3.1. Modeling of ARIMA
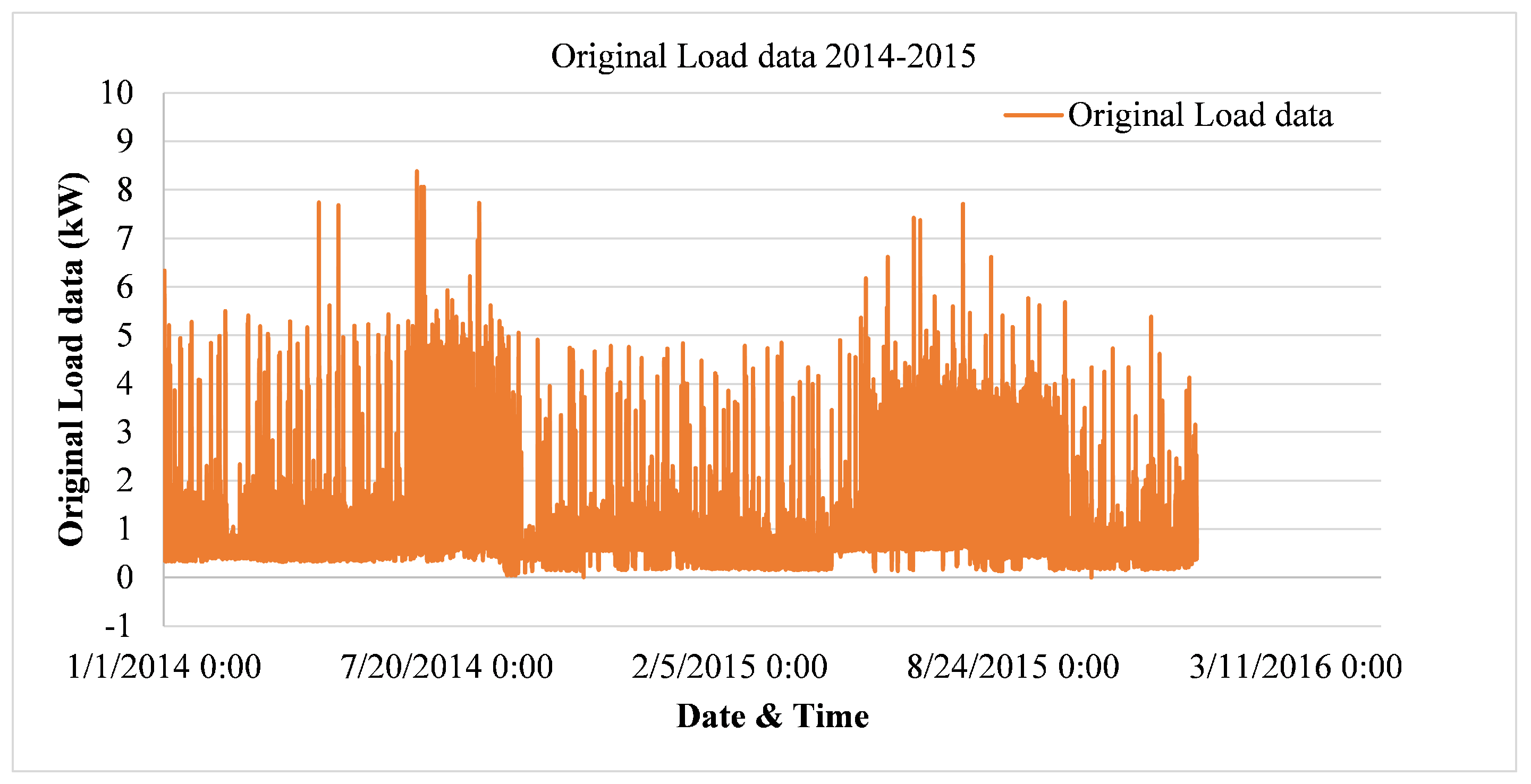
The ARIMA model processes data in a time series for making a prediction. The ARIMA model is used in both linear and multiple-regression models. The multiple regression model refers to the prediction of outcomes of dependent variables, which are based on variables of independent variables. The model is generally referred to as ARIMA (p, d, q), where p, d, and q are zero or positive numbers. The ARIMA model makes use of a stationary time series. Using a multiple linear regression model, it can work over non-stationary time series data. The values of p, q, and d can be found using auto-ARIMA. The process seeks to identify the most optimal parameters for the ARIMA model, settling on a single-fitted model. The process works by conducting differencing tests to determine the order of differencing ‘d’ and then fitting the models within the ranges of defined start p, max p, start q, and max q. The parameters p, q, and d were set to (4, 1, 1). Finally, the model trained on 2014–2015 data to obtain a prediction for 2016 consumption data.
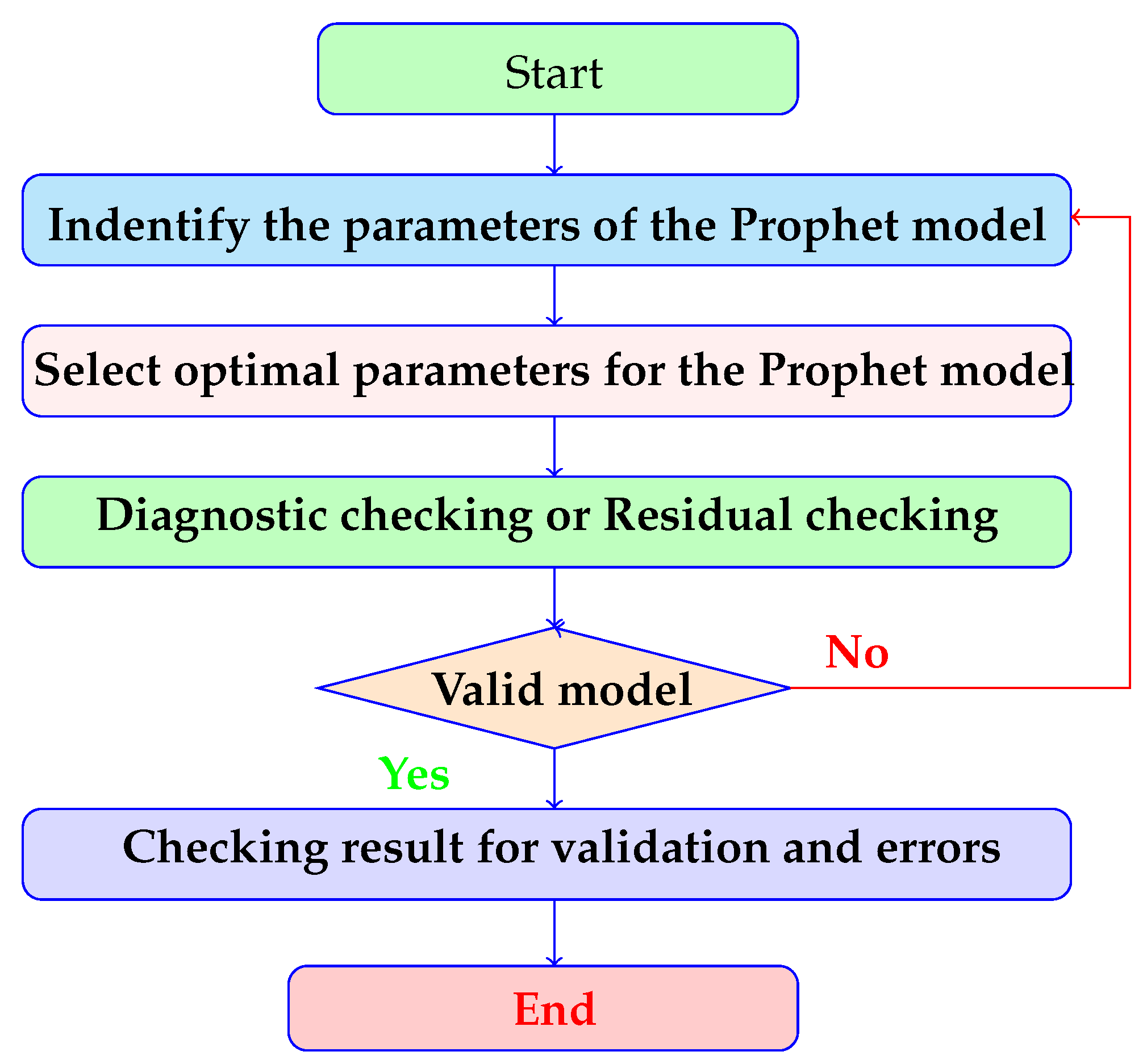
The ADF (Augmented Dickey Fuller) test is useful in detecting the unit root in a series to understand whether the series is stationary or non-stationary. Here, the null and alternate hypotheses state that if a series has a unit root, it fails to reject the null hypothesis, which says that the unit has a root. Then, the series is non-stationary. This means that the series can be linear, stationary, or difference stationary. The experimental results show that the ARMA (Auto Regressive Moving Average model) is based on real data, which is a stationary time series. In the flow chart shown in
Figure 2, three features of the stationary data have been selected. Here, the first characteristic is the constant mean, the second one is the variance, which is also a constant, and the third characteristic is the co-variance, where the signal of past data, at different times, is constant.
Here, the daily stationary signal does not meet the first condition, but satisfies the second and third conditions. The moving average component of ARMA is set for change mean, and therefore, the first condition is not essential for the appropriate ARMA for a given time series. Later, the process of residual checking is completed.
If conditions are satisfied, then the process is stopped or otherwise continued. In
Figure 2, the procedure of the ARIMA model is shown. Here, the power consumption datasets were collected and then the data is preprocessed. Subsequently, any abnormal data present in the datasets is eliminated. After the selection of features, the important features are extracted by using the classifier (Support Vectors Machine) and, at last, the predicted energy. On the basis of lagged data, future prediction is decided. In the above model, the equations are based on an autoregressive function. It is a function where the current value is generated based on the immediately preceding value. In the second process, the current value is generated based on the last two values. An AR (0) process would imply that there are no dependencies among the terms in the equations.
The aforementioned term predicts certain errors known as moving averages. The time series is differenced to make the data stationary. There are many models such as Randomwalk model, Random-trend model, Autoregressive model, and the Exponential-smoothing model. All are special cases of the ARIMA model. The time series representing the electricity consumption of a single consumer, at time
t, is given by the value
. The ARIMA model is discussed as in
Figure 2 which represents the flow chart of the model where the parameters are indicated. Here, the values of parameters are selected and residual checking is done. The residual value is differenced between the observed value and the predicted value. The ARIMA model aims to predict power.
whereas
indicates the consumption of energy at time
t,
c indicates obstruction of the signal at
q.
and
are the parameters and regressors for the AR part of the model, respectively. It assumes Gaussian noise as in
and compounds
q over time periods. Further,
and coefficient
represent the parameters and regressors of the MA part of the model, respectively.
In Equation (
2),
is the dependent variable and it indicates the prediction of the energy consumption using time series data. The values
and
are independent variables and define the first-order differencing for making stationary data into a non-stationary data.
The prediction of the energy consumption in a time series data is described as follows:
where at time
,
and
are the predicted values and the random error of data
indicates the model parameter,
indicates the model parameter,
p and
q are represented by the autoregressive and moving average orders. Equation (
3) shows some important cases of the ARIMA models, If
= 0, then Equation (
3) becomes an AR model of order
, and when
, the model decreases to a MA model to work with order
. The past data is the main basis in the prediction of energy by ARIMA model.
The general forecasting equation is:
George Box and Gwilym Jenkins have introduced the moving average parameters having negative values in the equation. Hence, the actual numbers are used in the equation and there is no ambiguity, as the output was read by us at the time of using this software. These parameters are denoted by AR(1), AR(2)…AR(N), and MA(1), MA(2)…MA(N). To recognize a suitable ARIMA model for , the order of differencing viz., is to be decided. It is very important to make the series spatial so that the characteristics of seasonality can be removed. If the prediction of the differenced next series is constant, then we have to apply random-trend model. Here, the series is autocorrelated and the errors show the number of AR terms and number MA . These are also needed in the equation. To determine the values of , and is the best way for a given time series.
There are many types of non-seasonal ARIMA models that are discussed as follows: The ARIMA (1, 0, 0) model is denoted as the first-order autoregressive model. If the series is stationary and autocorrelated, then it can be forecast as a multiple of its own previous value, plus a constant. The forecasting equation, in this case is as below.
In Equation (
5),
is less developed data on itself by one period. This is an ARIMA (1, 0, 0) + constant model. If the mean value of
is zero, then the constant value will not be sufficient. If the slope coefficient
is positive and less than 1,
is stationary. If the value of the next time period value is predicted to be
times it creates a great distance from the mean, as this is a time value. If
is negative, it predicts a mean level with alteration of the signs. It also predicts that
will be below the mean of the next period if it is above the mean at that time.
In a second order autoregressive model ARIMA (2, 0, 0), there is
term on the right, as well as on the left and depending on the signs and magnitudes of the coefficients. It describes a system where the mean level is of a sinusoidal wave pattern. It is like the motion of a mass on a spring that is subjected to random shocks. If the autoregressive coefficient is equal to 1, it is a series with an infinitely slow mean, which returns to the previous state. The equation for this model can be written as follows:
or equivalently
where the constant term is the mean, which periodically changes (i.e., the long-term drift)
. This model could be fitted as a no-intercept regression model in which the first differencing of
y is the dependent variable, as it includes only a nonseasonal difference and a constant term. It is “ARIMA0,1,0 with a constant.” The Random-walk without drift model would be ARIMA (0,1,0) without any constant. ARIMA1,1,0 is used as differenced with first-order in the autoregressive model. Here, autocorrelated means that the errors are found as in the Random walk model. Then the problem can be settled by adding past data of the dependent variable to the forecast equations, i.e., by regressing the first difference of
z on itself lagged by one period. The forecast equation is:
3.2. The Modeling of Prophet
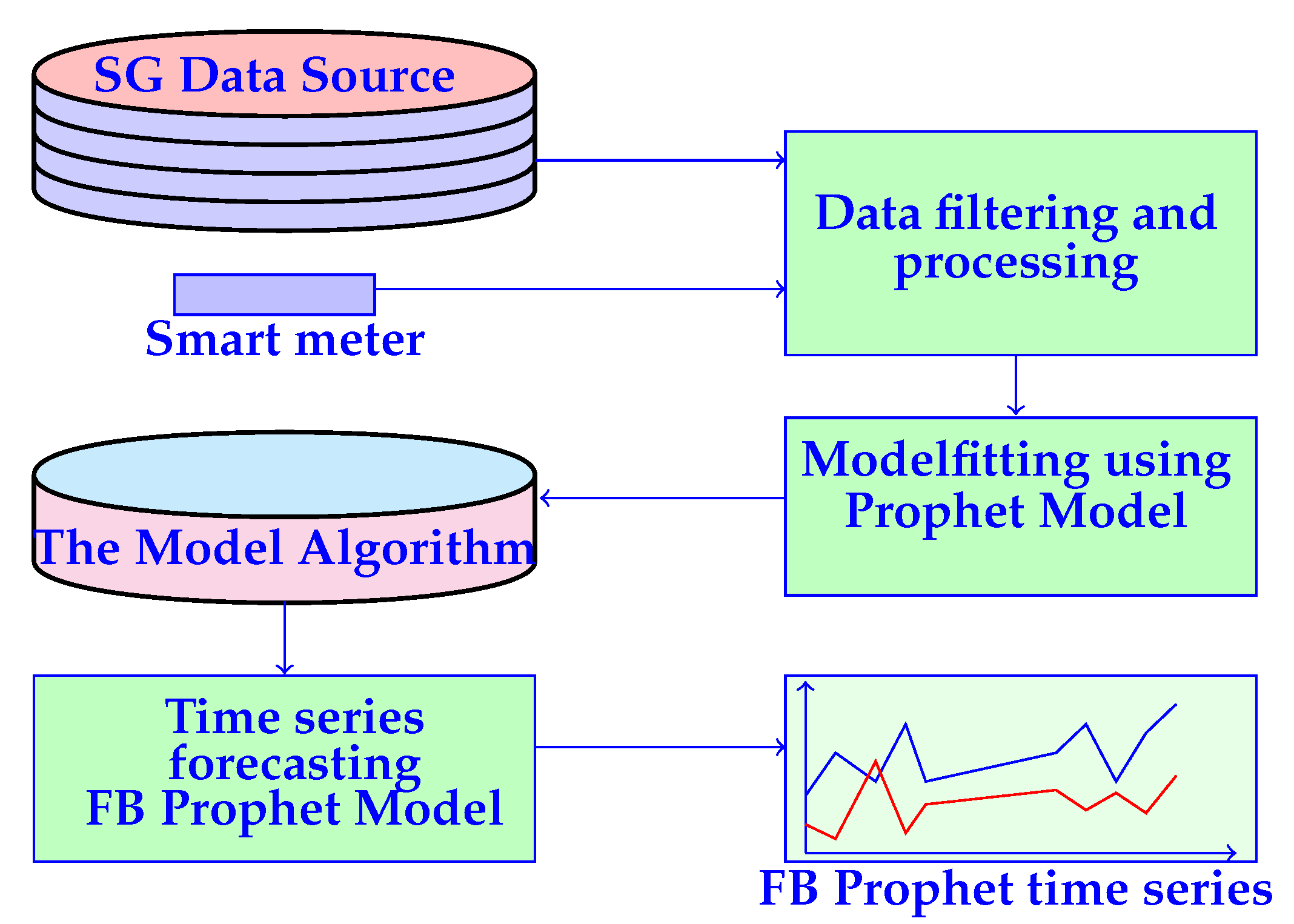
Prophet has been developed by Facebook in order to overcome some problems that exist in ARIMA. Prophet works through the use of an additive model whereby the non-linear trends in the series are fitted with the appropriate seasonality. It is a time series predictive method where the aim is to predict power in SG. The flow chart of Prophet model is shown in
Figure 3. For this purpose, appliances are categorized as: interruptible, non-interruptible, and base appliances. Power categorization of:
Interruptible Appliances
where
is the power consumption of appliances,
indicates Interruptible Appliance,
indicates power rating,
U is the total time slot, and
is the state of each Interruptible Appliance at time slot
t.
Non-interruptible Appliances
where
is the power consumption of appliances,
indicates Non-Interruptible Appliance,
indicates power rating,
U is total time slot, and
is the state of each Non-Interruptible Appliances at time slot
t.
Base appliances are similar to fixed appliances that do not have flexibility of operation. The pattern of consumption of energy and operational period of appliances cannot be changed. It is important that these appliances must be ‘ON’ when the user wants to switch them ON such as home appliances viz. TV, fridge, and other devices.
where
represents total energy consumption, B is the base appliance at time
t,
is each base appliance, and
is the power rating.
Since the Prophet model works on data trends, holidays and seasonal data provides complex features. Seasonality is input on the basis of day, week, and year. The prophet model, where consumption is represented by time series, is a data method expressed as follows,
where
indicates the consumption,
represents the data trend function,
indicates the seasonal data,
indicates the holiday-based data, and
represents the errors.
The trend function of the Prophet model
is highlighted by a piecewise linear growth model. It is also called a Saturation-growth model. The maximum load data does not show a saturating growth, which is a piecewise linear growth model represented as follows:
Here
l is the growth rate,
indicates rate adjustment,
n is an offset parameter, and
is the change point.
where
is the output and
is the change point.
The seasonality function is manifested by the following equation:
In Equation (
17),
is the seasonality function. Here, the time series multiperiod seasonality method is used. The Fourier series is applied to the daily and seasonal changes. Therefore, the seasonality function is discussed as:
Here,
indicates the matrix of regresses,
E indicates holidays, and 1 represents the holidays parameter.
In Equation (
19),
indicates holidays and
l indicates a corresponding change in the forecast. It produces estimates of unknown variables.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}