
SCA-MMA: Spatial and Channel-Aware Multi-Modal Adaptation for Robust RGB-T Object Tracking

Abstract
:1. Introduction
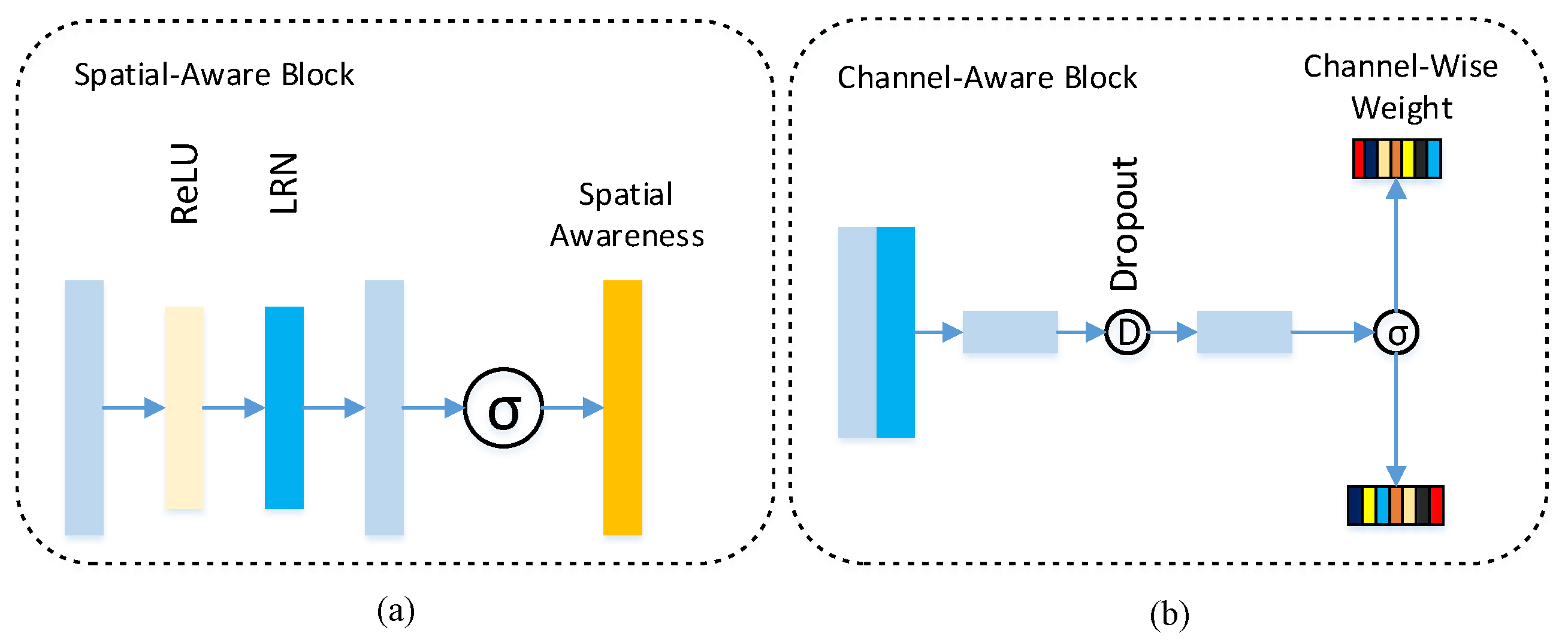
- We propose a novel spatial- and channel-aware multi-modal adaptation (SCA-MMA) framework for robust RGB-T object tracking in an end-to-end fashion. The proposed SCA-MMA can dynamically learn the location-based characteristics of specific tracking objects and simultaneously adopt channel-aware multi-modal adaptation for better consideration of the complementarity of RGB and thermal information.
- We introduce a feature aggregation mechanism to adaptively reconstruct the target descriptor for performing RGB-T object tracking. In particular, our proposed spatial-aware mechanism can adaptively learn spatial awareness to enhance the target appearance. Furthermore, we present a channel-aware multi-modal adaptation mechanism to aggregate visual RGB and thermal infrared data, which can adaptively learn the reliable degree of each channel and then better integrate the global information.
2. Related Work
2.1. Feature Aggregation Methods for RGB-T Object Tracking
2.2. Multi-Domain Object Tracking
3. Proposed Framework
3.1. Network Architecture
3.2. Spatial-Aware Mechanism
3.3. Channel-Aware Multi-Modal Adaptation Method
4. Experiment
4.1. Experiment Setting
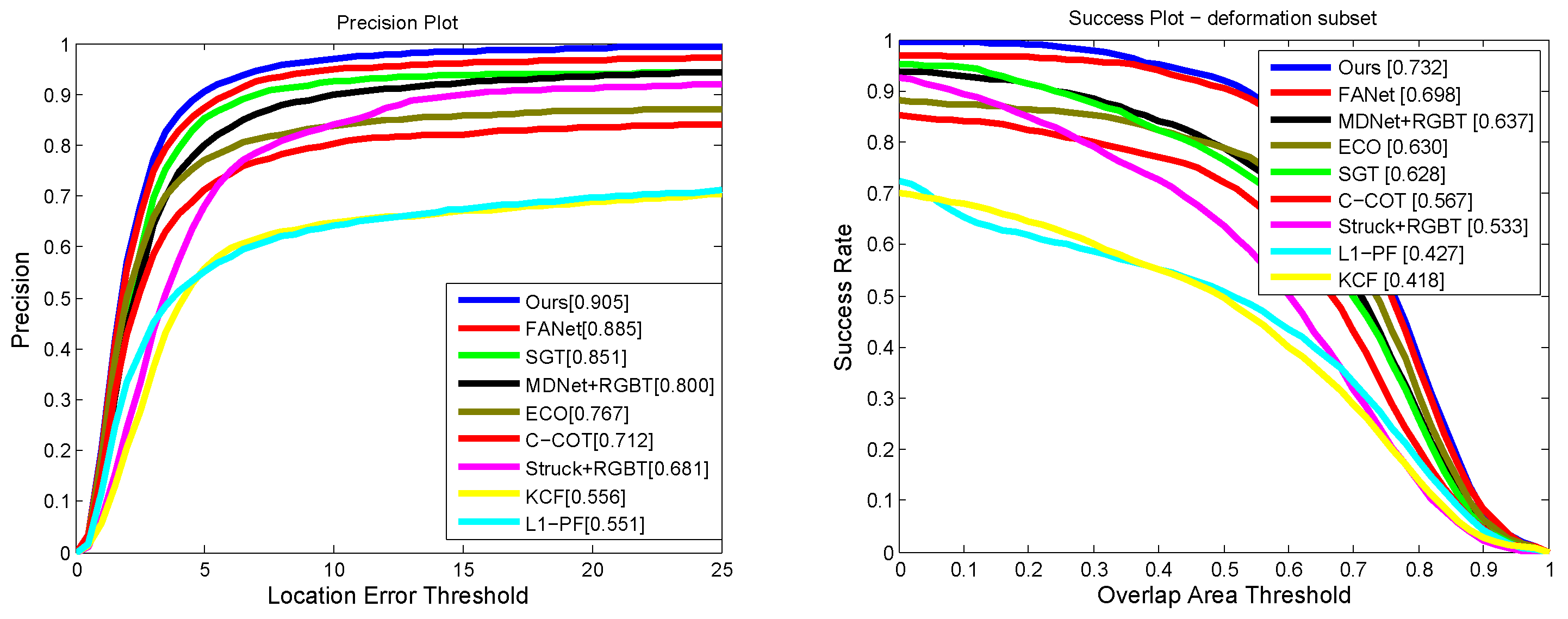
4.2. Result Comparisons
4.3. Algorithm Analysis
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual object tracking using adaptive correlation filters. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2544–2550. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-speed tracking with kernelized correlation filters. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 583–596. [Google Scholar] [CrossRef] [Green Version]
- Jung, I.; Son, J.; Baek, M.; Han, B. Real-time mdnet. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 83–98. [Google Scholar]
- Nam, H.; Han, B. Learning multi-domain convolutional neural networks for visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4293–4302. [Google Scholar]
- Mehmood, K.; Jalil, A.; Ali, A.; Khan, B.; Murad, M.; Khan, W.U.; He, Y. Context-aware and occlusion handling mechanism for online visual object tracking. Electronics 2020, 10, 43. [Google Scholar] [CrossRef]
- Gade, R.; Moeslund, T.B. Thermal cameras and applications: A survey. Mach. Vis. Appl. 2014, 25, 245–262. [Google Scholar] [CrossRef] [Green Version]
- Lan, X.; Ye, M.; Zhang, S.; Yuen, P.C. Robust collaborative discriminative learning for RGB-infrared tracking. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Li, C.; Cheng, H.; Hu, S.; Liu, X.; Tang, J.; Lin, L. Learning collaborative sparse representation for grayscale-thermal tracking. IEEE Trans. Image Process. 2016, 25, 5743–5756. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Wang, X.; Zhang, L.; Tang, J.; Wu, H.; Lin, L. Weighted low-rank decomposition for robust grayscale-thermal foreground detection. IEEE Trans. Circuits Syst. Video Technol. 2016, 27, 725–738. [Google Scholar] [CrossRef]
- Li, C.; Zhao, N.; Lu, Y.; Zhu, C.; Tang, J. Weighted sparse representation regularized graph learning for RGB-T object tracking. In Proceedings of the 25th ACM international conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 1856–1864. [Google Scholar]
- Li, C.; Wu, X.; Zhao, N.; Cao, X.; Tang, J. Fusing two-stream convolutional neural networks for RGB-T object tracking. Neurocomputing 2018, 281, 78–85. [Google Scholar] [CrossRef]
- Li, C.; Zhu, C.; Huang, Y.; Tang, J.; Wang, L. Cross-Modal Ranking with Soft Consistency and Noisy Labels for Robust RGB-T Tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 808–823. [Google Scholar]
- Zhu, Y.; Li, C.; Lu, Y.; Lin, L.; Luo, B.; Tang, J. FANet: Quality-Aware Feature Aggregation Network for RGB-T Tracking. arXiv 2018, arXiv:1811.09855. [Google Scholar]
- Leykin, A.; Hammoud, R. Pedestrian tracking by fusion of thermal-visible surveillance videos. Mach. Vis. Appl. 2010, 21, 587–595. [Google Scholar] [CrossRef]
- Wu, Y.; Blasch, E.; Chen, G.; Bai, L.; Ling, H. Multiple source data fusion via sparse representation for robust visual tracking. In Proceedings of the 14th International Conference on Information Fusion, Chicago, IL, USA, 5–8 July 2011; pp. 1–8. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective Kernel Networks. arXiv 2019, arXiv:1903.06586. [Google Scholar]
- Huang, P.; Yu, G.; Lu, H.; Liu, D.; Xing, L.; Yin, Y.; Kovalchuk, N.; Xing, L.; Li, D. Attention-aware Fully Convolutional Neural Network with Convolutional Long Short-Term Memory Network for Ultrasound-Based Motion Tracking. Med. Phys. 2019, 46, 2275–2285. [Google Scholar] [CrossRef] [PubMed]
- Su, K.; Yu, D.; Xu, Z.; Geng, X.; Wang, C. Multi-Person Pose Estimation with Enhanced Channel-wise and Spatial Information. arXiv 2019, arXiv:1905.03466. [Google Scholar]
- Li, C.; Liang, X.; Lu, Y.; Zhao, N.; Tang, J. RGB-T object tracking: Benchmark and baseline. arXiv 2018, arXiv:1805.08982. [Google Scholar] [CrossRef] [Green Version]
- Luo, C.; Sun, B.; Yang, K.; Lu, T.; Yeh, W.C. Thermal infrared and visible sequences fusion tracking based on a hybrid tracking framework with adaptive weighting scheme. Infrared Phys. Technol. 2019, 99, 265–276. [Google Scholar] [CrossRef]
- Li, C.; Zhu, C.; Zheng, S.; Luo, B.; Tang, J. Two-stage modality-graphs regularized manifold ranking for RGB-T tracking. Signal Process. Image Commun. 2018, 68, 207–217. [Google Scholar] [CrossRef]
- Wang, Y.; Wei, X.; Tang, X.; Shen, H.; Zhang, H. Adaptive Fusion CNN Features for RGBT Object Tracking. IEEE Trans. Intell. Transp. Syst. 2021. [Google Scholar] [CrossRef]
- Tang, Z.; Xu, T.; Li, H.; Wu, X.J.; Zhu, X.; Kittler, J. Exploring Fusion Strategies for Accurate RGBT Visual Object Tracking. arXiv 2022, arXiv:2201.08673. [Google Scholar]
- Park, E.; Berg, A.C. Meta-tracker: Fast and robust online adaptation for visual object trackers. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 569–585. [Google Scholar]
- Zhang, J.; Zhao, K.; Dong, B.; Fu, Y.; Wang, Y.; Yang, X.; Yin, B. Multi-domain collaborative feature representation for robust visual object tracking. Vis. Comput. 2021, 37, 2671–2683. [Google Scholar] [CrossRef]
- Zhang, J.; Yang, X.; Fu, Y.; Wei, X.; Yin, B.; Dong, B. Object Tracking by Jointly Exploiting Frame and Event Domain. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 13043–13052. [Google Scholar]
- Meshgi, K.; Mirzaei, M.S. Adversarial Semi-Supervised Multi-Domain Tracking. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Liu, W.; Liu, Y.; Bucknall, R. Filtering based multi-sensor data fusion algorithm for a reliable unmanned surface vehicle navigation. J. Mar. Eng. Technol. 2022, 1–17. [Google Scholar] [CrossRef]
- Stateczny, A.; Kazimierski, W. Multisensor Tracking of Marine Targets: Decentralized Fusion of Kalman and Neural Filters. Int. J. Electron. Telecommun. 2011, 57, 65–70. [Google Scholar] [CrossRef]
- Zhang, T.; Liu, S.; He, X.; Huang, H.; Hao, K. Underwater target tracking using forward-looking sonar for autonomous underwater vehicles. Sensors 2019, 20, 102. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Danelljan, M.; Bhat, G.; Shahbaz Khan, F.; Felsberg, M. ECO: Efficient convolution operators for tracking. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6638–6646. [Google Scholar]
- Danelljan, M.; Robinson, A.; Khan, F.S.; Felsberg, M. Beyond correlation filters: Learning continuous convolution operators for visual tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 472–488. [Google Scholar]
- Kim, H.U.; Lee, D.Y.; Sim, J.Y.; Kim, C.S. Sowp: Spatially ordered and weighted patch descriptor for visual tracking. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3011–3019. [Google Scholar]
- Danelljan, M.; Hager, G.; Shahbaz Khan, F.; Felsberg, M. Learning spatially regularized correlation filters for visual tracking. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4310–4318. [Google Scholar]
- Lukezic, A.; Vojir, T.; Cehovin Zajc, L.; Matas, J.; Kristan, M. Discriminative correlation filter with channel and spatial reliability. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21– 26 July 2017; pp. 6309–6318. [Google Scholar]
- Valmadre, J.; Bertinetto, L.; Henriques, J.; Vedaldi, A.; Torr, P.H. End-to-end representation learning for correlation filter based tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21– 26 July 2017; pp. 2805–2813. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| L1-PF [15] | CFNet + RGBT | CSR-DCF + RGBT | SOWP + RGBT | SGT [9] | MDNet + RGBT | FANet [13] | Ours | |
|---|---|---|---|---|---|---|---|---|
| NO | 56.5/37.9 | 76.4/56.3 | 82.6/60.0 | 86.8/53.7 | 87.7/55.5 | 86.2/61.1 | 84.7/61.1 | 90.5/66.8 |
| PO | 47.5/31.4 | 59.7/41.7 | 73.7/52.2 | 74.7/48.4 | 77.9/51.3 | 76.1/51.8 | 78.3/54.7 | 83.0/58.8 |
| HO | 33.2/22.2 | 41.7/29.0 | 59.3/40.9 | 57.0/37.9 | 59.2/39.4 | 61.9/42.1 | 70.8/48.1 | 72.9/50.7 |
| LI | 40.1/26.0 | 52.3/36.9 | 69.1/47.4 | 72.3/46.8 | 70.5/46.2 | 67.0/45.5 | 72.7/48.8 | 82.7/56.0 |
| LR | 46.9/27.4 | 55.1/36.5 | 72.0/47.6 | 72.5/46.2 | 75.1/47.6 | 75.9/51.5 | 74.5/50.8 | 80.7/55.4 |
| TC | 37.5/23.8 | 45.7/32.7 | 66.8/46.2 | 70.1/44.2 | 76.0/47.0 | 75.6/51.7 | 79.6/56.2 | 82.6/59.7 |
| DEF | 36.4/24.4 | 52.3/36.7 | 63.0/46.2 | 65.0/46.0 | 68.5/47.4 | 66.8/47.3 | 70.4/50.3 | 85.3/55.3 |
| FM | 32.0/19.6 | 37.6/25.0 | 52.9/35.8 | 63.7/38.7 | 67.7/47.2 | 58.6/36.3 | 63.3/41.7 | 74.3/49.3 |
| SV | 45.5/30.6 | 59.8/43.3 | 70.7/49.9 | 66.4/40.4 | 69.2/43.4 | 73.5/50.5 | 77.0/53.5 | 78.7/56.5 |
| MB | 28.6/20.6 | 35.7/27.1 | 58.0/42.5 | 63.9/42.1 | 64.7/43.6 | 65.4/46.3 | 67.4/48.0 | 69.9/51.1 |
| CM | 31.6/22.5 | 41.7/31.8 | 61.1/44.5 | 65.2/43.0 | 66.7/45.2 | 64.0/45.4 | 66.8/47.4 | 74.5/54.0 |
| BC | 34.2/22.0 | 46.3/30.8 | 61.8/41.0 | 64.7/41.9 | 65.8/41.8 | 64.4/43.2 | 71.0/47.8 | 78.3/52.7 |
| ALL | 43.1/28.7 | 55.1/39.0 | 69.5/49.0 | 69.6/45.1 | 72.0/47.2 | 72.2/49.5 | 76.4/53.2 | 80.2/56.9 |
| NO | PO | HO | LI | LR | TC | DEF | FM | SV | MB | CM | BC | ALL | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Ours-CA | 87.3/64.8 | 83.8/59.4 | 68.9/47.3 | 82.3/55.6 | 78.4/53.6 | 79.0/55.6 | 72.0/52.7 | 68.0/45.4 | 77.1/55.3 | 68.5/50.1 | 72.2/52.1 | 74.5/50.6 | 78.4/55.4 |
| Ours-SA | 88.6/64.8 | 84.4/59.3 | 69.2/48.2 | 80.3/54.8 | 78.3/53.6 | 76.8/54.6 | 84.9/54.6 | 71.5/46.2 | 78.5/55.3 | 69.5/50.9 | 72.2/52.2 | 76.7/52.2 | 79.1/55.8 |
| Ours | 90.5/66.8 | 83.0/58.8 | 72.9/50.7 | 82.7/56.0 | 80.7/55.4 | 82.6/59.7 | 85.3/55.3 | 74.3/49.3 | 78.7/56.5 | 69.9/51.1 | 74.5/54.0 | 78.3/52.7 | 80.2/56.9 |
| MDNet | MDNet + RGBT | Ours | ||
|---|---|---|---|---|
| GTOT | PR/SR | 81.2/63.3 | 80.0/63.7 | 90.5/73.2 |
| RGBT234 | PR/SR | 71.0/49.0 | 72.2/49.5 | 80.2/56.9 |
| FPS | 3.2 | 1.6 | 1.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, R.; Wang, C.; Zhao, G.; Xu, C. SCA-MMA: Spatial and Channel-Aware Multi-Modal Adaptation for Robust RGB-T Object Tracking. Electronics 2022, 11, 1820. https://doi.org/10.3390/electronics11121820
Shi R, Wang C, Zhao G, Xu C. SCA-MMA: Spatial and Channel-Aware Multi-Modal Adaptation for Robust RGB-T Object Tracking. Electronics. 2022; 11(12):1820. https://doi.org/10.3390/electronics11121820
Chicago/Turabian StyleShi, Run, Chaoqun Wang, Gang Zhao, and Chunyan Xu. 2022. "SCA-MMA: Spatial and Channel-Aware Multi-Modal Adaptation for Robust RGB-T Object Tracking" Electronics 11, no. 12: 1820. https://doi.org/10.3390/electronics11121820
APA StyleShi, R., Wang, C., Zhao, G., & Xu, C. (2022). SCA-MMA: Spatial and Channel-Aware Multi-Modal Adaptation for Robust RGB-T Object Tracking. Electronics, 11(12), 1820. https://doi.org/10.3390/electronics11121820