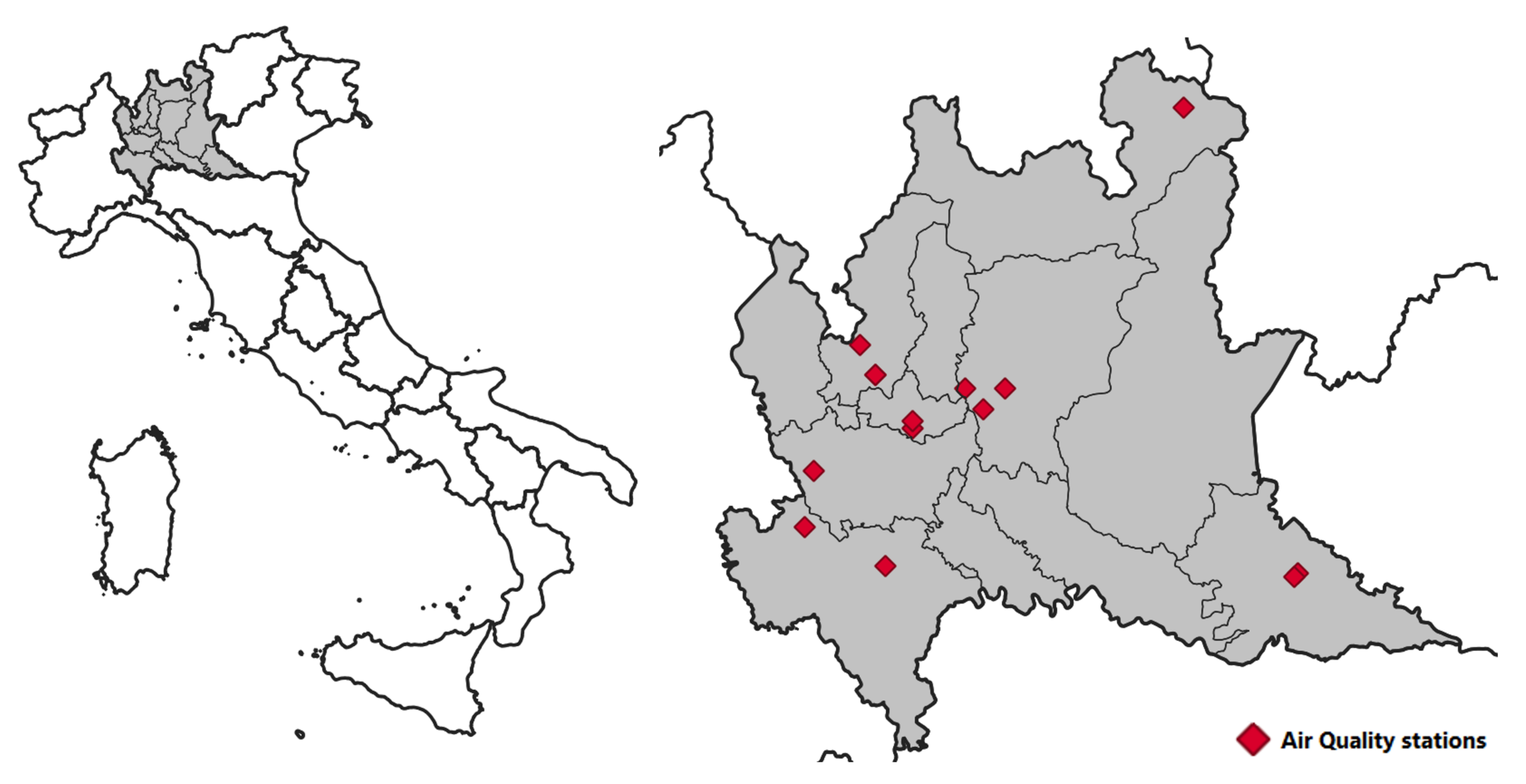
In order to test the presented methodology, a series of models has been trained and validated to reproduce the daily mean concentrations starting from different input measured by the Lombardy region monitoring network. The work has been tested using data measured by 14 monitoring stations belonging to the Lombardy region (Italy) monitoring network (Figure 4).
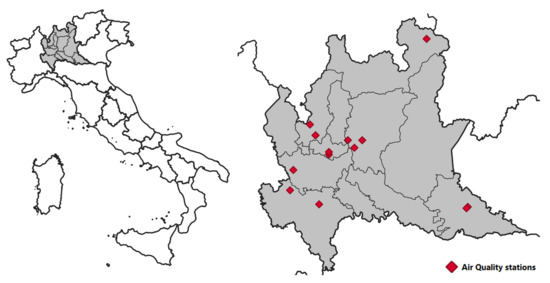
Figure 4.
Domain and measuring stations.
More in detail, the data from year 2019 have been used ( available raw data tuples). The performance evaluation for the different models has been performed using a leave-p-out approach with . Following this approach, 100 tests have been performed for each model configuration, with 10 stations being used for the identification, and the data for being randomly selected as stations queued in order to define the metastation used for the validation.
3.2. Configuration Tests
In order to evaluate the capability of the methodology presented in Section 2 to compute concentrations, all the possible configurations among the input variables have been considered, and the relative models trained.
In principle, the different configurations can be grouped into three categories:
- Configurations including only concentration as input;
- Configurations including only meteorological variables as input;
- Configurations including both concentrations and meteorological variables as input.
For each test, an analysis of the memory of the systems, i.e., an evaluation of the performances of varying , , , and , has been performed. On the basis of the knowledge of the phenomena related to the formation of in atmosphere, a maximum value of 5 days can be considered for these parameters. Each model has been evaluated on the basis of the following three different statistical indexes:
- Normalized Root Mean Squared Deviation:
- Root Mean Squared Error
- Correlation Coefficient
where and are, respectively, the t-th values of the model output and of the validation dataset, and and are their mean values. From the huge set of performed tests, only the best-performing ones are presented in this context, in particular for the combination of multiple input.
3.3. Validation Results
3.3.1. Models with as Input
This first class of models includes only daily mean concentrations as input. This is due to the fact that and concentrations are generated by several common emitting activities (i.e., road transport) and that the secondary inorganic fraction of is composed, in part, of nitrates, in particular ammonia nitrate, whose formation depends on the concentration in atmosphere. Table 1 highlights that the performances are quite good in terms of correlation, with values around 0.74, and acceptable in terms of root mean square error, with a normalised root mean standard deviation (allowing one to compare the root mean square error with respect to the overall variability of the output time series) around 0.1.

Table 1.
input configuration performances.
From these results, it is clear that an increase in the memory of the system does not lead to significant impacts on the performances and on the behavior of the model. The negligible increase in performances for the test with does not justify the increasing number of parameters. Table 2 shows the performances for the same configurations for the part of the time series where concentrations higher than have been measured. The table states that the model has strong difficulties in reproducing high concentrations, as highlighted by the strong decrease in statistical indexes.
Table 2.
input configuration performances for .
3.3.2. Models with Meteorological Variables as Input
The second class of models considers only the meteorological variables as input. These tests allow an assessment of the relative “importance” between meteorology and concentration for the computation of levels. Table 3 and Table 4 show poor performances, with the limited exception of the cases with temperature T as input. Thus, the performances suggest that the meteorological conditions alone are not enough to estimate concentrations, and, so, they may be at best used to increase the performances in addition to the concentrations.
Table 3.
Meteorological input configuration performances.
Table 4.
Meteorological input configuration performances for .
3.3.3. Models with and Meteorological Variables as Input
The last class of models considers both the meteorological variables and the daily mean concentration as input in order to evaluate if the joint use of these information sources leads to an increase in the performances. Table 5 presents the results with concentrations coupled to a meteorological variable at a certain time. The performances are in line with that of the models with only as an input. Moreover, the combined use of more than one meteorological variable did not lead to a consistent increase in performance (Table 6, Table 7 and Table 8). The only slight improvement can be seen for high concentrations when the temperature is used as input (Table 9, Table 10, Table 11 and Table 12), but also, in this case, the performances seem not to be good enough (correlation coefficient close to 0.52) in the preproduction of the peaks. These results suggest that, to reproduce mean levels in this domain, only the concentrations should used, thus relying on cheaper sensors. Nevertheless, a bond in the performances exists, which did not allow the reconstruction of peak concentrations.
Table 5.
and one meteorological variable input configuration performance.
Table 6.
and two meteorological variable input best configuration performances.
Table 7.
and three meteorological variable input configuration performances.
Table 8.
and four meteorological variable input configuration performances.
Table 9.
one meteorological variable input configuration performance for .
Table 10.
and two meteorological variable input best configuration performances for .
Table 11.
and three meteorological variable input configuration performances for .
Table 12.
and four meteorological variable input configuration performances for .
3.4. Comparison to State-of-the-Art Models
In this section, the comparison of the wavenet approach used in this work with two different state-of-the-art models is presented. The two models are a (1) K-nearest neighbors (KNN) and an (2) artificial neural network-based model, which are often used in this context to capture the dynamic of the [29]. The comparison (Table 13) shows how the performances of the best-identified wavenet are strongly better than that of the KNN model and very similar (slightly better for high orders) to that of the ANN ones. Moreover, it has to be stressed how the best model for the wavenet approach ensures these performances with limited complexity and with a limited number of variables (only concentration) with respect to the other approaches.
Table 13.
Best configuration performances.
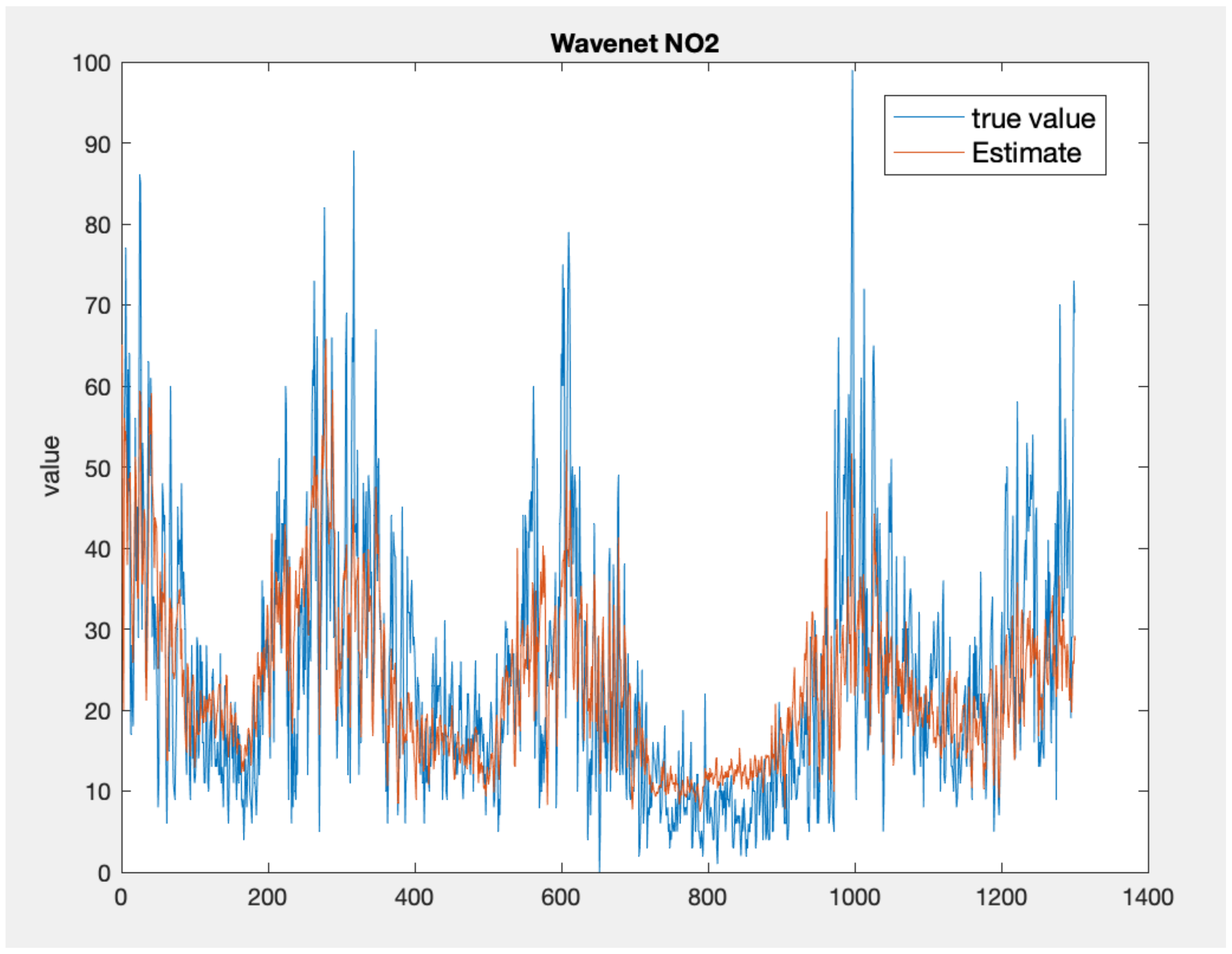
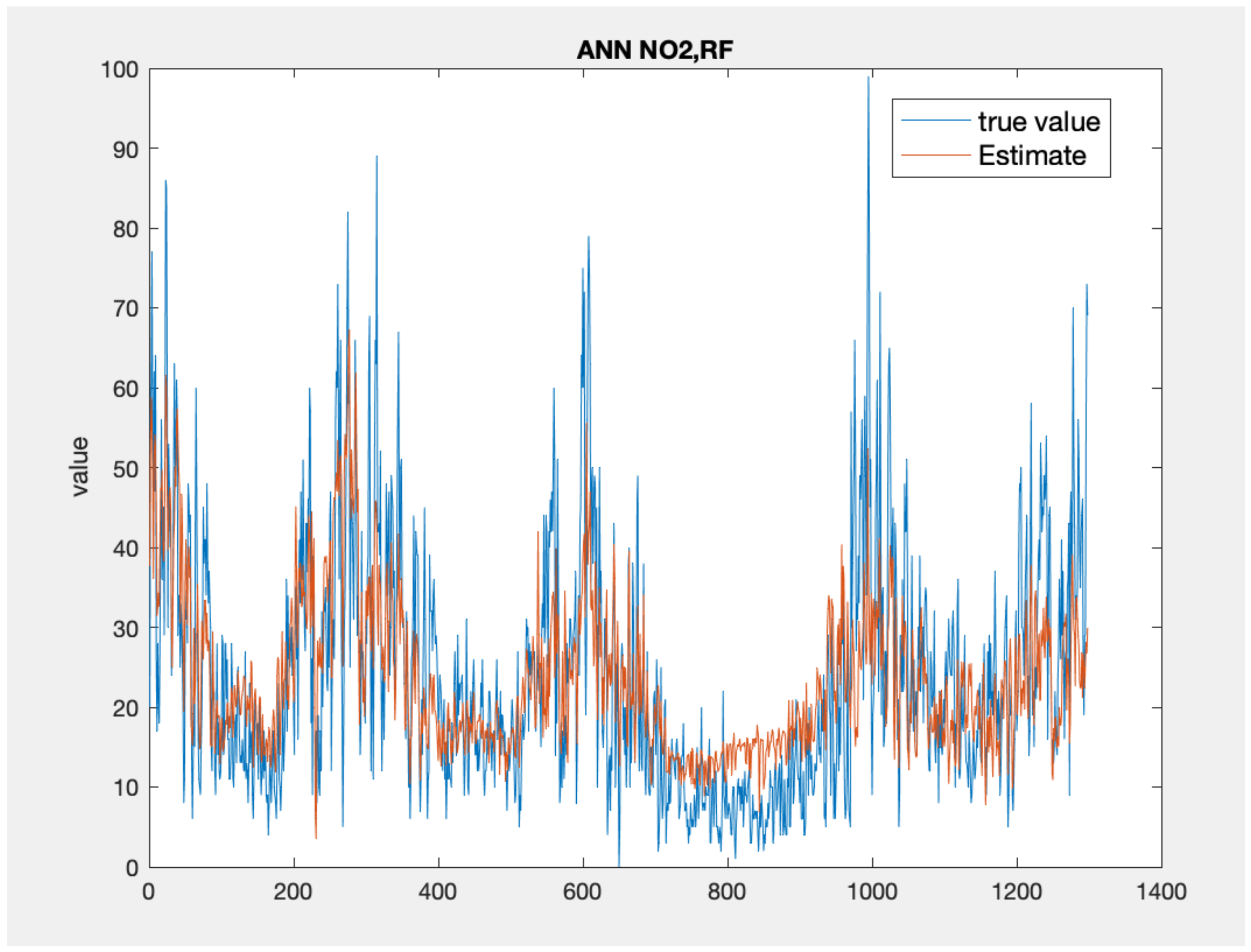
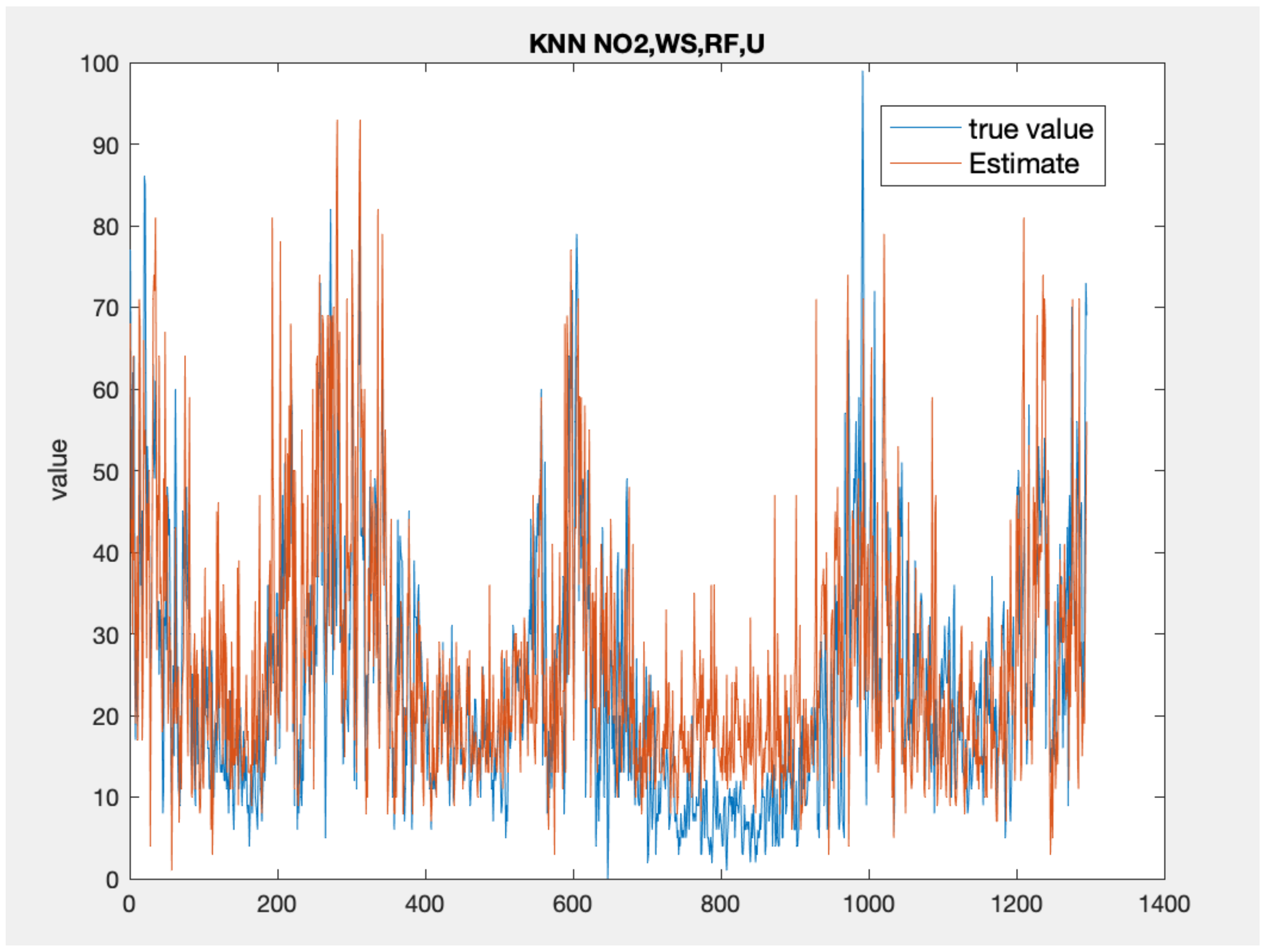
Figure 5, Figure 6 and Figure 7 present the time series plots for the best configuration of wavenet, artificial neural network and KNN models, respectively. As expected, the behaviour of the wavenet and ANN models is very similar, with the first models showing slightly better performances for the low value close to the sample n. 800. In general, the KNN model reproduces higher value but, as also stated by the lower values of correlation coefficient, the time series rarely follows the value and the gradient of the measured values.
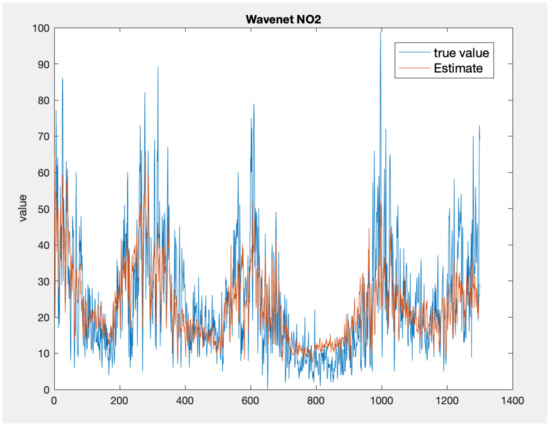
Figure 5.
Time series comparison between the measured values (blue) and the best wavenet model output (, red).
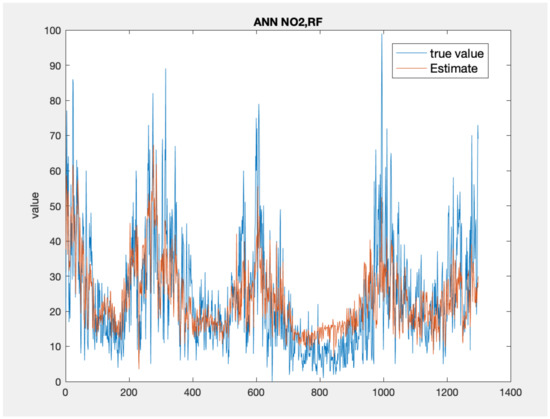
Figure 6.
Time series comparison between the measured values (blue) and the best neural network model output (, red).
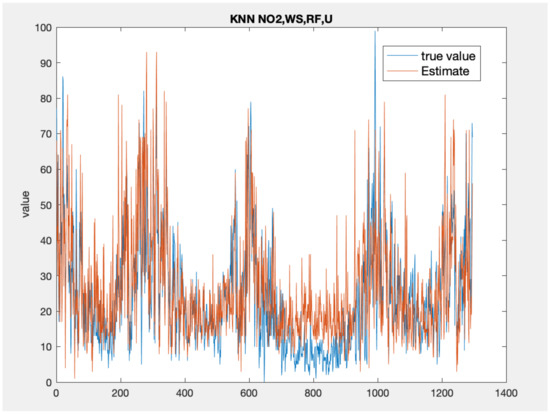
Figure 7.
Time series comparison between the measured values (blue) and the best KNN model output (, red).
4. Conclusions
In this work, a data-driven, wavenet-based virtual sensor for daily mean concentration is presented and evaluated. Different model configurations have been tested and evaluated. The methodology has been applied to data measured by the Lombardy regional monitoring network. The results show good agreement between the output of the virtual sensor and the measured data used for validation when the daily mean concentration is used as input—in particular, around the mean concentration values. Therefore, the models fail to reproduce the peak concentrations, and this behaviour will not change even if other inputs, such as meteorological data, are used. Nevertheless, the performances show that this approach can be used to produce supporting information to integrate the regional monitoring network that can be made available through app/web services due to a relatively fast computation.
Author Contributions
Conceptualization, C.C., E.T., R.Z.; software, C.C., R.Z.; validation, C.C., E.D.A., M.V.; funding acquisition, M.V. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Landrigan, P.; Fuller, R.; Acosta, N.; Adeyi, O.; Arnold, R.; Basu, N.; Baldé, A.; Bertollini, R.; Bose-O’Reilly, S.; Boufford, J.; et al. The Lancet Commission on pollution and health. Lancet 2018, 391, 462–512. [Google Scholar] [CrossRef] [Green Version]
- Pope, C., III; Dockery, D.; Spengler, J.; Raizenne, M. Respiratory health and PM10 pollution: A daily time series analysis. Am. Rev. Respir. Dis. 1991, 144, 668–674. [Google Scholar] [CrossRef]
- Pope, C., III; Dockery, D. Acute health effects of PM10 pollution on symptomatic and asymptomatic children. Am. Rev. Respir. Dis. 1992, 145, 1123–1128. [Google Scholar] [CrossRef] [PubMed]
- Turrini, E.; Carnevale, C.; Finzi, G.; Volta, M. A non-linear optimization programming model for air quality planning including co-benefits for GHG emissions. Sci. Total Environ. 2018, 621, 980–989. [Google Scholar] [CrossRef]
- Carnevale, C.; Ferrari, F.; Guariso, G.; Maffeis, G.; Turrini, E.; Volta, M. Assessing the Economic and Environmental Sustainability of a Regional Air Quality Plan. Sustainability 2018, 10, 3568. [Google Scholar] [CrossRef] [Green Version]
- Gimez Vilchez, J.; Julea, A.; Peduzzi, E.; Pisoni, E.; Krause, J.; Siskos, P.; Thiel, C. Modelling the impacts of EU countries electric car deployment plans on atmospheric emissions and concentrations. Eur. Transp. Res. Rev. 2019, 11, 40. [Google Scholar] [CrossRef]
- Relvas, H.; Miranda, A.; Carnevale, C.; Maffeis, G.; Turrini, E.; Volta, M. Optimal air quality policies and health: A multi-objective nonlinear approach. Environ. Sci. Pollut. Res. 2017, 24, 13687–13699. [Google Scholar] [CrossRef]
- Marques, G.; Pires, I.M.; Miranda, N.; Pitarma, R. Air Quality Monitoring Using Assistive Robots for Ambient Assisted Living and Enhanced Living Environments through Internet of Things. Electronics 2019, 8, 1375. [Google Scholar] [CrossRef] [Green Version]
- Arroyo, P.; Lozano, J.; Suárez, J. Evolution of Wireless Sensor Network for Air Quality Measurements. Electronics 2018, 7, 342. [Google Scholar] [CrossRef] [Green Version]
- Carnevale, C.; Finzi, G.; Pederzoli, A.; Pisoni, E.; Thunis, P.; Turrini, E.; Volta, M. A methodology for the evaluation of re-analyzed PM10 concentration fields: A case study over the PO Valley. Air Qual. Atmos. Health 2015, 8, 533–544. [Google Scholar] [CrossRef]
- Candiani, G.; Carnevale, C.; Finzi, G.; Pisoni, E.; Volta, M. A comparison of reanalysis techniques: Applying optimal interpolation and Ensemble Kalman Filtering to improve air quality monitoring at mesoscale. Sci. Total Environ. 2013, 458–460, 7–14. [Google Scholar] [CrossRef]
- Carnevale, C.; Finzi, G.; Pederzoli, A.; Turrini, E.; Volta, M.; Ferrari, F.; Gianfreda, R.; Maffeis, G. Impact of pollutant emission reductions on summertime aerosol feedbacks: A case study over the PO valley. Atmos. Environ. 2015, 122, 41–57. [Google Scholar] [CrossRef]
- Winkel, A.; Llorens Rubio, J.; Huis in’t Veld, J.W.; Vonk, J.; Ogink, N.W. Equivalence testing of filter-based, beta-attenuation, TEOM, and light-scattering devices for measurement of PM10 concentration in animal houses. J. Aerosol. Sci. 2015, 80, 11–26. [Google Scholar] [CrossRef]
- Costa, A.; Guarino, M. Definition of yearly emission factor of dust and greenhouse gases through continuous measurements in swine husbandry. Atmos. Environ. 2009, 43, 1548–1556. [Google Scholar] [CrossRef]
- Pathak, D.; Halale, V.P. An Introductory Approach to Virtual Sensors and Its Modelling Techniques. Sci. Eng. Res. 2016, 7, 461–464. [Google Scholar]
- Sun, S.; He, Y.; Zhou, S.D.; Yue, Z.J. A Data-Driven Response Virtual Sensor Technique with Partial Vibration Measurements Using Convolutional Neural Network. Sensors 2017, 17, 2888. [Google Scholar] [CrossRef] [Green Version]
- Kuo, S.; Zhou, M. Virtual sensing techniques and their applications. In Proceedings of the International Conference on Networking, Sensing and Control, Okayama, Japan, 26–29 March 2009; pp. 31–39. [Google Scholar]
- Rai, A.C.; Kumar, P.; Pilla, F.; Skouloudis, A.N.; Sabatino, S.D.; Ratti, C.; Yasar, A.; Rickerby, D. End-user perspective of low-cost sensors for outdoor air pollution monitoring. Sci. Total Environ. 2017, 607–608, 691–705. [Google Scholar] [CrossRef] [Green Version]
- Saljooghi, S.; Hezarkarkhani, A. Comparison of WAVENET and ANN for predicting the porosity obtained from well log data. J. Petrol. Sci. Eng. 2014, 123, 172–182. [Google Scholar] [CrossRef]
- Van den Oord, A.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. WaveNet: A Generative Model for Raw Audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Saljooghi, S.; Hezarkarkhani, A. A new approach to improve permeability prediction of petroleum reservois using neural network adaptive wavelet (Wavenet). J. Petrol. Sci. Eng. 2015, 123, 851–861. [Google Scholar] [CrossRef]
- Carnevale, C.; Angelis, E.; Finzi, G.; Turrini, E.; Volta, M. Application of data fusion techniques to improve air quality forecast: A case study in the Northern Italy. Atmosphere 2020, 11, 244. [Google Scholar] [CrossRef] [Green Version]
- Carnevale, C.; De Angelis, E.; Tagliani, F.; Turrini, E.; Volta, M. A short-term air quality control for PM10 levels. Electronics 2020, 9, 1409. [Google Scholar] [CrossRef]
- Sujatha, P. Vibration and Acoustics: Measurement and Signal Analysis; McGraw-Hill Education: Gautam Buddha Nagar, India, 2010. [Google Scholar]
- Cybenko, G. Approximation by Superposition of a Sigmoidal Function. Math. Control Signals Syst. 1989, 2, 303–314. [Google Scholar] [CrossRef]
- Mallat, S. A Theory for Multiresolution Signal Decomposition The Wavelet Representation. IEEE Trans. Pattern Anal. Mach. Intell. 1989, 11, 674–693. [Google Scholar] [CrossRef] [Green Version]
- Zakeri, V.; Naghavi, V.; Safavi, A. Developing real-time wave-net models for non-linear time-varying experimental processes. Comput. Chem. Eng. 2009, 33, 1379–1385. [Google Scholar] [CrossRef]
- Postalciouglu, S.; Erkan, K.; Bolat, E.D. Comparison of Wavenet and Neuralnet for System Modeling. In Knowledge-Based Intelligent Information and Engineering Systems; Khosla, R., Howlett, R.J., Jain, L.C., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 100–107. [Google Scholar]
- Carnevale, C.; Finzi, G.; Guariso, G.; Pisoni, E.; Volta, M. Surrogate models to compute optimal air quality planning policies at a regional scale. Environ. Model. Softw. 2012, 34, 44–50. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).