
Part-of-Speech Tagging with Rule-Based Data Preprocessing and Transformer


Abstract
:1. Introduction
- (1)
- To further improve the accuracy of POS tagging, we propose a novel approach for POS tagging, which combines the rule-based methods and deep learning.
- (2)
- We implement a rule-based method to tag some portion of the words. It can enhance the performance of POS tagging when combined with deep learning.
- (3)
- The proposed method utilizes the self-attention to capture dependencies between words at any distance. Moreover, we mask a certain portion of POS tags and the model only predicts the masked POS tags, which enables the model to better exploit the global contextual information.
- (4)
- We evaluate our method on a public dataset. On the dataset, the method achieves a per-token tag accuracy of 98.6% and a whole-sentence correct rate of 76.04%. Experimental results demonstrate the effectiveness of the method.
2. Related Work
2.1. Penn Treebank Tagset
2.2. POS Tagging
2.3. Transformer
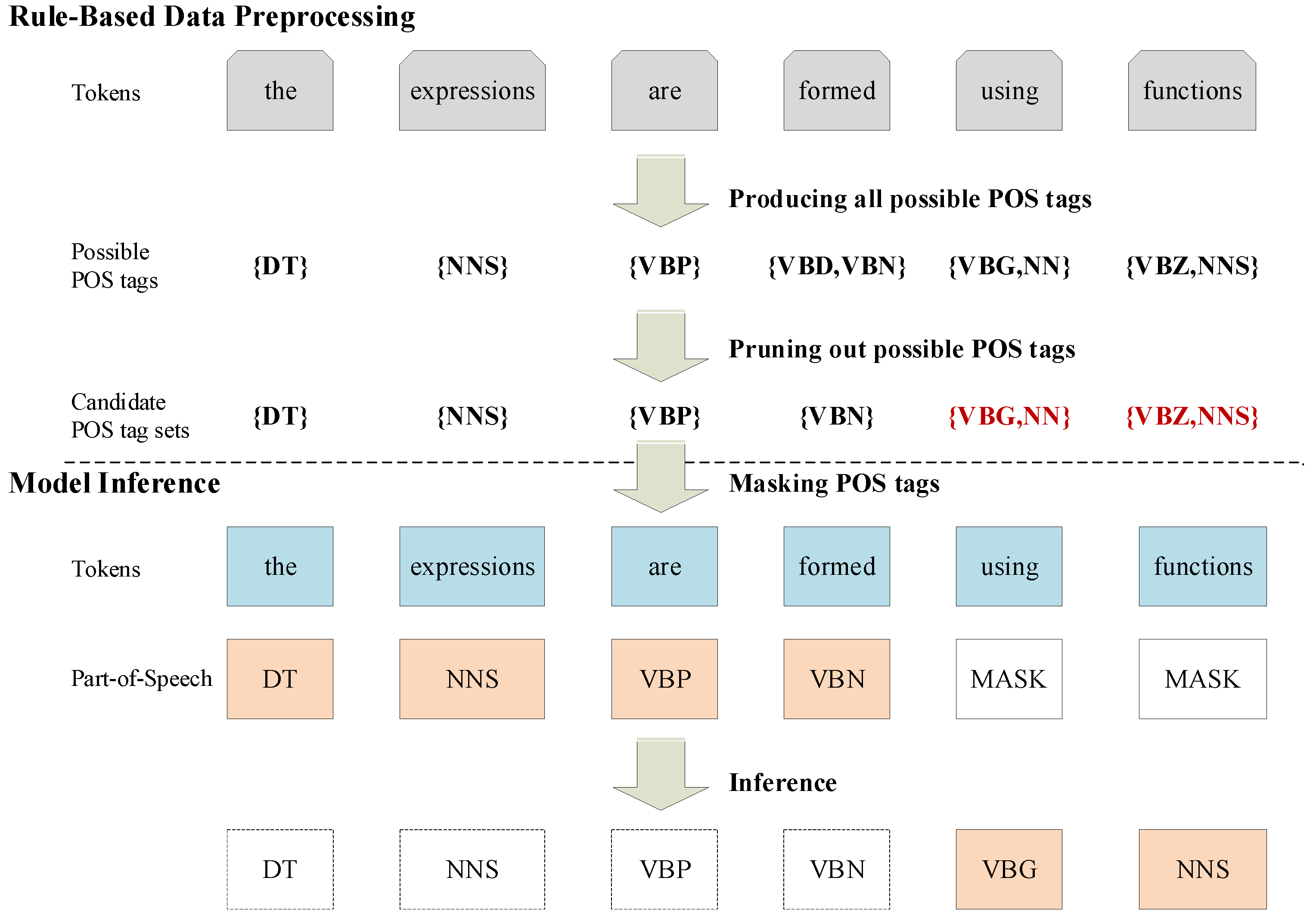
3. Rule-Based Data Preprocessing
3.1. Producing All Possible POS Tags
3.2. Pruning out Possible POS Tags
- It follows a preposition or determiner, and these tags are VB, VBP, VBD, VBZ, and MD.
- It follows an adjective, and these tags are RB, RBR, RBS, VB, VBP, VBD, VBZ, and MD.
- It is followed by an adverb, and these tags are JJ, JJR, and JJS.
- It is followed by or follows a verb with the POS tag VB, VBP, VBD, VBZ, or MD, and these tags are VB, VBP, VBD, VBZ, and MD.
- If it follows a preposition or determiner, or there are modifiers between the word and the preposition or the determiner, and the word can be used as a noun but cannot be used as a modifier, then the word is tagged NN or NNS.
- If it is followed by a noun and its candidate POS tags contains JJ, JJR, JJS, VBN, or VBG, then these POS tags are selected as new candidate POS tags.
- If it is followed by an adjective and its candidate POS tags contains RB, RBR, RBS, VB, VBP, VBD, VBN, or VBZ, then these POS tags are selected as new candidate POS tags.
- It is the first word in a sentence.
- It follows an adverb that is the first word in a sentence.
- It follows the word to or there are adverbs between it and the word to.
| Algorithm 1: The pruning |
| Input: The rules rules, all the words in a sentence words, and their candidate POS tagsets sets |
| changed = TRUE |
| while changed == TRUE |
| flag = FALSE |
| for i = 1 to rules.length |
| rule = rules[i] |
| flag = (flag || ApplyRule(rule, words, sets)) |
| changed = flag |
3.3. Masking POS Tags
4. Tagging with Transformer
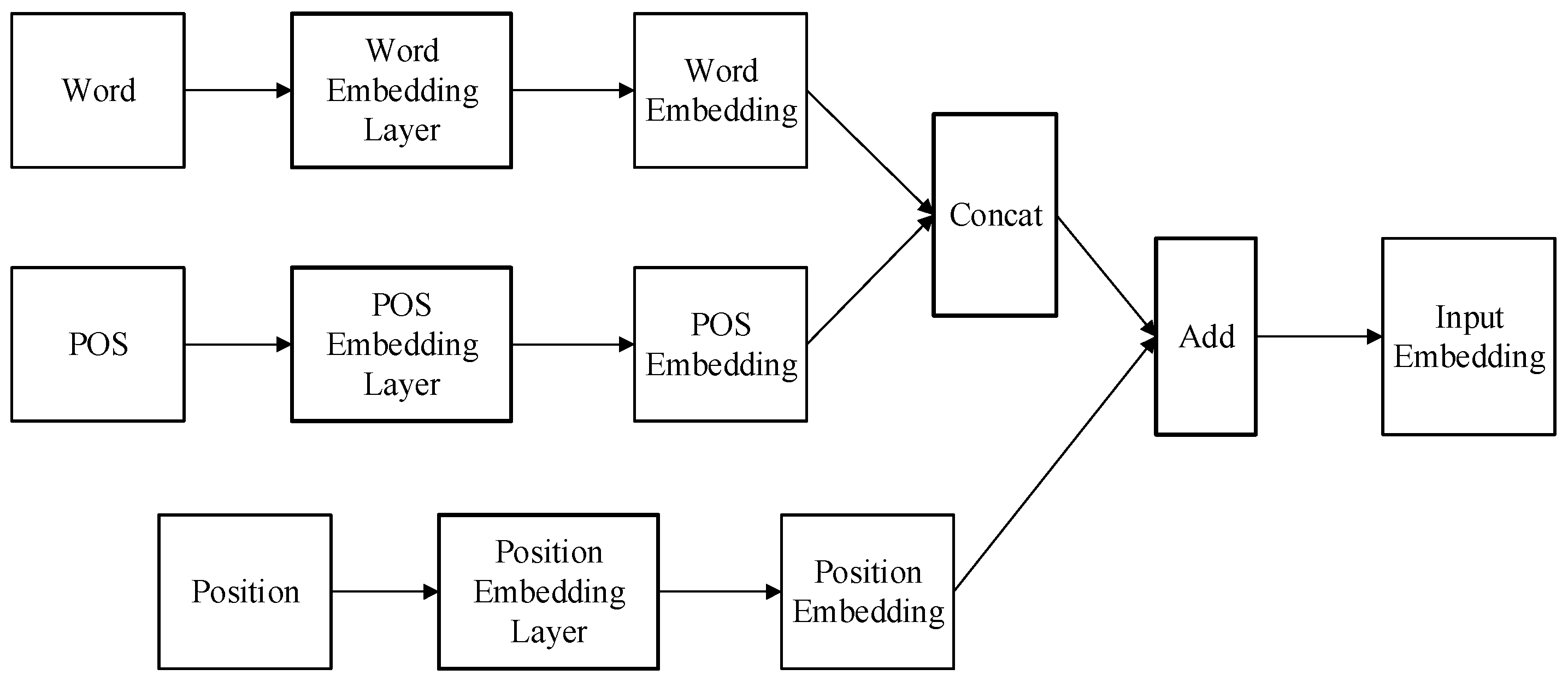
4.1. Model
4.2. Training
4.3. Inference
5. Experiments
5.1. Dataset
5.2. Settings
5.3. Evaluation
- Bi-LSTM: A two-layer Bi-LSTM with the hidden size 50 is used, where we do not load pretrained word embeddings in word embedding layer.
- BLSTM RNN with word embedding [20]: In addition to a two-layer Bi-LSTM with the hidden size 100, a function is introduced to indicate original case of words. For a fair comparison, 100-dimensional Glove word embeddings are adopted in word embedding layer.
- C2W: A C2W model [21] is employed to generate 100-dimensional character-level embeddings of words, and a two-layer Bi-LSTM with the hidden size 100 takes the embeddings as input for POS tagging. The C2W model is composed of a character embedding layer and a unidirectional LSTM with the hidden size 100. For the character embedding layer in the C2W model, it generates 50-dimensional embeddings of characters, which are fed into the unidirectional LSTM to produce 100-dimensional character-level embeddings of words.
- Highway Bi-LSTM: A two-layer highway Bi-LSTM [23] with the hidden size 150 is adopted. The input to the highway Bi-LSTM comes from two parts: 100-dimensional Glove word embeddings and 50-dimensional character-level embeddings generated by a C2W model. In the C2W model, the character embedding layer yields 10-dimensional embeddings of characters and the unidirectional LSTM produces 50-dimensional character-level embeddings of words.
- Transformer’s Encoder: The rule-based data preprocessing is removed from our method to verify whether the data preprocessing can deliver the performance gains. Without the rule-based data preprocessing, we cannot mask a certain portion of POS tags. Thus, the encoder of the Transformer is used to predict POS tags of all tokens.
- MLP with the data preprocessing: To verify the effectiveness of the self-attention mechanism on POS tagging, the multi-head attention layers are removed from the Transformer’s encoder, which degenerates to a multilayer perceptron (MLP). With the rule-based data preprocessing, the MLP only predicts the masked POS tags. It is difficult to capture dependencies between words due to lack of the self-attention layers.
6. Conclusions
7. Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hajic, J.; Ciaramita, M.; Johansson, R.; Kawahara, D.; Martí, M.A.; Màrquez, L.; Meyers, A.; Nivre, J.; Padó, S.; Stepánek, J.; et al. The CoNLL-2009 shared task: Syntactic and semantic dependencies in multiple languages. In Proceedings of the Thirteenth Conference on Computational Natural Language Learning (CoNLL 2009), Boulder, CO, USA, 4–5 June 2009; pp. 1–18. [Google Scholar]
- Yang, X.; Liu, Y.; Xie, D.; Wang, X.; Balasubramanian, N. Latent part-of-speech sequences for neural machine translation. arXiv 2019, arXiv:1908.11782. [Google Scholar]
- Tan, Y.; Wang, X.; Jia, T. From syntactic structure to semantic relationship: Hypernym extraction from definitions by recurrent neural networks using the part of speech information. In Proceedings of the 19th International Semantic Web Conference, Athens, Greece, 2–6 November 2020. [Google Scholar]
- Qi, P.; Zhang, Y.; Zhang, Y.; Bolton, J.; Manning, C.D. Stanza: A python natural language processing toolkit for many human languages. arXiv 2020, arXiv:2003.07082. [Google Scholar]
- Zhou, H.; Zhang, Y.; Li, Z.; Zhang, M. Is POS tagging necessary or even helpful for neural dependency parsing? In Proceedings of the Natural Language Processing and Chinese Computing, Zhengzhou, China, 14–18 October 2020; pp. 179–191. [Google Scholar]
- Manning, C.D. Part-of-speech tagging from 97% to 100%: Is it time for some linguistics? In Proceedings of the Computational Linguistics and Intelligent Text Processing, Tokyo, Japan, 20–26 February 2011; pp. 171–189. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Processing 1997, 45, 2673–2681. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Marcus, M.P.; Santorini, B.; Marcinkiewicz, M.A. Building a large annotated corpus of English: The penn treebank. Comput. Linguist. 1993, 19, 313–330. [Google Scholar]
- Brill, E. A Simple rule-based part of speech tagger. In Proceedings of the Third Conference on Applied Natural Language Processing, Trento, Italy, 31 March–3 April 1992; pp. 152–155. [Google Scholar]
- Brill, E. Some advances in transformation-based part of speech tagging. In Proceedings of the 12th National Conference on Artificial Intelligence, Seattle, WA, USA, 31 July–4 August 1994; pp. 722–727. [Google Scholar]
- Pandian, S.L.; Geetha, T.V. CRF models for tamil part of speech tagging and chunking. In Proceedings of the Computer Processing of Oriental Languages. Language Technology for the Knowledge-Based Economy, Hong Kong, 26–27 March 2009; pp. 11–22. [Google Scholar]
- Albared, M.; Omar, N.; Aziz, M.J.A.; Ahmad Nazri, M.Z. Automatic part of speech tagging for arabic: An experiment using bigram hidden Markov model. In Proceedings of the Rough Set and Knowledge Technology, Beijing, China, 15–17 October 2010; pp. 361–370. [Google Scholar]
- Horsmann, T.; Zesch, T. Do LSTMs really work so well for PoS tagging?—A replication study. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017. [Google Scholar]
- Ma, X.; Hovy, E.H. End-to-end sequence labeling via Bi-directional LSTM-CNNs-CRF. arXiv 2016, arXiv:1603.01354v5. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the 27th Annual Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–8 December 2013. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of tricks for efficient text classification. arXiv 2016, arXiv:1607.01759. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Wang, P.; Qian, Y.; Soong, F.K.; He, L.; Zhao, H. Part-of-Speech Tagging with Bidirectional Long Short-Term Memory Recurrent Neural Network. arXiv 2015, arXiv:1510.06168. [Google Scholar]
- Ling, W.; Luís, T.; Marujo, L.; Astudillo, R.F.; Amir, S.; Dyer, C.; Black, A.W.; Trancoso, I. Finding function in form: Compositional character models for open vocabulary Word Representation. arXiv 2015, arXiv:1508.02096. [Google Scholar]
- Plank, B.; Søgaard, A.; Goldberg, Y. Multilingual part-of-speech tagging with bidirectional long short-term memory models and auxiliary loss. arXiv 2016, arXiv:1604.05529. [Google Scholar]
- Srivastava, R.K.; Greff, K.; Schmidhuber, J. Highway networks. arXiv 2015, arXiv:1505.00387. [Google Scholar]
- Qi, P.; Dozat, T.; Zhang, Y.; Manning, C.D. Universal dependency parsing from scratch. arXiv 2019, arXiv:1901.10457. [Google Scholar]
- Dozat, T.; Qi, P.; Manning, C. Stanford’s graph-based neural dependency parser at the CoNLL 2017 shared task. In Proceedings of the CoNLL 2017 Shared Task: Multilingual Parsing from Raw Text to Universal Dependencies, Vancouver, BC, Canada, 3–4 August 2017; pp. 20–30. [Google Scholar]
- Warjri, S.; Pakray, P.; Lyngdoh, S.A.; Maji, A.K. Part-of-speech (POS) tagging using conditional random field (CRF) model for Khasi corpora. Int. J. Speech Technol. 2021, 24, 853–864. [Google Scholar] [CrossRef]
- AlKhwiter, W.; Al-Twairesh, N. Part-of-speech tagging for Arabic tweets using CRF and Bi-LSTM. Comput. Lang. 2021, 65, 101138. [Google Scholar] [CrossRef]
- Maimaiti, M.; Wumaier, A.; Abiderexiti, K.; Yibulayin, T. Bidirectional long short-term memory network with a conditional random field layer for uyghur part-of-speech tagging. Information 2017, 8, 157. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Sun, Y.; Tang, S.; Zhang, C.; Ma, H. Sentence-level semantic features guided adversarial network for zhuang language part-of-speech tagging. In Proceedings of the 2019 IEEE 31st International Conference on Tools with Artificial Intelligence (ICTAI), Portland, OR, USA, 4–6 November 2019; pp. 265–272. [Google Scholar]
- Gui, T.; Huang, H.; Peng, M.; Huang, X. Part-of-speech tagging for Twitter with adversarial neural networks. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 2411–2420. [Google Scholar]
- Yang, Z.; Salakhutdinov, R.; Cohen, W.W. Transfer Learning for Sequence Tagging with Hierarchical Recurrent Networks. arXiv 2017, arXiv:1703.06345. [Google Scholar]
- Wang, H.; Yang, J.; Zhang, Y. From genesis to creole language: Transfer learning for singlish universal dependencies parsing and POS tagging. ACM Trans. Asian Low-Resource Lang. Inf. Processing 2019, 19, 1–29. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.-K.; Kim, Y.-B.; Sarikaya, R.; Fosler-Lussier, E. Cross-lingual transfer learning for POS tagging without cross-lingual resources. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 2832–2838. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A robustly optimized BERT pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.G.; Salakhutdinov, R.; Le, Q.V. XLNet: Generalized autoregressive pretraining for language understanding. In Proceedings of the 32nd Annual Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Bos, J.; Basile, V.; Evang, K.; Venhuizen, N.J.; Bjerva, J. The groningen meaning bank. In Handbook of Linguistic Annotation; Ide, N., Pustejovsky, J., Eds.; Springer: Dordrecht, The Netherlands, 2017; pp. 463–496. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- PyTorch. Available online: https://pytorch.org/ (accessed on 12 October 2021).
- Huang, Z.; Liang, D.; Xu, P.; Xiang, B. Improve transformer models with better relative position embeddings. arXiv 2020, arXiv:2009.13658. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. arXiv 2018, arXiv:1802.05365. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| POS Tag | Description | POS Tag | Description |
|---|---|---|---|
| CC | Coordinating conjunction | TO | to |
| CD | Cardinal number | UH | Interjection |
| DT | Determiner | VB | Verb, base form |
| EX | Existential there | VBD | Verb, past tense |
| FW | Foreign word | VBG | Verb, gerund/present participle |
| IN | Preposition | VBN | Verb, past participle |
| JJ | Adjective | VBP | Verb, non-3rd |
| JJR | Adjective, comparative | VBZ | Verb, 3rd |
| JJS | Adjective, superlative | WDT | wh-determiner |
| LS | List item marker | WP | wh-pronoun |
| MD | Modal | WP$ | Possessive wh-pronoun |
| NN | Noun, singular or mass | WRB | wh-adverb |
| NNS | Noun, plural | # | Pound sign |
| NNP | Proper noun, singular | $ | Dollar sign |
| NNPS | Proper noun, plural | . | Sentence-final punctuation |
| PDT | Predeterminer | , | Comma |
| POS | Possessive ending | : | Colon, semi-colon |
| PRP | Personal pronoun | ( | Left bracket character |
| PRP$ | Possessive pronoun | ) | Right bracket character |
| RB | Adverb | “ | Straight double quote |
| RBR | Adverb, comparative | ‘ | Left open single quote |
| RBS | Adverb, superlative | “ | Left open double quote |
| RP | Particle | ’ | Right close single quote |
| SYM | Symbol | ” | Right close double quote |
| Lemmas | Basic POS Tags |
|---|---|
| watch | NN, VB |
| small | RB, JJ, NN |
| and | CC |
| the | DT |
| his | PRP$ |
| him | PRP |
| to | TO, IN |
| at | IN |
| … | … |
| Words | Possible POS Tags |
|---|---|
| stopped | VBD, VBN |
| better | JJR, RBR, VB, VBP |
| cast | VB, VBP, VBD, VBN, NN |
| children | NNS |
| … | … |
| Model | Token Accuracy (%) | Sentence Accuracy (%) |
|---|---|---|
| Bi-LSTM | 96.75 | 57.82 |
| BLSTM RNN with word embedding | 97.58 | 62.71 |
| C2W | 98.08 | 68.04 |
| Highway Bi-LSTM | 98.44 | 73.19 |
| Transformer’s Encoder | 97.18 | 57.67 |
| MLP with the data preprocessing | 96.04 | 45.65 |
| Ours | 98.60 | 76.04 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Mao, H.; Wang, J. Part-of-Speech Tagging with Rule-Based Data Preprocessing and Transformer. Electronics 2022, 11, 56. https://doi.org/10.3390/electronics11010056
Li H, Mao H, Wang J. Part-of-Speech Tagging with Rule-Based Data Preprocessing and Transformer. Electronics. 2022; 11(1):56. https://doi.org/10.3390/electronics11010056
Chicago/Turabian StyleLi, Hongwei, Hongyan Mao, and Jingzi Wang. 2022. "Part-of-Speech Tagging with Rule-Based Data Preprocessing and Transformer" Electronics 11, no. 1: 56. https://doi.org/10.3390/electronics11010056
APA StyleLi, H., Mao, H., & Wang, J. (2022). Part-of-Speech Tagging with Rule-Based Data Preprocessing and Transformer. Electronics, 11(1), 56. https://doi.org/10.3390/electronics11010056