
GicoFace: A Deep Face Recognition Model Based on Global-Information Loss Function †


Abstract
:1. Introduction
- We propose a novel loss function to enhance the discriminative capacity of the deep features. To the best of our knowledge, it is the first loss that simultaneously satisfies all the first four properties in Table 1 and also the first attempt to use global information as the feedback information;
- We propose and implement three different versions of Gico loss and analyze their performance variation on multiple datasets;
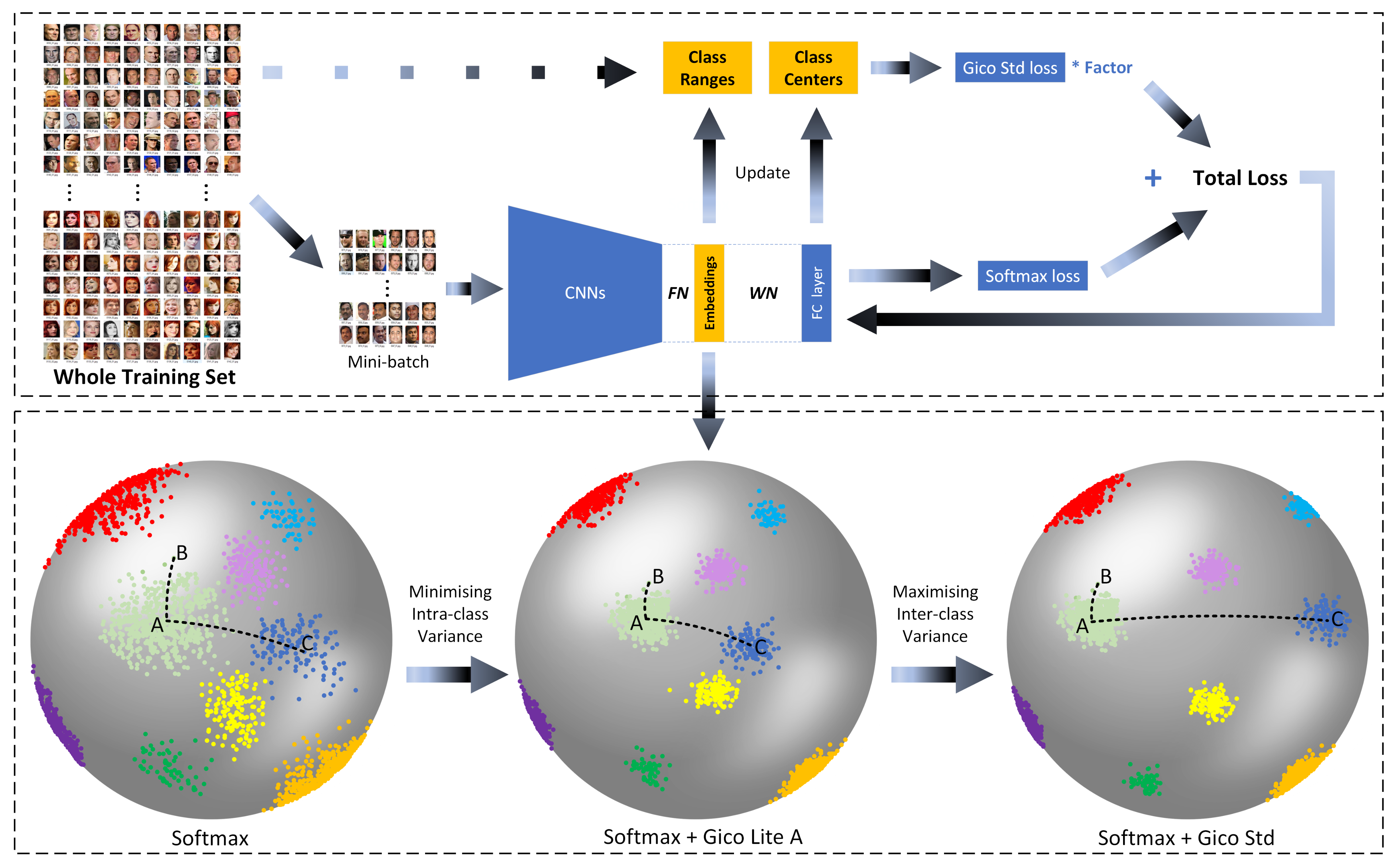
- To break through the hardware constraints and make Gico loss possible, we propose an algorithm to learn the cosine similarity between the class center and the class edge;
- We conduct extensive experiments on multiple public benchmark datasets including LFW [17], SLLFW [18], YTF [19], MegaFace [20] and FaceScrub [21] datasets. Experimental results presented in Section 3 confirm the efficacy of the proposed method and show the state-of-the-art performance of the method.
2. From Cross Entropy Loss to Gico Loss
2.1. Cross Entropy Loss and Center Loss
2.2. Variants of Cross Entropy Loss Based on Cosine Similarity
2.3. The Proposed Gico Loss
| Algorithm 1 Learning algorithm in the CNNs with the proposed Gico Std. |
|
2.4. Discussion
- Why combine and using multiplication instead of simple addition? Does it cause instability?The idea of multiplication is inspired by LDA (Linear Discriminative Analysis). Using multiplication, only one parameter is needed for adjusting the impact of Gico Std. Using addition, two parameters are needed for the two parts of Gico Std respectively. Roughly speaking, Gico Std is the quotient of the average inter-class distance and the average intra-class distance as shown in Equation (13). Both denominator and nominator have limits, and they are mutually constrained; thus, their quotient does not lead to instability. We checked the loss curves, and confirm that the cases of instability did not happen.
- The improvements on recognition accuracy are somewhat incremental?Our observation is that incremental improvements are common in General Face Recognition (GFR). GFR has reached a very high level of performance so the scope of improvement is limited. Most of the recent GFR methods have marginal improvement or even worse than the state-of-the-art but are aimed to solve specific problems. For example, Sphereface+ [9], Center loss [1] and CosFace [15] have improvements from −0.19% to 0.31% on LFW dataset.
- What are the highlights of the proposed method?Our method creates two "firsts". It is the first loss function that simultaneously satisfies all five properties in Table 1 and is the first to use global information as feedback. Therefore, the proposed loss has its own merits, will encourage others to carefully consider the use of global information and will create opportunities for new research.
- Cross entropy loss separates the samples of different classes, but does not enlarge the margin between neighbor classes". What’s the difference?These two cases correspond to two kinds of features: separable features and discriminative features. Separable features are able to separate classes by decision boundaries. Discriminative features are further required to have better intra-class compactness and inter-class separability to enhance predictivity. The Example can be found in Figure 1 of [1].
- Using global information is better than just using mini-batch? Why is global information introduced?No, both of them are necessary for training a deep learning model. All practitioners are aware that using mini-batch SGD (Stochastic Gradient Descent) makes the neural network generalize better than using standard gradient descent that takes the entire dataset as input, as the randomness helps the network jump out of some local minimals which is beneficial to the generalization. Therefore, the proposed deep model is trained by the mini-batch data on one hand. On the other hand, the proposed methods also introduce global information, as the mini-batch data cannot provide the loss functions with precise measurement information, like the positions of the class center and the class edge in Gico loss. Introducing global information makes the measurement information precise, thus improve the final recognition accuracy.
3. Experiments
3.1. Experiment Settings
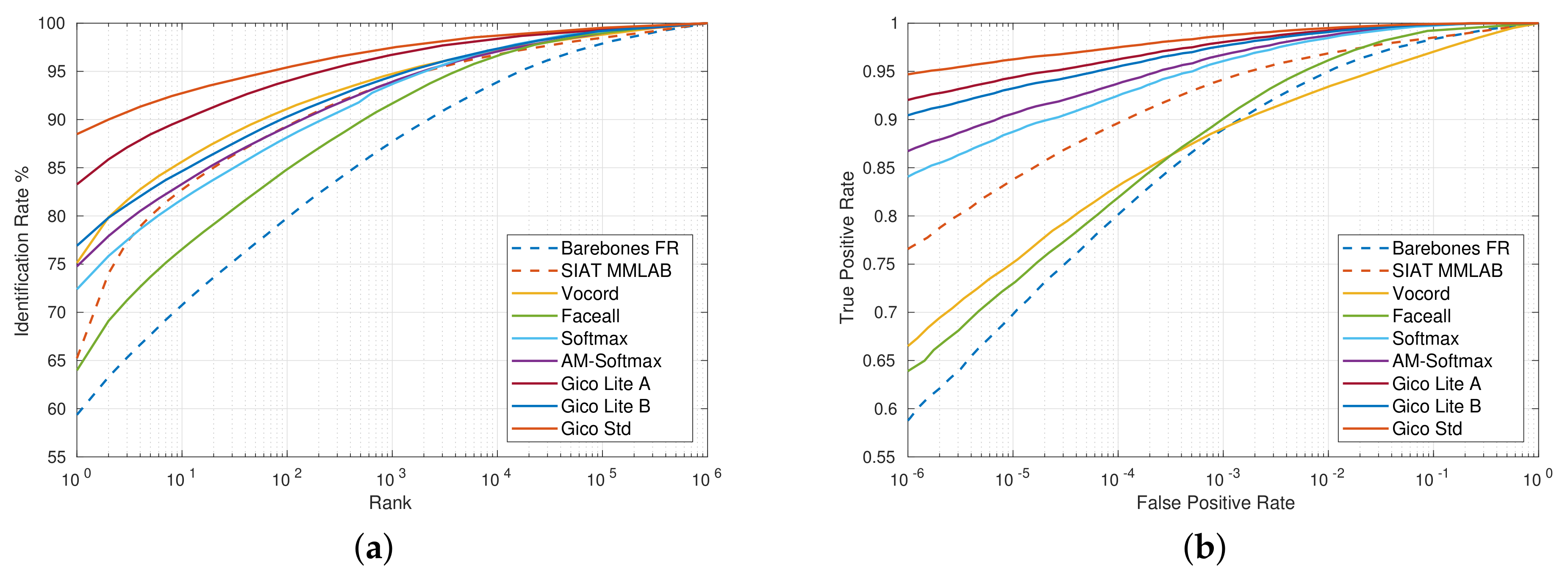
3.2. MegaFace Challenge 1 on FaceScrub
3.3. Results on LFW, YTF and SLLFW
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wen, Y.; Zhang, K.; Li, Z.; Qiao, Y. A Discriminative Feature Learning Approach for Deep Face Recognition. In Computer Vision—ECCV (Lecture Notes in Computer Science); Springer: Cham, Switzerland, 2016; pp. 499–515. [Google Scholar]
- Deng, J.; Zhou, Y.; Zafeiriou, S. Marginal Loss for Deep Face Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops; IEEE: New York, NY, USA, 2017; pp. 60–68. [Google Scholar]
- Zhang, X.; Fang, Z.; Wen, Y.; Li, Z.; Qiao, Y. Range loss for deep face recognition with long-tailed training data. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5409–5418. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Sun, Y.; Chen, Y.; Wang, X.; Tang, X. Deep learning face representation by joint identification-verification. In Advances in Neural Information Processing Systems; The Chinese University of Hong Kong: Hong Kong, China, 2014; pp. 1988–1996. [Google Scholar]
- Deng, J.; Guo, J.; Zafeiriou, S. ArcFace: Additive Angular Margin Loss for Deep Face Recognition. arXiv 2018, arXiv:1801.07698. [Google Scholar]
- Liu, B.; Deng, W.; Zhong, Y.; Wang, M.; Hu, J.; Tao, X.; Huang, Y. Fair loss: Margin-aware reinforcement learning for deep face recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 10052–10061. [Google Scholar]
- Liu, W.; Wen, Y.; Yu, Z.; Yang, M. Large-Margin Softmax Loss for Convolutional Neural Networks. In International Conference on Machine Learning; ICML: New York, USA, 2016; pp. 507–516. [Google Scholar]
- Liu, W.; Wen, Y.; Yu, Z.; Li, M.; Raj, B.; Song, L. SphereFace: Deep Hypersphere Embedding for Face Recognition. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6738–6746. [Google Scholar] [CrossRef] [Green Version]
- Wang, F.; Cheng, J.; Liu, W.; Liu, H. Additive margin softmax for face verification. IEEE Signal Process. Lett. 2018, 25, 926–930. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.; Chen, Y.; Yang, W.; Wang, G.; Xue, J.-H.; Liao, Q. Class-Variant Margin Normalized Softmax Loss for Deep Face Recognition. IEEE Trans. Neural Netw. Learn. Syst. 2020. [Google Scholar] [CrossRef] [PubMed]
- Zhong, Y.; Deng, W.; Hu, J.; Zhao, D.; Li, X.; Wen, D. SFace: Sigmoid-Constrained Hypersphere Loss for Robust Face Recognition. IEEE Trans. Image Process. 2021, 30, 2587–2598. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Li, H.; Wang, X. Rethinking feature discrimination and polymerization for large-scale recognition. arXiv 2017, arXiv:1710.00870. [Google Scholar]
- Ranjan, R.; Castillo, C.D.; Chellappa, R. L2-constrained softmax loss for discriminative face verification. arXiv 2017, arXiv:1703.09507. [Google Scholar]
- Wang, H.; Wang, Y.; Zhou, Z.; Ji, X.; Gong, D.; Zhou, J.; Li, Z.; Liu, W. CosFace: Large Margin Cosine Loss for Deep Face Recognition. arXiv 2018, arXiv:1801.09414. [Google Scholar]
- Liu, W.; Zhang, Y.-M.; Li, X.; Yu, Z.; Dai, B.; Zhao, T.; Song, L. Deep hyperspherical learning. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 3950–3960. [Google Scholar]
- Huang, G.-B.; Ramesh, M.; Berg, T.; Learned-Miller, E. Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments; Technical Report 07-49; University of Massachusetts: Amherst, MA, USA, 2007. [Google Scholar]
- Zhang, N.; Deng, W. Fine-grained LFW database. In Proceedings of the International Conference on Biometrics, Niagara Falls, NY, USA, 1–6 September 2016; pp. 1–6. [Google Scholar]
- Wolf, L.; Hassner, T.; Maoz, I. Face recognition in unconstrained videos with matched background similarity. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 529–534. [Google Scholar]
- Kemelmacher-Shlizerman, I.; Seitz, S.M.; Miller, D.; Brossard, E. The megaface benchmark: 1 million faces for recognition at scale. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4873–4882. [Google Scholar]
- Ng, H.W.; Winkler, S. A data-driven approach to cleaning large face datasets. In Proceedings of the Image Processing (ICIP), 2014 IEEE International Conference on, Toronto, ON, Canada, 27 April–2 May 2014; pp. 343–347. [Google Scholar]
- Wei, X.; Wang, H.; Scotney, B.; Wan, H. Gicoface: Global Information-Based Cosine Optimal Loss for Deep Face Recognition. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 3457–3461. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. arXiv 2016, arXiv:1602.07261. [Google Scholar]
- Cao, Q.; Shen, L.; Xie, W.; Parkhi, O.M.; Zisserman, A. VGGFace2: A dataset for recognising faces across pose and age. arXiv 2017, arXiv:1710.08092. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.B.; Learned-Miller, E. Labeled faces in the wild: Updates and new reporting procedures. Dept. Comput. Sci. Univ. Mass. Amherst Amherst MA USA Tech. Rep. 2014, 14, 14–003. [Google Scholar]
- Sun, Y.; Wang, X.; Tang, X. Deeply learned face representations are sparse, selective, and robust. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2892–2900. [Google Scholar]
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. DeepFace: Closing the Gap to Human-Level Performance in Face Verification. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR ’14), Washington, DC, USA, 23–28 June 2014; IEEE Computer Society: Washington, DC, USA, 2014; pp. 1701–1708. [Google Scholar]
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. Web-scale training for face identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2746–2754. [Google Scholar]
- Tadmor, O.; Rosenwein, T.; Shalev-Shwartz, S.; Wexler, Y.; Shashua, A. Learning a Metric Embedding for Face Recognition Using the Multibatch Method. In Proceedings of the 30th International Conference on Neural Information Processing Systems (NIPS’16); Curran Associates Inc.: Red Hook, NY, USA, 2016; pp. 1396–1397. [Google Scholar]
- Masi, I.; Tran, A.T.; Hassner, T.; Leksut, J.T.; Medioni, G. Do We Really Need to Collect Millions of Faces for Effective Face Recognition? In Computer Vision—ECCV; (Lecture Notes in Computer Science); Springer: Cham, Switzerland, 2016; pp. 579–596. [Google Scholar]
- Deng, W.; Hu, J.; Zhang, N.; Chen, B.; Guo, J. Fine-grained face verification: FGLFW database, baselines, and human-DCMN partnership. Pattern Recognit. 2017, 66, 63–73. [Google Scholar] [CrossRef]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep Face Recognition. In Proceedings of the 2015 British Machine Vision Conference (BMVC), Swansea, UK, 7–10 September 2015; Volume 1, p. 6. [Google Scholar]
- Chen, B.; Deng, W.; Du, J. Noisy softmax: Improving the generalization ability of dcnn via postponing the early softmax saturation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]



{kind=link}
{kind=link}
| Optimize Intra-Class Variance | Optimize Inter-Class Variance | WN | FN | Feedback Source | |
|---|---|---|---|---|---|
| Contrastive loss [5] | Yes | Yes | No | No | mini-batch |
| Triplet loss [4] | Yes | Yes | No | No | mini-batch |
| Center loss [1] | Yes | No | No | No | mini-batch |
| Marginal loss [2] | Yes | Yes | No | No | mini-batch |
| Range loss [3] | Yes | Yes | No | No | mini-batch |
| Fair loss [7] | No | Yes | Yes | Yes | mini-batch |
| SFace loss [12] | Yes | Yes | Yes | Yes | mini-batch |
| CVM loss [11] | Yes | Yes | No | No | mini-batch |
| L-Softmax loss [8] | No | Yes | No | No | mini-batch |
| A-Softmax loss [9] | No | Yes | Yes | No | mini-batch |
| AM-Softmax loss [10] | No | Yes | Yes | Yes | mini-batch |
| ArcFace [6] | No | Yes | Yes | Yes | mini-batch |
| Gico loss | Yes | Yes | Yes | Yes | global info |
| Notations | Interpretations |
|---|---|
| d | the number of dimensionality |
| W | the weight matrix in the final fully connected layer |
| the jth column of W | |
| the label of ith sample | |
| f | feature vector |
| the feature vector of the ith sample belonging to th class | |
| the bias term of the jth class | |
| P | the number of classes in the entire traning set |
| N | batch size |
| the class center of the th class | |
| a hyper-parameter in the center loss | |
| the weight matrix of the th class | |
| the angel between and | |
| m | inter-class constraint |
| the center of class j | |
| the farthest smaple of class j from the class center | |
| the cosine range of class j | |
| the shrink rate for adjusting the shrink speed of the learned class range | |
| A | set A |
| the sum of the K largest elements in A |
| Parameters | Values |
|---|---|
| epoch size | 320 |
| batch size | 120 |
| weight decay | 5 × 10 |
| keep probability of the fully connected layer | 0.4 |
| embeding size | 512 |
| shrink rate | 0.01 |
| initial learning rate | 0.05 |
| Methods | Images | LFW(%) | YTF(%) |
|---|---|---|---|
| ICCV17’ Range Loss [3] | 1.5M | 99.52 | 93.7 |
| CVPR15’ DeepID2+ [27] | 99.47 | 93.2 | |
| CVPR14’ Deep Face [28] | 4M | 97.35 | 91.4 |
| CVPR15’ Fusion [29] | 500M | 98.37 | |
| ICCV15’ FaceNet [4] | 200M | 99.63 | 95.1 |
| ECCV16’ Center Loss [1] | 0.7M | 99.28 | 94.9 |
| NIPS16’ Multibatch [30] | 2.6M | 98.20 | |
| ECCV16’ Aug [31] | 0.5M | 98.06 | |
| ICML16’ L-Softmax [8] | 0.5M | 98.71 | |
| CVPR17’ A-Softmax [9] | 0.5M | 99.42 | 95.0 |
| Softmax | 3.05M | 99.50 | 95.22 |
| AM-Softmax | 3.05M | 99.57 | 95.62 |
| Gico Lite A | 3.05M | 99.60 | 95.70 |
| Gico Lite B | 3.05M | 99.62 | 95.78 |
| Gico Std | 3.05M | 99.63 | 95.82 |
| Method | Images | LFW(%) | SLLFW(%) |
|---|---|---|---|
| Deep Face [28] | 0.5M | 92.87 | 78.78 |
| DeepID2 [5] | 0.2M | 95.00 | 78.25 |
| VGG Face [33] | 2.6M | 96.70 | 85.78 |
| DCMN [32] | 0.5M | 98.03 | 91.00 |
| Noisy Softmax [34] | 0.5M | 99.18 | 94.50 |
| Softmax | 3.05M | 99.50 | 96.17 |
| AM-Softmax | 3.05M | 99.57 | 98.02 |
| Gico Lite A | 3.05M | 99.60 | 98.15 |
| Gico Lite B | 3.05M | 99.62 | 98.13 |
| Gico Std | 3.05M | 99.63 | 98.17 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, X.; Du, W.; Hu, X.; Huang, J.; Min, W. GicoFace: A Deep Face Recognition Model Based on Global-Information Loss Function. Electronics 2021, 10, 2387. https://doi.org/10.3390/electronics10192387
Wei X, Du W, Hu X, Huang J, Min W. GicoFace: A Deep Face Recognition Model Based on Global-Information Loss Function. Electronics. 2021; 10(19):2387. https://doi.org/10.3390/electronics10192387
Chicago/Turabian StyleWei, Xin, Wei Du, Xiaoping Hu, Jie Huang, and Weidong Min. 2021. "GicoFace: A Deep Face Recognition Model Based on Global-Information Loss Function" Electronics 10, no. 19: 2387. https://doi.org/10.3390/electronics10192387
APA StyleWei, X., Du, W., Hu, X., Huang, J., & Min, W. (2021). GicoFace: A Deep Face Recognition Model Based on Global-Information Loss Function. Electronics, 10(19), 2387. https://doi.org/10.3390/electronics10192387