1. Introduction
Along with climate change, air pollution is one of the most serious environmental hazards to human health, estimated to cause 7 million premature deaths per year [
1]. The economic consequences of air pollution are dire, as estimates indicate
$5 trillion in welfare losses and 225 billion in lost income [
2,
3].
Air pollution includes greenhouse gas (GHG) emissions that warm the earth’s surface and atmosphere [
4]. GHG refer to the sum of seven gases that have direct effects on climate change: carbon dioxide (CO
2), methane (CH4), nitrous oxide (N2O), chlorofluorocarbons (CFCs), hydrofluorocarbons (HFCs), perfluorocarbons (PFCs), sulfur hexafluoride (SF6), and nitrogen trifluoride (NF3) [
5].
Understanding the urgency of more vigorous climate combat, decisive steps have been taken at the global level. The United Nations Framework Convention on Climate Change (UNFCCC) adopted the Kyoto Protocol (1997) and the Paris Agreement (2015) [
6]. The Paris Agreement, signed in December 2015, gathered all signatory countries under a common goal toward making significant efforts to tackle climate change and air pollution [
7,
8]. The Paris Agreement is meant to improve upon and replace the Kyoto Protocol, an earlier international treaty designed to curb the release of GHG, whose effectiveness has been heavily criticized because the world’s two top carbon dioxide-emitting countries, China and the United States, chose not to be part of the agreement [
9]. In contrast, the 2015 Paris agreement has been signed by nearly every country in the world (together responsible for more than 90 percent of global emissions), with 190 of the signatory countries (including the US and China) going further and having underlined their support with formal approval. As such, while before the Paris Conference the signatory countries submitted carbon reduction targets (i.e., “intended nationally determined contributions” or INDCs), these targets subsequently became “nationally determined contributions” or NDCs after the formal approval of the agreement [
10]. Hence, the Paris Agreement and the attainment of long-term climate targets are built around these NDCs representing each country’s efforts to cut national emissions and adapt to climate change consequences. Given the heterogeneity in circumstances, resources, and capabilities, the agreement was developed so that each country establishes their own commitments in terms of how much they can contribute to the 2030 Agenda. However, almost all submitted NDCs contain a target to reduce polluting emissions by a specific percentage over a specified period, in most cases, the first established deadline being 2030. However, while signatory parties are legally required to establish an NDC under the Paris agreement and to take actions to accomplish it, the NDC itself is not legally binding or enforceable pledge [
11].
Considering the GHG emission mitigation targets that most world countries have set for 2030 and/or 2050 under the Paris agreement, the total GHG emissions were expected to decline significantly in the aftermath of its adoption and to continue a decreasing trend over the next decades. However, the vast majority of world economies are yet to deliver on their pledges [
12].
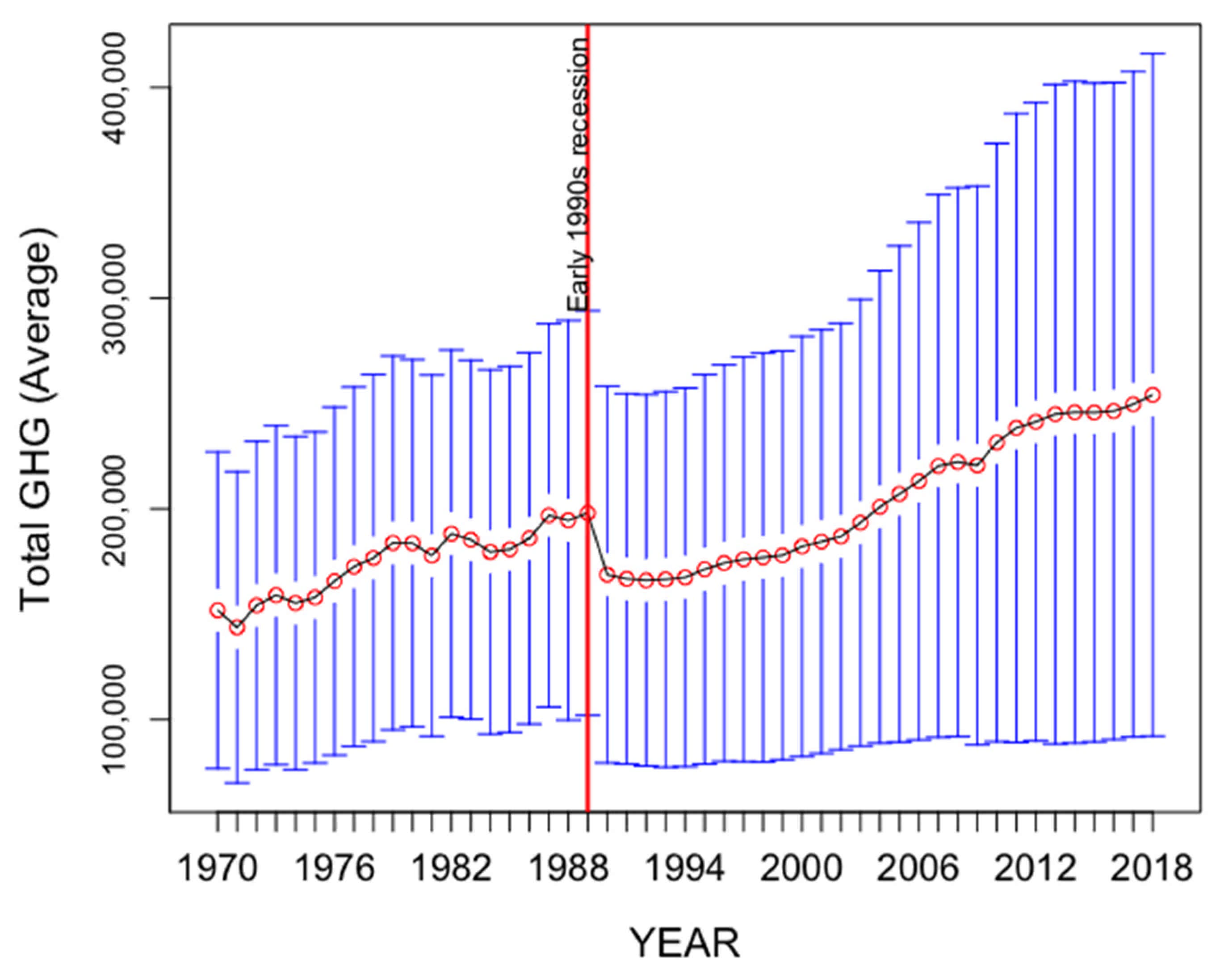
Data employed in our study backs this finding.
Figure 1 shows that on average total GHG emissions have continued to increase after 2015, although there is high heterogeneity across countries at the world level when it comes to their contribution to world pollution.
Figure 2 highlights that only a handful of countries significantly contributed to world pollution over the 1970–2018 period. Specifically, the main culprits reflected in
Figure 2 are the US, with a mean annual value for total GHG emissions measured in kt of CO
2 equal to 6,134,747 over the 49-year period, closely followed by China with 5,439,570 kt average annual GHG over the same period and at some distance by the Russian Federation, which registered 2,635,846 kt average annual GHG emissions. The rhythm of emissions growth has also been heterogenic at the world level over the past decades, as our study will further reflect. Overall, global greenhouse gas emissions have risen considerably since 1970, showing a 67.31% increase by 2018 (when total GHG emissions in kt of CO
2 equivalent at world level registered a mean value of 254,047.3) relative to their 1970 levels (mean value of 151,837.9 kt of CO
2 equivalent). This translates into an increase of 102,209.4 kt CO
2 in absolute terms over the 1970–2018. Over the entire 49-year period, interim short-term reversals followed economic contractions, with a sharper decrease during the 1990s economic recession caused by the Gulf War and subsequent oil price shocks.
This incongruence between policy targets and the current reality is particularly worrying given that top polluters continue to show significant increases in total GHG emissions and highlights the necessity of more impactful policies and measures to bring the set targets within reach. Consequently, accurate and robust forecasts for polluting emissions are needed for an effective and efficient policy-making process. The issue is timely, as countries must juggle post-pandemic recovery and bend the emission trends [
13]. However, the task is particularly challenging, as the world should halve annual greenhouse gas emissions in the next eight years to keep global warming below 1.5 °C this century, and thus meet the aspirational goal of the Paris Agreement [
14]. Other studies report the need for a cut of total GHG emissions by 7.6 percent each year between 2020 and 2030 to stay on track toward the 1.5 °C temperature goal of the Paris Agreement [
15]. Current statistics show a rapid recovery of economic activity and increasing emissions as energy demand soars [
16].
Unsurprisingly, polluting emissions have steadily drawn the attention of academics and policymakers over the past decades, and national and international agencies increasingly employ forecasts of polluting emissions in their policy-making process. Consequently, producing accurate estimates for GHG emissions and their evolution is critical for robust policy-making processes and ultimately for solving global climate challenges [
17]. This in turn is an important motivator for this study, which intends to identify the over-performing predictive model in terms of forecasting accuracy for total GHG emissions and subsequently apply it for producing forecasts for GHG emissions in top-emitting countries over long forecasting horizons, covering the first benchmark set for individual pledges within the Paris agreement, i.e., 2030.
Unlike most studies in the existing literature that investigate driving factors for polluting emissions, we take a univariate approach. This further brings two important advantages. First, it eliminates the challenge of identifying the right mix of macroeconomic, social, and financial variables that are potential impact factors for polluting emissions, and thus eliminates the risk of model misspecification, with further gains in terms of increasing estimation efficiency. Second, and most importantly, our approach allows us to produce forecasts for a validated leading indicator, independent of other variables.
Considering the above considerations, this study makes several contributions to the extant literature, as follows.
First, we employ a wider variety of candidate predictive models, including econometric and machine-learning methods, and perform a battery of robustness checks to assure that the best-performing out-of-sample forecasting model is identified. As we are more concerned with prediction accuracy than in-sample information, and in light of the previous literature, we a-priori expect machine learning methods to over-perform.
Secondly, we use a more relevant metric for air pollution, GHG emissions, instead of CO
2 emissions that are usually employed in previous studies. Consequently, by including a more accurate indicator of air pollution (i.e., CO
2 emissions account for approximately 76 percent of total GHG emissions, according to the Center for Climate and Energy Solutions [
18], estimation results are more relevant for policymakers. To this end, this study uses data for the 1970–2018 period provided by the World Development Indicators (WDI) database of the World Bank.
Thirdly, unlike most of the aforementioned previous studies that focus only on a single country or cover at most a handful of economies, this study includes the 12 most polluting countries in the world, which are responsible together for around 75% of total GHG emissions at world level. This contributes to assuring the robustness of the forecasting method and further increases the relevance of results for policymakers.
Results of this study confirm prior expectations and find that overall on average, the neural network autoregression model (NNAR) presents the best out-of-sample forecasting performance for GHG emissions over a long forecasting horizon by reporting the lowest average RMSE within the array of predictive models. Results further show that the world’s top polluters will not meet assumed GHG emissions’ reduction targets under the Paris agreement, and thus more impactful policies and measures are needed to bring the set goals within reach.
The remainder of the paper is organized as follows. The next section gives an overview of the related literature. Next,
Section 3 explains the data and methodology employed in the empirical investigation, while
Section 4 presents and discusses the estimation results and the performed robustness checks. Finally,
Section 5 concludes the study.
2. Literature Review
The environmental Kuznets curve (EKC) theory [
19,
20] states that pollution rises with the economic expansion until a certain level of wealth is achieved, at which point emissions begin to decline, implying an inverted U-shaped link between environmental degradation and income [
21]. Overall, mixed results were obtained from previous research that looked at the presence of the EKC in different countries and across different time periods [
22]. As a result, the topic of how economic growth and environmental quality are related (i.e., the form of the environmental Kuznets curve) continues to be contentious [
23]. As such, on one hand, the EKG hypothesis has been validated empirically by numerous studies (among others, [
6,
24,
25,
26]). However, on the other hand, a bidirectional causality has also been repeatedly encountered [
27], thus suggesting that emissions can also be a leading indicator of growth.
Moreover, besides its proven impact on economic growth, air pollution has a substantial influence on public health [
28]. Hence, previous studies confirmed that polluting emissions are also a leading indicator for various health variables [
29] and for mortality [
30,
31]. These effects have been found in both long-term studies, which have followed cohorts of exposed individuals over time, and in studies that connect day-to-day fluctuations in air pollution and health [
32]. Moreover, there is mounting evidence that indoor air pollution is a severe concern to human health in addition to ambient air quality, particularly in low-income nations where biomass fuels are still used as an energy source [
33]. All these findings further highlight the importance of combating climate change.
As such, given its validated role as an impact factor for important socio-economic variables, the primary objective of this study is to produce more accurate forecasts of GHG emissions. This in turn contributes to the timely evaluation of the progress achieved toward meeting global climate goals set by international agendas and also acts as an early-warning system when projections show that the state of affairs does not reflect policy statements and formal pledges are not followed by concrete measures and results. Hence, results of this study are also important for policymakers to incorporate forecasts of polluting emissions in their policy-making process.
However, time series analysis and forecasting remain challenging tasks [
34], and air pollution prediction is no exception [
35]. Broadly, based on the work of [
36] prediction models pertain to two main cultures or schools of thought [
37], each with its benefits and drawbacks [
38]: (i) econometrics, or statistical methods, a category that covers many familiar models [
39], and (ii) machine learning (self-learning systems, capable of learning from data to improve their performance). Their two common goals, information, and predictability [
40] are differently prioritized, with statistical methods focusing on inference, whereas machine-learning techniques concentrate on prediction [
41]. As the British statistician George Box has famously put it: “All models are wrong, but some are useful.” Consequently, the aim in time-series forecasting should be to identify the best predictive model within a pool of candidates and employ it to produce forecasts for the series of interest. This study does not deviate from this goal. Previous studies that attempt to model and forecast univariate polluting emission time series (most often CO
2) primarily employ statistical methods, including the logistic equation [
42], the ARIMA [
43], and the ARIMA, Holt–Winters, exponential smoothing, and singular spectrum analysis (SSA) [
44]. In the second category, we encounter among others [
45] that use extreme learning machines based on particle swarm optimization to predict CO
2 emissions in Hebei, ref. [
46] that use an artificial neural network (ANN) to predict carbon emission intensity for Australia, Brazil, China, India, and the USA, and [
47], which employ a neural network model for forecasting the CO
2 emission produced by the cereal sector in a southern Italy region. Overall, previous studies confirm that nonlinear models can capture the nonlinear pattern of real-world data, and thus overcome the limitation of linear models, improving their prediction performance [
48]. Additionally, artificial neural networks (ANN) are found to be useful in time series modeling where past values of a variable of interest are used to determine its future values [
49].
In this study, we attempt to forecast the evolution of GHG emissions by employing six candidate models belonging to both the aforementioned categories. As such, we estimate the innovations state-space models for exponential smoothing (ETS), the Holt–Winters (HW) model, the autoregressive integrated moving average (ARIMA) model, the trigonometric ETS state-space model with Box-Cox transformation, ARMA errors, trend and seasonal components (TBATS) model, the structural time series model (STS) and the neural network autoregression (NNAR) model. Additionally, a naive model is also employed for comparative purposes.
Similar approaches in the literature, but with application on other time series, include the study by [
50], which estimate and report the forecasting performance of nine models for the price of gold, concluding that on average, the exponential smoothing model is providing the best forecasts in terms of the lowest root mean squared error. Similarly, ref. [
51] uses seven automated forecasting techniques, including statistical and machine learning models, for explaining and predicting the evolution of CO
2 emissions in Bahrain and identify the NNAR model to provide the most accurate out-of-sample forecasts. More recently, ref. [
34] also predicted the evolution of Bahrain’s CO
2 emissions by employing a neural network time series nonlinear autoregressive model, the Gaussian process regression model, and Holt’s method, to agree that the NNAR model is outperforming the other candidates. Ref. [
52] also employs four of the techniques applied in this investigation (i.e., ARIMA, ETS, NNAR, and TBATS) along with their feasible hybrid combinations to forecast the second wave of COVID-19 hospitalizations in Italy, concluding that the best single models were NNAR and ARIMA, and that the best hybrid models always included a NNAR process. Finally, ref. [
53] employ statistical and deep learning methods to forecast long-term pollution trends for the two categories of particulate matter (PM) in a major city in eastern India, i.e., Kolkata. They conclude that statistical methods (i.e., auto-regressive (AR), seasonal auto-regressive integrated moving average (SARIMA) and Holt–Winters) outperform deep learning methods for their data. However, they argue that the results might be due to the limited data available, and that with a higher quantity of data and higher frequency and forecasting horizon, deep-learning models would out-perform.
All of these works bring important results for the global climate fight related literature. However, most of these works have a narrow interest (i.e., most are single-country studies, as seen above) and most importantly, they do not strongly defend their results robustness. The vast majority stops at evaluating the predictive ability of alternative models by reporting various forecasting accuracy metrics. [
34] employs the root mean square errors (RMSE) to this end, whereas [
53] estimate both RMSE and MAE, and [
52] reports MAE, MAPE, MASE, and RMSE metrics. Nonetheless, except [
51] that reports the KSPA test, other studies do not estimate and present statistical tests for multiple forecast comparisons and thus, do not investigate the hypothesis whether forecasts are significantly different, defending their results. Additionally, none of these previous works have re-estimated the models by employing an alternative forecasting technique (i.e., recursive window, changing window length, various time series slitting rules, etc.).
In this study, results’ robustness is assured firstly by employing out-of-sample forecasting on a holdout sample of observations and investigating the accuracy of several forecasting methods in comparative perspective, then by reassessing the predictive ability of candidate models via the recursive window forecasting technique, and finally by performing all estimations for 12 different top polluting countries, responsible for around ¾ of total GHG emissions at world level. Moreover, applying the Kolmogorov–Smirnov (KS) predictive accuracy test (KSPA) proposed by [
54] and the Diebold–Mariano (DM) test introduced by [
55] and developed by [
56] further contributes to testing the over-performance of the best predictive model and assures our results’ robustness.
Additionally, a further advantage of our approach consists in the fact that the employment of standard econometric methods together with machine-learning techniques in estimations and predictions allows comparison with previous results from the literature.
5. Conclusions
Greenhouse gas emissions (GHG) have risen significantly for the past 49 years at the world level. However, enormous disparities are encountered among individual countries, both in terms of absolute GHG emissions values and in terms of their rhythm of growth over the 1970–2018 period. On an absolute basis, China, the United States, and India are the three largest emitters. Together, they account for 48% of 2018 global GHG emissions. The 12 most polluting countries produce overall around three quarters of total GHG emissions at the world level, while the other 163 countries included in the analysis are responsible together for 26% of total greenhouse gas emissions in 2018. This underlines that a minority of countries create a global problem with systemic consequences and further motivates our focus on the 12 top emitting countries in our investigation.
The primary objective of this study is thus is to produce more accurate forecasts of GHG emissions. This in turn contributes to the timely evaluation of the progress achieved towards meeting global climate goals set by international agendas and also acts as an early-warning system when projections show that the state of affairs does not reflect policy statements and formal pledges are not followed by concrete measures and results. Results of this study are also important for policymakers that incorporate forecasts of polluting emissions in their policy-making process. A policy can only be efficient if it is developed based on robust input elements. Consequently, an accurate estimation of GHG emissions in top polluting countries is not only paramount for an effective policy-making process in the climate combat arena but will also play a vital role in planning economic developments over the long run. The issue is timely, as countries have to pursue post-pandemic economic recovery while bending the emissions trend.
As such, this paper attempts to forecast the evolution of GHG emissions in the world top polluters by employing seven statistical and machine learning methods, such as the exponential smoothing state-space model (ETS), the Holt–Winters model, the TBATS model, ARIMA, the structural time series model (STS), and the neural network time series forecasting method (NNAR). A naive model is also estimated and serves for comparative purposes. In particular, the study takes a univariate approach that offers the important advantage of producing forecasts for a validated leading indicator independent of other variables, aside from increasing efficiency. The results demonstrate that the best single model in terms of forecasting accuracy for GHG emissions is NNAR, and this finding resists a battery of robustness checks (including re-estimations at different forecasting horizons and re-estimation by implementing a recursive window forecasting technique). Consequently, the NNAR model is further employed to produce GHG emissions point forecasts for the 12 top polluting countries until 2030, i.e., until the first benchmark under the Paris agreement.
Although total GHG emissions were expected to decline sharply in the aftermath of the 2015 Paris agreement and to continue a decreasing trend over the next decades, empirical results indicate that top polluters will see an overall increase of 3.67% in GHG emissions relative to their 2018 levels. However, significant disparities remain among individual countries. Projections from the NNAR model at the 2030 forecasting horizon point to a 22.75% increase in GHG total emissions in Brazil, a 15.75% increase in Indonesia, and 7.45% in India. Decreases in GHG total emissions are expected in Canada (−5.57%), the Russian Federation (−3.01%), the US (−0.76%), and China (−0.89%), although they remain in the upper decile. More importantly, GHG projected levels fall well behind set pledges for all top polluting countries and none of the 12 sample economies is expected to meet its NDCs under the Paris agreement.
Overall, this study makes several important contributions to the extant literature, as follows: (i) it employs a wider variety of candidate predictive models for polluting emissions, including econometric and machine-learning methods, and also performs a battery of robustness checks to defend its findings; (ii) it employs a more accurate indicator for air pollution, thus increasing the relevancy of its results; (iii) it focuses on the 12 most polluting countries that are together responsible for around 75% of total GHG emissions at world level, thus further increasing the relevancy of the findings relative to single-country/narrower studies.
We conclude that country-specific policies would be more efficient to tackle global pollution than the global approach that is currently being implemented. In addition, a country-specific approach is only fair, given the enormous historical disparities in terms of individual countries’ contributions to world pollution, which are expected to persist. Moreover, public policies and the recovery funds directed toward post-pandemic economic recovery should target sustainable energy production and consumption, which in turn mitigate polluting emissions.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}