
A Middle-Level Learning Feature Interaction Method with Deep Learning for Multi-Feature Music Genre Classification


Abstract
:1. Introduction
- MLFI optimizes the multi-feature models. This is the method reported so far to maximize the classification accuracy while ensuring speed. Compared with the BBNN model with the highest accuracy 93.7%, the running speed of our method is only half of the former.
- MLFI is a simple and very general method for multi-feature models. Firstly, as long as the appropriate interaction mode is found, the classification accuracy can be greatly improved. Secondly, our research verifies that in the multi-feature model using MLFI, the learning features close to the input and output have a better impact on improving the classification accuracy, which is an important and core contribution of this research.
- It is also proved by the MLFI method that using more learning features as interactive information may produce a gain effect or inhibit other learning features from playing a role.
- As mentioned above, the interaction between middle-level learning features and their impact on the classification results of the multi-feature model are not discussed in the existing methods.
2. Pre-Processing and Feature
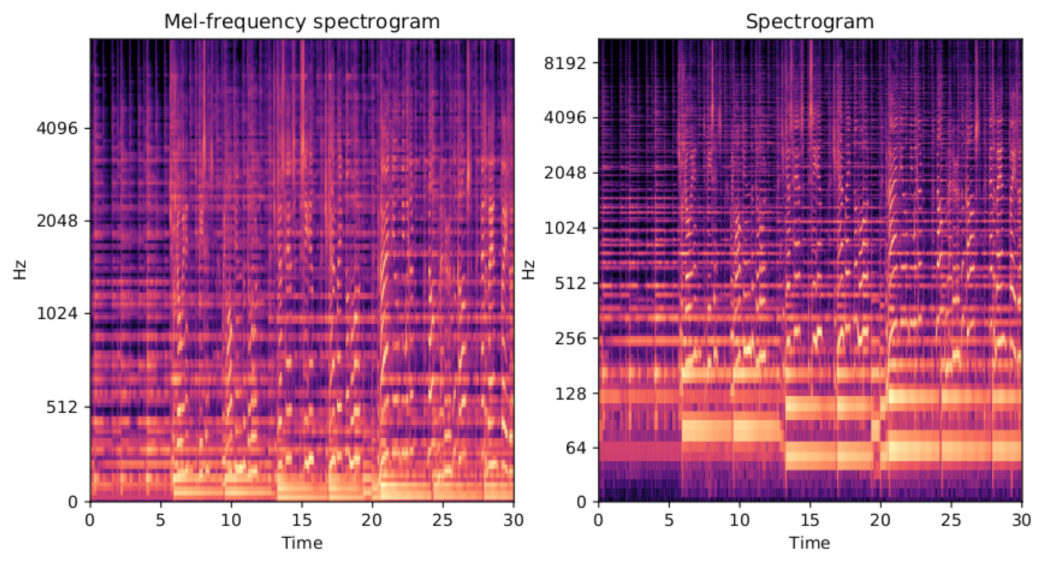
2.1. Visual Features
2.2. Audio Features
2.2.1. Timbral Texture Features
2.2.2. Other Features
3. Proposed Design and Approach
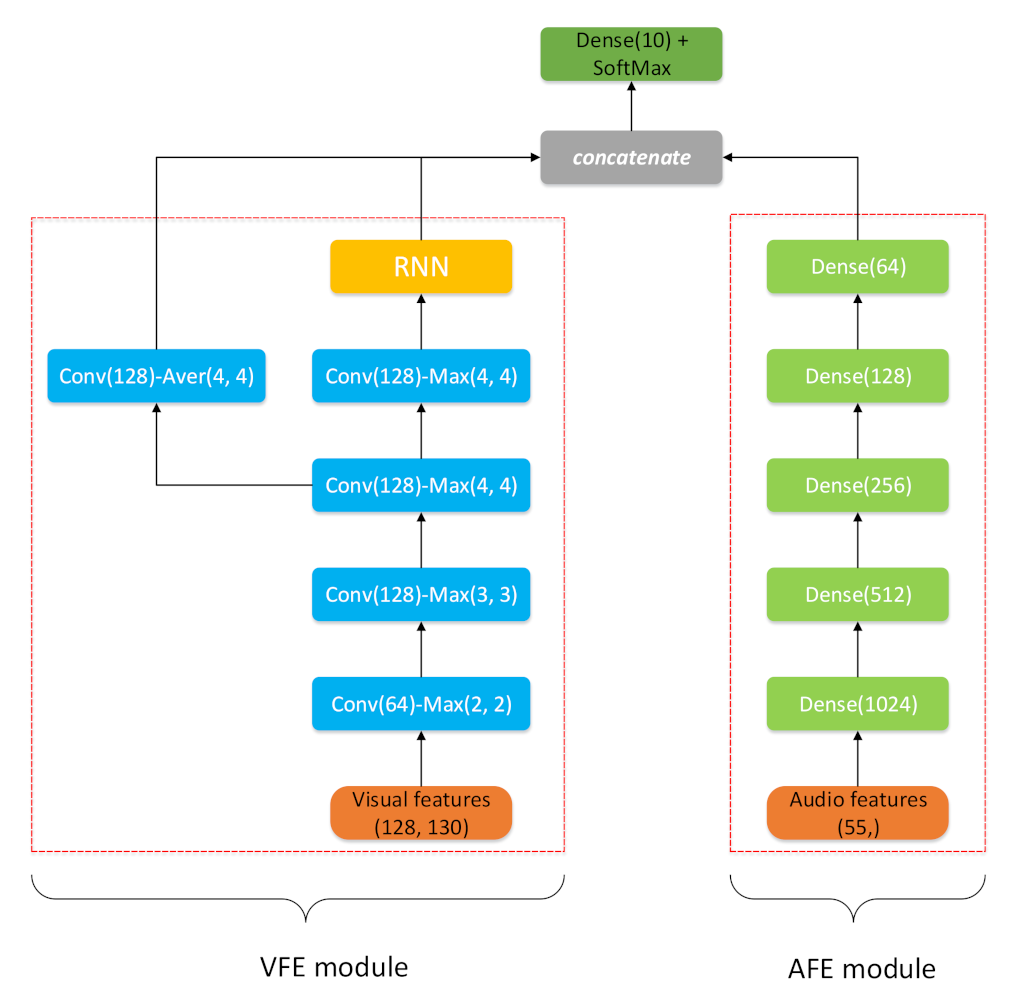
3.1. The Visual Features Extractor (VFE) Module
3.2. The Audio Features Extractor (AFE) Module
3.3. Network Structure
3.4. Middle-Level Learning Feature Interaction Method
4. Experimental Setup and Results
4.1. Dataset
4.2. Preprocessing
4.3. Training and Other Details
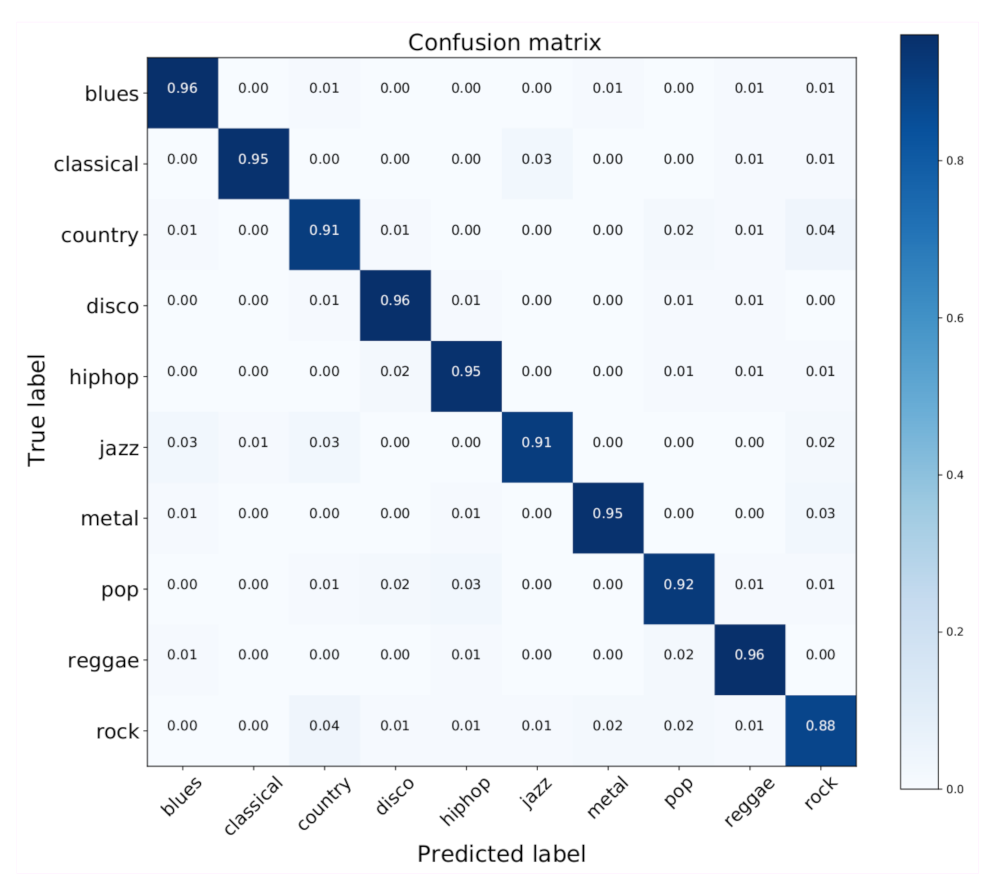
4.4. Classification Results on GTZAN
4.4.1. Classification Results of One-Way Interaction (Audio) Mode
4.4.2. Classification Results of One-Way Interaction (Vision) Mode
4.4.3. Classification Results of Two-Way Interaction Mode
4.4.4. Comparison of Each Mode
- Considering that dense (128) is closer to the output layer and has a similar degree of abstraction with the input and output of the RNN layer, the restriction between the two learning features will be smaller, and the gain effect will be more prominent.
- Considering that dense (1024) is closer to the input layer, it is equivalent to increasing the depth of the model for the input and output of RNN, which is conducive to extracting more effective learning features.
4.4.5. Comparison to State-of-the-Art
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Song, Y.; Zhang, C. Content-based information fusion for semi-supervised music genre classification. IEEE Trans. Multimed. 2007, 10, 145–152. [Google Scholar] [CrossRef]
- Fu, Z.; Lu, G.; Ting, K.M.; Zhang, D. A survey of audio-based music classification and annotation. IEEE Trans. Multimed. 2010, 13, 303–319. [Google Scholar] [CrossRef]
- Lim, S.-C.; Lee, J.-S.; Jang, S.-J.; Lee, S.-P.; Kim, M.Y. Music-genre classification system based on spectro-temporal features and feature selection. IEEE Trans. Consum. Electron. 2012, 58, 1262–1268. [Google Scholar] [CrossRef]
- Lee, C.-H.; Shih, J.-L.; Yu, K.-M.; Lin, H.-S. Automatic music genre classification based on modulation spectral analysis of spectral and cepstral features. IEEE Trans. Multimed. 2009, 11, 670–682. [Google Scholar]
- Liu, J.; Yin, T.; Cao, J.; Yue, D.; Karimi, H.R. Security control for TS fuzzy systems with adaptive event-triggered mechanism and multiple cyber-attacks. IEEE Trans. Syst. Man Cybern. Syst. 2020, 1–11. [Google Scholar] [CrossRef]
- Liu, J.; Suo, W.; Xie, X.; Yue, D.; Cao, J. Quantized control for a class of neural networks with adaptive event-triggered scheme and complex cyber-attacks. Int. J. Robust Nonlinear Control 2021, 31, 4705–4728. [Google Scholar] [CrossRef]
- Liu, J.; Wang, Y.; Zha, L.; Xie, X.; Tian, E. An event-triggered approach to security control for networked systems using hybrid attack model. Int. J. Robust Nonlinear Control 2021, 31, 5796–5812. [Google Scholar] [CrossRef]
- Jin, K.H.; McCann, M.T.; Froustey, E.; Unser, M. Deep convolutional neural network for inverse problems in imaging. IEEE Trans. Image Process. 2017, 26, 4509–4522. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, K.; Zuo, W.; Chen, Y.; Meng, D.; Zhang, L. Beyond a gaussian denoiser: Residual learning of deep CNN for image denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [Green Version]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Deng, X.; Zhang, Y.; Xu, M.; Gu, S.; Duan, Y. Deep coupled feedback network for joint exposure fusion and image super-resolution. IEEE Trans. Image Process. 2021, 30, 3098–3112. [Google Scholar] [CrossRef]
- Qian, Y.; Chen, Z.; Wang, S. Audio-visual deep neural network for robust person verification. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 1079–1092. [Google Scholar] [CrossRef]
- Luo, Y.; Mesgarani, N. Conv-tasNet: Surpassing ideal time–frequency magnitude masking for speech separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 1256–1266. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Abdel-Hamid, O.; Mohamed, A.; Jiang, H.; Deng, L.; Penn, G.; Yu, D. Convolutional neural networks for speech recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 1533–1545. [Google Scholar] [CrossRef] [Green Version]
- Dethlefs, N.; Schoene, A.; Cuayáhuitl, H. A divide-and-conquer approach to neural natural language generation from structured data. Neurocomputing 2021, 433, 300–309. [Google Scholar] [CrossRef]
- Zhang, K.; Sun, S. Web music emotion recognition based on higher effective gene expression programming. Neurocomputing 2013, 105, 100–106. [Google Scholar] [CrossRef]
- Zhang, J.; Huang, X.; Yang, L.; Nie, L. Bridge the semantic gap between pop music acoustic feature and emotion: Build an interpretable model. Neurocomputing 2016, 208, 333–341. [Google Scholar] [CrossRef]
- Wu, M.-J.; Jang, J.-S.R. Combining acoustic and multilevel visual features for music genre classification. ACM Trans. Multimed. Comput. Commun. Appl. 2015, 12, 1–17. [Google Scholar] [CrossRef]
- Montalvo, A.; Costa, Y.M.G.; Calvo, J.R. Language identification using spectrogram texture. In Iberoamerican Congress on Pattern Recognition; Springer: Berlin, Germany, 2015; pp. 530–550. [Google Scholar]
- Hafemann, L.G.; Oliveira, L.S.; Cavalin, P. Forest species recognition using deep convolutional neural networks. In Proceedings of the 2014 22Nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 1103–1107. [Google Scholar]
- Zhang, W.; Lei, W.; Xu, X.; Xing, X. Improved music genre classification with convolutional neural networks. In Proceedings of the Interspeech, San Francisco, CA, USA, 8–12 September 2016; pp. 3304–3308. [Google Scholar]
- Yang, H.; Zhang, W.-Q. Music genre classification using duplicated convolutional layers in neural networks. In Proceedings of the Interspeech, Graz, Austria, 15–19 September 2019; pp. 3382–3386. [Google Scholar]
- Choi, K.; Fazekas, G.; Sandler, M.; Cho, K. Convolutional recurrent neural networks for music classification. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 2392–2396. [Google Scholar]
- Liu, C.; Feng, L.; Liu, G.; Wang, H. Bottom-up broadcast neural network for music genre classification. Multimed. Tools Appl. 2021, 80, 7313–7331. [Google Scholar] [CrossRef]
- Nanni, L.; Costa, Y.M.; Lucio, D.R.; Silla, C.N., Jr.; Brahnam, S. Combining visual and acoustic features for audio classification tasks. Pattern Recognit. Lett. 2017, 88, 49–56. [Google Scholar] [CrossRef]
- Senac, C.; Pellegrini, T.; Mouret, F.; Pinquier, J. Music feature maps with convolutional neural networks for music genre classification. In Proceedings of the 15th International Workshop on Content-Based Multimedia Indexing, Florence, Italy, 19–21 June 2017; pp. 1–5. [Google Scholar]
- Dai, J.; Liu, W.; Ni, C.; Dong, L.; Yang, H. “Multilingual” deep neural network For music genre classification. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Stockholm, Sweden, 20–24 August 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Stevens, S.S.; Volkmann, J.; Newman, E.B. A scale for the measurement of the psychological magnitude pitch. J. Acoust. Soc. Am. 1937, 8, 185–190. [Google Scholar] [CrossRef]
- Klapuri, A.; Davy, M. Signal Processing Methods for Music Transcription; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2007; pp. 45–68. [Google Scholar]
- Papadopoulos, H.; Peeters, G. Local key estimation from an audio signal relying on harmonic and metrical structures. IEEE Trans. Audio Speech Lang. Process. 2011, 20, 1297–1312. [Google Scholar] [CrossRef]
- Lim, W.; Lee, T. Harmonic and percussive source separation using a convolutional auto encoder. In Proceedings of the 2017 25th European Signal Processing Conference (EUSIPCO), Kos, Greece, 28 August–2 September 2017; pp. 1804–1808. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Gupta, S. GTZAN Dataset—Music Genre Classification. 2021. Available online: https://www.kaggle.com/imsparsh/gtzan-genre-classification-deep-learning-val-92-4 (accessed on 21 March 2021).
- Tzanetakis, G.; Cook, P. Marsyas “Data Sets”. GTZAN Genre Collection. 2002. Available online: http://marsyas.info/download/data_sets (accessed on 21 March 2021).
- Tzanetakis, G.; Cook, P. Musical genre classification of audio signals. IEEE Trans. Speech Audio Process. 2002, 10, 293–302. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Browne, M.W. Cross-Validation Methods. J. Math. Psychol. 2000, 44, 108–132. [Google Scholar] [CrossRef] [Green Version]
- Sylvain, A.; Alain, C. A Survey of Cross-Validation Procedures for Model Selection. Stat. Surv. 2010, 4, 40–79. [Google Scholar]
- Francois, C. Keras. 2015. Available online: https://keras.io. (accessed on 21 March 2021).
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Karunakaran, N.; Arya, A. A scalable hybrid classifier for music genre classification using machine learning concepts and spark. In Proceedings of the 2018 International Conference on Intelligent Autonomous Systems (ICoIAS), Singapore, 1–3 March 2018; pp. 128–135. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Timbral Texture Features | Other Features 1 | Other Features 1 |
|---|---|---|
| Chroma | Harmonic component | Tempo |
| Root Mean Square (RMS) | Percussive component | |
| Spectral centroid | ||
| Spectral rolloff | ||
| Zero-Crossing Rate (ZCR) | ||
| MFCCs (1–20) |
| Genre | Tracks | Number of Clips |
|---|---|---|
| Reggae | 100 | 1000 |
| Metal | 100 | 1000 |
| Pop | 100 | 1000 |
| Jazz | 100 | 1000 |
| Blues | 100 | 1000 |
| Disco | 100 | 999 |
| Rock | 100 | 998 |
| Classical | 100 | 998 |
| Hip-hop | 100 | 998 |
| Country | 100 | 997 |
| Total | 1000 | 9990 |
| Learning Feature (A or B) | Paths | Dense Layer Marker | Accuracy (%) |
|---|---|---|---|
| A | [1] 2’ 3’ 4’ | 1024 | 92.35 |
| A | 1’ [2] 3’ 4’ | 512 | 92.18 |
| A | 1’ 2’ [3] 4’ | 256 | 92.60 |
| A | 1’ 2’ 3’ [4] | 128 | 93.14 |
| Avg: 92.5675 | |||
| B | [1] 2’ 3’ 4’ | 1024 | 93.65 |
| B | 1’ [2] 3’ 4’ | 512 | 91.08 |
| B | 1’ 2’ [3] 4’ | 256 | 91.67 |
| B | 1’ 2’ 3’ [4] | 128 | 93.28 |
| Avg: 92.42 |
| Input Size of RNN | Paths | Dense Layer Marker | Accuracy (%) |
|---|---|---|---|
| (72, 16) | e | 1024 | 93.11 |
| (40, 16) | d | 512 | 91.99 |
| (24, 16) | c | 256 | 91.28 |
| (16, 16) | b | 128 | 91.79 |
| (16, 12) | a | 64 | 91.72 |
| Avg: 91.978 |
| Learning Feature (A or B) | Paths | Dense Layer Marker | Accuracy (%) |
|---|---|---|---|
| A | [1] 2’ 3’ 4’ e | 1024 | 93.01 |
| A | 1’ [2] 3’ 4’ d | 512 | 90.79 |
| A | 1’ 2’ [3] 4’ c | 256 | 92.74 |
| A | 1’ 2’ 3’ [4] b | 128 | 92.82 |
| Avg: 92.39 | |||
| B | [1] 2’ 3’ 4’ e | 1024 | 92.84 |
| B | 1’ [2] 3’ 4’ d | 512 | 92.72 |
| B | 1’ 2’ [3] 4’ c | 256 | 93.04 |
| B | 1’ 2’ 3’ [4] b | 128 | 93.28 |
| Avg: 92.97 |
| Methods | Preprocessing | Accuracy (%) |
|---|---|---|
| CRNN [24] | mel-spectrogram | 86.5 |
| Hybrid model [43] | MFCCs, SSD, etc. | 88.3 |
| Combining Visual Furthermore, Acoustic (CVAF) [26] | mel-spectrogram, SSD, etc. | 90.9 |
| Music Feature Maps with CNN (MFMCNN) [27] | STFT, ZCR, etc | 91.0 |
| Multi-DNN [28] | MFCCs | 93.4 |
| BBNN [25] | mel-spectrogram | 93.7 |
| Ours(one-way interaction) | mel-spectrogram, ZCR, etc. | 93.65 |
| Methods | Graphics Processing Unit (GPU) | Compute Capability | Run Time/Epoch |
|---|---|---|---|
| BBNN | NVIDIA Titan XP (12 GB) | 6.1 | 28 s |
| ours | NVIDIA Tesla K80 (12 GB) | 3.7 | 19 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Wang, C.; Zha, L. A Middle-Level Learning Feature Interaction Method with Deep Learning for Multi-Feature Music Genre Classification. Electronics 2021, 10, 2206. https://doi.org/10.3390/electronics10182206
Liu J, Wang C, Zha L. A Middle-Level Learning Feature Interaction Method with Deep Learning for Multi-Feature Music Genre Classification. Electronics. 2021; 10(18):2206. https://doi.org/10.3390/electronics10182206
Chicago/Turabian StyleLiu, Jinliang, Changhui Wang, and Lijuan Zha. 2021. "A Middle-Level Learning Feature Interaction Method with Deep Learning for Multi-Feature Music Genre Classification" Electronics 10, no. 18: 2206. https://doi.org/10.3390/electronics10182206
APA StyleLiu, J., Wang, C., & Zha, L. (2021). A Middle-Level Learning Feature Interaction Method with Deep Learning for Multi-Feature Music Genre Classification. Electronics, 10(18), 2206. https://doi.org/10.3390/electronics10182206