
Ensemble-Based Out-of-Distribution Detection



Abstract
:1. Introduction
2. Related Work
2.1. OOD Detection Methods
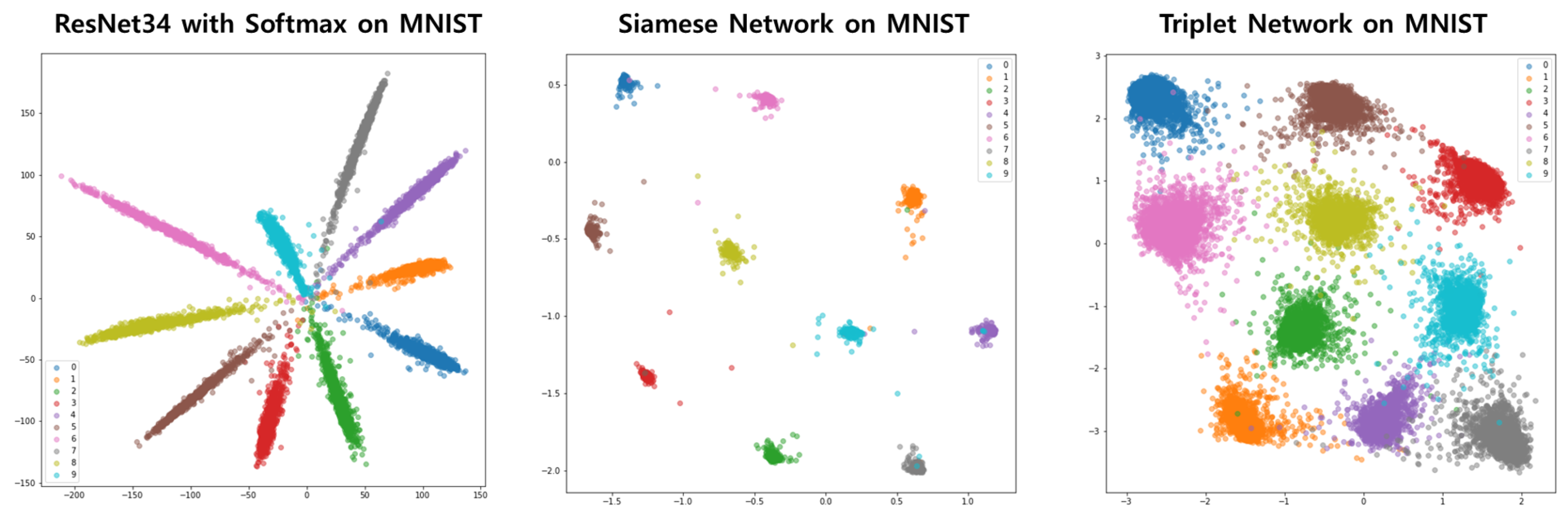
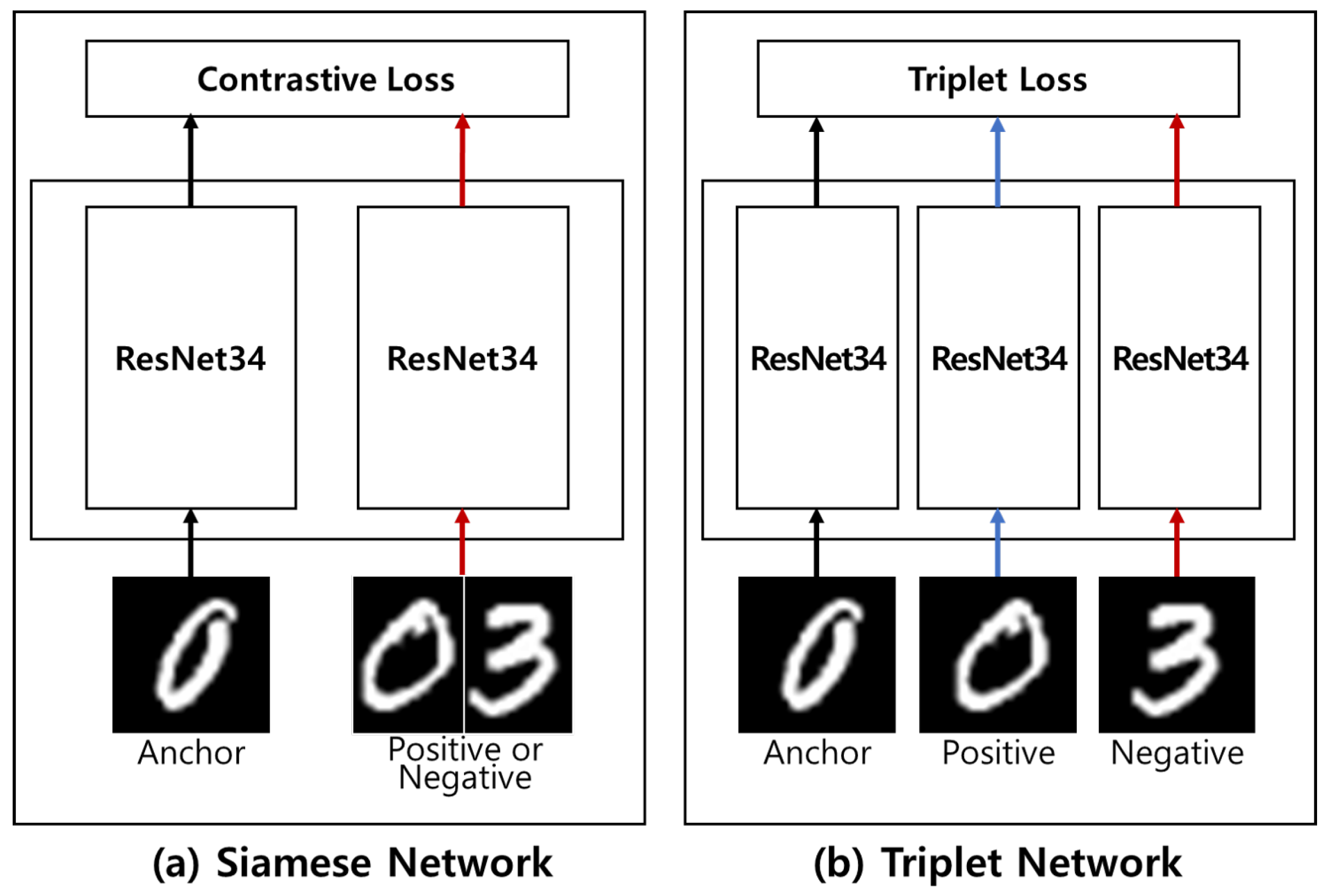
2.2. Networks Based on Distance Metric Learning (DML)
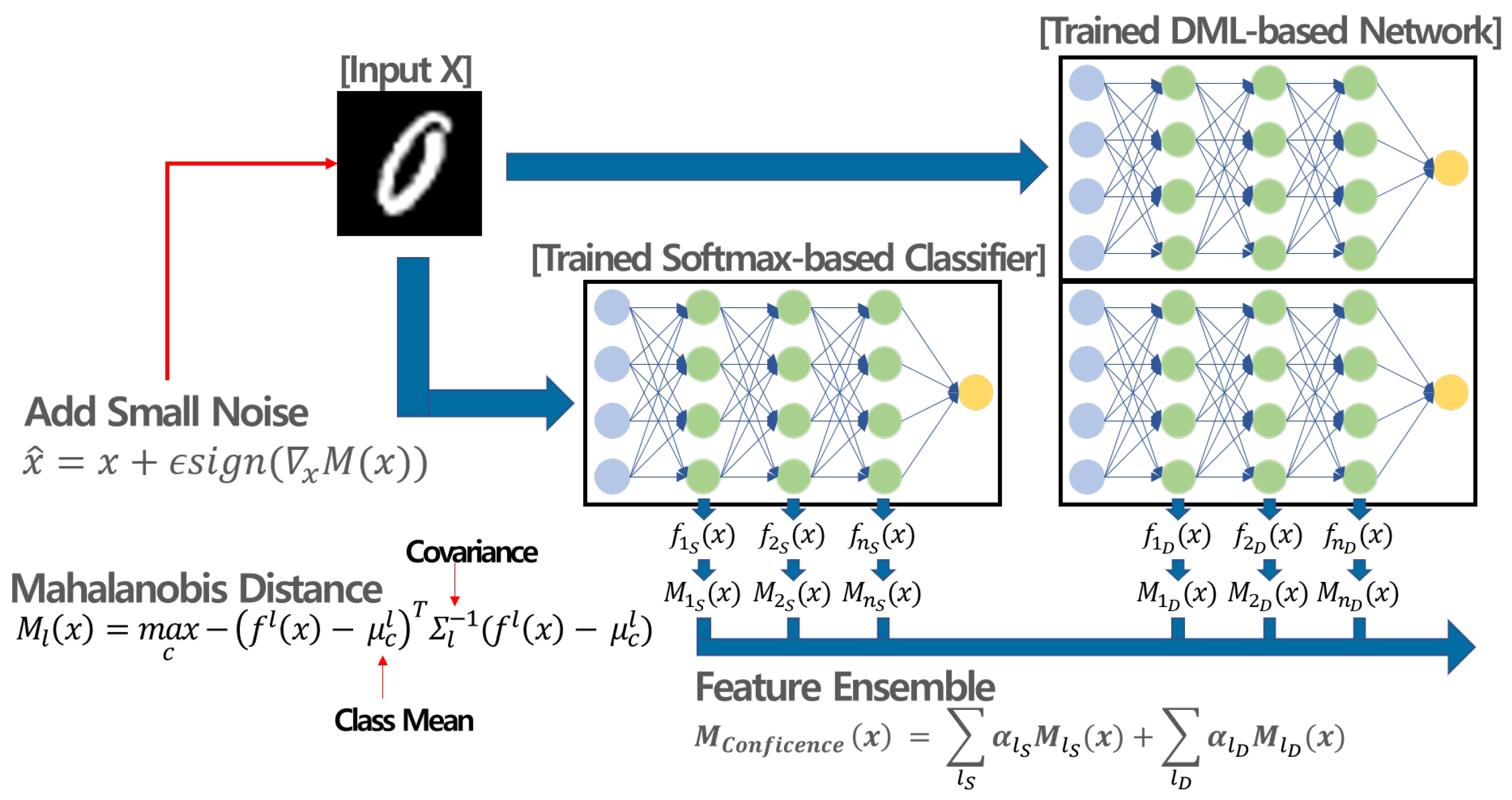
3. Methodology
4. Experiments
4.1. Experimental Setup
4.2. Experimental Results on 1-Channel Image Datasets
4.3. Experimental Results on 3-Channel Image Datasets
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Hannun, A.; Case, C.; Casper, J.; Catanzaro, B.; Diamos, G.; Elsen, E.; Prenger, R.; Satheesh, S.; Sengupta, S.; Coates, A.; et al. Deep speech: Scaling up end-to-end speech recognition. arXiv 2014, arXiv:1412.5567. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. Master’s Thesis, University of Toronto, Toronto, ON, Canada, 2009. [Google Scholar]
- Villegas, R.; Yang, J.; Zou, Y.; Sohn, S.; Lin, X.; Lee, H. Learning to generate long-term future via hierarchical prediction. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 3560–3569. [Google Scholar]
- Tulyakov, S.; Liu, M.Y.; Yang, X.; Kautz, J. Mocogan: Decomposing motion and content for video generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1526–1535. [Google Scholar]
- Caruana, R.; Lou, Y.; Gehrke, J.; Koch, P.; Sturm, M.; Elhadad, N. Intelligible models for healthcare: Predicting pneumonia risk and hospital 30-day readmission. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 1721–1730. [Google Scholar]
- Wu, N.; Phang, J.; Park, J.; Shen, Y.; Huang, Z.; Zorin, M.; Jastrzębski, S.; Févry, T.; Katsnelson, J.; Kim, E.; et al. Deep neural networks improve radiologists’ performance in breast cancer screening. IEEE Trans. Med. Imaging 2019, 39, 1184–1194. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hsu, Y.C.; Shen, Y.; Jin, H.; Kira, Z. Generalized ODIN: Detecting out-of-distribution image without learning from out-of-distribution data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10951–10960. [Google Scholar]
- Amodei, D.; Olah, C.; Steinhardt, J.; Christiano, P.; Schulman, J.; Mané, D. Concrete problems in AI safety. arXiv 2016, arXiv:1606.06565. [Google Scholar]
- Nguyen, A.; Yosinski, J.; Clune, J. Deep neural networks are easily fooled: High confidence predictions for unrecognizable images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 427–436. [Google Scholar]
- Hendrycks, D.; Gimpel, K. A baseline for detecting misclassified and out-of-distribution examples in neural networks. arXiv 2016, arXiv:1610.02136. [Google Scholar]
- Davis, J.; Goadrich, M. The relationship between Precision-Recall and ROC curves. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 233–240. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Liang, S.; Li, Y.; Srikant, R. Enhancing the reliability of out-of-distribution image detection in neural networks. arXiv 2017, arXiv:1706.02690. [Google Scholar]
- Lee, K.; Lee, H.; Lee, K.; Shin, J. Training confidence-calibrated classifiers for detecting out-of-distribution samples. arXiv 2017, arXiv:1711.09325. [Google Scholar]
- Papadopoulos, A.A.; Rajati, M.R.; Shaikh, N.; Wang, J. Outlier exposure with confidence control for out-of-distribution detection. arXiv 2019, arXiv:1906.03509. [Google Scholar]
- Hendrycks, D.; Mazeika, M.; Dietterich, T. Deep anomaly detection with outlier exposure. arXiv 2018, arXiv:1812.04606. [Google Scholar]
- Lee, K.; Lee, K.; Lee, H.; Shin, J. A simple unified framework for detecting out-of-distribution samples and adversarial attacks. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 7167–7177. [Google Scholar]
- Yang, D.; Shin, I.; Ngoc, K.M.; Kim, H.; Yu, C.; Hwang, M. Out-of-Distribution Detection Based on Distance Metric Learning. In Proceedings of the 9th International Conference on Smart Media and Applications (SMA 2020), Jeju Island, Korea, 17–19 September 2020. [Google Scholar]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese Neural Networks for One-Shot Image Recognition. Master’s Thesis, University of Toronto, Toronto, ON, Canada, 2015. Available online: http://www.cs.toronto.edu/~gkoch/files/msc-thesis.pdf (accessed on 27 February 2021).
- Hoffer, E.; Ailon, N. Deep metric learning using triplet network. In International Workshop on Similarity-Based Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2015; pp. 84–92. [Google Scholar]
- Suárez, J.L.; García, S.; Herrera, F. A Tutorial on Distance Metric Learning: Mathematical Foundations, Algorithms, Experimental Analysis, Prospects and Challenges. Neurocomputing 2021, 425, 300–322. [Google Scholar] [CrossRef]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- LeCun, Y. The MNIST Database of Handwritten Digits. 1998. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 27 February 2021).
- Netzer, Y.; Wang, T.; Coates, A.; Bissacco, A.; Wu, B.; Ng, A. Reading Digits in Natural Images with Unsupervised Feature Learning. NIPS 2011. Available online: http://ufldl.stanford.edu/housenumbers/ (accessed on 27 February 2021).
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Yu, F.; Seff, A.; Zhang, Y.; Song, S.; Funkhouser, T.; Xiao, J. Lsun: Construction of a large-scale image dataset using deep learning with humans in the loop. arXiv 2015, arXiv:1506.03365. [Google Scholar]
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Prechelt, L. Early stopping-but when. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 1998; pp. 55–69. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (a) In: Fashion-MNIST/Out: MNIST | |||||||
| Metric | Baseline | ODIN | Mahal. | OnlySiamese (Our Previous) | OnlyTriplet (Our Previous) | Ensemble-Siamese (Ours) | Ensemble-Triplet (Ours) |
| TNR at TPR 95%. | 43.08 ± 8.45 | 76.84 ± 7.16 | 94.53 ± 2.84 | 97.22 ± 3.61 | 99.90 ± 0.10 | 99.37 ± 0.50 | 99.96 ± 0.04 |
| AUROC. | 86.75 ± 5.32 | 93.87 ± 1.85 | 98.18 ± 0.53 | 98.97 ± 0.63 | 99.76 ± 0.09 | 99.48 ± 0.21 | 99.82 ± 0.11 |
| DTACC. | 83.23 ± 3.45 | 87.71 ± 3.01 | 95.23 ± 1.00 | 96.57 ± 1.27 | 98.63 ± 0.28 | 97.85 ± 0.69 | 99.03 ± 0.34 |
| AUPRin. | 79.74 ± 9.23 | 92.12 ± 4.59 | 98.57 ± 0.47 | 99.22 ± 0.46 | 99.80 ± 0.08 | 99.58 ± 0.19 | 99.87 ± 0.08 |
| AUPRout. | 86.18 ± 4.03 | 94.64 ± 1.48 | 98.74 ± 1.01 | 98.04 ± 1.15 | 99.62 ± 0.13 | 98.92 ± 0.34 | 99.61 ± 0.35 |
| (b) In: MNIST/Out: Fashion-MNIST | |||||||
| Metric | Baseline | ODIN | Mahal. | OnlySiamese (Our Previous) | OnlyTriplet (Our Previous) | Ensemble-Siamese (Ours) | Ensemble-Triplet (Ours) |
| TNR at TPR 95%. | 98.42 ± 1.07 | 99.51 ± 0.25 | 100.0 ± 0.00 | 100.0 ± 0.00 | 100.0 ± 0.00 | 99.99 ± 0.03 | 100.0 ± 0.00 |
| AUROC. | 99.04 ± 0.18 | 99.55 ± 0.14 | 100.0 ± 0.00 | 100.0 ± 0.01 | 100.0 ± 0.00 | 99.99 ± 0.03 | 99.99 ± 0.00 |
| DTACC. | 96.92 ± 0.64 | 97.86 ± 0.40 | 99.98 ± 0.01 | 99.94 ± 0.03 | 99.94 ± 0.03 | 99.95 ± 0.03 | 99.94 ± 0.02 |
| AUPRin. | 98.71 ± 0.45 | 99.64 ± 0.10 | 99.99 ± 0.00 | 99.99 ± 0.00 | 99.99 ± 0.00 | 99.91 ± 0.24 | 99.99 ± 0.00 |
| AUPRout. | 98.74 ± 0.26 | 99.42 ± 0.20 | 99.99 ± 0.04 | 99.95 ± 0.05 | 99.99 ± 0.00 | 99.96 ± 0.04 | 99.98 ± 0.03 |
| In-Dist. | Out-Dist. | Metric | Baseline | ODIN | Mahal. | OnlySiamese (Our Previous) | OnlyTriplet (Our Previous) | Ensemble-Siamese (Ours) | Ensemble-Triplet (Ours) |
|---|---|---|---|---|---|---|---|---|---|
| SVHN | CIFAR-10 | TNR at TPR 95%. | 78.26 | 79.83 | 97.63 | 82.46 ± 6.17 | 91.12 ± 3.72 | 98.45 ± 0.28 | 99.00 ± 0.45 |
| AUROC. | 92.92 | 92.09 | 99.04 | 96.34 ± 1.31 | 98.08 ± 0.59 | 99.20 ± 0.08 | 99.46 ± 0.19 | ||
| DTACC. | 90.03 | 89.44 | 96.37 | 91.10 ± 1.87 | 93.80 ± 1.20 | 96.85 ± 0.17 | 97.42 ± 0.66 | ||
| AUPRin. | 95.06 | 93.96 | 99.58 | 98.38 ± 0.91 | 99.26 ± 0.24 | 99.65 ± 0.11 | 99.79 ± 0.10 | ||
| AUPRout. | 85.66 | 86.83 | 96.15 | 89.04 ± 3.10 | 93.85 ± 1.75 | 96.55 ± 0.13 | 97.59 ± 0.78 | ||
| SVHN | Tiny ImageNet | TNR at TPR 95%. | 79.02 | 82.10 | 99.78 | 99.34 ± 0.34 | 99.76 ± 0.11 | 99.90 ± 0.04 | 99.94 ± 0.02 |
| AUROC. | 93.51 | 91.99 | 99.82 | 99.73 ± 0.12 | 99.89 ± 0.04 | 99.87 ± 0.04 | 99.94 ± 0.03 | ||
| DTACC | 90.44 | 89.35 | 98.70 | 98.18 ± 0.42 | 99.00 ± 0.26 | 98.98 ± 0.13 | 99.21 ± 0.14 | ||
| AUPRin. | 95.68 | 93.88 | 99.87 | 99.88 ± 0.07 | 99.95 ± 0.03 | 99.92 ± 0.03 | 99.97 ± 0.03 | ||
| AUPRout. | 86.18 | 88.12 | 99.06 | 98.99 ± 0.46 | 99.31 ± 0.33 | 99.23 ± 0.17 | 99.48 ± 0.31 | ||
| SVHN | LSUN | TNR at TPR 95%. | 74.29 | 77.34 | 99.77 | 99.75 ± 0.18 | 99.93 ± 0.04 | 99.94 ± 0.06 | 99.98 ± 0.01 |
| AUROC. | 91.58 | 89.43 | 99.75 | 99.81 ± 0.16 | 99.93 ± 0.03 | 99.87 ± 0.05 | 99.95 ± 0.02 | ||
| DTACC. | 88.96 | 87.19 | 99.28 | 98.89 ± 0.39 | 99.41 ± 0.26 | 99.23 ± 0.19 | 99.58 ± 0.13 | ||
| AUPRin. | 94.19 | 92.12 | 99.64 | 99.84 ± 0.25 | 99.97 ± 0.02 | 99.92 ± 0.07 | 99.98 ± 0.01 | ||
| AUPRout. | 83.95 | 85.47 | 99.05 | 99.27 ± 0.33 | 99.22 ± 0.33 | 98.93 ± 0.43 | 99.38 ± 0.37 |
| In-Dist. | Out-Dist. | Metric | Baseline | ODIN | Mahal. | OnlySiamese (Our Previous) | OnlyTriplet (Our Previous) | Ensemble-Siamese (Ours) | Ensemble-Triplet (Ours) |
|---|---|---|---|---|---|---|---|---|---|
| CIFAR-10 | SVHN | TNR at TPR 95%. | 32.47 | 86.60 | 96.93 | 50.69 ± 5.69 | 51.77 ± 7.84 | 96.94 ± 0.18 | 97.01 ± 0.26 |
| AUROC. | 89.88 | 96.65 | 99.23 | 90.75 ± 1.29 | 90.39 ± 2.01 | 99.21 ± 0.05 | 99.22 ± 0.04 | ||
| DTACC. | 85.06 | 91.09 | 95.99 | 84.41 ± 1.58 | 84.24 ± 2.30 | 96.04 ± 0.11 | 96.06 ± 0.17 | ||
| AUPRin. | 85.40 | 92.53 | 98.44 | 81.68 ± 3.18 | 79.35 ± 6.11 | 98.23 ± 0.15 | 98.29 ± 0.24 | ||
| AUPRout. | 93.96 | 98.52 | 99.65 | 95.01 ± 0.54 | 95.01 ± 0.95 | 99.65 ± 0.04 | 99.65 ± 0.03 | ||
| CIFAR-10 | Tiny ImageNet | TNR at TPR 95%. | 44.72 | 72.51 | 97.10 | 72.86 ± 3.98 | 78.92 ± 4.18 | 97.69 ± 0.11 | 97.51 ± 0.10 |
| AUROC. | 91.02 | 94.04 | 99.47 | 91.82 ± 1.50 | 93.90 ± 1.22 | 99.51 ± 0.04 | 99.48 ± 0.02 | ||
| DTACC. | 85.05 | 86.48 | 96.32 | 86.08 ± 1.51 | 88.28 ± 1.48 | 96.60 ± 0.09 | 96.52 ± 0.09 | ||
| AUPRin. | 92.49 | 94.21 | 99.48 | 87.99 ± 2.37 | 90.71 ± 1.78 | 99.47 ± 0.07 | 99.41 ± 0.12 | ||
| AUPRout. | 88.40 | 94.09 | 99.48 | 92.82 ± 1.32 | 94.67 ± 1.13 | 99.51 ± 0.04 | 99.44 ± 0.08 | ||
| CIFAR-10 | LSUN | TNR at TPR 95%. | 45.44 | 73.83 | 98.57 | 80.09 ± 4.99 | 82.73 ± 3.93 | 99.01 ± 0.07 | 98.94 ± 0.07 |
| AUROC. | 91.04 | 94.14 | 99.70 | 94.32 ± 1.42 | 95.40 ± 0.91 | 99.65 ± 0.02 | 99.67 ± 0.03 | ||
| DTACC. | 85.26 | 86.69 | 97.41 | 88.95 ± 1.93 | 90.08 ± 1.32 | 97.89 ± 0.10 | 97.78 ± 0.11 | ||
| AUPRin. | 92.45 | 94.21 | 99.70 | 91.97 ± 1.75 | 93.52 ± 1.25 | 99.18 ± 0.13 | 99.33 ± 0.18 | ||
| AUPRout. | 88.55 | 94.34 | 99.70 | 94.84 ± 1.33 | 95.74 ± 0.95 | 99.69 ± 0.04 | 99.71 ± 0.02 |
| In-Dist. | Out-Dist. | Metric | Baseline | ODIN | Mahal. | OnlySiamese (Our Previous) | OnlyTriplet (Our Previous) | Ensemble-Siamese (Ours) | Ensemble-Triplet (Ours) |
|---|---|---|---|---|---|---|---|---|---|
| CIFAR-100 | SVHN | TNR at TPR 95%. | 20.25 | 62.76 | 91.94 | 45.91 ± 5.15 | 48.11 ± 7.16 | 93.60 ± 0.94 | 93.80 ± 0.54 |
| AUROC. | 79.45 | 93.94 | 98.36 | 88.43 ± 1.48 | 88.91 ± 2.13 | 98.47± 0.10 | 98.46 ± 0.10 | ||
| DTACC. | 73.20 | 88.04 | 93.66 | 82.12 ± 1.60 | 82.22 ± 2.12 | 94.44 ± 0.40 | 94.54 ± 0.20 | ||
| AUPRin. | 64.83 | 88.97 | 96.41 | 74.74 ± 3.90 | 76.63 ± 6.01 | 96.57 ± 0.38 | 96.63 ± 0.38 | ||
| AUPRout. | 89.02 | 96.91 | 99.34 | 94.19 ± 0.79 | 94.61 ± 0.89 | 99.24 ± 0.09 | 99.21 ± 0.06 | ||
| CIFAR-100 | Tiny ImageNet | TNR at TPR 95%. | 20.40 | 49.19 | 90.12 | 63.45 ± 8.59 | 65.20 ± 6.86 | 92.24 ± 0.30 | 92.22 ± 0.35 |
| AUROC. | 77.17 | 87.62 | 98.06 | 88.32 ± 2.62 | 88.98 ± 2.12 | 98.43 ± 0.08 | 98.39 ± 0.10 | ||
| DTACC. | 70.82 | 80.11 | 93.02 | 82.86 ± 2.60 | 82.99 ± 2.16 | 93.79 ± 0.17 | 93.77 ± 0.14 | ||
| AUPRin. | 79.74 | 87.06 | 98.11 | 82.67 ± 3.14 | 84.41 ± 2.80 | 98.39 ± 0.15 | 98.21 ± 0.29 | ||
| AUPRout. | 73.30 | 87.39 | 98.02 | 89.89 ± 2.63 | 90.43 ± 2.17 | 98.42 ± 0.07 | 98.42 ± 0.08 | ||
| CIFAR-100 | LSUN | TNR at TPR 95%. | 18.78 | 45.59 | 90.71 | 75.23 ± 8.88 | 72.73 ± 7.13 | 97.21 ± 0.39 | 97.08 ± 0.28 |
| AUROC. | 75.75 | 85.64 | 98.13 | 92.36 ± 2.53 | 92.10 ± 2.16 | 99.20 ± 0.09 | 99.17 ± 0.06 | ||
| DTACC. | 69.89 | 78.26 | 93.47 | 87.06 ± 3.03 | 86.40 ± 2.55 | 96.26 ± 0.23 | 96.24 ± 0.24 | ||
| AUPRin. | 77.62 | 84.49 | 98.34 | 89.58 ± 2.90 | 89.49 ± 2.46 | 98.89 ± 0.11 | 98.81 ± 0.12 | ||
| AUPRout. | 71.98 | 85.70 | 97.74 | 93.13 ± 2.61 | 92.64 ± 2.24 | 99.22 ± 0.10 | 99.20 ± 0.10 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, D.; Mai Ngoc, K.; Shin, I.; Lee, K.-H.; Hwang, M. Ensemble-Based Out-of-Distribution Detection. Electronics 2021, 10, 567. https://doi.org/10.3390/electronics10050567
Yang D, Mai Ngoc K, Shin I, Lee K-H, Hwang M. Ensemble-Based Out-of-Distribution Detection. Electronics. 2021; 10(5):567. https://doi.org/10.3390/electronics10050567
Chicago/Turabian StyleYang, Donghun, Kien Mai Ngoc, Iksoo Shin, Kyong-Ha Lee, and Myunggwon Hwang. 2021. "Ensemble-Based Out-of-Distribution Detection" Electronics 10, no. 5: 567. https://doi.org/10.3390/electronics10050567