
k-NDDP: An Efficient Anonymization Model for Social Network Data Release


Abstract
:1. Introduction
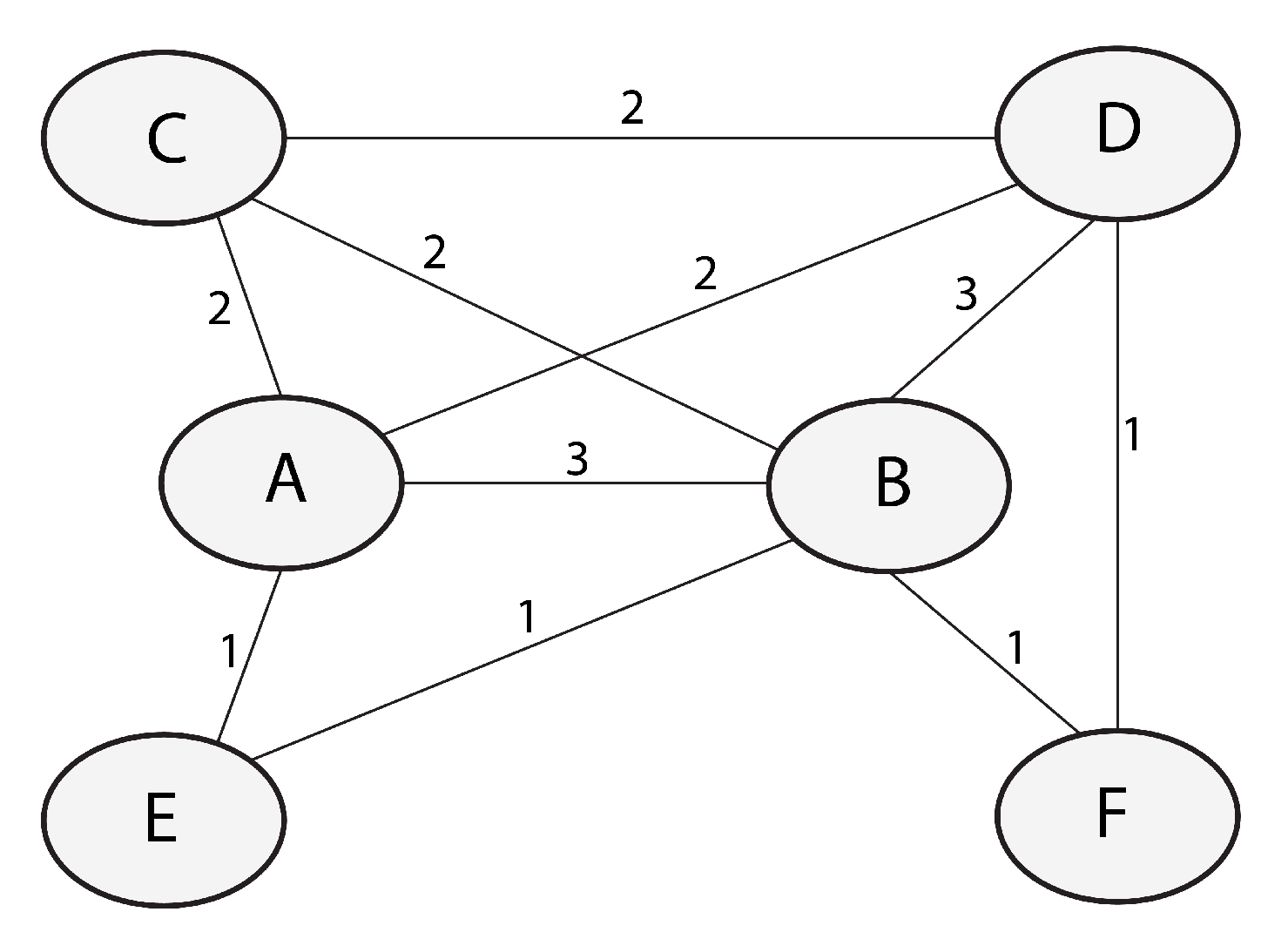
1.1. Motivational Example
1.2. Challenges
- To breach an individual’s privacy, the adversary uses a variety of background knowledge. Modeling their background knowledge, capabilities, and types of attacks it might perform on released social data is a complicated task [11]. The reason is that every bit of detail on graphs can be used to perform any attack, such as the label of vertices, no links, etc. Thus, it is very difficult and complicated to find a suitable privacy model for social networks.
- The relational data contains the list of tuples where each tuple is independent of others. Applying any anonymization method on the set of rows does not influence other rows in the relational datasets [12]. The social graph is a correlation of vertices and links, any change can affect the whole graph structure. So, it is much more challenging to choose an appropriate graph anonymization method and maintain the balance between privacy and utility [13].
- The third issue is related to data utility. Anonymization of graphs is much more different and complicated than relational datasets. Data loss is evaluated using tuples in relational datasets, whereas in social graphs it is rather different. The reason is that social data is a combination of vertices and links. Unlike relational datasets, we cannot correlate social graphs even if they have the same numbers of vertices and links [14]. Every graph is different in terms of APL, CC, and BW.
1.3. Contribution and Organization
- It proposes the concept of k–NDDP(k-Node Degree Differential Privacy) which injects noise for synthesizing the social graph and defends against identity disclosures. Then design and implementation of k-NDDP algorithm is done where the degrees are partitioned into k-anonymized groups such that degree anonymization cost is minimized and the whole social graph is reconstructed using anonymous degree sequences. The anonymized graph protects the vertices and their associated links.
- For privacy analysis, it uses the concept of differential privacy to analyze the k-NDDP in terms of privacy preservation. Furthermore, evaluates the efficiency of k-NDDP on three real-life datasets. Empirical study indicates that proposed method outputs the graph which correctly preserves the structural properties of the original graph also provides strong privacy.
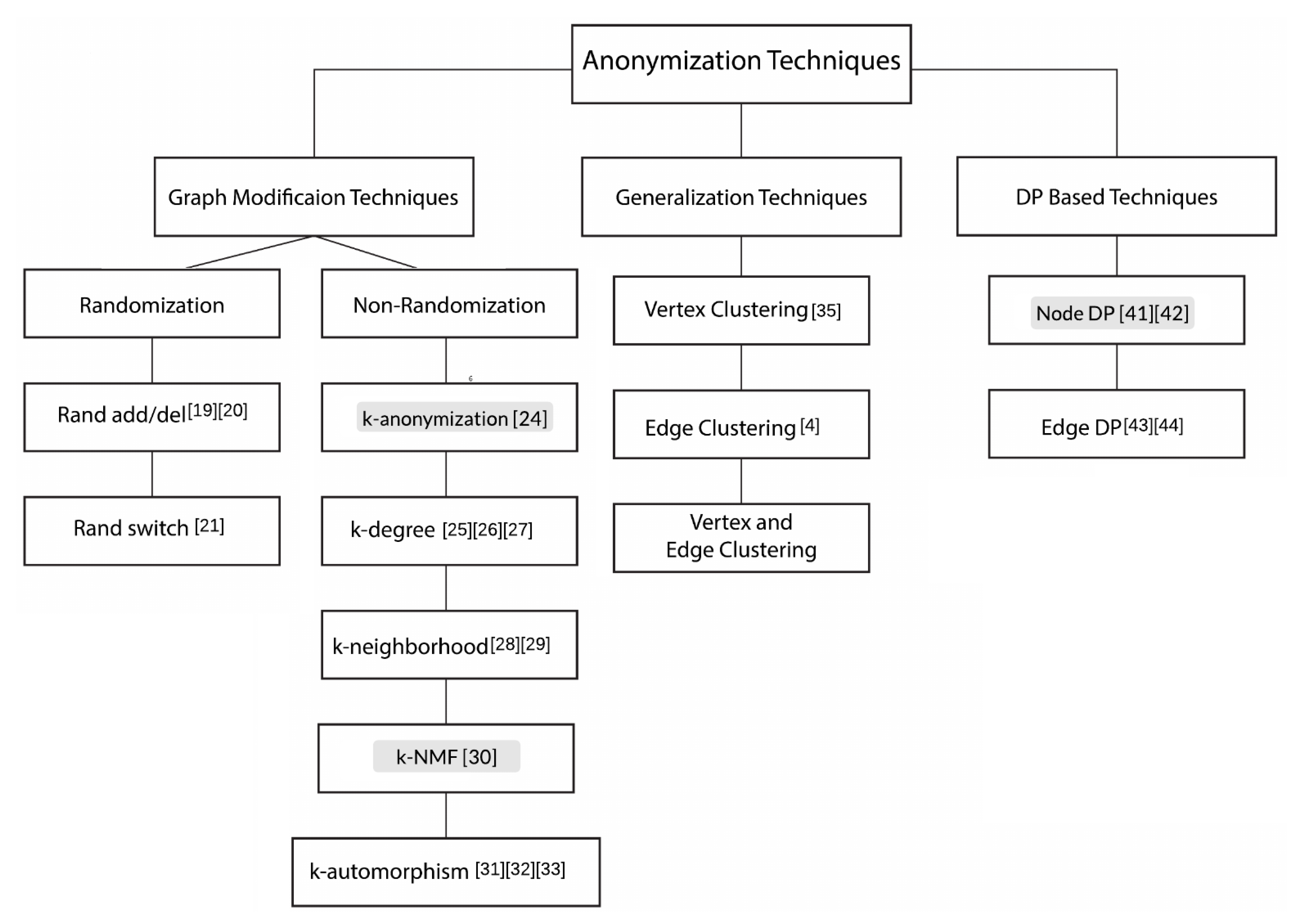
2. Related Work
2.1. Graph Modification Techniques
- k-anonymization: k-anonymization method modifies the original graph by inserting/deleting links or vertices to obtain certain requirement [24]. If an adversary has background knowledge of degrees and relationship details about its victim, it tries to re-identify the victim from the anonymized graph. Different k-anonymity based anonymization methods differ by the type of adversary’s background knowledge.
- k-degree anonymity: Degree-based anonymization methods provide prevention from attacks when the adversary uses degree information about the target as background knowledge to identify its victim from a naive anonymized graph. k-degree anonymity transforms the original graph into the new modified version by only adding vertices or links or both [25]. The main objective is to insert the minimum number of vertices or links to maintain the characteristics of the original graph. Ref. [26] proposed k-degree-based method, using a dynamic anonymization process. The method in [27] modifies the original graph into k-degree-based anonymized graph by adding fake vertices rather than new links.
- k-neighborhood anonymity: The adversary uses background knowledge of its victim’s degree and neighbor connections to perform neighborhood attack and k-neighborhood anonymity is used to provide the defense [28]. Ref. [29] proposed an algorithm to provide defense from neighborhood attacks by inserting links or vertices in the original graph until there are k vertices and their subgraphs becomes isomorphic. Ref. [30] identified an attack called mutual friend attack that occurs due to disclosure of sensitive link between two vertices. Ref. [31] proposed an algorithm (k-NMF) that adds extra links into the original graph and ensures that there must be at least other links with the same number of mutual friends.
- k-automorphism: The adversary uses background knowledge of a subgraph to identify the target from a published graph [32]. Ref. [33] proposed a method to prevent subgraph-based privacy attacks. In Ref. [34], the method modifies the original graph by providing k identical subgraphs where every vertex is automorphic with other vertices. k-automorphism provides strong security against structural subgraph attacks [35].
2.2. Generalization Techniques
2.3. DP Based Techniques
- Node Differential Privacy: Node Differential Privacy protects a vertex and its associated links. In Node Differential Privacy, social graphs and (which are obtained by adding or removing vertices and their associated links) are said to be vertex neighbors of each other Ref. [44]. Different approaches are developed to realize vertex differential privacy. Ref. [38] proposed many node differential privacy algorithms and methods to analyze the accuracy of those algorithms. Ref. [45] proposed a new concept to achieve vertex differential privacy and discussed some problems to accomplish it.
- Edge Differential Privacy: Edge Differential Privacy only protects connections between two vertices where two graphs and are link neighbors of each other. Ref. [46] presented Edge Differential Privacy technique for general subgraphs. Ref. [37] proposed an Edge DP for the case of spanning trees and triangle problems in a graph.
3. Preliminaries
3.1. Degree Sequence Partitioning ()
3.2. Degree Anonymization
3.3. Graph Reconstruction
3.4. Differential Privacy
3.5. Node DP
3.6. Identity Disclosure
3.7. Mutual Friend Attack
3.8. k-NMF
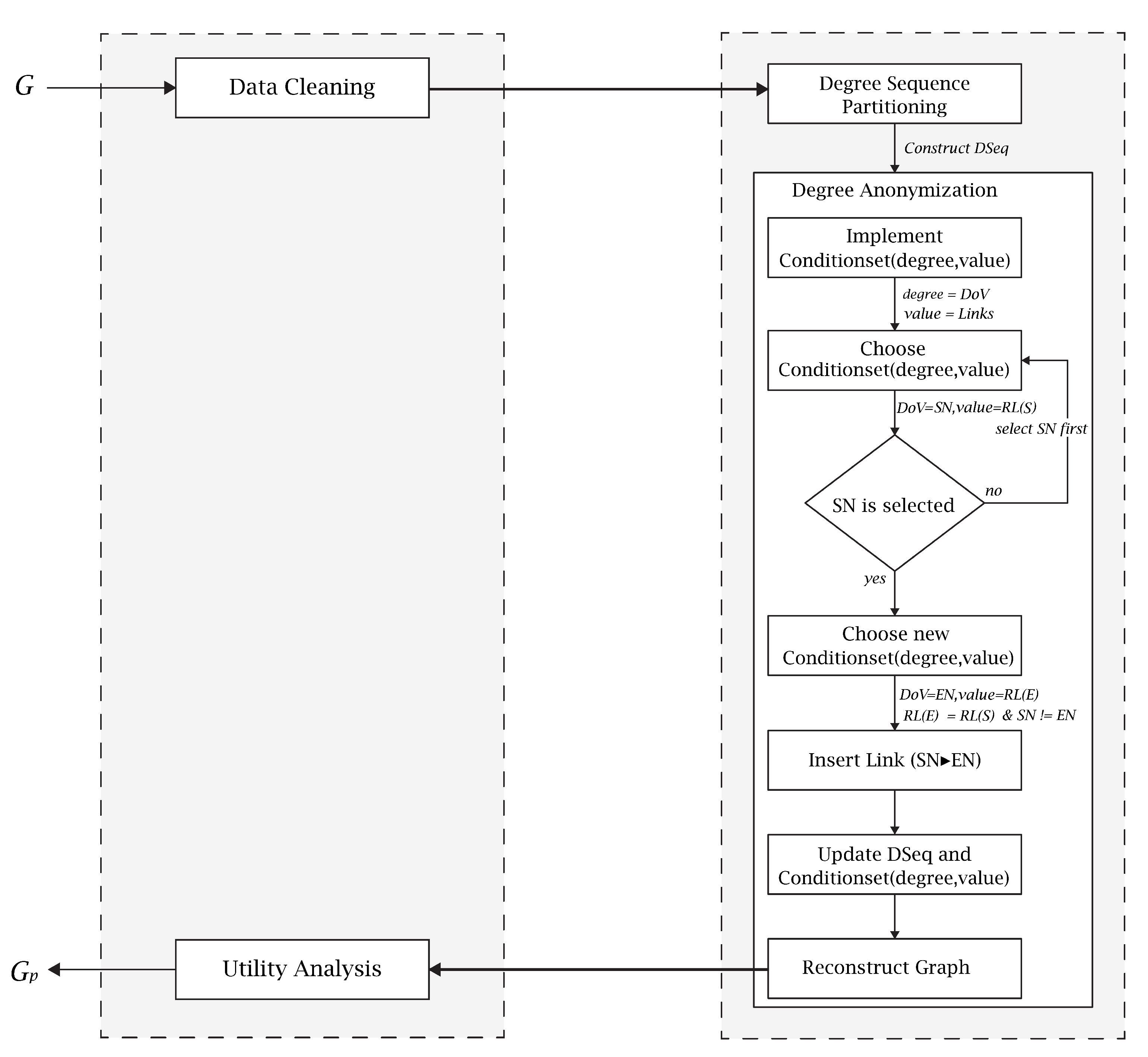
4. The Proposed -NDDP Approach
- First, it creates the sequence partitioning () of G in descending order and constructs new degree sequence partitioning () that is k-anonymous and such that degree partitioning cost is minimized.
- Given new degree sequence partitioning , it constructs a new anonymized graph such that and graph anonymization cost is minimized.
- Lastly, it uses the concept of differential privacy to analyze the proposed approach in terms of privacy protection.
4.1. Proposed Methodology
4.1.1. Degree Sequence Partitioning ()
| Algorithm 1: Degree sequence partitioning |
|
4.1.2. Degree Anonymization and Graph Reconstruction
| Algorithm 2: Degree anonymization |
|
4.1.3. Privacy Analysis
5. Experiments
5.1. Datasets
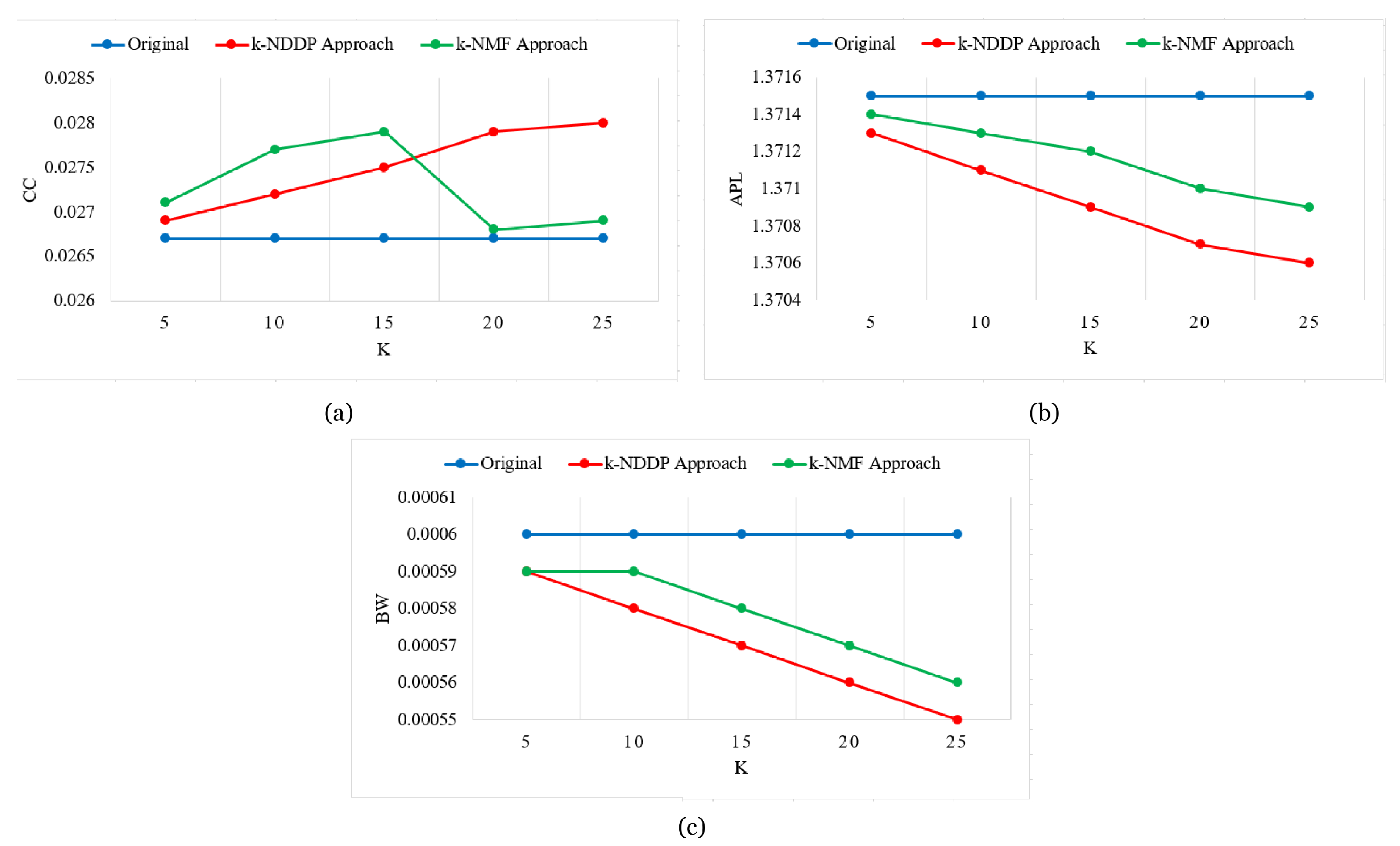
5.2. Evaluation Metrics
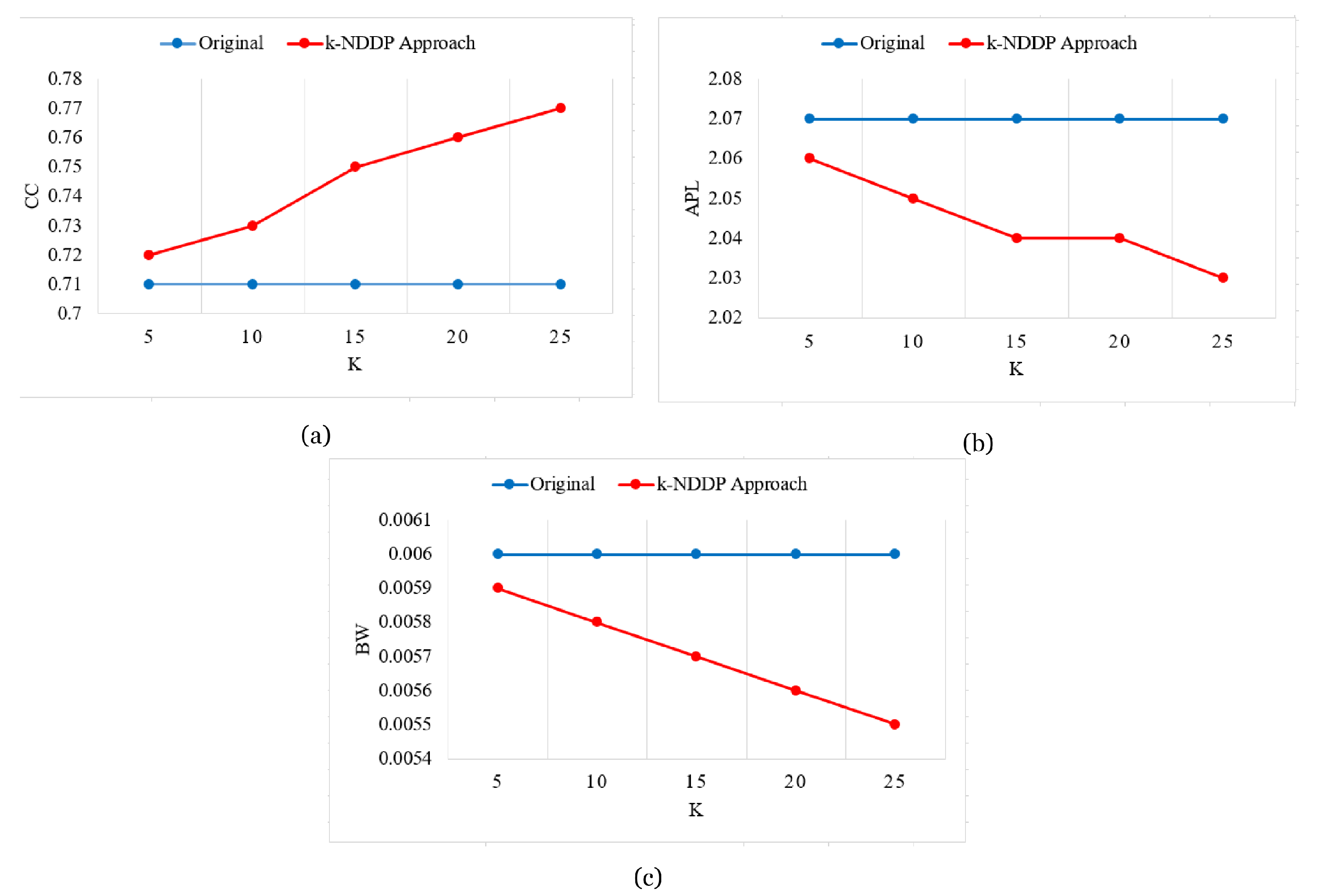
- Average shortest path length: APL measures the efficiency of information that transport through the network. This concept calculates the mean path between two vertices, which is the average shortest path length of those vertices. APL calculates the mean path for all possible pairs of network vertices by using this formula.
- Clustering coefficient: CC is a measure of the degree of vertices that make closer clusters with each other. This concept calculates the average clustering coefficient of all available vertices, which depends on localityThe clustering coefficient for the whole graph is the average of the local values .
- Betweenness centrality: BW is a measure of centrality of all vertices in the graph based on their shortest paths. It calculates the shortest path from all vertices that pass through one specific vertex. For vertex V, it is calculated using this formula.
5.3. Experimental Evaluation
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Romanini, D.; Lehmann, S.; Kivelä, M. Privacy and Uniqueness of Neighborhoods in Social Networks. arXiv 2020, arXiv:2009.09973. [Google Scholar]
- Huang, H.; Zhang, D.; Xiao, F.; Wang, K.; Gu, J.; Wang, R. Privacy-preserving approach PBCN in social network with differential privacy. IEEE Trans. Netw. Serv. Manag. 2020, 17, 931–945. [Google Scholar] [CrossRef]
- Papoutsakis, M.; Fysarakis, K.; Spanoudakis, G.; Ioannidis, S.; Koloutsou, K. Towards a Collection of Security and Privacy Patterns. Appl. Sci. 2021, 11, 1396. [Google Scholar] [CrossRef]
- Jain, R.; Jain, N.; Nayyar, A. Security and privacy in social networks: Data and structural anonymity. In Handbook of Computer Networks and Cyber Security; Springer: Cham, Switzerland, 2020; pp. 265–293. [Google Scholar]
- Kiranmayi, M.; Maheswari, N. A Review on Privacy Preservation of Social Networks Using Graphs. J. Appl. Secur. Res. 2020, 1–34. [Google Scholar] [CrossRef]
- Xian, X.; Wu, T.; Liu, Y.; Wang, W.; Wang, C.; Xu, G.; Xiao, Y. Towards link inference attack against network structure perturbation. Knowl. Based Syst. 2021, 218, 106674. [Google Scholar] [CrossRef]
- Bourahla, S.; Laurent, M.; Challal, Y. Privacy preservation for social networks sequential publishing. Comput. Netw. 2020, 170, 107106. [Google Scholar] [CrossRef]
- Jin, L.; Joshi, J.B.; Anwar, M. Mutual-friend based attacks in social network systems. Comput. Secur. 2013, 37, 15–30. [Google Scholar] [CrossRef]
- Omran, E.; Bokma, A.; Abu-Almaati, S. A k-anonymity based semantic model for protecting personal information and privacy. In Proceedings of the 2009 IEEE International Advance Computing Conference, Patiala, India, 6–7 March 2009; pp. 1443–1447. [Google Scholar]
- Hu, J. Effective and Efficient Algorithms for Large Graph Analysis. Ph.D. Thesis, University of Hong Kong, Hong Kong, 2018. [Google Scholar]
- Pensa, R.G.; Di Blasi, G.; Bioglio, L. Network-aware privacy risk estimation in online social networks. Soc. Netw. Anal. Min. 2019, 9, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Rathore, N.C.; Tripathy, S. InfoRest: Restricting Privacy Leakage to Online Social Network App. arXiv 2019, arXiv:1905.06403. [Google Scholar]
- Pham, V.V.H.; Yu, S.; Sood, K.; Cui, L. Privacy issues in social networks and analysis: A comprehensive survey. IET Netw. 2018, 7, 74–84. [Google Scholar] [CrossRef]
- Reza, K.J.; Islam, M.Z.; Estivill-Castro, V. Privacy Preservation of Social Network Users Against Attribute Inference Attacks via Malicious Data Mining. In Proceedings of the ICISSP-Proceedings of the 5th International Conference on Information Systems Security and Privacy, Prague, Czech Republic, 23–25 February 2019; pp. 412–420. [Google Scholar]
- Qiuyang, G.; Qilian, N.; Xiangzhao, M.; Zhijiao, Y. Dynamic social privacy protection based on graph mode partition in complex social network. Pers. Ubiquitous Comput. 2019, 23, 511–519. [Google Scholar] [CrossRef] [Green Version]
- Truta, T.M.; Campan, A.; Ralescu, A.L. Preservation of structural properties in anonymized social networks. In Proceedings of the 8th International Conference on Collaborative Computing: Networking, Applications and Worksharing (CollaborateCom), Pittsburgh, PA, USA, 14–17 October 2012; pp. 619–627. [Google Scholar]
- Sarah, A.K.; Tian, Y.; Al-Rodhaan, M. A Novel (K, X)-isomorphism Method for Protecting Privacy in Weighted social Network. In Proceedings of the 2018 21st Saudi Computer Society National Computer Conference (NCC), Riyadh, Saudi Arabia, 25–26 April 2018; pp. 1–6. [Google Scholar]
- Waniek, M.; Michalak, T.P.; Wooldridge, M.J.; Rahwan, T. Hiding individuals and communities in a social network. Nat. Hum. Behav. 2018, 2, 139–147. [Google Scholar] [CrossRef]
- Hay, M.; Miklau, G.; Jensen, D.; Weis, P.; Srivastava, S. Anonymizing social networks. In Computer Science Department Faculty Publication Series; UMASS AMHERST: Amherst, MA, USA, 2007; p. 180. [Google Scholar]
- Majeed, A.; Lee, S. Anonymization Techniques for Privacy Preserving Data Publishing: A Comprehensive Survey. IEEE Access 2020, 9, 8512–8545. [Google Scholar] [CrossRef]
- Ying, X.; Wu, X. Randomizing social networks: A spectrum preserving approach. In Proceedings of the 2008 SIAM International Conference on Data Mining, Atlanta, GA, USA, 24–26 April 2008; pp. 739–750. [Google Scholar]
- Li, Y.; Hu, X. Social network analysis of law information privacy protection of cybersecurity based on rough set theory. Libr. Hi Tech. 2019. ahead-of-print. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, X.; Yuan, Y.; Ni, L. RcDT: Privacy preservation based on R-constrained dummy trajectory in mobile social networks. IEEE Access 2019, 7, 90476–90486. [Google Scholar] [CrossRef]
- Hamideh Erfani, S.; Mortazavi, R. A Novel Graph-modification Technique for User Privacy-preserving on Social Networks. J. Telecommun. Inform. Technol. 2019, 3, 27–38. [Google Scholar]
- Liu, K.; Terzi, E. Towards identity anonymization on graphs. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 9–12 June 2008; pp. 93–106. [Google Scholar]
- Lu, X.; Song, Y.; Bressan, S. Fast identity anonymization on graphs. In International Conference on Database and Expert Systems Applications; Springer: Berlin/Heidelberg, Germany, 2012; pp. 281–295. [Google Scholar]
- Tabassum, S.; Pereira, F.S.; Fernandes, S.; Gama, J. Social network analysis: An overview. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1256. [Google Scholar] [CrossRef]
- Rahman, M.A.; Mezhuyev, V.; Bhuiyan, M.Z.A.; Sadat, S.N.; Zakaria, S.A.B.; Refat, N. Reliable decision making of accepting friend request on online social networks. IEEE Access 2018, 6, 9484–9491. [Google Scholar] [CrossRef]
- Zhou, B.; Pei, J. Preserving privacy in social networks against neighborhood attacks. In Proceedings of the 2008 IEEE 24th International Conference on Data Engineering, Cancun, Mexico, 7–12 April 2008; pp. 506–515. [Google Scholar]
- Gao, T.; Li, F. Protecting Social Network With Differential Privacy Under Novel Graph Model. IEEE Access 2020, 8, 185276–185289. [Google Scholar] [CrossRef]
- Macwan, K.R.; Patel, S.J. k-NMF anonymization in social network data publishing. Comput. J. 2018, 61, 601–613. [Google Scholar] [CrossRef]
- Ouafae, B.; Mariam, R.; Oumaima, L.; Abdelouahid, L.; Data Anonymization in Social Networks. EasyChair Preprint No. 2310. 2020. Available online: https://easychair.org/publications/preprint_download/dfvj (accessed on 21 December 2020).
- Chaurasia, S.K.; Mishra, N.; Sharma, S. Comparison of K-automorphism and K2-degree Anonymization for Privacy Preserving in Social Network. Int. J. Comput. Appl. 2013, 79, 30–36. [Google Scholar]
- Wu, W.; Xiao, Y.; Wang, W.; He, Z.; Wang, Z. K-symmetry model for identity anonymization in social networks. In Proceedings of the 13th International Conference on Extending Database Technology, Lausanne, Switzerland, 22–26 March 2010; pp. 111–122. [Google Scholar]
- Liu, A.X.; Li, R. Publishing Social Network Data with Privacy Guarantees. In Algorithms for Data and Computation Privacy; Springer: Cham, Switzerland, 2021; pp. 279–311. [Google Scholar]
- Hay, M.; Miklau, G.; Jensen, D.; Towsley, D.; Li, C. Resisting structural re-identification in anonymized social networks. VLDB J. 2010, 19, 797–823. [Google Scholar] [CrossRef] [Green Version]
- Al-Rabeeah, A.A.N.; Hashim, M.M. Social Network Privacy Models. Cihan Univ. Erbil Sci. J. 2019, 3, 92–101. [Google Scholar] [CrossRef]
- Qu, Y.; Yu, S.; Zhou, W.; Chen, S.; Wu, J. Customizable Reliable Privacy-Preserving Data Sharing in Cyber-Physical Social Network. IEEE Trans. Netw. Sci. Eng. 2020, 8, 269–281. [Google Scholar] [CrossRef]
- Steil, J.; Hagestedt, I.; Huang, M.X.; Bulling, A. Privacy-aware eye tracking using differential privacy. In Proceedings of the 11th ACM Symposium on Eye Tracking Research & Applications, Stuttgart, Germany, 2–5 June 2019; pp. 1–9. [Google Scholar]
- Dwork, C.; Smith, A. Differential privacy for statistics: What we know and what we want to learn. J. Priv. Confidentiality 2010, 1, 135–154. [Google Scholar] [CrossRef] [Green Version]
- Ye, M.; Barg, A. Optimal schemes for discrete distribution estimation under locally differential privacy. IEEE Trans. Inf. Theory 2018, 64, 5662–5676. [Google Scholar] [CrossRef] [Green Version]
- Qiao, K.; Hu, L.; Sun, S. Differential Security Evaluation of Simeck with Dynamic Key-guessing Techniques. IACR Cryptol. EPrint Arch. 2015, 2015, 902. [Google Scholar]
- Gao, T.; Li, F. Sharing social networks using a novel differentially private graph model. In Proceedings of the 2019 16th IEEE Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 11–14 January 2019; pp. 1–4. [Google Scholar]
- Lin, Z. Privacy Preserving Social Network Data Publishing. Ph.D. Thesis, Miami University, Oxford, OH, USA, 2021. [Google Scholar]
- Huang, W.Q.; Xia, J.F.; Yu, M.; Liu, C. Personal Privacy Metric based on Public Social Network Data. J. Phys. 2018, 1087, 032007. [Google Scholar] [CrossRef]
- Fu, Y.; Wang, W.; Fu, H.; Yang, W.; Yin, D. Privacy Preserving Social Network Against Dopv Attacks. In International Conference on Web Information Systems Engineering; Springer: Cham, Switzerland, 2018; pp. 178–188. [Google Scholar]
- Rossi, R.A.; Ahmed, N.K. The Network Data Repository with Interactive Graph Analytics and Visualization. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Leskovec, J.; Krevl, A. SNAP Datasets: Stanford Large Network Dataset Collection. 2014. Available online: http://snap.stanford.edu/data (accessed on 15 January 2021).
- Traud, A.L.; Mucha, P.J.; Porter, M.A. Social structure of Facebook networks. Physic A 2012, 391, 4165–4180. [Google Scholar] [CrossRef] [Green Version]
- Rozemberczki, B.; Sarkar, R. Characteristic Functions on Graphs: Birds of a Feather, from Statistical Descriptors to Parametric Models. In Proceedings of the 29th ACM International Conference on Information and Knowledge Management (CIKM ’20), Online, 19–23 October 2020; pp. 1325–1334. [Google Scholar]
- Mohamed, E.M.; Agouti, T.; Tikniouine, A.; El Adnani, M. A comprehensive literature review on community detection: Approaches and applications. Procedia Comput. Sci. 2019, 151, 295–302. [Google Scholar]
- Zhang, X.K.; Ren, J.; Song, C.; Jia, J.; Zhang, Q. Label propagation algorithm for community detection based on node importance and label influence. Phys. Lett. A 2017, 381, 2691–2698. [Google Scholar] [CrossRef]
- Zhang, J.; Luo, Y. Degree centrality, betweenness centrality, and closeness centrality in social network. In. 2017 2nd International Conference on Modelling, Simulation and Applied Mathematics (MSAM2017), Chengdu, China, 2–4 June 2017; pp. 300–303. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. No. | Technique | Anonymization Strategy | Advantages | Limitations |
|---|---|---|---|---|
| [24] | k-anonymization | Add or deletes links/vertices | Protects link identity | High algorithm complexity |
| [19] | Rand add/del | Randomly adds or deletes links/vertices | Maintain the actual number of links | Not considered any adversarial attack |
| [36] | Vertex Clustering | Vertex clustering | Allow structural queries from different domains | Difficult to analyze local structural details in the graph |
| [4] | Edge Clustering | Vertex generalization | Balances utility and privacy | Execution time increases with generalization |
| [37] | Edge Differential Privacy | Link addition or deletion | Protect relation between two vertices | Susceptible to vertex identification |
| [38] | Node Differential Privacy | Vertex modification | Protect vertex and adjacent links | N/A |
| [25] | k-degree anonymity | Addition of fake links/vertices | Conserve much of the characteristics of the graph. Prevent vertex identification problem | Unsecured neighbor connections |
| [31] | k-NMF | Fake links addition | Protect sensitive links between vertices | Unsecured neighbor connections and Increased runtime |
| [34] | k-automorphism | Vertex modification | Strong security against structural subgraph attacks | Susceptible to identity disclosure |
| [21] | Rand switch | Switch old links with new links | Preserve spectral characteristics of the graph | Not considered any adversarial attack |
| [29] | k-neighborhood anonymity | Fake vertices and links addition | Re-identification attack protection | Utility loss (extreme change) |
| Links in G | Non-Links in G | Sum | |
|---|---|---|---|
| Links in | |||
| Non-Links in | |||
| Sum |
| k | APL | CC | BW |
|---|---|---|---|
| 0 | 2.65 | 0.0040 | 0.015 |
| 5 | 2.64 | 0.0041 | 0.014 |
| 10 | 2.63 | 0.0043 | 0.013 |
| 15 | 2.62 | 0.0045 | 0.012 |
| 20 | 2.60 | 0.0048 | 0.011 |
| 25 | 2.60 | 0.0049 | 0.010 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shakeel, S.; Anjum, A.; Asheralieva, A.; Alam, M. k-NDDP: An Efficient Anonymization Model for Social Network Data Release. Electronics 2021, 10, 2440. https://doi.org/10.3390/electronics10192440
Shakeel S, Anjum A, Asheralieva A, Alam M. k-NDDP: An Efficient Anonymization Model for Social Network Data Release. Electronics. 2021; 10(19):2440. https://doi.org/10.3390/electronics10192440
Chicago/Turabian StyleShakeel, Shafaq, Adeel Anjum, Alia Asheralieva, and Masoom Alam. 2021. "k-NDDP: An Efficient Anonymization Model for Social Network Data Release" Electronics 10, no. 19: 2440. https://doi.org/10.3390/electronics10192440
APA StyleShakeel, S., Anjum, A., Asheralieva, A., & Alam, M. (2021). k-NDDP: An Efficient Anonymization Model for Social Network Data Release. Electronics, 10(19), 2440. https://doi.org/10.3390/electronics10192440