
inTIME: A Machine Learning-Based Framework for Gathering and Leveraging Web Data to Cyber-Threat Intelligence

 ,
,  ,
,  and
and 
Abstract
:1. Introduction
- Collecting public cyber-threat intelligence data from the social, clear, deep and dark web, including related forums, marketplaces, security-related websites and public databases via specialized ready-to-use machine learning-based tools.
- Ranking crawled content to assess its potential relevance and usefulness to the task at hand; it comes with pre-trained models and utility functions that cover basic needs and is customizable to more specific tasks.
- Extracting CTI from the collected content that was classified as useful, by resorting to state-of-the-art natural language understanding and named entity recognition techniques.
- Managing and sharing collected CTI via a combination of custom-made and widely adopted, state-of-the-art solutions that allow the exploration, consolidation, visualization, and seamless sharing of CTI across different organizations.
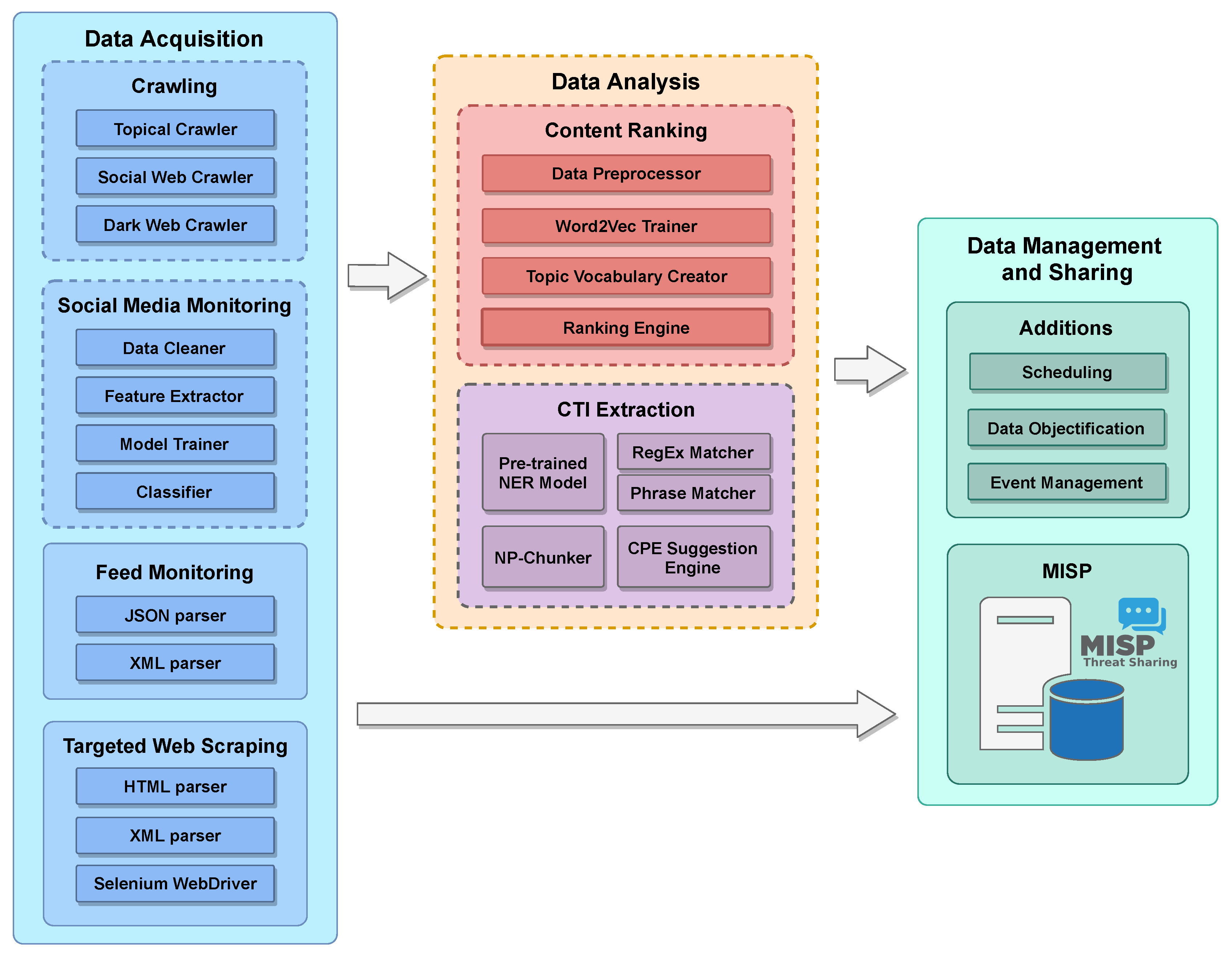
- CTI data collection goes beyond any currently available open-source platform, by providing a novel family of crawlers, social media monitoring tools, and targeted web scrappers that specialize in collecting a wide variety of data. The designed and developed family of crawlers supports a wide variety of crawling options that include focused/topical crawling directed by appropriate machine learning methods, downloading of entire domains based on powerful, yet easy to set up in-depth crawlers, and TOR-based dark web spidering. The social media monitoring tool allows users to monitor popular social media streams for content of interest, by utilising publicly available APIs from social platforms and providing a pre-trained, ready-to-use set of classification algorithms to distinguish between relevant and non-relevant content. Finally, the targeted web scrapers provide access to structured data from reputable sources that do not provide a data feed capability. This is achieved by developing a ready-to-use toolkit for the most prominent sources and by providing appropriate tools for the extension and incorporation of new sources. All content is stored in scalable NoSQL datastores that provide the necessary flexibility, efficiency and interoperability with the rest of the components.
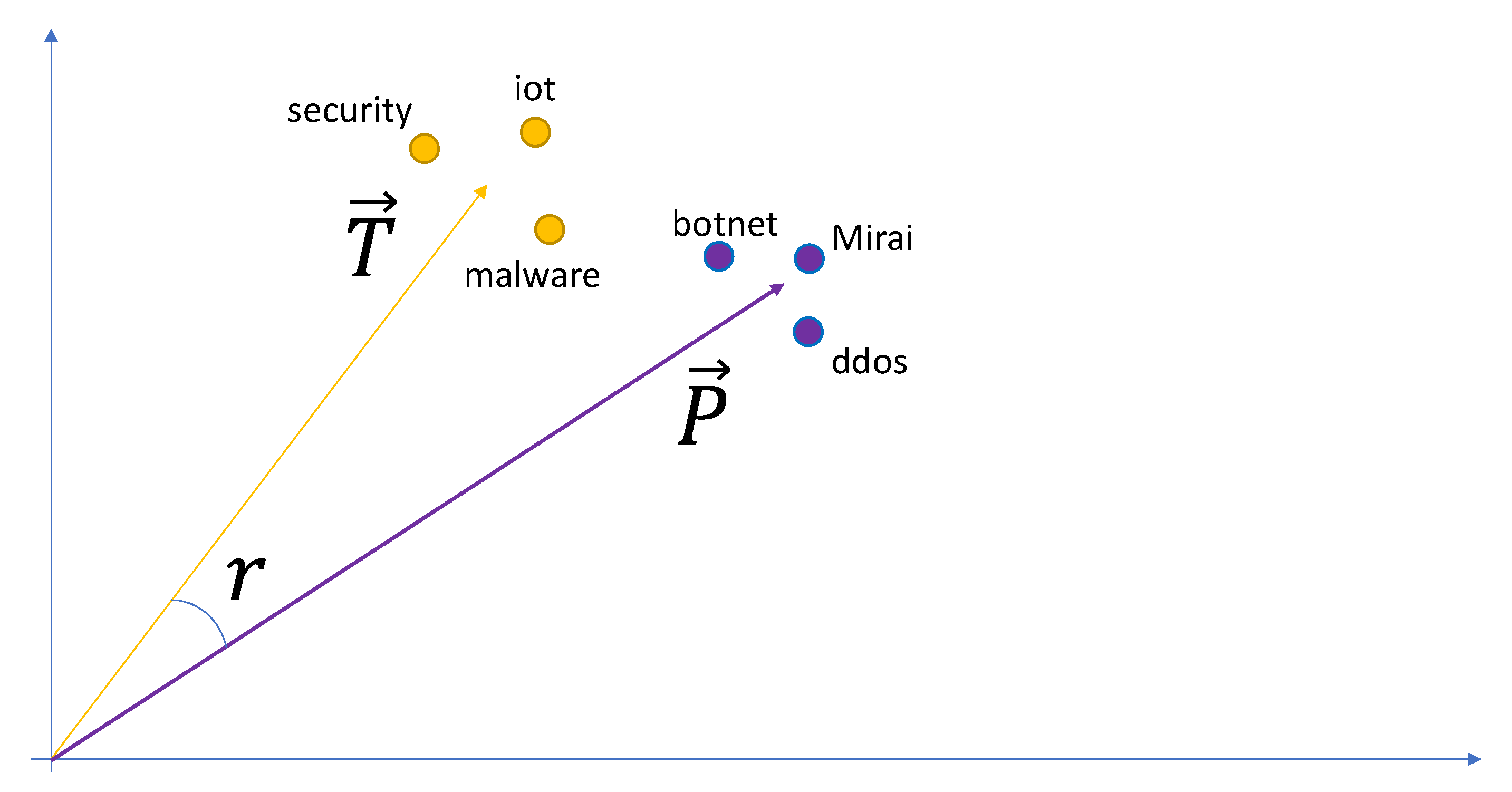
- Ranking of the collected data employs novel, purpose-specific statistical language modeling techniques to represent all information in a latent low-dimensional feature space and a novel ranking-based approach to the collected content (i.e., rank it according to its potential to be useful) modeled as vector similarity. These techniques allow us to train our language models to (i) capture and exploit the most salient words for the given task by building upon user conversations, (ii) compute the semantic relatedness between the crawled content and the task of CTI collection by leveraging the identified salient words, and (iii) classify the crawled content according to its relevance/usefulness based on its semantic similarity to CTI gathering.
- The designed CTI extraction solution goes beyond (the typical for the task) rule-based matching by introducing natural language understanding and named entity recognition to the CTI domain. To do so, it introduces domain-specific entities, employs dependency parsing for more accurate extraction, and provides a set of specialized tools for aiding semi-automated linking to known platform/vulnerability naming schemes.
- The CTI management and sharing is achieved by appropriately extending MISP [5,6]; a state-of-the-art platform for CTI storage and sharing. The integrated technological solution provides enhanced and scalable CTI management functionality, such as CTI storage, consolidation, exploration, inspection and visualization, and supports CTI sharing in both human and machine-based formats to interested stakeholders.
2. Related Work
2.1. Crawler Architectures
2.1.1. Policy-Based Typology
2.1.2. Usage Typology
2.2. Information Extraction for CTI
2.3. CTI Sharing
2.3.1. CTI Sharing Tools and Platforms
2.3.2. Threat Intelligence Services
2.3.3. Threat Intelligence Platforms
3. System Architecture
3.1. Data Acquisition Module
- Crawling allows users to easily setup and deploy automated data collection crawlers that are able to navigate the clear, social, and dark web to discover and harvest content of interest. The Crawling submodule allows the user to select between a wide variety of options including focused/topical crawling directed by appropriate machine learning methods, downloading of entire domains based on powerful, yet easy to set up in-depth crawlers, TOR-based dark web spidering, and semi-automated handling of authentication methods based on cookie management. After collecting the content of interest, the users may then use rest of the modules provided by our architecture to further process it to extract useful CTI from it. The Crawling submodule is discussed in more detail in Section 3.1.1.
- Social Media Monitoring allows users to observe popular social media streams for content of interest; to do so it uses publicly available APIs from social platforms and provides a pre-trained, ready-to-use set of classification algorithms that may be used to distinguish between relevant and non-relevant content. The Social Media Monitoring submodule is elaborated on in Section 3.1.2.
- Feed Monitoring allows the users to record structured JSON or RSS-based data feeds from established credible sources such as NIST, while allowing them to modify several monitoring parameters like the monitoring interval and the type of objects they are interested in (e.g., CVEs, CPEs, or CWEs).
- Targeted Web Scraping provides tools to access structured data from reputable sources, like KB-Cert Notes by Carnegie Mellon University [97] or Exploit-DB [98], that do not provide a data feed capability. To support this process, our architecture offers a pre-installed set of tools that may be used to assist the programmer, including standard HTML parsing, XPath querying and Javascript handling tools and libraries.
3.1.1. The Crawling Submodule
3.1.2. The Social Media Monitoring Submodule
3.1.3. Feed Monitoring and Target Web Scraping Submodules
3.2. Data Analysis Module
- capture and exploit the most salient words for the given task by building upon user conversations,
- compute the semantic relatedness between the crawled content and the task of CTI collection by leveraging the identified salient words, and
- classify the crawled content according to its relevance/usefulness based on its semantic similarity to CTI gathering.
3.3. Data Management and Sharing Module
- Identifies the discovered CTI from the Data Acquisition and Data Analysis modules (Section 3.1 and Section 3.2) and checks if it is new or it can be used to augment already stored CTI. In the former case discovered CTI is added as new; in the latter case, existing CTI is appropriately extended and updated by merging the discovered CTI.
- Stores CTI in a structured, organized and extensible manner.
- Correlates all CTI stored giving security experts the ability to browse the cyber landscape.
- Provides a UI which implements appropriate tools for the presentation, management, analysis and review of the stored CTI.
- Implements a sharing mechanism, that is able to export CTI in a plethora of CTI sharing standard formats.
3.4. Implementation Aspects
4. Cyber-Trust Case Study
4.1. Data Acquisition
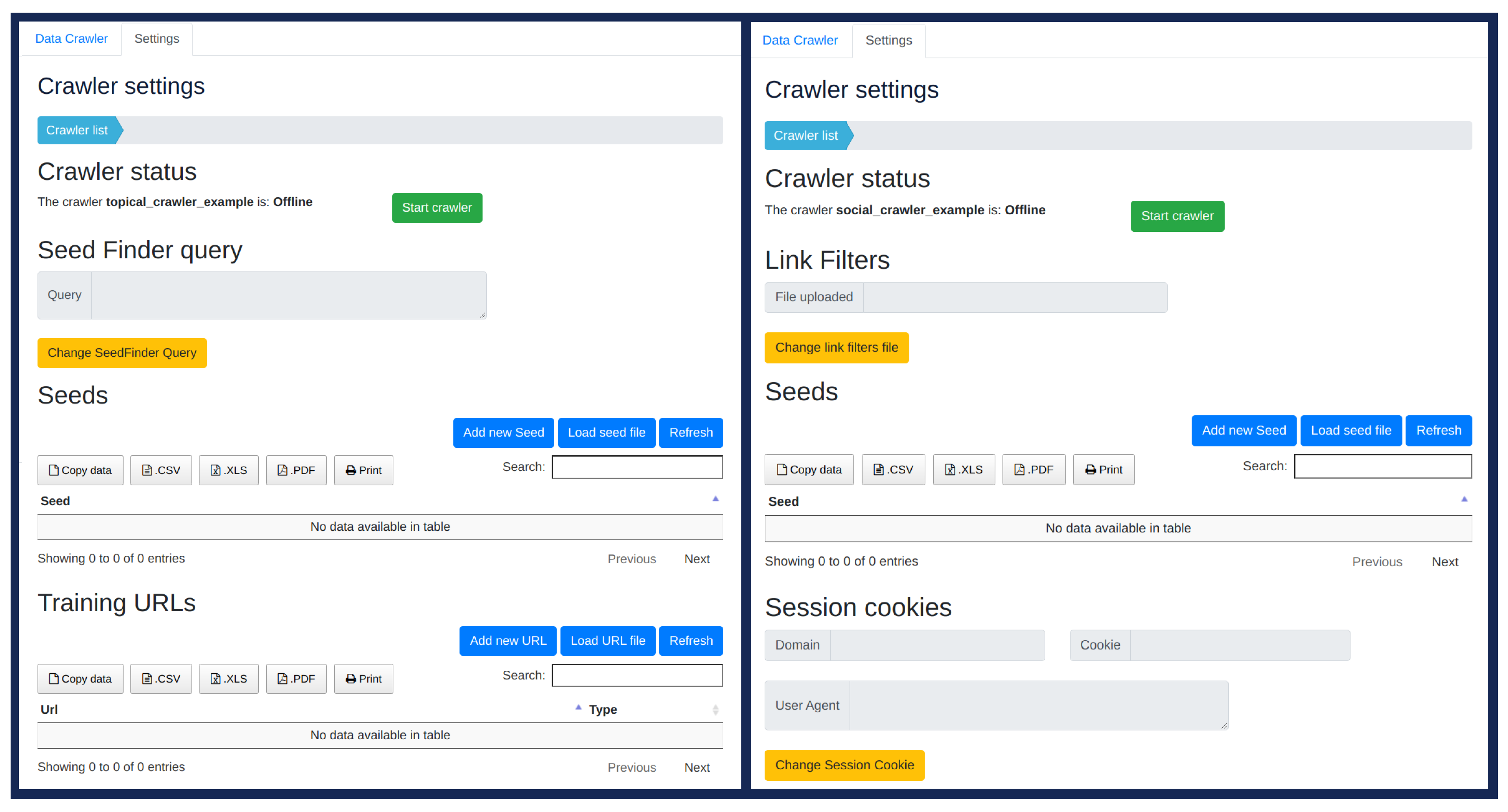
4.1.1. Crawling
- Create new crawlers,
- Start/Stop crawlers, and
- Configure the Seed URLs, Training URLs, Link Filters, SeedFinder queries (depending on the type of crawler).
4.1.2. Social Media Monitoring
4.1.3. Feed Monitoring
- NVD provides public access to a plethora of data feeds of its contents [115] including vulnerability data, CPE match links, RSS vulnerability information, and official vendor comments on existing vulnerabilities. The vulnerability data feeds contain feeds grouped by the year of the CVE ID (i.e., nvdcve-1.1-2020.json), the most recent entries (nvdcve-1.1-recent.json) and the most recent modifications of past entries (nvdcve-1.1-modified.json).We download the latter two data feeds, which contain the recent and recently modified entries of NVD. Then, through our custom-built Python JSON parser, we extract the CTI of each entry of the JSON files.
- JVN provides public access to various data feeds of the JVN iPedia contents [116], that include vulnerability data, CPE match links, and product developer information. As with NVD, the vulnerability data feeds contain feeds grouped by the year of the CVE ID (i.e., jvndb_detail_2020.rdf), the most recent entries (jvndb_new.rdf), and the most recent modifications of past entries (jvndb.rdf).We download the latter two data feeds, which contain the recent entries and the modifications of the past entries of JVN. Then, similarly to the NVD Parsing, through our custom-built Python XML parser, we extract the CTI of each entry of the XML files.
4.1.4. Targeted Web Scraping
4.2. Data Analysis
4.2.1. The Content Ranking Submodule
4.2.2. The CTI Extraction Submodule
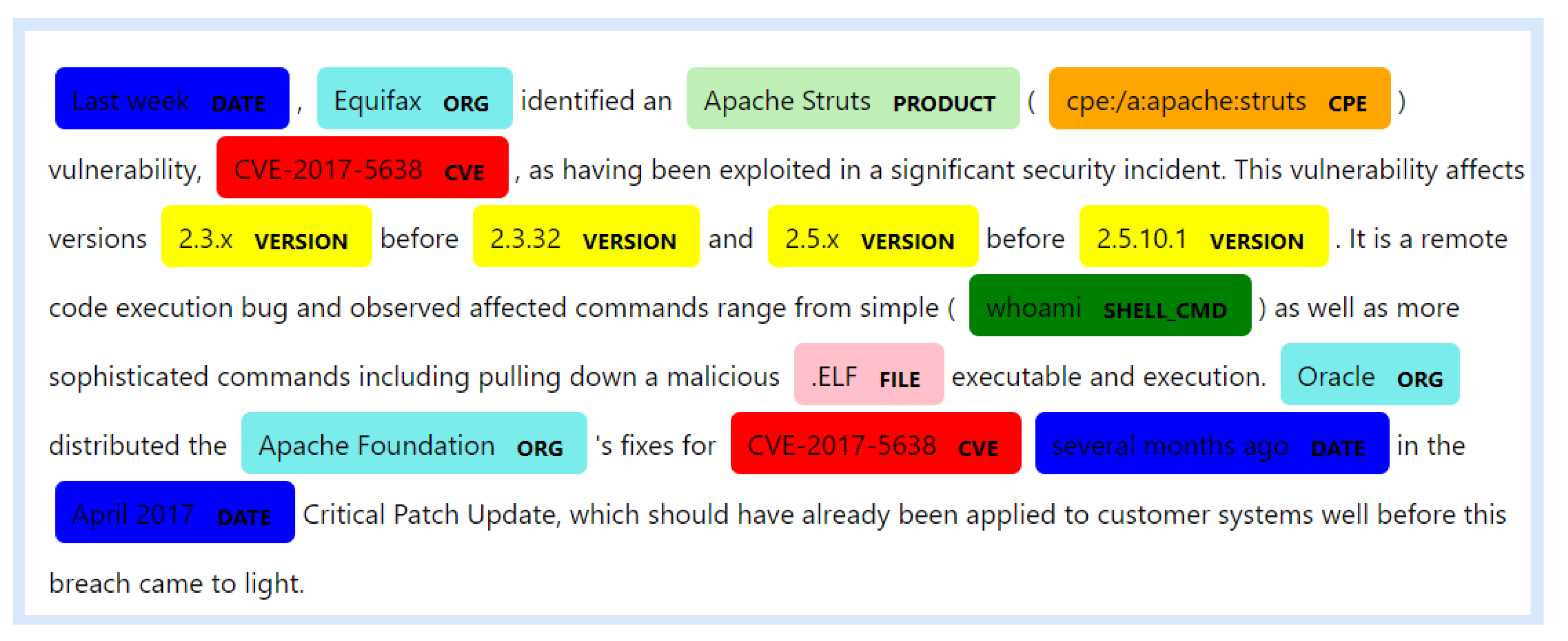
- “Apache Struts vulnerability”,
- “remote code execution bug”, and
- “April 2017 Critical Patch Update”
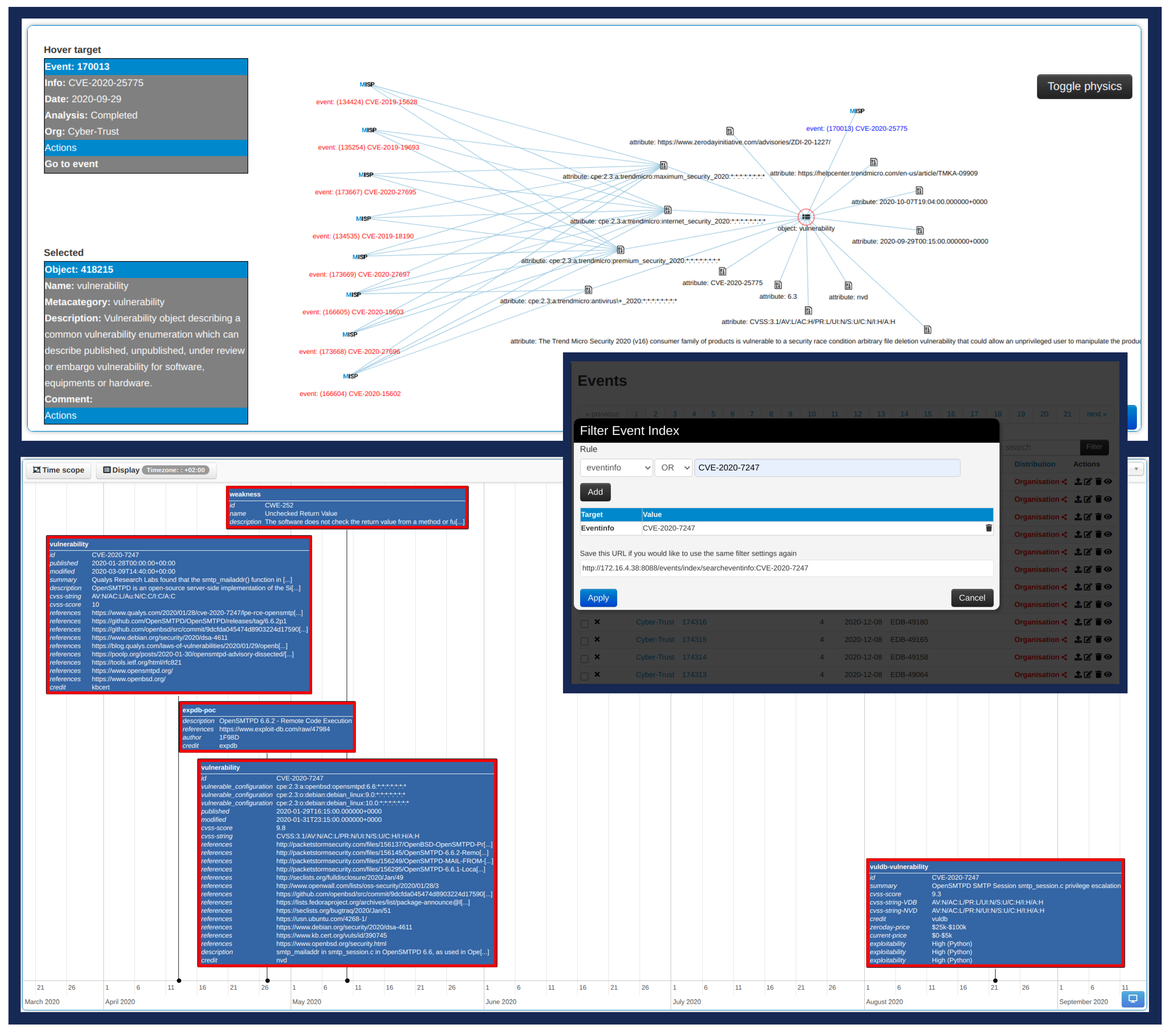
4.3. Data Management and Sharing
- publication status (published or not),
- organisation that produced the event,
- organisation that owns the generated event
- event’s unique identifier,
- MISP clusters and tags that may describe the event,
- number of attributes included in the event,
- email of the user that produced the event on the instance,
- event’s generation date,
- event’s information field,
- event’s distribution level.
5. Experimental Evaluation
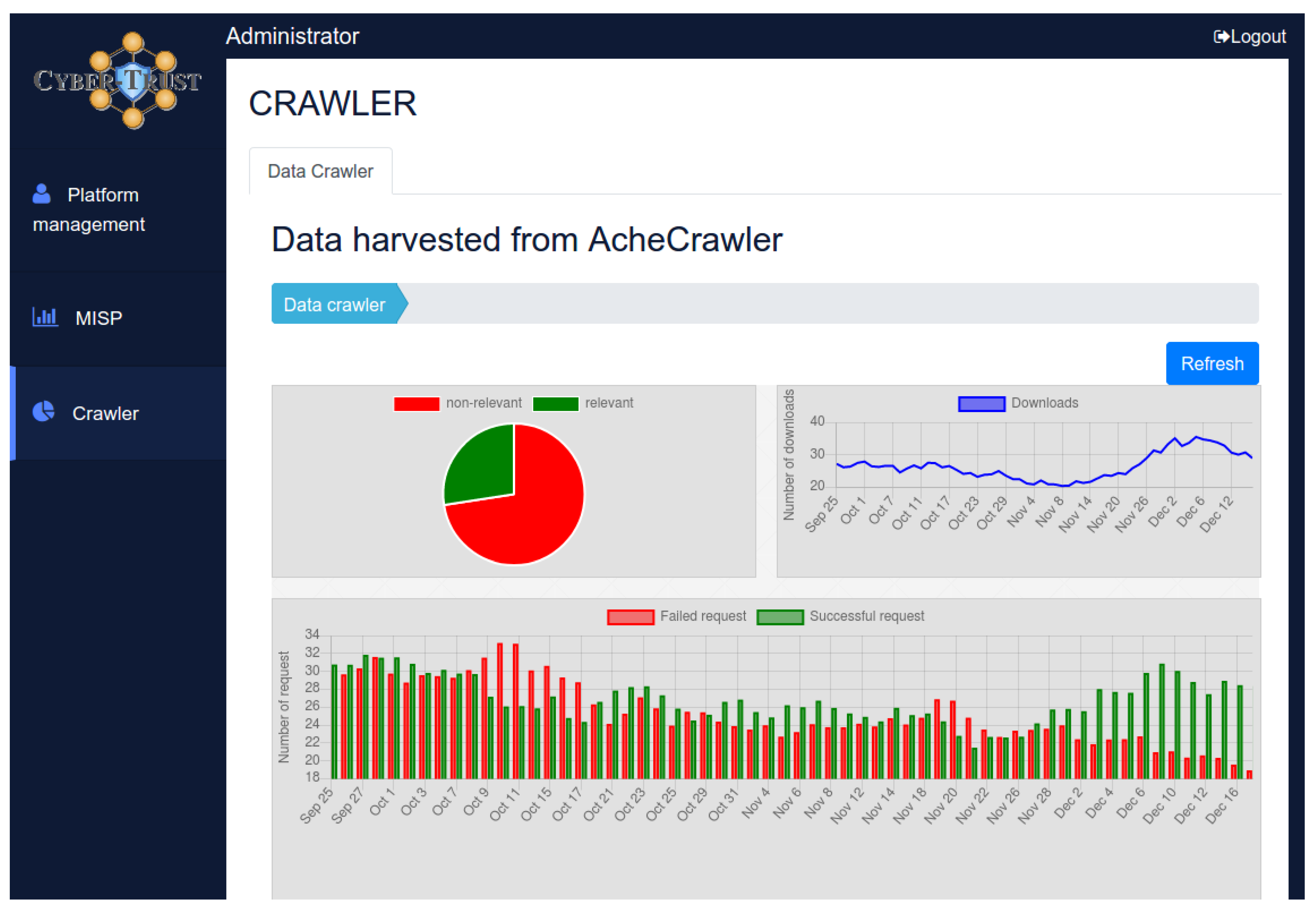
5.1. Evaluation of the Topical Crawler’s Classification Model
- The total number of crawled pages.
- The number of crawled pages that were considered relevant.
- The number of crawled pages that were considered irrelevant.
- The percentage of relevant pages or harvest rate.
5.2. Twitter Classifier Comparison: CNN vs. Random Forest
5.3. Data Management and Sharing Insights
6. Conclusions and Outlook
- easy-to-deploy data harvesting from the clear, social, deep, and dark web; this approach allows security analysts to define and deploy pre-trained focused crawlers, perform site acquisition via in-depth crawlers, and define targeted social media monitors via an easy-to-use graphical user interface that masks away all relevant technicalities. While specialized CTI crawlers are available in the literature, this is the first system that offers so wide functionality with respect to CTI collection without requiring specialized user intervention.
- automated content ranking according to its potential usefulness with respect to CTI; this approach targets to identify the most promising crawler content and is the first in the literature to view the crawling task as a two-stage process, where a crude classification is initially used to prune the crawl frontier, while a more refined approach based on the collected content is used to decide on its relevance to the task.
- automated CTI identification and extraction via state-of-the-art natural language understanding processes; this is the first work in the literature to go beyond regular expression matching (typically used to identify simple objects such as IPs) used in CTI extraction and defines new entities (such as commands, CVEs, and bitcoin values) that are interlinked and correlated according to context via dependency parsing.
- leveraging of the identified security items to actionable cyber-threat intelligence using automated entity disambiguation, and machine-assisted assisted linkage and correlation; this is the first work in the literature to augment CTI with proposed related identifiers such as CPE in order to assist correlation of previously uncorrelated CTI objects.
- CTI management and sharing via open standards and intuitive tools; this is facilitated by adopting research and industry standards such as STIX/TAXII and by resorting to standardized CTI visualization options such as timelines and correlation graphs.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cvitić, I.; Peraković, D.; Periša, M.; Botica, M. Novel approach for detection of IoT generated DDoS traffic. Wirel. Netw. 2019, 1–14. [Google Scholar] [CrossRef]
- Cvitić, I.; Peraković, D.; Periša, M.; Husnjak, S. An overview of distributed denial of service traffic detection approaches. Promet-Traffic Transp. 2019, 31, 453–464. [Google Scholar] [CrossRef]
- Bhushan, K.; Gupta, B.B. Distributed denial of service (DDoS) attack mitigation in software defined network (SDN)-based cloud computing environment. J. Ambient Intell. Humaniz. Comput. 2019, 10, 1985–1997. [Google Scholar] [CrossRef]
- Osanaiye, O.; Choo, K.K.R.; Dlodlo, M. Distributed denial of service (DDoS) resilience in cloud: Review and conceptual cloud DDoS mitigation framework. J. Netw. Comput. Appl. 2016, 67, 147–165. [Google Scholar] [CrossRef]
- Wagner, C.; Dulaunoy, A.; Wagener, G.; Iklody, A. MISP: The Design and Implementation of a Collaborative Threat Intelligence Sharing Platform. In Proceedings of the 2016 ACM on Workshop on Information Sharing and Collaborative Security, Vienna, Austria, 24–28 October 2016; ACM: New York, NY, USA; pp. 49–56. [Google Scholar]
- MISP. Available online: https://www.misp-project.org/ (accessed on 20 February 2021).
- Cyber-Trust EU. Available online: http://cyber-trust.eu/ (accessed on 20 February 2021).
- Najork, M. Web Crawler Architecture. In Encyclopedia of Database Systems; Springer: New York, NY, USA, 2009; pp. 3462–3465. [Google Scholar] [CrossRef]
- Hsieh, J.M.; Gribble, S.D.; Levy, H.M. The Architecture and Implementation of an Extensible Web Crawler. In Proceedings of the 7th USENIX Symposium on Networked Systems Design and Implementation, NSDI 2010, San Jose, CA, USA, 28–30 April 2010; pp. 329–344. [Google Scholar]
- Harth, A.; Umbrich, J.; Decker, S. MultiCrawler: A Pipelined Architecture for Crawling and Indexing Semantic Web Data. In Proceedings of the Semantic Web—ISWC 2006, 5th International Semantic Web Conference, ISWC 2006, Athens, GA, USA, 5–9 November 2006; pp. 258–271. [Google Scholar] [CrossRef] [Green Version]
- Ahmadi-Abkenari, F.; Selamat, A. An architecture for a focused trend parallel Web crawler with the application of clickstream analysis. Inf. Sci. 2012, 184, 266–281. [Google Scholar] [CrossRef]
- Quoc, D.L.; Fetzer, C.; Felber, P.; Rivière, E.; Schiavoni, V.; Sutra, P. UniCrawl: A Practical Geographically Distributed Web Crawler. In Proceedings of the 8th IEEE International Conference on Cloud Computing, CLOUD 2015, New York, NY, USA, 27 June–2 July 2015; pp. 389–396. [Google Scholar] [CrossRef]
- Vikas, O.; Chiluka, N.J.; Ray, P.K.; Meena, G.; Meshram, A.K.; Gupta, A.; Sisodia, A. WebMiner—Anatomy of Super Peer Based Incremental Topic-Specific Web Crawler. In Proceedings of the Sixth International Conference on Networking (ICN 2007), Sainte-Luce, Martinique, France, 22–28 April 2007; p. 32. [Google Scholar] [CrossRef]
- Bamba, B.; Liu, L.; Caverlee, J.; Padliya, V.; Srivatsa, M.; Bansal, T.; Palekar, M.; Patrao, J.; Li, S.; Singh, A. DSphere: A Source-Centric Approach to Crawling, Indexing and Searching the World Wide Web. In Proceedings of the 23rd International Conference on Data Engineering, ICDE 2007, Istanbul, Turkey, 15–20 April 2007; pp. 1515–1516. [Google Scholar] [CrossRef] [Green Version]
- Stoica, I.; Morris, R.T.; Liben-Nowell, D.; Karger, D.R.; Kaashoek, M.F.; Dabek, F.; Balakrishnan, H. Chord: A scalable peer-to-peer lookup protocol for internet applications. IEEE/ACM Trans. Netw. 2003, 11, 17–32. [Google Scholar] [CrossRef]
- Shkapenyuk, V.; Suel, T. Design and Implementation of a High-Performance Distributed Web Crawler. In Proceedings of the 18th International Conference on Data Engineering, San Jose, CA, USA, 26 February–1 March 2002; pp. 357–368. [Google Scholar] [CrossRef]
- Gupta, K.; Mittal, V.; Bishnoi, B.; Maheshwari, S.; Patel, D. AcT: Accuracy-aware crawling techniques for cloud-crawler. World Wide Web 2016, 19, 69–88. [Google Scholar] [CrossRef]
- Li, Y.; Zhao, L.; Liu, X.; Zhang, P. A Security Framework for Cloud-Based Web Crawling System. In Proceedings of the 11th Web Information System and Application Conference, WISA 2014, Tianjin, China, 12–14 September 2014; pp. 101–104. [Google Scholar] [CrossRef]
- Ntoulas, A.; Cho, J.; Olston, C. What’s new on the web?: The evolution of the web from a search engine perspective. In Proceedings of the 13th international conference on World Wide Web, WWW 2004, New York, NY, USA, 17–20 May 2004; pp. 1–12. [Google Scholar] [CrossRef]
- McCurley, K.S. Incremental Crawling. In Encyclopedia of Database Systems; Springer: New York, NY, USA, 2009; pp. 1417–1421. [Google Scholar] [CrossRef]
- Sizov, S.; Graupmann, J.; Theobald, M. From Focused Crawling to Expert Information: An Application Framework for Web Exploration and Portal Generation. In Proceedings of the 29th International Conference on Very Large Data Bases, VLDB 2003, Berlin, Germany, 9–12 September 2003; pp. 1105–1108. [Google Scholar]
- Chakrabarti, S.; van den Berg, M.; Dom, B. Focused Crawling: A New Approach to Topic-Specific Web Resource Discovery. Comput. Netw. 1999, 31, 1623–1640. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Nasraoui, O.; van Zwol, R. Exploiting Tags and Social Profiles to Improve Focused Crawling. In Proceedings of the 2009 IEEE/WIC/ACM International Conference on Web Intelligence, WI 2009, Milan, Italy, 15–18 September 2009; pp. 136–139. [Google Scholar] [CrossRef]
- Ester, M.; Gro, M.; Kriegel, H.P. Focused Web Crawling: A Generic Framework for Specifying the User Interest and for Adaptive Crawling Strategies. In Proceedings of the 27th International Conference on Very Large Data Bases, Roma, Italy, 11–14 September 2001; Morgan Kaufmann Publishers: Burlington, MA, USA, 2001. [Google Scholar]
- Chakrabarti, S.; Punera, K.; Subramanyam, M. Accelerated focused crawling through online relevance feedback. In Proceedings of the Eleventh International World Wide Web Conference, WWW 2002, Honolulu, HI, USA, 7–11 May 2002; pp. 148–159. [Google Scholar] [CrossRef] [Green Version]
- Gaur, R.; Sharma, D.K. Focused crawling with ontology using semi-automatic tagging for relevancy. In Proceedings of the Seventh International Conference on Contemporary Computing, IC3 2014, Noida, India, 7–9 August 2014; pp. 501–506. [Google Scholar] [CrossRef]
- Pham, K.; Santos, A.S.R.; Freire, J. Learning to Discover Domain-Specific Web Content. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, WSDM 2018, Marina Del Rey, CA, USA, 5–9 February 2018; pp. 432–440. [Google Scholar] [CrossRef] [Green Version]
- Singh, M.P. The Practical Handbook of Internet Computing; CRC Press, Inc.: Boca Raton, FL, USA, 2004. [Google Scholar]
- Jiang, J.; Yu, N.; Lin, C. FoCUS: Learning to crawl web forums. In Proceedings of the 21st World Wide Web Conference, WWW 2012, Lyon, France, 16–20 April 2012; Companion Volume, pp. 33–42. [Google Scholar] [CrossRef]
- Sachan, A.; Lim, W.; Thing, V.L.L. A Generalized Links and Text Properties Based Forum Crawler. In Proceedings of the 2012 IEEE/WIC/ACM International Conferences on Web Intelligence, WI 2012, Macau, China, 4–7 December 2012; pp. 113–120. [Google Scholar] [CrossRef]
- Yang, J.; Cai, R.; Wang, C.; Huang, H.; Zhang, L.; Ma, W. Incorporating site-level knowledge for incremental crawling of web forums: A list-wise strategy. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009; pp. 1375–1384. [Google Scholar] [CrossRef]
- Wang, Y.; Yang, J.; Lai, W.; Cai, R.; Zhang, L.; Ma, W. Exploring traversal strategy for web forum crawling. In Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2008, Singapore, 20–24 July 2008; pp. 459–466. [Google Scholar] [CrossRef]
- Cai, R.; Yang, J.; Lai, W.; Wang, Y.; Zhang, L. iRobot: An intelligent crawler for web forums. In Proceedings of the 17th International Conference on World Wide Web, WWW 2008, Beijing, China, 21–25 April 2008; pp. 447–456. [Google Scholar] [CrossRef]
- Guo, Y.; Li, K.; Zhang, K.; Zhang, G. Board Forum Crawling: A Web Crawling Method for Web Forum. In Proceedings of the 2006 IEEE/WIC/ACM International Conference on Web Intelligence (WI 2006), Hong Kong, China, 18–22 December 2006; pp. 745–748. [Google Scholar] [CrossRef] [Green Version]
- Hurst, M.; Maykov, A. Social Streams Blog Crawler. In Proceedings of the 25th International Conference on Data Engineering, ICDE 2009, Shanghai, China, 29 March–2 April 2009; pp. 1615–1618. [Google Scholar] [CrossRef]
- Agarwal, S.; Sureka, A. A Topical Crawler for Uncovering Hidden Communities of Extremist Micro-Bloggers on Tumblr. In Proceedings of the the 5th Workshop on Making Sense of Microposts Co-Located with the 24th International World Wide Web Conference (WWW 2015), Florence, Italy, 18 May 2015; pp. 26–27. [Google Scholar]
- Chau, D.H.; Pandit, S.; Wang, S.; Faloutsos, C. Parallel crawling for online social networks. In Proceedings of the 16th International Conference on World Wide Web, WWW 2007, Banff, AB, Canada, 8–12 May 2007; pp. 1283–1284. [Google Scholar] [CrossRef]
- Zhang, Z.; Nasraoui, O. Profile-Based Focused Crawler for Social Media-Sharing Websites. In Proceedings of the 20th IEEE International Conference on Tools with Artificial Intelligence (ICTAI 2008), Dayton, OH, USA, 3–5 November 2008; Volume 1, pp. 317–324. [Google Scholar] [CrossRef]
- Buccafurri, F.; Lax, G.; Nocera, A.; Ursino, D. Crawling Social Internetworking Systems. In Proceedings of the International Conference on Advances in Social Networks Analysis and Mining, ASONAM 2012, Istanbul, Turkey, 26–29 August 2012; pp. 506–510. [Google Scholar] [CrossRef]
- Khan, A.; Sharma, D.K. Self-Adaptive Ontology based Focused Crawler for Social Bookmarking Sites. IJIRR 2017, 7, 51–67. [Google Scholar] [CrossRef]
- Ferreira, R.; Lima, R.; Melo, J.; Costa, E.; de Freitas, F.L.G.; Luna, H.P.L. RetriBlog: A framework for creating blog crawlers. In Proceedings of the ACM Symposium on Applied Computing, SAC 2012, Trento, Italy, 26–30 March 2012; pp. 696–701. [Google Scholar] [CrossRef]
- Tor Project. Available online: https://www.torproject.org/ (accessed on 20 February 2021).
- I2P Anonymous Network. Available online: https://geti2p.net/en/ (accessed on 20 February 2021).
- Valkanas, G.; Ntoulas, A.; Gunopulos, D. Rank-Aware Crawling of Hidden Web sites. In Proceedings of the 14th International Workshop on the Web and Databases 2011, WebDB 2011, Athens, Greece, 12 June 2011. [Google Scholar]
- Wang, Y.; Lu, J.; Chen, J.; Li, Y. Crawling ranked deep Web data sources. World Wide Web 2017, 20, 89–110. [Google Scholar] [CrossRef]
- Zhao, F.; Zhou, J.; Nie, C.; Huang, H.; Jin, H. SmartCrawler: A Two-Stage Crawler for Efficiently Harvesting Deep-Web Interfaces. IEEE Trans. Serv. Comput. 2016, 9, 608–620. [Google Scholar] [CrossRef]
- Zheng, Q.; Wu, Z.; Cheng, X.; Jiang, L.; Liu, J. Learning to crawl deep web. Inf. Syst. 2013, 38, 801–819. [Google Scholar] [CrossRef]
- Jiang, L.; Wu, Z.; Feng, Q.; Liu, J.; Zheng, Q. Efficient Deep Web Crawling Using Reinforcement Learning. In Proceedings of the Advances in Knowledge Discovery and Data Mining, 14th Pacific-Asia Conference, PAKDD 2010, Hyderabad, India, 21–24 June 2010; Part I. pp. 428–439. [Google Scholar] [CrossRef]
- Madhavan, J.; Ko, D.; Kot, L.; Ganapathy, V.; Rasmussen, A.; Halevy, A.Y. Google’s Deep Web crawl. PVLDB 2008, 1, 1241–1252. [Google Scholar] [CrossRef] [Green Version]
- Shaila, S.G.; Vadivel, A. Architecture specification of rule-based deep web crawler with indexer. Int. J. Knowl. Web Intell. 2013, 4, 166–186. [Google Scholar] [CrossRef]
- Zhao, J.; Wang, P. Nautilus: A Generic Framework for Crawling Deep Web. In Proceedings of the Data and Knowledge Engineering—Third International Conference, ICDKE 2012, Wuyishan, China, 21–23 November 2012; pp. 141–151. [Google Scholar] [CrossRef]
- Li, Y.; Wang, Y.; Tian, E. A New Architecture of an Intelligent Agent-Based Crawler for Domain-Specific Deep Web Databases. In Proceedings of the 2012 IEEE/WIC/ACM International Conferences on Web Intelligence, WI 2012, Macau, China, 4–7 December 2012; pp. 656–663. [Google Scholar] [CrossRef]
- Furche, T.; Gottlob, G.; Grasso, G.; Schallhart, C.; Sellers, A.J. OXPath: A language for scalable data extraction, automation, and crawling on the deep web. VLDB J. 2013, 22, 47–72. [Google Scholar] [CrossRef]
- Lu, J.; Wang, Y.; Liang, J.; Chen, J.; Liu, J. An Approach to Deep Web Crawling by Sampling. In Proceedings of the 2008 IEEE/WIC/ACM International Conference on Web Intelligence, WI 2008, Sydney, NSW, Australia, 9–12 December 2008; pp. 718–724. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Wu, Z.; Jiang, L.; Zheng, Q.; Liu, X. Crawling Deep Web Content through Query Forms. In Proceedings of the Fifth International Conference on Web Information Systems and Technologies, WEBIST 2009, Lisbon, Portugal, 23–26 March 2009; pp. 634–642. [Google Scholar]
- Li, Y.; Wang, Y.; Du, J. E-FFC: An enhanced form-focused crawler for domain-specific deep web databases. J. Intell. Inf. Syst. 2013, 40, 159–184. [Google Scholar] [CrossRef]
- He, Y.; Xin, D.; Ganti, V.; Rajaraman, S.; Shah, N. Crawling deep web entity pages. In Proceedings of the Sixth ACM International Conference on Web Search and Data Mining, WSDM 2013, Rome, Italy, 4–8 February 2013; pp. 355–364. [Google Scholar] [CrossRef] [Green Version]
- Sapienza, A.; Bessi, A.; Damodaran, S.; Shakarian, P.; Lerman, K.; Ferrara, E. Early Warnings of Cyber Threats in Online Discussions. In Proceedings of the 2017 IEEE International Conference on Data Mining Workshops, ICDM Workshops 2017, New Orleans, LA, USA, 18–21 November 2017; Gottumukkala, R., Ning, X., Dong, G., Raghavan, V., Aluru, S., Karypis, G., Miele, L., Wu, X., Eds.; IEEE Computer Society: Piscataway, NJ, USA, 2017; pp. 667–674. [Google Scholar] [CrossRef] [Green Version]
- Mittal, S.; Das, P.K.; Mulwad, V.; Joshi, A.; Finin, T. CyberTwitter: Using Twitter to generate alerts for cybersecurity threats and vulnerabilities. In Proceedings of the 2016 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, ASONAM 2016, San Francisco, CA, USA, 18–21 August 2016; Kumar, R., Caverlee, J., Tong, H., Eds.; IEEE Computer Society: Piscataway, NJ, USA, 2016; pp. 860–867. [Google Scholar] [CrossRef]
- Alves, F.; Bettini, A.; Ferreira, P.M.; Bessani, A. Processing tweets for cybersecurity threat awareness. Inf. Syst. 2021, 95, 101586. [Google Scholar] [CrossRef]
- Syed, R.; Rahafrooz, M.; Keisler, J.M. What it takes to get retweeted: An analysis of software vulnerability messages. Comput. Hum. Behav. 2018, 80, 207–215. [Google Scholar] [CrossRef]
- Sabottke, C.; Suciu, O.; Dumitras, T. Vulnerability Disclosure in the Age of Social Media: Exploiting Twitter for Predicting Real-World Exploits. In Proceedings of the 24th USENIX Security Symposium, USENIX Security 15, Washington, DC, USA, 12–14 August 2015; Jung, J., Holz, T., Eds.; USENIX Association: Berkeley, CA, USA, 2015; pp. 1041–1056. [Google Scholar]
- Sauerwein, C.; Sillaber, C.; Huber, M.M.; Mussmann, A.; Breu, R. The Tweet Advantage: An Empirical Analysis of 0-Day Vulnerability Information Shared on Twitter. In Proceedings of the ICT Systems Security and Privacy Protection—33rd IFIP TC 11 International Conference, SEC 2018, Held at the 24th IFIP World Computer Congress, WCC 2018, Poznan, Poland, 18–20 September 2018; IFIP Advances in Information and Communication, Technology. Janczewski, L.J., Kutylowski, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; Volume 529, pp. 201–215. [Google Scholar] [CrossRef]
- CVE Dictionary, MITRE. Available online: https://cve.mitre.org/ (accessed on 20 February 2021).
- Le, B.D.; Wang, G.; Nasim, M.; Babar, M.A. Gathering Cyber Threat Intelligence from Twitter Using Novelty Classification. arXiv 2019, arXiv:1907.01755. [Google Scholar]
- Husari, G.; Al-Shaer, E.; Ahmed, M.; Chu, B.; Niu, X. TTPDrill: Automatic and Accurate Extraction of Threat Actions from Unstructured Text of CTI Sources. In Proceedings of the 33rd Annual Computer Security Applications Conference, ACSAC 2017, Orlando, FL, USA, 4–8 December 2017; ACM: New York, NY, USA, 2017; pp. 103–115. [Google Scholar] [CrossRef]
- CAPEC, MITRE. Available online: https://capec.mitre.org/ (accessed on 20 February 2021).
- ATTA&CK, MITRE. Available online: https://attack.mitre.org/ (accessed on 20 February 2021).
- Liao, X.; Yuan, K.; Wang, X.; Li, Z.; Xing, L.; Beyah, R. Acing the IOC Game: Toward Automatic Discovery and Analysis of Open-Source Cyber Threat Intelligence. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, CCS ’16, Vienna, Austria, 24–28 October 2016; ACM: New York, NY, USA, 2016; pp. 755–766. [Google Scholar] [CrossRef]
- OpenIOC. Available online: https://www.fireeye.com/services/freeware.html (accessed on 20 February 2021).
- GOSINT. Available online: https://gosint.readthedocs.io/en/latest/ (accessed on 20 February 2021).
- YETI—Your Everyday Threat Intelligence. Available online: https://yeti-platform.github.io/ (accessed on 20 February 2021).
- OpenTAXII. Available online: https://opentaxii.readthedocs.io/en/stable/ (accessed on 20 February 2021).
- CIF—Collective Intelligence Framework. Available online: https://csirtgadgets.com/collective-intelligence-framework (accessed on 20 February 2021).
- ZeroFox. Available online: https://www.zerofox.com/ (accessed on 20 February 2021).
- CTAC, Wapack Labs. Available online: https://www.wapacklabs.com/ctac (accessed on 20 February 2021).
- SearchLight, Digital Shadows. Available online: https://www.digitalshadows.com/searchlight/ (accessed on 20 February 2021).
- Intel 471. Available online: https://intel471.com/ (accessed on 20 February 2021).
- Flashpoint Intelligence Platform. Available online: https://www.flashpoint-intel.com/platform/ (accessed on 20 February 2021).
- BitSight Security Ratings. Available online: https://www.bitsight.com/security-ratings (accessed on 20 February 2021).
- BreachAlert, SKURIO. Available online: https://skurio.com/solutions/breach-alert/ (accessed on 20 February 2021).
- F5 Labs. Available online: https://www.f5.com/labs (accessed on 20 February 2021).
- Helix Security Platform, FireEye. Available online: https://www.fireeye.com/products/helix.html (accessed on 20 February 2021).
- Recorded Future. Available online: https://www.recordedfuture.com/ (accessed on 20 February 2021).
- Cyjax. Available online: https://www.cyjax.com/cyber-threat-services/ (accessed on 20 February 2021).
- EclecticIQ. Available online: https://www.eclecticiq.com/platform (accessed on 20 February 2021).
- Cyber Advisor, SurfWatch Labs. Available online: https://www.surfwatchlabs.com/threat-intelligence-products/cyber-advisor (accessed on 20 February 2021).
- Infoblox. BloxOne Threat Defense Advanced: Strengthen and Optimize Your Security Posture from the Foundation. 2020. Available online: https://www.infoblox.com/wp-content/uploads/infoblox-datasheet-bloxone-threat-defense-advanced.pdf (accessed on 30 October 2020).
- ThreatStream, Anomali. Available online: https://www.anomali.com/products/threatstream (accessed on 20 February 2021).
- ThreatQ, ThreatQuotient. Available online: https://www.threatq.com/ (accessed on 20 February 2021).
- Soltra, Celerium. Available online: https://www.celerium.com/automate (accessed on 20 February 2021).
- ThreatConnect. Available online: https://threatconnect.com/ (accessed on 20 February 2021).
- VDMR, Qualys. Available online: https://www.qualys.com/apps/vulnerability-management-detection-response/ (accessed on 20 February 2021).
- The MANTIS Cyber Threat Intelligence Management Framework, SIEMENS. Available online: https://django-mantis.readthedocs.io/en/latest/readme.html (accessed on 20 February 2021).
- BrightCloud, Webroot. Available online: https://www.brightcloud.com/ (accessed on 20 February 2021).
- Koloveas, P.; Chantzios, T.; Tryfonopoulos, C.; Skiadopoulos, S. A crawler architecture for harvesting the clear, social, and dark web for IoT-related cyber-threat intelligence. In Proceedings of the 2019 IEEE World Congress on Services (SERVICES), Milan, Italy, 8–13 July 2019; IEEE: Piscataway, NJ, USA, 2019; Volume 2642, pp. 3–8. [Google Scholar]
- CERT Vulnterability Notes Database, Carnegie Mellon University. Available online: https://www.kb.cert.org/vuls/bypublished/desc/ (accessed on 20 February 2021).
- Exploit Database—ExploitDB. Available online: https://www.exploit-db.com/ (accessed on 20 February 2021).
- Ache Crawler, GitHub. Available online: https://github.com/ViDA-NYU/ache (accessed on 20 February 2021).
- Li, H. Smile. 2014. Available online: https://haifengl.github.io (accessed on 20 February 2021).
- Vieira, K.; Barbosa, L.; da Silva, A.S.; Freire, J.; Moura, E. Finding seeds to bootstrap focused crawlers. World Wide Web 2016, 19, 449–474. [Google Scholar] [CrossRef]
- Chantzios, T.; Koloveas, P.; Skiadopoulos, S.; Kolokotronis, N.; Tryfonopoulos, C.; Bilali, V.; Kavallieros, D. The Quest for the Appropriate Cyber-threat Intelligence Sharing Platform. In Proceedings of the 8th International Conference on Data Science, Technology and Applications, DATA 2019, Prague, Czech Republic, 26–28 July 2019; Hammoudi, S., Quix, C., Bernardino, J., Eds.; SciTePress: Setúbal, Portugal, 2019; pp. 369–376. [Google Scholar] [CrossRef]
- de Melo e Silva, A.; Gondim, J.J.C.; de Oliveira Albuquerque, R.; García-Villalba, L.J. A Methodology to Evaluate Standards and Platforms within Cyber Threat Intelligence. Future Internet 2020, 12, 108. [Google Scholar] [CrossRef]
- Flask. Available online: https://flask.palletsprojects.com/en/1.1.x/ (accessed on 20 February 2021).
- Swagger. Available online: https://swagger.io/ (accessed on 20 February 2021).
- MongoDB. Available online: https://www.mongodb.com/ (accessed on 20 February 2021).
- Řehůřek, R.; Sojka, P. Software Framework for Topic Modelling with Large Corpora. In Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks, Valletta, Malta, 22 May 2010; ELRA: Valletta, Malta, 2010; pp. 45–50. [Google Scholar]
- Honnibal, M.; Montani, I.; Van Landeghem, S.; Boyd, A. spaCy: Industrial-strength Natural Language Processing in Python. zenodo 2020. [Google Scholar] [CrossRef]
- MySQL. Available online: https://www.mysql.com/ (accessed on 20 February 2021).
- CakePHP. Available online: https://cakephp.org/ (accessed on 20 February 2021).
- PyMISP, GitHub. Available online: https://github.com/MISP/PyMISP (accessed on 20 February 2021).
- Twitter API. Available online: https://developer.twitter.com/en/docs/twitter-api (accessed on 20 February 2021).
- NVD, NIST. Available online: https://nvd.nist.gov/ (accessed on 20 February 2021).
- JVN iPedia. Available online: https://jvndb.jvn.jp/en/ (accessed on 20 February 2021).
- NVD Data Feeds, NIST. Available online: https://nvd.nist.gov/vuln/data-feeds (accessed on 20 February 2021).
- JVN iPedia Feed. Available online: https://jvndb.jvn.jp/en/feed/ (accessed on 20 February 2021).
- Selenium. Available online: https://www.selenium.dev/ (accessed on 20 February 2021).
- Vulnerability Database – VulDB. Available online: https://vuldb.com/ (accessed on 20 February 2021).
- 0Day.today Exploit Database. Available online: https://0day.today/ (accessed on 20 February 2021).
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed Representations of Words and Phrases and Their Compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems—Volume 2, NIPS’13, Lake Tahoe, NV, USA, 5–8 December 2013; Curran Associates Inc.: Red Hook, NY, USA, 2013; pp. 3111–3119. [Google Scholar]
- Stack Exchange Data Dump, Archive.org. Available online: https://archive.org/details/stackexchange (accessed on 20 February 2021).
- Internet of Things, Stack Exchange. Available online: https://iot.stackexchange.com/ (accessed on 20 February 2021).
- Information Security, Stack Exchange. Available online: https://security.stackexchange.com/ (accessed on 20 February 2021).
- Arduino, Stack Exchange. Available online: https://arduino.stackexchange.com/ (accessed on 20 February 2021).
- Raspberry Pi, Stack Exchange. Available online: https://raspberrypi.stackexchange.com/ (accessed on 20 February 2021).
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2009. [Google Scholar]
- Biega, J.A.; Gummadi, K.P.; Mele, I.; Milchevski, D.; Tryfonopoulos, C.; Weikum, G. R-Susceptibility: An IR-Centric Approach to Assessing Privacy Risks for Users in Online Communities. In Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval, Pisa, Italy, 17–21 July 2016; ACM: New York, NY, USA, 2016. SIGIR ’16. pp. 365–374. [Google Scholar] [CrossRef]
- Sang, E.F.; Buchholz, S. Introduction to the CoNLL-2000 shared task: Chunking. arXiv 2000, arXiv:abs/cs/0009008. [Google Scholar]
- Veenstra, J.; Buchholz, S. Fast NP chunking using memory-based learning techniques. In Proceedings of the 8th Belgian—Dutch conference on machine learning, (BENELEARN’98), Wageningen, The Netherlands, 1998; ATO-DLO. pp. 71–78. [Google Scholar]
- MISP Objects—Vulnerability. Available online: https://www.misp-project.org/objects.html#_vulnerability (accessed on 20 February 2021).
- MISP Objects—Weakness. Available online: https://www.misp-project.org/objects.html#_weakness (accessed on 20 February 2021).
- MISP Objects—Exploit-poc. Available online: https://www.misp-project.org/objects.html#_exploit_poc (accessed on 20 February 2021).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MISP | GOSINT | YETI | OpenTAXII | CIF | inTIME | |
|---|---|---|---|---|---|---|
| Human & machine readable | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| API | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Tagging mechanism | ✓ | ✓ | ✓ | ✗ | ✓ | ✓ |
| Correlation mechanism | automatically | ✗ | manually | ✗ | ✗ | automatically, with CPE auto-suggestion |
| Data formats | CSV, XML, JSON, OpenIOC, STIX/TAXII, and more | STIX/TAXII, VERIS, IODEF, IDMEF | JSON | TAXII | JSON, CSV | CSV, XML, JSON, OpenIOC, STIX/TAXII, and more |
| ZeroFox | CTAC | SearchLight | Intel 471 | Security Ratings | Flashpoint | BreachAlert | F5 Labs | inTIME | |
|---|---|---|---|---|---|---|---|---|---|
| Vulnerabilities tracking | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✗ | ✓ | ✓ |
| TTPs tracking | ✓ | ✓ | ✗ | ✓ | ✓ | ✓ | ✗ | ✓ | ✓ |
| Organisation assets’ tracking | ✓ | ✓ | ✓ | ✓ | ✓ | ✗ | ✓ | ✗ | ✓ |
| Deep/dark web monitoring | ✓ | ✓ | ✓ | ✓ | ✗ | ✓ | ✓ | ✓ | ✓ |
| Social media monitoring | ✓ | ✓ | ✓ | ✗ | ✓ | ✗ | ✓ | ✗ | ✓ |
| CTI reports | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| API | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✗ | ✓ |
| Alerting mechanism | ✓ | ✗ | ✓ | ✓ | ✓ | ✓ | ✓ | ✗ | ✓ |
| Helix | Recorded Future | Cyjax | EclecticIQ | Cyber Advisor | BloxOne | ThreatStream | ThreatQ | Soltra | ThreatConnect | VDMR | MANTIS | BrightCloud | inTIME | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Vulnerabilities tracking | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✗ | ✓ | ✓ | ✗ | ✓ |
| TTPs tracking | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✗ | ✓ | ✗ | ✓ |
| Organisation assets’ tracking | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✗ | ✓ | ✓ | ✗ | ✓ | ✓ |
| Threat monitoring (IoCs, Malicious IPs, etc.) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✗ | ✓ | ✓ | ✗ | ✓ | ✓ |
| CTI intercorrelation | ✓ | ✓ | ✓ | ✓ | ✗ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Deep/dark web monitoring | ✓ | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ |
| Social media monitoring | ✓ | ✓ | ✓ | ✗ | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ |
| CTI reports | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Alerting mechanism | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ | ✓ | ✓ | ✗ | ✓ | ✓ |
| Remediation proposals | ✓ | ✓ | ✗ | ✓ | ✓ | ✓ | ✗ | ✓ | ✓ | ✓ | ✓ | ✗ | ✗ | ✓ |
| CTI sharing | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✗ | ✓ | ✗ | ✓ |
| Data formats | STIX/ TAXII, XML, JSON | STIX/ TAXII | STIX/ TAXII, JSON | STIX/ TAXII, OASIS | STIX/ TAXII, JSON | STIX/ TAXII, JSON, CSV, more | STIX/ TAXII, JSON, CSV, more | STIX/ TAXII, Open- IOC, Snort, Suricata | STIX/ TAXII | STIX/ TAXII | JSON, XML | STIX/ TAXII, CybOX, Open- IOC, IODEF, JSON, more | XML | STIX/ TAXII, CSV, XML, JSON, Open- IOC, more |
| On-premises | ✗ | ✗ | ✗ | ✓ | ✗ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| SaaS | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✗ | ✓ | ✓ |
| Positive | Negative |
|---|---|
| 1.CSO Online| IoT, Cloud, or Mobile: All Ripe for Exploit and Need Security’s Attention. | 1.CSO Online| Scammers pose as CNN’s Wolf Blitzer, target security professionals. |
| 2.eSecurity Planet| New IoT Threat Exploits Lack of Encryption in Wireless Keyboards. | 2.eSecurity planet| 19 top UEBA vendors to protect against insider threats and external attacks. |
| 3.Beyond Security| Security Testing the Internet of Things: Dynamic testing (Fuzzing) for IoT security. | 3.SoftLayer| Build your own cloud. |
| Rank | Term | Rank | Term | Rank | Term |
|---|---|---|---|---|---|
| #1 | volumetric | #6 | denial_of_service | #11 | slowloris |
| #2 | dos | #7 | cloudflare | #12 | ip_spoofing |
| #3 | flooding | #8 | prolexic | #13 | loic |
| #4 | flood | #9 | floods | #14 | drdos |
| #5 | sloloris | #10 | aldos | #15 | zombies |
| Excerpt from (accessed June 2020): | www.iotforall.com/5-worst-iot-hacking-vulnerabilities |
|---|---|
| The Mirai Botnet (aka Dyn Attack) Back in October of 2016, the largest DDoS attack ever was launched on service provider Dyn using an IoT botnet. This led to huge portions of the internet going down, including Twitter, the Guardian, Netflix, Reddit, and CNN. | |
| This IoT botnet was made possible by malware called Mirai. Once infected with Mirai, computers continually search the internet for vulnerable IoT devices and then use known default usernames and passwords to log in, infecting them with malware. These devices were things like digital cameras and DVR players. | |
| Relevance Score: | 0.8563855440900794 |
| Type | Description | Source |
|---|---|---|
| PERSON | People, including fictional. | Pre-trained model |
| ORG | Companies, agencies, institutions, etc. | Pre-trained model, PhraseMatcher |
| PRODUCT | Objects, vehicles, foods, etc. | Pre-trained model, PhraseMatcher, RegexMatcher |
| DATE | Absolute or relative dates or periods. | Pre-trained model |
| TIME | Times smaller than a day. | Pre-trained model |
| MONEY | Monetary values. | Pre-trained model, RegexMatcher |
| CVE | Common Vulnerabilities and Exposures (CVE) identifier. | Regex Matcher |
| CPE | Common Platform Enumeration (CPE) identifier. | Regex Matcher |
| CWE | Common Weakness Enumeration (CWE) identifier. | Regex Matcher |
| CVSS2_VECTOR | Common Vulnerability Scoring System (CVSS) v2. | Regex Matcher |
| CVSS3_VECTOR | Common Vulnerability Scoring System (CVSS) v3.0-v3.1. | Regex Matcher |
| IP | IP address. | Regex Matcher |
| VERSION | Software version. | Regex Matcher |
| FILE | Filename or file extension. | Regex Matcher |
| COMMAND/FUNCTION/ CONFIG | Shell command, code function or configuration setting. | Regex Matcher |
| # | Product | CPE | Score |
|---|---|---|---|
| 1 | Apache Struts | cpe:/a:apache:struts | 1160.75 |
| 2 | Apache Struts Showcase App | cpe:/a:apache:struts2-showcase | 1148.02 |
| 3 | Apache Storm | cpe:/a:apache:storm | 748.68 |
| 4 | Apache Stats | cpe:/a:apache_stats:apache_stats | 748.68 |
| 5 | Apache LDAP Studio | cpe:/a:apache:apache_ldap_studio | 734.84 |
| 6 | Apache Directory Studio | cpe:/a:apache:apache_directory_studio | 730.98 |
| 7 | Apache Standard Taglibs | cpe:/a:apache:standard_taglibs | 720.43 |
| 8 | Apache Solr | cpe:/a:apache:solr | 643.65 |
| 9 | Apache Shindig | cpe:/a:apache:shindig | 642.21 |
| 10 | Apache Syncope | cpe:/a:apache:syncope | 642.21 |
| # | Product | CPE | Score |
|---|---|---|---|
| 1 | Apache Struts Showcase App | cpe:/a:apache:struts2-showcase | 223.72 |
| 2 | Apache Struts | cpe:/a:apache:struts | 195.83 |
| 3 | S2Struts | cpe:/a:theseasar_foundation:s2struts | 170.00 |
| Metric | NFP Model | WFP Model |
|---|---|---|
| Total Pages | 392,157 | 1,020,983 |
| Relevant Pages | 37,157 | 1,012,045 |
| Irrelevant Pages | 355,000 | 8938 |
| Harvest Rate | 9.475% | 99.125% |
| Metric | Classifier | Train CVE – | Train CVE – | Train No CVE – | Train No CVE– |
|---|---|---|---|---|---|
| Test CVE | Test No CVE | Test CVE | Test No CVE | ||
| Accuracy | Random Forest | 0.8737 | 0.8744 | 0.8751 | 0.8751 |
| CNN | 0.8542 | 0.8287 | 0.8426 | 0.8483 | |
| Precision | Random Forest | 0.8914 | 0.8799 | 0.8925 | 0.8925 |
| CNN | 0.8491 | 0.8440 | 0.8714 | 0.8595 | |
| Recall | Random Forest | 0.8484 | 0.8645 | 0.8503 | 0.8503 |
| CNN | 0.8581 | 0.8025 | 0.8002 | 0.8291 | |
| F1-score | Random Forest | 0.8694 | 0.8721 | 0.8709 | 0.8709 |
| CNN | 0.8536 | 0.8227 | 0.8343 | 0.8441 |
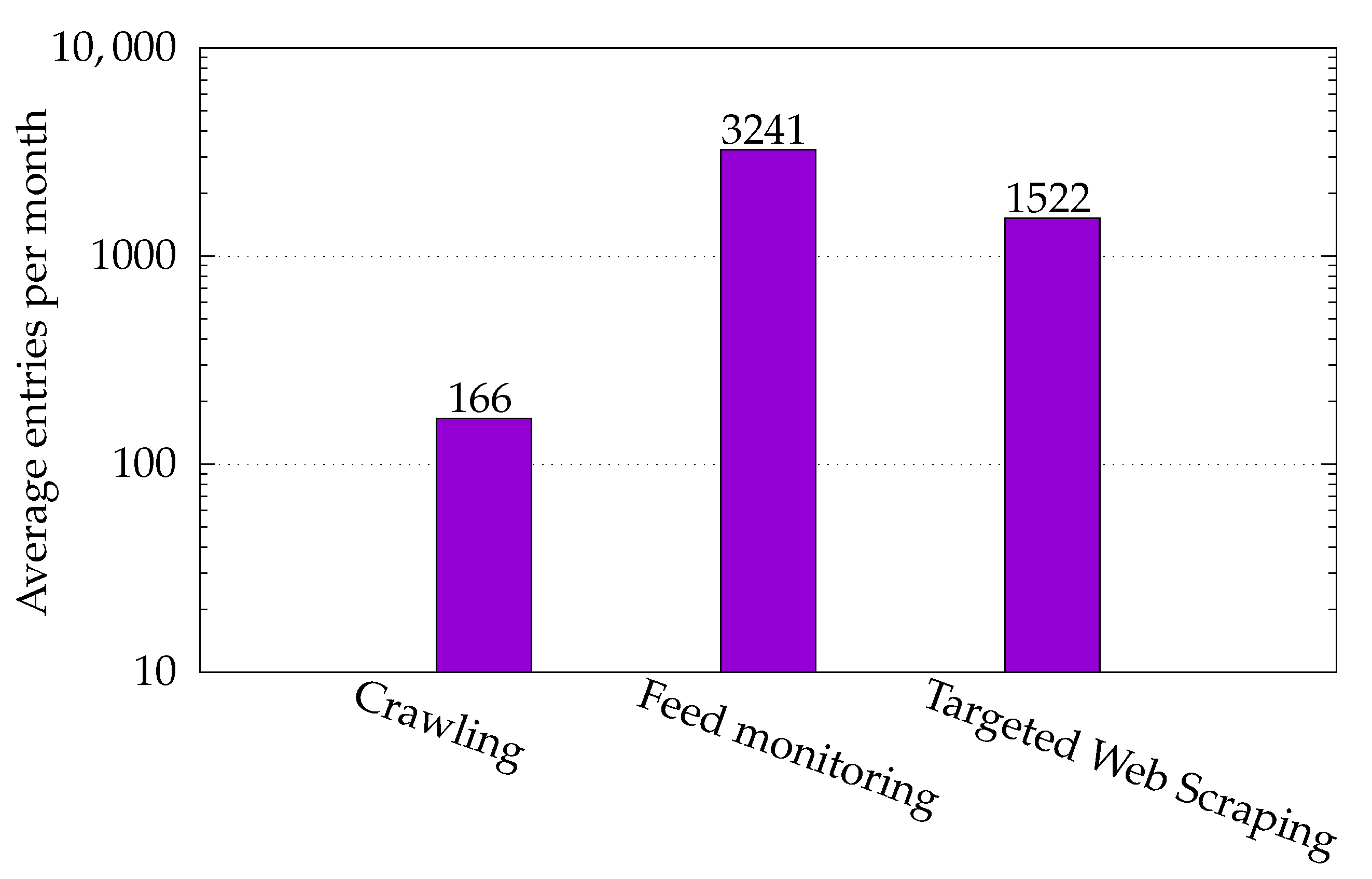
| Source | Number of Artifacts |
|---|---|
| Crawling | ~4000 |
| Feed monitoring | ~157,000 |
| Targeted Web Scraping | ~115,000 |
| Total Entries | ~181,000 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koloveas, P.; Chantzios, T.; Alevizopoulou, S.; Skiadopoulos , S.; Tryfonopoulos , C. inTIME: A Machine Learning-Based Framework for Gathering and Leveraging Web Data to Cyber-Threat Intelligence. Electronics 2021, 10, 818. https://doi.org/10.3390/electronics10070818
Koloveas P, Chantzios T, Alevizopoulou S, Skiadopoulos S, Tryfonopoulos C. inTIME: A Machine Learning-Based Framework for Gathering and Leveraging Web Data to Cyber-Threat Intelligence. Electronics. 2021; 10(7):818. https://doi.org/10.3390/electronics10070818
Chicago/Turabian StyleKoloveas, Paris, Thanasis Chantzios, Sofia Alevizopoulou, Spiros Skiadopoulos , and Christos Tryfonopoulos . 2021. "inTIME: A Machine Learning-Based Framework for Gathering and Leveraging Web Data to Cyber-Threat Intelligence" Electronics 10, no. 7: 818. https://doi.org/10.3390/electronics10070818
APA StyleKoloveas, P., Chantzios, T., Alevizopoulou, S., Skiadopoulos , S., & Tryfonopoulos , C. (2021). inTIME: A Machine Learning-Based Framework for Gathering and Leveraging Web Data to Cyber-Threat Intelligence. Electronics, 10(7), 818. https://doi.org/10.3390/electronics10070818