1. Introduction
With the popularity of mobile Internet and the rise of the Internet of things (IoT) and industrial Internet, various mobile applications with low latency requirements have appeared, such as augmented reality, intelligent vision applications, online games, etc. However, achieving low-latency mobility support in existing IP networks has been a challenge, because IP addresses couple the identifier and locator of network entities. Thus, the mobile entity cannot naturally keep a unique identifier when attaching to different access points in the network.
Information-Centric Networking (ICN) [
1] is a brand-new network architecture. The key feature of ICN is that it decouples the identifier and locator of the network entities, providing a natural advantage in supporting mobility. To gain the advantage of ICN to support mobility, an urgent challenge is the problem of practical implementation with performance optimization [
2]. Currently, although numerous protocols and architectures have been proposed to support ICN mobility [
2,
3], few of them have been implemented in commercial networks. ICN can be essentially classified into two kinds according to the implementation method [
4]. One of the ICN solutions adopts clean-slate implementation, such as content-centric networking (CCN) [
5], named data networking (NDN) [
6], and publish–subscribe Internet technology (PURSUIT) [
7]. However, high cost limits the implementation of the clean-slate ICN solutions. Therefore, this paper focuses on ICN solutions that can coexist with existing IP networks to achieve incremental implementation, such as MobilityFirst [
8] and SEANet [
9]. These ICN solutions decouple name resolution and data routing. The unique identifier (ID) is used for identifying a network entity, and network addresses (NAs) are used for forwarding packets. After the network entity moves, the ID of the network entity is invariable, while the NA of the network entity is variable. The name resolution system (NRS) dramatically maintains the mapping between the IDs and NAs of the mobile entities. The problem that the ICN mobility solves is how packets can reach the moving network entity. In order to deliver the packets to the moving entity, network devices on packets’ forwarding paths should have the capability of quickly perceiving the mobile event and modifying the packet’s forwarding paths. In order to reduce the packet loss and handover latency due to mobility, intelligent implementation methods should be designed to enable network devices to support ICN mobility with performance optimization.
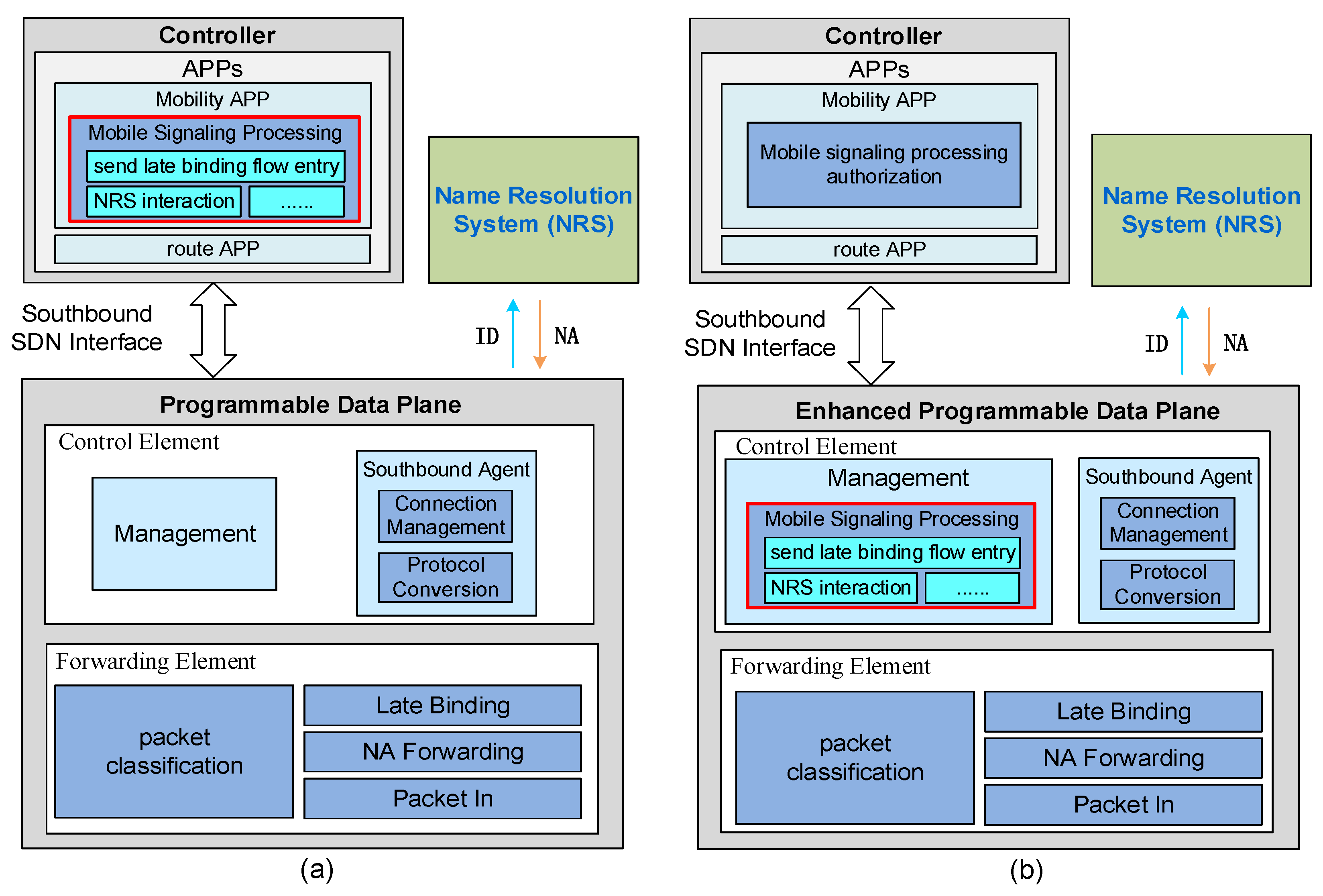
However, traditional network architectures couple the control plane and data plane of the network. Therefore, it is difficult to manage today’s networks, and is hard to deploy new protocols without updating the network devices. As shown in
Figure 1a, the network device can be logically divided into the device control plane and device data plane [
10]. The device control plane is responsible for managing the device and formulating the packets’ forwarding policies, while the device data plane is responsible for executing the packet-forwarding policies set by the device control plane. Software-defined networking (SDN) [
11] is proposed to improve the flexibility and programmability of the network, and to enable the continuous evolution of network architecture. As shown in
Figure 1b, SDN decouples the network control plane and data plane, and the network control plane becomes an independent, logically centralized controller. Some functions of the device control plane are separated and transferred to the controller. However, the device control plane does not disappear. The device control plane is responsible for establishing a stable connection with the controller, completing the protocol conversion between the controller and the data plane, and managing the device [
10]. The controller communicates with the data plane through the southbound interface protocol. Protocol-oblivious forwarding (POF) [
12] and programming protocol-independent packet processors (P4) [
13] are the mainstream protocol-independent southbound interface protocols. P4 implements the protocol-oblivious forwarding by designing a high-level language for programming protocol-independent packet processors. POF provides the full programmability of the network through defining a set of protocol-independent instructions. The protocol-oblivious character enables POF to support various new network protocols. POF makes the implementation of the ICN mobility possible.
When supporting ICN mobility, the centralized controller replaces the device control plane to process mobile signaling compared with the traditional network architecture (this paper defines packets exchanged between terminal devices as data packets, while other packets are defined as signaling packets). The controller initiates a resolution query to obtain the latest mapping between the ID and NA of the mobile entity from the NRS, and sends the mapping to the data plane in the form of flow entry. Later, the data plane can modify the destination NA of the packet sent to the mobile entity according to the flow entry, and then the packet is forwarded according to the new NA, and the forwarding path of the packet is be modified. The above process is called late binding. The concept of late binding [
8] is rebinding the ID with a new NA while a packet is in transit.
However, it is difficult for the controller to quickly process mobile signaling, due to the centralized control characteristics of SDN. The logically centralized controller introduces scalability challenges, as the controller is unable to quickly process events from large networks [
14]. Moreover, [
15,
16] show that the latency between the control plane and the data plane cannot be ignored, and this latency can be a major concern for the performance. Therefore, we pull back (or offload) the mobile signaling processing functions from the controller to the control element of the data plane (in the following description, we refer to the device control plane as the control element and the device data plane as the forwarding element). In order to follow the idea of centralized control of the controller in SDN, the controller authorizes the data plane’s control element to process the mobile signaling by loading a programmable rule table to the control element. Both the control element and the forwarding element of the data plane are programmable. The forwarding element’s programmability is ensured by the controller loading flow tables to it, while the control element’s programmability is ensured by the controller loading rule tables to it. The control element intercepts mobile signaling, matches the predefined rule tables, and executes a series of application logic actions. Thus, network devices can quickly process the mobile signaling locally, obtain the latest mapping between the ID and NA of the mobile entity, and modify packets’ destination NA to the new NA, thereby modifying the packets’ forwarding path. This greatly reduces the packet loss and handover latency due to mobility.
The contributions of our work can be summarized in the following four points:
We propose an architecture consisting of enhanced programmable data plane supporting ICN mobility, where the data plane can locally process mobile signaling without interacting with the controller, bringing some performance gains.
We provide a theoretical analysis of latency overhead to compare the latency of the traditional programmable data plane and that of the proposed enhanced programmable data plane for processing mobile signaling, and to see how we should implement the offloaded control plane functions on the data plane to optimize the latency performance.
We propose an offloading mechanism for control plane functions, where the controller authorizes the data plane to process mobile signaling by loading a programmable rule table to data plane’s control element, and the control element intercepts the mobile signaling, matches the predefined rule table, and executes a series of application logic actions. The programmable rule table and the application logic actions make the offloaded control plane functions flexible and easy to implement on the data plane. In addition, we propose an improved SmartSplit algorithm to manage the rule table and speed up packets matching the rule table.
Based on Intel’s DPDK [
17], we implement the enhanced programmable data plane. Our experimental results prove that the proposed enhanced programmable data plane has a stronger ability to process mobile signaling and reduce latency.
The rest of this paper is organized as follows:
Section 2 introduces the related work on mobility support in ICN and offloading of control plane functions in SDN. In
Section 3, we provide a detailed description of the architectures of the traditional programmable data plane supporting ICN mobility and the proposed enhanced programmable data plane supporting ICN mobility. In addition, we offer a theoretical analysis of the latency overhead to compare the processing latency of mobile signaling when processed in each of the above two architectures, and to see how we should implement offloaded control plane functions on the data plane to optimize latency performance.
Section 4 introduces the control-plane-function offloading mechanism based on the rule table. In
Section 5, we evaluate the performance of our enhanced programmable data plane in terms of processing ability and latency. Finally, we summarize our results and conclusions in
Section 6.
3. Enhanced Programmable Data Plane Supporting ICN Mobility
Figure 2b shows the global view of the architecture of the enhanced programmable data plane supporting ICN mobility. The core idea of the architecture is that SDN is regarded as infrastructure and ICN mobility is supported by enhancing the function of the programmable data plane. The advantage of the enhanced programmable data plane in supporting ICN mobility is that the data plane can flexibly and locally process mobile signaling without interacting with the controller, optimizing the latency performance. In this section, firstly, we introduce the architecture of the traditional programmable data plane supporting ICN mobility that we aimed to enhance. Then, we introduce the architecture of the proposed enhanced programmable data plane, and how the enhanced programmable data plane supports ICN mobility. Finally, we provide a theoretical analysis of latency overhead to compare the latency of the traditional programmable data plane and the proposed enhanced programmable data plane for processing mobile signaling, and to see how we should implement offloaded control plane functions on the data plane to optimize the latency performance.
3.1. Architecture of the Traditional Programmable Data Plane Supporting ICN Mobility
Figure 2a shows the architecture of the traditional programmable data plane that we enhanced. The centralized controller is responsible for formulating policies based on the needs of applications, and then sends policies to the data plane in the form of flow entries. The data plane only forwards packets according to the flow entries. The controller connects with the data plane through the southbound SDN interface. The data plane consists of a control element (CE) and a forwarding element (FE). When supporting ICN mobility, the route APP in the controller is responsible for monitoring the network topology and network state, calculating the forwarding paths of the packets according to routing protocols, and sending the mapping between the NA and the data plane’s port to the data plane’s FE in the form of flow entry for routing packets according to the NA. The mobility APP is responsible for receiving mobile signaling from the data plane and executing corresponding mobile processing logic, such as interacting with the NRS to obtain the latest mapping between the ID and NA of the mobile entity, sending late-binding flow entries to the data plane to modify packets’ forwarding paths, etc. The CE in the data plane consists of two modules: a southbound agent, and a management module. The southbound agent ensures a stable connection with the upper controller. In addition, it finishes the protocol conversion between the controller and the data plane, such as encapsulating the packet as a packet_in message, which is sent to the controller, parsing the packet from the controller. The management module in the CE is responsible for managing the data plane’s resources (ports, cache, etc.) and configuration, initializing the data plane according to the configure file, etc. The FE in the programmable data plane is mainly responsible for identifying the packet, and then according to the corresponding packet classification result, the FE executes late binding on the packet, forwards the packet according to the NA, or sends the packet up to the controller.
As mentioned above, the mobile signaling is processed by the controller. When the destination NA of the packet is unreachable due to the movement of the network entity, the controller obtains the latest mapping between the ID and NA of the mobile entity from the NRS, and sends the mapping to the data plane’s FE in the form of late-binding flow entries to modify the packet’s forwarding path. However, it is difficult for the controller to quickly process mobile signaling, due to the centralized control characteristics of SDN. Especially in scenarios with large-scale mobile users, the processing pressure of the controller and the latency between the controller and the data plane are larger. Hence, we propose enhanced programmable data plane to locally process mobile signaling and optimize latency performance.
3.2. Architecture of the Enhanced Programmable Data Plane Supporting ICN Mobility
The architecture of the enhanced programmable data plane is shown in
Figure 2b. In this architecture, we revisit the labor of the SDN controller and data plane. By offloading some of the control plane functions to the data plane, this architecture makes the data plane more intelligent, and brings many benefits—especially for applications with low latency requirements. The controller offloads the mobile signaling processing function to the CE’s management module, and authorizes the CE to process the mobile signaling. Thus, the CE can interact with the NRS and send the late-binding flow entries to the data plane’s FE to modify the packet’s forwarding path.
When the destination NA of the packet is unreachable due to the movement of the network entity, the enhanced programmable data plane quickly and locally obtains the latest mapping between the ID and NA of the mobile entity, and sends the mapping to the FE in the form of late-binding flow entries. Subsequent packets whose destination is the mobile entity are identified by the FE, which rebinds the packet with a new NA and modifies its forwarding path.
3.3. Analysis of Latency Overhead
We compared and analyzed the latency of the two abovementioned architectures for processing the mobile signaling. In the architecture of the traditional programmable data plane, after the data plane receives the mobile signaling, the data plane’s FE sends the mobile signaling up to the CE. The southbound agent encapsulates the mobile signaling as a packet_in message and sends the mobile signaling to the controller. The controller then processes the mobile signaling. We assume that the processing result of the mobile signaling is to generate late-binding flow entries in the data plane’s FE. The controller sends the flow_mod message carrying the late-binding flow entry to the data plane, and the CE’s southbound agent parses the flow_mod message and continues to send the late-binding flow entry to the FE. Finally, the late-binding flow entry takes effect in the FE, and modifies the forwarding path of the packet sent to the mobile entity. In the architecture of the enhanced programmable data plane, the data plane’s FE sends the mobile signaling to the CE, whose management module intercepts and processes the mobile signaling. The mobile signaling is not encapsulated as a packet_in message and sent to the controller. We assume that the processing result of the mobile signaling is to generate late-binding flow entries in the data plane’s FE. The CE’s management module sends the late-binding flow entry to the FE through the southbound agent. The southbound agent does not need to parse the message from the management module—only to forward the message to the FE. Finally, the late-binding flow entry takes effect in the FE, and modifies the forwarding path of the packet sent to the mobile entity.
Figure 3 shows the detailed composition of the latency of the traditional programmable data plane and the enhanced programmable data plane for processing mobile signaling. The description of the symbols in
Figure 3 is shown in
Table 1.
As shown in
Figure 3a, the latency of the traditional programmable data plane for processing mobile signaling
is:
As shown in
Figure 3b, the latency of the enhanced programmable data plane for processing mobile signaling
is:
First, intuitively, from Formulae (1) and (2), we can see that is four items smaller than : , , , . Then, , of and , of are all generated by the FE’s operation. The FE runs on independent cores, and we do not make any changes to the FE. Therefore, we assume that is equal to , and is equal to . Finally, we analyze the remaining and . If is smaller than , considering the above analysis of the previous two points, will be smaller than . Therefore, we should reduce the latency of as much as possible, and when implementing the control plane functions, we should try to reduce the latency of the CE’s management module for processing mobile signaling.
The offloaded control plane functions are implemented based on the rule table. The data plane’s CE intercepts the mobile signaling, matches the rule table, and executes a series of application logic actions to process the mobile signaling, so we should design a fast lookup algorithm to manage the rule table to speed up packets matching the rule table. Hash lookup is famous for its fast lookup speed. If the rule table’s number of rules is small and the matching fields of the rules are all exact values, it is wise to use hash lookup to manage the rule table. However, if the number of rules is large and the match fields of the rules contain wildcards (*), the hash lookup is obviously not suitable for the above scenario, so in order to make a more scalable and usable rule table that can accommodate rules of different sizes and with wildcards (*), we can improve the SmartSplit algorithm to manage the rule table and speed up packets matching the rule table. The SmartSplit algorithm [
26] is nearly the fastest packet classification algorithm based on decision trees.
4. Control-Plane-Functions Offloading Mechanism Based on the Rule Table
In this section, we explain how to implement the offloaded control plane functions on the data plane. Firstly,
Section 4.1 introduces the overview of the control-plane-function offloading mechanism.
Section 4.2 introduces the programmable rule table and explains how the rule table implements the offloaded control plane functions. Finally, we propose an improved SmartSplit algorithm to manage the rule table and speed up packets matching the rule table in
Section 4.3.
4.1. Overview
Figure 4 shows the overview of the control-plane-function offloading mechanism based on the rule table. Firstly, we define the function of each module in the control-plane-function offloading mechanism.
Mobility APP: This is responsible for converting the offloaded mobile application into the rule table and sending the rule table to the data plane. The rule table is forwarded to the management module through the southbound agent in the data plane.
Southbound Agent: This is responsible for establishing a stable connection with the controller and processing messages from the controller and the CE’s management module. The messages from the controller include messages carrying the rule table, messages operating on the flow table of the data plane’s FE, and messages forwarding packets out of the data plane’s FE. The messages from the management module can be divided into two categories: one is the packet_in messages from the FE, and the other is the processing results of the rule executor interpreting and executing application logic actions in the rule table. The processing results include operating on the flow table of the data plane’s FE and forwarding packets out of the data plane’s FE.
Management: This is responsible for implementing the offloaded control plane functions based on the rule table. The rules in the rule table consist of fields and application logic actions. The fields can be from the field of the packet or the metadata, and each field can be an exact value or a range (including wildcards (*)). Rules with the same number and type of fields are placed in the same rule table. The application logic actions are used to implement the mobile application logic. The rule executor in the management module is responsible for interpreting and executing the application logic actions in the rule table, and sending the processing results to the southbound agent.
Next, we introduce the detailed process of the control-plane-function offloading mechanism.
After the data plane receives the mobile signaling, the data plane’s FE sends the mobile signaling to the controller, while the management module intercepts the mobile signaling and matches the rule table. If the mobile signaling matches the fields of the rules in the rule table, a series of application logic actions of the rule are interpreted and executed by the rule executor. The processing results of the rule executor may include forwarding packets out of the data plane’s FE, or operating on the flow table in the data plane’s FE. The rule executor sends the processing results to the southbound agent, and the southbound agent further completes the processing results, implementing the offloaded mobile application on the data plane. If the mobile signaling does not match the rule table, the management module sends the mobile signaling to the controller via the southbound agent. The mobile APP in the controller receives the mobile signaling and authorizes the CE to process the mobile signaling by converting the offloaded mobile application logic into a rule table (which may contain multiple rules, including rules for processing the mobile signaling) and sending the rule table to data plane. The rule table is forwarded to the CE’s management module through the southbound agent. Then, the rule executor interprets and executes a series of application logic actions of the rule for processing the mobile signaling, and sends the processing result to the southbound agent. The southbound agent further completes the processing results, implementing the offloaded mobile application on the data plane.
4.2. Programmable Rule Table
4.2.1. OFPT_RULE_TABLE_MOD Message
The data plane’s FE contains one or more flow tables, and each flow table contains many flow entries. The controller sends an OFPT_TABLE_MOD message to the data plane to generate or update the flow table, thereby ensuring network programmability. Following the same idea as the network programmability in SDN, we designed an OFPT_RULE_TABLE_MOD message to generate or update the rule table in the data plane’s CE. The controller sends the OFPT_RULE_TABLE_MOD message to the data plane, and the message is forwarded to the CE’s management module through the southbound agent to add, modify, and delete the rule table. The flow table in the FE is used to forward packets, while the rule table in the CE is used to process the mobile signaling, thereby implementing the offloaded mobile application logic.
The composition of the OFPT_RULE_TABLE_MOD message is shown in
Table 2. The message contains the header of a standard OpenFlow/POF message. The command field can be one of the following: add, modify, or delete. The table index chooses the rule table to which the change should be applied. We use the data type field to indicate that the following data are changes to a rule table or rule. The controller can flexibly generate and update the rule table using the OFPT_RULE_TABLE_MOD message.
4.2.2. Composition of the Rule Table
Rules in the rule table are composed of fields and application logic actions. The fields may be from packets or metadata, and the fields may be exact values or ranges (including wildcards (*)). The rule is triggered by the receipt of a packet or metadata whose fields match a pre-specified rule, and then a series of application logic actions of the rule are executed. The application logic actions make the offloaded control plane functions easy to implement on the data plane. The application logic actions contain flow processing actions, packet processing actions, and logic processing actions. The flow processing actions enable the CE to operate on flow tables or flow entries in the FE, such as adding, deleting, or looking up the flow entry. The packet processing actions enable the CE to add, delete, or modify the packet, construct a packet, adjust the offset of the packet, calculate the packet’s checksum, send the packet out from the data plane’s port, or drop the packet. The logic processing actions enable the CE to support some basic processing logic, such as adding, subtracting, shifting left, shifting right, or comparing.
We offload the mobile signaling processing function from the controller to the data plane’s management module, so that the data plane can process mobile signaling locally and execute the corresponding mobile application logic. For example, the data plane’s CE can interact with the NRS to obtain the latest ID and NA mapping of the mobile entity. In the above process, the data plane needs to send a resolution query message to the NRS, and the NRS responds with the resolution ACK message carrying the latest ID and NA mapping of the mobile entity to the data plane. Therefore, the management module on the data plane should have the ability to construct and forward the resolution query message. In the above application logic actions, the packet processing actions can carry out the functions of constructing and forwarding the resolution query message. In addition, the data plane’s CE can send late-binding flow entries to the data plane’s FE, thereby modifying the forwarding path of the packets. Therefore, the management module on the data plane should have the ability to operate on the flow tables and flow table entries of the FE. In the above application logic actions, the flow processing actions can implement the functions of operating on the flow tables and flow table entries of the data plane’s FE.
4.2.3. Practical Example of a Rule Table
In this section, we use a concrete example to show how the rule table implements the mobility-related control plane functions.
Firstly, for a better introduction, we assume a mobile scenario, as shown in
Figure 5. The data producer continuously sends data packets to the data consumer. Packets carry both NA1 and ID1 of the consumer (①). The consumer moves away from the original switch S0 where it was originally connected (②). The external interface, such as an access point (AP) or base station, sends a mobile event message carrying the ID1 of the consumer to S0 to enable the network to perceive the mobile event (③). S0 initiates a resolution query, and sends a resolution query message to the NRS to obtain the latest mapping between the ID and NA of the consumer (ID1-NA2) (④). The NRS responds with the resolution ACK message carrying the latest mapping between the ID and NA (ID1-NA2) to S0 (⑤). After S0 receives the resolution ACK message, it generates late-binding flow entry to modify the forwarding path of the data packets sent to the consumer (⑥). Eventually, the new path of the packets becomes producer–S3–S0–S4–consumer. In the above mobile scene, the mobile event message, the resolution query message, and the resolution ACK message are all mobile signaling. The data plane’s CE processes the mobile event message and resolution ACK message based on the rule table, while the resolution query message is the result of the CE processing the mobile event message.
The mobile scenario described above is consumer mobility. However, the enhanced programmable switch proposed in this paper does not differentiate between the consumer and producer mobility when supporting ICN mobility. The specific reasons for this are described below. This paper focuses on ICN solutions that can coexist with existing IP networks to achieve incremental implementation, such as MobilityFirst [
8] and SEANet [
9]. These ICN solutions decouple name resolution and data routing. The unique identifier (ID) is used for identifying network entities, and network addresses (NAs) are used for forwarding the packets. After the network entity moves, the ID of the network entity is invariable, while the NA of the network entity is variable. The name resolution system (NRS) dramatically maintains the mapping between the IDs and NAs of the mobile entities. The problem that the ICN mobility solves is how the packet can reach the moving network entity. In order to deliver the packet to the mobile entity, network devices on the packet’s forwarding path should have the ability to quickly modify the packet’s forwarding path. The mobile entity mentioned above can be either the consumer or the producer. If the mobile entity is the consumer, the network device (switch) needs to modify the forwarding path of the data packets sent by the producer to the consumer. If the mobile entity is the producer, the network device (switch) needs to modify the forwarding path of the data request packets sent by the consumer to the producer. In other words, the proposed enhanced programmable switch does not differentiate between the producer and the consumer when supporting ICN mobility.
Next, we introduce the rule table for processing the mobile event message and resolution ACK message in the CE’s management module. We assume that the mobile event message and the resolution ACK message are both UDP packets, and the switch recognizes the mobile event message and the resolution ACK message based on the source port and the destination port of the packet’s UDP header. Therefore, the rule for processing the mobile event message and the rule for processing the resolution ACK message can be placed in the same rule table. We define the rule table as a mobile signaling processing rule table. The mobile signaling processing rule table is shown in
Table 3, and includes two rules: a mobile event message processing rule, and a resolution ACK message processing rule. The fields of the mobile signaling processing rule table are the UDP header’s source port and destination port. The mobile event message processing rule is used to match the mobile event message and initiate a resolution query to obtain the latest mapping between the ID and NA of the mobile entity from the NRS. The fields of the rule are source port 1 and destination port 1. After the mobile event message matches the rule, a series of application logic actions are executed. The first action is to generate a resolution query packet template, and then a sequence of set_field (src, dst) actions are executed to fill the corresponding fields of the constructed resolution query packet. For example, the destination NA of the constructed packet should be set as the NA of the NRS. After the packet is constructed, the last action is to send the constructed packet out of the original switch S0 in the form of a packet_out message.
The resolution ACK message processing rule is used to match the resolution ACK message returned by the NRS and add a late-binding flow entry in the switch’s FE. The fields of the rule are source port 2 and destination port 2. After the resolution ACK message matches the rule, the application logic action in the rule is executed, and a late-binding flow entry is added to the switch’s FE to modify the forwarding path of the packets sent to the mobile entity.
Finally, we introduce the generation and use of the mobile signaling processing rule table in the mobile scenario depicted in
Figure 6. After the consumer moves, the edge switch S0 receives the mobile event message. S0 sends the mobile event message to the controller, while S0’s management module intercepts the mobile event message and matches the rule table. Since there is no rule table or rule for processing the mobile event message in the management module, the mobile event message does not match the rule table. S0 continues to send the mobile event message to the controller. After the controller receives the mobile event message, the mobility APP in the controller converts the mobile application logic into the rule table (mobile signaling processing rule table). As described above, the mobile signaling processing rule table contains two rules: a mobile event message processing rule, and a resolution ACK message processing rule. Next, the controller sends the mobile signaling processing rule table to switch S0, and the mobile signaling processing rule table is forwarded to S0’s management module through S0’s southbound agent. The rule executor interprets and executes a series of application logic actions of the mobile event message processing rule, constructing a resolution query message and sending the message out of S0. The resolution query message reaches the NRS, which responds by sending a resolution ACK message to S0. After receiving the resolution ACK message, S0 sends the message to the controller, while S0’s management module intercepts the resolution ACK message and matches the rule table. Since the resolution ACK message processing rule already exists in the mobile signaling processing rule table in the management module, the resolution ACK message matches the resolution ACK message processing rule. The rule executor interprets and executes the application logic action of the resolution ACK message processing rule, and generates a late-binding flow entry in S0’s FE, thereby modifying the forwarding path of the packets sent to the mobile entity.
4.2.4. Overhead of Sending Rule Tables
In SDN, there are two ways for the controller to respond to packets that do not match the flow entry: positive or passive. The positive way means that the controller sends flow entries to the switch’s FE in advance, while the passive way means that the controller sends flow entries to the switch’s FE only when the controller receives packets from the switch. Although the passive way has poor latency performance when processing the first packet of the flow, it greatly saves the flow table resources of the switch’s FE. Similarly, the way that the controller sends the rule table to the CE can also be divided into positive and passive ways. In the positive way, the controller sends rule tables to all switches after the controller establishes connections with the switches, which may cause a waste of memory resources of a large number of switches that do not need to process mobile applications. Therefore, this paper adopts the passive way, where only when the mobile host moves from the network covered by a switch to another network does the controller send the rule table to the switch. The controller only needs to send the rule table to the switch once for a given mobile application.
The way that the controller passively sends the rule table to the switch increases the latency overhead of the proposed switch for processing the first mobile signal of the same mobile application. The mobile host, who is the first to leave the network covered by the switch, does not receive the latency performance gain discussed in
Section 3.3. This is because the first mobile signal still needs to be sent to the controller, and triggers the controller to send the rule table to the switch’s CE. After that, the CE sends a late-binding flow entry to the FE, thereby modifying the forwarding path of the packets sent to the mobile host. However, with the development of the mobile Internet and industrial IoT, a large number of mobile hosts that use the same mobile application will visit the same switch. In the above scenario, the latency overhead introduced by sending the rule table can be negligible. In the experiments, we performed a stress test. The number of mobile hosts in the network covered by the switch was more than 1000, and we calculated the average latency performance of the above hosts. The experimental results include the latency overhead of sending the rule table, but the latency overhead is negligible.
4.3. Improved SmartSplit Algorithm
4.3.1. Why Improve the SmartSplit Algorithm to Manage the Rule Table?
Let us analyze the characteristics of the rule table. At first, the processing logic of the mobile application does not change frequently, so the rule table need not be updated frequently. In addition, in order to support mobile applications with low latency requirements, there are high requirements for the speed of packets matching the rule table.
Currently, packet classification algorithms can be divided into three categories: packet classification algorithms based on decision trees, packet classification algorithms based on rule set division, and hybrid packet classification algorithms [
27]. The advantage of the packet classification algorithms based on decision trees is that their speed of packet classification is high. The disadvantage of the packet classification algorithm based on decision trees is that the speed of rule updating is slow. Therefore, the packet classification algorithms based on decision trees are suitable for scenarios where the rule set is not updated frequently, but the speed of packet classification needs to be high.
From the above analysis, we can see that the characteristics of the rule table are exactly in line with the applicable scenario of the packet classification algorithms based on decision trees. The SmartSplit algorithm [
26] is currently nearly the fastest packet classification algorithm based on decision trees. Therefore, we improved the SmartSplit algorithm to quickly implement packets matching the rule table.
4.3.2. Packet Classification Strategy of the SmartSplit Algorithm
The packet classification strategy of the SmartSplit algorithm mainly includes two points: divide the rule set into different rule subsets according to the size of the fields, and choose an appropriate packet classification algorithm to construct a decision tree for a rule subset according to the uniformity of the rule subset.
SmartSplit regards matching fields whose value is the wildcard
as large fields, and other fields as small fields. The rule set is divided into rule subsets according to the size of the field. SmartSplit only considers the source IP and destination IP as matching fields. Therefore, the rule set is divided into four subsets:
. Then, the SmartSplit algorithm chooses an appropriate packet classification algorithm to construct a decision tree for every rule subset according to the uniformity of the rule subset. SmartSplit sets up a centralized interval tree [
28] for the rule subset on the small field dimension, and counts the
of the centralized interval tree. The
is the maximum number of quiasi-balanced trees of the centralized interval tree that is used to indicate the uniformity of the rule subset. If
is in the interval of Formula (3), where
is the number of rules in the rule subset and
is the minimum number of rules that the leaf node of the decision tree must store, then the rule subset is uniform, and the HiCuts algorithm [
29] can be used to construct the decision tree for the rule subset. Otherwise, the HyperSplit algorithm [
30] is used to construct the decision tree for the rule subset.
The SmartSplit algorithm divides the large and small fields of the same matching field dimensions into different rule subsets, avoiding the rule redundancy of the large fields caused by fine-grained splitting in order to distinguish the small fields. In addition, the SmartSplit algorithm selects an appropriate packet classification algorithm according to the characteristics of the rule subset to construct a decision tree for the rule subset. Both of these packet classification strategies improve the speed of packet classification. However, SmartSplit only considers the source IP and destination IP as matching fields, and it does not support matching of multiple fields. In addition, SmartSplit regards the wildcard (*) as a large field. There are still many redundant rules when splitting the rule sets on some matching field dimensions. Therefore, we improved the SmartSplit algorithm to support matching of multiple fields. Furthermore, we set any matching field whose value occupies more than 50% of the total interval of the matching field dimension as a large field, thereby reducing the redundancy of the rule.
4.3.3. Detailed Explanation of the Improved SmartSplit Algorithm
Here, we introduce the improved SmartSplit algorithm in detail. Firstly, rules with the same number and type of matching fields are put in the same rule table. Next, we set each matching field of the rule as a large or small field. After that, we divide the rule set into different rule subsets according to the size of the field. Finally, we set up a decision tree for each rule subset. When constructing the decision tree, we select the matching field dimension with the least number of overlapping rules firstly to split the rule subset at each tree node and decide whether to split the rule subset uniformly according to the uniformity of the rule subset on the selected matching field dimension. If the rule subset is uniformly distributed on the selected matching field dimension, the rule subset is split uniformly; otherwise, the rule subset is split non-uniformly, but the number of rules in each splitting interval is the same.
In the above algorithm, there are still three problems to be solved when constructing the decision tree for each rule subset.
We set the first rule of the rule subset as the current rule, and compare the matching field of the current rule with matching fields of rules that have not been set as the current rule in the rule subset. If two matching fields overlap, the number of overlapping rules increases by 1. Then, we set the next rule as the current rule, and perform the above comparison process until the last rule in the rule subset is set as the current rule. The detailed calculation algorithm for the number of overlapping rules is shown in Algorithm 1.
| Algorithm 1. Calculation algorithm for the number of overlapping rules |
1: procedure CALCULATE_OVERLAPPING_RULES_NUMBER ()
2: = 0
3: for each do
4:
5: for each do
6: compare the matching fields of and
7: if matching field of overlaps matching field of then
8: + 1
9: end if
10: end for
11: end for
12: end procedure |
- 2.
How to determine the uniformity of the rule subset on different matching field dimensions at each tree node?
We use the same method as SmartSplit to determine the uniformity of the rule subset on different matching field dimensions. We set up a centralized interval tree for the rule subset on each matching field dimension, and calculate the of the centralized interval tree. is the maximum number of quiasi-balanced trees of the centralized interval tree that is used to indicate the uniformity of the rule subset. If is in the interval of Formula (3), we assume that the rule subset is uniformly distributed on the matching field dimensions. Otherwise, we assume that the rule subset is non-uniformly distributed on the matching field dimensions.
- 3.
How to determine the splitting interval numbers on different matching field dimensions at each tree node?
We assume that the splitting interval numbers are . The affects the time of mobile signaling matching the rule table, thereby affecting the processing latency of the mobile signaling. The larger the , the smaller the depth of the decision tree, which speeds up the mobile signaling matching the rule table. However, the larger the , the more memory space the decision tree takes up, because there are more redundant rules. Therefore, we have to make a trade-off between memory usage and mobile signaling matching speed. Therefore, we define a memory constraint function and a memory threshold function to determine the maximum of .
The memory constraint function
is:
The memory threshold function
is:
Then, the memory constraint function should be less than the memory threshold function:
In Formula (6), we can use the binary search method to gradually increase , which will be 2, 4, 8 …… The value of N can be given according to the memory resources of the switch’s CE; for example, N can be 4. Thus, we can determine the maximum allowed by the .
6. Conclusions
In this paper, we propose and implement enhanced programmable data plane supporting ICN mobility. By offloading mobility-related control plane functions from the controller to the data plane, the programmable data plane shows the ability of on-site computation, and can locally process the mobile signaling without interacting with the controller. In order to implement the offloaded control plane functions, we proposed a control-plane-function offloading mechanism based on a rule table. In the proposed mechanism, the control element of the data plane intercepts the mobile signaling, matches the predefined rule table, and executes a series of application logic actions, thereby implementing the offloaded control plane functions. In addition, we propose an improved SmartSplit algorithm to manage the rule table and speed up packets matching the rule table.
In order to verify the performance of our proposed enhanced programmable data plane, we implemented the enhanced programmable data plane based on Intel’s DPDK, and compared the performance of our enhanced programmable data plane with that of FCCPMS. The experimental results proved that the proposed enhanced programmable data plane had a stronger ability to process mobile signaling and reduce latency. When the maximum value of processing latency of mobile signaling does not exceed 100 μs, EPDPPMS has about 25 times the processing ability of FCCPMS. In addition, the processing latency of mobile signaling of FCCPMS is about seven times greater than that of EPDPPMS, and the remaining latency of EPDPPMS is significantly smaller than that of FCCPMS. The remaining latency of EPDPPMS is in the order of microseconds, while that of FCCPMS is in the order of milliseconds.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}