
A Low-Cost Hardware-Friendly Spiking Neural Network Based on Binary MRAM Synapses, Accelerated Using In-Memory Computing


Abstract
:1. Introduction
- We proposed a low-cost hardware-friendly spiking neuron network architecture with a small number of neurons and synapses. It is based on binary MRAM devices and can be accelerated using in-memory computing to implement high-efficiency neuromorphic computation.
- We introduced a discretized learning rule to train the network. It is specially optimized for fixed-point weights, which lowers the hardware complexity, but is still able to reach convergence within much fewer samples than other works can.
- We tested our network and learning rule on the MNIST dataset, and the result showed that the recognizing accuracy is decent enough compared to other similar works, and it has great robustness against MRAM’s technology problems. It even works well in ultra-low-cost situations.
2. High Accuracy, Low Sample Size, Hardware-Friendly SNN Based on MTJ Synapses
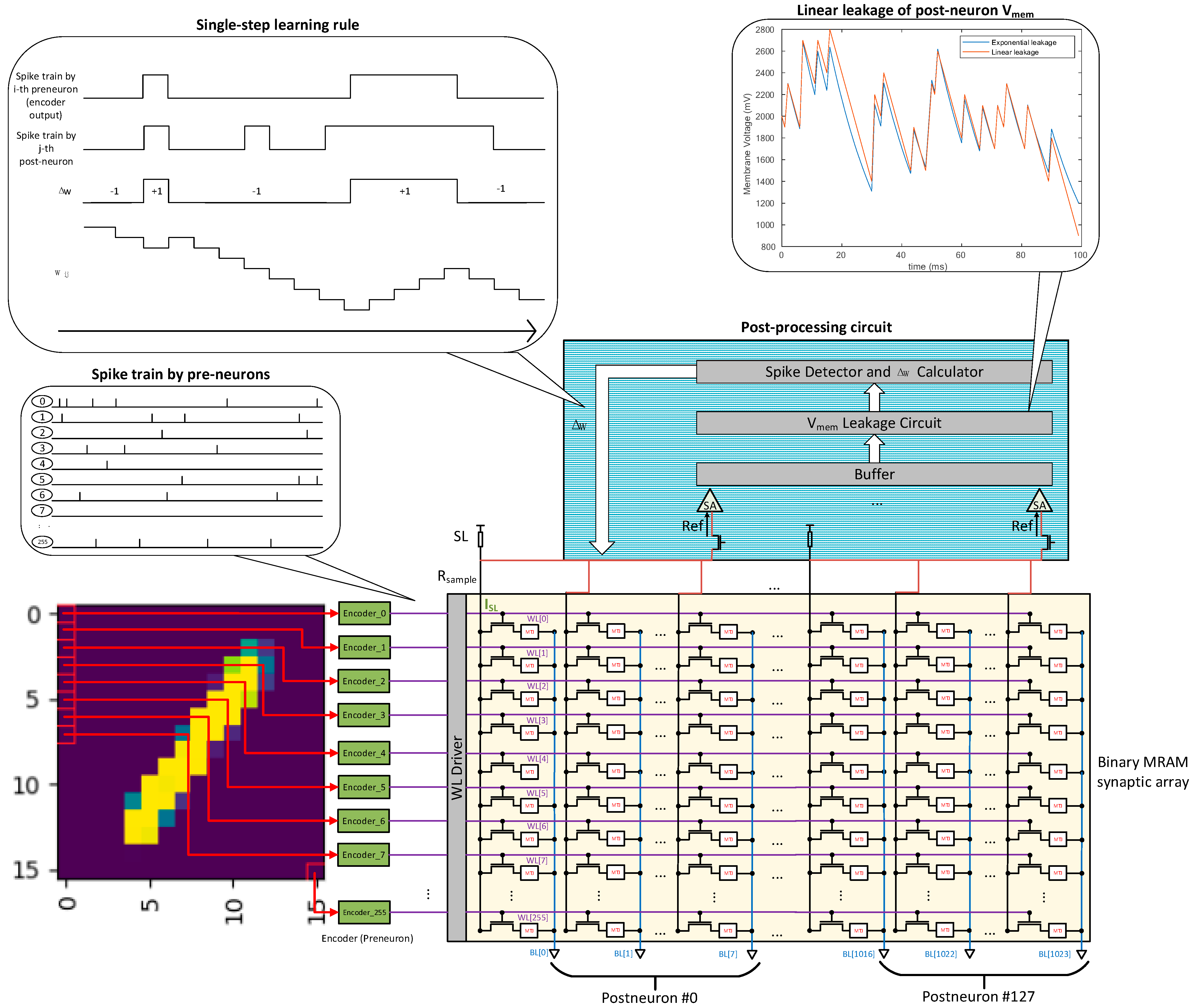
2.1. SNN Architecture
2.1.1. Binary MRAM-Based Synaptic Array
2.1.2. Multi-Mode Input Encoder with Spike Sparsity
2.1.3. Learning Rule with Single-Step Fixed-Point Weight Update
2.1.4. Feature Layer Neuron Model with Linear Leakage
2.2. SNN Workflow
2.2.1. Training
- In the preparation stage, the system receives image data from PC and saves it to the buffer. After the grayscale values of all pixels of the entire picture are received, this stage ends.
- In the CIM stage, the grayscale data in the buffer is encoded to generate spike trains in the time domain. These output spike trains will be overdriven and sent to the wordlines of the MRAM array. Then, the signals will be kept for a period of time while the MAC (multiply-accumulate) operation is being performed. The calculated results will be sensed and read from bitlines when stable. By checking the value of leakage timer, the membrane potential with leakage can be obtained. Finally, by comparing the membrane potential with the threshold voltage through a digital comparator, the response of the feature layer neuron (whether it fires) can be obtained.
- In the update stage, the weight change Δw of the synapse can be calculated according to the feature layer neurons’ response. We use ‘0’ to represent the Δw = +1 level, and ‘1’ to represent the Δw = −1 level; then, the feature layer neuron and the input layer neuron’s state registers only need to be bitwise-ANDed to obtain the value of Δw. After that, the weight value that needs to be changed is updated.
2.2.2. Pre-Classification
2.2.3. Classification
3. Results
3.1. Simulation Environment
3.2. Network Parameters
3.3. Results and Analysis
3.3.1. Number of Input Layer and Feature Layer Neurons
3.3.2. Training Samples
3.3.3. Pre-Classification Samples
3.3.4. Encoding Scheme
3.3.5. Weight Precision
3.3.6. Learning Rule
3.3.7. Resistance Fluctuation of MTJ
3.3.8. Comparison
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Akopyan, F.; Sawada, J.; Cassidy, A.; Alvarez-Icaza, R.; Arthur, J.V.; Merolla, P.; Imam, N.; Nakamura, Y.Y.; Datta, P.; Nam, G.-J.; et al. TrueNorth: Design and Tool Flow of a 65 mW 1 Million Neuron Programmable Neurosynaptic Chip. IEEE Trans. Comput. Des. Integr. Circuits Syst. 2015, 34, 1537–1557. [Google Scholar] [CrossRef]
- Davies, M.; Srinivasa, N.; Lin, T.-H.; Chinya, G.; Cao, Y.; Choday, S.H.; Dimou, G.; Joshi, P.; Imam, N.; Jain, S.; et al. Loihi: A Neuromorphic Manycore Processor with On-Chip Learning. IEEE Micro 2018, 38, 82–99. [Google Scholar] [CrossRef]
- Ambrogio, S.; Narayanan, P.; Tsai, H.; Shelby, R.M.; Boybat, I.; Di Nolfo, C.; Sidler, S.; Giordano, M.; Bodini, M.; Farinha, N.C.P.; et al. Equivalent-accuracy accelerated neural-network training using analogue memory. Nat. Cell Biol. 2018, 558, 60–67. [Google Scholar] [CrossRef] [PubMed]
- Borghetti, J.; Snider, G.S.; Kuekes, P.J.; Yang, J.J.; Stewart, D.R.; Williams, S. ‘Memristive’ switches enable ‘stateful’ logic operations via material implication. Nat. Cell Biol. 2010, 464, 873–876. [Google Scholar] [CrossRef] [PubMed]
- Zhu, X.; Yang, X.; Wu, C.; Xiao, N.; Wu, J.; Yi, X. Performing Stateful Logic on Memristor Memory. IEEE Trans. Circuits Syst. II Express Briefs 2013, 60, 682–686. [Google Scholar] [CrossRef]
- Hu, M.; Graves, C.; Li, C.; Li, Y.; Ge, N.; Montgomery, E.; Davila, N.; Jiang, H.; Williams, R.S.; Yang, J.J.; et al. Memristor-Based Analog Computation and Neural Network Classification with a Dot Product Engine. Adv. Mater. 2018, 30, 1705914. [Google Scholar] [CrossRef] [PubMed]
- Payvand, M.; Nair, M.V.; Müller, L.K.; Indiveri, G. A neuromorphic systems approach to in-memory computing with non-ideal memristive devices: From mitigation to exploitation. Faraday Discuss. 2018, 213, 487–510. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning Internal Representations by Error Propagation; California Univ San Diego La Jolla Inst for Cognitive Science: San Diego, CA, USA, 1985. [Google Scholar]
- Bohte, S.M.; Kok, J.N.; La Poutré, H. Error-backpropagation in temporally encoded networks of spiking neurons. Neurocomputing 2002, 48, 17–37. [Google Scholar] [CrossRef] [Green Version]
- Lee, J.H.; Delbruck, T.; Pfeiffer, M. Training Deep Spiking Neural Networks Using Backpropagation. Front. Neurosci. 2016, 10, 508. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shrestha, A.; Fang, H.; Wu, Q.; Qiu, Q. Approximating Back-propagation for a Biologically Plausible Local Learning Rule in Spiking Neural Networks. In Proceedings of the International Conference on Neuromorphic Systems, 23 July 2019, Oak Ridge, TN, USA; ACM Press: New York, NY, USA, 2019; pp. 1–8. [Google Scholar]
- Rueckauer, B.; Lungu, L.-A.; Hu, Y.; Pfeiffer, M. Theory and tools for the conversion of analog to spiking convolutional neural networks. arXiv 2016, arXiv:1612.04052. [Google Scholar]
- Rueckauer, B.; Lungu, I.-A.; Hu, Y.; Pfeiffer, M.; Liu, S.-C. Conversion of Continuous-Valued Deep Networks to Efficient Event-Driven Networks for Image Classification. Front. Neurosci. 2017, 11, 682. [Google Scholar] [CrossRef] [PubMed]
- Rueckauer, B.; Liu, S.-C. Conversion of analog to spiking neural networks using sparse temporal coding. In Proceedings of the 2018 IEEE International Symposium on Circuits and Systems (ISCAS), Florence, Italy, 27–30 May 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–5. [Google Scholar]
- Midya, R.; Wang, Z.; Asapu, S.; Joshi, S.; Li, Y.; Zhuo, Y.; Song, W.; Jiang, H.; Upadhay, N.; Rao, M.; et al. Artificial Neural Network (ANN) to Spiking Neural Network (SNN) Converters Based on Diffusive Memristors. Adv. Electron. Mater. 2019, 5, 1900060. [Google Scholar] [CrossRef]
- Sengupta, A.; Ye, Y.; Wang, R.; Liu, C.; Roy, K. Going Deeper in Spiking Neural Networks: VGG and Residual Architectures. Front. Neurosci. 2019, 13, 95. [Google Scholar] [CrossRef] [PubMed]
- Diehl, P.U.; Cook, M. Unsupervised learning of digit recognition using spike-timing-dependent plasticity. Front. Comput. Neurosci. 2015, 9, 99. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Querlioz, D.; Bichler, O.; Dollfus, P.; Gamrat, C. Immunity to Device Variations in a Spiking Neural Network with Memristive Nanodevices. IEEE Trans. Nanotechnol. 2013, 12, 288–295. [Google Scholar] [CrossRef] [Green Version]
- Thiele, J.C.; Bichler, O.; Dupret, A. Event-Based, Timescale Invariant Unsupervised Online Deep Learning With STDP. Front. Comput. Neurosci. 2018, 12, 46. [Google Scholar] [CrossRef] [PubMed]
- Pan, Y.; Ouyang, P.; Zhao, Y.; Kang, W.; Yin, S.; Zhang, Y.; Zhao, W.; Wei, S. A Multilevel Cell STT-MRAM-Based Computing In-Memory Accelerator for Binary Convolutional Neural Network. IEEE Trans. Magn. 2018, 54, 1–5. [Google Scholar] [CrossRef]
- Pan, Y.; Ouyang, P.; Zhao, Y.; Kang, W.; Yin, S.; Zhang, Y.; Zhao, W.; Wei, S. A MLC STT-MRAM based Computing in-Memory Architec-ture for Binary Neural Network. In Proceedings of the 2018 IEEE International Magnetics Conference (INTERMAG), Singapore, 23–27 April 2018; IEEE: Piscataway, NJ, USA, 2018; p. 1. [Google Scholar]
- Zhou, E.; Fang, L.; Yang, B. Memristive Spiking Neural Networks Trained with Unsupervised STDP. Electronics 2018, 7, 396. [Google Scholar] [CrossRef] [Green Version]
- Wang, N.; Choi, J.; Brand, D.; Chen, C.-Y.; Gopalakrishnan, K. Training deep neural networks with 8-bit floating point numbers. arXiv 2018, arXiv:1812.08011. [Google Scholar]
- Zhang, Y.; Zhang, L.; Wujie, W.G.; Yiran, S.C. Multi-level cell STT-RAM: Is it realistic or just a dream? In Proceedings of the 2012 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), San Jose, CA, USA, 5–8 November 2012. [Google Scholar]
- Jouppi, N.P.; Young, C.; Patil, N.; Patterson, D.; Agrawal, G.; Bajwa, R.; Bates, S.; Bhatia, S.; Boden, N.; Borchers, A.; et al. In-Datacenter Performance Analysis of a Tensor Processing Unit. In Proceedings of the 44th Annual International Symposium on Computer Architecture, Association for Computing Machinery, Toronto, ON, Canada, 24–28 June 2017; pp. 1–12. [Google Scholar]
- Sanders, J.; Kandrot, E. CUDA By Example: An Introduction to General-Purpose GPU Programming; Addison-Wesley Professional: Boston, MA, USA, 2010. [Google Scholar]
- Heeger, D. Poisson Model of Spike Generation Handout; University of Standford: Stanford, CA, USA, 2000; Volume 5, p. 76. [Google Scholar]
- Zhao, Z.; Qu, L.; Wang, L.; Deng, Q.; Li, N.; Kang, Z.; Guo, S.; Xu, W. A Memristor-Based Spiking Neural Network With High Scalability and Learning Efficiency. IEEE Trans. Circuits Syst. II Express Briefs 2020, 67, 931–935. [Google Scholar] [CrossRef]
- Zhang, T.; Zheng, Y.; Zhao, D.; Shi, M. A Plasticity-Centric Approach to Train the Non-Differential Spiking Neural Networks. In Proceedings of the The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18), New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Lv, M.; Shao, C.; Li, H.; Li, J.; Sun, T. A novel spiking neural network with the learning strategy of biomimetic structure. In Proceedings of the 2021 Asia-Pacific Conference on Communications Technology and Computer Science (ACCTCS), Shenyang, China, 22–24 January 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 69–74. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Number of input neurons | 256~784 |
| Max firing rate | 156.25 Hz |
| Pulse length | 25 ms |
| Number of feature neurons | 100~800 |
| Threshold voltage (Vth) | 256 levels or 2.5 V fixed |
| Time window length | 350 ms |
| Pulse length | 25 ms |
| Inhibition length | 15 ms |
| Timestep | 100 μs |
| Time constant (τm) | 50 ms |
| Number of synapses | 25,600~627,200 |
| Max value | 250 (1.000) |
| Min value | 1 (0.004) |
| Precision | 8-bit (250 levels) |
| Feature Neurons | Encoding Scheme | Accuracy | Feature Neurons | Encoding Scheme | Accuracy | Feature Neurons | Encoding Scheme | Accuracy |
|---|---|---|---|---|---|---|---|---|
| 100 | Poisson | 85.6% | 400 | Poisson | 90.6% | 800 | Poisson | 93.0% |
| 100 | 8-bit variable-rate | 81.9% | 400 | 8-bit variable-rate | 88.3% | 800 | 8-bit variable-rate | 91.0% |
| 100 | 1-bit fixed-rate | 73.0% | 400 | 1-bit fixed-rate | 80.8% | 800 | 1-bit fixed-rate | 82.5% |
| Feature Neurons | Weight Precision | Accuracy | Feature Neurons | Weight Precision | Accuracy | Feature Neurons | Weight Precision | Accuracy |
|---|---|---|---|---|---|---|---|---|
| 100 | 8-bit | 85.6% | 400 | 8-bit | 90.6% | 800 | 8-bit | 93.0% |
| 100 | 1-bit | 80.9% | 400 | 1-bit | 88.0% | 800 | 1-bit | 92.6% |
| Feature Neurons | Learning Rule | Accuracy | Feature Neurons | Learning Rule | Accuracy | Feature Neurons | Learning Rule | Accuracy |
|---|---|---|---|---|---|---|---|---|
| 100 | Exponential | 76.4% | 400 | Exponential | 88.8% | 800 | Exponential | 93.7% |
| 100 | Single-step | 73.0% | 400 | Single-step | 88.3% | 800 | Single-step | 93.0% |
| Architecture | Two-Layer SNN [17] | Two-Layer SNN [18] | Two-Layer SNN [22] | Two-Layer SNN [28] | Three-Layer SNN [29] | Four-Layer SNN [30] | This Work | This Work |
|---|---|---|---|---|---|---|---|---|
| Learning Rule | Exponential | Rectangular | Exponential | Exponential | Exponential | Exponential | Single-step | Single-step |
| EncodingScheme | Rate | Rate | Temporal | Rate | Rate | Rate | Rate (multi-mode) | Rate (multi-mode) |
| Pixel Depth | 8-bit | 8-bit | 8-bit | 8-bit | 8-bit | 8-bit | 8-bit | 1-bit |
| Vmem Leakage | Exponential | Exponential | Exponential | Exponential | Exponential | Exponential | Exponential | Linear |
| Lateral Inhibition | Yes | Yes | No | Simplified | No | Yes | Yes | Yes |
| Threshold Voltage | Adaptive, Analog | Adaptive, Analog | Fixed | Adaptive, Analog | Adaptive, Analog | Adaptive, Analog | 256-level | Fixed |
| Total Neurons | 2384 | 1084 | 7184 | 1184 | 5294 | 1595 | 1184/384 | 384 |
| Total Synapses | 1,254,400 | 235,200 | 5,017,600 | 313,600 | 3,573,000 | 318,400 | 313,600/32,768 | 32,768 |
| Training Samples | 900,000 | 180,000 | 60,000 | >100,000 | 60,000 | >150,000 | <30,000/<12,000 | <4000 |
| Accuracy | 95.0% | 93.5% | 94.6% | 91.7% | 98.5% | 92.1% | 90.6%/84.0% | 77.0% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Wu, D.; Wang, Y.; Hu, X.; Ma, Z.; Feng, J.; Xie, Y. A Low-Cost Hardware-Friendly Spiking Neural Network Based on Binary MRAM Synapses, Accelerated Using In-Memory Computing. Electronics 2021, 10, 2441. https://doi.org/10.3390/electronics10192441
Wang Y, Wu D, Wang Y, Hu X, Ma Z, Feng J, Xie Y. A Low-Cost Hardware-Friendly Spiking Neural Network Based on Binary MRAM Synapses, Accelerated Using In-Memory Computing. Electronics. 2021; 10(19):2441. https://doi.org/10.3390/electronics10192441
Chicago/Turabian StyleWang, Yihao, Danqing Wu, Yu Wang, Xianwu Hu, Zizhao Ma, Jiayun Feng, and Yufeng Xie. 2021. "A Low-Cost Hardware-Friendly Spiking Neural Network Based on Binary MRAM Synapses, Accelerated Using In-Memory Computing" Electronics 10, no. 19: 2441. https://doi.org/10.3390/electronics10192441
APA StyleWang, Y., Wu, D., Wang, Y., Hu, X., Ma, Z., Feng, J., & Xie, Y. (2021). A Low-Cost Hardware-Friendly Spiking Neural Network Based on Binary MRAM Synapses, Accelerated Using In-Memory Computing. Electronics, 10(19), 2441. https://doi.org/10.3390/electronics10192441