
Resource Allocation on Blockchain Enabled Mobile Edge Computing System



Abstract
:1. Introduction
- (1)
- As the blockchain system has something to do with the resource allocation policy in MEC systems, the blockchain mining process is taken into account in resource allocation model. There into, mining delay and mining reward are considered.
- (2)
- To improve the utilization of edge computing resources, the new consensus algorithm: proof of learning (PoL), is applied in the system based on previous studies [26,27]. PoL replaces the meaningless hash puzzle with the task of training neural networks, which are common in MEC application scenarios. Furthermore, the mining delay and mining reward are calculated according to this consensus.
- (3)
- To learn the impact of these indicators on resource allocation policies, we set different combinations of weight coefficients to adjust the resource allocation policies to different tendencies. Furthermore, we explored the effect of varying task arrival rates on policies with different preferences.
- (4)
- To learn the long-term pattern of impending tasks, the structure of temporal convolutional network (TCN) [28] is referred to as the policy function and state-value function in asynchronous advantage Actor-Critic (A3C) algorithm. The convergence speed of TCN enabled A3C algorithm and traditional A3C algorithm, which choose action only depends on current state, is compared, and it is found that using TCN as the policy and state-value functions can converge faster and more stable.
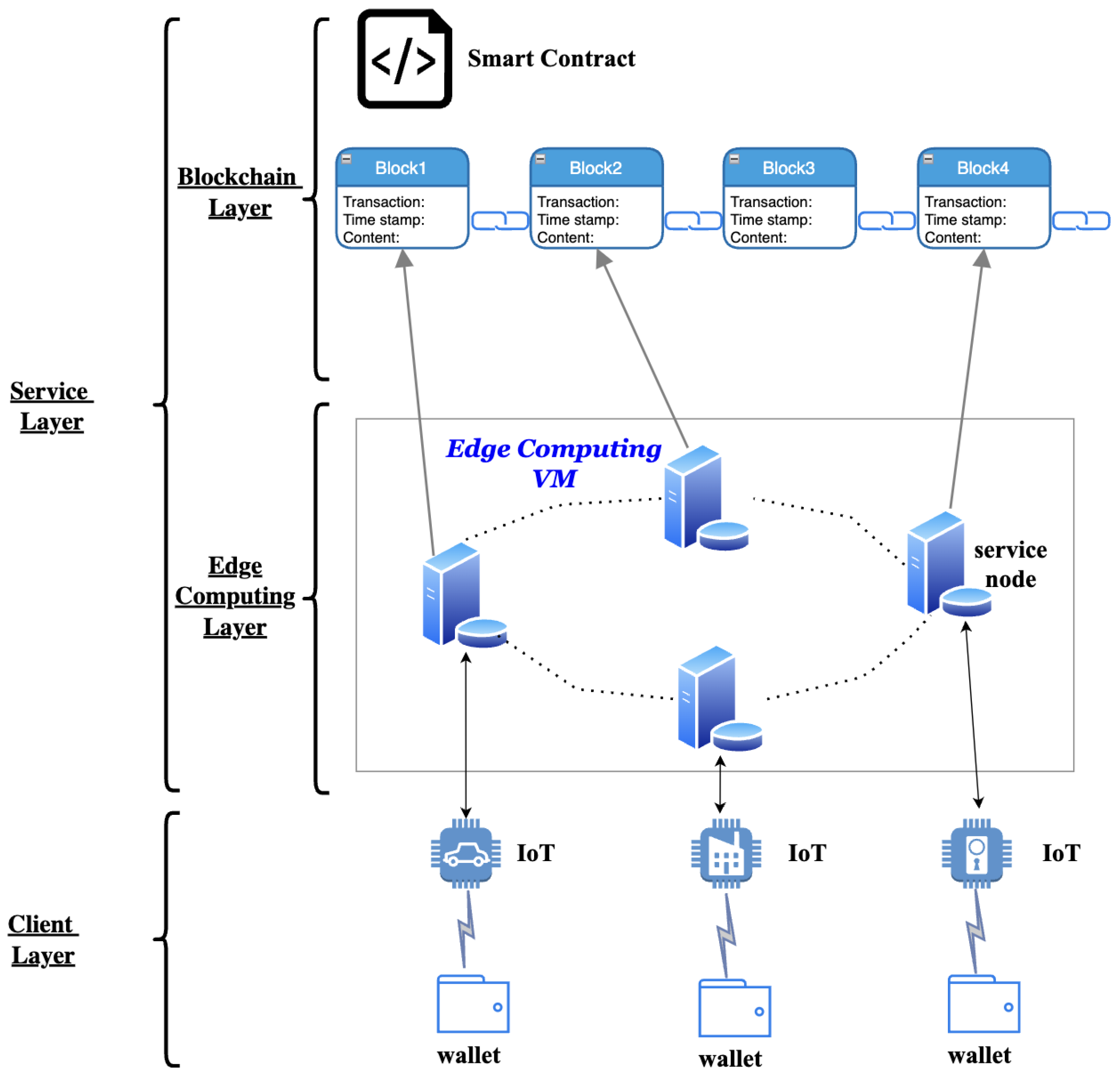
2. Overview of the System
2.1. Framework of the System
- (1)
- While using the blockchain technology, the MEC system that could previously run only on a trusted intermediary, can now operate safely without the need for a central authority [29]. Furthermore, the heavy use of cryptography brings authoritativeness and security [29]. For example, the zero-knowledge proof can protect the information with anonymity [18], the consensus algorithms can avoid malicious attacks [30], and the script validation used in transactions, namely Pay-to-Public-Key-Hash transaction (en.bitcoinwiki.org/wiki/Pay-to-Pubkey_Hash, accessed on 4 February 2020) and multi-signature transaction (en.bitcoin.it/wiki/Multi-signature, accessed on 20 July 2021), can improve the security [31].
- (2)
- As the MEC system is in a quite decentralized environment, using just an online platform may suffer from “a central point of failure” [32]. The decentralized trait of blockchain technology can build mutual trust among participants by implement specific consensus: PoW, proof of stake (PoS), and thus enhance the robustness of the system [31]. The model proposed by Xu J.L. et al. [31] have proved its correctness.
- (3)
- Smart contracts, which are scripts that reside on the blockchain that allow for the automation of multi-step processes, translate contractual clauses into code and embed them into property that can self-enforce them. They operate as autonomous actors, whose behavior is based on the embedded logic [30]. When combined with MEC system, the smart contract can provide flexible and scalable computing capability to address the tradeoff between limited computing capacity and high latency [33]. The work performed by Ye X.Y. et al. [34] has proved that the combination of blockchain and MEC can have an improvement on optimal allocation policy compared with other existing schemes.
2.2. Working Flow of the System
- (1)
- The air quality sensor, which is a mobile device, connects to the wallet to make sure the device itself links to the blockchain-based mobile edge computing system.
- (2)
- The wallet is used to send a request to the service node, along with a certain amount of crypto token for the cost of edge computing services.
- (3)
- The smart contract will detect this transaction and allocate computing resources to the data, which is uploaded by the air quality sensor, based on the current state of the system and the size of the uploaded data, and it is called the “edge task”.
- (4)
- The allocated computing resources then start dealing with the “edge task”, and the processed result is finally obtained. After that, the service node, or the miner, needs to finish the training of a specific neural network under the PoL consensus, which is the “mining task”, for the preparation of block generation.
- (5)
- Once the “mining task” is finished, the service node is required to upload the training results, such as the accuracy of the training model and the neural network parameters. Furthermore, other miners can thus verify its correctness and make sure the service node is not doing malicious things. After everything is completed, a block is generated and stored in the blockchain system.
- (6)
- Finally, the result of “edge task” will be sent back to the air quality sensor.
3. Resource Allocation Problem
3.1. Edge Computing System Model
3.2. Blockchain Model
- (1)
- Forward Propagation
- (2)
- Backward Propagation
3.3. Reinforcement Learning Model
3.3.1. State
3.3.2. Action
3.3.3. Transition of State
3.3.4. Reward Function
3.3.5. TCN Enabled A3C Model
- Global network parameter initialization.
- Workers duplicate global network.
- Workers interact with their environments.
- Workers calculate the loss of value and policy.
- Workers calculate gradient through loss function.
- Workers update the parameters of global network.
4. Simulation and Analysis
4.1. Impacts of Weight Coefficients
4.2. Impacts of Arrival Rate
4.3. Appropriate Choice of Weight Coefficients
4.4. Comparison between TCN Enabled A3C and Fully-Connected A3C
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| MEC | Mobile edge computing |
| A3C | Asynchronous advantage Actor-Critic |
| TCN | Temporal Convolutional Network |
| FLOPs | Floating Point Operations |
References
- Cisco. Cisco Annual Internet Report (2018–2023) White Paper. 2020. Available online: https://www.cisco.com/c/en/us/solutions/collateral/executive-perspectives/annual-internet-report/white-paper-c11-741490.html (accessed on 14 July 2021).
- Patel, M.; Naughton, B.; Chan, C.; Sprecher, N.; Abeta, S.; Neal, A. Mobile-edge computing introductory technical white paper. Mob.-Edge Comput. (MEC) Ind. Initiat. 2014. [Google Scholar]
- Gai, K.; Fang, Z.; Wang, R.; Zhu, L.; Jiang, P.; Choo, K.K.R. Edge Computing and Lightning Network Empowered Secure Food Supply Management. IEEE Internet Things J. 2020. [Google Scholar] [CrossRef]
- Pal, A.; Kant, K. IoT-Based Sensing and Communications Infrastructure for the Fresh Food Supply Chain. Computer 2018, 51, 76–80. [Google Scholar] [CrossRef]
- Mao, Y.; You, C.; Zhang, J.; Huang, K.; Letaief, K.B. A survey on mobile edge computing: The communication perspective. IEEE Commun. Surv. Tutor. 2017, 19, 2322–2358. [Google Scholar] [CrossRef] [Green Version]
- Garcia Lopez, P.; Montresor, A.; Epema, D.; Datta, A.; Higashino, T.; Iamnitchi, A.; Barcellos, M.; Felber, P.; Riviere, E. Edge-centric computing: Vision and challenges. ACM SIGCOMM Comput. Commun. Rev. 2015, 45, 37–42. [Google Scholar] [CrossRef]
- Li, F.; Wang, D. 5G Network Data Migration Service Based on Edge Computing. Symmetry 2021, 13, 2134. [Google Scholar] [CrossRef]
- Tong, M.; Wang, X.; Li, S.; Peng, L. Joint Offloading Decision and Resource Allocation in Mobile Edge Computing-Enabled Satellite-Terrestrial Network. Symmetry 2022, 14, 564. [Google Scholar] [CrossRef]
- Liu, Y.; Xie, R.; Huang, T.; Yang, F. Edge Computing Principles and Practice; Posts and Telecommunications Press: Beijing, China, 2019. [Google Scholar]
- Gul, F.; Mir, I.; Abualigah, L.; Sumari, P.; Forestiero, A. A Consolidated Review of Path Planning and Optimization Techniques: Technical Perspectives and Future Directions. Electronics 2021, 10, 2250. [Google Scholar] [CrossRef]
- Huang, D.; Wang, P.; Niyato, D. A dynamic offloading algorithm for mobile computing. IEEE Trans. Wirel. Commun. 2012, 11, 1991–1995. [Google Scholar] [CrossRef]
- Yang, T.; Hu, Y.; Gursoy, M.C.; Schmeink, A.; Mathar, R. Deep reinforcement learning based resource allocation in low latency edge computing networks. In Proceedings of the 15th International Symposium on Wireless Communication Systems (ISWCS), Lisbon, Portugal, 28–31 August 2018; pp. 1–5. [Google Scholar]
- Wang, X.; Zhang, Y.; Shen, R.; Xu, Y.; Zheng, F.C. DRL-based energy-efficient resource allocation frameworks for uplink NOMA systems. IEEE Internet Things J. 2020, 7, 7279–7294. [Google Scholar] [CrossRef]
- Forestiero, A.; Papuzzo, G. Agents-based algorithm for a distributed information system in Internet of Things. IEEE Internet Things J. 2021, 8, 16548–16558. [Google Scholar] [CrossRef]
- Xu, S.; Ratazzi, E.P.; Du, W. Security architecture for federated mobile cloud computing. In Mobile Cloud Security; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Roman, R.; Lopez, J.; Mambo, M. Mobile edge computing, fog et al.: A survey and analysis of security threats and challenges. Future Gener. Comput. Syst. 2018, 78, 680–698. [Google Scholar] [CrossRef] [Green Version]
- Hafid, A.; Hafid, A.S.; Samih, M. Scaling blockchains: A comprehensive survey. IEEE Access 2020, 8, 125244–125262. [Google Scholar] [CrossRef]
- Cao, L.; Wan, Z. Anonymous scheme for blockchain atomic swap based on zero-knowledge proof. In Proceedings of the IEEE International Conference on Artificial Intelligence and Computer Applications (ICAICA), Dalian, China, 27–29 June 2020; pp. 371–374. [Google Scholar] [CrossRef]
- Gai, K.; Guo, J.; Zhu, L.; Yu, S. Blockchain meets cloud computing: A survey. IEEE Commun. Surv. Tutor. 2020, 22, 2009–2030. [Google Scholar] [CrossRef]
- Damianou, A.; Angelopoulos, C.M.; Katos, V. An architecture for blockchain over edge-enabled IoT for smart circular cities. In Proceedings of the 15th International Conference on Distributed Computing in Sensor Systems (DCOSS), Thera, Greece, 29–31 May 2019; pp. 465–472. [Google Scholar]
- Luo, C.; Xu, L.; Li, D.; Wu, W. Edge computing integrated with blockchain technologies. In Complexity and Approximation; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Pan, J.; Wang, J.; Hester, A.; Alqerm, I.; Liu, Y.; Zhao, Y. EdgeChain: An edge-IoT framework and prototype based on blockchain and smart contracts. IEEE Internet Things J. 2018, 6, 4719–4732. [Google Scholar] [CrossRef] [Green Version]
- Asheralieva, A.; Niyato, D. Bayesian reinforcement learning and bayesian deep learning for blockchains with mobile edge computing. IEEE Trans. Cogn. Commun. Netw. 2020, 7, 319–335. [Google Scholar] [CrossRef]
- He, Y.; Wang, Y.; Qiu, C.; Lin, Q.; Li, J.; Ming, Z. Blockchain-based edge computing resource allocation in IoT: A deep reinforcement learning approach. IEEE Internet Things J. 2020, 8, 2226–2237. [Google Scholar] [CrossRef]
- Qiu, X.; Liu, L.; Chen, W.; Hong, Z.; Zheng, Z. Online deep reinforcement learning for computation offloading in blockchain-empowered mobile edge computing. IEEE Trans. Veh. Technol. 2019, 68, 8050–8062. [Google Scholar] [CrossRef]
- Qiu, C.; Wang, X.; Yao, H.; Du, J.; Yu, F.R.; Guo, S. Networking Integrated Cloud–Edge–End in IoT: A Blockchain-Assisted Collective Q-Learning Approach. IEEE Internet Things J. 2020, 8, 12694–12704. [Google Scholar] [CrossRef]
- Qiu, C.; Yao, H.; Wang, X.; Zhang, N.; Yu, F.R.; Niyato, D. AI-Chain: Blockchain energized edge intelligence for beyond 5G networks. IEEE Netw. 2020, 34, 62–69. [Google Scholar] [CrossRef]
- Bai, S.; Kolter, J.Z.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Zyskind, G.; Nathan, O.; Pentland, A.S. Decentralizing Privacy: Using Blockchain to Protect Personal Data. In Proceedings of the IEEE Security and Privacy Workshops, San Jose, CA, USA, 18–20 May 2015; pp. 180–184. [Google Scholar] [CrossRef]
- Christidis, K.; Devetsikiotis, M. Blockchains and Smart Contracts for the Internet of Things. IEEE Access 2016, 4, 2292–2303. [Google Scholar] [CrossRef]
- Xu, J.; Wang, S.; Zhou, A.; Yang, F. Edgence: A blockchain-enabled edge-computing platform for intelligent IoT-based dApps. China Commun. 2020, 17, 78–87. [Google Scholar] [CrossRef]
- Huang, Y.; Zhang, J.; Duan, J.; Xiao, B.; Ye, F.; Yang, Y. Resource Allocation and Consensus of Blockchains in Pervasive Edge Computing Environments. IEEE Trans. Mob. Comput. 2021, 8, 829–843. [Google Scholar] [CrossRef]
- Wu, H.; Wolter, K.; Jiao, P.; Deng, Y.; Zhao, Y.; Xu, M. EEDTO: An Energy-Efficient Dynamic Task Offloading Algorithm for Blockchain-Enabled IoT-Edge-Cloud Orchestrated Computing. IEEE Internet Things J. 2021, 8, 2163–2176. [Google Scholar] [CrossRef]
- Ye, X.; Li, M.; Si, P.; Yang, R.; Sun, E.; Zhang, Y. Blockchain and MEC-assisted reliable billing data transmission over electric vehicular network: An actor—Critic RL approach. China Commun. 2021, 18, 279–296. [Google Scholar] [CrossRef]
- Marques, G.; Pitarma, R. Air quality through automated mobile sensing and wireless sensor networks for enhanced living environments. In Proceedings of the 14th Iberian Conference on Information Systems and Technologies (CISTI), Coimbra, Portugal, 19–22 June 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Xue, J.; Wang, Z.; Zhang, Y.; Wang, L. Task allocation optimization scheme based on queuing theory for mobile edge computing in 5G heterogeneous networks. Mob. Inf. Syst. 2020, 2020, 1501403. [Google Scholar] [CrossRef]
- Zhou, J.P. Communication Networks Theory; The People’s Posts and Telecommunications Press: Beijing, China, 2009. [Google Scholar]
- Kimura, T. Approximations for the delay probability in the M/G/s queue. Math. Comput. Model. 1995, 22, 157–165. [Google Scholar] [CrossRef]
- Hunger, R. Floating Point Operations in Matrix-Vector Calculus; Munich University of Technology, Institute Circuit Theory and Signal Processing: Munich, Germany, 2005. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning (PMLR), New York, NY, USA, 19–24 June 2016; pp. 1928–1937. [Google Scholar]
- Ajay Rao, P.; Navaneesh Kumar, B.; Cadabam, S.; Praveena, T. Distributed deep reinforcement learning using TensorFlow. In Proceedings of the International Conference on Current Trends in Computer, Electrical, Electronics and Communication (CTCEEC), Mysore, India, 8–9 September 2017; pp. 171–174. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Explanation | Value |
|---|---|---|
| the mean of data size | 7 (Mb) | |
| the variance of data size | 2 | |
| c | minimum data size split | 1 (Mb) |
| floating point operations | ||
| M | CPU cycles required for 1 bit | [2, 5, 7] (bit/Hz) |
| N | number of training task | |
| f | domain frequency of server | [15, 16, 17, 18] (GHz) |
| arrival rate | [14, 16, 18, 20, 22, 24] | |
| u | server cost | [1, 1.1, 1.2, 1.3] |
| D | mining difficulty | [5, 6] |
| coefficient of process delay | [100, 25, 50, 100, 100, 5, 5, 1] | |
| coefficient of mining delay | [2, 0.5, 1, 2, 2, 0.1, 0.1, 1] | |
| coefficient of cost | [1, 1, 1, 1, 1, 100, 200, 1] | |
| coefficient of bonus | [20, 5, 10, 5, 1, 1, 1, 10] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, X.; Zhang, Y.; Yang, F.; Xu, F. Resource Allocation on Blockchain Enabled Mobile Edge Computing System. Electronics 2022, 11, 1869. https://doi.org/10.3390/electronics11121869
Zheng X, Zhang Y, Yang F, Xu F. Resource Allocation on Blockchain Enabled Mobile Edge Computing System. Electronics. 2022; 11(12):1869. https://doi.org/10.3390/electronics11121869
Chicago/Turabian StyleZheng, Xinzhe, Yijie Zhang, Fan Yang, and Fangmin Xu. 2022. "Resource Allocation on Blockchain Enabled Mobile Edge Computing System" Electronics 11, no. 12: 1869. https://doi.org/10.3390/electronics11121869
APA StyleZheng, X., Zhang, Y., Yang, F., & Xu, F. (2022). Resource Allocation on Blockchain Enabled Mobile Edge Computing System. Electronics, 11(12), 1869. https://doi.org/10.3390/electronics11121869