
Unsupervised Outlier Detection: A Meta-Learning Algorithm Based on Feature Selection


Abstract
:1. Introduction
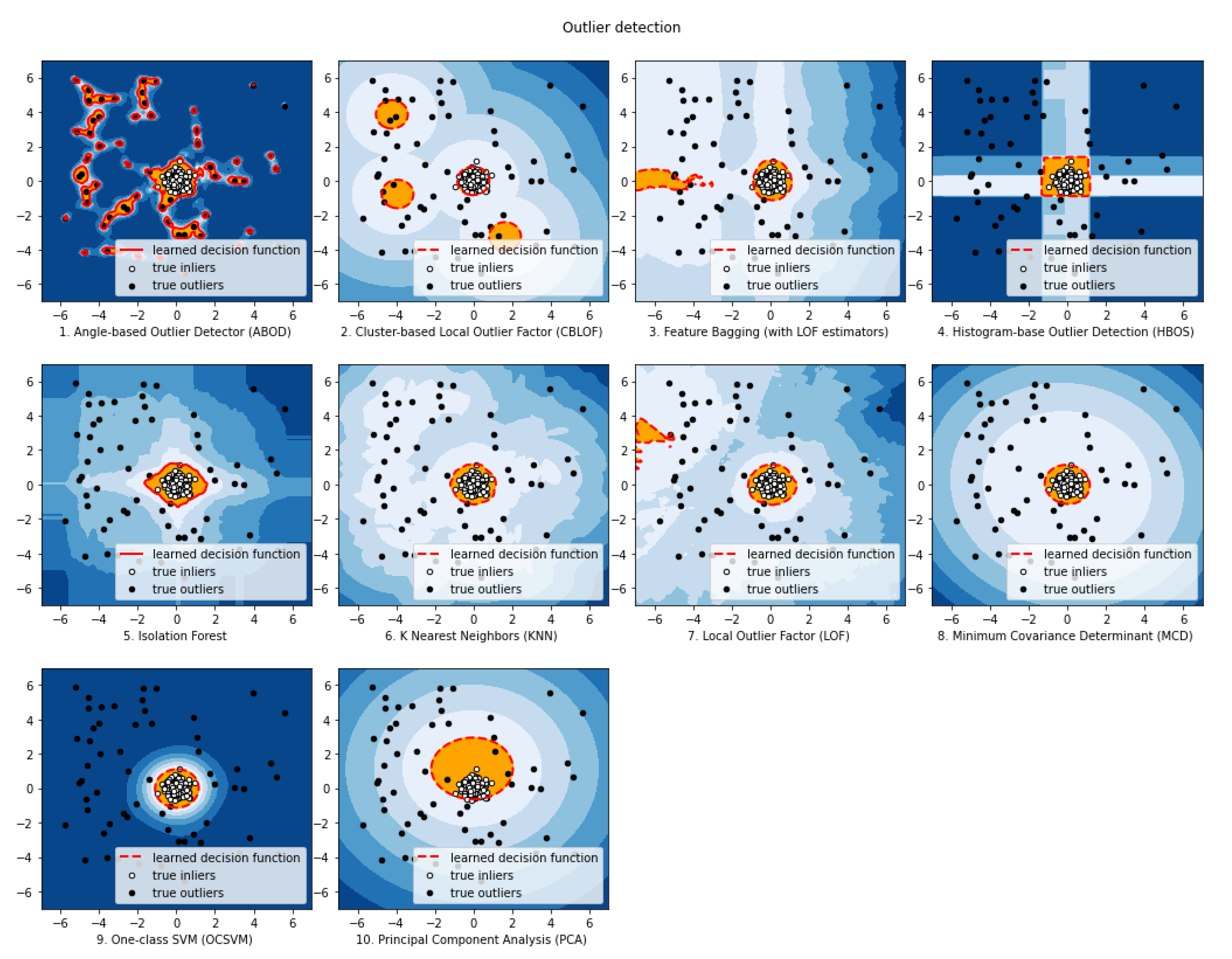
2. Unsupervised Outlier Detection Methods
2.1. k-Nearest Neighbours (k-NN)
2.2. Local Outlier Factor (LOF)
2.3. Cluster-Based Local Outlier Factor (CBLOF)
2.4. Histogram-Based Outlier Score (HBOS)
2.5. One-Class Support Vector Machines (OCSVM)
2.6. Minimum Covariance Determinant (MCD)
2.7. Principal Component Analysis (PCA)
2.8. Angle-Based Outlier Detection (ABOD)
2.9. Feature Bagging (FB)
2.10. Isolation Forest (iForest)
2.11. Ensemble Voting Methods
- Average: The outlier scores of all the detectors are averaged to produce a final score;
- Maximisation: The maximum score across all detectors is considered the final score;
- Average of Maximum (AOM): Sub-detectors are divided into subgroups and the maximum score for each subgroup is computed. The final score is the average of all subgroup maximum scores
- Maximum of Average (MOA): Sub-detectors are divided into subgroups and the average score for each subgroup is computed. The final score is the maximum of all subgroup average scores
3. Unsupervised Feature Selection
3.1. Spectral Feature Selection (SPEC)
3.2. Unsupervised Lasso
3.3. Weighted K-Means
4. Proposed Methodology
4.1. Data Preparation and Training
4.2. Unsupervised Feature Selection and Scoring
| Algorithm 1 Proposed Methodology Steps. |
|
5. Experiments Are Results
5.1. Experiment 1: Measuring the Performance of the Proposed Methodology
5.2. Experiment 2: Measuring the Impact of the Proposed Feature Selection Method
5.3. Experiment 3: Measuring the Impact of the Proposed Ensemble Voting Method
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A

{kind=link}
| Data | #Rows | #Dims | Outlier Perc | ABOD | CBLOF | FB | HBOS | IForest | KNN | LOF | MCD | OCSVM | PCA | AOM | PROPOSED |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| arrhythmia | 452 | 274 | 14.6018 | 0.75478 | 0.76042 | 0.76624 | 0.83304 | 0.83536 | 0.76834 | 0.767 | 0.786 | 0.777 | 0.7779 | 0.79932 | 0.80636 |
| cardio | 1831 | 21 | 9.6122 | 0.55894 | 0.82858 | 0.51898 | 0.84824 | 0.94268 | 0.70402 | 0.50432 | 0.87412 | 0.94658 | 0.96004 | 0.9136 | 0.91544 |
| glass | 214 | 9 | 4.2056 | 0.74278 | 0.86444 | 0.7806 | 0.6897 | 0.7364 | 0.81004 | 0.82102 | 0.73902 | 0.62024 | 0.6295 | 0.74618 | 0.71386 |
| ionosphere | 351 | 33 | 35.8974 | 0.91228 | 0.902 | 0.89394 | 0.54206 | 0.84296 | 0.92442 | 0.89956 | 0.94716 | 0.85314 | 0.80264 | 0.8687 | 0.86776 |
| letter | 1600 | 32 | 6.25 | 0.86142 | 0.75734 | 0.86804 | 0.58572 | 0.59716 | 0.85534 | 0.85218 | 0.77182 | 0.5809 | 0.49494 | 0.79738 | 0.78382 |
| lympho | 148 | 18 | 4.0541 | 0.9043 | 0.96702 | 0.96314 | 0.99784 | 0.9913 | 0.96264 | 0.96092 | 0.9045 | 0.96264 | 0.98046 | 0.97364 | 0.98664 |
| mnist | 7603 | 100 | 9.2069 | 0.78148 | 0.84176 | 0.7292 | 0.56444 | 0.78834 | 0.84392 | 0.72004 | 0.84854 | 0.83976 | 0.83872 | 0.8291 | 0.81276 |
| musk | 3062 | 166 | 3.1679 | 0.10668 | 1 | 0.53836 | 0.99994 | 0.99944 | 0.7665 | 0.54098 | 0.99974 | 1 | 0.99998 | 0.99972 | 0.99522 |
| optdigits | 5216 | 64 | 2.8758 | 0.4515 | 0.76966 | 0.4691 | 0.87552 | 0.61316 | 0.37698 | 0.46556 | 0.3584 | 0.49338 | 0.5019 | 0.68606 | 0.70976 |
| pendigits | 6870 | 16 | 2.2707 | 0.69892 | 0.96238 | 0.48352 | 0.92942 | 0.94228 | 0.75506 | 0.49278 | 0.82788 | 0.92926 | 0.93426 | 0.92598 | 0.9094 |
| pima | 768 | 8 | 34.8958 | 0.67502 | 0.6728 | 0.63302 | 0.70656 | 0.65712 | 0.7175 | 0.64198 | 0.6979 | 0.63014 | 0.6485 | 0.68686 | 0.69372 |
| satellite | 6435 | 36 | 31.6395 | 0.56742 | 0.72168 | 0.55492 | 0.74798 | 0.69672 | 0.67996 | 0.55398 | 0.79804 | 0.64634 | 0.58926 | 0.72258 | 0.7279 |
| satimage-2 | 5803 | 36 | 1.2235 | 0.855 | 0.99816 | 0.49052 | 0.9723 | 0.9904 | 0.95222 | 0.48928 | 0.99458 | 0.99548 | 0.97168 | 0.99648 | 0.9914 |
| shuttle | 49097 | 9 | 7.1511 | 0.62174 | 0.62754 | 0.5201 | 0.98438 | 0.99692 | 0.64868 | 0.53478 | 0.98996 | 0.99154 | 0.98958 | 0.99576 | 0.99396 |
| vertebral | 240 | 6 | 12.5 | 0.33178 | 0.38306 | 0.35728 | 0.31012 | 0.41318 | 0.35792 | 0.36848 | 0.36968 | 0.45958 | 0.3993 | 0.34466 | 0.3712 |
| vowels | 1456 | 12 | 3.4341 | 0.95528 | 0.91872 | 0.93292 | 0.69868 | 0.72978 | 0.96316 | 0.9298 | 0.69494 | 0.77312 | 0.60994 | 0.9016 | 0.93778 |
| wbc | 378 | 30 | 5.5556 | 0.91486 | 0.92016 | 0.94198 | 0.95988 | 0.94378 | 0.94226 | 0.93542 | 0.90236 | 0.93878 | 0.93096 | 0.94576 | 0.94966 |
| Data | #Rows | #Dims | Outlier Perc | ABOD | CBLOF | FB | HBOS | IForest | KNN | LOF | MCD | OCSVM | PCA | AOM | PROPOSED |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| arrhythmia | 452 | 274 | 14.6018 | 0.34726 | 0.42538 | 0.4468 | 0.53914 | 0.53226 | 0.4468 | 0.43942 | 0.3835 | 0.4537 | 0.4468 | 0.48252 | 0.51108 |
| cardio | 1831 | 21 | 9.6122 | 0.19314 | 0.49558 | 0.1307 | 0.46098 | 0.51398 | 0.30234 | 0.1367 | 0.42454 | 0.55406 | 0.65912 | 0.41988 | 0.44812 |
| glass | 214 | 9 | 4.2056 | 0.23 | 0.19 | 0.27 | 0.04 | 0.19 | 0.19 | 0.27 | 0 | 0.19 | 0.19 | 0.19 | 0.19 |
| ionosphere | 351 | 33 | 35.8974 | 0.82946 | 0.8031 | 0.7551 | 0.34232 | 0.66184 | 0.86012 | 0.7551 | 0.86674 | 0.72184 | 0.59522 | 0.72576 | 0.75152 |
| letter | 1600 | 32 | 6.25 | 0.29908 | 0.19576 | 0.36988 | 0.1053 | 0.07544 | 0.30538 | 0.32488 | 0.11414 | 0.11834 | 0.05386 | 0.22008 | 0.21428 |
| lympho | 148 | 18 | 4.0541 | 0.34 | 0.56 | 0.56 | 0.88 | 0.76 | 0.56 | 0.56 | 0.56 | 0.56 | 0.68 | 0.56 | 0.74 |
| mnist | 7603 | 100 | 9.2069 | 0.35008 | 0.40298 | 0.36356 | 0.1167 | 0.28742 | 0.41504 | 0.34344 | 0.35448 | 0.3772 | 0.3724 | 0.37578 | 0.35494 |
| musk | 3062 | 166 | 3.1679 | 0.04908 | 1 | 0.19502 | 0.97548 | 0.92588 | 0.2618 | 0.16998 | 0.95502 | 1 | 0.99 | 0.96214 | 0.79334 |
| optdigits | 5216 | 64 | 2.8758 | 0.0236 | 0 | 0.03268 | 0.23424 | 0.00966 | 0 | 0.02904 | 0 | 0 | 0 | 0.00322 | 0.01612 |
| pendigits | 6870 | 16 | 2.2707 | 0.0596 | 0.32224 | 0.06194 | 0.2796 | 0.31412 | 0.07138 | 0.0585 | 0.06952 | 0.30956 | 0.33176 | 0.26516 | 0.2249 |
| pima | 768 | 8 | 34.8958 | 0.50892 | 0.47066 | 0.435 | 0.5085 | 0.48504 | 0.51154 | 0.45544 | 0.4928 | 0.46252 | 0.50084 | 0.48514 | 0.51868 |
| satellite | 6435 | 36 | 31.6395 | 0.39006 | 0.55224 | 0.40148 | 0.55862 | 0.58046 | 0.49674 | 0.40076 | 0.6786 | 0.5278 | 0.4679 | 0.59938 | 0.59226 |
| satimage-2 | 5803 | 36 | 1.2235 | 0.24624 | 0.88134 | 0.06712 | 0.6289 | 0.85068 | 0.36758 | 0.07246 | 0.5631 | 0.90354 | 0.82048 | 0.73912 | 0.52934 |
| shuttle | 49097 | 9 | 7.1511 | 0.19844 | 0.23528 | 0.11194 | 0.97682 | 0.9357 | 0.22658 | 0.15128 | 0.74876 | 0.95396 | 0.94942 | 0.94168 | 0.91272 |
| vertebral | 240 | 6 | 12.5 | 0.01538 | 0.01538 | 0.03076 | 0.01538 | 0.03076 | 0 | 0.03076 | 0 | 0.01538 | 0 | 0.01538 | 0.01538 |
| vowels | 1456 | 12 | 3.4341 | 0.4888 | 0.35528 | 0.3205 | 0.14918 | 0.19304 | 0.52408 | 0.35584 | 0.01112 | 0.3174 | 0.13548 | 0.29576 | 0.39978 |
| wbc | 378 | 30 | 5.5556 | 0.255 | 0.535 | 0.5 | 0.695 | 0.475 | 0.475 | 0.415 | 0.39 | 0.475 | 0.535 | 0.535 | 0.495 |
References
- Hodge, V.; Austin, J. A survey of outlier detection methodologies. Artif. Intell. Rev. 2004, 22, 85–126. [Google Scholar] [CrossRef] [Green Version]
- Domingues, R.; Filippone, M.; Michiardi, P.; Zouaoui, J. A comparative evaluation of outlier detection algorithms: Experiments and analyses. Pattern Recognit. 2018, 74, 406–421. [Google Scholar] [CrossRef]
- Boukerche, A.; Zheng, L.; Alfandi, O. Outlier Detection: Methods, Models, and Classification. ACM Comput. Surv. CSUR 2020, 53, 1–37. [Google Scholar] [CrossRef]
- Zimek, A.; Filzmoser, P. There and back again: Outlier detection between statistical reasoning and data mining algorithms. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1280. [Google Scholar] [CrossRef] [Green Version]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. CSUR 2009, 41, 1–58. [Google Scholar] [CrossRef]
- Wang, H.; Bah, M.J.; Hammad, M. Progress in outlier detection techniques: A survey. IEEE Access 2019, 7, 107964–108000. [Google Scholar] [CrossRef]
- Aggarwal, C.C. An introduction to outlier analysis. In Outlier Analysis; Springer: Berlin, Germany, 2017; pp. 1–34. [Google Scholar]
- Aggarwal, C.C.; Philip, S.Y. An effective and efficient algorithm for high-dimensional outlier detection. VLDB J. 2005, 14, 211–221. [Google Scholar] [CrossRef]
- Alghushairy, O.; Alsini, R.; Soule, T.; Ma, X. A Review of Local Outlier Factor Algorithms for Outlier Detection in Big Data Streams. Big Data Cogn. Comput. 2021, 5, 1. [Google Scholar]
- Dong, X.L.; Srivastava, D. Big data integration. In Proceedings of the 2013 IEEE 29th International Conference on Data Engineering (ICDE), Brisbane, Australia, 8–12 April 2013; pp. 1245–1248. [Google Scholar]
- Liu, H.; Shah, S.; Jiang, W. On-line outlier detection and data cleaning. Comput. Chem. Eng. 2004, 28, 1635–1647. [Google Scholar] [CrossRef]
- Meng, F.; Yuan, G.; Lv, S.; Wang, Z.; Xia, S. An overview on trajectory outlier detection. Artif. Intell. Rev. 2019, 52, 2437–2456. [Google Scholar] [CrossRef]
- Zhao, Y.; Nasrullah, Z.; Li, Z. PyOD: A Python Toolbox for Scalable Outlier Detection. J. Mach. Learn. Res. 2019, 20, 1–7. [Google Scholar]
- Munoz, A.; Muruzábal, J. Self-organizing maps for outlier detection. Neurocomputing 1998, 18, 33–60. [Google Scholar] [CrossRef] [Green Version]
- Kriegel, H.P.; Kröger, P.; Schubert, E.; Zimek, A. Outlier detection in axis-parallel subspaces of high dimensional data. In Pacific-Asia Conference on Knowledge Discovery and Data Mining; Springer: Berlin, Germany, 2009; pp. 831–838. [Google Scholar]
- Almardeny, Y.; Boujnah, N.; Cleary, F. A Novel Outlier Detection Method for Multivariate Data. IEEE Trans. Knowl. Data Eng. 2020. [Google Scholar] [CrossRef]
- Li, Z.; Zhao, Y.; Botta, N.; Ionescu, C.; Hu, X. COPOD: Copula-based outlier detection. In Proceedings of the 2020 IEEE International Conference on Data Mining (ICDM), Sorrento, Italy, 17–20 November 2020; pp. 1118–1123. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. In Proceedings of the 2nd International Conference on Learning Representations, ICLR, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Burgess, C.P.; Higgins, I.; Pal, A.; Matthey, L.; Watters, N.; Desjardins, G.; Lerchner, A. Understanding disentangling in β-VAE. arXiv 2018, arXiv:1804.03599. [Google Scholar]
- Zhao, Y.; Nasrullah, Z.; Hryniewicki, M.K.; Li, Z. LSCP: Locally selective combination in parallel outlier ensembles. In Proceedings of the 2019 SIAM International Conference on Data Mining, Calgary, AB, Canada, 2–4 May 2019; pp. 585–593. [Google Scholar]
- Angiulli, F.; Pizzuti, C. Fast outlier detection in high dimensional spaces. In European Conference on Principles of Data Mining and Knowledge Discovery; Springer: Berlin, Germany, 2002; pp. 15–27. [Google Scholar]
- Ramaswamy, S.; Rastogi, R.; Shim, K. Efficient algorithms for mining outliers from large data sets. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, Dallas, TX, USA, 16–18 May 2000; pp. 427–438. [Google Scholar]
- Breunig, M.M.; Kriegel, H.P.; Ng, R.T.; Sander, J. LOF: Identifying density-based local outliers. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, Dallas, TX, USA, 16–18 May 2000; pp. 93–104. [Google Scholar]
- He, Z.; Xu, X.; Deng, S. Discovering cluster-based local outliers. Pattern Recognit. Lett. 2003, 24, 1641–1650. [Google Scholar] [CrossRef]
- Goldstein, M.; Dengel, A. Histogram-based outlier score (hbos): A fast unsupervised anomaly detection algorithm. In Proceedings of the KI-2012 Poster and Demo Track German Conference on Artificial Intelligence (Künstliche Intelligenz), Saarbrücken, Germany, 24–27 September 2012; pp. 59–63. [Google Scholar]
- Schölkopf, B.; Platt, J.C.; Shawe-Taylor, J.; Smola, A.J.; Williamson, R.C. Estimating the support of a high-dimensional distribution. Neural Comput. 2001, 13, 1443–1471. [Google Scholar] [CrossRef]
- Cristianini, N.; Shawe-Taylor, J. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods; Cambridge University Press: Cambridge, MA, USA, 2000. [Google Scholar]
- Rousseeuw, P.J.; Driessen, K.V. A fast algorithm for the minimum covariance determinant estimator. Technometrics 1999, 41, 212–223. [Google Scholar] [CrossRef]
- Hardin, J.; Rocke, D.M. The distribution of robust distances. J. Comput. Graph. Stat. 2005, 14, 928–946. [Google Scholar] [CrossRef] [Green Version]
- Hardin, J.; Rocke, D.M. Outlier detection in the multiple cluster setting using the minimum covariance determinant estimator. Comput. Stat. Data Anal. 2004, 44, 625–638. [Google Scholar] [CrossRef] [Green Version]
- Aggarwal, C.C. Outlier analysis. In Data Mining; Springer: Berlin, Germany, 2015; pp. 237–263. [Google Scholar]
- Shyu, M.L.; Chen, S.C.; Sarinnapakorn, K.; Chang, L. A novel anomaly detection scheme based on principal component classifier. In Proceedings of the IEEE Foundations and New Directions of Data Mining Workshop, in Conjunction with the Third IEEE International Conference On Data Mining (ICDM’03), Melbourne, FL, USA, 19–22 November 2003; pp. 172–179. [Google Scholar]
- Kriegel, H.P.; Schubert, M.; Zimek, A. Angle-based outlier detection in high-dimensional data. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; pp. 444–452. [Google Scholar]
- Lazarevic, A.; Kumar, V. Feature bagging for outlier detection. In Proceedings of the Eleventh ACM SIGKDD International Conference on Knowledge Discovery in Data Mining, Chicago, IL, USA, 21–24 August 2005; pp. 157–166. [Google Scholar]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 413–422. [Google Scholar]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation-based anomaly detection. ACM Trans. Knowl. Discov. Data TKDD 2012, 6, 1–39. [Google Scholar] [CrossRef]
- Zimek, A.; Campello, R.J.; Sander, J. Ensembles for unsupervised outlier detection: Challenges and research questions a position paper. ACM Sigkdd Explor. Newsl. 2014, 15, 11–22. [Google Scholar] [CrossRef]
- Dietterich, T.G. Ensemble methods in machine learning. In International Workshop on Multiple Classifier Systems; Springer: Berlin, Germany, 2000; pp. 1–15. [Google Scholar]
- Zhao, Z.; Liu, H. Spectral feature selection for supervised and unsupervised learning. In Proceedings of the 24th International Conference on Machine Learning, Corvallis, OR, USA, 20–24 June 2007; pp. 1151–1157. [Google Scholar]
- Alelyani, S.; Tang, J.; Liu, H. Feature selection for clustering: A review. Data Clust. Algorithms Appl. 2013, 29, 144. [Google Scholar]
- Shi, J.; Malik, J. Normalized cuts and image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 888–905. [Google Scholar]
- Witten, D.M.; Tibshirani, R. A framework for feature selection in clustering. J. Am. Stat. Assoc. 2010, 105, 713–726. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, J.Z.; Ng, M.K.; Rong, H.; Li, Z. Automated variable weighting in k-means type clustering. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 657–668. [Google Scholar] [CrossRef]
- He, X.; Cai, D.; Niyogi, P. Laplacian score for feature selection. Adv. Neural Inf. Process. Syst. 2005, 18, 507–514. [Google Scholar]
- Marques, H.O.; Campello, R.J.; Sander, J.; Zimek, A. Internal evaluation of unsupervised outlier detection. ACM Trans. Knowl. Discov. Data TKDD 2020, 14, 1–42. [Google Scholar] [CrossRef]
| Rank | Algorithm |
|---|---|
| 4.8823 | Proposed methodology |
| 5.0588 | Average of maximum |
| 5.1470 | Cluster-based local outlier factor |
| 5.3529 | Isolation forest |
| 6.0882 | K Nearest neighbours (KNN) |
| 6.1176 | Histogram-base outlier detection (HBOS) |
| 6.1764 | Minimum covariance determinant (MCD) |
| 6.4705 | One-class SVM (OCSVM) |
| 6.9411 | Principal component analysis (PCA) |
| 8.4705 | Feature bagging |
| 8.5882 | Angle-based outlier detector (ABOD) |
| 8.7058 | Local outlier factor (LOF) |
| Rank | Algorithm |
|---|---|
| 5.44117 | Proposed methodology |
| 5.58823 | Cluster-based local outlier factor |
| 5.61764 | Histogram-base outlier detection (HBOS) |
| 5.73529 | Average of maximum |
| 5.82352 | One-class SVM (OCSVM) |
| 5.94117 | Isolation forest |
| 6.29411 | Principal component analysis (PCA) |
| 6.58823 | K nearest neighbours (KNN) |
| 7.17647 | Feature bagging |
| 7.82352 | Local outlier factor (LOF) |
| 7.97058 | Angle-based outlier detector (ABOD) |
| 8 | Minimum covariance determinant (MCD) |
| Percentage | Algorithm |
|---|---|
| 0.80 | Cluster-based local outlier factor |
| 0.76 | Isolation forest |
| 0.73 | K Nearest neighbours (KNN) |
| 0.71 | Histogram-base outlier detection (HBOS) |
| 0.65 | Minimum covariance determinant (MCD) |
| 0.59 | One-class SVM (OCSVM) |
| 0.53 | Principal component analysis (PCA) |
| 0.45 | Feature bagging |
| 0.40 | Angle-based outlier detector (ABOD) |
| 0.39 | Local outlier factor (LOF) |
| Rank | Algorithm |
|---|---|
| 3.05882 | Fixed clustering |
| 3.32352 | Normalised cut |
| 3.5 | Lasso |
| 3.88235 | Weighted k-means |
| 4.11764 | Arbitrary clustering |
| Rank | Algorithm |
|---|---|
| 3.0294 | Fixed clustering |
| 3.1764 | Normalised cut |
| 3.6764 | Lasso |
| 3.8235 | Weighted k-means |
| 4 | Arbitrary clustering |
| Rank | Algorithm |
|---|---|
| 1.82352 | Average of maximum |
| 2.52941 | Maximisation |
| 2.64705 | Maximum of average |
| 3 | Average |
| Rank | Algorithm |
|---|---|
| 2.17647 | Average of maximum |
| 2.35294 | Maximum of average |
| 2.41176 | Maximisation |
| 3.05882 | Average |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Papastefanopoulos, V.; Linardatos, P.; Kotsiantis, S. Unsupervised Outlier Detection: A Meta-Learning Algorithm Based on Feature Selection. Electronics 2021, 10, 2236. https://doi.org/10.3390/electronics10182236
Papastefanopoulos V, Linardatos P, Kotsiantis S. Unsupervised Outlier Detection: A Meta-Learning Algorithm Based on Feature Selection. Electronics. 2021; 10(18):2236. https://doi.org/10.3390/electronics10182236
Chicago/Turabian StylePapastefanopoulos, Vasilis, Pantelis Linardatos, and Sotiris Kotsiantis. 2021. "Unsupervised Outlier Detection: A Meta-Learning Algorithm Based on Feature Selection" Electronics 10, no. 18: 2236. https://doi.org/10.3390/electronics10182236