1. Introduction
With the development of emerging network applications such as short video, virtual reality (VR) and the Internet of Things (IoT), the distribution of massive amounts of content makes it increasingly difficult for traditional TCP/IP networks to meet quality of service (QoS) requirements. A content delivery network (CDN) [
1] makes up for the shortcomings of TCP/IP networks in content distribution to a certain extent by deploying a large number of caching servers on the user side to cache content, but as application layer technology, its performance is still limited.
ICN has received increasing attention from researchers [
2]. Different from traditional TCP/IP, ICN names the content and places a cache in the network, only cares about the content and not the location and naturally supports the distribution of large-scale network content. In recent years, the research on information-centric networking (ICN) has been very active. For example, due to the advantages of ICN in content distribution efficiency, some researchers combine ICN with software-defined networking (SDN) to propose the SDN-based ICN approach [
3]. With the support of flexible programmability and efficient manageability of SDN, ICN has received more attention [
3,
4]. Furthermore, most IoT applications inherently follow a content-oriented communication paradigm [
5], which is similar to the way ICN operates. Some research on the IoT is even easy to apply to ICN [
6], and the application of ICN in the IoT has also attracted the attention of researchers [
5].
There are many ICN architectures [
7,
8,
9,
10,
11,
12,
13,
14]. Based on the routing and forwarding approach, there are two main types: the name-based routing approach and the stand-alone name resolution approach [
15]. Due to the existence of a large number of IP facilities in the current network, smooth evolution of the network architecture is a realistic requirement. The former’s name resolution process and message routing process are coupled, so they are less compatible with existing IP architectures, such as CCNs [
8] and NDNs [
7]. In contrast, the latter has better compatibility with IP architectures such as MobilityFirst [
9], NetInf [
13] and SEANet [
14].
In the ICN architecture adopting the standalone name resolution approach, the information of the named data chunk (NDC) is registered in the name resolution system (NRS). To complete the acquisition of the NDC, the receiver first needs to obtain the locator from the NRS and then uses the locator for routing to complete the data transmission. To prevent over-utilization of the NRS and the overhead of the cache system, the size of the NDC should not be too small [
16,
17]. Larger NDCs require congestion control of traffic during transmission; otherwise, this will easily cause severe network congestion or even collapse.
In traditional TCP/IP networks, congestion control algorithms have been well-studied [
18,
19,
20]. The separation of the name resolution process and the message routing process makes it easier to apply congestion control algorithms from TCP/IP networks to ICN networks. Considering that the ICN obtains the NDC based on the pull method, the congestion control algorithm in the traditional network must first adapt to the receiver-driven transmission mode [
21]. Secondly, each NDC has a fixed size, which is very different from the communication method based on the byte stream in traditional networks. In a high-speed network, if the size of the NDC is not large enough, the data transmission will end quickly, and it is difficult to achieve a relatively fair throughput between different NDC transmission processes. In this case, the convergence speed and fairness of the algorithm are very important.
In this paper, we study some excellent congestion control algorithms in traditional networks, such as BBR [
22], Cubic [
23], NewReno [
24] and Copa [
25]. Due to the excellent performance of the Copa algorithm in terms of convergence speed and fairness, we propose the Copa-ICN algorithm based on the original Copa algorithm. In order to observe the performance of different algorithms more accurately, we propose an ICN transport protocol prototype compatible with the IP architecture. It first obtains the locator from the NRS and then uses the set congestion control algorithm for data transmission. The transport protocol allows switching of the NDC replica nodes to take advantage of ICN’s multi-replica feature. We implement the proposed transport protocol prototype in Network Simulator 3 (NS-3) [
26] and implement Copa-ICN as well as several other receiver-driven algorithms. The experiment results show that the Copa-ICN algorithm has huge advantages in algorithm convergence speed and delay compared with the BBR, Cubic and NewReno algorithms. Compared with the original Copa algorithm, Copa-ICN not only further improves the convergence speed but also maintains a high throughput when there is an NDC transmission process in the opposite direction.
The remaining parts of the paper are structured as follows. We review the related work about congestion control mechanisms of ICN in
Section 2. In
Section 3, we introduce a complete ICN transport protocol. In
Section 4, we describe the motivation of the Copa algorithm in ICN and propose the Copa-ICN algorithm.
Section 5 evaluates the NS-3 experiment results of the Copa-ICN by comparison with the Cubic, BBR, NewReno and Copa algorithms. Conclusions and discussions are carried out in
Section 6.
2. Related Work
Whether it is the traditional TCP/IP network or the novel ICN network, congestion control mechanisms are essential to ensure network performance and efficient use of network bandwidth. Since ICN was proposed, many ICN architectures have appeared, and researchers have proposed various congestion control algorithms based on various ICN architectures.
A number of new congestion control mechanisms have emerged in ICN. MFTP is the transport protocol of the MobilityFirst architecture, which enables congestion control within the network through a hop-by-hop backpressure scheme, whereby when congestion occurs within the network, the congestion signal is passed back to the traffic source on a hop-by-hop basis, ultimately resulting in a reduction in the amount of traffic injected into the network [
27]. Some researchers have studied the congestion control of wireless links. For example, the authors of [
28] tried to reduce the delay of ICN wireless links, while those in [
6] proposed a mechanism to reduce wireless network congestion using clustering, which can be easily applied in ICN. Hop-by-hop interest shaping has been proposed as a viable congestion control mechanism in NDN [
29,
30]. Researchers have proposed many hop-by-hop interest shaping algorithms. In [
29], the authors pointed out that both interests and contents can lead to congestion. By shaping interest packets, the loss of data packets can be prevented, and the bandwidth utilization of links can be improved. The authors of [
31] proposed a bandwidth fair sharing algorithm between different flows. Interests and NACKs which exceed the fair share will be discarded together, and the additive increase multiplicative decrease (AIMD) mechanism is used to control the receiver’s interest rate. PCON [
32] uses the CoDel active queue management algorithm to detect network congestion and then sends signals downstream by explicitly marking certain packets. Downstream devices recognize the signal, the router can divert traffic to another path, and the receiver can slow down the interest rate.
Some works try to borrow mature congestion control solutions in TCP/IP networking. ICP [
33] is a well-known ICN congestion control solution. It uses a congestion window (CWND) similar to TCP in NDN and uses the AIMD mechanism to control the size of the congestion window. Each round-trip time (RTT) congestion window increases by one. When a congestion event occurs, the CWND is reduced to half of its original value. DCP [
34] is a delay-based ICN congestion control protocol that measures the queuing delay on the forwarding path from the producer or caching site to the consumer using a protocol similar to the LEDBAT [
35] algorithm, and it addresses issues such as slow start fairness and “latecomer advantage”. CCTCP [
36] is a transport protocol suitable for the CCN architecture. It redesigns the TCP as a receiver-driven transport protocol, maintains multiple congestion windows, and proposes a new RTT estimation method. The authors of [
37] proposed EC-CUBIC, which uses the core idea of the CUBIC [
23] algorithm to control the rate at which consumers send interest packets, sensing congestion in the network through the implementation of explicit congestion notifications in routers. NetInf TP [
38] is the transport protocol of the NetInf [
13] architecture which is compatible with the IP infrastructure. It can share bandwidth fairly with TCP traffic using the NewReno [
24] algorithm by implementing the AIMD mechanism for the congestion window. In [
21], the authors propose a two-level congestion control mechanism (2LCCM), which first avoids the congestion path through the selection of replica nodes and then uses the receiver-driven BBR [
22] congestion control algorithm for data transmission.
Whether it is a hop-by-hop congestion control scheme, a purely receiver-driven scheme, or other work, most of them do not focus on the convergence speed of the congestion control algorithm. In some particular architectures, such as NetInf [
13] and SEANet [
14], the transmission processes of different NDCs are independent. The size of the NDC is often larger than one maximum transmission unit (MTU), but the size is limited [
16]. In this case, the convergence speed of the algorithm is particularly important. If the convergence speed of the algorithm is slow, then NDC transmission will be at an unfair rate most of the time, and the data transmission rate will be unstable, which will adversely affect the user experience. Copa [
25] is a new congestion control algorithm which was proposed in 2018. It has better fairness and a faster convergence speed than algorithms such as the Cubic [
23] and BBR algorithms [
22]. In this paper, we redesign it as a receiver-driven model, improve its performance including queuing delay calculation and propagation delay measurement, and then propose a solution to further accelerate the convergence speed of the Copa algorithm.
3. Proposed Transport Protocol
In this section, we introduce a receiver-driven transport protocol that can be used in the ICN architecture by adopting the standalone name resolution approach and can be deployed over an IP infrastructure.
3.1. Overview of the Transmission Process
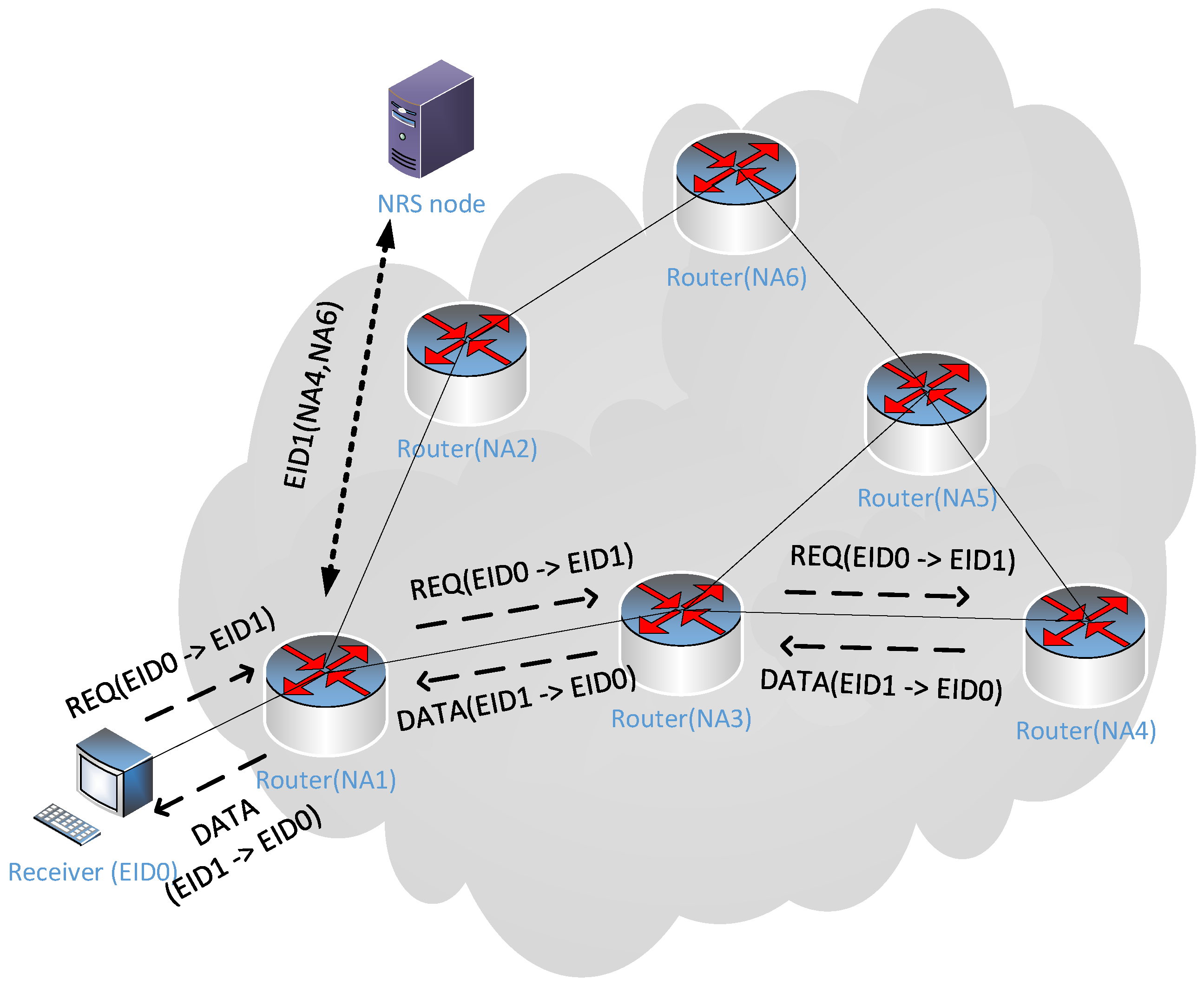
In the ICN architecture of the standalone name resolution approach, the process of name resolution and message routing are separated, and the NRS maintains the mapping between the identifier and the locator [
39]. In this paper, Entity-ID (EID) is the identifier, and the network address (NA) is the locator. Specifically, EID represents a receiver device or an NDC, and the NA represents an IP address. When a new NDC is generated in a device, the NDC is assigned a unique EID. The EID of the NDC and the IP of the device will be registered in the NRS. If the receiver wants to obtain the NDC identified by the EID in the network, it first needs to query the NRS for the NA list of nodes that have replicas of the NDC and then select a replica node to obtain the NDC. For security reasons, receiver devices often cannot directly obtain the NAs of nodes in the network, so replica selection often requires the assistance of edge nodes. Since the size of the NDC is often larger than the maximum segment size (MSS), the NDC should be split into segments for transmission. The congestion control algorithm controls the transmission rate, and the retransmission algorithm performs error recovery. In this process, the sender only needs to reply with data according to the request of the receiver, which is stateless. ICN routers may cache forwarded segments. When the ICN router successfully assembles a complete NDC, it will register with the NRS to become a new replica node. In addition, the dynamic binding of identifiers and locators makes it easier to modify the NA during packet forwarding. This means that when severe network congestion occurs between the receiver and the selected replica node, the NDC transmission can be successfully completed by switching the replica node.
Figure 1 is a schematic diagram of NDC transmission in ICN.
3.2. Message Type
Transport protocols use IP addresses for routing, so all messages are encapsulated as IP packets. An unassigned value for the “Protocol” [
40] field of IPv4 or the “Next Header” [
41] field of IPv6 can be set to indicate that the IP header is followed by an EID header. The EID header is followed by the transport layer header. There are mainly two types of packets used in the transmission process: one is the request (REQ) packet, and the other is the data (DATA) packet. The receiver sends the REQ packet to the network, and the replica node replies with the DATA packet after receiving the REQ packet.
Figure 2 is the packet format in the ICN transport protocol.
In the REQ packet, “Source EID” indicates the EID of the receiver device, “Destination EID” is the EID of the NDC, “Message Type” indicates that the packet is an REQ packet, “Packet Number” is a monotonically increasing request packet sequence number, “Offset and Length” indicates the offset and length of the requested data in the NDC, and “Other parameters” are other optional parameters, such as specifying the MSS and checksum.
In the DATA packet, “Source EID” is the EID of the NDC, “Destination EID” is the EID of the receiver device, “Message Type” indicates that the packet is a DATA packet, “Packet Number” is the “Packet Number” of the REQ packet, (An REQ packet usually requests multiple DATA packets, so the “Packet Number” of the DATA packet will be repeated.) “Offset and Length” indicates the offset and length of the data in the packet in the NDC, and “Other parameters” are other optional parameters, such as the NDC size and checksum.
3.3. Rate and Congestion Control
We use a sliding window (WND) to control the rate during transmission. The size of the WND is the smaller of the congestion windows (CWNDs) and the available buffer to the receiver. This paper focuses on the congestion window. In fact, for NDCs with a limited size, except for resource-limited embedded devices, normal computers rarely have an available buffer smaller than the congestion window. In the transmission process controlled by the sliding window, the amount of data that the receiver can request is the difference between the WND and inflight data. When the size of the WND and inflight data are equal, the receiver will not be able to send REQ packets, and then when DATA packets are received, inflight data changes to be small, the WND will be larger than inflight data, and the receiver will be able to request the data.
When DATA packet loss occurs, we need to detect it as soon as possible and subtract the amount of lost data from the inflight data so that the receiver can send a new request. For the loss of DATA packets, we have two ways to find this out. One is the number of DATA packets received that should arrive after the packet exceeds a certain threshold, which is similar to the TCP’s fast retransmission, with the difference being that the threshold in the TCP is a value that can be dynamically changed. Our design refers to the practice of ICTP [
16] and NetInf TP [
38] and sets the threshold to a fixed value of three. Another way to detect packet loss is timer timeout, which is consistent with the calculation method of RTO in the TCP [
42]. Data found to be lost will be re-recorded in the queue waiting to be transmitted.
Based on the above protocol details, we have implemented a set of congestion control algorithm interfaces, which can transplant some congestion control algorithms of the TCP. It should be noted that in the implementation of the interface, the switching of the replica node is also transmitted to the congestion control algorithm as a congestion control signal. In addition, according to the needs of some congestion control algorithms, the pacing [
43] mechanism is also supported. We have implemented four congestion algorithms—NewReno [
24], Cubic [
23], BBR [
22], and Copa [
25]—in the transport protocol.
5. Experimental Evaluation and Analysis
NS-3 is an easy-to-use discrete event network simulator. The protocol stack proposed in
Section 3 has been implemented in NS-3, which has a set of easy-to-use congestion control interfaces to facilitate the implementation of new congestion control algorithms. Mvfst [
46] is Facebook’s implementation of the QUIC protocol, which includes a Copa code. We referred to the Copa code of mvfst and implemented the Copa algorithm in our protocol stack. Meanwhile, Copa-ICN was implemented by modifying the Copa code. In this section, we experimentally evaluate Copa-ICN using the NS-3 platform.
5.1. Experiment Set-Up
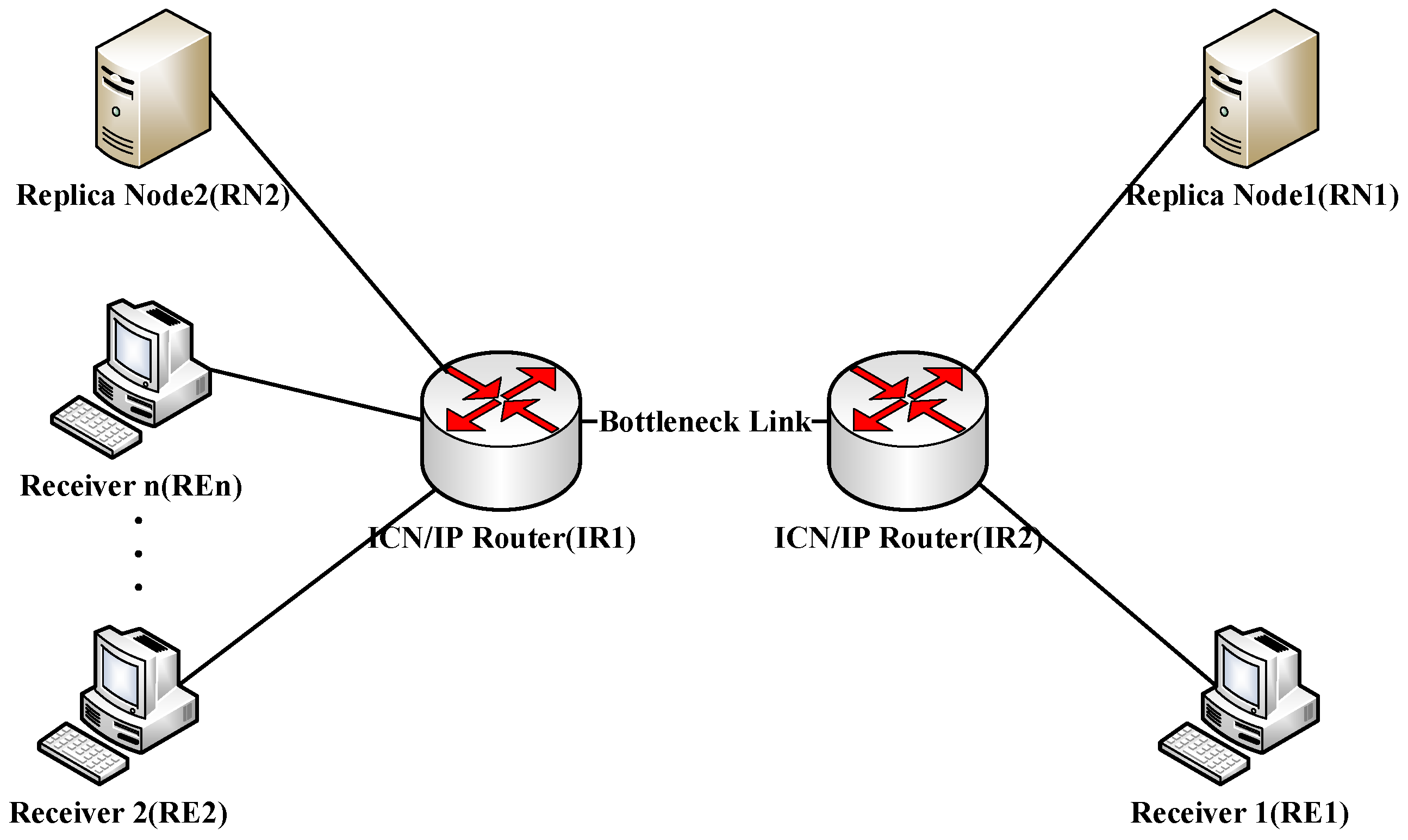
The simulation experiment mainly included three kinds of nodes: the receiver that initiated the NDC request, the replica node that cached the NDC, and the ICN/IP router for forwarding REQ packets and DATA packets. The nomenclature of the device was determined by its role in the simulation experiment. For example, the replica node may have actually been a server, a router with an ICN cache, or even a user device. We placed NDCs 1 MB, 5 MB, 10 MB, 20 MB, 30 MB, 40 MB, and 50 MB in size on the replica nodes. Since not all algorithms have a high convergence speed, in order to fully observe the performance of different congestion control algorithms in transmitting NDCs, some scenarios chose to transmit the NDC with a size of 50 MB. In practical scenarios, the NDC is often much smaller, and the algorithm with a faster convergence speed will have a greater advantage at this time. Additionally, the header of the DATA packet is 108 bytes, and the valid data contained are a maximum of 1250 bytes. The REQ packet size is generally 106 bytes. Our experiments used two topologies, shown in
Figure 4 and
Figure 5.
Figure 4 shows simulation experiment network topology 1 (topo-1). It is a linear topology with
n receivers (RE1-REn), one replica node (RN), and two routers (IR1 and IR2).
Figure 5 shows simulation experiment network topology 2 (topo-2). It contains
n receivers (RE1-REn), two replica nodes (RN1 and RN2), and two routers (IR1 and IR2).
5.2. Comparison of Copa-ICN with BBR, Cubic, and NewReno
In topo-1, we compared the convergence speed of the Copa-ICN algorithm with the BBR, Cubic and NewReno algorithms. We set up two experimental scenarios. In the first scenario, the bottleneck bandwidth of the link was 20 Mbps, RTprop was 30 ms, the size of NDC-1 was 10 MB, and the size of NDC-2 was 1 MB. In the second scenario, the bottleneck bandwidth of the link was 60 Mbps, RTprop was 50 ms, the size of NDC-1 was 50 MB, and the size of NDC-2 was 10 MB. At 0.1 s, RE1 began to request the transmission of NDC-1, and at 2.1 s, RE2 began to request the transmission of NDC-2.
Figure 6 shows the variation of inflight data over time in two transmission processes in different congestion control algorithms. Before NDC-2 was added, Copa-ICN and BBR had the smallest inflight data, of which Copa-ICN had the smallest extreme value, while NewReno and Cubic had larger inflight data because NewReno and Cubic were buffer-filling algorithms, while Copa-ICN is based on the queuing delay and the BBR algorithm is based on the BDP. Therefore, the inflight of the latter two was small. After the addition of NDC-2, the two transmission processes of the Copa-ICN algorithm converged to fairness quickly, while the Cubic and BBR algorithms failed to converge to fairness. In
Figure 6(7), NewReno converges to fairness because the congestion window of NDC-2 accidentally increased to a value similar to that of NDC-1 at the end of the slow start. For the Cubic and NewReno algorithms, only when the packet loss reduced the size of the congestion window multiplicatively did the transmission processes with different rates have a chance to converge; otherwise, the congestion windows of the two transmission processes increased together. A transmission with a smaller congestion window will never catch up with a transmission with a larger congestion window. BBR relies on periodically changing the transmission rate gain and periodically entering the detection minimum RTT phase to empty the bottleneck buffer and make the transmission process converge. The former has less impact on the transmission rate, and the latter has a very low trigger frequency. The default was about 10 s, so the overall convergence speed of BBR was slower.
When using different congestion control algorithms, the throughputs of the two transmission processes joined at different times are shown in
Figure 7. The maximum throughputs in the figure are not 20 Mbps and 60 Mbps due to the existence of the packet header. The relationship between the maximum throughput (
) and the bottleneck bandwidth (
) is
is the header size of the DATA packet, and its value is 108 bytes.
is the maximum value of the DATA packet payload, and its value is 1250 bytes. Therefore, for the bottleneck links of 20 Mbps and 60 Mbps, the maximum throughputs that could be achieved by the NDC transmission process were 18.41 Mbps and 55.23 Mbps, respectively. It can be seen from
Figure 7 that the addition of NDC-2 reduced the throughput of NDC-1, and the throughputs of the two NDCs in Copa-ICN would soon tend to be the same. Although the throughput of NDC-1 in the Cubic and BBR algorithms was reduced, it was greater than that of NDC-2. The performance of the NewReno algorithm was unstable, although there was better performance in the experiment in
Figure 7(7), while the performance of the experiment in
Figure 7(8) was poor.
Since the fluctuation of the RTT value was relatively large, in order to clearly observe the change in the RTT, we used the smooth RTT (SRTT), where
.
Figure 8 shows the variation of the SRTT over time in the transmission process using different congestion control algorithms. It can be seen that the Copa-ICN algorithm always had the smallest delay, while the BBR and NewReno algorithms had relatively large latency, and Cubic was almost always algorithm with the longest delay.
Compared with the receiver-driven implementation of the other three common algorithms, which failed to converge to a fair rate, Copa-ICN not only successfully converged but also had a fast convergence speed. In addition, Copa-ICN also had the lowest latency. After the start of the second transmission process, the average latency of Copa-ICN was more than 37% lower than those of the other three algorithms. This shows the correctness of using Copa-ICN instead of several other algorithms in the ICN scenario.
5.3. Comparison of Copa-ICN with Original Copa
We changed the Copa algorithm to a receiver-driven model and improved it. To verify the effectiveness of the improvement, we set up four experiments to compare the Copa-ICN and Copa algorithms.
5.3.1. Convergence Experiment of NDC Transmission Process
In topo-1, we set up two experimental scenarios to compare the performance of the Copa-ICN and Copa algorithms in terms of convergence speed. The experimental parameters of the two experimental settings are shown in
Table 2. In Experiment-1, RE1 started requesting the NDC at 0.1 s and RE2 at 2.1 s. In Experiment-2, RE1–RE4 started requesting the NDC at 0.1, 2.1, 4.1, and 6.1 s, respectively.
It should be noted that, according to the expression in Equation (
8), when the bottleneck bandwidth was 20 Mbps and 50 Mbps, the maximum throughputs were 18.41 Mbps and 46.02 Mbps, respectively. In addition, for the convenience of observing the experimental phenomenon, the size of the NDC was set to 50 MB.
Figure 9 shows the change in throughput over time during the first 10 s of Experiment-1. When the second transmission process was added, the throughput of the first transmission process would decrease, and the throughput of the second transmission process would continue to increase so that the throughputs of the two transmission processes would continue to tend to be the same. Observing the time required for the throughput of the transmission process under different bandwidths and RTprops to become the same, it can also be seen that with the increase in the bandwidth and RTprop, the convergence speed of the Copa-ICN and Copa algorithms would become slower and slower. However, the variation in Copa-ICN’s convergence speed was much smaller than that of Copa. The time it took for Copa-ICN to converge to a fair rate was only about 20% of that of Copa.
The variations of multiple transmission processes over time in the first 10 s of Experiment-2 are shown in
Figure 10. It can be seen that with the Copa-ICN algorithm, the throughputs of different transmission processes converged to the same value quickly when a transmission process was added. With the Copa algorithm, however, it took much longer for the throughputs of the different processes to become the same, and a better convergence rate was achieved only when there were many transmission processes in the link. The reason for this is that when there are many transmission processes, the fair share of the throughput of each process becomes smaller, and so the convergence time required is reduced.
A dynamic
value was used in Copa-ICN with a maximum value of 0.5. The Copa algorithm used a fixed default value of 0.5. According to the calculation in [
25], the number of packets in the bottleneck buffer of a transmission process is
. Therefore, using the Copa-ICN algorithm will have more data packets queued in the bottleneck buffer. It can be seen from
Figure 11 that the queue length of the bottleneck buffer area of the Copa-ICN algorithm was significantly larger than that of the Copa algorithm. When the fourth transmission process started, the average queue length of Copa-ICN was eight times that of Copa. Moreover, after the third NDC transmission process was added, the packets in the buffer area had not even been emptied, meaning that it was difficult to measure the RTprop of the link during the transmission process, and thus the measured queuing delay would be too small. If the queuing delay measured by the transmission process added later is too small, it will occupy more bandwidth in the competition with other transmission processes, resulting in unfairness between transmission processes. However, as can be seen from
Figure 10, Copa-ICN still maintained good fairness at this time, which shows that our improvement to the queuing delay accuracy was effective.
5.3.2. Coexistence with the NDC Transmission Process in the Opposite Direction
In topo-2, we conducted throughput experiments with the Copa-ICN and Copa algorithms in the presence of NDC transmission processes in opposite directions. NDCs were placed at RN1 and RN2. The bottleneck bandwidth and RTprop settings of the link were 20 Mbps and 40 ms and 50 Mbps and 80 ms, respectively. At 0.1 s, receivers (RE2-REn) would start requesting the NDC from RN1 as a reverse NDC transmission process, where n had a value of 1, 2, and 3. At 2.1 s, RE1 started requesting the NDC from RN2.
Figure 12 shows the throughput changes in RE1 upon obtaining the NDC from RN2 under different parameters. It can be seen that in any case, when there was no NDC transmission process in the opposite direction, RE1 obtained the maximum throughput, and when there was an NDC transmission process in the opposite direction, the throughput of RE1 would decrease. In the case of using the Copa algorithm, the throughput would continue to decrease as the number of transmissions in opposite directions increased. However, in the case of using the Copa-ICN algorithm, the throughput would not change much as the number of transmissions in the opposite direction increased. In the network with a bandwidth of 50 Mbps and RTprop of 80 ms, when there were two transmission processes in opposite directions, the throughput of Copa was reduced to 39%, while that of Copa-ICN was 87%. Copa-ICN could still maintain good performance.
5.3.3. Experiment with Different-Sized NDCs in Transmission
We measured the flow completion time (FCT) for NDCs of different sizes in topology 1. The NDC was placed in the RN. The bottleneck bandwidth of the link was 100 Mbps, and the RTprop was 60 ms. We used RE1–RE5 to request the NDC from the RN as 5 background traffic at 0 s, and RE6 started to request the RN to transmit the NDCs of 1 MB, 5 MB, 10 MB, 20 MB, 30 MB, 40 MB and 50 MB respectively at the 8th second.
According to the expression in Equation (
8), the maximum throughput was 92.05 Mbps when there were 6 NDC transmission processes. The average throughput of each transmission process was 15.34 Mbps, so we could calculate the optimal FCTs of NDC transmission of different sizes.
Figure 13 shows the relationship between the ratio of the FCT measurement value and the optimal value of the NDC and the size of the NDC. As can be seen from the figure, as the size of the NDC increased, the gap between the FCT measurement and the optimal value became smaller and smaller. When the NDC size was 1 MB, the FCT of Copa-ICN was 85% of that of Copa, and when the NDC size was 50 MB, the FCT of Copa-ICN was 97% of that of Copa. The reason for this is that with the increase in the NDC size, the transmission time will be longer, and when the network conditions remain unchanged, the convergence time of different transmission processes is certain, which will make the transmission process in the optimal throughput time longer. Therefore, it is closer to the optimal FCT value. In the figure, the FCT of Copa-ICN consistently outperformed Copa. The reason for this is that when the Copa-ICN algorithm is used, the transmission process converges faster, which also increases the time during which the transmission process is at the best throughput, resulting in a better FCT.
6. Discussion
The convergence speed is an important indicator to measure the congestion control algorithm. In ICN, especially in some architectures of the stand-alone name resolution approach, the convergence speed of the algorithm is even more important. In this paper, we proposed a congestion control mechanism based on the Copa algorithm, called Copa-ICN, which is suitable for the IP network-compatible ICN architecture. Copa-ICN not only has huge advantages over the BBR, Cubic, and NewReno algorithms in terms of convergence speed, fairness, and delay, but it also has two important improvements over the original Copa algorithm. One is that the Copa-ICN algorithm converges faster without reducing fairness, and the other is that the throughput of the algorithm is significantly improved when there is an NDC transmission process in the opposite direction.
The Copa-ICN algorithm is easy to deploy. Although we only implemented it in NS-3, there are no technical difficulties when Copa-ICN is implemented in practical systems. First, the protocol stack supports the mechanism where the receiver sets the flag bit in the REQ packet to notify the replica node to stamp the device time in the DATA packet. Second, the protocol stack needs to modify the congestion control algorithm. Because the protocol stack often has a set of easy-to-use congestion control algorithm interfaces, just like the congestion control interface of the Linux kernel protocol stack, by using the congestion control algorithm interface, we can easily implement various congestion control algorithms, including Copa-ICN.
In the ICN architecture compatible with IP networks, how to coexist with TCP traffic is an important issue. TCP traffic may use a variety of different congestion control algorithms, which will challenge the convergence speed of the Copa-ICN algorithm. This will be the content of our further research in the future.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}