1. Introduction
Programmability and elasticity of management layers in Internet of Things (IoT) networking are the primary prerequisites for future autonomous systems (zero-touch network and service management), which can be obtained predominantly based on three enabler technologies: (1) software-defined networking (SDN), (2) network function virtualization (NFV), and (3) multi-access edge computing (MEC) [
1,
2,
3]. Each paradigm consists of significant contributions to activate automation on network path configuration, multiple virtual resource blocks on dedicated hardware, flexible/resource-gathering application programming interfaces, and enhanced computational distribution. Towards the future of self-managing capabilities in real-time intelligent IoT services (e.g., mission-critical deep learning-based applications), each technology requires further enhancement as follows [
4,
5,
6]:
Routing optimization, priority-aware traffic classification (e.g., application-based/flow-based approaches), quality-of-service (QoS) and quality-of-experience estimation, advanced security, and resource allocation in SDN systems;
Increasing flexibility in terms of instantiation, modification, and placement of virtual network functions (VNFs) in the NFV layer with model scalability and transferability;
Reactive/proactive caching placement, improved service slicing, virtualized resource mapping, and task offloading decisions in resource-constrained MEC.
Numerous deep reinforcement learning (DRL) approaches have been studied and recommended by researchers and standardization to enhance these abovementioned perspectives, which consider optimization of joint weighted sum models for communication, computation, caching, and controllability [
7,
8]. Experience-driven and data-driven mechanisms (e.g., replay batch- and state-aware enhancement) are well known as efficient facilitators for scalable self-organizing IoT networking. With a variety of taxonomies, namely actor–critic or deep deterministic gradient policy, DRL algorithm selection has to be optimized before deployment based on the discrete/continuous action spaces and final policy expectation. In multi-service networks, DRL is a promising decision-making entity, particularly in NFV-based dynamic service function chaining (SFC), that considers the isolation of each service based on a set of VNF forwarding graphs (VNFFGs) [
9].
Figure 1 presents an overview of correlations from ingress to egress VNF descriptors, which are specified through the capabilities, resource properties, connection points, and virtual links. Each specific service has to be determined within the selected forwarding graphs. The ingress index is denoted as
followed by sequential indices for representational services
and
. The egress index is denoted as
followed by services
and
, which refers to the multi-service environment of heterogenous IoT tenants. The function-specific VNF descriptors are executed at least once throughout the selected services to perform the setup mechanism. By setting up the model environment and formulating the evaluation rewards on load balancing, upper-bound delays, and required computation resources, VNF costs and service chain selection can be optimized by the proposed agent.
In massive real-time IoT services, the major domain to tackle in SDN systems and NFV-enabled MEC architectures is the adaptivity of SFC orchestration, which requires dealing with five challenging issues: (1) insufficient virtual resource mapping, (2) deficient delay-sensitive service flow classification, (3) inaccurate priority labels, (4) unstable workload in diversified network congestion states, and (5) incomplete adaptive policy self-modification [
4,
7]. To handle these issues, several aspects of deployed SFC need to be jointly considered as weighted sum models of allocation costs, computation delays, descriptor modification requirements, and virtual linkages. The upper-bound delays have to be detected/predicted for ensuring the prioritization of both mission-critical and non-mission-critical IoT services. The total execution delays and resource consumption have to be minimized throughout multiple agents to meet the requirements of each aspect.
In this paper, a system model of NFV-based SFC is given by considering the computation resource and orchestration models (VNF placement, virtual link, and modification costs) in multi-service IoT networks. The system architecture of SFC deployment is given by presenting the correlations between instantiated VNF descriptor with defined VNFFG, virtual machine (VM) blocks in NFV infrastructure, and SFC orchestration policy. The multi-agent approaches, including (1) agent 1, virtual resource mapping; (2) agent 2, VNF placement; and (3) agent 3, priority-aware service classification, are primarily based on deep Q-networks (DQNs) which independently observe specific states, actions, and rewards on integrated purposes of priority-aware management. Experimental simulation is conducted in both SDN/NFV-enabled and DRL-based environments.
The rest of the paper is structured as follows:
Section 2 presents the preliminary studies on DRL-based SFC.
Section 3 presents the system models for the setup environment and orchestration/computation models in the NFV-enabled SFC environment. The working flow and execution processes of proposed multiple agents on priority-aware resource management in real-time intelligent IoT services are given in
Section 4.
Section 5 shows the performance evaluation, which includes the simulation setup, indication metrics, reference schemes, and result discussions. Finally, the conclusion is presented in
Section 6.
Table 1 presents a list of important acronyms used in this paper.
2. Preliminary Studies on DRL-Based SFC Deployment
In this section, the promising selected studies on applying DRL for optimizing the procedures of SFC deployment are outlined, including the autonomous VNF placement via DRL-based performance prediction, optimal placement via double DQN, optimal resource usages, and adaptive online SFC with DRL.
Reinforcement learning problems have been modeled and dealt with using a Markov decision process framework throughout the interactions between four tuple elements including a set of state spaces, action spaces, transition probability function, and reward, which are denoted as
,
,
, and
[
10,
11,
12]. The setup environment, namely the NFV-based SFC scenario, samples a set of state features, denoted as
, throughout numerous timeslot
-iteration. The agent executes the action
by exploring or exploiting selection to the environment for altering the conditions and evaluating the update metrics. The transition function as a probability distribution presents the likelihood of updating the state features in the NFV-based SFC environment towards
.
can be adjusted in SFC environment as the expected objectives to illustrate the satisfactions of applied action in that particular state characteristic within timeslot
.
can be referred to as the end-to-end execution delay or computational network function latency [
13,
14,
15,
16]. As an experience-driven mechanism, each element is stored within the replay batch for synchronously optimizing the parameters of online/target function approximators. Throughout this processing flow, the agent can maximize the reward for particular states by selecting the optimal action, which is collectively known as an optimal policy. This overview procedure has been adopted and modified to various promising approaches in SFC orchestration.
In [
17], the authors use a DRL agent to interact with an SDN/NFV-enabled environment to optimize the VNF placement through a weighted sum model of cost minimization on allocation, VNF instance execution, and SFC request rejection. The placement model is formulated as binary integer programming. A good reward function, which jointly considers each aspect of the environment, efficiently generates reliable and long-term agent flexibility. In [
18], the authors propose an adopted reinforcement learning scheme for autonomous VNF placement via performance prediction. To predict the transmission efficiency as an approximation of expected VNF performance, the elements for reinforcement learning agent are described as follows:
State consists of all the possible ranging predictions classified into three categories, namely underestimation (predicted value is less than the actual value), equivalent (predicted value is equal to the actual value), and overestimation (predicted value is more than the actual value).
Action alters states by setting decrement/increment values of the prediction by 0.01.
Reward considers an outcome range between 0 and 1 as a deficiency and efficiency of the state–action pairs for improving immediate and next state. The acceptable error margin is defined.
The communication and computation resource utilization in SFC architecture is optimized by adjusting the flow specifications and service function instances. In [
19,
20,
21], the optimization problem is formulated in SFC-aware flow systems for minimizing resource usage in each chain. The optimized scheme needs to consider the constraints of SFC-aware flow conservation, capacity, and service function processing order. In DRL-based SFC deployment, the is a need to consider the system description on orchestration entity and Markov decision process models, which includes the elements of service-required VNF, service-related SFC, and characteristics of service requests. The components that interact with this setup environment consist of primary features as follows [
19]:
State defines the features of remaining resource capacities, output bandwidth, and characteristics of processed VNFs.
Action indicates the placement index of deploying particular VNFs in the selected server node. The action alters the placement specifications which output different performances, whereas the null action indicates the undeployed status of VNFs.
Reward formulates the optimization model of the weighted total between provider and client profits, which can be obtained by the approved requests and expenditures for deployment.
Throughout these selected promising studies, SFC processing flows have been enhanced with DRL-based approaches. However, the challenge in multi-service prioritization of real-time intelligent IoT networks remains a critical aspect that needs to converge between autonomous placement, resource mapping, and classification of service criticality. Particularly, in deep learning-based applications, the procedures of data-driven models need an adaptive function-specific VNF selection with minimization of total execution time and resource consumption. To acquire an efficient priority-aware resource orchestration in SFC deployment, a setup system model and problem formulation, jointly tackling in-depth aspects of an NFV-based system and the Markov decision process, are required for ensuring the reliability and scalability of the proposed multi-agent scheme via confluence models in total reward function.
3. System Models
In this section, the collaboration models between NFV-enabled SFC architecture and the Markov decision process framework are given for specifying the features that matter in the agent policy formulation.
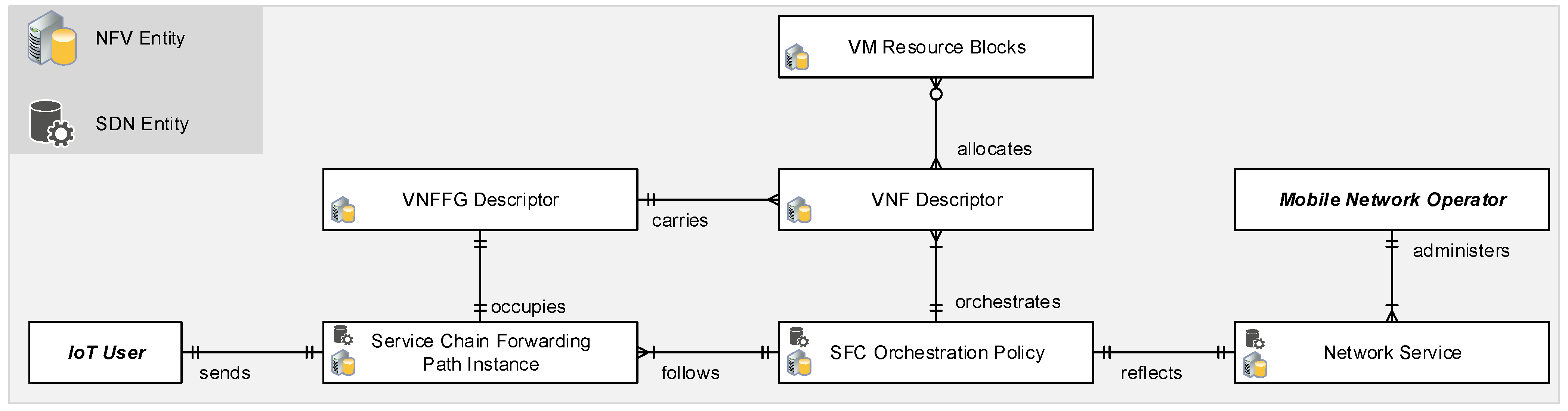
Figure 2 presents the exemplary entity relationship diagram of the system architecture [
22,
23,
24]. In this proposed SDN/NFV-assisted SFC, the connectivity between multi-service IoT users to specific network services is through the orchestration of SFC policy, which is associated with the VNFFG/VNF specifications and VM resource building block determination. In an example execution timeslot, the end user sends a single flow, which belongs to a unique service chain forwarding path instance. The forwarding decisions and rules follow the optimal SFC orchestration policy. Each path instance is based on the occupied VNFFG descriptor using the topology and orchestration specification for cloud applications (TOSCA) template in NFV, which carries many VNF descriptors as a set of ordered functions. The VM resource blocks and other resource properties are allocated within the configuration of the descriptor. The proposed weighted sum model has to reflect the performance of policy with the network service. The expectations on QoS class identifiers are key primary features for priority-aware management, which are varied between each service criticality.
The SDN and NFV entities comply with each other to flexibly modify the instances, adjust the virtual resource blocks, orchestrate the descriptors, and install the forwarding rules. The data and control plane are decoupled by SDN concepts which list the main entities of (1) the
data plane, namely a set of small base stations, denoted as
, equipped with NFV-enabled nodes with allocated virtual resources, denoted as
, and (2)
control plane, namely the configuration from NFV management and orchestration proposed for assigning weights to apply increment or decrement actions on virtual resource capacities. Application programming interfaces are used to extract the state information of maximum/available resources, congestion states, etc. Within this architecture, the SDN/NFV-assisted SFC system models require tackling the orchestration and computational resources.
Table 2 presents important notations used in this paper.
To fully formulate the model for SFC orchestration, a weighted sum of VNF placement in a complete VNFFG and virtual link usages is given for outputting the costs. The computation resource is expected to be minimized for further enhancement. Afterward, the total execution delays for processing from ingress to egress VNFs in a particular service path instance require consideration in the proposed system as well.
3.1. Costs of Allocation and Virtual Link Usages
A set of VNFFGs is denoted as
, and a set of VNFs is denoted as
. The status of deploying VNF-
into forwarding graph VNFFG-
(particular service instance) with a specified resource block in node
is presented as
. The placement cost is considered as
; however, with a defined weight
of priority-aware service criticality, the total cost can be significantly decreased or increased, which guides the orchestration emphasis after the weights are predetermined via the proposed algorithm. For allocation cost in a VNFFG, denoted as
, the summation of each placement is formulated to associate with the VM resource blocks that operate the defined function, which is given in (1). Moreover, in a VNFFG, the utilization of virtual links for connection points consists of a configuration cost. With
number of VNFs in a forwarding path, the number of virtual links is required to be one less than the total number of VNFs (
, which connects within each ordered function. A set of links is denoted as
. The costs of total utilization, denoted as
, can be formulated as Equation (2) by considering four essential variables as follows: (1) the bandwidth allocation between NFV-enabled nodes, denoted as
; (2) link costs of each VNF in NFV-enabled node
, denoted as
; (3) the critical weight
of the forward path; and (4) the status of placing virtual link
connecting between ingress VNF
and egress VNF
, denoted as
.
3.2. Computation Model
In a particular defined service, the allocated VM resource blocks are essential for adequately managing computing a complete service path in SFC systems within a required QoS class expectation. To ensure reliability, the pre-allocated resource properties need to optimally match with the required computation resources per end-to-end service transmission. For real-time mission-critical services, the resources can be extended for securing the future congestion states, which are assigned as a primary variable in dynamic configuration. Equation (3) expresses the computation model, denoted as
, that is based on the parameters of (1) allocation status
, (2) predetermined resource allocation in node
for executing VNF
primarily based on the
, denoted as
, and (3) required resources for computing VNF
, denoted as
. The model outputs 0 if VNF
does not belong in that particular service; otherwise, the model returns a ratio between 0 to 1 for optimizing the placement, where 1 indicates the optimal point. If the predetermined allocation leads to output higher than 1, it indicates a service drop due to exceeding the upper-bound limitation, which severely affects the real-time model building in intelligent IoT services.
3.3. Execution Delays
Within a particular service, the total execution delay is the most critical metric to be minimized by optimally adjusting adequate computation resources, bandwidth for NFV-enabled node
, and accurate predictive VNF performance on the ordered path. Equation (4) expresses the total delay in a particular chain
, denoted as
, where each element is gathered from the computation and placement models.
determines the modification delay to reconfigure the chain descriptor following the proposed agent policy in any required intervals. In chain
, the total orchestration and execution delays of each placed VNF
, which are denoted as
and
, are considered in terms of function instantiation, configuration, and processing.
4. Priority-Aware Agent for Resource Management in SFC
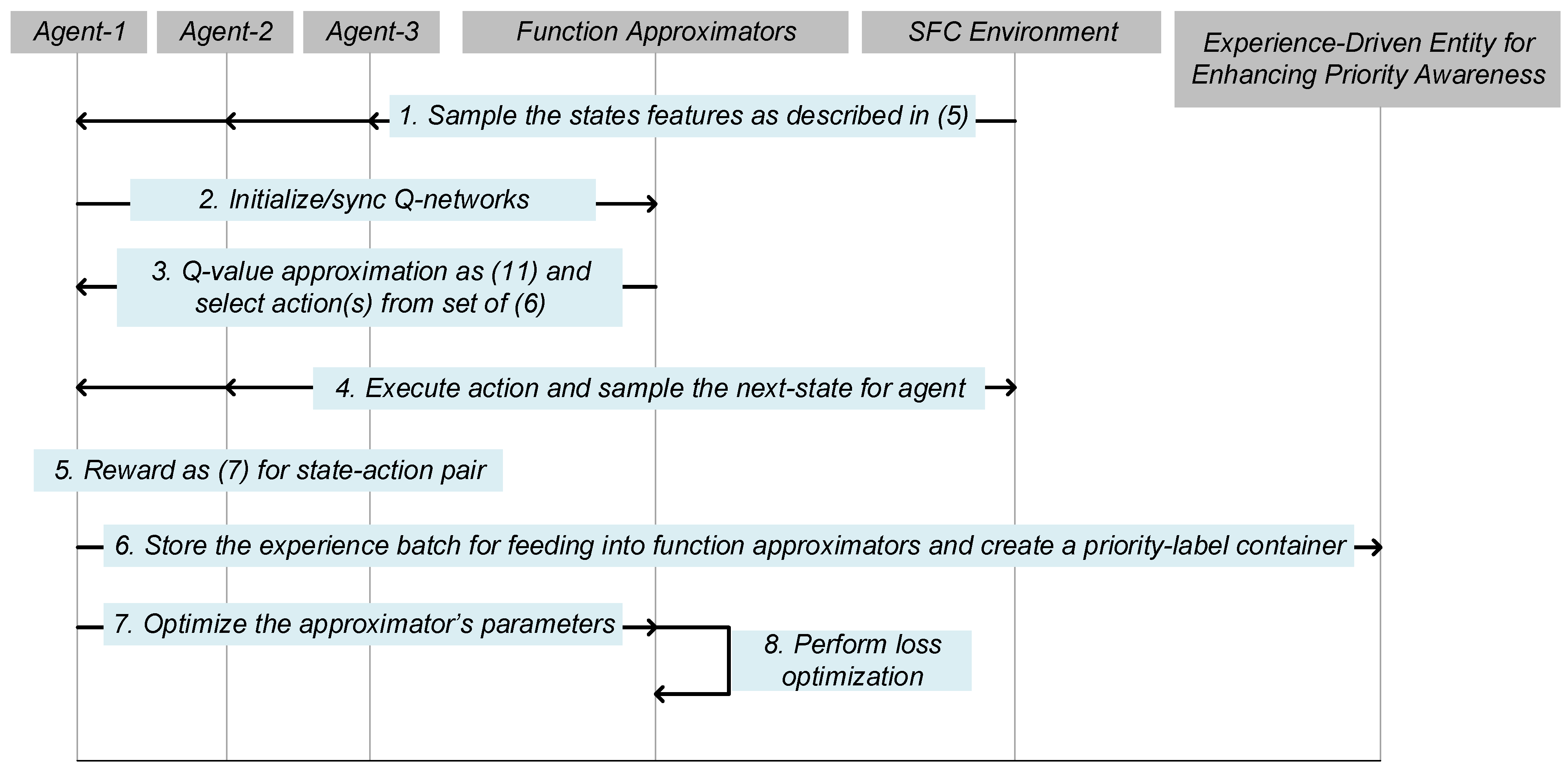
To interact between SDN/NFV-assisted SFC system models with the proposed agent, the Markov decision process model is applied for determining the state observations, action spaces, and rewards as primary objectives in policy orchestration. The process of each agent follows four primary phases, namely SFC environment initialization, state gathering, reward-maximized action selection, experience-driven exploitation, and improved parameters for the function approximator. In the early stage, the proposed model of each agent learns the possible actions for fitting within state observations in different congestion intervals of massive IoT. The management layer of the setup environment uses the application programming interfaces and protocols to sample the workload of VNF instances within each path for the proposed agent in the core control. The agent selects actions via an optimization process and experience-driven mechanism. Each applied action is stored for iterative improvement and synchronously transitioning to future states.
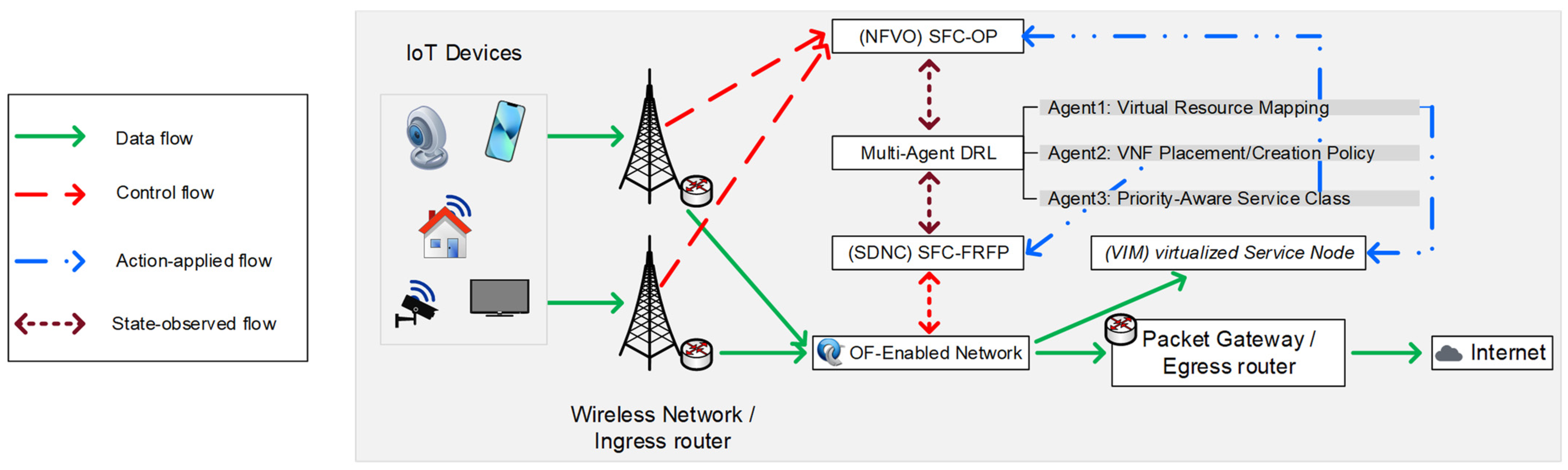
Figure 3 presents an overview architecture of the interaction between SDN/NFV-assisted SFC systems and proposed agents. There are three predominant agents which aim for (1) virtual resource mapping, (2) VNF placement/creation policy, and (3) priority-aware service labeling. The agents observe the states and apply the action from/to the SFC orchestration policy (SFC-OP) and SFC flow rule forwarding path (SFC-FRFP) in the NFV orchestrator (NFVO) and SDN controller (SDNC), respectively.
SFC-OP responses control the forwarding path, initialize/modify/delete service chains, and adjust the priority. SFC-FRFP manages the flow rule installation and instance selection. The virtual service nodes at the virtual infrastructure manager (VIM) consist of virtualized resources and maps with workload-based functions. To execute this processing flow and acquire an optimal reward, the primary objectives, model formulation of each agent, and SDN/NFV-based SFC orchestration requires in-depth descriptions, which will be presented in this section as follows.
The confluence of reinforcement learning and deep neural networks (function approximators) enables an optimal output on action selection and advanced Q-value function. The proposed agent uses the components of the Markov decision process in the SFC environment for handling the optimization learning. There are four primary components for multiple agents to feed and iteratively establish for the final learning policy, which includes a collective batch, in this system architecture:
State spaces indicate the significant features of the SDN/NFV-assisted SFC environment, where the placement costs, bandwidth allocation, link costs, and required resources per VNF are observed for formulating the central policy in both SFC-OP and SFC-FRFP. The proposed multi-agent DRL utilizes the Markov decision process framework to tackle the problem by synchronously storing the sequential experienced IoT networking. SFC-OP ensures the provision of the placement
and link
costs for agents. SFC-FRFP responds with
and
The reference points are assigned within NFV management and orchestration entities. Representational state transfer is used mainly in SDNC for interactions between OF-enabled networks (cluster heads), SFC-FRFP, and central multiple agents. These interfaces allow communications within central software mechanism systems for high and reliable performance.
Actor spaces consist of the configuration parameters in priority-aware SFC systems that highly impact the system execution. The status of deploying VNF in any particular path
can be adjusted between 0 and 1, which acts as a decision variable of the placement. The proposed agent considers the workload of services, application criticality, and congestion as major factors. Similarly,
is also a decision variable for placing virtual links between VNFs, which outputs between 0 and 1. This configuration aims to emphasize the difference between connectivity points in non-real-time and real-time IoT services. The service criticality is incorporated with the application plane in the SDN-based management and experience-driven entity for enhancing the priority awareness, which integrates weight
for any service path
. The critical ratio is a ranging float value from 0.0 to 1.0, where 1.0 allows the allocation to be completely placed in critical real-time labels. The predetermined resource allocation from
maximizes or stabilizes its value based on the service-critical weights. For example, the critical weight of 0.5 in service
from
agent 3 decides the final values of placement and resource capacities from both
agents 1 and
2 as described in Equations (1) and (2).
Reward determines the evaluation of applied
, in terms of placement decision variables and weights, on current costs, required computation, and available bandwidth resources as
. With the performance of the state–action pair
, the collective rewards on each agent, as shown in (7), are reflected to reward
agents 1,
2, and
3 as expressed in (8), (9), and (10), respectively. The reward for
agent 1, denoted as
, presents the resource efficiency by aiming to compare the optimal variables that minimize the overload resource placement. The minimization follows the constraints of decreasing the output when it exceeds 1, and the optimal output is 1 since the model meets the best matching orchestration when
is equal to
. The reward for
agent 2, denoted as
, aims to range the scoring reward based on a container with minimization of the placing costs. A tradeoff between high cost and latency occurs when the
is equal to 1 (highly mission-critical weight). The latency performance of executing the service path is emphasized as a reward
in
agent 3. The latency in orchestration, execution, and modification in the processing SFC systems reflects the performances compared with the lower-bound and upper-bound threshold of each service QoS class identifier.
Q-value and loss optimization aims to optimize long-term targets and parameters for the deep networks of function approximators. The target network uses the replay batch parameters for training. However, in every training phase, loss values appear as either high or low compared to the satisfactory point. The loss follows the mean square error concept, which is a squared difference between the target
and predicted q-value. With optimal q-value approximation, the agent can take actions that maximize the performance of each real-time service with long-term efficiency. Equation (11) presents the primary target
q-value, which follows the rewards in (8)–(10) with the discount factor
(uncertainty rate) of the expected maximum in the next state. The networks (online and target) iteratively modify the parameters and synchronously exchange the weights. The policy iteration of multi-agent DQNs consists of a flow transition between each component in the Markov decision process framework, which is depicted in
Figure 4.
When the service task is offloaded in the SFC environment, the requests will be checked in the SFC-OP and SFC-FRFP entities to delete, occupy, or instantiate the new/existing service type with the same or different required VNFs. If the service is instantiated, the states of costs, computing properties, and bandwidth for transmission will be observed for the agents. The descriptors are created in SFC-OP. The existing set of VNFs will be iteratively checked in the VNF manager for matching, and the virtual links will be placed. Agent 1 slices the virtual resource mapping based on the optimal policy in the current timeslot. After finalizing the creation of the required VNFs, VNFFG, and SFC flows, the SDNC appends the flow rules and executes the service path.
5. Performance Evaluation
This section shows the performance evaluation of the proposed priority-aware policy with multi-agent DQNs for optimal resource management, termed PA-DQNs-RM. The SDN/NFV testbed is integrated for considering the complete processes of instantiating/declining the service chain (using ordered descriptor representations with the TOSCA NFV template).
Table 3 presents the software-defined control system configuration [
25,
26,
27,
28]. With a defined SFC topology on SDN/NFV-enabled architecture, the data features are extracted for computing the agent model on OpenAI Gym and TensorFlow 2.0 [
29,
30,
31,
32]. Each agent consists of five primary entities, namely environment initialization, deploying action, next-state transition, reset/complete statuses, and immediate rewards/Q-values/epsilon-greedy on the main agent function. The hyperparameters of the proposed agent are 0.01, 0.95, and 300 as learning rate, discount factor, and episodes, respectively. The overall simulations were executed on a computing server with an Intel(R) Xeon(R) Silver 4280 CPU @ 2.10 GHz, 128 GB memory, and an NVIDIA Quadro RTX 4000 GPU.
5.1. Proposed and Reference Schemes
The proposed scheme, termed PA-DQNs-RM, follows the multi-agent DQN mechanism as described in
Section 3 and
Section 4, primarily using (1) the state features of the SFC environment including costs, bandwidth availability, and virtual links; (2) actions of making decisions on adjusting weights depending on the service priority; and (3) a multi-perspective reward valuation. To handle the uncertainty of congestion and performance instability, the proposed scheme gathers the state features and experienced path for dynamically adjusting the critical weight. In the aspect of experiments, the assigned application programming interfaces abstract devices/resources for state observations and adjust the simulation parameters to heavily congested, normally congested, and non-congested communications. By fully merging the outputs between each agent, the policy orchestration and forwarding rules on SDN/NFV management entities are capable of managing the resources efficiently. To present the performance efficiency of the proposed scheme, three reference schemes are selected for experimentation and comparison as follows:
DQN-RM indicates the single-agent mechanism which tackles resource management without considering the critical weights
of service priority awareness. A variety of congestion intervals leads DQN-RM to consist of deficient action selection, particularly when parallel service requests occur. By solely tackling the resource predetermination
, the efficiency of resources is high; however, it remains an optimizable mechanism for real-time intelligent IoT services [
33,
34,
35]. This reference scheme observes the same states as the proposed priority-aware scheme.
Random-RM is used as a conventional approach in various complementary studies, where the orchestration policy allocates the system resources by random method [
15,
34]. The rewards are still formulated in this scheme, by executing the service requests with adjusted random resources and service-critical weights.
MR-RM follows the greedy method by managing the resources based on either cost or real-time latency optimization. In our experience, we prioritize real-time latency over cost, which leads to a configuration maximal rate of .
5.2. Performance Metrics
In this study, the main objective is to illustrate the performance optimization within the execution of SFC environments from IoT tenants to end services. The optimization mechanism is located in the control plane/orchestrator as a core system of virtual resource mapping, virtual function placement, and priority awareness. Other than the core system, the flows are executed via default simulation topology. The interfaces for N4, N6, and N9 are adopted for SDN-based systems. The payload is assigned for IoT services. The detailed configuration is described in
Table 3. The selected metrics for evaluation are captured and calculated in the aspects of executing per service chain in heterogeneous IoT networks. The performance metrics include the following:
The average immediate total reward per episode identifies the output of evaluating the state–action execution as expressed in Equations (7), (8), (9), and (10). In the experiment, the agent operates for 300 episodes. Epsilon-greedy balances the exploring and exploiting phase. The immediate rewards are most likely to be stable after 150 episodes. The average metric sums up every immediate reward of that episode and then divides it by the total numbers. The visualization is considered per 50-episode average to present the accumulative outputs. The proposed and reference schemes operate using the same hyperparameters. A negative reward (−10, −1) identifies deficient action selection. The maximum value is 0.
End-to-end executing delay of requested services is measured in milliseconds (ms) within 300 s simulation time. This metric is considered the total time from IoT tenants to end service, which differentiates between the proposed and reference schemes only by . The propagation, queueing, transmission, and proposed agent orchestration are calculated for this metric.
Delivery ratio: tasks of requested services represent the efficiency of the decision-making agent when the service requests are being operated, whether there is a reliable path or not. The instantiation, deletion, and modification of service requests are the key management in this environment and variables for ensuring the reliability of the offloading and placed service tasks on any particular chain. With low delivery ratios, the policy is not suitable for real-time IoT scenarios. The priority-aware scheme takes the upper-bound tolerable delays more critically, and they are assigned a critical weight for preventing the high drop possibility.
Throughput indicates the success data over the allocated bandwidth and VM computation resources for going through each VNF on SFC systems. This metric is measured in megabits per second (Mbps).
5.3. Result and Discussions
In this sub-section, the outputs of the proposed and reference schemes are shown in terms of four main performance metrics. Each scheme follows the simulation setup for overall topologies. SFC-OP and SFC-FRPR differentiate the performance metrics as depicted in
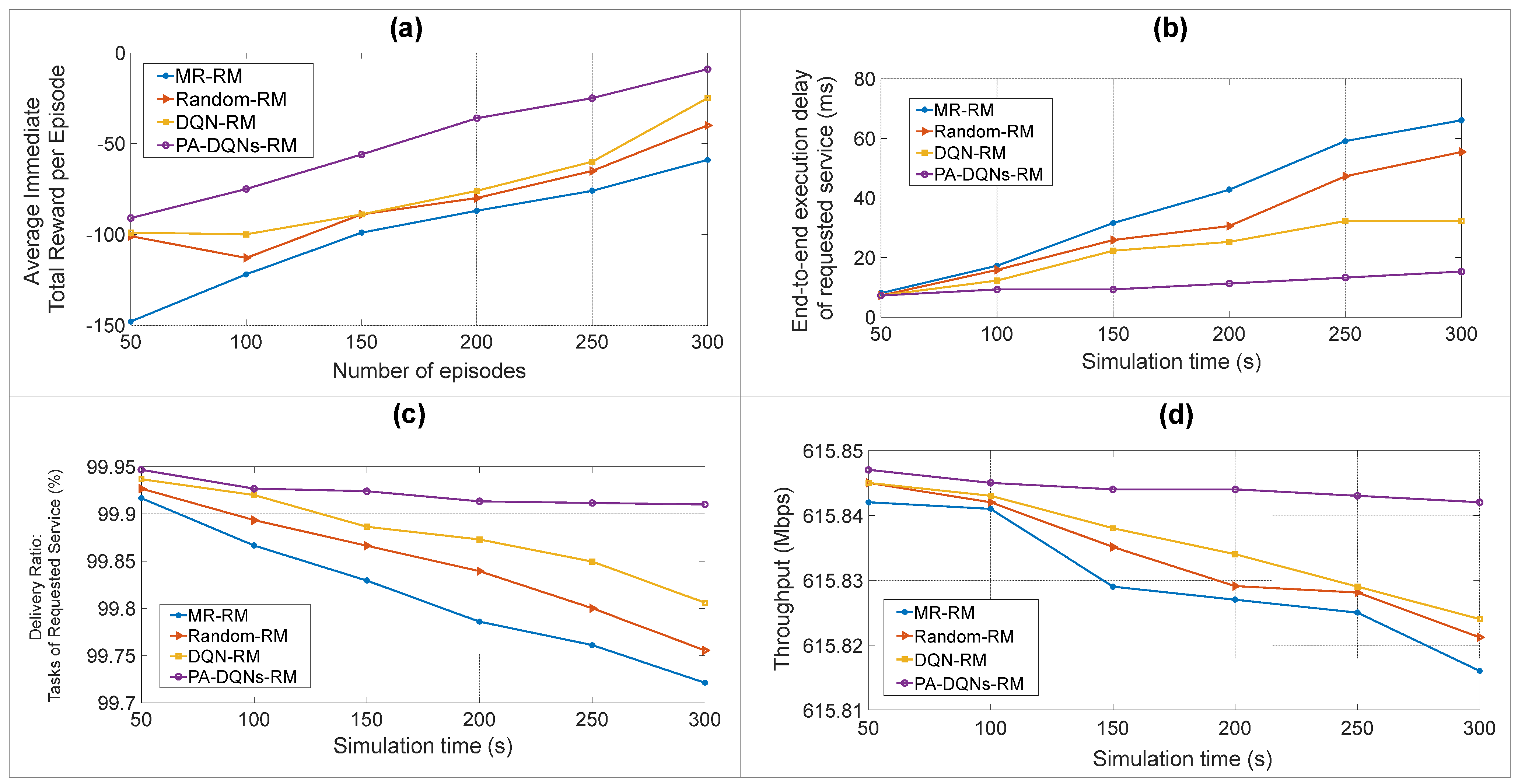
Figure 5, which include (a) the average immediate total reward per 50 episodes over a 300-episode experiment; (b) end-to-end execution delay of requested services in ms; (c) delivery ratio: tasks of requested service in percentile ratio; and (d) throughput in Mbps. Over a 300 s simulation, the fluctuation is greatly shown in 150 and 250, where the configuration of requesting a new service is assigned to the experiment. The uncertainty of network states is randomized following congestion levels in both peak and off-peak hours. The states of congestion and non-congestion are observed for the agent.
Figure 5a illustrates how the agent explored and exploited throughout each episode. In the early first 50 iterations, the proposed PA-DQNs-RM obtains −91 negative rewards, which are 8, 10, and 57 positive scores higher than DQN-RM, Random-RM, and MR-RM, respectively. By 150, the proposed policy is capable of alleviating 39.5301% of errors and obtains a great reward. By the end of 300, the agent reached optimal exploitation satisfaction with −9 scores. This score indicates only nine non-optimal orchestrations over numerous possible states. With a multi-aspect weighted sum reward, the agent is more reliable for estimating a long-term SFC instantiation, particularly for multi-taxonomy IoT applications. The priority-aware algorithm with nine non-optimal statuses ensures the reliability and transferability of scalable SFC-IoT management systems. Since the total reward
considers the optimization points of costs, resources, and latencies, the output presents a whole tradeoff in different congestion states, where multiple service requests from real-time IoT services are labeled into different priority classes.
The end-to-end execution delay of the requested service primarily tackles the IoT tenant task of determining whether (1) to request new chain instantiation or (2) to check for an existing chain until the flow rule is installed into Open vSwitch and execute the service with its required set of VNFs.
Figure 5b shows the results of the proposed and reference delays. In 150 s, the reference schemes increase the delays by 25.6014%, 28.1801%, and 32.7842%, which gives an unsatisfactory jitter for real-time IoT experiences. Within the configuration of new request instantiation on 150 and 250, the proposed scheme has a deviation of only 1.9911 ms and 5.9932 ms compared to the first 50 s of the experiment.
The execution delay of the proposed scheme shows the sustainability of SFC-OP and SFC-FRFP for long-term self-managing SFC when it comes to instantiating new chain requests or modifying the VNF/VNFFG instances. In terms of reliability,
Figure 5c shows the delivery ratio of the requested service tasks. Since the real-time IoT QoS class identifier sets the required upper-bound tolerable delays lower than non-real-time applications, the priority-aware approach is significant for deployment within adaptive agent observation. PA-DQNs-RM reached an average successful chain execution ratio of 99.9221% over a 300 s simulation, which is 0.0423%, 0.0751%, and 0.1085% higher than DQN-RM, Random-RM, and MR-RM, respectively. Each agent has different responsibility for this performance metric, and it is equally significant to map adequate resource capacities, place appropriate VNFs, and proactively label the service-critical weight. By predetermining the communication and computation resources, the delivery ratio on future bottlenecks can be greatly reduced.
Figure 5d presents the total throughput per second in the conducted experiments. In 150, IoT tenants request new chains for the central SFC systems, which heavily degrades the throughput of reference schemes. Compared to a 100 s experiment point, MR-RM degrades the performance by 12 time differences, which can be explained by that when the new chain request is required, the maximal rate configuration cannot configure the optimal weight and lacks self-organizing on unseen requests. This drawback severely affects real-time IoT services. For Random-RM and DQN-RM, a great fluctuation is not shown in 150; however, the throughputs are noticeably lessening until the ending point. The proposed scheme has a stable performance, where the difference between the beginning and the ending point of the experiment is only 0.005 Mbps. The balance of serving both existing/new requests contributes to being a sufficient system. In real-time deep learning-based modeling in IoT services, each VNF can be modified over time, as can the VM allocation; therefore, the priority-aware resource management with dynamic multi-agent DQNs is an efficient approach for maintaining an adaptive SFC system.
6. Conclusions and Future Work
This paper presented a priority-aware resource management scheme for SDN/NFV-assisted SFC systems. The proposed scheme, termed PA-DQNs-RM, primarily relies on multi-agent DQNs, which consist of three aspects, namely virtual resource mapping, VNF placement/creation, and awareness of different real-time IoT service priorities. The system models of NFV-based SFC and SDNC for SFC forwarding path installation were described in this paper. Each model consists of action-configurable parameters such as the critical weight of prioritized service, the status variables of deploying VNF/virtual links, and the predetermination function of resource allocation in each VNF/VNFFG descriptor. A multi-aspect total reward, including resource valuation, placing costs, and latency performance, was assigned for scoring the efficiencies of applied actions over the proposed SFC environment. The simulation setup was given, and the experiment was conducted by including both SDN/NFV-enabled testbed and agent models. PA-DQNs-RM achieved a variety of satisfying performance metrics, including (1) average immediate total reward per episode, (2) end-to-end executing delay of requested services, (3) delivery ratio: tasks of requested services, and (4) throughput, for supporting multi-priority services in real-time IoT. Within this simulation environment, the proposed agent obtained averages of rewards per episode, end-to-end delays, delivery ratio of requested new/created services, and throughput of −48.6666, 10.9766 ms, 99.9221%, and 615.8441 Mbps, respectively. Compared to the reference approaches, the proposed scheme offers an optimized awareness policy for multi-service priorities in real-time IoT networks.
In a future study, experience-driven virtual resource scheduling for IoT network slicing will be further extended over this proposed approach. The SDN/NFV-enabled system architecture for on-demand network slicing will be modeled for a deep deterministic policy gradient-based agent to configure continuous actions and optimize the complete end-to-end real-time IoT network slicing.
Author Contributions
Conceptualization, S.K., P.T. and S.M.; methodology, S.K., P.T. and S.M.; software, P.T.; validation, P.T. and S.M.; formal analysis, P.T.; investigation, S.K.; resources, S.K.; data curation, P.T. and S.M.; writing—original draft preparation, P.T.; writing—review and editing, S.K., P.T. and S.M.; visualization, P.T.; supervision, S.K.; project administration, S.K.; funding acquisition, S.K. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by Institute of Information & communications Technology Planning & Evaluation (IITP) grant funded by the Korea government(MSIT) (No. RS-2022-00167197, Development of Intelligent 5G/6G Infrastructure Technology for The Smart City), in part by BK21 FOUR (Fostering Outstanding Universities for Research) under Grant 5199990914048, in part by the National Research Foundation of Korea (NRF), Ministry of Education, through Basic Science Research Program under Grant NRF-2020R1I1A3066543, and in part by the Soonchunhyang University Research Fund.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Mijumbi, R.; Serrat, J.; Gorricho, J.L.; Bouten, N.; De Turck, F.; Boutaba, R. Network function virtualization: State-of-the-art and research challenges. IEEE Commun. Surv. Tutor. 2016, 18, 236–262. [Google Scholar] [CrossRef]
- European Telecommunications Standards Institute (ETSI). Deployment of Mobile Edge Computing in an NFV environment. ESTI Group Rep. MEC 2018, 17, V1. [Google Scholar]
- Contreras, L.M.; Bernardos, C.J. Overview of Architectural Alternatives for the Integration of ETSI MEC Environments from Different Administrative Domains. Electronics 2020, 9, 1392. [Google Scholar] [CrossRef]
- Xie, J.; Yu, F.R.; Huang, T.; Xie, R.; Liu, J.; Wang, C.; Liu, Y. A survey of machine learning techniques applied to software defined networking (SDN): Research issues and challenges. IEEE Commun. Surv. Tutor. 2018, 21, 393–430. [Google Scholar] [CrossRef]
- Minias, D.M.; Shami, A. The Need for Advanced Intelligence in NFV Management and Orchestration. IEEE Netw. 2021, 35, 365–371. [Google Scholar] [CrossRef]
- McClellan, M.; Cervelló-Pastor, C.; Sallent, S. Deep Learning at the Mobile Edge: Opportunities for 5G Networks. Appl. Sci. 2020, 10, 4735. [Google Scholar] [CrossRef]
- Chen, W.; Qiu, X.; Cai, T.; Dai, H.N.; Zheng, Z.; Zhang, Y. Deep Reinforcement Learning for Internet of Things: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2021, 23, 1659–1692. [Google Scholar] [CrossRef]
- ETSI GS ZSM 009-2 V1.1.1; Zero-Touch Network and Service Management (ZSM); Cross-Domain E2E Service Lifecycle Management. European Telecommunications Standards Institute (ETSI): Sophia-Antipolis, France, 2022.
- Ning, Z.; Wang, N.; Tafazolli, R. Deep Reinforcement Learning for NFV-based Service Function Chaining in Multi-Service Networks. In Proceedings of the 2020 IEEE 21st International Conference on High Performance Switching and Routing (HPSR), Newark, NJ, USA, 11–14 May 2020; pp. 1–6. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Introduction to Reinforcement Learning; MIT Press Cambridge: Cambridge, MA, USA, 1998; Volume 2. [Google Scholar]
- Vithayathil Varghese, N.; Mahmoud, Q.H. A Survey of Multi-Task Deep Reinforcement Learning. Electronics 2020, 9, 1363. [Google Scholar] [CrossRef]
- Chae, J.; Kim, N. Multicast Tree Generation using Meta Reinforcement Learning in SDN-based Smart Network Platforms. KSII Trans. Internet Inf. Syst. 2021, 15, 3138–3150. [Google Scholar]
- Adoga, H.U.; Pezaros, D.P. Network Function Virtualization and Service Function Chaining Frameworks: A Comprehensive Review of Requirements, Objectives, Implementations, and Open Research Challenges. Future Internet 2022, 14, 59. [Google Scholar] [CrossRef]
- Moonseong, K.; Woochan, L. Adaptive Success Rate-based Sensor Relocation for IoT Applications. KSII Trans. Internet Inf. Syst. 2021, 15, 3120–3137. [Google Scholar]
- Kim, E.G.; Kim, S. An Efficient Software Defined Data Transmission Scheme based on Mobile Edge Computing for the Massive IoT Environment. KSII Trans. Internet Inf. Syst. 2018, 12, 974–987. [Google Scholar]
- Guo, A.; Yuan, C. Network Intelligent Control and Traffic Optimization Based on SDN and Artificial Intelligence. Electronics 2021, 10, 700. [Google Scholar] [CrossRef]
- Pei, J.; Hong, P.; Pan, M.; Liu, J.; Zhou, J. Optimal VNF placement via deep reinforcement learning in SDN/NFV-enabled networks. IEEE J. Sel. Areas Commun. 2019, 38, 263–278. [Google Scholar] [CrossRef]
- Bunyakitanon, M.; Vasilakos, X.; Nejabati, R.; Simeonidou, D. End-to-end performance-based autonomous VNF placement with adopted reinforcement learning. IEEE Trans. Cogn. Commun. Netw. 2021, 6, 534–547. [Google Scholar] [CrossRef]
- Jang, I.; Choo, S.; Kim, M.; Pack, S.; Shin, M. Optimal Network Resource Utilization in Service Function Chaining. In Proceedings of the 2016 IEEE NetSoft Conference and Workshops 2016, Seoul, Korea, 6–10 June 2016; pp. 11–14. [Google Scholar]
- Wang, X.; Xu, B.; Jin, F. An Efficient Service Function Chains Orchestration Algorithm for Mobile Edge Computing. KSII Trans. Internet Inf. Syst. 2021, 15, 4364–4384. [Google Scholar]
- Okafor, K.C.; Longe, O.M. Integrating Resilient Tier N+1 Networks with Distributed Non-Recursive Cloud Model for Cyber-Physical Applications. KSII Trans. Internet Inf. Syst. 2022, 16, 2257–2285. [Google Scholar]
- Qiao, Q. Routing Optimization Algorithm for Logistics Virtual Monitoring Based on VNF Dynamic Deployment. KSII Trans. Internet Inf. Syst. 2022, 16, 1708–1734. [Google Scholar]
- Alonso, R.S.; Sittón-Candanedo, I.; Casado-Vara, R.; Prieto, J.; Corchado, J.M. Deep Reinforcement Learning for the Management of Software-Defined Networks and Network Function Virtualization in an Edge-IoT Architecture. Sustainability 2020, 12, 5706. [Google Scholar] [CrossRef]
- Huang, Y.-X.; Chou, J. A Survey of NFV Network Acceleration from ETSI Perspective. Electronics 2022, 11, 1457. [Google Scholar] [CrossRef]
- Lantz, B.; O’Connor, B. A mininet-based virtual testbed for distributed sdn development. ACM Sigcomm Comput. Commun. Rev. 2015, 45, 365–366. [Google Scholar] [CrossRef]
- Oliveira, R.L.S.D.; Schweitzer, C.M.; Shinoda, A.A.; Prete, L.R. Using mininet for emulation and prototyping software-defined networks. In Proceedings of the 2014 IEEE Colombian Conference on Communications and Computing (COLCOM), Bogota, Colombia, 4–6 June 2014; pp. 1–6. [Google Scholar]
- Svorobej, S.; Takako Endo, P.; Bendechache, M.; Filelis-Papadopoulos, C.; Giannoutakis, K.M.; Gravvanis, G.A.; Tzovaras, D.; Byrne, J.; Lynn, T. Simulating Fog and Edge Computing Scenarios: An Overview and Research Challenges. Future Internet 2019, 11, 55. [Google Scholar] [CrossRef]
- Park, J.-H.; Kim, H.-S.; Kim, W.-T. DM-MQTT: An Efficient MQTT Based on SDN Multicast for Massive IoT Communications. Sensors 2018, 18, 3071. [Google Scholar] [CrossRef]
- Abadi, M. Tensorflow: Learning Functions at Scale. ACM Sigplan Not. 2016, 51, 1. [Google Scholar] [CrossRef]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. OpenAI Gym. arXiv 2016, arXiv:1606.01540. [Google Scholar]
- Li, L.; Lv, Y.; Wang, F.Y. Traffic signal timing via deep reinforcement learning. IEEE/CAA J. Autom. Sin. 2016, 3, 247–254. [Google Scholar]
- Wang, S.; Liu, H.; Gomes, P.H.; Krishnamachari, B. Deep reinforcement learning for dynamic multichannel access in wireless networks. IEEE Trans. Cogn. Commun. Netw. 2018, 4, 257–265. [Google Scholar] [CrossRef]
- Tam, P.; Math, S.; Nam, C.; Kim, S. Adaptive Resource Optimized Edge Federated Learning in Real-Time Image Sensing Classifications. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 10929–10940. [Google Scholar] [CrossRef]
- Nam, C.; Math, S.; Tam, P.; Kim, S. Intelligent resource allocations for software-defined mission-critical IoT services. Comput. Mater. Contin. 2022, 73, 4087–4102. [Google Scholar]
- Math, S.; Tam, P.; Kim, S. Intelligent Offloading Decision and Resource Allocations Schemes Based on RNN/DQN for Reliability Assurance in Software-Defined Massive Machine-Type Communications. Secur. Commun. Netw. 2022, 2022, 4289216. [Google Scholar] [CrossRef]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}