Abstract
Sparse Representation-based Classification (SRC) has been seen to be a reliable Face Recognition technique. The Bayesian based on the Lasso algorithm has proven to be most effective in class identification and computation complexity. In this paper, we revisit classification algorithm and then recommend the group-based classification. The proposed modified algorithm, which is called as Group Class Residual Sparse Representation-based Classification (GCR-SRC), extends the coherency of the test sample to the whole training samples of the identified class rather than only to the nearest one of the training samples. Our method is based on the nearest coherency between a test sample and the identified training samples. To reduce the dimension of the training samples, we choose random projection for feature extraction. This method is selected to reduce the computational cost without increasing the algorithm’s complexity. From the simulation result, the reduction factor () 64 can achieve a maximum recognition rate about 10% higher than the SRC original using the downscaling method. Our proposed method’s feasibility and effectiveness are tested on four popular face databases, namely AT&T, Yale B, Georgia Tech, and AR Dataset. GCR-SRC and GCR-RP-SRC achieved up to 4% more accurate than SRC random projection with class-specific residuals. The experiment results show that the face recognition technology based on random projection and group-class-based not only reduces the dimension of the face data but also increases the recognition accuracy, indicating that it is a feasible method for face recognition.
1. Introduction
Signal classification is one of the essential roles in machine learning [1,2], and has a wide range of applications, including computer vision. Compressive Sensing (CS) advances have prompted the development of sparse representation, which has shown to be a very successful classification algorithm. Face recognition, as one of the most successful applications of image classification, has attracted many researchers and has been a subject to sustained development over the past 30 years. The recent surge in the interest in face recognition can be attributed to many factors, including the growing concerns of the general public regarding the safety [3] and requirement for identity verification in the digital age [4].
CS theory was first established by Candés et al. in 2006 on the signal processing field for reconstructing a sparse signal by utilizing its sparsity structure [5]. A sparse signal can be precisely reconstructed in the compressive framework using significantly fewer samples (measurements) than the Shannon–Nyquist Theorem requires [6]. The reconstruction is based on the usage of optimization methods, and this is possible if specific requirements are met. In the CS, samples should be collected at random, and signals should be sparsely represented in a given transformation domain, sparsity domain in frequency, time-frequency, and so on. Sparse signals retain essential information in the sparsity domain using a small number of non-zero coefficients [7,8].
The suggestion of incorporating CS for face recognition applications was developed for the first time by Wright et al. in 2008 [9]. They reported interesting results on both of recognition rate and robustness to noise when compared to other recognition methods [10]. When representing a specific test sample as a sparse linear combination of all training samples, the sparse non-zero representation coefficient should focus on the training sample with the same class label as the test sample [9]. This technique has successfully addressed the recognition challenges with sufficient training images of each gallery subject.
In SRC, the challenge is to identify the class that a test sample belongs to using a set of training images from different classes that are provided [9]. Nevertheless, the extensive database of samples is endorsed as necessary to fulfil sparseness conditions and even more sample additions for pose variation handling. Because the SRC has already been subjected to high computational complexity to solve a complex -minimization problem, this condition requires increased sample spaces and a large amount of processing. The training samples are also used to develop approaches for improving recognition performance. It involves more computing, sample spaces, illumination, position, and expression. Our goal is to devise a system that capable of overcoming this limitation.
SRC is a nonparametric learning method comparable to the nearest subspace [11]. There is no need for training with these approaches because they can immediately assign a class label to any test sample [12]. In other words, they are not required to learn a collection of hypothesis functions or the hypothesis function parameters (for example, the weight vector). Signal reconstruction algorithms are used to implement the classification process in SRC, which may be thought of as a learning machine. From this perspective, SRC is a perfect example of a machine learning and compressed sensing combination method [12]. The experimental results demonstrate that SRC outperforms nearest neighbour (NN) and nearest subspace (NS) as well as linear Support Vector Machine (SVM) [13]. Although the incredible accuracy of facial recognition is based on deep learning approaches [14,15], the model is complex, and the identification speed is slow, even when dealing with a single image [16]. To compete with other algorithms, CNN must have massive datasets, and costly computations [17].
In this paper, we used random projection to lower the images’ dimensions. We proposed a method based on the coherency of intra-class and incoherence of inter-class, an algorithm that will be the minimum residual of class-based modified Lasso. We called this method Group Class Residual Sparse Representation Classifier (GCR-SRC). SRC uses class-specific residuals, as of the distances between all of these classes and the test sample. This method will improve the classification accuracy when the intra-class coherency and inter-class in-coherency are maximum, as we know in Linear Discriminant Analysis (LDA) technique compared to Principle Component Analysis (PCA) method [18]. The contribution of this paper is to have a simple algorithm that can achieve good accuracy; the main contribution is to use this algorithm on a single-board computer such as Raspberry Pi.
2. Literature Review
PCA [19] and LDA [20] are two standard methods used for feature extraction. A combination of PCA and SVM can improve face recognition [21]. PCA and LDA will decline in the recognition accuracy rate on the noisy image, such as occlusion and image corruption. SRC can handle this problem, but the drawbacks of this method are computationally complexity and require an extensive database to endorse the sparse condition. Many supplement algorithms were developed and published on the original SRC method. Yang et al. [22] discussed fast -minimization algorithm for Robust Face Recognition. Deng et al. [23] proposed extended SRC (E-SRC) and employed an auxiliary intra-class variant dictionary to reflect the potential difference between training and testing images. Mi et al. [24] proposed a technique to reduce computational complexity using the nearest subspace. Wei et al. [25] proposed robust auxiliary dictionary learning, a method to handle undersampled data. Duan et al. [26] presented a multiple sparse representation classification based on weighted residuals as a strategy to increase the effectiveness and reliability of sparse representation classification. Gou et al. [27] designed discriminative group collaborative competitive representation-based classification method (DGCCR). To improve the power of pattern discrimination, there is discriminative competitive relationships of classes. The DGCCR model simultaneously considers discriminative decorrelations among classes and weighted class-specific group restrictions. Wei et al. [28] introduces a new probability judgement method for sparse representation classifiers (SRCs), which employs a probability judgement model rather than directly employing the truncation residual. Krasnobayev et al. [29] proposed the method for the determination of the rank of a number in the system of residual classes. SRC uses a decision rule based on class reconstruction residuals, which is then used by Yang et al. [30] as a criterion to direct the development of a feature extraction strategy called SRC steered discriminative projection (SRC-DP). To improve SRC’s performance, the SRC-DP maximizes the ratio of between-class reconstruction residual to within-class reconstruction residual in the projected space. Based on the SRC decision rule, Lu et al. [31] designed OP-SRC to simultaneously decrease the within-class reconstruction residual and increase the between-class reconstruction residual on the training data.
Complex computations are performed in all of these practically essential computer science applications. The employment of the residual class system allows boosting the computing architecture’s speed and reliability considerably.
3. Background of Our Algorithm
3.1. Sparse Representation-Based Classification
SRC employs sparse signal reconstruction in CS to implement sparse data representation and classify data in terms of reconstruction errors.
Suppose c pattern classes are known. Let be the matrix formed by the training samples of class-i, i.e., , where is the number of training samples of class i. We define a matrix , where . The matrix A is clearly made up of all of the training samples. Any new test sample is a linear span of , which is [9]:
If the system of linear equations is underdetermined where , the formula of Equation (1) is sparse. The sparsest solution can be sought by solving the following optimization problem:
Using Equation (2) is NP hard and extremely time-consuming, but it has been proven that the problem can also be solved by -minimization popular linear programming equation problem [9]:
A generalized form of Equation (3) that allows for some noise is to find in such a form that the following objective function is minimized:
while is a regularization factor. After the sparsest solution is obtained, for each class i, let be the characteristic function that selects the coefficients associated with the i-th class. For , is a vector whose nonzeros are the entries in that are associated with class i. Using only the i-th class’s coefficients, one can reconstruct a given test sample as . is also known as the prototype of class i with respect to the sample . The distance between and its primal of class i are also formulated as:
The face recognition (FR) always comes along with the problems of occlusion, noise or image corruption, pose and illumination variation; these problems are represented by Equation (6) below:
where is a nonzero-valued unknown vector associated with the FR problems of . The vector cannot be neglected due to its relative significant values compared to vector . Nevertheless, similar to vector , generally, are sparse, while FR problems in most cases affect only a fraction of the training samples and test sample images.
3.2. Coherency Principles
The dictionary vector is known and overcomplete (), and the columns of are the atoms of the database. It is assumed throughout this work that the atoms are normalized such that:
we also assume that is zero-mean White Gaussian noise with covariance . Other methods have been proposed to formalize the definition of the suitability of a database for sparse estimation. One of the efficient methods to calculate the estimation for an arbitrary given dictionary is the mutual coherence parameter. The mutual coherence , which is defined as:
The mutual coherence can be efficiently calculated directly from (8), is related to the correlation between atoms or similarity between atoms. Furthermore the mutual coherence can be taken to bound the constants involved in the restricted isometry constant (RICs), it has been proven by [32].
4. Proposed Algorithm
4.1. Dimensionality Reduction Using Random Projection
The computational cost of most classification algorithms is determined by the dimensionality of the input samples. The dimensionality of the data can be high in many cases, particularly those involving image classification; thus, reducing the dimensionality of the data becomes necessary. SRC is an algorithm that almost gives a complete solution to address FR issues, including down-sampling feature extraction methods for handling sample corruption and occlusions and without down-sampling to combat corruption and occlusion [9]. Nevertheless, the extensive database of samples is endorsed to fulfill sparseness conditions, and even more sample additions for pose variation handling. This condition means that there is a high requirement of high sample spaces and high computation; this is worse naturally when the SRC has suffered from high computational complexity to solve a complex min problem. The other explication is that the training sample building methods increase recognition performance. This is including illumination, pose and expression, and also means more computations and sample spaces. Dimensionality reduction (DR) is an effective approach to dealing with such data because it has the potential to eliminate the “curse of dimensionality” [33]. In our previous work [34], we simulated the SRC method with and without the dimensionality reduction. The simulation results show that without dimensionality reduction, it will take about 10–11 min to recognize 200 samples on the AT&T dataset, while after the DR using downscale or random projection techniques, it only takes 11 s with almost the same recognition rate achievements.
Researchers have created many dimensionality reduction methods such as PCA, LDA, marginal Fisher analysis (MFA), maximum margin criterion (MMC) [35], locality preserving projections (LPP) [36], Sparsity Preserving Projection (SSP) [33], semi-supervised dimensionality reduction (SSDR), semi-supervised discriminant analysis (SDA) [37] and random projection (RP) [38].
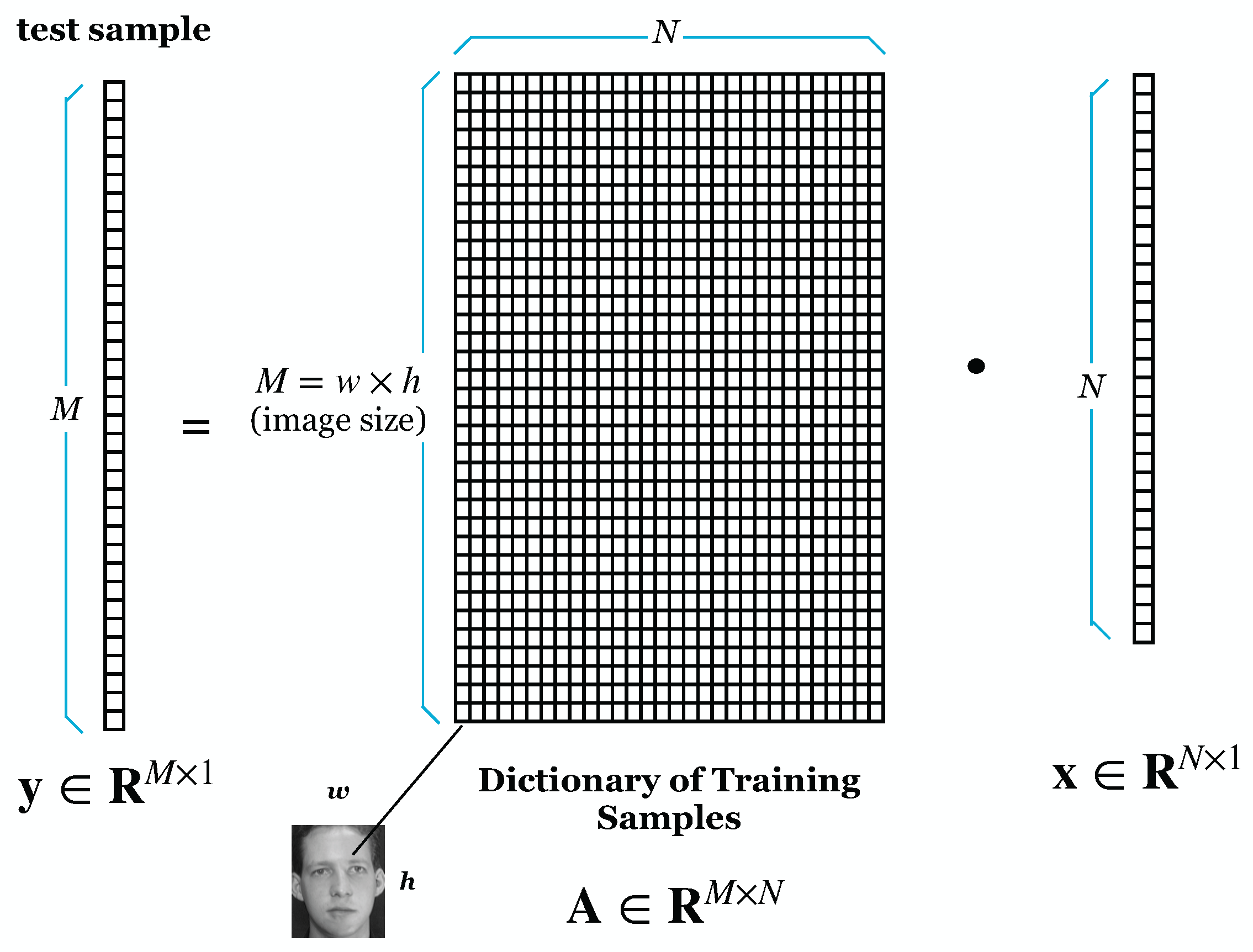
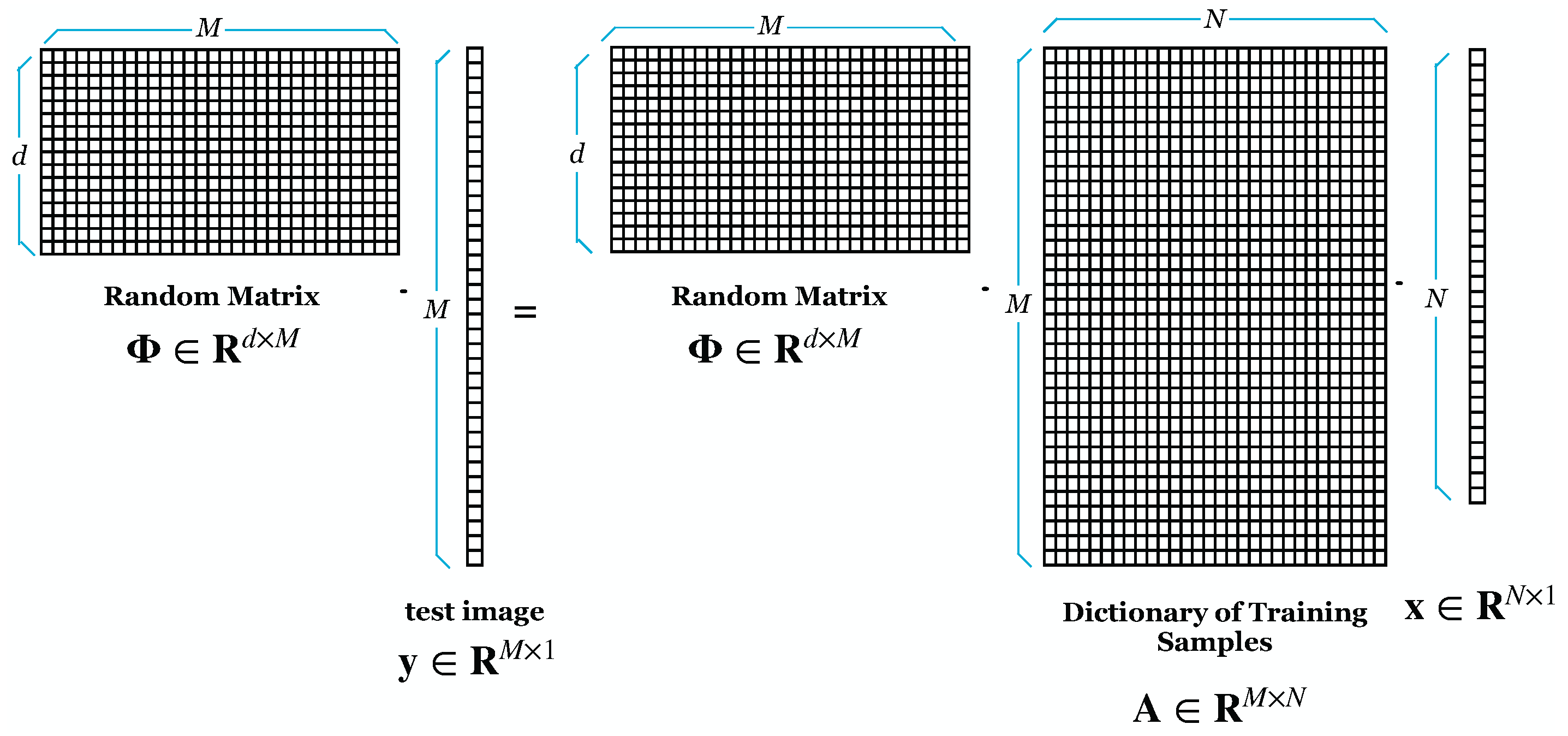
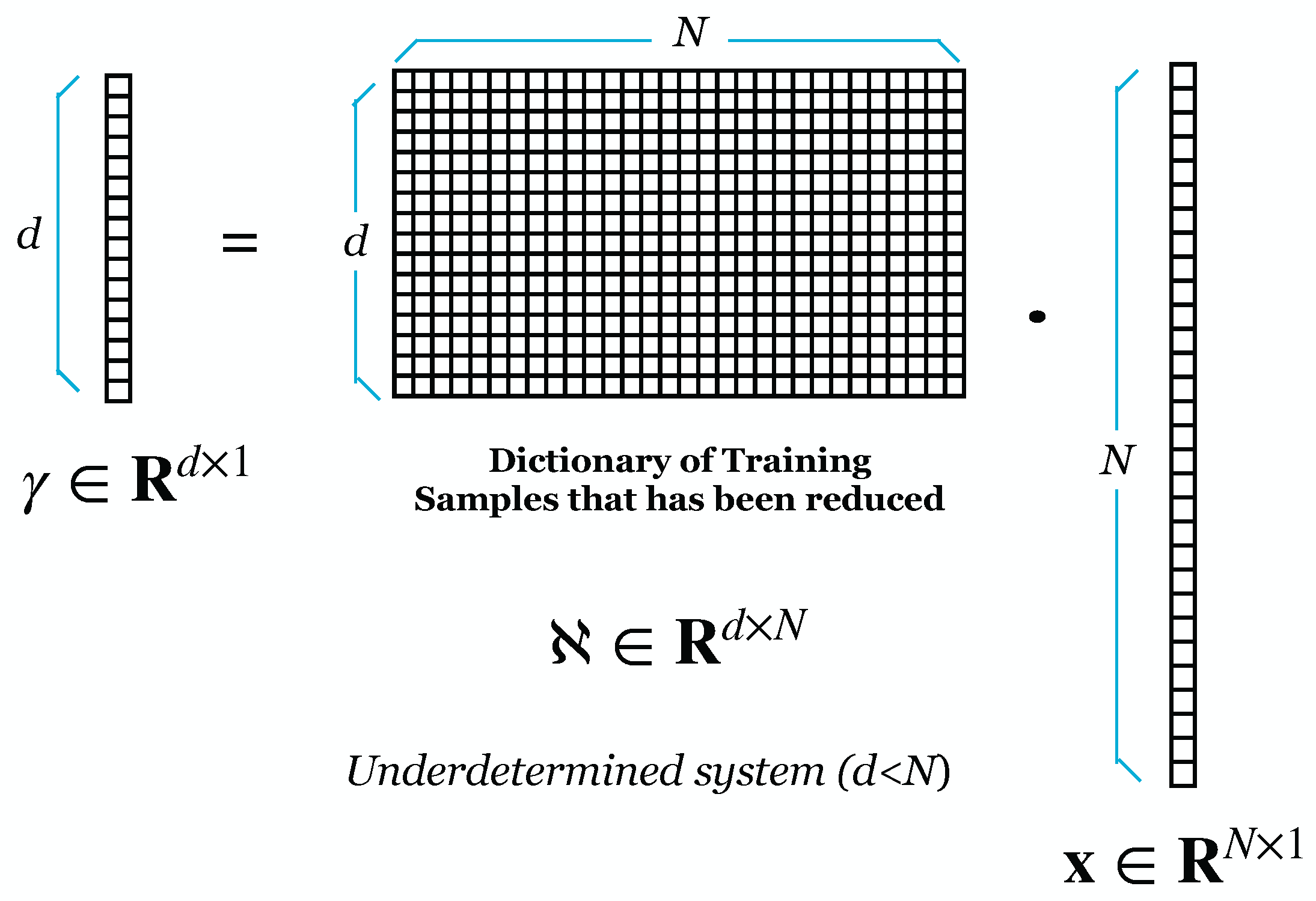
Wright et al. [9] proposed using RP to reduce the dimensionality of face images. We demonstrated experimentally that the SRC is resistant to DR. However, ref. [9] lacked a theoretical understanding of why the SRC is resistant to such dimensionality reduction. Majumdar and Ward [38] prove theoretically and practically that SRC is robust to dimensionality reduction by RP. Our experiment also tested that using RP for DR gives good results on recognition rate and lowers the computational cost [34]. Figure 1 shows the initial process of SRC, where M is the image size and N is the number in the training image. Suppose can result from an overdetermined system. Figure 2 shows the projection of the dictionary of training samples with a random matrix (). The result of the DR is shown in Figure 3.
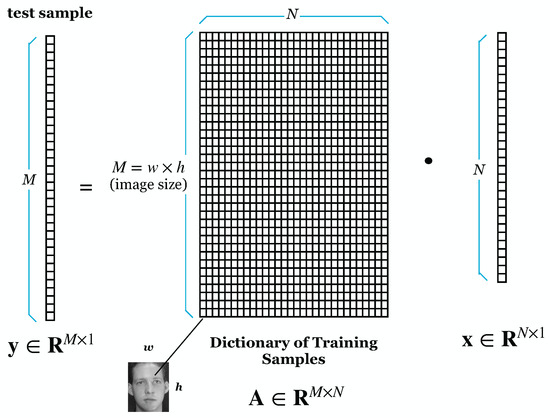
Figure 1.
SRC before Dimensionality Reduction.
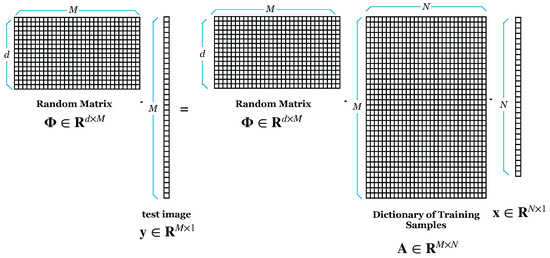
Figure 2.
Dimensionality Reduction using Random Projection.
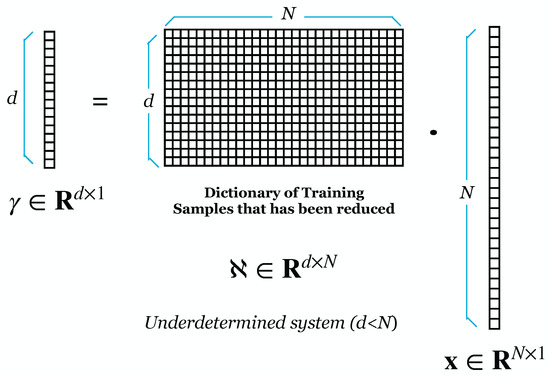
Figure 3.
Underdetermined System After Dimensionality Reduction.
The algorithm for dimensionality reduction using random projection on SRC method described on Algorithm 1.
| Algorithm 1: Algorithm for RP-SRC |
|
Input: a matrix of training samples for c classes. a test sample (and optional error tolerance ) Output: class
(Or alternatively), solve
|
4.2. Group Class Residual-SRC
The proposed algorithm is based on group or class-based coherency. The notion is to maximize the coherency, as in Equation (8) between test sample of interest to the whole training samples in each class rather than only individual training samples of the original SRC algorithm. The proposed modified algorithm will be based on Equation (4). The residual values of corresponding test samples will be the sum for each class. The class will be determined by the minimum result of a class-based residual reconstruction error value. This method is also based on the nearest class, or the highest coherence of the test sample compared to each class’s training samples or dictionary. This method we called Group Class Residual Sparse Representation based Classification (GCR-SRC) and described in Algorithm 2.
| Algorithm 2: Algorithm for GCR-RP-SRC |
|
Input: a matrix of training samples for c classes. a test sample (and optional error tolerance ) Output: class
(Or alternatively), solve
|
5. Result and Discussions
We used AT&T [39], Yale B [40], Georgia Tech (GT) [41] and the AR [42] dataset for testing the recognition accuracy. The AT&T dataset bundle includes 400 images. There are 40 classes or subjects, and each class contains 10 images. In this experiment, we used 200 images for training and 200 for testing. The photographs were taken at various times, with different lighting, face expressions (open vs. closed eyes, smiling vs. not smiling) and facial details (glasses vs. no glasses). Figure 4 shows several subjects of the AT&T dataset.

Figure 4.
AT&T Dataset.
The Yale B dataset includes 38 participants under 64 distinct lighting conditions and is commonly used to assess various illumination-processing systems. While using this dataset for testing, we used image data numbers 1 to 32 for training and 33 to 64 for testing. All test image data were manually aligned, cropped and resized to 168 × 192 images for the experiments. Figure 5 depicted several images on the Yale B dataset. For testing pose variation, we used the Georgia Tech (GT) dataset. These pose variation examples are shown in Figure 6. All 50 people in the GT dataset were provided with 15 color JPEG photos with a complex background that were taken at a resolution of pixels. The average face size in these photos is pixels. Because this dataset has different pixels on each image, we resize all images into pixels.

Figure 5.
Yale B Dataset.

Figure 6.
Georgia Tech Dataset.
We also tested our method on the AR Dataset. In the Computer Vision Center (CVC) at the University of Alabama in Birmingham, Aleix Martinez and Robert Benavente developed this face database. It includes over 4000 color images corresponding to the faces of 126 people (70 men and 56 women). Faces seen from the front, with various expressions, lighting conditions and occlusions, are depicted in the images (sunglasses and scarf)—the samples of face variations are shown in Figure 7. The photographs were taken at the CVC in a setting where the environment was carefully monitored and controlled. The participants were not limited by what they could wear (clothes, glasses, etc.), how they made up their faces, how they styled their hair or anything else. Everyone participated in two different sessions, each spaced out by one week and a half (14 days) [42].

Figure 7.
Aleix Martinez and Robert Benavente (AR) Dataset.
Reducing the size of the images is an essential step we must fulfill to have an underdetermined system. Downscaling and random projection techniques are chosen for their simplicity and minimum computation complexity. Table 1 shows the results of dimensionality reduction using downscaling techniques and random projections on the AT&T Dataset. Where is the reduction factor from sample images to the extraction images . For example, means that if we take a sample image from the AT&T dataset, the size of the sample image is 10,304 pixels, so the extraction image becomes 161 pixels. From Table 1, we can see that Random Projection techniques achieve a better recognition rate from 2% to 4% higher than the downscale technique. We simulate the different reduction factors with , and , and the simulation result shows the recognition rate declined, respectively. The simulation results are obtained from running on Python, using computer specification 2.5 GHz Dual-Core Intel Core i5 and memory of 8 GB 1600 MHz DDR3.

Table 1.
Dimensionality Reduction vs. Recognition Rate on AT&T Dataset.
Table 2 shows the result of recognition rate on AT&T, Yale B, Georgia Tech and AR Dataset with . The experimental results show that our Group Class Residual approach performs better than the original SRC-Downscale technique. The proposed method can achieve up to 4% compared to the original SRC method.
Table 2.
Recognition Rate Simulation Result.
Table 3 shows the processing time on AT&T, Yale B and Georgia Tech datasets. The proposed method can achieve higher accuracy than the original SRC method with almost the same computation time.
Table 3.
Processing Time Simulation Result.
The experiment results are presented and compared with the outcomes of other models depicted in Table 4. As a result of our simulation, the proposed method has a higher level of accuracy, requires less time for classification and completes the training phase in a shorter amount of time than the SRC-DP and OP-SRC models. Future work could include some enhancement of the proposed method; the group class classification will make it possible for K-distance-based classification that it used to reduce numerous classes to several calculated classes.
Table 4.
Comparison between proposed and other FR methods on Yale Dataset.
6. Conclusions
This paper proposes the modified SRC algorithm based on coherency principles. The modified algorithm determines the minimum reconstruction error of the corresponding class of the test sample by calculating the minimum residual mistake of reconstruction by class bases. The coherency between samples of the same class and in-coherency for inter-class samples can also be tested by the Fisher discriminating factor parameter. We proposed these group classifications to be furthered by our near future research paper to compare with the K-Euclidean distance method for finding K-nearest group class training samples.
Author Contributions
Conceptualization, S.I.L. and A.B.S.; methodology and software, S.I.L.; formal analysis, A.B.S. and I.J.M.E.; data analysis, K.U.; writing and original draft preparation, S.I.L.; review, A.B.S., I.J.M.E. and K.U.; editing, S.I.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The data/results of the experiments are available upon request.
Acknowledgments
S.I.L. sincerely thank LPDP (Indonesia Endowment Fund for Education), Ministry of Finance, Republic Indonesia for providing the financial support for this research. A.B.S is supported by ITB Research Grant 2022 (PN-6-01-2022).
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AR | Aleix Martinez and Robert Benavente |
| CS | Compressive Sensing/ Compressive Sampling |
| CNN | Convolutional Neural Network |
| DR | Dimensionality Reduction |
| DGCR | Discriminative Group Collaborative Competitive Representation-based Classification |
| E-SRC | Extended Sparse Representation based Classification |
| FR | Face Recognition |
| GT | Georgia Tech |
| GCR-SRC | Group Class Residual Sparse Representation based Classification |
| GCR-RP-SRC | Group Class Residual Random Projection Sparse Representation based Classification |
| LLP | Locality Preserving Projection |
| MFA | Marginal Fisher Analysis |
| MMC | Maximum Margin Criterion |
| NN | Nearest Neighbour |
| NS | Nearest Subspace |
| OP-SRC | Optimized Projection Sparse Representation Classification |
| PCA | Principle Component Analysis |
| RP | Random Projection |
| SDA | Semi Supervised Discriminant Analysis |
| SR | Sparse Representation |
| SRC | Sparse Representation based Classification |
| SRC-DP | Sparse Representation Classification Discriminant Projection |
| SSDR | Semi Supervised Dimensionality Reduction |
| SVM | Support Vector Machine |
References
- Shailendra, R.; Jayapalan, A.; Velayutham, S.; Baladhandapani, A.; Srivastava, A.; Kumar Gupta, S.; Kumar, M. An IOT and machine learning based intelligent system for the classification of therapeutic plants. Neural Process. Lett. 2022. [Google Scholar] [CrossRef]
- Sarker, I.H. Machine learning: Algorithms, real-world applications and Research Directions. SN Comput. Sci. 2021, 2, 1–21. [Google Scholar] [CrossRef] [PubMed]
- Wójcik, W.; Gromaszek, K.; Junisbekov, M. Face recognition: Issues, methods and alternative applications. In Face Recognition—Semisupervised Classification, Subspace Projection and Evaluation Methods; IntechOpen: London, UK, 2016. [Google Scholar]
- Singh, S.; Chintalacheruvu, S.C.; Garg, S.; Giri, Y.; Kumar, M. Efficient face identification and authentication tool for biometric attendance system. In Proceedings of the 2021 8th International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 26–27 August 2021. [Google Scholar]
- Donoho, D. Compressed sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Candes, E.; Wakin, M. An Introduction To Compressive Sampling. IEEE Signal Process. Mag. 2008, 25, 21–30. [Google Scholar] [CrossRef]
- Wang, Z.; Yang, J.; Zhang, H.; Wang, Z.; Yang, Y.; Liu, D.; Huang, T. Sparse Coding and Its Applications in Computer Vision; World Scientific Publishing Co. Pte. Ltd.: Singapore, 2016. [Google Scholar]
- Zhang, Z.; Xu, Y.; Yang, J.; Li, X.; Zhang, D. A Survey of Sparse Representation: Algorithms and Applications. IEEE Access 2015, 3, 142–149. [Google Scholar] [CrossRef]
- Wright, J.; Yang, A.; Ganesh, A.; Sastry, S.; Ma, Y. Robust Face Recognition via Sparse Representation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 210–227. [Google Scholar] [CrossRef]
- Yang, M. Face recognition via sparse representation. Wiley Encycl. Electr. Electron. Eng. 2015, 1–12. [Google Scholar] [CrossRef]
- Lv, S.; Liang, J.; Di, L.; Yunfei, X.; Hou, Z.J. A Probabilistic Collaborative Dictionary Learning-Based Approach for Face Recognition. IET Image Process. 2020, 15, 868–884. [Google Scholar] [CrossRef]
- Zhang, L.; Zhou, W.; Chang, P.; Liu, J.; Yan, Z.; Wang, T.; Li, F. Kernel Sparse Representation-Based Classifier. IEEE Trans. Signal Process. 2012, 60, 1684–1695. [Google Scholar] [CrossRef]
- Zhang, S.; Zhao, X.; Lei, B. Robust Facial Expression Recognition via Compressive Sensing. Sensors 2012, 12, 3747–3761. [Google Scholar] [CrossRef] [Green Version]
- Xiao, H.; Hu, Z. Feature-similarity network via soft-label training for infrared facial emotional classification in human-robot interaction. Infrared Phys. Technol. 2021, 117, 103823. [Google Scholar] [CrossRef]
- Ju, J.; Zheng, H.; Li, C.; Li, X.; Liu, H.; Liu, T. AGCNNs: Attention-guided convolutional neural networks for infrared head pose estimation in assisted driving system. Infrared Phys. Technol. 2022, 123, 104146. [Google Scholar] [CrossRef]
- Lin, C.-L.; Huang, Y.-H. The application of adaptive tolerance and serialized facial feature extraction to automatic attendance systems. Electronics 2022, 11, 2278. [Google Scholar] [CrossRef]
- Alskeini, N.H.; Thanh, K.N.; Chandran, V.; Boles, W. Face recognition. In Proceedings of the 2nd International Conference on Graphics and Signal Processing—ICGSP’18, Sydney, Australia, 6–8 October 2018. [Google Scholar]
- Thushitha, V.R.; Priya, M. Comparative analysis to improve the image accuracy in face recognition system using hybrid LDA compared with PCA. In Proceedings of the 2022 International Conference on Business Analytics for Technology and Security (ICBATS), Dubai, United Arab Emirates, 16–17 February 2022. [Google Scholar]
- Chen, Z.; Zhu, Q.; Soh, Y.C.; Zhang, L. Robust Human Activity Recognition Using Smartphone Sensors via CT-PCA and Online SVM. IEEE Trans. Ind. Inform. 2017, 13, 3070–3080. [Google Scholar] [CrossRef]
- Yu, T.; Chen, J.; Yan, N.; Liu, X. A Multi-Layer Parallel LSTM Network for Human Activity Recognition with Smartphone Sensors. In Proceedings of the 2018 10th International Conference on Wireless Communications and Signal Processing (WCSP), Hangzhou, China, 18–20 October 2018; pp. 1–6. [Google Scholar]
- Wang, Y.; Wu, Q. Research on face recognition technology based on PCA and SVM. In Proceedings of the 2022 7th International Conference on Big Data Analytics (ICBDA), Guangzhou, China, 4–6 March 2022. [Google Scholar]
- Yang, A.; Zhou, Z.; Balasubramanian, A.; Sastry, S.; Ma, Y. Fast l1 Minimization Algorithms for Robust Face Recognition. IEEE Trans. Image Process. 2013, 22, 3234–3246. [Google Scholar] [CrossRef]
- Deng, W.; Hu, J.; Guo, J. Extended SRC: Undersampled Face Recognition via Intraclass Variant Dictionary. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1864–1870. [Google Scholar] [CrossRef]
- Mi, J.; Liu, J. Face Recognition Using Sparse Representation-Based Classification on K-Nearest Subspace. PLoS ONE 2013, 8, e59430. [Google Scholar]
- Wei, C.-P.; Wang, Y.-C.F. Undersampled face recognition via robust auxiliary dictionary learning. IEEE Trans. Image Process. 2015, 24, 1722–1734. [Google Scholar]
- Duan, G.L.; Li, N.; Wang, Z.; Huangfu, J. A multiple sparse representation classification approach based on weighted residuals. In Proceedings of the 2013 Ninth International Conference on Natural Computation (ICNC), Shenyang, China, 23–25 July 2013. [Google Scholar]
- Gou, J.; Wang, L.; Yi, Z.; Yuan, Y.-H.; Ou, W.; Mao, Q. Discriminative group collaborative competitive representation for visual classification. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019. [Google Scholar]
- Wei, J.-S.; Lv, J.-C.; Xie, C.-Z. A new sparse representation classifier (SRC) based on Probability judgement rule. In Proceedings of the 2016 International Conference on Information System and Artificial Intelligence (ISAI), Hong Kong, China, 24–26 June 2016. [Google Scholar]
- Krasnobayev, V.; Kuznetsov, A.; Popenko, V.; Kononchenko, A.; Kuznetsova, T. Determination of positional characteristics of numbers in the residual class system. In Proceedings of the 2020 IEEE 11th International Conference on Dependable Systems, Services and Technologies (DESSERT), Kyiv, Ukraine, 14–18 May 2020. [Google Scholar]
- Yang, J.; Chu, D.; Zhang, L.; Xu, Y.; Yang, J. Sparse representation classifier steered discriminative projection with applications to face recognition. IEEE Trans. Neural Netw. Learn. Syst. 2013, 24, 1023–1035. [Google Scholar] [CrossRef]
- Lu, C.-Y.; Huang, D.-S. Optimized projections for sparse representation based classification. Neurocomputing 2013, 113, 213–219. [Google Scholar] [CrossRef]
- Ben-Haim, Z.; Eldar, Y.C.; Elad, M. Coherence-based performance guarantees for estimating a sparse vector under random noise. IEEE Trans. Signal Process. 2010, 58, 5030–5043. [Google Scholar] [CrossRef]
- Qiao, L.; Chen, S.; Tan, X. Sparsity preserving projections with applications to face recognition. Pattern Recognit. 2010, 43, 331–341. [Google Scholar] [CrossRef] [Green Version]
- Lestariningati, S.I.; Suksmono, A.B.; Usman, K.; Edward, I.J. Random projection on sparse representation based classification for face recognition. In Proceedings of the 2021 13th International Conference on Information Technology and Electrical Engineering (ICITEE), Chiang Mai, Thailand, 14–15 October 2021. [Google Scholar]
- Ai, X.; Wang, Y.; Zheng, X. Sub-pattern based maximum margin criterion for face recognition. In Proceedings of the 2017 2nd International Conference on Image, Vision and Computing (ICIVC), Chengdu, China, 2–4 June 2017. [Google Scholar]
- Cai, X.-F.; Wen, G.-H.; Wei, J.; Li, J. Enhanced supervised locality preserving projections for face recognition. In Proceedings of the 2011 International Conference on Machine Learning and Cybernetics, Guilin, China, 10–13 July 2011. [Google Scholar]
- Ling, G.F.; Han, P.Y.; Yee, K.E.; Yin, O.S. Face recognition via semi-supervised discriminant local analysis. In Proceedings of the 2015 IEEE International Conference on Signal and Image Processing Applications (ICSIPA), Kuala Lumpur, Malaysia, 19–21 October 2015. [Google Scholar]
- Majumdar, A.; Ward, R.K. Robust classifiers for data reduced via random projections. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 2010, 40, 1359–1371. [Google Scholar] [CrossRef]
- The ORL Database. Available online: https://cam-orl.co.uk/facedatabase.html (accessed on 24 July 2022).
- The Yale B Face Database. Available online: http://vision.ucsd.edu/~leekc/YaleDatabase/ExtYaleB.html (accessed on 24 July 2022).
- The Georgia Tech Database. Available online: http://www.anefian.com/face\protect\T1\textdollar_\protect\T1\textdollarreco.htm (accessed on 24 July 2022).
- The Aleix Martinez and Robert Benavente Database. Available online: https://www2.ece.ohio-state.edu/~aleix/ARdatabase.html (accessed on 22 August 2022).




Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).