
YOLO MDE: Object Detection with Monocular Depth Estimation

Abstract
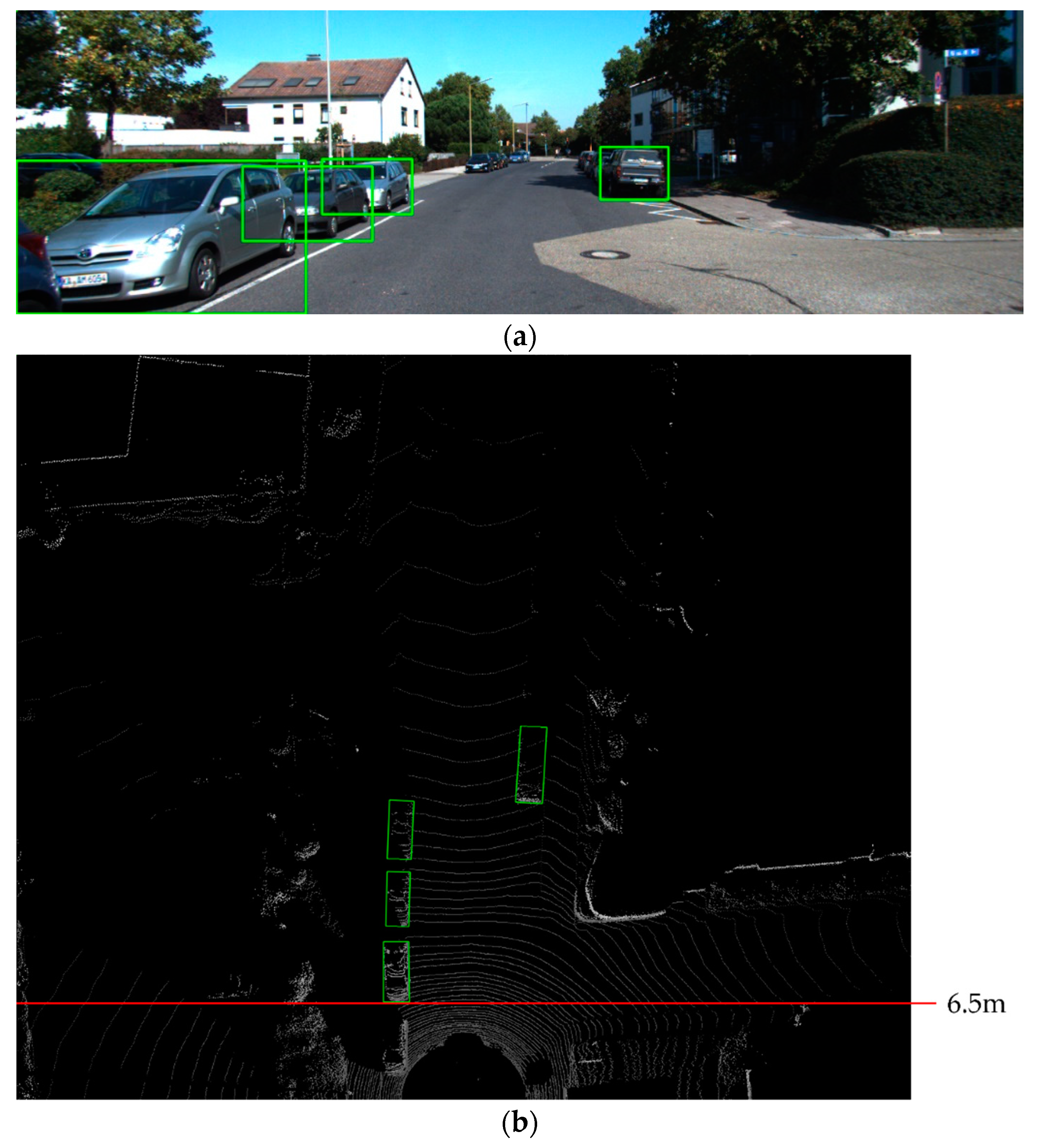
:1. Introduction
- Our model uses monocular camera images for 2D object detection and depth estimation with a straightforward model architecture. Recent 3D object detectors in the literature have dozens of additional channels for 3D box information, but ours adds only a single channel to the 2D object detection model. As a result, our detection has far better performance and faster detection speed than the latest 3D detection models.
- We designed a novel loss function to train depth estimation striking a balance between near and far distance accuracy.
2. Related Works
3. Methodology
3.1. Image-Based 2D Object Detection
3.1.1. Backbone Network and Detection Neck
3.1.2. Detection Head
- : The coordinates of the bounding box center points.
- : The height and width of the bounding box.
- : The confidence score representing the objectness.
- : The probabilities for each class.
- : The estimated depth of the object.
3.1.3. Loss Function for Object Detection
3.2. Depth Estimation
3.2.1. Activation
3.2.2. Depth Loss
4. Experiments
4.1. Dataset and Settings
4.1.1. KITTI Dataset
4.1.2. Data Preparation
4.1.3. Evaluation Metrics
4.1.4. Settings in Detail
4.2. Training Result and Performance
4.2.1. Performance Comparison
4.2.2. Ablation Study
4.2.3. A2D2 Dataset
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Liu, Z.; Zhao, X.; Huang, T.; Hu, R.; Zhou, Y.; Bai, X. Tanet: Robust 3D object detection from point clouds with triple attention. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 11677–11684. [Google Scholar]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3D object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4490–4499. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. Second: Sparsely embedded convolutional detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; Li, H. Pv-rcnn: Point-voxel feature set abstraction for 3D object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10529–10538. [Google Scholar]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-View 3D Object Detection Network for Autonomous Driving. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 1907–1915. [Google Scholar]
- Li, B.; Zhang, T.; Xia, T. Vehicle Detection from 3D Lidar Using Fully Convolutional Network. 2016. Available online: https://arxiv.org/abs/1608.07916 (accessed on 24 November 2021).
- Yang, B.; Luo, W.; Urtasun, R. PIXOR: Real-Time 3D Object Detection from Point Clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7652–7660. [Google Scholar]
- Liang, M.; Yang, B.; Wang, S.; Urtasun, R. Deep Continuous Fusion for Multi-Sensor 3D Object Detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 641–656. [Google Scholar]
- Ku, J.; Mozifian, M.; Lee, J.; Harakeh, A.; Waslander, S. Joint 3D Proposal Generation and Object Detection from View Aggregation. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–8. [Google Scholar]
- Ma, X.; Wang, Z.; Li, H.; Zhang, P.; Ouyang, W.; Fan, X. Accurate Monocular 3D Object Detection via Color-Embedded 3D Reconstruction for Autonomous Driving. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 15–20 June 2019; pp. 6851–6860. [Google Scholar]
- Chen, X.; Kundu, K.; Zhang, Z.; Ma, H.; Fidler, S.; Urtasun, R. Monocular 3D Object Detection for Autonomous Driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2147–2156. [Google Scholar]
- Brazil, G.; Liu, X. M3D-RPN: Monocular 3D Region Proposal Network for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 15–20 June 2019; pp. 9287–9296. [Google Scholar]
- Mousavian, A.; Anguelov, D.; Flynn, J.; Košecká, J. 3D Bounding Box Estimation Using Deep Learning and Geometry. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7074–7082. [Google Scholar]
- Ding, M.; Huo, Y.; Yi, H.; Wang, Z.; Shi, J.; Lu, Z.; Luo, P. Learning Depth-Guided Convolutions for Monocular 3D Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1000–1001. [Google Scholar]
- Li, P.; Chen, X.; Shen, S. Stereo R-CNN Based 3D Object Detection for Autonomous Driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7644–7652. [Google Scholar]
- Qin, Z.; Wang, J.; Lu, Y. Triangulation Learning Network: From Monocular to Stereo 3D Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7615–7623. [Google Scholar]
- Liu, Y.; Yixuan, Y.; Liu, M. Ground-Aware Monocular 3D Object Detection for Autonomous Driving. Robot. Autom. Lett. 2021, 6, 919–926. [Google Scholar] [CrossRef]
- Masoumian, A.; Marei, D.G.; Abdulwahab, S.; Cristiano, J.; Puig, D.; Rashwan, H.A. Absolute distance prediction based on deep learning object detection and monocular depth estimation models. In Proceedings of the 23rd International Conference of the Catalan Association for Artificial Intelligence, Artificial Intelligence Research and Development, Lleida, Spain, 20–22 October 2021; pp. 325–334. [Google Scholar]
- Bochokvskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. 2020. Available online: https://arxiv.org/abs/2004.10934 (accessed on 23 April 2020).
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision Meets Robotics: The KITTI Dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. 2018. Available online: https://arxiv.org/abs/1804.02767 (accessed on 8 April 2018).
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint Triplets for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 15–20 June 2019; pp. 6569–6578. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Purkait, P.; Zhao, C.; Zach, C. SPP-Net: Deep Absolute Pose Regression with Synthetic Views. 2017. Available online: https://arxiv.org/abs/1712.03452 (accessed on 9 December 2017).
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Boston, MA, USA, 7–12 June 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, C.-Y.; Liao, H.-Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A New Backbone That Can Enhance Learning Capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12993–13000. [Google Scholar]
- Huber, P. Robust Estimation of a Location Parameter. In Breakthroughs in Statistics; Springer: New York, NY, USA, 1992; pp. 492–518. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–16 July 2017; pp. 2117–2125. [Google Scholar]
- Geyer, J.; Kassahun, Y.; Mahmudi, M.; Ricou, X.; Durgesh, R.; Chung, A.S.; Hauswald, L.; Pham, V.H.; Mühlegg, M.; Dorn, S.; et al. A2D2: Audi Autonomous Driving Dataset. 2020. Available online: https://arxiv.org/abs/2004.06320 (accessed on 14 April 2020).



{kind=link}
{kind=link}
{kind=link}
| Models | AP (Car) | AP (Pedestrian) | Input Size | Depth Error Rate | FPS 1 |
|---|---|---|---|---|---|
| D4LCN [14] | 67.42% | 47.56% | 288 × 1280 | 4.07% | 5 |
| GM3D [17] | 59.61% | 512 × 1760 | 2.77% | 20 | |
| Yolo MDE | 56.73% | 55.20% | 256 × 832 | 4.23% | 34 |
| Yolo MDE Large | 71.68% | 62.12% | 384 × 1248 | 3.71% | 25 |
| Network | Activation | AP (Car) | AP (Pedestrian) | Depth Error Rate |
|---|---|---|---|---|
| Darknet53 + FPN | Exponential | 53.94% | 48.27% | 4.28% |
| Reciprocal-Sigmoid | 54.07% | 41.99% | 3.87% | |
| Log-Sigmoid | 68.32% | 55.61% | 3.35% | |
| CSP-Darknet53 + PAN Large | Exponential | 66.54% | 59.47% | 4.70% |
| Reciprocal-Sigmoid | 68.83% | 61.31% | 3.83% | |
| Log-Sigmoid | 71.68% | 62.12% | 3.71% | |
| CSP-Darknet53 + PAN | Exponential | 54.88% | 46.10% | 4.07% |
| Reciprocal-Sigmoid | 53.30% | 47.16% | 3.99% | |
| Log-Sigmoid | 56.72% | 55.80% | 3.67% |
| Network | Activation | AP (Car) | Depth Error Rate |
|---|---|---|---|
| CSP-Darknet53 + PAN | Exponential | 76.94% | 10.14% |
| Reciprocal-Sigmoid | 77.75% | 10.41% | |
| Log-Sigmoid | 77.94% | 11.12% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, J.; Choi, H. YOLO MDE: Object Detection with Monocular Depth Estimation. Electronics 2022, 11, 76. https://doi.org/10.3390/electronics11010076
Yu J, Choi H. YOLO MDE: Object Detection with Monocular Depth Estimation. Electronics. 2022; 11(1):76. https://doi.org/10.3390/electronics11010076
Chicago/Turabian StyleYu, Jongsub, and Hyukdoo Choi. 2022. "YOLO MDE: Object Detection with Monocular Depth Estimation" Electronics 11, no. 1: 76. https://doi.org/10.3390/electronics11010076
APA StyleYu, J., & Choi, H. (2022). YOLO MDE: Object Detection with Monocular Depth Estimation. Electronics, 11(1), 76. https://doi.org/10.3390/electronics11010076