
Hybrid Beamforming for MISO System via Convolutional Neural Network

 , , ,
, , ,
Abstract
:1. Introduction
1.1. Contributions of the Work
- We develop a DL-based approach for the joint optimization of digital and analog beamformers under the SE maximization problem. To solve the nonconvex problem, we propose a novel CNN-based HBF network framework with multiple convolutional blocks to efficiently extract more channel features. The proposed CNN structure can predict analog beamforming solution quickly and achieve excellent performance with low complexity, due to the parameter sharing feature of its convolutional operations. We also select the ELU activation function to speed up the convergence and employ dropout to avoid the risk of overfitting.
- We take an unsupervised deep-learning strategy to train the proposed CNN structure for the hybrid beamforming optimization problem. Unlike supervised CNNs, the devised unsupervised CNN updates the weights just based on the loss function without any optimal beamformer as labeled data, which is normally calculated by traditional algorithms. In addition, actually, there is no useful algorithm to find the global optimum due to the nonconvex nature of the problem. We only need to take CSI as input data for training to obtain feasible beamforming solutions adaptively. Thus, a huge amount of time and computational resources can be saved and the problem of data acquisition can be solved efficiently.
- To perform HBF optimization, we first train the neural network offline with a self-defined loss function and continuously learn to optimize the parameters, and then feed the saved model weight parameters into the trained network for online testing. This approach shifts the computational complexity from online testing to offline training, which can significantly lower the computational complexity of the online testing stage.
- Distinct from previous works, the performance of the proposed HBF algorithm with other algorithms in terms of the generalization ability for multiple CSIs is not only investigated, but we also innovatively discuss the performance of the mentioned algorithms with respect to the specific solving capability for a single CSI. We innovatively apply DL to the HBF optimization problem from this new perspective, which has not been mentioned in prior work. Simulation experiments are conducted in two classical channel environments, namely, a Rayleigh fading channel and geometric mmWave channel, respectively.
1.2. Paper Organization
2. System Model and Problem Formulation
2.1. System Model
2.2. Problem Formulation
3. Proposed CNN-Based Hybrid Beamforming Optimization
3.1. Data Preparation
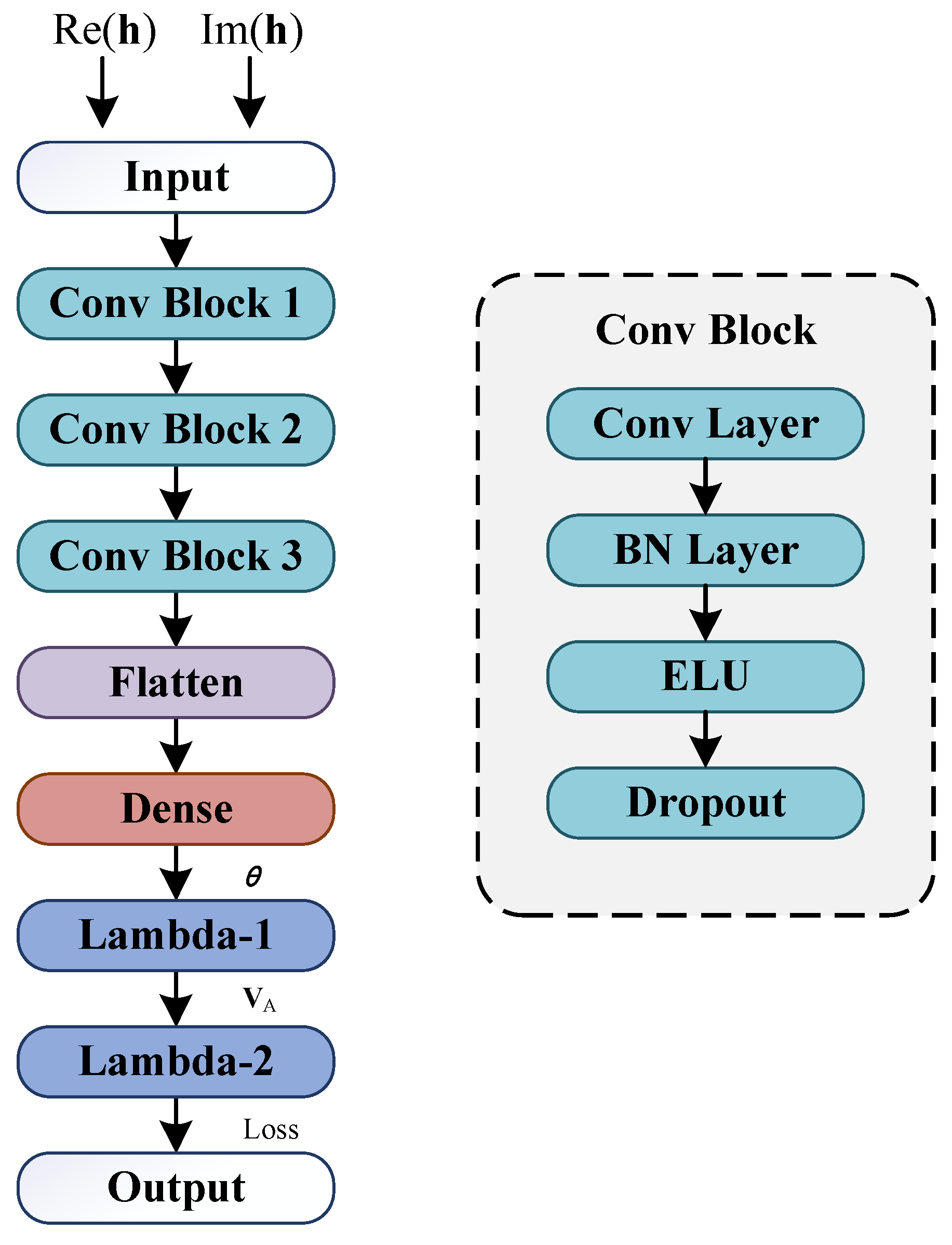
3.2. CNN Structure
3.2.1. Input Layer
3.2.2. Conv Blocks
3.2.3. Flatten Layer
3.2.4. Dense Layer
3.2.5. Lambda Layers
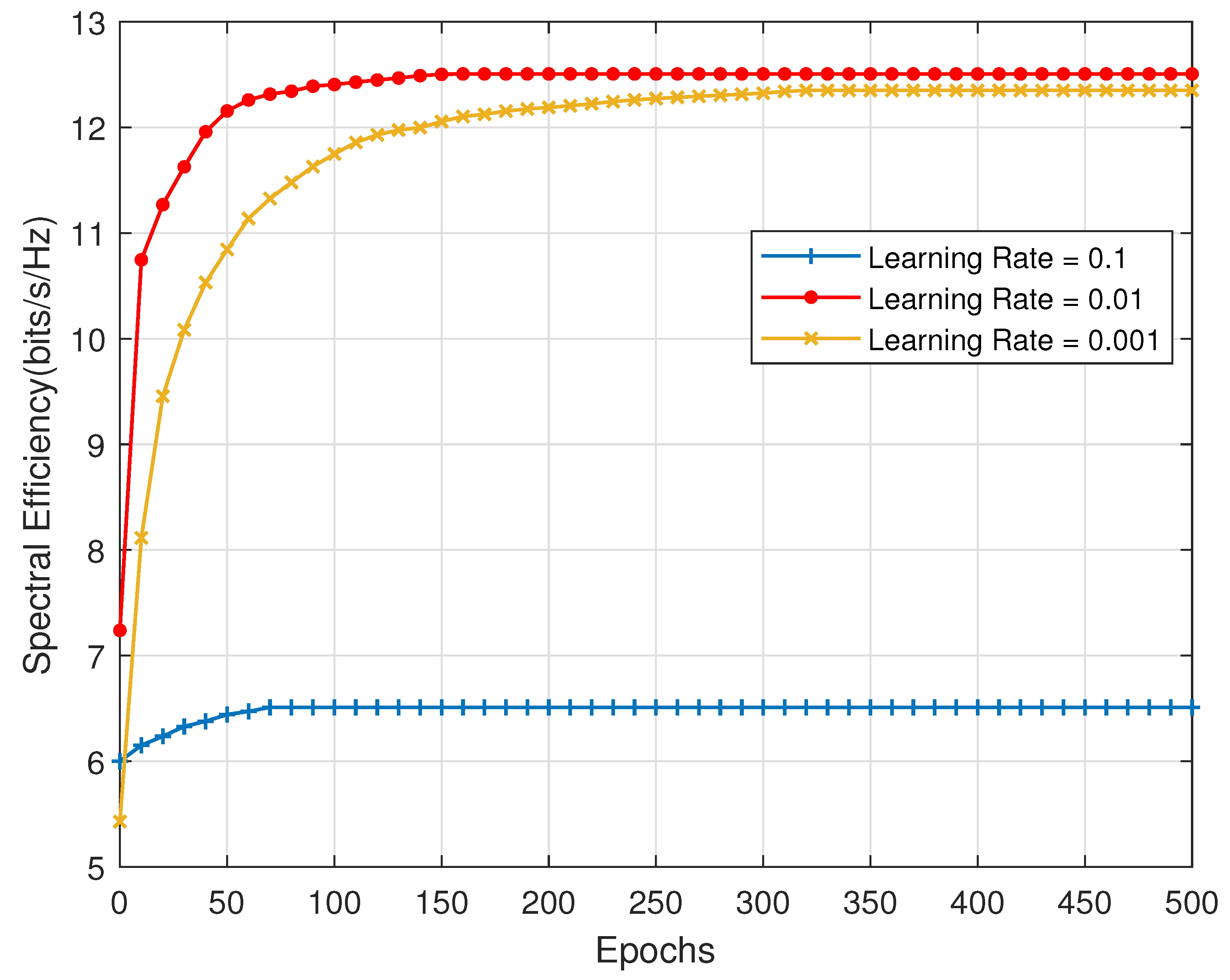
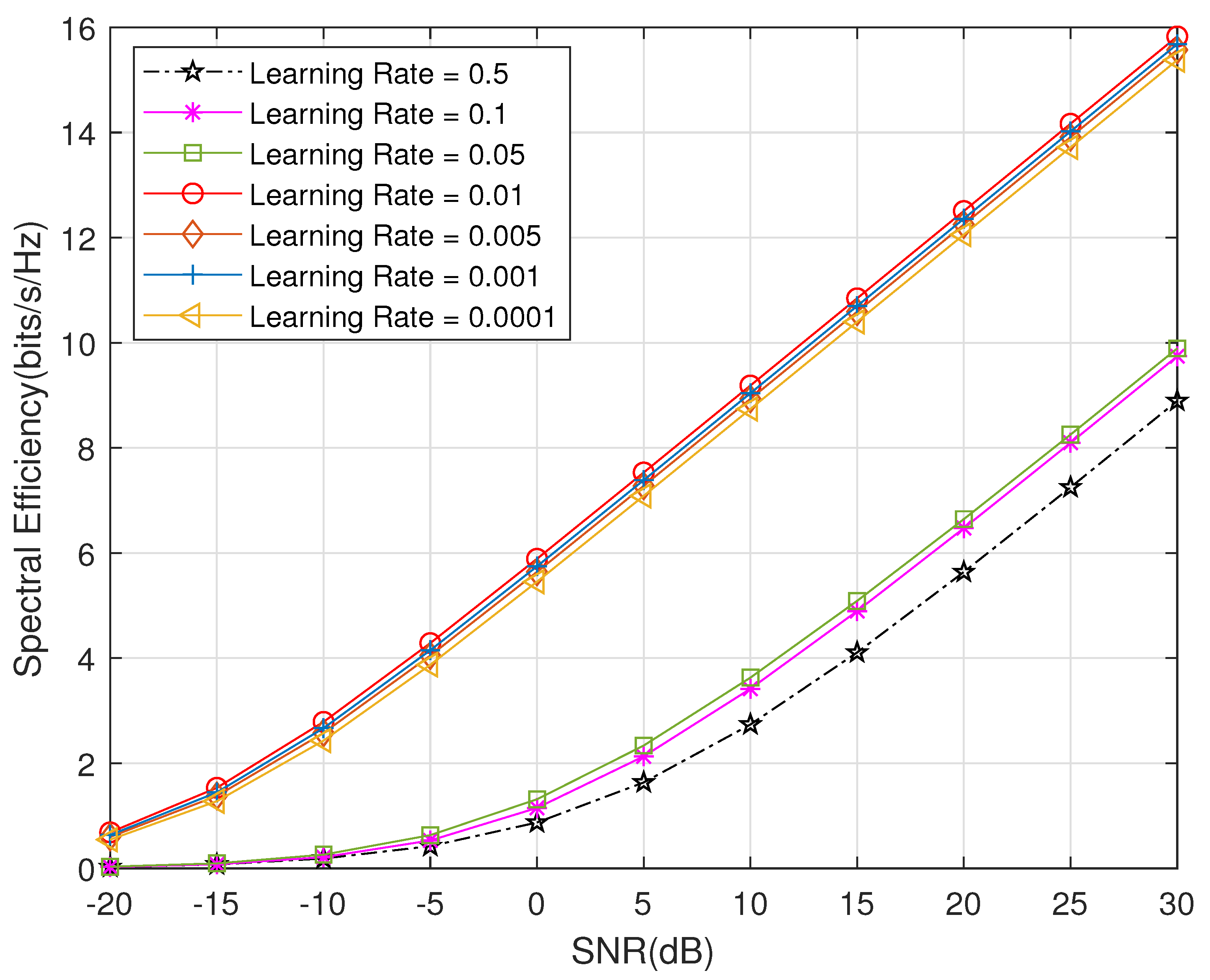
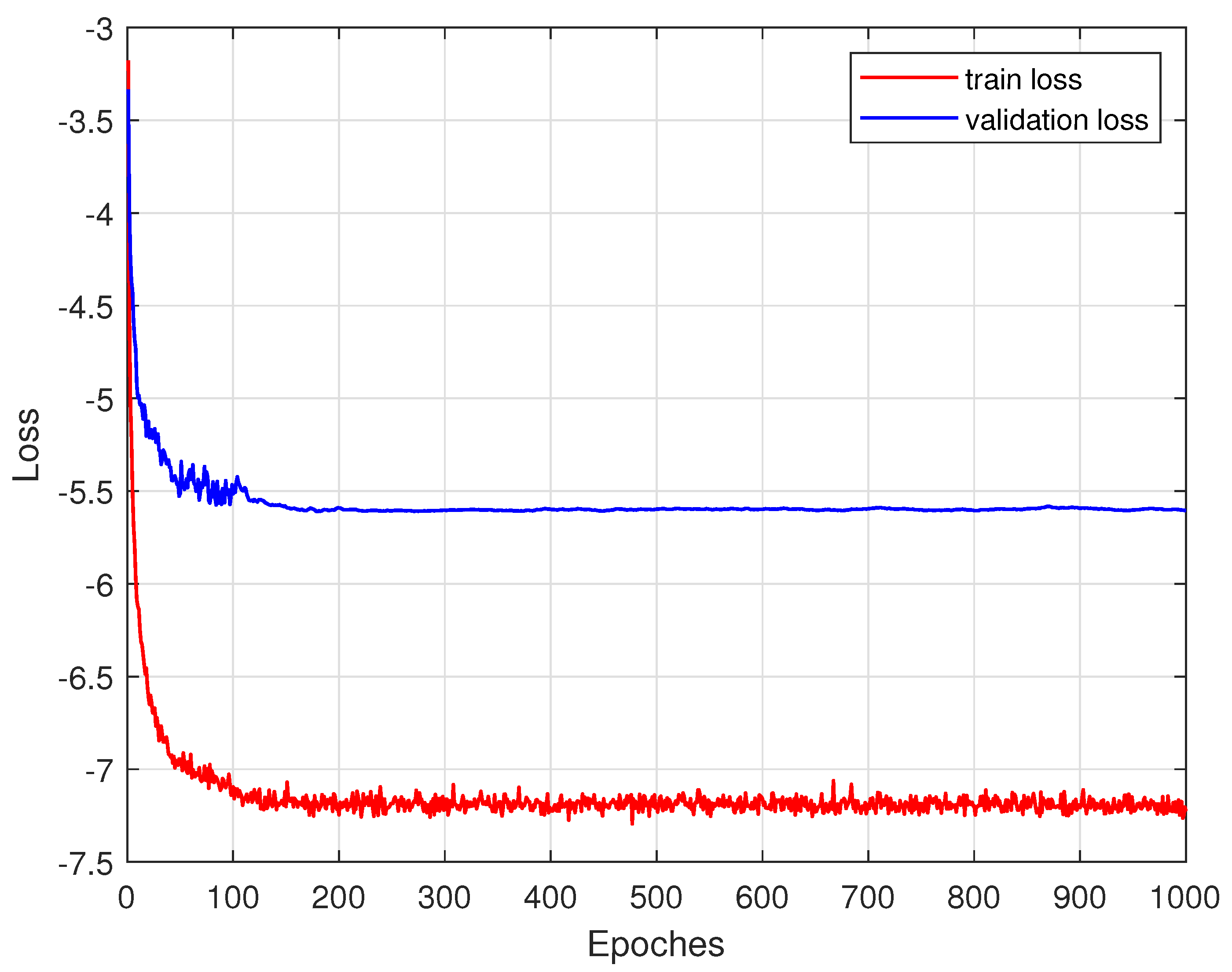
3.3. Training Strategy
3.4. Complexity Analysis
4. Simulation Results
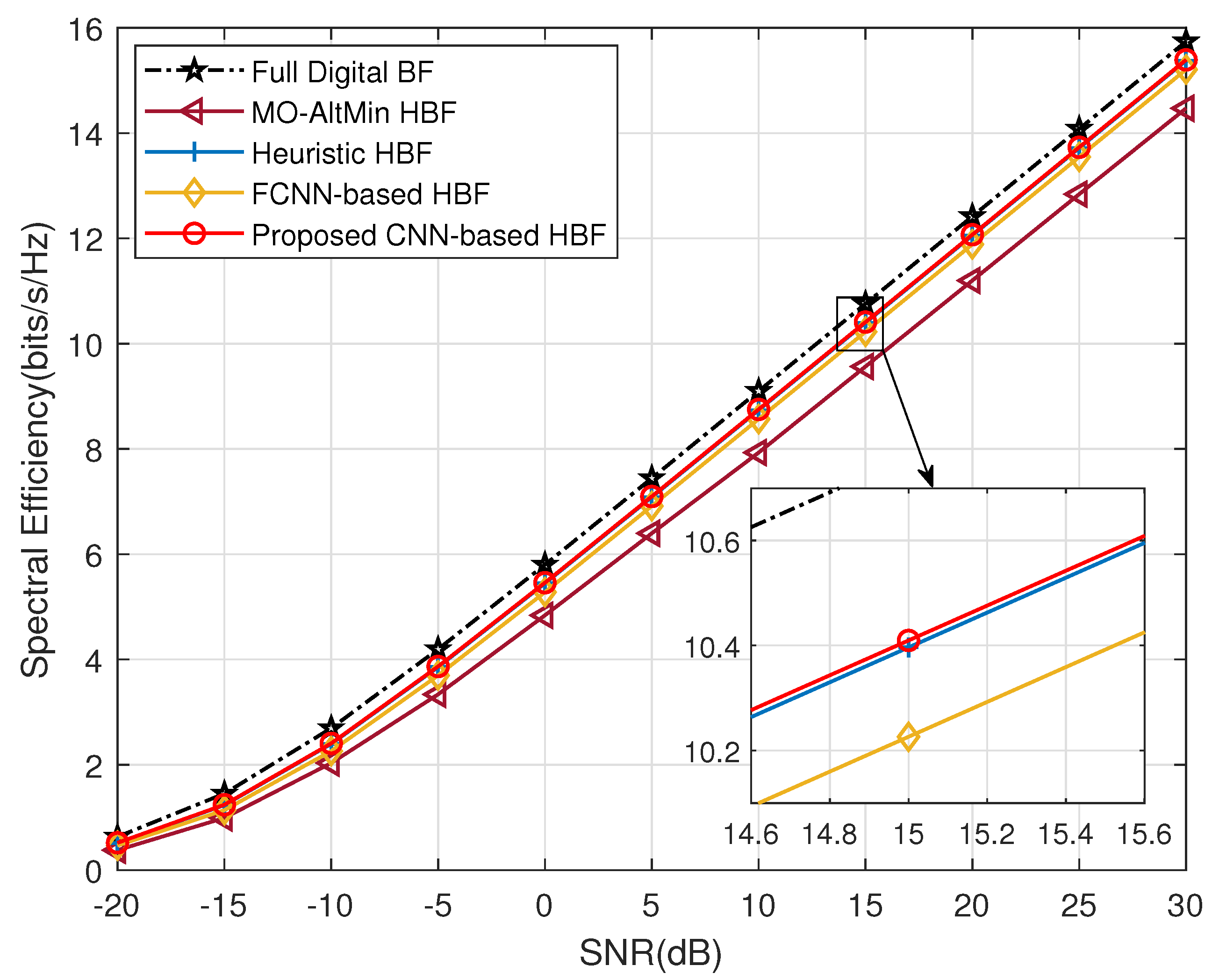
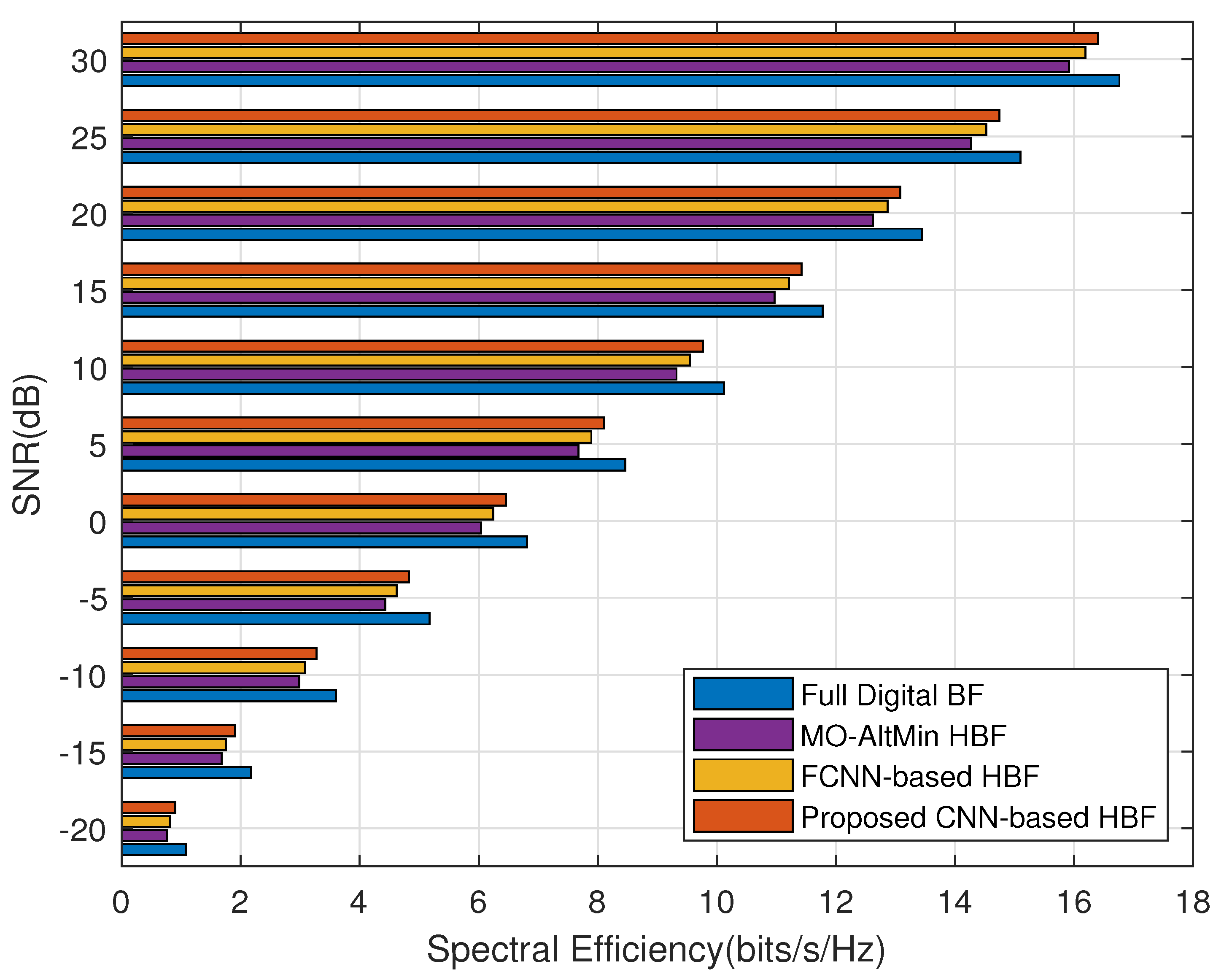
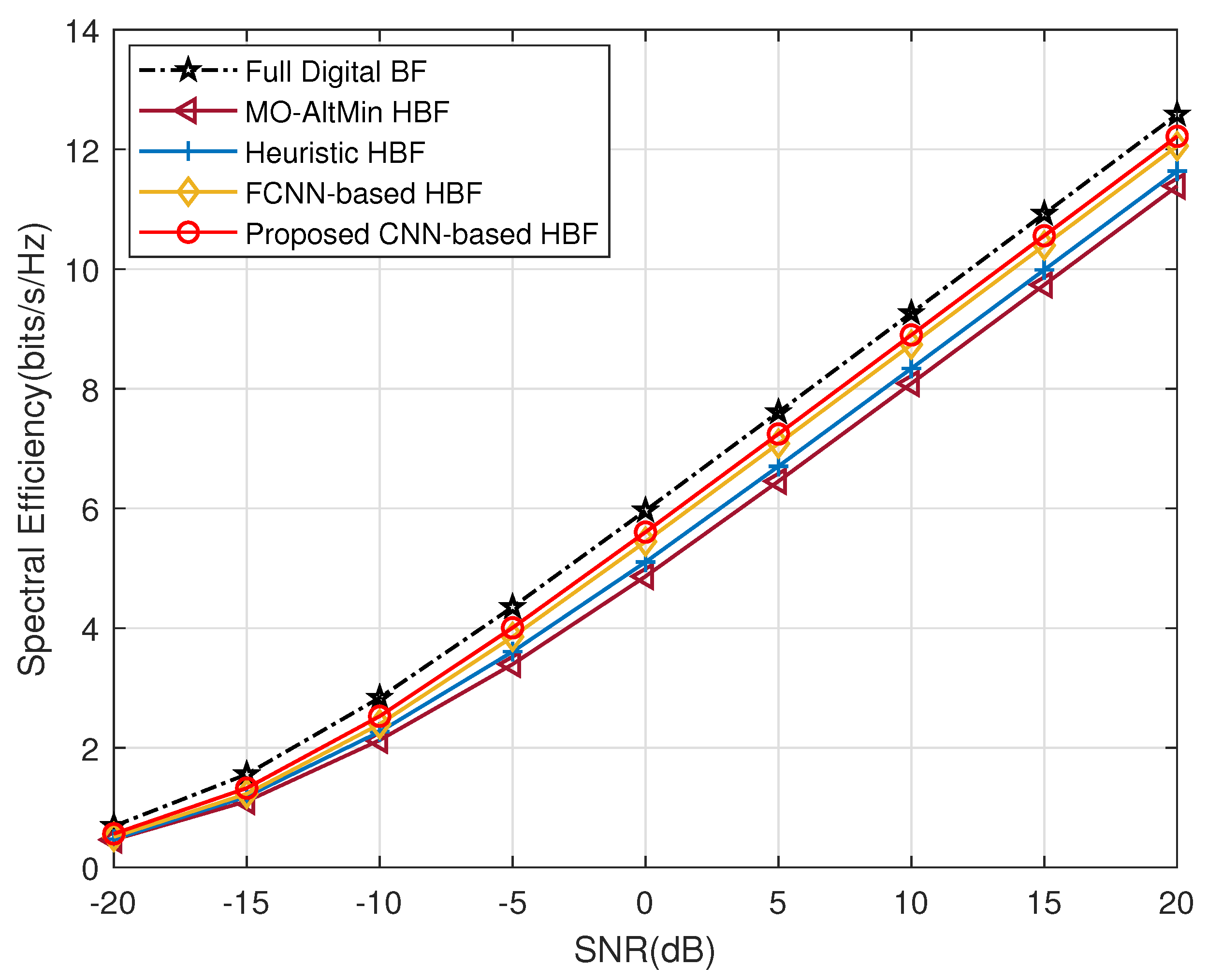
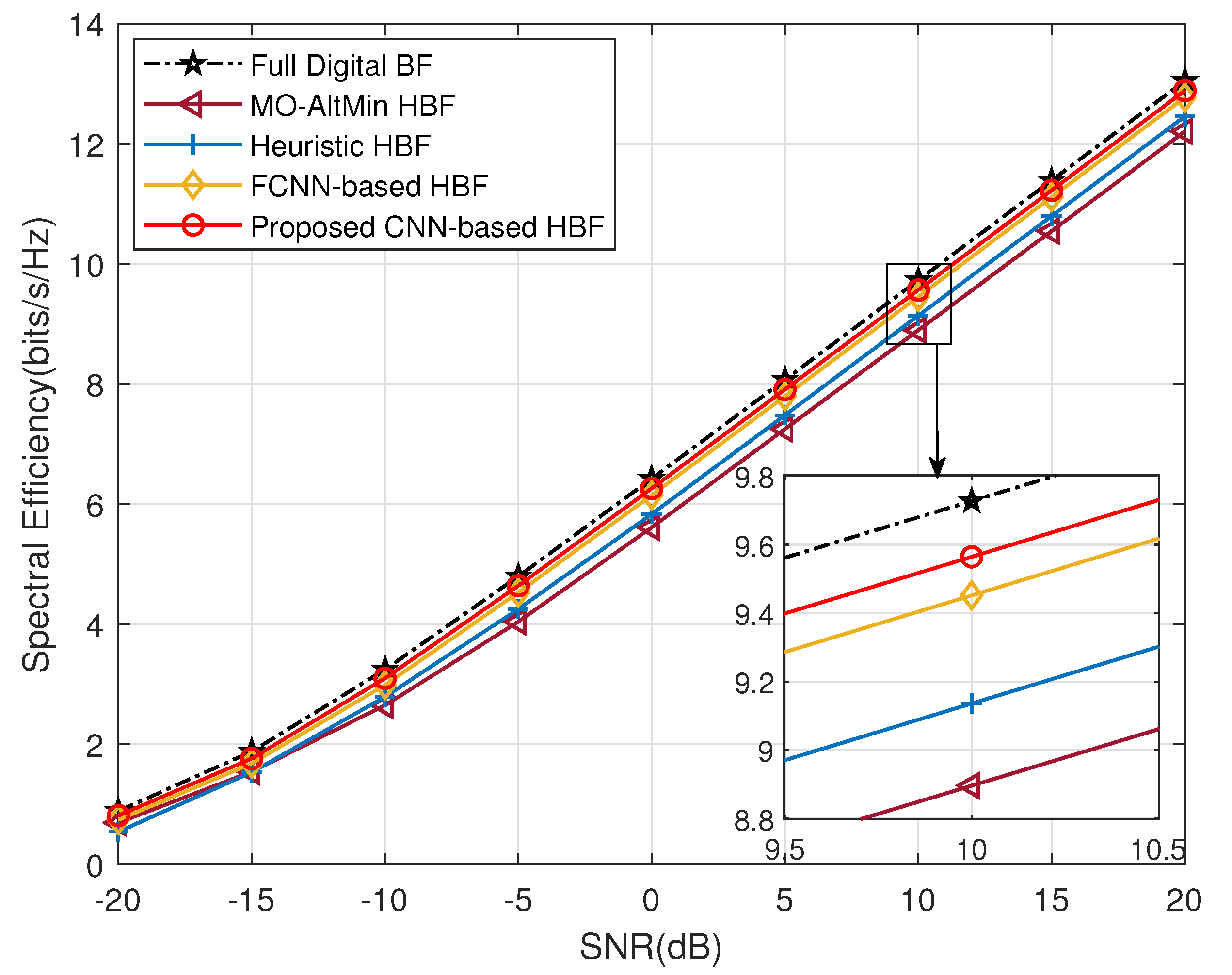
- Full digital beamforming algorithm: This algorithm (labeled with ’Full Digital BF’) is a digital beamforming technique based on singular value decomposition (SVD). Although the optimal performance can be achieved theoretically, it will face the issues of high overhead, high implementation complexity and high power consumption in large-scale antenna arrays.
- Traditional HBF algorithm [12]: This scheme (labeled with ’MO-AltMin HBF’) approximates the HBF optimization problem as a matrix factorization problem with alternate optimization of analog and digital beamforming. However, it imposes a performance loss and fails to obtain optimal results.
- Traditional HBF algorithm [13]: This method (labeled with ’Heuristic HBF’) is an element-based heuristic HBF iterative algorithm that optimizes the beamforming matrix while taking the performance metric as the optimization objective directly. Yet, it requires numerous iterative operations with high computational complexity and long execution time.
- FCNN-based HBF algorithm [19]: This scheme employs DL network architecture to optimize HBF, but its use of multiple fully connected layers suffers from the issue of excessive weight parameters, which may raise the computational complexity.
4.1. Channel Model
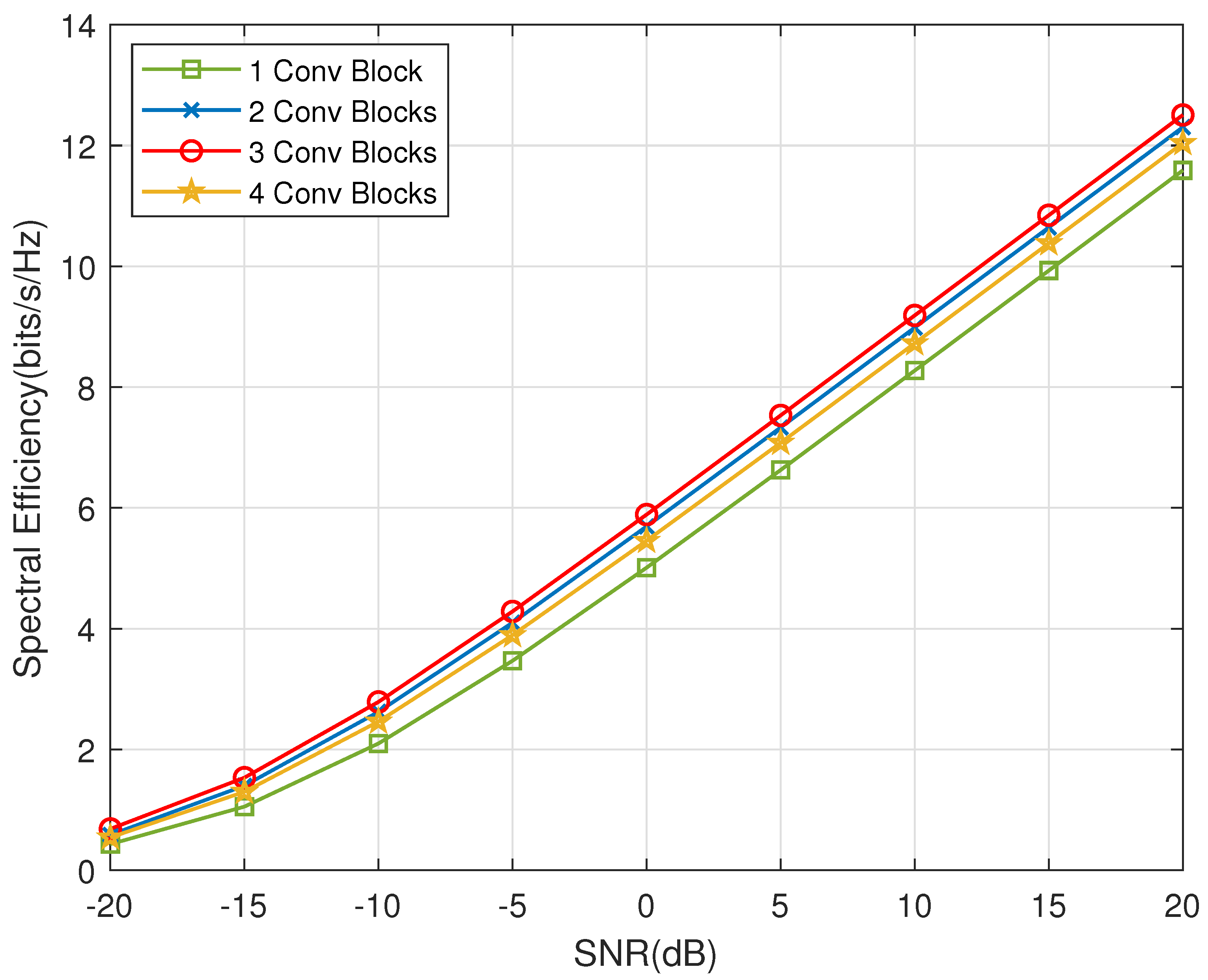
4.2. Generalization for Multiple CSIs
4.3. Specific Solution for an Individual CSI
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Andrews, J.G.; Buzzi, S.; Choi, W.; Hanly, S.V.; Lozano, A.; Soong, A.C.; Zhang, J.C. What will 5G be? IEEE J. Sel. Areas Commun. 2014, 32, 1065–1082. [Google Scholar] [CrossRef]
- Niu, Y.; Li, Y.; Jin, D.; Su, L.; Vasilakos, A.V. A survey of millimeter wave communications (mmWave) for 5G: Opportunities and challenges. Wirel. Netw. 2015, 21, 2657–2676. [Google Scholar] [CrossRef]
- Hong, S.H.; Park, J.; Kim, S.J.; Choi, J. Hybrid beamforming for intelligent reflecting surface aided millimeter wave MIMO systems. IEEE Trans. Wirel. Commun. 2022. [Google Scholar] [CrossRef]
- Wiesel, A.; Eldar, Y.C.; Shamai, S. Zero-forcing precoding and generalized inverses. IEEE Trans. Signal Process. 2008, 56, 4409–4418. [Google Scholar] [CrossRef] [Green Version]
- Cui, W.; Dong, A.; Cao, Y.; Zhang, C.; Yu, J.; Li, S. Deep learning based MIMO transmission with precoding and radio transformer networks. Procedia Comput. Sci. 2021, 187, 396–401. [Google Scholar] [CrossRef]
- Zhang, T.; Yu, J.; Dong, A.; Qiu, J. Deep learning-based transceiver design for multi-user MIMO systems. Internet Things 2022, 19, 100512. [Google Scholar] [CrossRef]
- Molisch, A.F.; Ratnam, V.V.; Han, S.; Li, Z.; Nguyen, S.L.H.; Li, L.; Haneda, K. Hybrid beamforming for massive MIMO: A survey. IEEE Commun. Mag. 2017, 55, 134–141. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Molisch, A.F.; Kung, S.Y. Variable-phase-shift-based RF-baseband codesign for MIMO antenna selection. IEEE Trans. Signal Process. 2005, 53, 4091–4103. [Google Scholar] [CrossRef]
- Mo, J.; Alkhateeb, A.; Abu-Surra, S.; Heath, R.W. Hybrid architectures with few-bit ADC receivers: Achievable rates and energy-rate tradeoffs. IEEE Trans. Wirel. Commun. 2017, 16, 2274–2287. [Google Scholar] [CrossRef]
- El Ayach, O.; Rajagopal, S.; Abu-Surra, S.; Pi, Z.; Heath, R.W. Spatially sparse precoding in millimeter wave MIMO systems. IEEE Trans. Wirel. Commun. 2014, 13, 1499–1513. [Google Scholar] [CrossRef] [Green Version]
- Hung, W.L.; Chen, C.H.; Liao, C.C.; Tsai, C.R.; Wu, A.Y.A. Low-complexity hybrid precoding algorithm based on orthogonal beamforming codebook. In Proceedings of the 2015 IEEE Workshop on Signal Processing Systems (SiPS), Hangzhou, China, 14–16 October 2015; pp. 1–5. [Google Scholar]
- Yu, X.; Shen, J.C.; Zhang, J.; Letaief, K.B. Alternating minimization algorithms for hybrid precoding in millimeter wave MIMO systems. IEEE J. Sel. Top. Signal Process. 2016, 10, 485–500. [Google Scholar] [CrossRef] [Green Version]
- Sohrabi, F.; Yu, W. Hybrid digital and analog beamforming design for large-scale antenna arrays. IEEE J. Sel. Top. Signal Process. 2016, 10, 501–513. [Google Scholar] [CrossRef] [Green Version]
- Ren, Y.; Wang, Y.; Qi, C.; Liu, Y. Multiple-beam selection with limited feedback for hybrid beamforming in massive MIMO systems. IEEE Access 2017, 5, 13327–13335. [Google Scholar] [CrossRef]
- Alkhateeb, A.; Alex, S.; Varkey, P.; Li, Y.; Qu, Q.; Tujkovic, D. Deep learning coordinated beamforming for highly-mobile millimeter wave systems. IEEE Access 2018, 6, 37328–37348. [Google Scholar] [CrossRef]
- Huang, H.; Song, Y.; Yang, J.; Gui, G.; Adachi, F. Deep-learning-based millimeter-wave massive MIMO for hybrid precoding. IEEE Trans. Veh. Technol. 2019, 68, 3027–3032. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Alkhateeb, A. Deep learning for direct hybrid precoding in millimeter wave massive MIMO systems. In Proceedings of the 2019 53rd Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 3–6 November 2019; pp. 800–805. [Google Scholar]
- Xia, W.; Zheng, G.; Zhu, Y.; Zhang, J.; Wang, J.; Petropulu, A.P. A deep learning framework for optimization of MISO downlink beamforming. IEEE Trans. Commun. 2020, 68, 1866–1880. [Google Scholar] [CrossRef]
- Lin, T.; Zhu, Y. Beamforming design for large-scale antenna arrays using deep learning. IEEE Wirel. Commun. Lett. 2020, 9, 103–107. [Google Scholar] [CrossRef] [Green Version]
- Attiah, K.M.; Sohrabi, F.; Yu, W. Deep learning approach to channel sensing and hybrid precoding for TDD massive MIMO systems. In Proceedings of the 2020 IEEE Globecom Workshops (GC Wkshps), Taipei, Taiwan, 7–11 December 2020; pp. 1–6. [Google Scholar]
- Song, H.; Zhang, M.; Gao, J.; Zhong, C. Unsupervised learning-based joint active and passive beamforming design for reconfigurable intelligent surfaces aided wireless networks. IEEE Commun. Lett. 2021, 25, 892–896. [Google Scholar] [CrossRef]
- Kuo, C.H.; Chang, H.Y.; Chang, R.Y.; Chung, W.H. Unsupervised Learning Based Hybrid Beamforming with Low-Resolution Phase Shifters for MU-MIMO Systems. arXiv 2022, arXiv:2202.01946. [Google Scholar]
- Alkhateeb, A.; El Ayach, O.; Leus, G.; Heath, R.W. Channel estimation and hybrid precoding for millimeter wave cellular systems. IEEE J. Sel. Top. Signal Process. 2014, 8, 831–846. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Activation Function | Number of Parameters (When ) | |
|---|---|---|---|
| Input | - | 0 | |
| Conv Block 1 | ELU | 176 | |
| Conv Block 2 | ELU | 424 | |
| Conv Block 3 | ELU | 116 | |
| Flatten | - | 0 | |
| Dense | Sigmoid | 14,912 | |
| Lambda-1 | - | 0 |
| HBF Scheme | Number of Parameters | Number of FLOPs |
|---|---|---|
| Proposed CNN-based | 16,556 | 0.09 million |
| FCNN-based [19] | 75,720 | 0.15 million |
| Traditional | - | 0.26 million |
| HBF Scheme | Execution Time |
|---|---|
| Proposed CNN-based | 0.3223 s |
| FCNN-based [19] | 0.3338 s |
| Traditional [12] | 11.9553 s |
| Traditional [13] | 9.5333 s |
| - | Rayleigh Fading Channel | Geometric mmWave Channel |
|---|---|---|
| Model generation | ||
| Properties |
|
|
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, T.; Dong, A.; Zhang, C.; Yu, J.; Qiu, J.; Li, S.; Zhou, Y. Hybrid Beamforming for MISO System via Convolutional Neural Network. Electronics 2022, 11, 2213. https://doi.org/10.3390/electronics11142213
Zhang T, Dong A, Zhang C, Yu J, Qiu J, Li S, Zhou Y. Hybrid Beamforming for MISO System via Convolutional Neural Network. Electronics. 2022; 11(14):2213. https://doi.org/10.3390/electronics11142213
Chicago/Turabian StyleZhang, Teng, Anming Dong, Chuanting Zhang, Jiguo Yu, Jing Qiu, Sufang Li, and You Zhou. 2022. "Hybrid Beamforming for MISO System via Convolutional Neural Network" Electronics 11, no. 14: 2213. https://doi.org/10.3390/electronics11142213
APA StyleZhang, T., Dong, A., Zhang, C., Yu, J., Qiu, J., Li, S., & Zhou, Y. (2022). Hybrid Beamforming for MISO System via Convolutional Neural Network. Electronics, 11(14), 2213. https://doi.org/10.3390/electronics11142213