
On the Transformation Optimization for Stencil Computation

Abstract
:1. Introduction
1.1. Stencil Computation
1.2. Loop Transformation
- Depicting the optimization recipes for loop transformation in detail and introducing their separate advantages and disadvantages as well as their specific scope of application.
- Implementing the mentioned recipes as well as a combination of the recipes on various stencil computation kernels to explore their potential benefits.
- Validating the transformation recipes on various stencil computation instances to illustrate their effectiveness experimentally on two common architectures.
2. Background
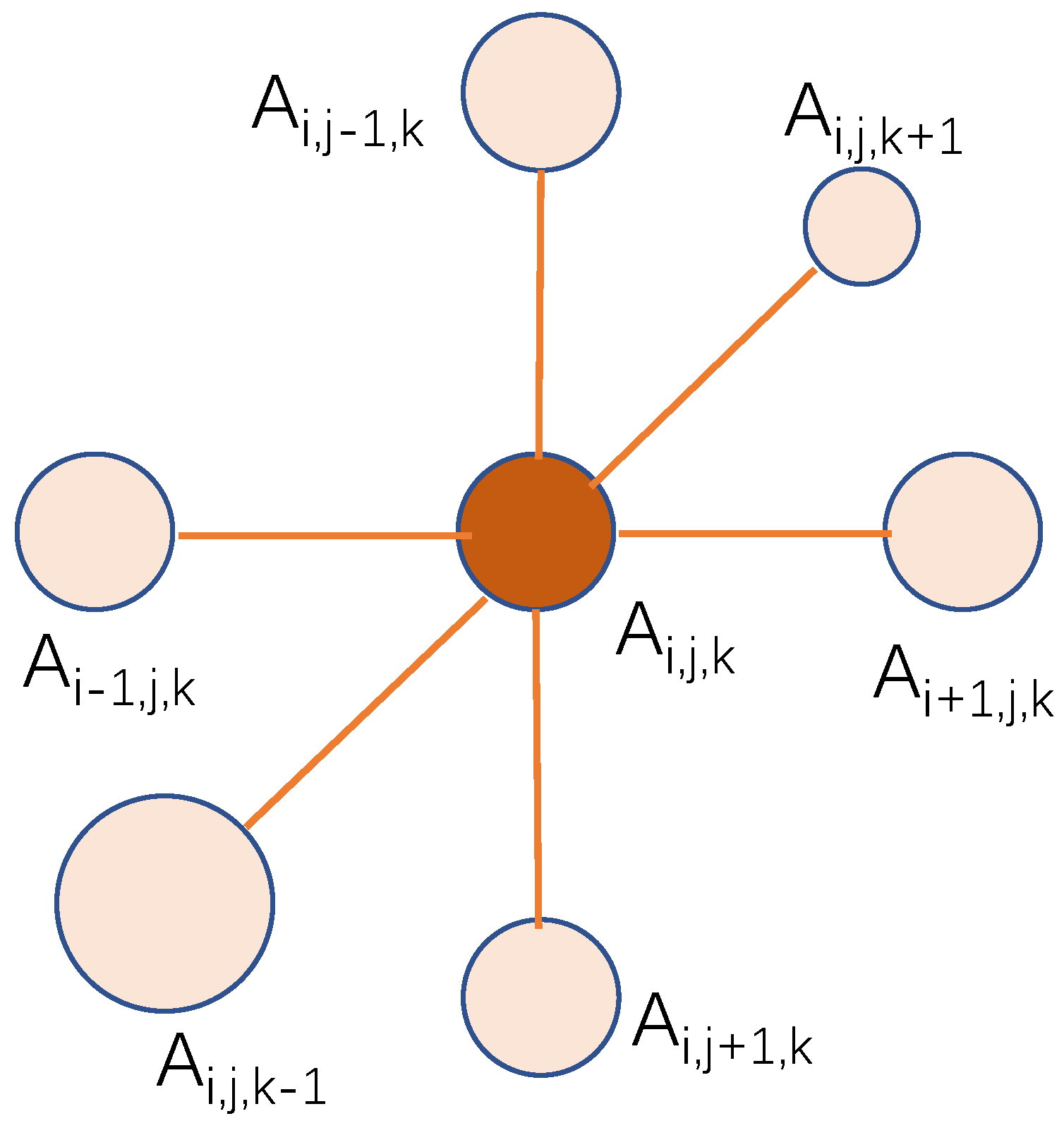
2.1. The Stencil Problem
- First, it is the non-continuous memory access pattern. There exist distances among elements needed for the computation except those in the innermost or the unit-stride dimension. Many more cycles in latencies are required to access these points. Furthermore, much more costs are paid with a bigger stencil radius.
- Second, it is the low arithmetic intensity and poor data reuse. Just one point is updated with all the elements loaded. The data reuse between two updates is also limited within the unit-stride dimension, while the other dimensions’ elements that are expensive to access have no data reuse at all.
| Algorithm 1 The classical stencil algorithm pseudo-code for a 3D problem [1] |
Require:, , r, , , , , , ;
|
3. Transformation Optimizations Recipes
3.1. Loop Unrolling
| Algorithm 2 Loop unrolling algorithm |
Require:, , r, , , , , , , ;
|
3.2. Loop Fusion
| Algorithm 3 Loop fusion algorithm |
Require:, , r, , , , , , , H, , ;
|
3.3. Address Precalculation
3.3.1. Code Analysis
| Algorithm 4 Original stencil code with linear array access |
Require:, , , , , , , , , , ;
|
3.3.2. Integrate the Changes
| Algorithm 5 Stencil code with optimized index access |
Require:, , P, , , , , , , , , ;
|
3.4. Redundancy Elimination
| Algorithm 6 Stencil computation with the principle of sub-expression elimination |
Require:, , , , , , , , , ;
|
3.5. Instruction Reordering
| Algorithm 7 Expand the 2 original iteration formulas |
Require:, , , , , , , ;
|
| Algorithm 8 Continue to expand the formula in Algorithm 7 |
Require:, , , , , , , ;
|
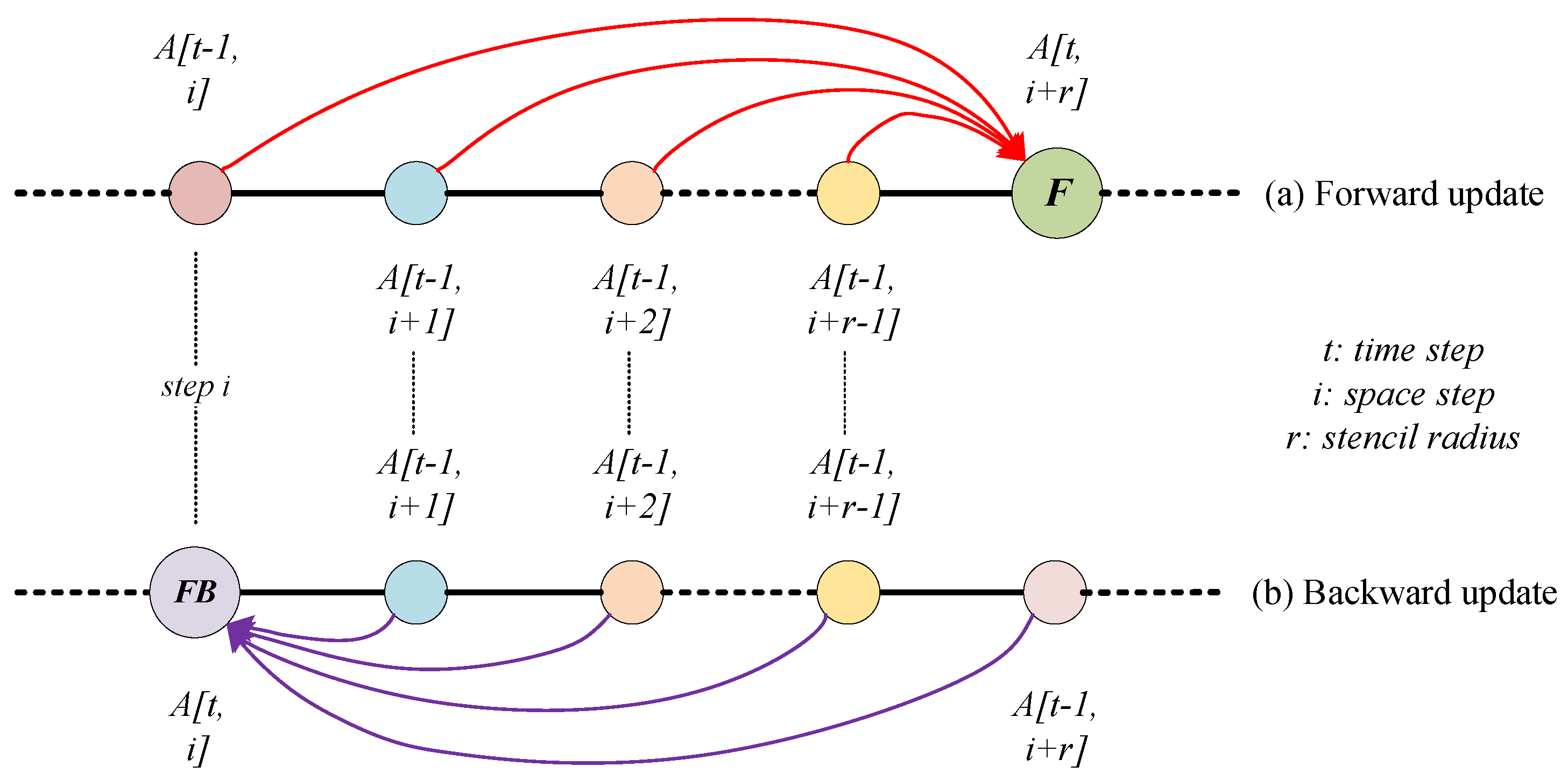
3.6. Forward and Backward Update Algorithm
3.6.1. Forward and Backward Updates
3.6.2. Arithmetic Intensity Analysis
3.7. Load Balance
| Algorithm 9 Stencil computation with load balance |
Require:, , , , , , , ;
|
3.8. Put It All Together
4. Experimental Evaluations
4.1. Stencil Benchmarks
4.2. Testbed Architectures
- Intel Xeon E5: Intel Xeon CPU E5-2640 v4 @ 2.40 GHz, with 20 physical cores divided into 2 NUMA nodes, and AVX supported.
- ARM: ARMv8 ISA64 compatible processors, with 64 physical cores in total and evenly divided into 8 NUMA nodes, and SIMD Extension NEON supported [18].
4.3. Results and Analysis
5. Related Work
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Cruz, R.D.L.; Araya-Polo, M. Algorithm 942: Semi-Stencil. ACM Trans. Math. Softw. 2014, 40, 1–39. [Google Scholar] [CrossRef]
- OLCF Titan Summit 2011. Available online: https://www.olcf.ornl.gov/event/titan2011 (accessed on 9 October 2021).
- Diede, T.; Hagenmaier, C.F. The Titan Graphics Supercomputer architecture. Computer 1988, 21, 13–30. [Google Scholar] [CrossRef]
- Bacon, D.F.; Graham, S.L.; Sharp, O.J. Compiler Transformations for High-Performance Computing. ACM Comput. Surv. 1994, 26, 345–420. [Google Scholar] [CrossRef] [Green Version]
- Banerjee, U. Loop Transformations for Restructuring Compilers: The Foundations; Springer: Berlin/Heidelberg, Germany, 1993. [Google Scholar]
- Sarkar, V.; Thekkath, R. A general framework for iteration-reordering loop transformations. ACM Sigplan Not. 1992, 27, 175–187. [Google Scholar] [CrossRef]
- Wolf, M.E.; Lam, M.S. A Loop Transformation Theory and an Algorithm to Maximize Parallelism; IEEE Press: Piscataway, NJ, USA, 1991. [Google Scholar]
- Cocke, J. Global common subexpression elimination. ACM Sigplan Not. 1970, 5, 20–24. [Google Scholar] [CrossRef]
- Armejach, A.; Caminal, H.; Cebrian, J.M.; Langarita, R.; González-Alberquilla, R.; Adeniyi-Jones, C.; Valero, M.; Casas, M.; Moretó, M. Using Arm’s scalable vector extension on stencil codes. J. Supercomput. 2019, 76, 2039–2062. [Google Scholar] [CrossRef]
- Armejach, A.; Caminal, H.; Cebrian, J.M.; González-Alberquilla, R.; Adeniyi-Jones, C.; Valero, M.; Casas, M.; Moretó, M. Stencil codes on a vector length agnostic architecture. In Proceedings of the 27th International Conference on Parallel Architectures and Compilation Techniques, Portland, OR, USA, 9–13 September 2018; pp. 1–12. [Google Scholar]
- Manjikian, N.; Abdelrahman, T.S. Fusion of loops for parallelism and locality. Parallel Distrib. Syst. IEEE Trans. 1997, 8, 193–209. [Google Scholar] [CrossRef]
- Kennedy, K.; Mckinley, K.S. Maximizing Loop Parallelism and Improving Data Locality via Loop Fusion and Distribution. In Languages & Compilers for Parallel Computing; Springer: Berlin/Heidelberg, Germany, 1994. [Google Scholar]
- Stefan, K. Automatic Performance Optimization of Stencil Codes. Ph.D. Thesis, Universität Passau, Passau, Germany, 2020. [Google Scholar]
- Aho, A.V.; Lam, M.S.; Sethi, R.; Ullman, J.D. Compilers: Principles, Techniques, and Tools, 2nd ed.; Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 2006. [Google Scholar]
- Rawat, P.S.; Rajam, A.S.; Rountev, A.; Rastello, F.; Sadayappan, P. Associative Instruction Reordering to Alleviate Register Pressure. In Proceedings of the SC18: International Conference for High Performance Computing, Networking, Storage and Analysis, Dallas, TX, USA, 11–16 November 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- de la Cruz, R.; Arayapolo, M.; Cela, J.M. Introducing the Semi-Stencil Algorithm; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Williams, S.; Waterman, A.; Patterson, D.A. Roofline: An insightful visual performance model for multicore architectures. Commun. ACM 2009, 52, 65–76. [Google Scholar] [CrossRef]
- JianBin, F.; XiangKe, L.; Chun, H.; De Zun, D. Performance Evaluation of Memory-Centric ARMv8 Many-Core Architectures: A Case Study with Phytium 2000+. J. Comput. Sci. Technol. 2021, 36, 33–43. [Google Scholar]
- GCC, the GNU Compiler Collection. Available online: https://www.gnu.org/software/gcc/libstdc++/ (accessed on 12 June 2021).
- Using the GNU Compiler Collection (GCC). Available online: https://gcc.gnu.org/onlinedocs/gcc/Optimize-Options.html#Optimize-Options (accessed on 20 October 2020).
- Bassetti, F.; Davis, K.; Quinlan, D.J. Optimizing Transformations of Stencil Operations for Parallel Object-Oriented Scientific Frameworks on Cache-Based Architectures. In Proceedings of the International Symposium on Computing in Object-Oriented Parallel Environments, Santa Fe, NM, USA, 8–11 December 1998; IEEE: Piscataway, NJ, USA, 1998. [Google Scholar]
- Yun, Z. Towards Automatic Compilation for Energy Efficient Iterative Stencil. Ph.D. Thesis, Colorado State University, Fort Collins, CO, USA, 2016. [Google Scholar]
- Seyfari, Y.; Lotfi, S.; Karimpour, J. Optimizing inter-nest data locality in imperfect stencils based on loop blocking. J. Supercomput. 2018, 74, 5432–5460. [Google Scholar] [CrossRef]
- Donglin, C.; Jianbin, F.; Chuanfu, X.; Shizhao, C.; Zheng, W. Optimizing Sparse Matrix-Vector Multiplications on An ARMv8-based Many-Core Architecture. Int. J. Parallel Program. 2019, 48, 418–432. [Google Scholar]
- Hall, M.; Chame, J.; Chen, C.; Shin, J.; Rudy, G.; Khan, M.M. Loop Transformation Recipes for Code Generation and Auto-Tuning; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Hall, M.W.; Chame, J.N.; Chen, C.; Shin, J.; Rudy, G.; Khan, M. Loop transformation recipes for code generation and auto-tuning. In Proceedings of the International Workshop on Languages and Compilers for Parallel Computing, Newark, DE, USA, 8–10 October 2009; IEEE: Piscataway, NJ, USA, 2009. [Google Scholar]
- Hall, M. Model-Guided Empirical Optimization for Memory Hierarchy. Available online: https://dl.acm.org/doi/10.5555/1329582 (accessed on 9 October 2021).
- Chen, C.; Shin, J.; Kintali, S.; Chame, J.; Hall, M. Model-Guided Empirical Optimization for Multimedia Extension Architectures: A Case Study. In Parallel and Distributed Processing Symposium; IEEE: Piscataway, NJ, USA, 2007. [Google Scholar]
- Yi, Q.; Seymour, K.; You, H.; Vuduc, R.W.; Quinlan, D.J. POET: Parameterized Optimizations for Empirical Tuning. In Proceedings of the 21th International Parallel and Distributed Processing Symposium (IPDPS 2007), Long Beach, CA, USA, 26–30 March 2007. [Google Scholar]
- István, Z. Reguly, Gihan R. Mudalige, M.B.G. Loop Tiling in Large-Scale Stencil Codes at Run-Time with OPS. IEEE Trans. Parallel Distrib. Syst. 2018, 4, 873–886. [Google Scholar]
- Basu, P.; Hall, M.; Williams, S.; Straalen, B.V.; Oliker, L.; Colella, P. Compiler-Directed Transformation for Higher-Order Stencils. In Proceedings of the 2015 IEEE International Parallel and Distributed Processing Symposium, Hyderabad, India, 25–29 May 2015; IEEE: Piscataway, NJ, USA, 2015. [Google Scholar]
- Advanced Stencil-Code Engineering (ExaStencils). Available online: https://www.exastencils.fau.de/ (accessed on 6 September 2021).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Range of Values |
|---|---|
| Problem sizes | 16 M, 32 M, 64 M (1D), , , (2D) , , , (3D) |
| Stencil sizes(r) | 1, 2, 4, 5, 7, 14 |
| Stencil | 1D 3pt, 1D 11pt, 2D 5pt, 2D 121pt, 3D 7pt, 3D 13pt, 3D 25pt, 3D 27pt, 3D 43pt, 3D 85pt, 3D 125pt Jacobi |
| Time-steps | 1, 100 |
| Algorithms | naive, loop unroll, loop fusion, address precalculation redundancy elimination, instruction reordering semi-stencil, load balance, compound recipes |
| Core Architecture | ||
|---|---|---|
| Type | superscalar out-of-order | superscalar out-of-order |
| SIMD | NEON | AVX |
| Threads/Core | 1 | 1 |
| Clock (GHz) | 2.2-2.4 | 2.4 |
| DP (GFlops) | 8.8 | 19.2 |
| L1 Cache (D + I) | 32 KB + 32 KB | 32 KB + 32 KB |
| Socket Architecture | ||
| Cores/Socket | 4 | 10 |
| L2 Data Cache | 2 MB/4 Cores | 256 KB |
| Shared L3 Data Cache | - | 25 MB |
| primary memory parallelism paradigm | HW prefetch | HW prefetch |
| System Architecture | ||
| Sockets/SMP | 2 | 1 |
| DP (GFlops) | 563.2 @ 2.2 GHz | 384 |
| DRAM BW (GB/s) | 204.8 | 68.3 |
| DP Flop: Byte Ratio | 2.75 | 5.62 |
| DRAM Capacity (GB) | 256 | 64 |
| DRAM Type | DDR4-2666 | DDR4-2133 |
| System Power (W) | 100 | 90 |
| Compiler | gcc 8.3 | gcc 4.8 |
| 3D 7pt | N | Naive | Fusion | Speedup |
|---|---|---|---|---|
| T = 1 | 128 | 1.15 | 1.15 | 1.00 |
| T = 100 | 1.46 | 1.18 | 0.81 | |
| T = 1 | 256 | 1.23 | 0.91 | 0.74 |
| T = 100 | 1.56 | 0.92 | 0.58 | |
| T = 1 | 512 | 0.94 | 0.79 | 0.84 |
| T = 100 | 1.13 | 0.80 | 0.70 | |
| 2D 5pt | N | naive | fusion | Speedup |
| T = 1 | 8K | 0.63 | 0.74 | 1.17 |
| T = 100 | 0.76 | 0.75 | 0.99 | |
| T = 1 | 16K | 0.60 | 0.62 | 1.02 |
| T = 100 | 0.73 | 0.62 | 0.85 | |
| T = 1 | 32K | 0.53 | 0.47 | 0.87 |
| T = 100 | 0.64 | 0.46 | 0.73 | |
| 1D 3pt | N | naive | fusion | Speedup |
| T = 1 | 16M | 0.89 | 0.57 | 0.64 |
| T = 100 | 1.67 | 0.57 | 0.34 | |
| T = 1 | 32M | 0.90 | 0.55 | 0.61 |
| T=100 | 1.66 | 0.55 | 0.33 | |
| T = 1 | 64M | 0.90 | 0.53 | 0.59 |
| T = 100 | 1.66 | 0.53 | 0.32 |
| 3D-7pt | N | Naive | Fusion | Speedup |
|---|---|---|---|---|
| T = 1 | 128 | 2.03 | 3.83 | 1.88× |
| T = 100 | 4.20 | 4.34 | 1.03× | |
| T = 1 | 256 | 2.57 | 3.74 | 1.45× |
| T = 100 | 4.05 | 3.75 | 0.92× | |
| T = 1 | 512 | 2.48 | 3.67 | 1.48× |
| T = 100 | 3.89 | 3.67 | 0.94× | |
| 2D-5pt | N | naive | fusion | Speedup |
| T = 1 | 8K | 1.68 | 2.46 | 1.45× |
| T = 100 | 2.57 | 2.45 | 0.95× | |
| T = 1 | 16K | 1.61 | 2.39 | 1.48× |
| T = 100 | 2.40 | 2.39 | 0.99× | |
| T = 1 | 32K | 1.35 | 2.39 | 1.76× |
| T = 100 | 2.08 | 2.13 | 1.02× | |
| 1D-3pt | N | naive | fusion | Speedup |
| T = 1 | 16M | 1.03 | 0.79 | 0.76× |
| T = 100 | 1.67 | 0.79 | 0.47× | |
| T = 1 | 32M | 1.04 | 0.79 | 0.75× |
| T = 100 | 1.66 | 0.80 | 0.48× | |
| T = 1 | 64M | 1.02 | 0.81 | 0.79× |
| T = 100 | 1.69 | 0.81 | 0.48× |
| N | Version | r = 1 | r = 2 | r = 4 | r = 7 | r = 14 | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| GFs. | Spe. | GFs. | Spe. | GFs. | Spe. | GFs. | Spe. | GFs. | Spe. | ||
| 128 | naive | 1.85 | 1.00× | 2.52 | 1.00× | 1.55 | 1.00× | 1.16 | 1.00× | 1.17 | 1.00× |
| fb | 1.45 | 0.78× | 2.16 | 0.86× | 1.62 | 1.05× | 1.38 | 1.19× | 1.79 | 1.53× | |
| 256 | naive | 1.96 | 1.00× | 1.62 | 1.00× | 1.44 | 1.00× | 0.95 | 1.00× | 0.83 | 1.00× |
| fb | 1.47 | 0.75× | 1.48 | 0.91× | 1.45 | 1.01× | 1.09 | 1.15× | 1.41 | 1.70× | |
| 512 | naive | 1.41 | 1.00× | 1.99 | 1.00× | 1.32 | 1.00× | 1.00 | 1.00× | 0.75 | 1.00× |
| fb | 0.55 | 0.39× | 1.71 | 0.86× | 1.45 | 1.10× | 1.07 | 1.07× | 1.20 | 1.60× | |
| 1024 | naive | 0.84 | 1.00× | 1.61 | 1.00× | 1.40 | 1.00× | 0.93 | 1.00× | 0.69 | 1.00× |
| fb | 0.82 | 0.98× | 1.11 | 0.69× | 1.43 | 1.02× | 0.92 | 0.99× | 1.06 | 1.52× | |
| N | Version | r = 1 | r = 2 | r = 4 | r = 7 | r = 14 | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| GFs. | Spe. | GFs. | Spe. | GFs. | Spe. | GFs. | Spe. | GFs. | Spe. | ||
| 128 | naive | 4.73 | 1.00× | 5.84 | 1.00× | 2.37 | 1.00× | 2.18 | 1.00× | 2.52 | 1.00× |
| fb | 3.19 | 0.68× | 4.12 | 0.71× | 2.91 | 1.23× | 2.13 | 0.98× | 2.77 | 1.10× | |
| 256 | naive | 5.06 | 1.00× | 5.66 | 1.00× | 2.27 | 1.00× | 1.73 | 1.00× | 1.76 | 1.00× |
| fb | 3.17 | 0.63× | 4.05 | 0.72× | 2.68 | 1.18× | 1.82 | 1.05× | 1.95 | 1.10× | |
| 512 | naive | 2.44 | 1.00× | 3.96 | 1.00× | 2.04 | 1.00× | 1.74 | 1.00× | 1.15 | 1.00× |
| fb | 1.48 | 0.61× | 3.76 | 0.95× | 2.36 | 1.16× | 1.69 | 0.97× | 1.70 | 1.47× | |
| 1024 | naive | 2.56 | 1.00× | 3.60 | 1.00× | 1.88 | 1.00× | 1.59 | 1.00× | 1.06 | 1.00× |
| fb | 1.99 | 0.78× | 2.81 | 0.78× | 1.94 | 1.03× | 1.59 | 1.00× | 1.54 | 1.45× | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Su, H.; Zhang, K.; Mei, S. On the Transformation Optimization for Stencil Computation. Electronics 2022, 11, 38. https://doi.org/10.3390/electronics11010038
Su H, Zhang K, Mei S. On the Transformation Optimization for Stencil Computation. Electronics. 2022; 11(1):38. https://doi.org/10.3390/electronics11010038
Chicago/Turabian StyleSu, Huayou, Kaifang Zhang, and Songzhu Mei. 2022. "On the Transformation Optimization for Stencil Computation" Electronics 11, no. 1: 38. https://doi.org/10.3390/electronics11010038