1. Introduction
Air turbulence can seriously distort image contents and consequently can negatively affect target detection and classification performance in video surveillance [
1,
2,
3,
4].
Figure 1 shows the impact of air turbulence on video quality. All the fine features of the tower are smeared. In the past, researchers have developed numerous algorithms to mitigate turbulence effects [
5,
6,
7,
8,
9,
10,
11,
12,
13] among which there are simultaneous turbulence mitigation and super-resolution (SR) algorithms [
8,
9]. In recent years, there are also new SR algorithms using deep learning approaches [
14,
15]. Combining SR with some turbulence mitigation only algorithm is of interest to the community as well.
In the aforementioned turbulence mitigation studies, researchers used simulated and real turbulence videos for demonstrations. For real videos, it is difficult to assess which algorithm is performing better because of lack of ground truth. Hence, most of the time, subjective evaluations are used, which may not be consistent in the sense that some methods with close performance may be difficult to differentiate by humans. For simulated turbulence videos, objective metrics can be generated to compare different algorithms.
In [
16], a blind video quality assessment metric known as the Video Intrinsic Integrity and Distortion Evaluation Oracle (VIIDEO) was developed. However, it was tailored towards assessing compressed video quality. At this time, there does not seem to exist a consistent blind video quality assessment tool for evaluating different turbulence mitigation algorithms. In [
11], a blind video quality assessment tool was mentioned. However, the code is not available to the public. In [
17,
18], blind video quality assessment methods were proposed for videos containing natural scenes without air turbulence. In [
19], the authors compared three air turbulence mitigation algorithms. One idea uses a reference marker in the scene and this may not be practical because many videos with air turbulence are recorded in the wild.
In this paper, a new blind video quality metric for assessing different turbulence mitigation algorithms is proposed. First, given a video containing turbulence or a video that is already turbulence mitigated, one can apply existing blind still image quality assessment metrics such as Perception-based Image Quality Evaluator (PIQE) [
20] and Blind/Referenceless Image Spatial Quality Evaluator (BRISQUE) [
21] to assess the intra-frame spatial quality. PIQE and BRISQUE are well-known tools that can meet this intra-frame spatial quality assessment need. In this paper, the proposed metric will be utilizing BRISQUE as it was found to behave more consistently with visual inspection. Second, in order to capture the inter-frame fluctuations due to turbulence, an inter-frame root mean square error (IFRMSE) metric is proposed, which simply computes the RMSE between two neighboring frames and then take the average of all the RMSE of the frame pairs in the video. The intuition behind IFRMSE is that there are random fluctuations due to turbulence between the same pixels of different frames. If the IFRMSE is small, then turbulence effect should be small as well. Third, a hybrid metric that computes the geometric mean of the intra-frame scores and the inter-frame scores is proposed. As a result, both the intra- and inter-frame qualities have been taken into account. The proposed blind metric is in sharp contrast to the BRISQUE metric, which does not explicitly consider inter-frame fluctuations.
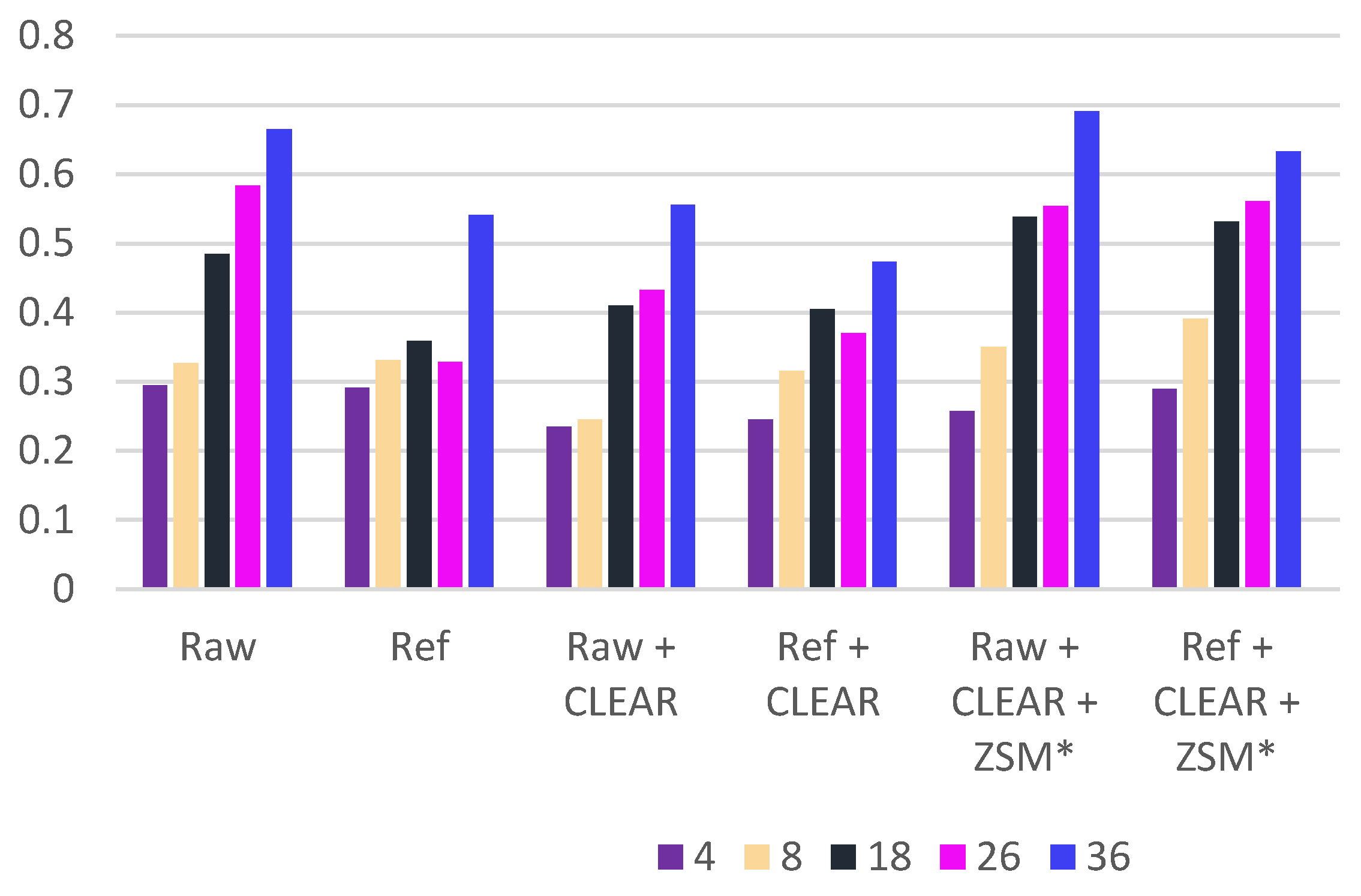
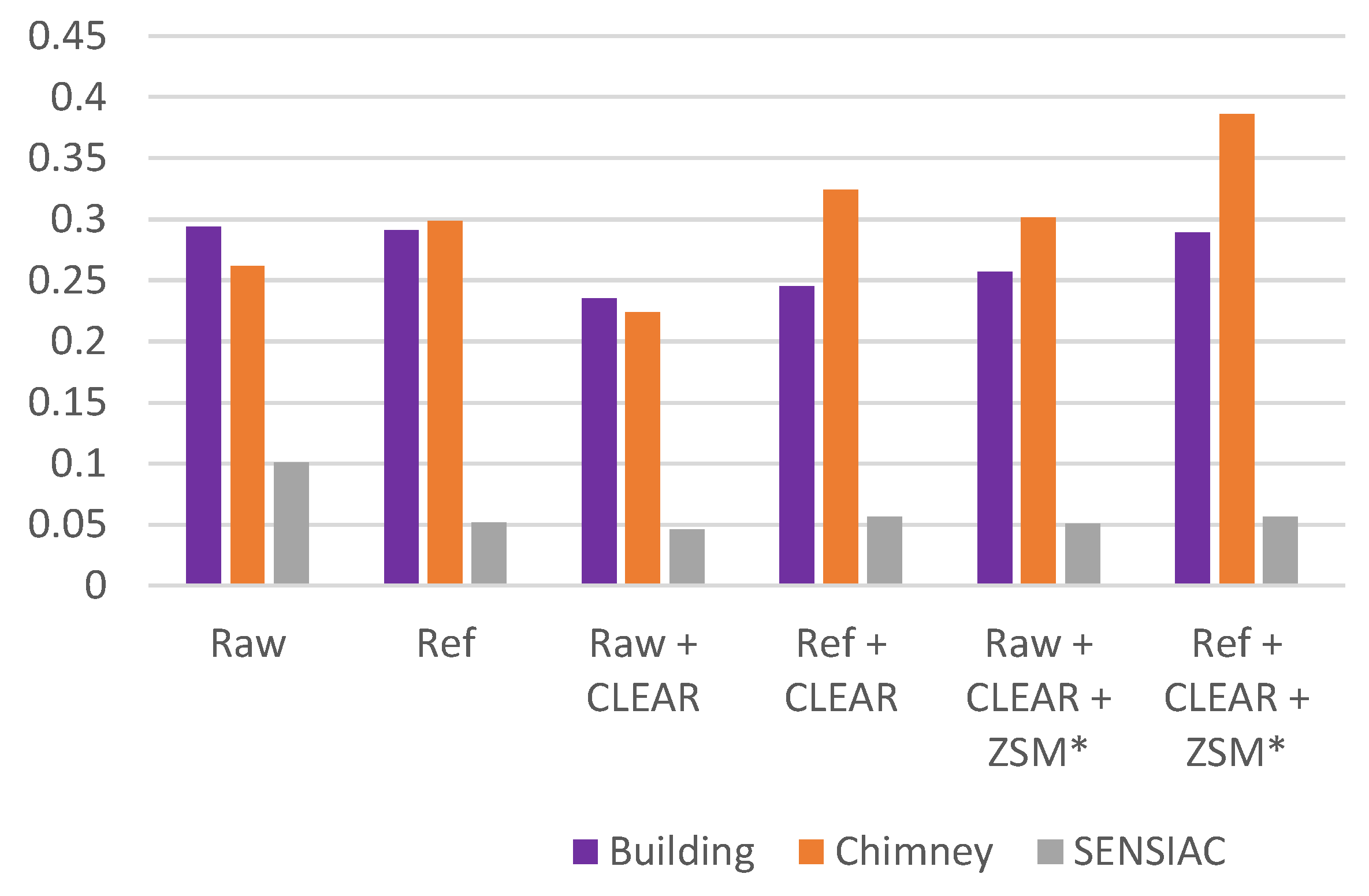
Here, several research questions are addressed. First, is the proposed hybrid blind video quality metric consistent with subjective evaluation results? Several turbulence mitigation algorithms in the literature were investigated, as well as the combination of those algorithms with a deep learning-based SR algorithm known as Zooming Slow Motion (ZSM) [
22]. This question is important for assessing some algorithms that have very close turbulence mitigation performance. Second, can the use of additional alignment and registration techniques alongside the well-known method CLEAR [
11] improve air turbulence mitigation? Third, is the existing blind video quality metric known as VIIDEO [
16] suitable for assessing turbulence mitigation algorithms? Answering this will motivate new research in blind video quality assessment specifically for turbulence mitigation.
The contributions of this paper are as follows:
- ▪
A new blind video quality assessment metric specifically for assessing turbulence mitigation algorithms is proposed. The new metric combines both intra-frame and inter-frame qualities in videos. This metric is consistent with subjective evaluations, meaning that the new metric can help differentiate algorithms that are too close in visual inspection. Hence, the first question raised earlier is answered.
- ▪
The use of additional alignment and registration techniques are demonstrated to visually improve videos with air turbulence. This answers the second question raised earlier.
- ▪
This metric is compared with an existing metric and observed that the previous metric in [
16] is not suitable for assessing turbulent mitigation algorithms. This answers the third question above.
The remainder of this paper is organized as follows. In
Section 2, a few representative and recent turbulence mitigation methods are summarized. Relevant works in the field of blind quality assessment, air turbulence mitigation, and super resolution are described. In
Section 3, the proposed blind video quality assessment metric and a workflow for performing air turbulence mitigation are explained in detail.
Section 4 showcases the experimental results of this workflow and metric on 12 videos. In
Section 5, a few concluding remarks and future directions are mentioned.
3. Methods
3.1. Using Reference Frame Only for Turbulence Mitigation
One way to potentially mitigate air turbulence is by using a new approach to generate a reference frame, which is important for image alignment. The authors of [
13] outline this approach in the equation below. For each given patch in a frame, a search is performed on a set number of subsequent frames and previous frames for that same patch in a search window slightly larger than the patch size. There is an assumption that there is no significant motion of objects between consecutive frames. Based on the Euclidian distance of the patch in the subsequent and previous frames, the best possible match for the patch at the current frame is found. Afterwards, a weighted average of the patches is used to generate a new reference frame
.
where
r denotes the given patch center location,
is a search window surrounding the current patch,
denotes the shift in terms of pixels between the current patch and a patch in the search window, and
represents the weighting of a given patch and is the inverse of Euclidean distance between the current patch and a given patch within the search window.
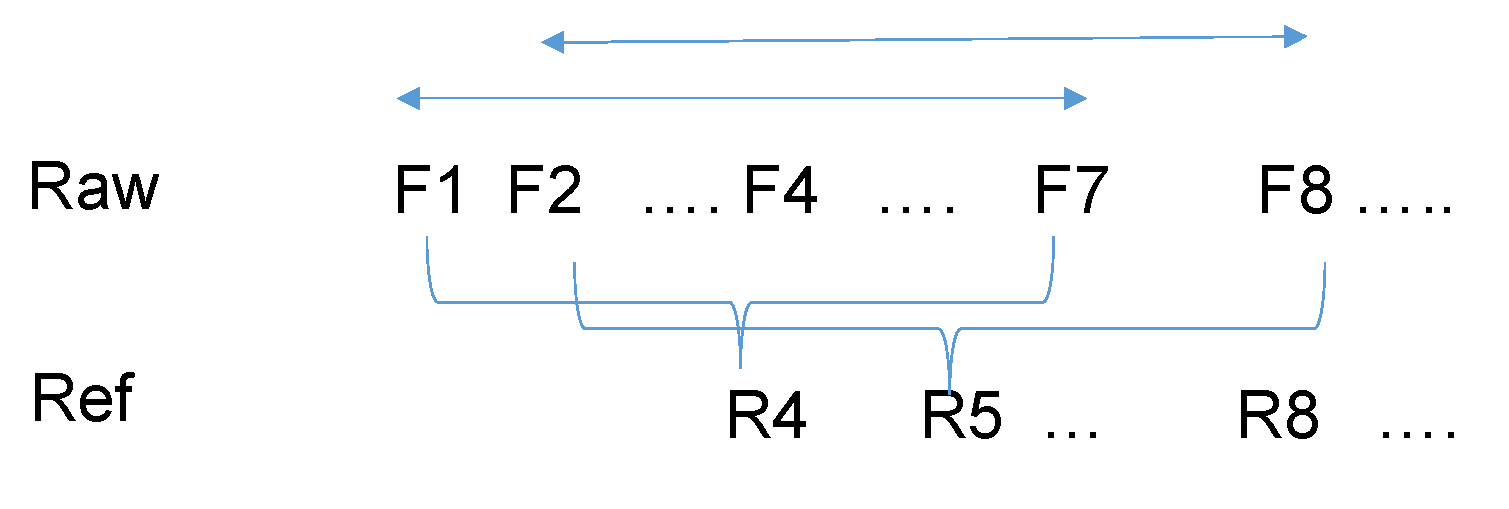
Figure 5 illustrates how to generate a sequence of reference (Ref) video. For a group of
N frames, Equation (1) is applied to generate one reference frame. The window of frames shifts to the right by one and then another reference frame is generated. This process repeats for the whole video.
Previous approaches, such as averaging the frames [
8,
9,
10], do not work as well as this approach. If there is air turbulence or even motion in the frames, simply averaging the frames will only smear the moving objects. This new approach to generating reference frames creates a much smooth frame that maintains the edges and shapes of moving objects.
Figure 6 shows a comparison of the two different approaches and the advantages offered by the patch-based reference generation.
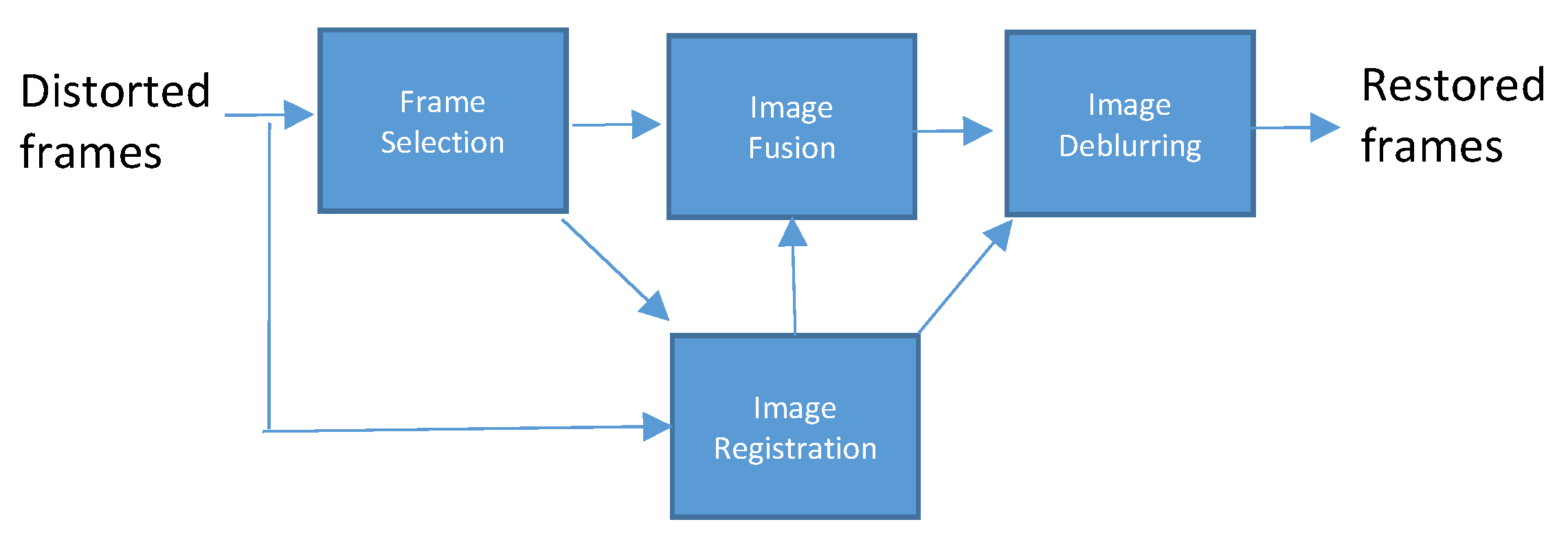
3.2. Proposed Workflow for Air Turbulence Mitigation
Instead of independently using reference frame alignment, CLEAR, or ZSM, these can be used in conjunction with one another to further improve image quality of air turbulent videos. The following order of algorithms are proposed: reference frame alignment, CLEAR, ZSM. As shown above in
Section 3.1, the reference frame alignment can provide crisper frames. In theory, this will make objects sharper even before the air turbulence mitigation. The final step would be to apply ZSM to the output of CLEAR. Although ZSM is a super resolution method, it also performs image fusion. It does so by aligning neighboring sequences of frames. These alignments further improve the quality of the frames. In essence, this proposed workflow utilizes a variety of registration and alignment methods to perform more holistic air turbulence mitigation.
3.3. Proposed Simple Inter-Frame RMSE (IFRMSE) Metric for Inter-Frame Quality Assessment
Simply using a blind quality assessment metric on a still frame does not give a holistic representation of the performance of different turbulence mitigation algorithms in a video with turbulence. The issue with air turbulence is not the noise in the individual frame but the noise that randomly changes from frame to frame due to air turbulence. In order to better assess air turbulence mitigation, a metric needs to measure the consistency of pixels across frames.
One simple way to measure the consistency is to take the RMSE at each pixel location between frame pairs. Using an inter-frame RMSE to measure the effect of air turbulence across frames is proposed. For every frame pair, the RMSE between the current frame,
Fi, and the subsequent frame,
Fi+1 is taken. That is, the inter-frame RMSE for frame pair
i is defined as
where
Fi,j denotes the
jth pixel in frame
Fi and
N is the total number of pixels in a frame.
To assess the video quality, it is necessary to compute IFRMSE values from multiple frame pairs in order to reduce the statistical variations. For a video sequence,
v, of
n frames, there will be
n−1 frame pairs. The following equation calculates the mean of the IFRMSEs as
A few cautionary notes are needed. First, if the camera moves, then an image registration step is needed between the two frames in a frame pair. The aligned images can then be used for computing the IMRMSE. Second, if there are moving objects in the videos, the number and size of the moving objects may limit the effectiveness of the metric. If the number of pixels related to the moving objects is a small percentage (<5%) of the total number of pixels in a frame, then it should be alright to proceed with the calculation of IFRMSE. However, if the number of moving pixels due to moving objects is too large (10% or more), then one must apply optical flow techniques to determine those large moving objects and then exclude them in the computation of IFRMSE.
3.4. Proposed Hybrid Blind Video Quality Assessment Metric
One shortcoming of the IFRMSE metric is that it does not measure the actual quality of individual frames. For example, in a case where the image quality in a video was poor and the frames were consistently poor across the sequence, the IFRMSE metric would be quite low (indicating a high-quality video) even though there is no air turbulence. Such a case can happen to a highly compressed video in which all frames have poor quality due to compression. To overcome this shortcoming of IFRMSE, one can combine the score with one of the blind quality assessment scores. More specifically, take the geometric mean of the IFRMSE metric over many frame pairs and the intra-frame metric BRISQUE scores over many frames to generate a hybrid score. That is, the hybrid metric is given by
Experiments were conducted with PIQE, but could not get consistent results. Hence, only Equation (4) is used in the experiments. PIQE could be used as a replacement for BRISQUE for certain datasets if needed.
The geometric mean has a few advantages over the arithmetic mean. First, in dealing with metrics from different domains, it will be a good practice to use geometric mean. This will be fair to each of the contributing metrics in the product. That is, a given percentage change in any of the two metrics has the same effect on the product. For example, a 10% change in intra-frame metric from 0.1 to 0.11 has the same effect on the overall geometric mean as a 10% change in inter-frame metric from 0.5 to 0.55. Second, the geometric mean can better handle large dynamic ranges of two metrics. For instance, if the intra-frame metric is 0.01 and inter-frame is 0.9, the geometric of the two will be 0.3, but the arithmetic mean will give 0.455. As a result, the arithmetic mean will favor the metric that has large values.
The hybrid metric above should be more indicative of air turbulence mitigation across videos. Additionally, the metric can be used on datasets without having a ground truth video. This makes it more flexible in real-world scenarios where the ground truth video may not be available or possible to attain.
One might think that the proposed metric in Equation (4) is too simple and lacks novelty. Indeed, the proposed blind metric is simple and intuitive. However, there were no similar approaches in the literature. Moreover, scientific discoveries are usually incremental in nature. In this sense, the proposed metric is contributing new knowledge to the literature.
It is worth mentioning some differences between VIIDEO and the proposed metric. First, the VIIDEO metric is a patch-based method. It computes the local contrast of each patch across multiple frames. The metric is simpler in that one only needs to compute the RMSE between neighboring frames without using patches. Second, VIIDEO does not have a spatial only metric for assessing the image quality in each frame whereas the proposed approach has an explicit spatial quality component.
5. Conclusions
A new blind video quality metric was proposed to assess air turbulence mitigation performance in video sequences. These results were in agreement with visual inspection. Twelve commonly used videos were used to perform this validation. Experimental results showed that the metrics are consistent with subjective evaluation of videos. The experiments demonstrated the effectiveness of using CLEAR in combination with reference frame alignment and ZSM to mitigate air turbulence.
One anonymous reviewer pointed out that turbulence may be treated as shake and blurry effects and hence some denoising algorithms such as [
27,
28] can be used. This could be a reasonable future research topic. Another future direction is to investigate how one can adapt some blind assessment metrics, such as those in [
16,
29,
30], to turbulence mitigated videos. Finally, there could be further research into the effects of motion within videos and how they may affect blind quality assessment metrics like IFRMSE. Some new developments in video quality assessment [
31,
32,
33] in non-air-turbulence mitigation areas could potentially be adapted to blind image quality assessment in air turbulence videos.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}